Java集合大家族(学习推荐版,通俗易懂)
4.集合(ArrayList)、其他集合框架及容器遍历方式

1.ArrayList
注意:索引从0开始
该集合可以添加任意类型的数据,要约束添加数据的类型,需用泛型约束(jdk1.7开始支持泛型)

删除+遍历集合方式1(i--)
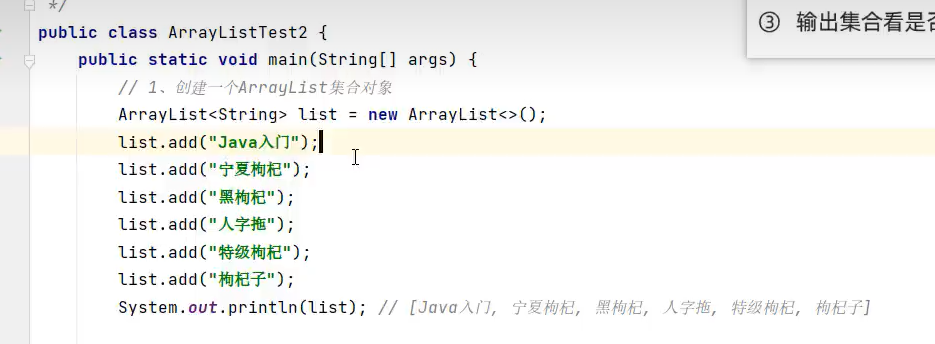
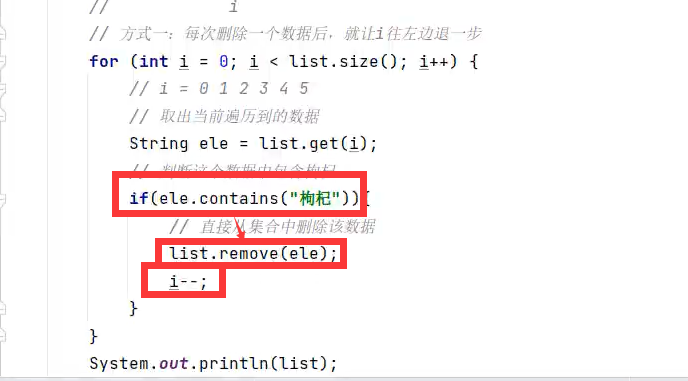
这里还可以写list.remove(i)根据索引来删和根据内容来删效果都是一样的
注意:remove删除当前元素后,当前元素后面的所有元素会整体前移,所以上面代码这里要i--;
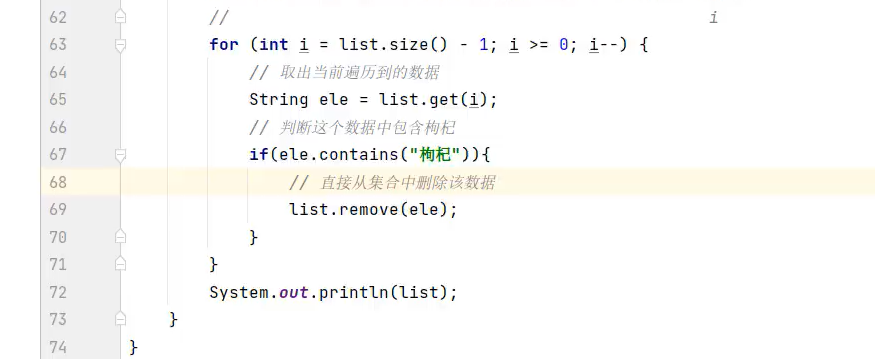
删除+遍历集合方式2(从最后索引开始倒着删)
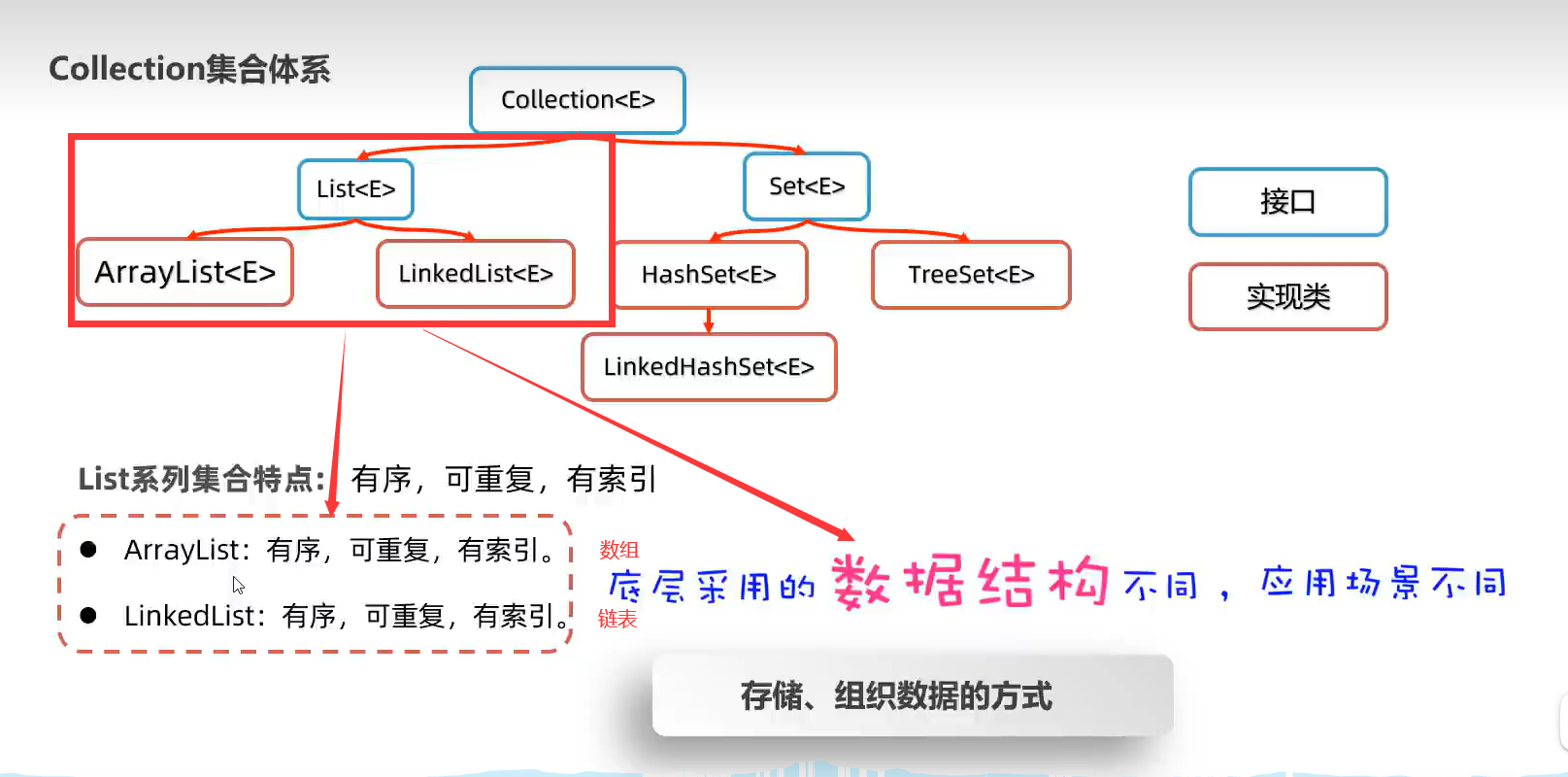
2.集合框架(Collection、Map)

1.Collection接口集合(List、Set接口集合)
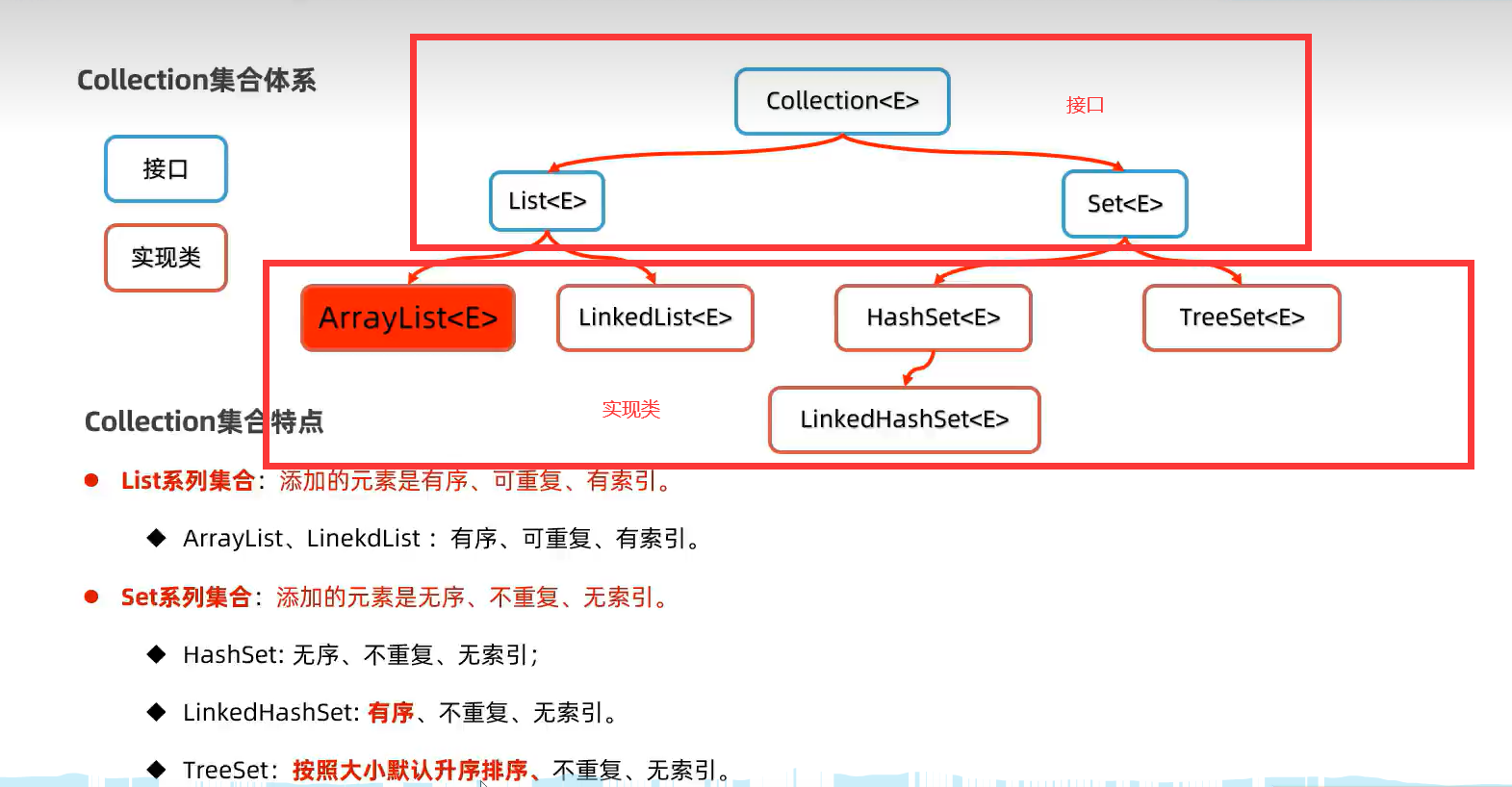
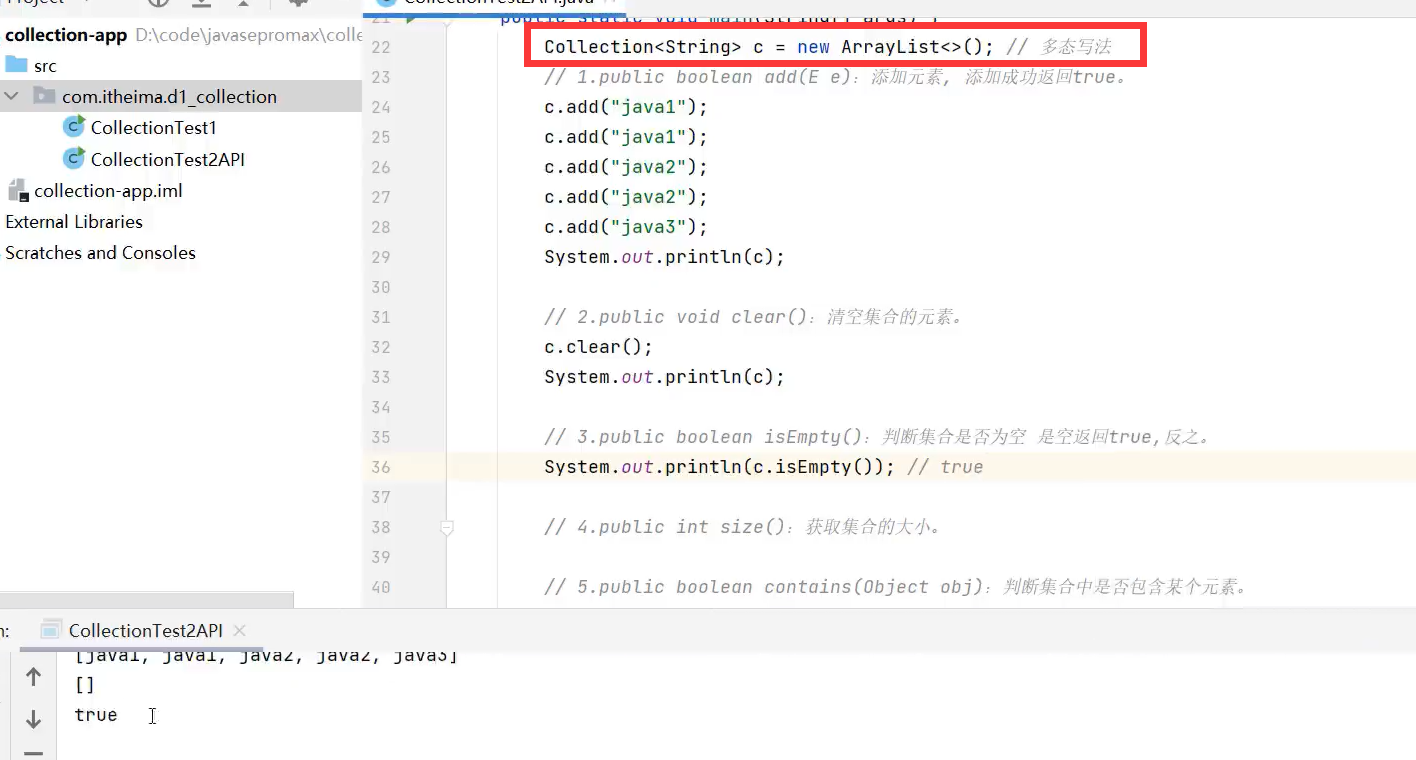
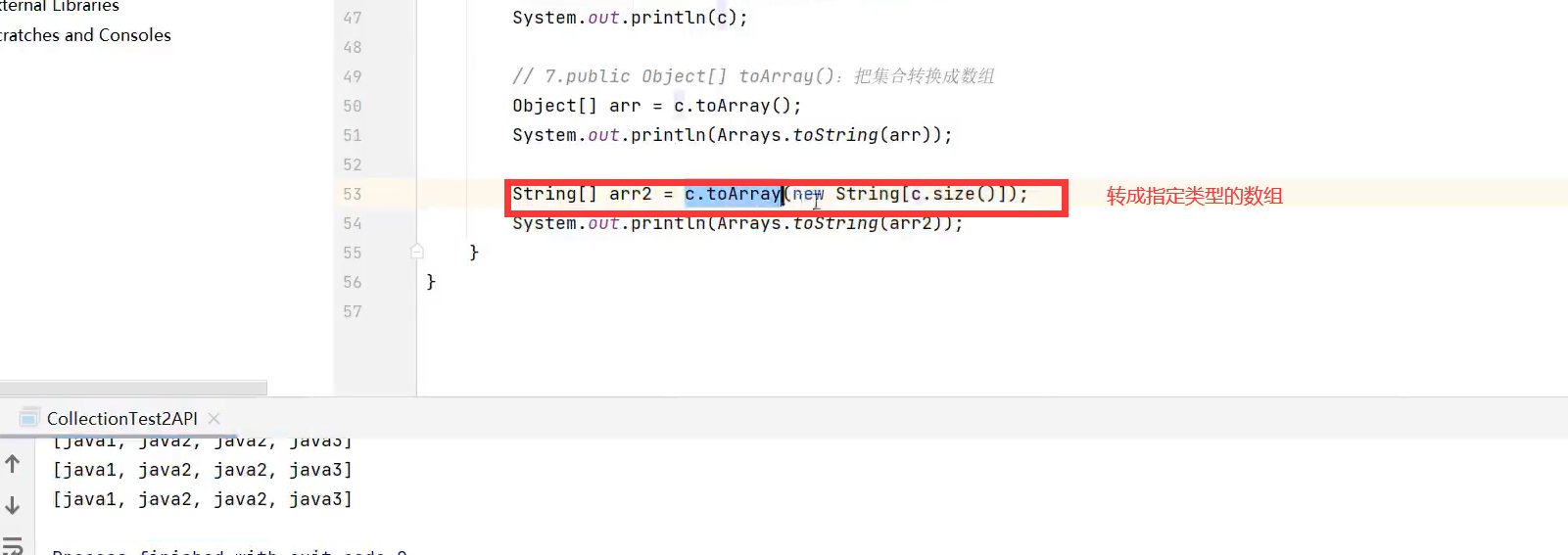
*Collection常用方法及遍历(子类为List、Set)
Collection这个父类是有序、可重复、无索引的特点。

这些方法子类及子孙类都可以使用,所以要学。
示例代码:

2.Collection的遍历方式
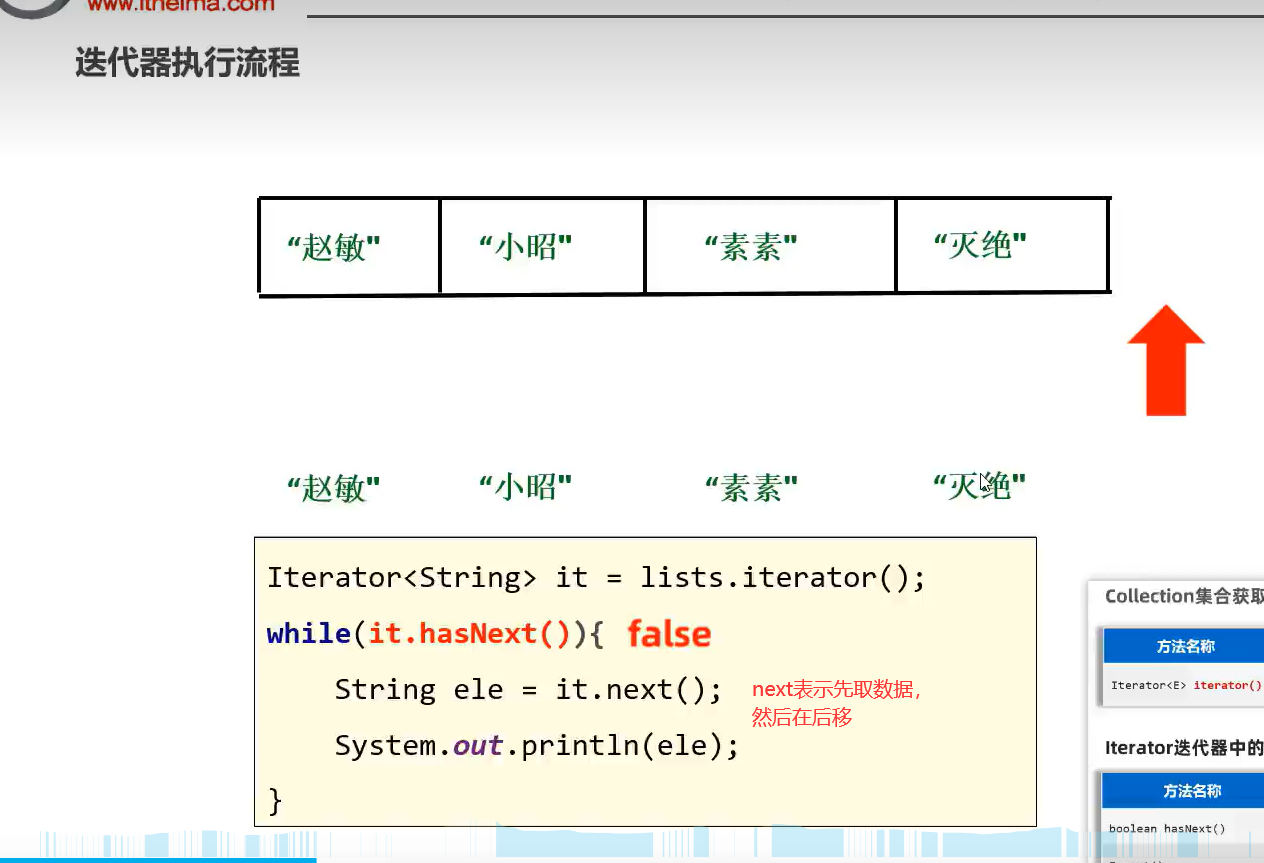
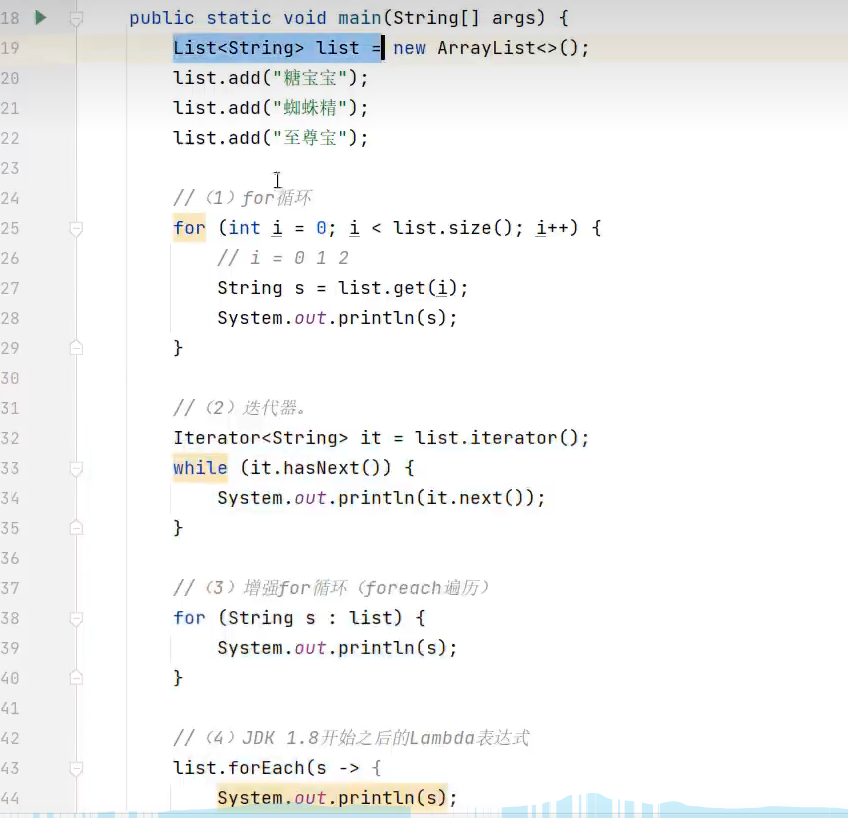
1.迭代器遍历(用于遍历无索引的容器)

想象成迭代器从第一个元素的前面开始就好了,那么next方法就可以理解为后移一个,并返回该元素值
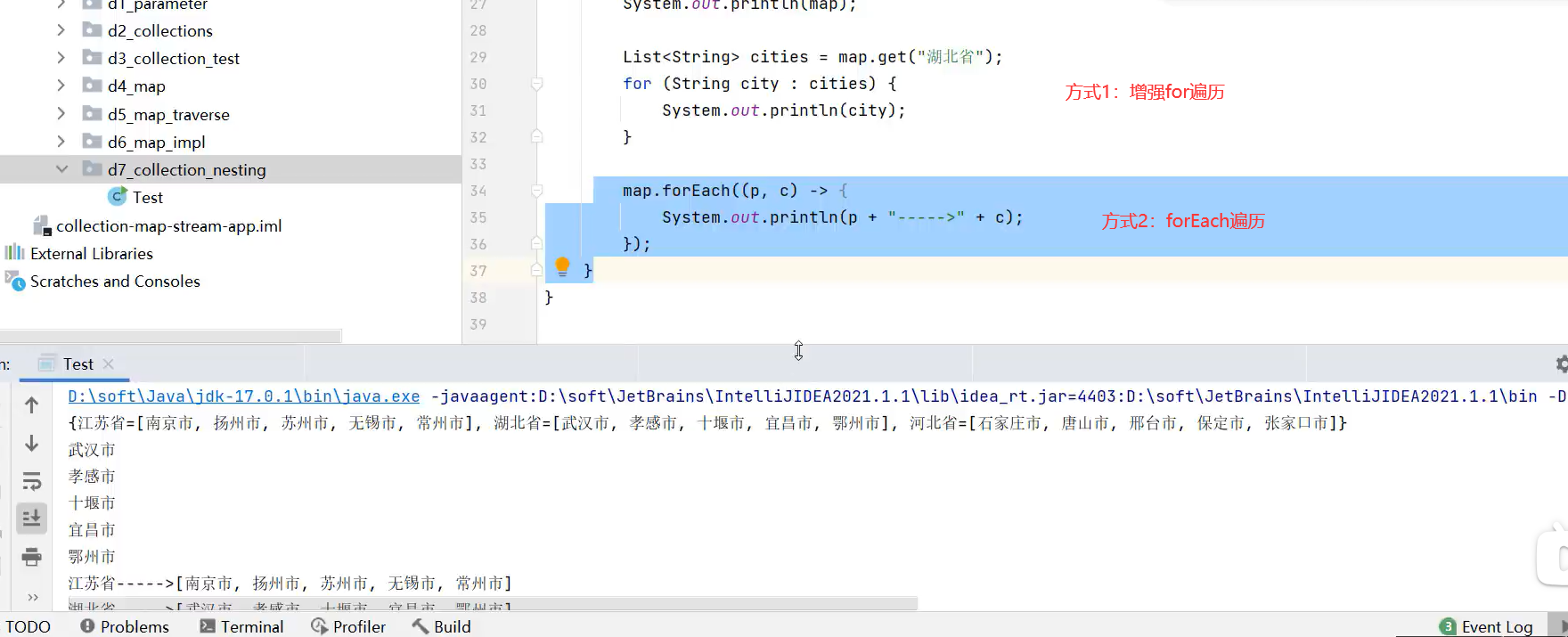
2.增强for循环(本质迭代器遍历的简化写法)
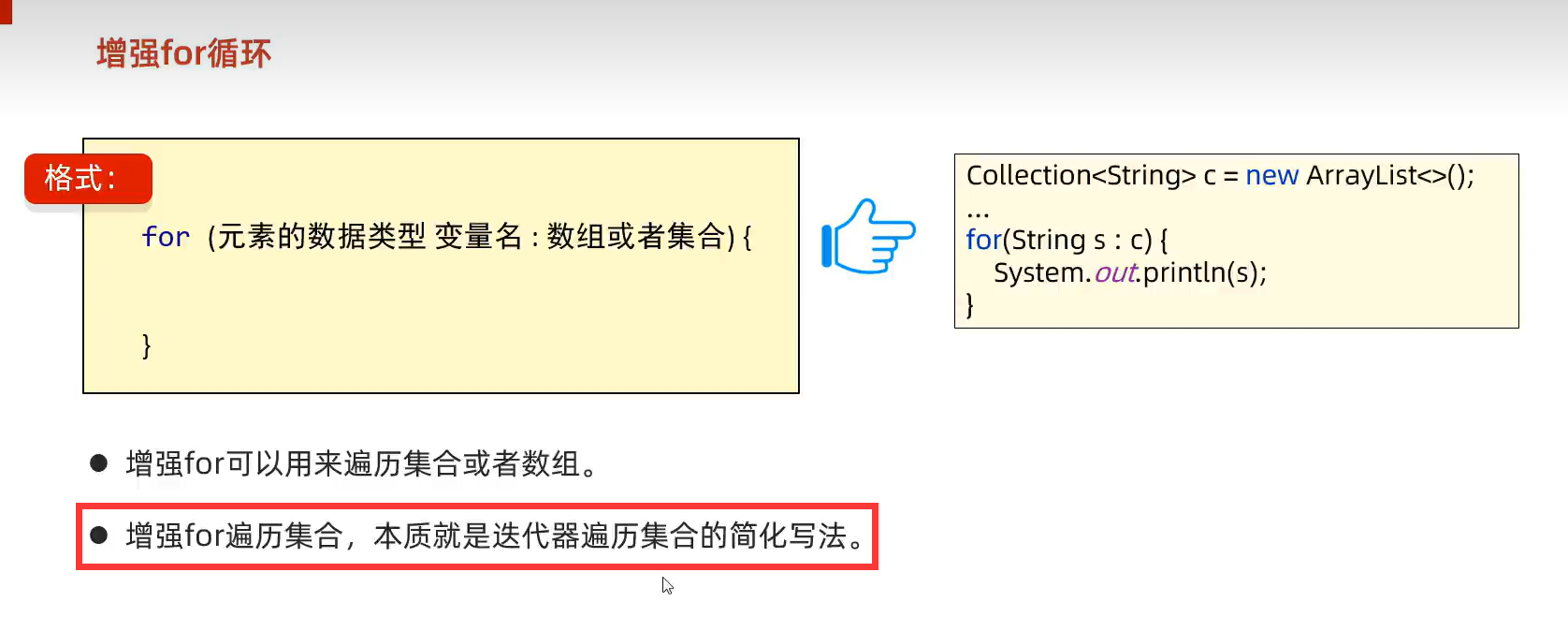
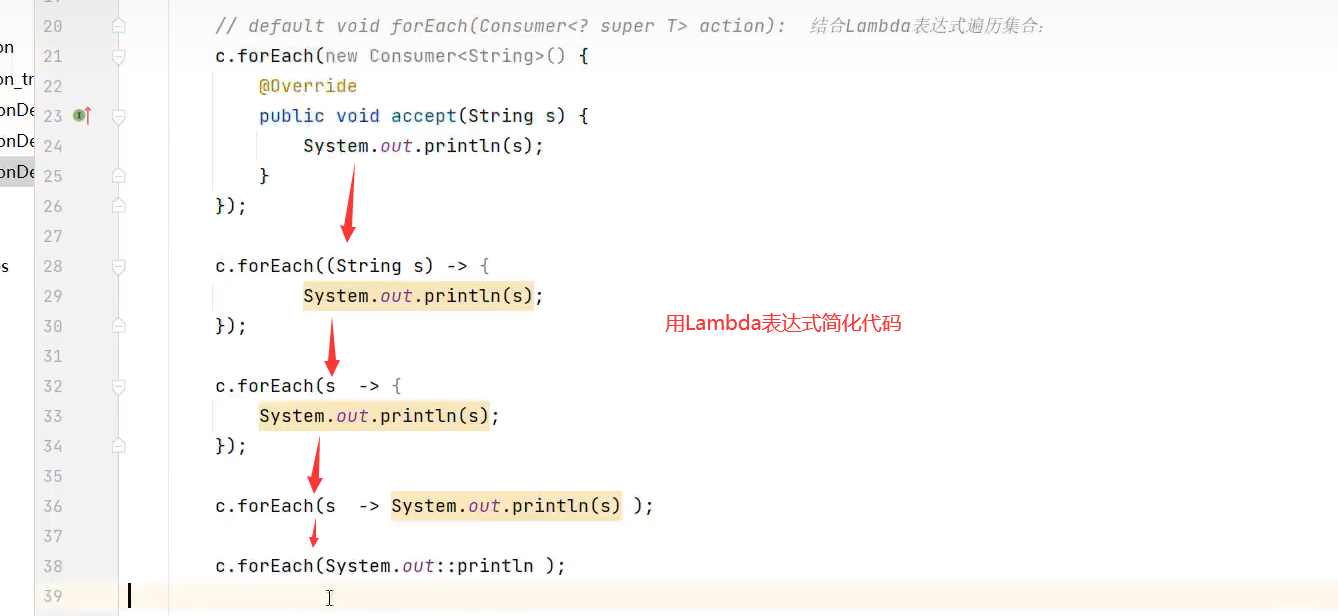
3.forEach(可用Lambda表达式简化代码,底层代码增强for)
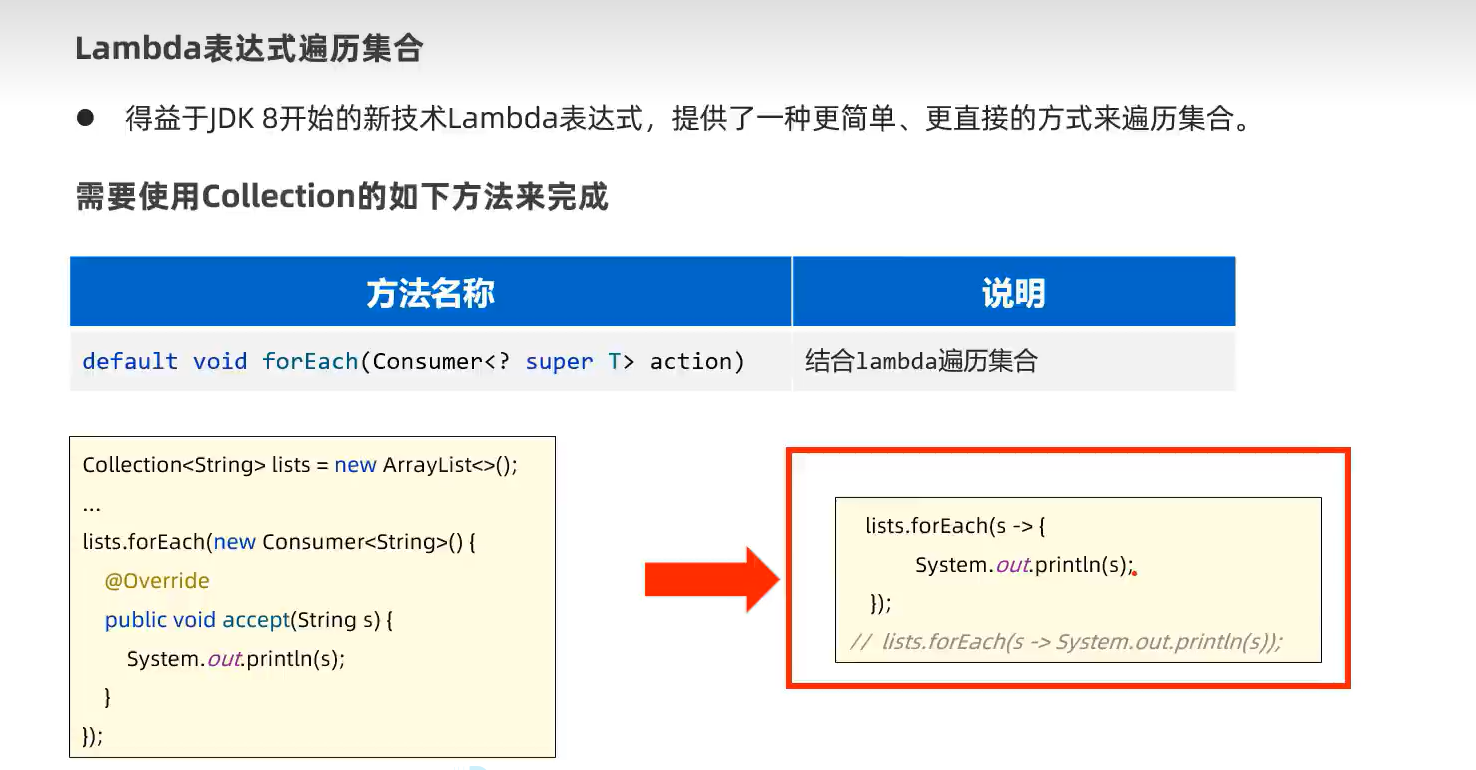
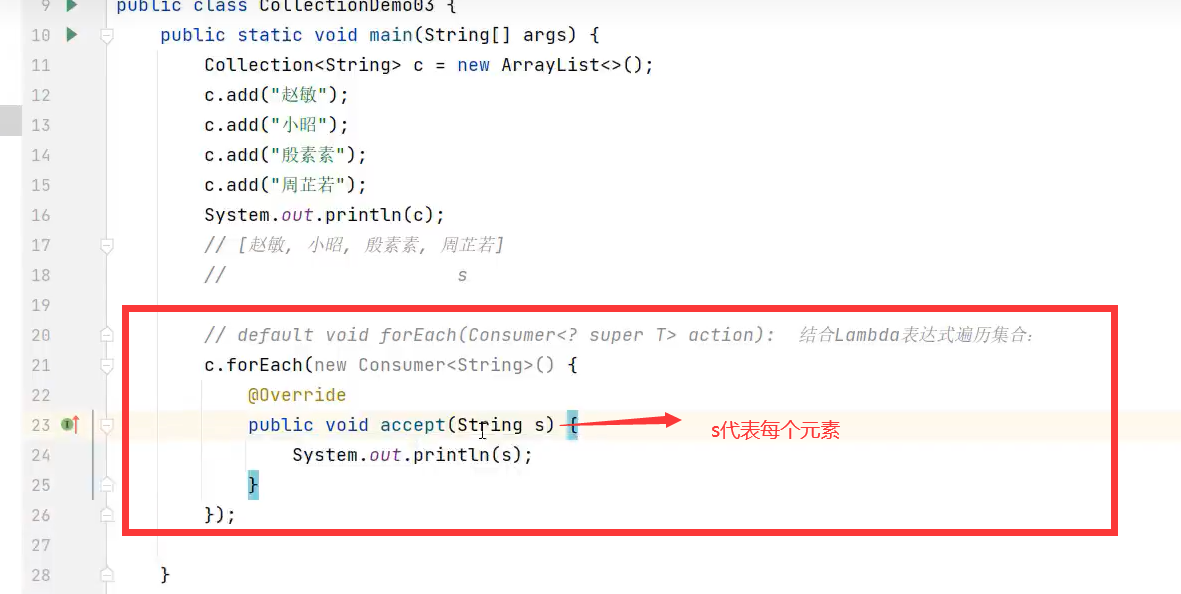
示例代码:
用Lambda表达式简化形式如下:
3.List集合(ArrayList,LinkedList)

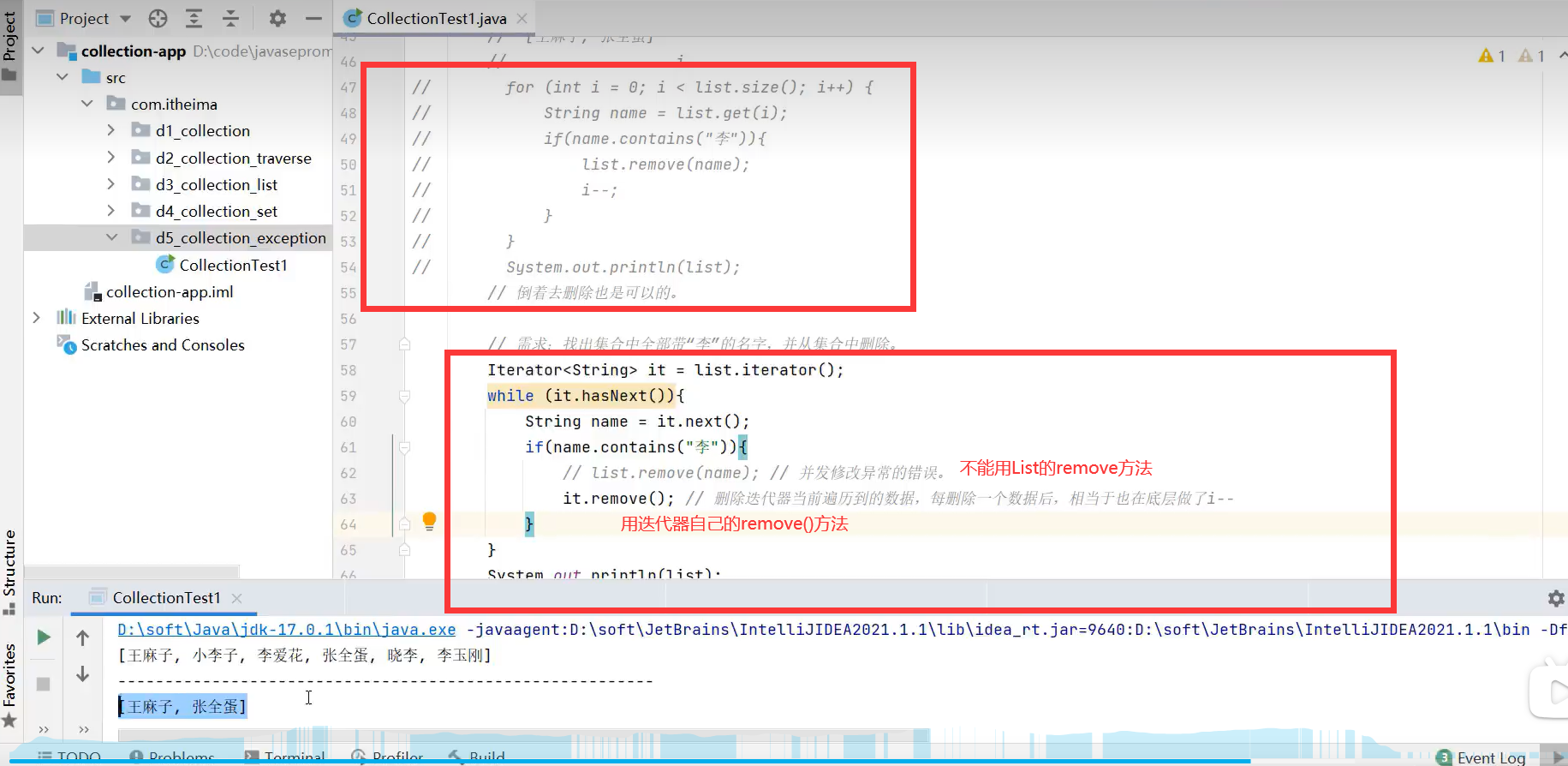
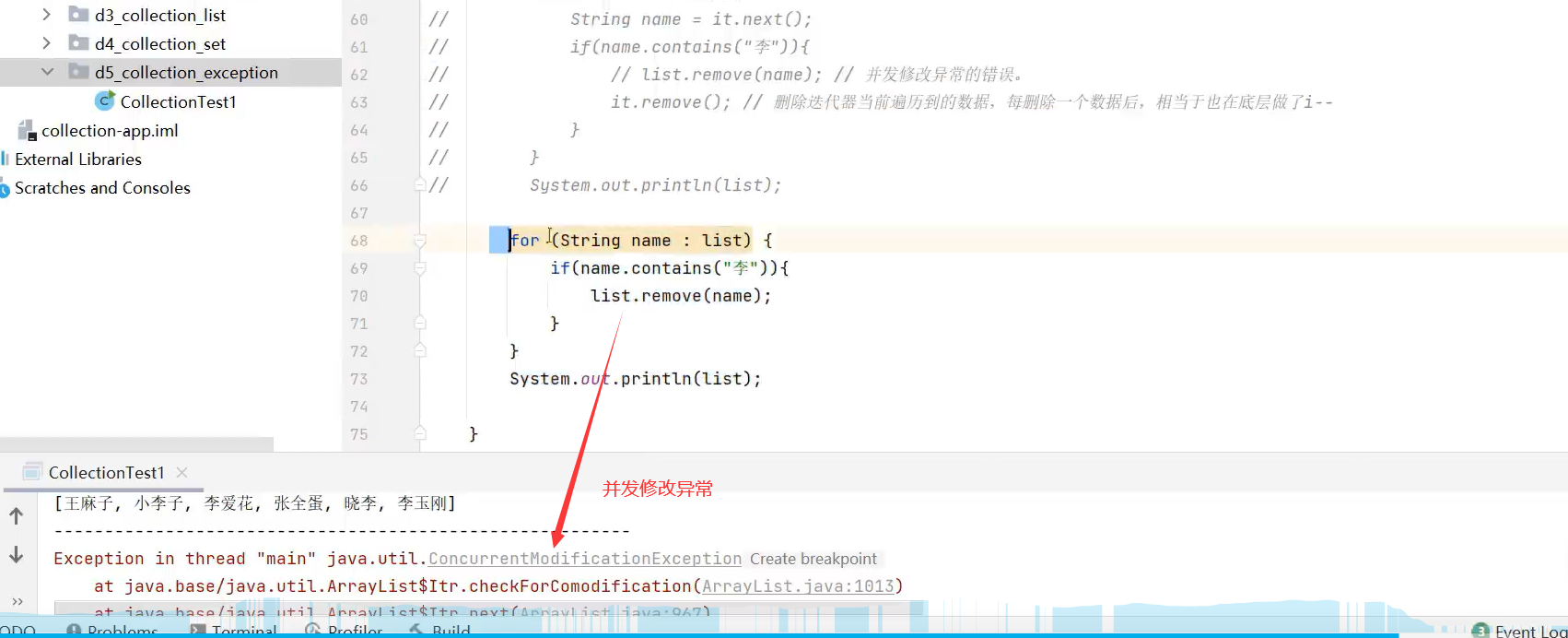
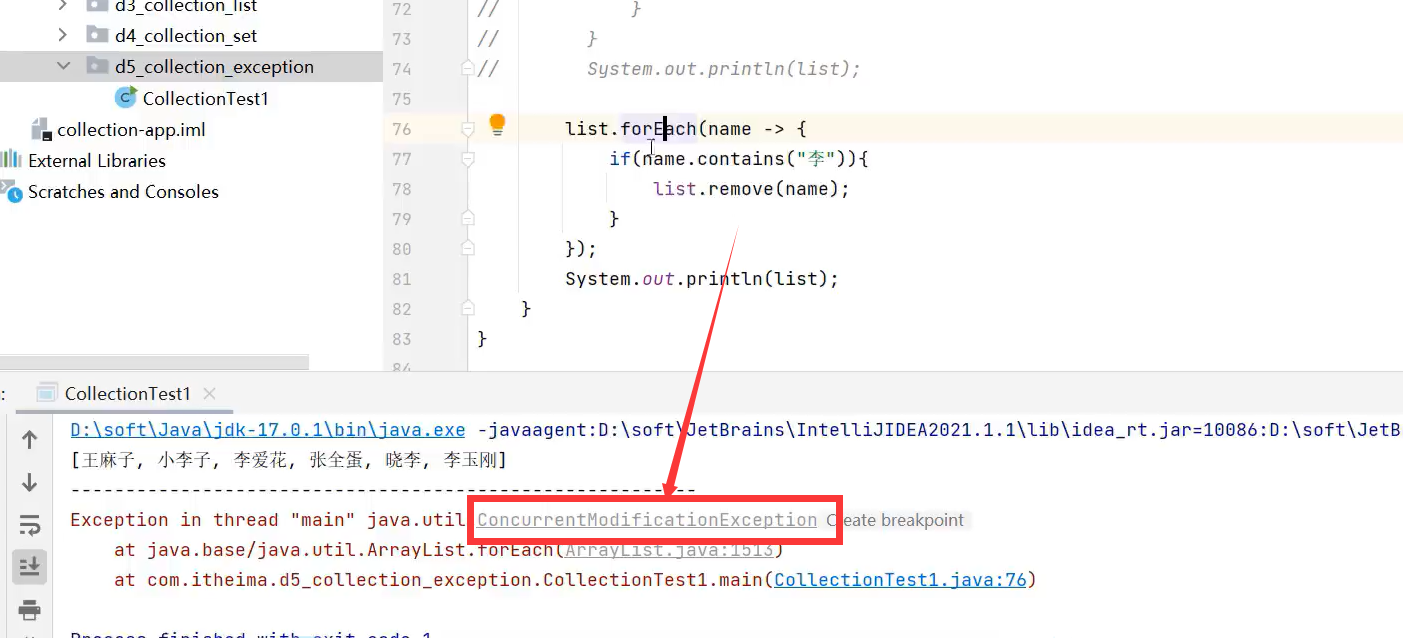
注意:List集合remove方法删除某元素后,某元素后的所有元素会前移。在遍历删除容器元素时,用该方法会有并发修改异常,所以只能用迭代器的.remove()方法进行遍历删除容器元素

ConcurrentModificationException:并发修改异常。
1.迭代器Iterator遍历删除元素时删不干净的解决方法:用迭代器自己的remove()方法
迭代器Iterator自己的remove方法,删除元素时,会回退到删除元素的位置。
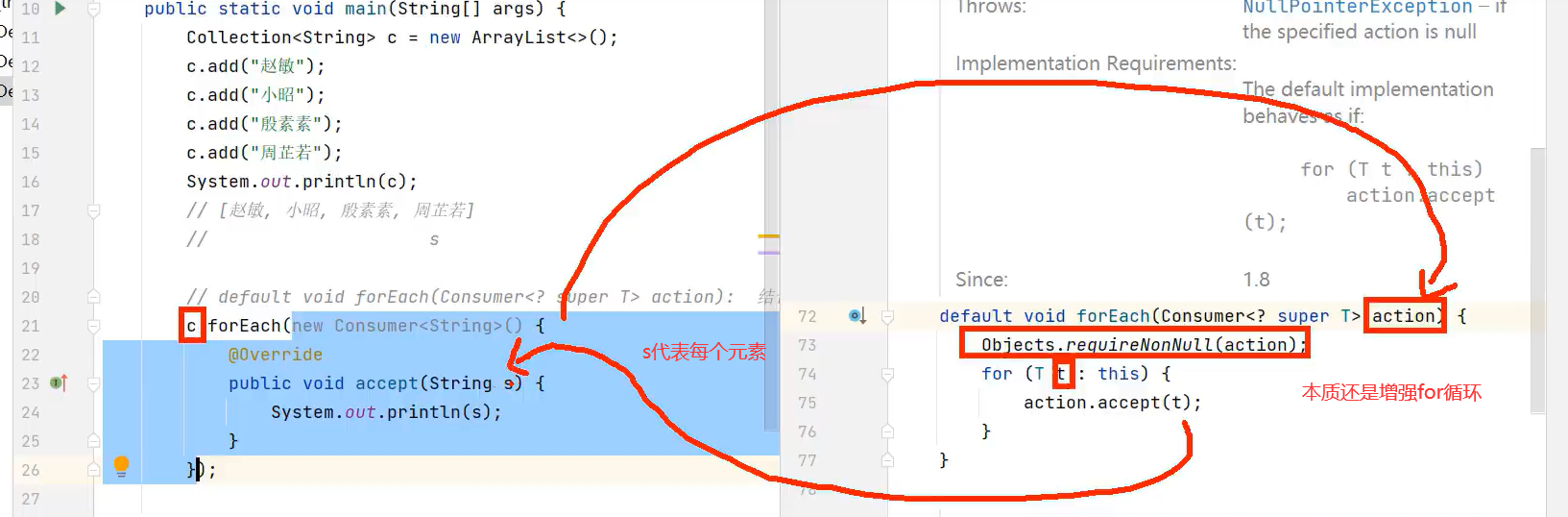
2.增强for和forEach不能解决边遍历边删除容器元素的问题,所以要删除元素并遍历集合只能用迭代器Iterator
List子类可用直接该方法

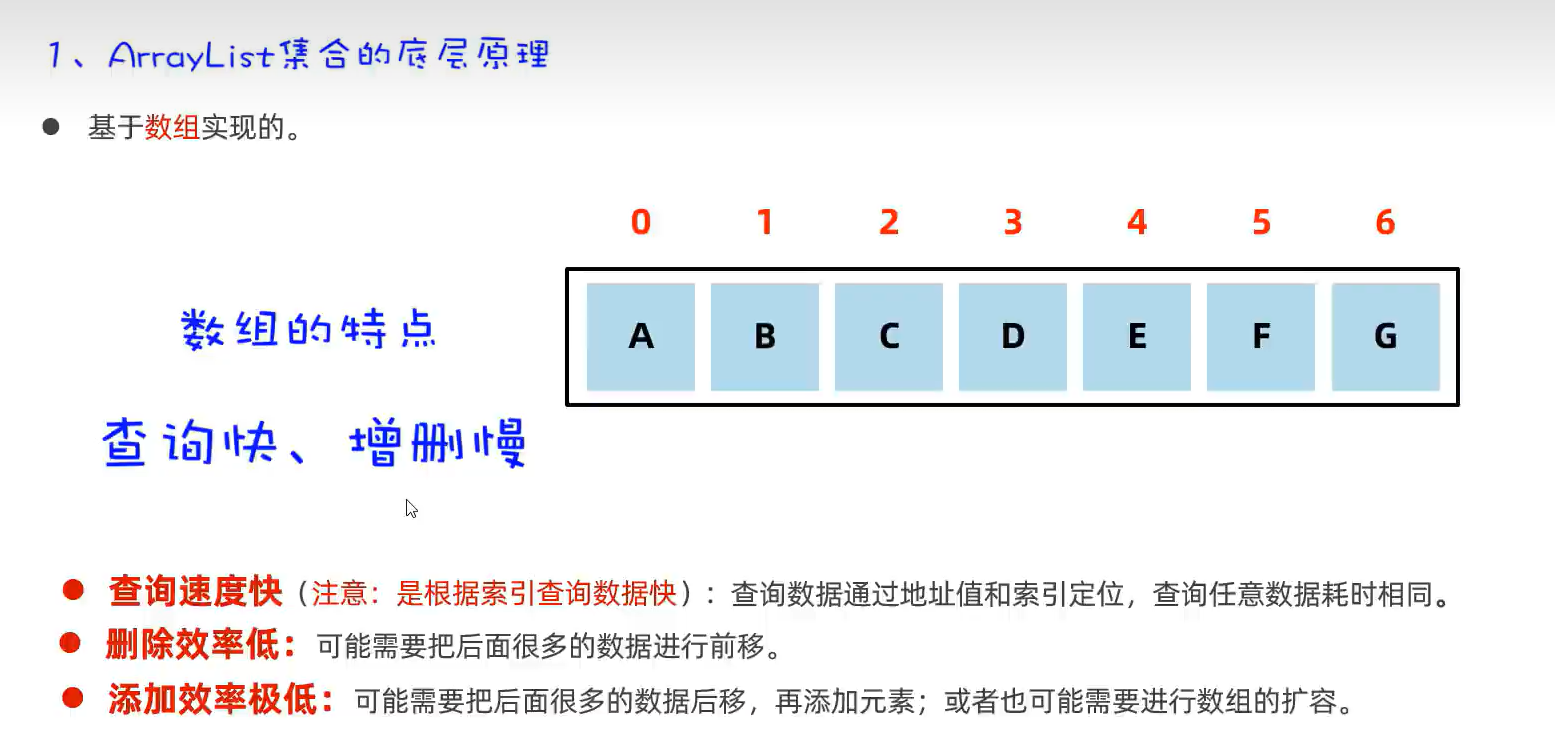
1.ArrayList(底层代码基于数组)


示例代码:
2.LinedList(基于双链表)

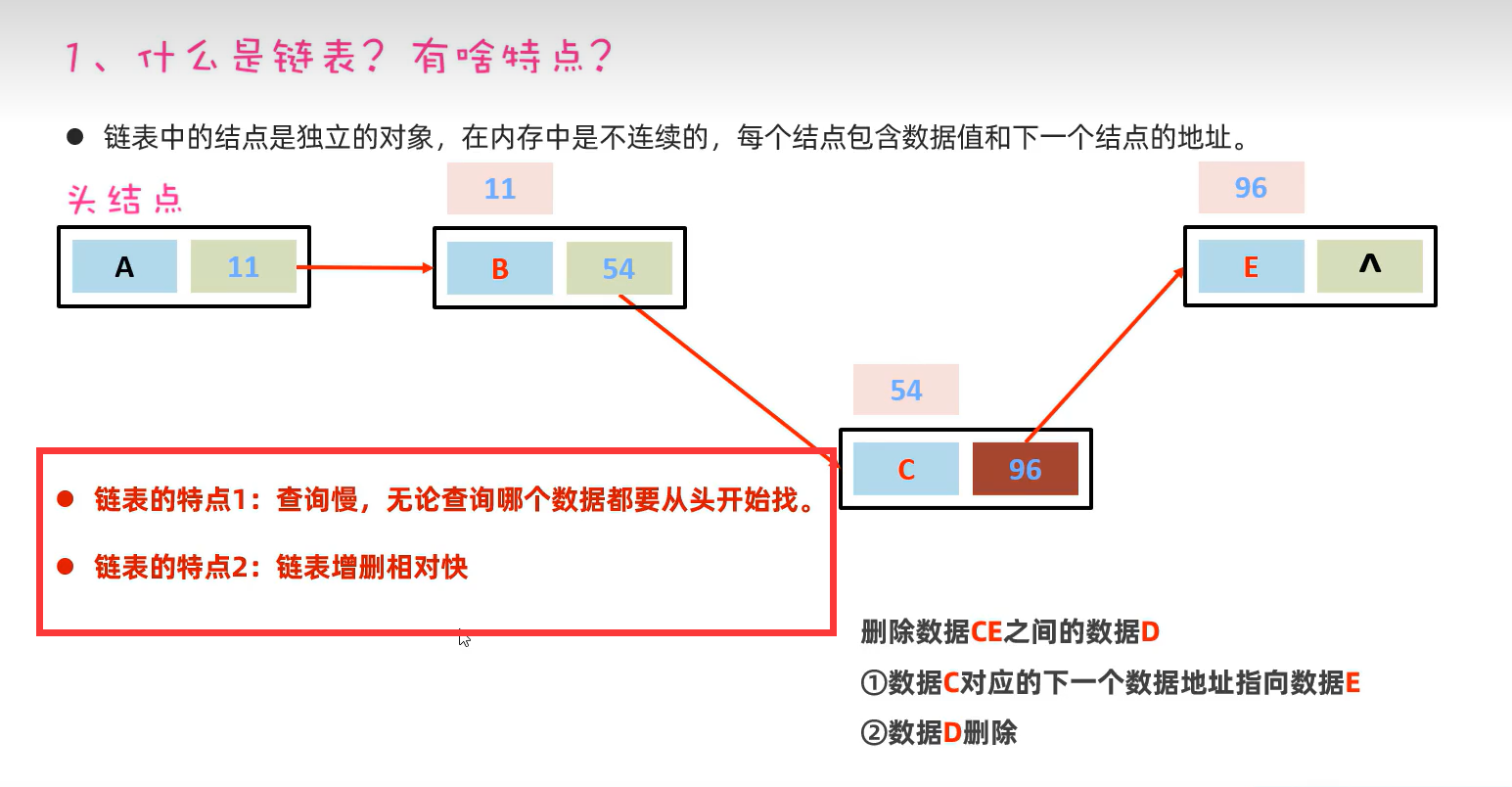

还可以用来设计栈。
示例代码:
1.队列
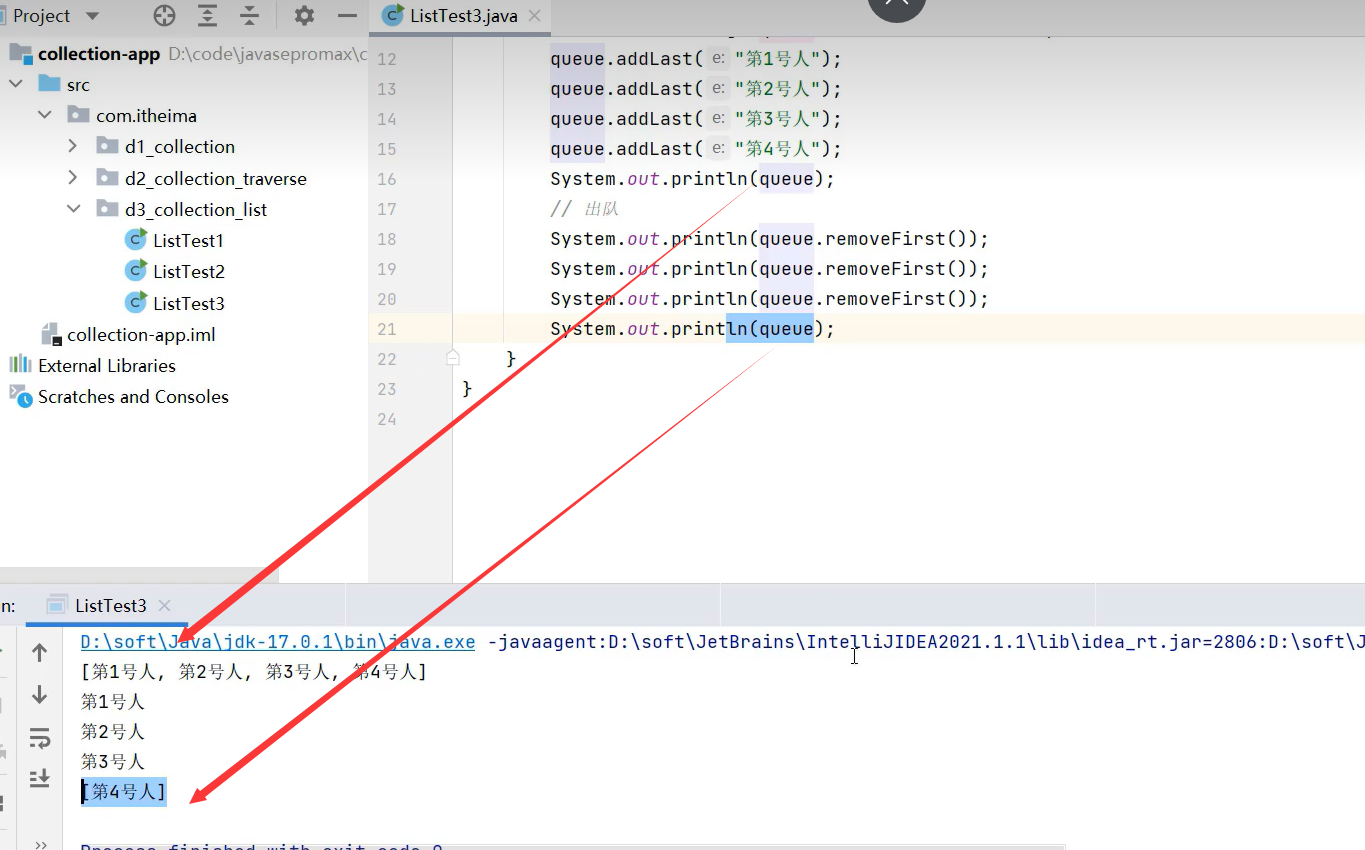
2.栈
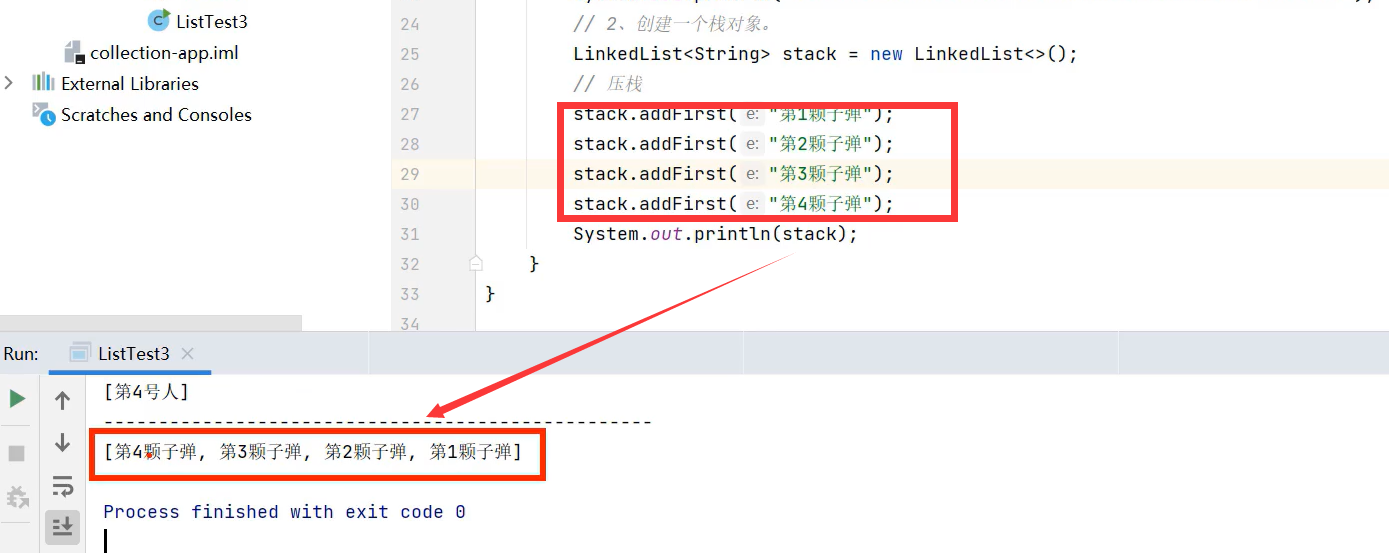
进栈/压栈用addFirst(参数)方法,出栈用removeFirst()方法。当然直接用pop()和push(参数)方法更直观,而且方法里面无需填参数,见下图代码
pop()和push()方法
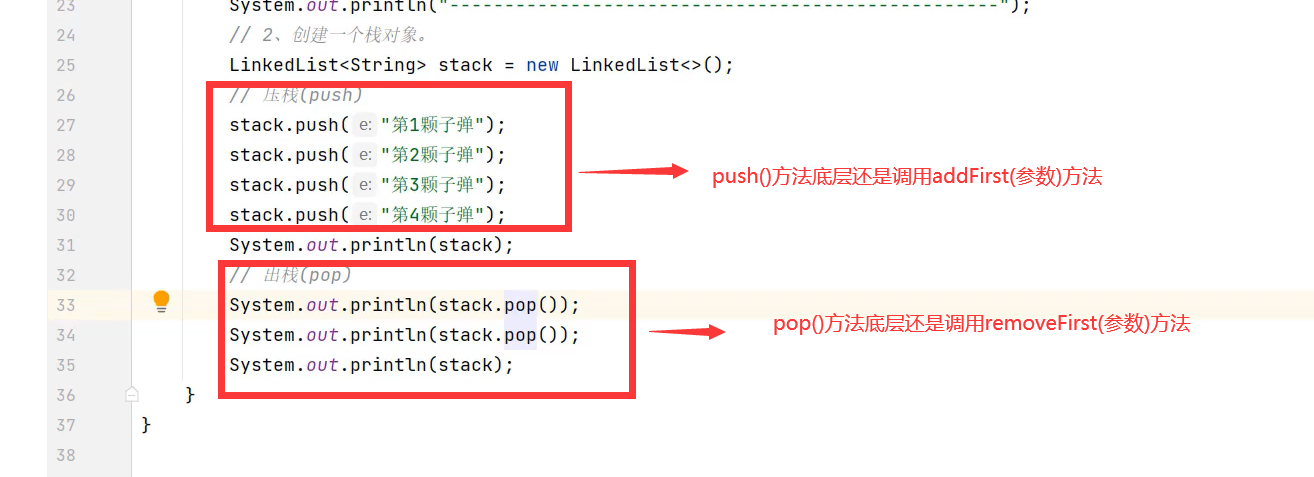
其本质还是调用addFirst()和removeFirst()方法,只不过被push()和pop()方法包装了而已,包装目的是为了符合压榨和出栈的方法名字的书写
4.Set集合(HashSet,LinkedHashSet,TreeSet)
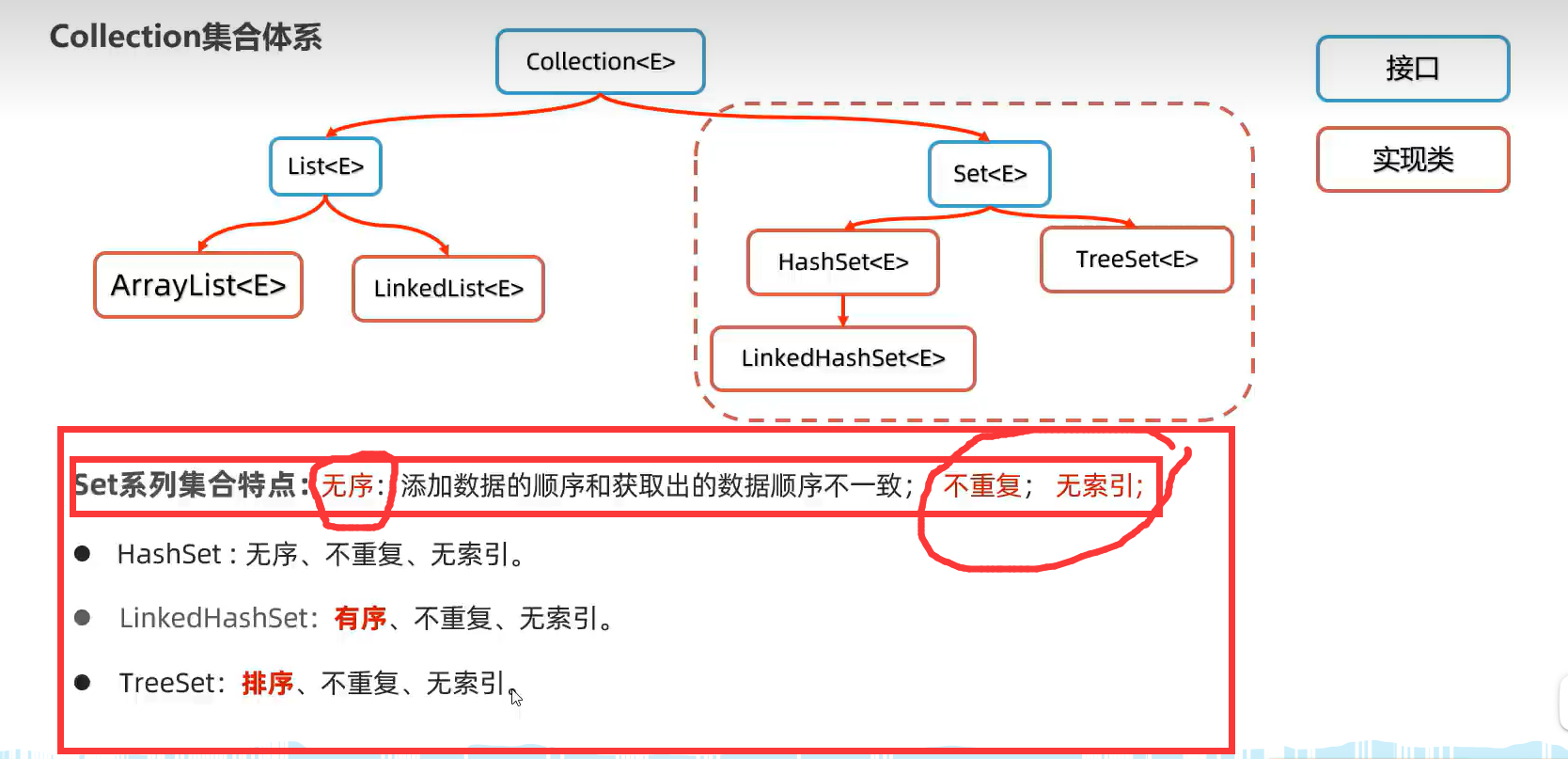

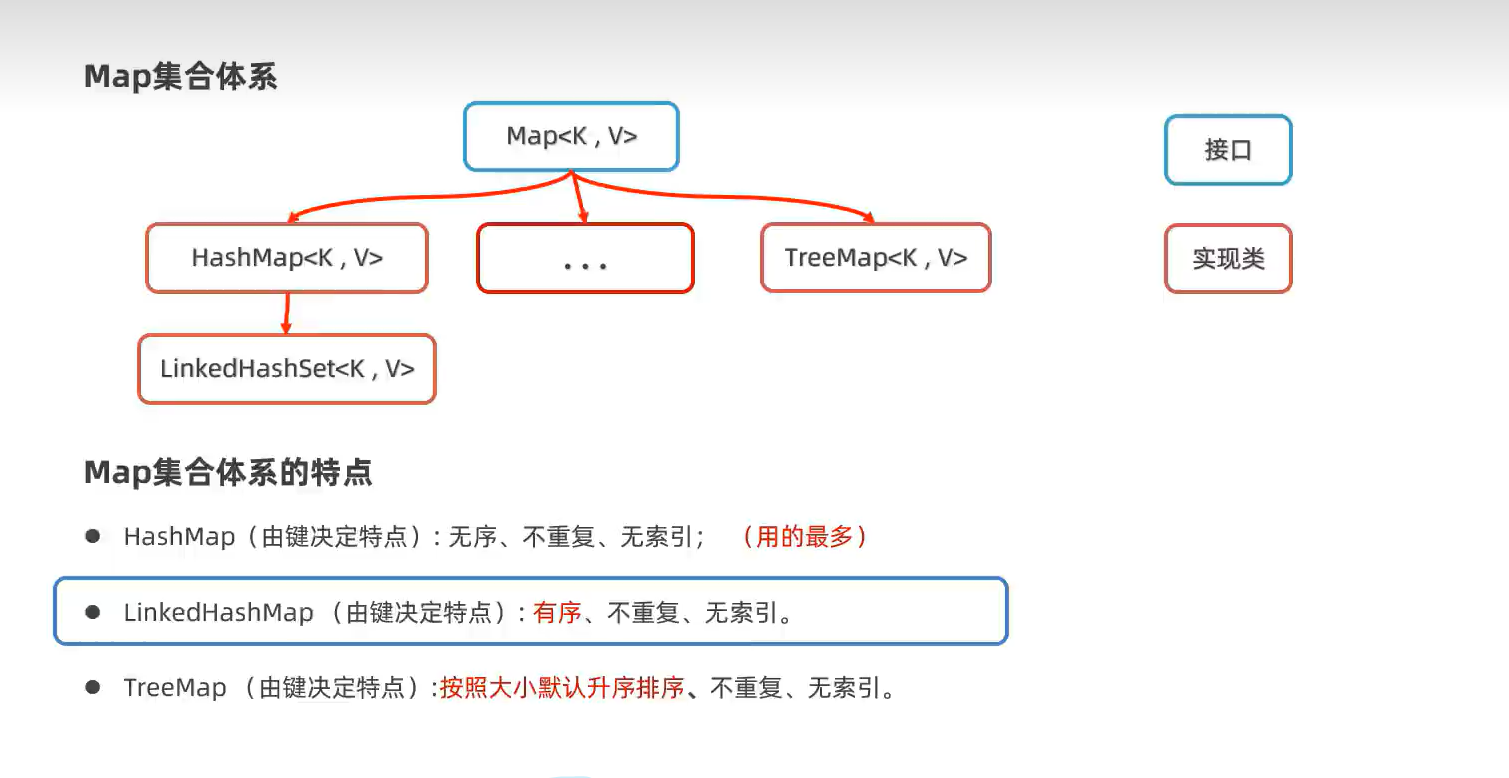
有序无序是指添加数据时和输出数据时的顺序是否一样。
示例代码:
1.HashSet(无序及不重复,无索引)
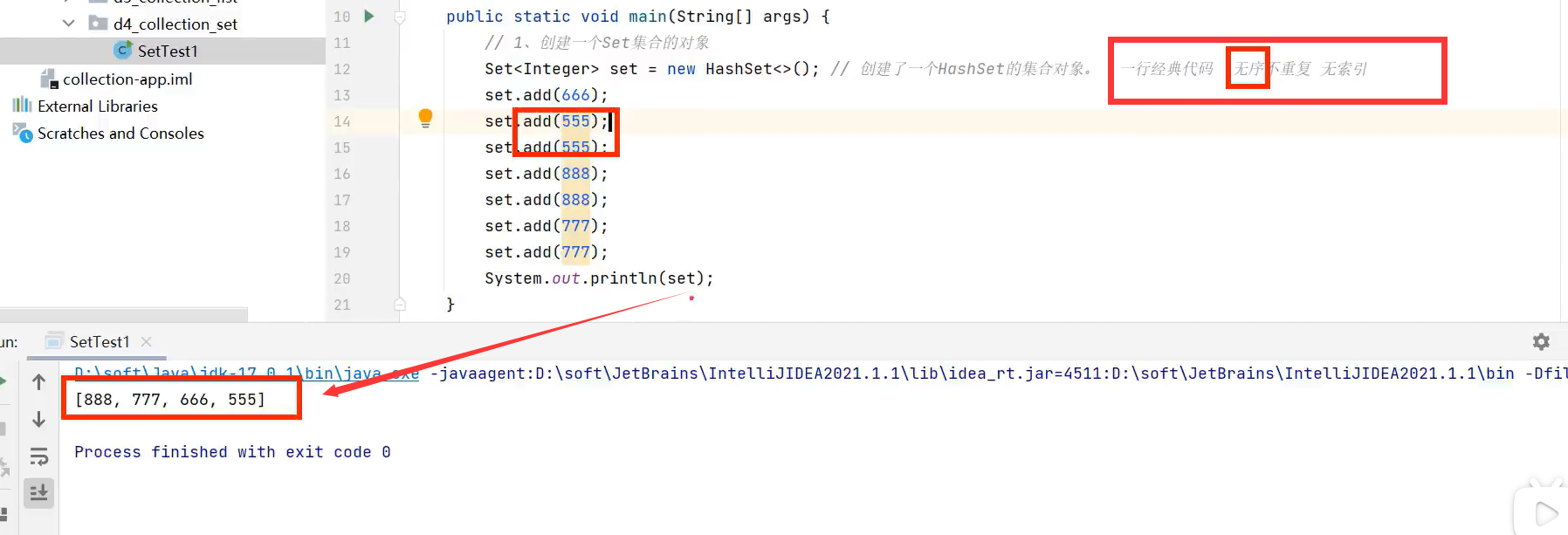
无序是指添加数据时和输出数据时的顺序不一样。输出结果会随机。
2.LinkedHashSet(有序及不重复,无索引)
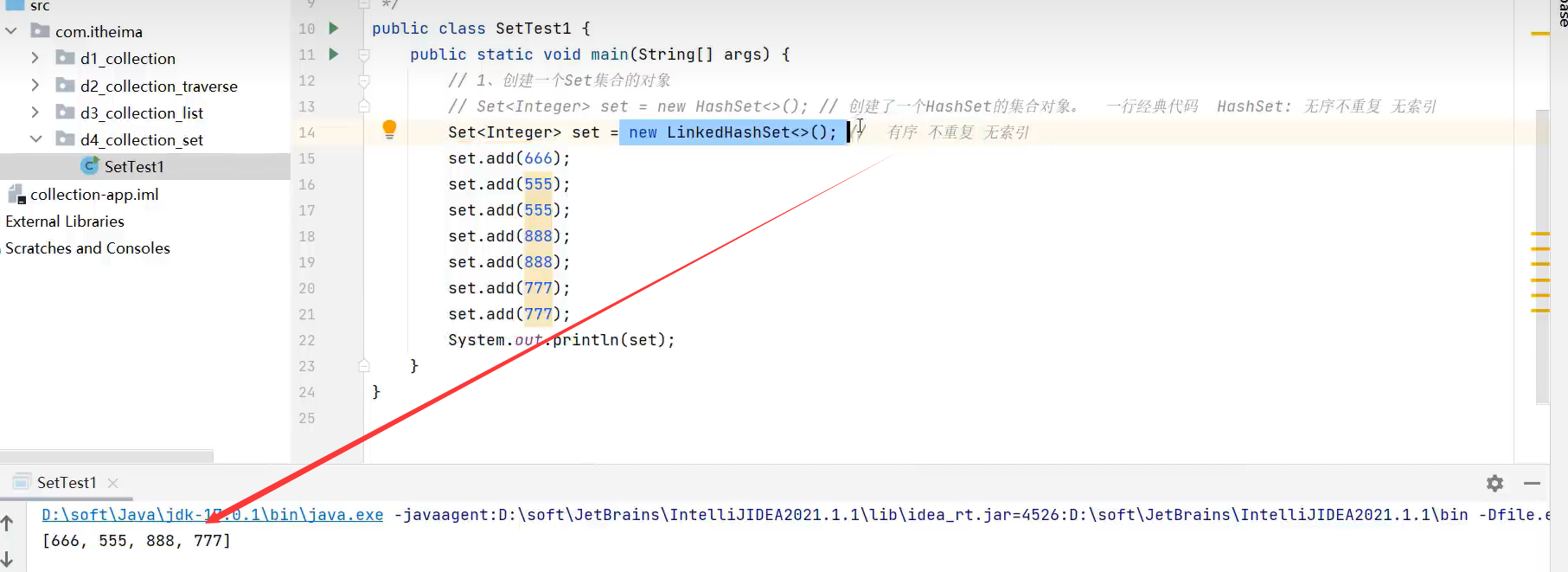
有序是指添加数据时和输出数据时的顺序一样。
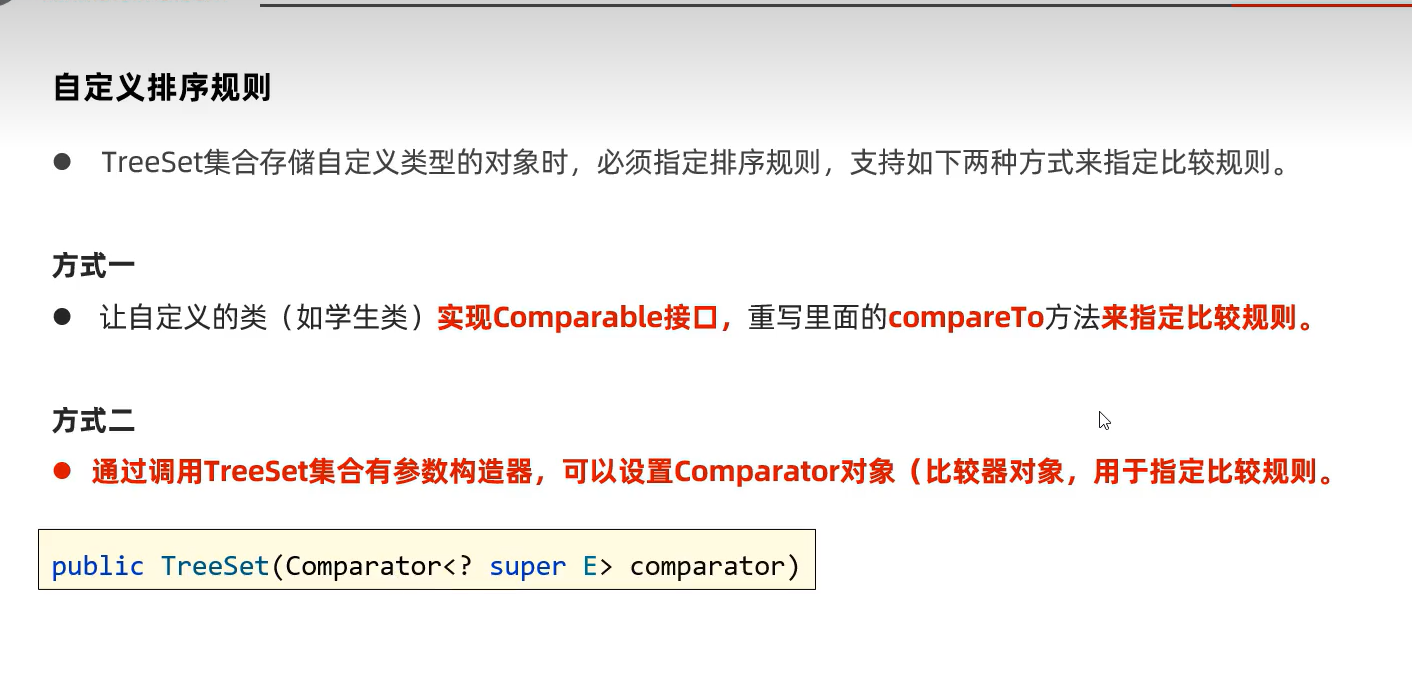
3.TreeSet(可排序及不重复,无索引)
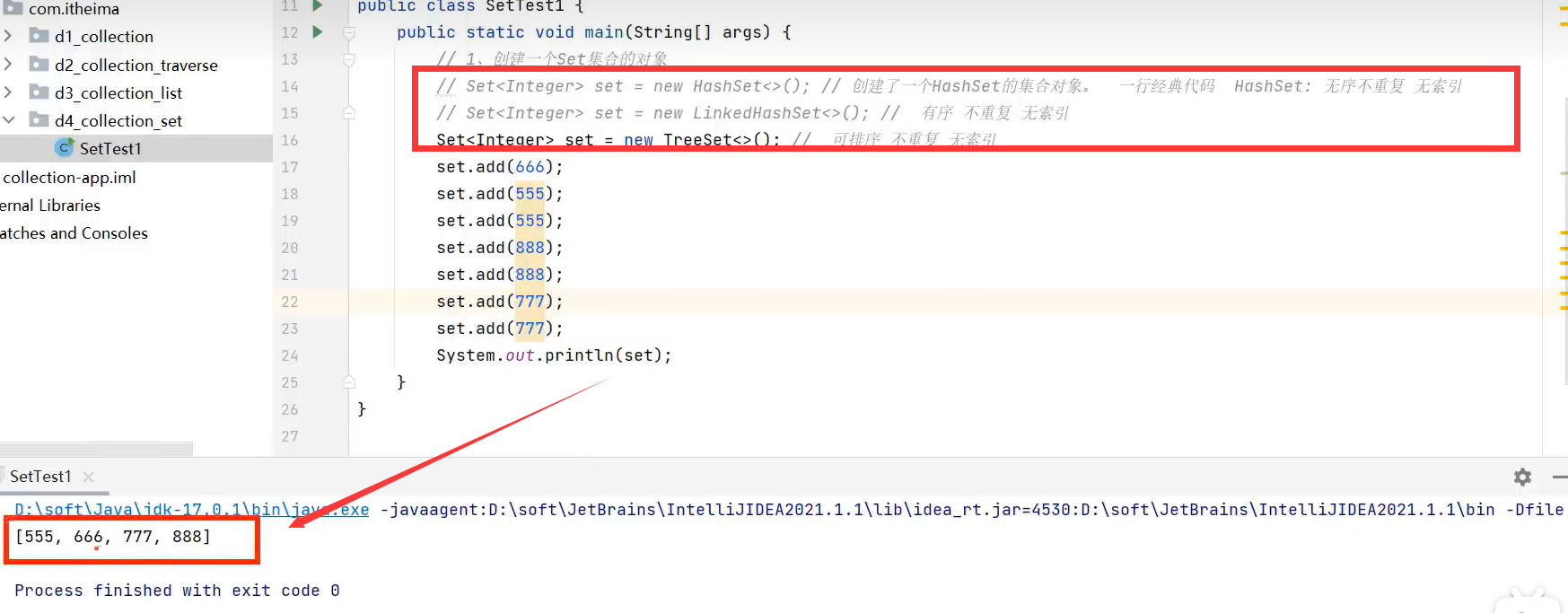
可排序可以是升序,降序。
1.HashSet
基于哈希表(数组、链表和红黑树)

哈希表(数组+链表)是一种增删改查性能都比较好的结构。
这里加载因子0.75是指当数组个数站该数组长度的0.75时,会对该数组进行扩容。

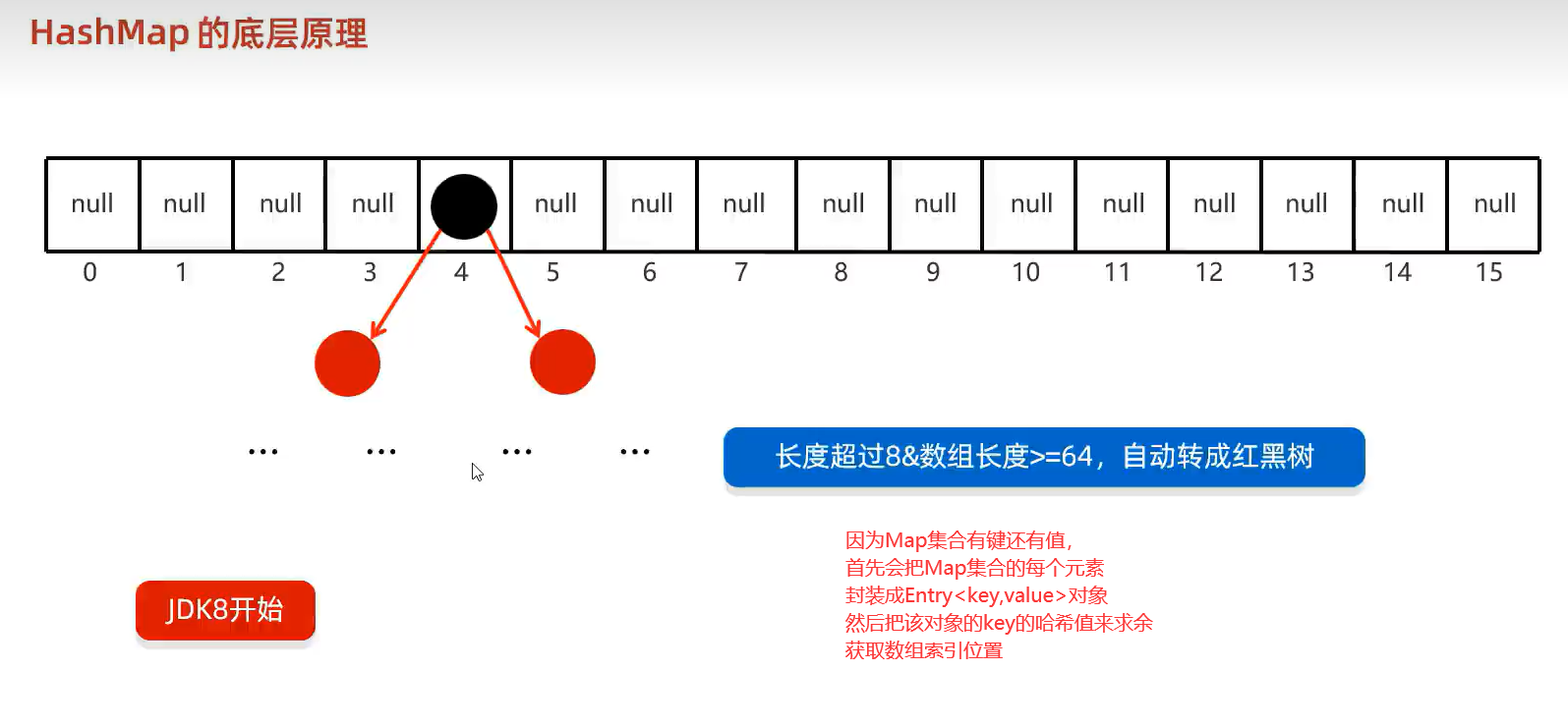
注意:JDK8之前的数组元素的链表如果很长时,会影响查询速度。所以在在JDK8开始之后,当满足条件时(链表长度超过8,且数组长度大于等于64时)自动将链表转成红黑树。见下图
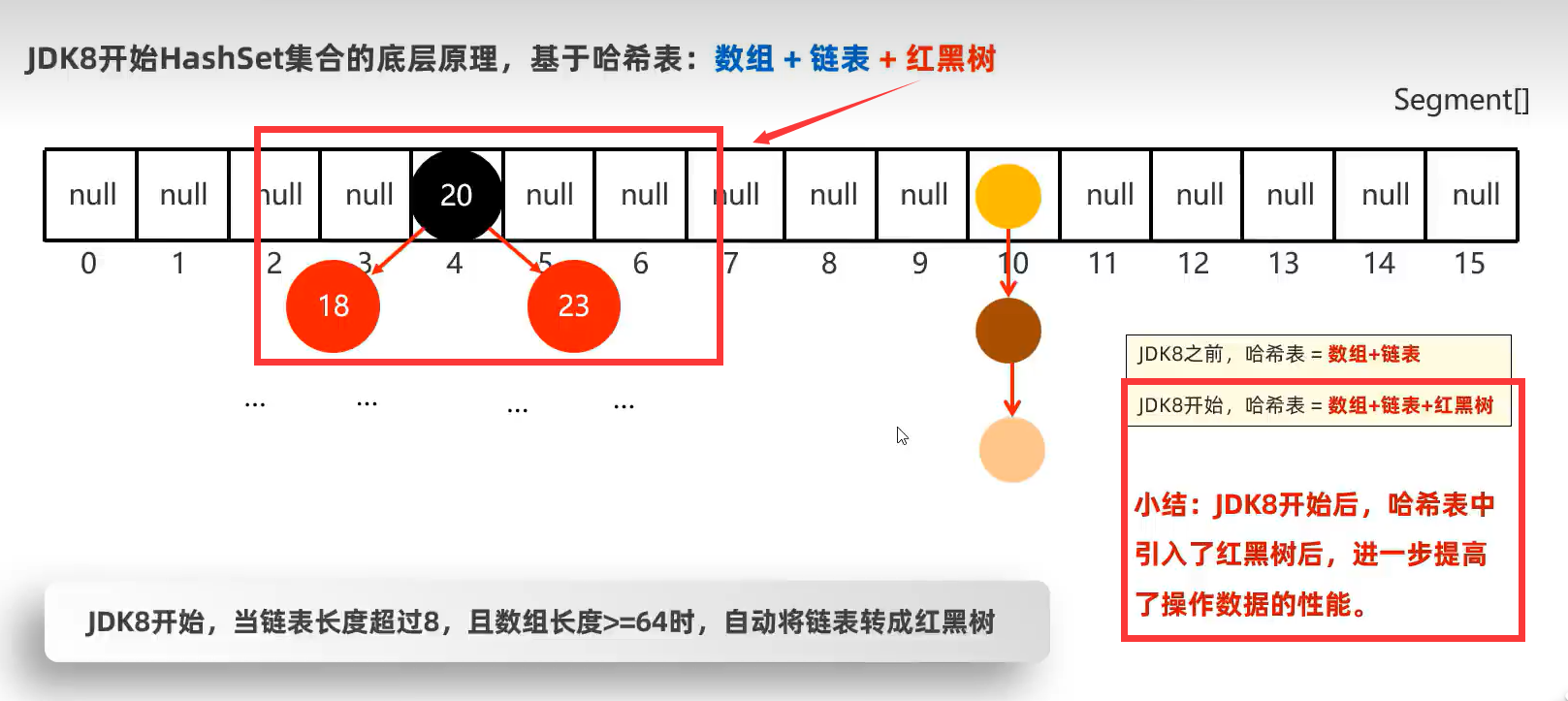
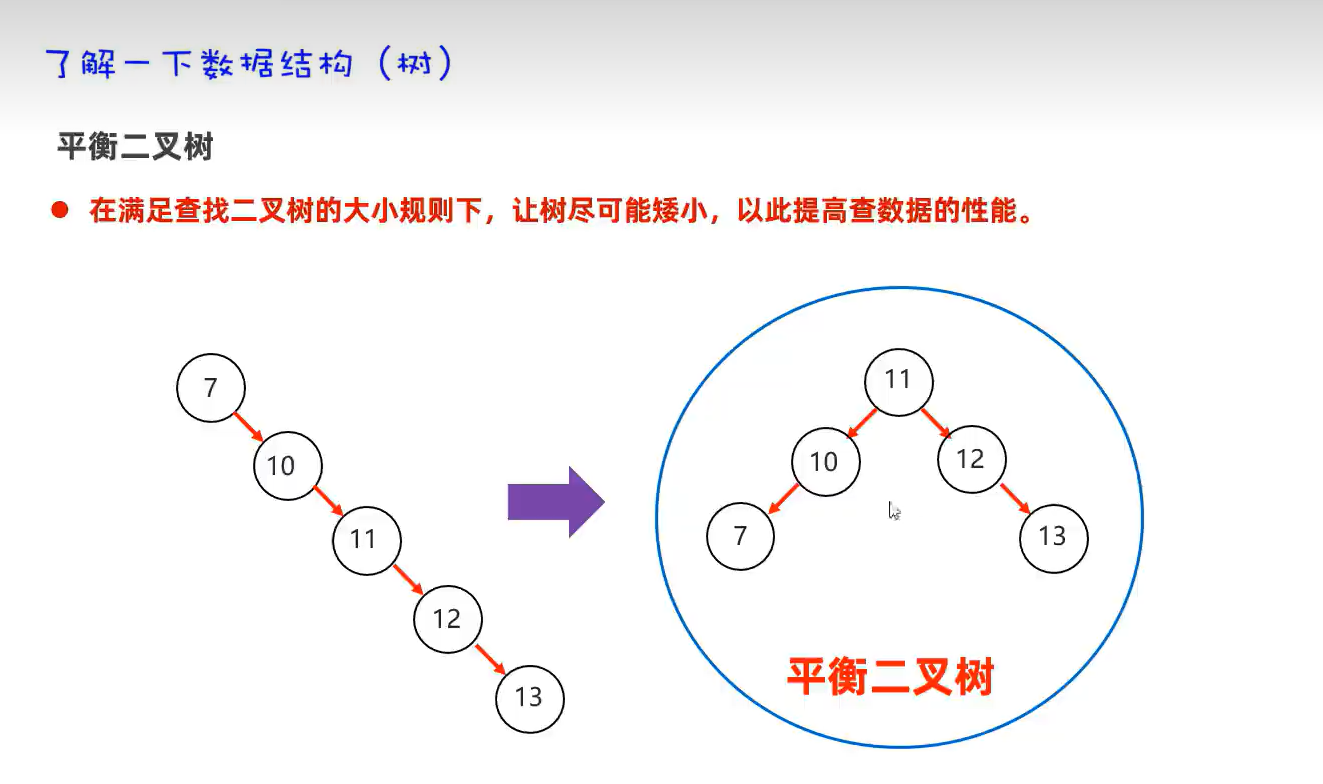

HashSet底层原理总结:
无序底层实现就是得到该对象的哈希值然后求余某个数,所以得到的位置会不一样。
不重复底层实现就是求余某个数后,然后逐个比较该位置的链表元素,有重复的话就不添加了。
无索引底层实现就是java任务如果用数组索引去得到元素值的话,可能得不到自己想要的元素,所以索性就不提供索引访问数组了。
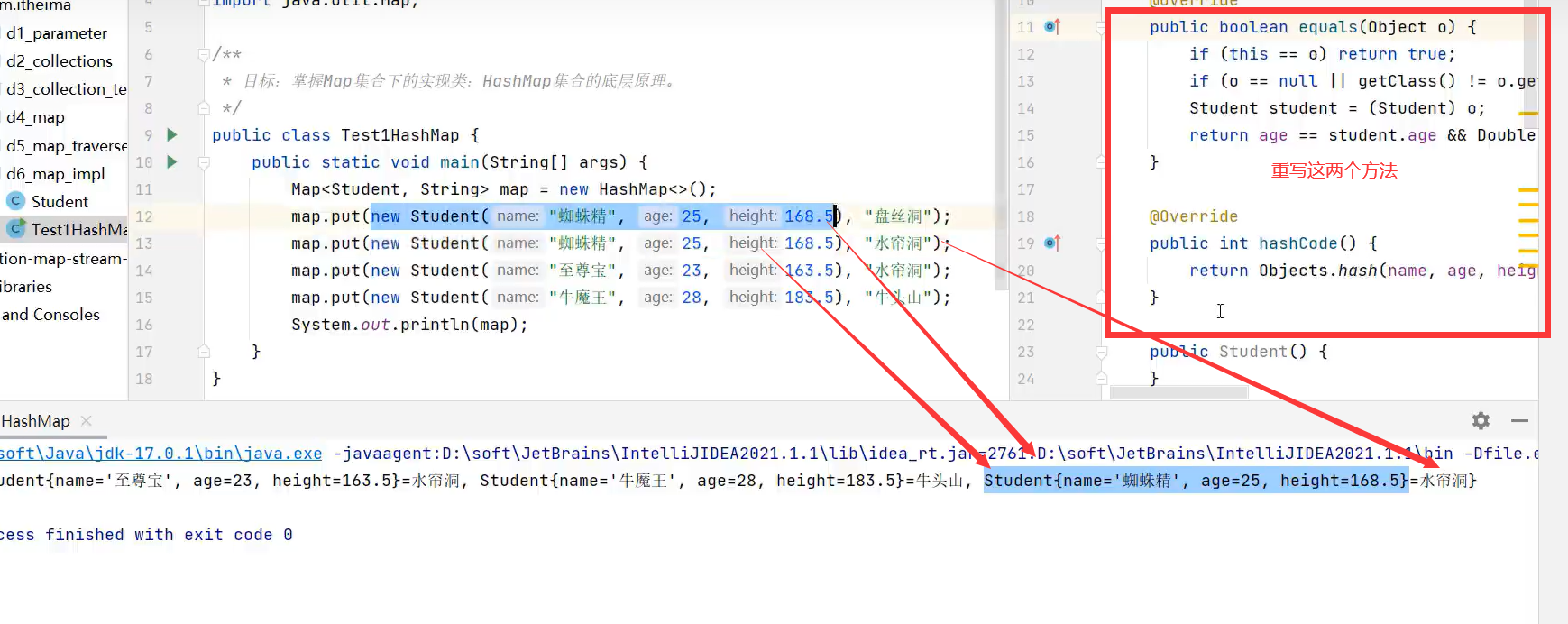
对象去重复性(重写hashCode和equals方法)


示例代码:
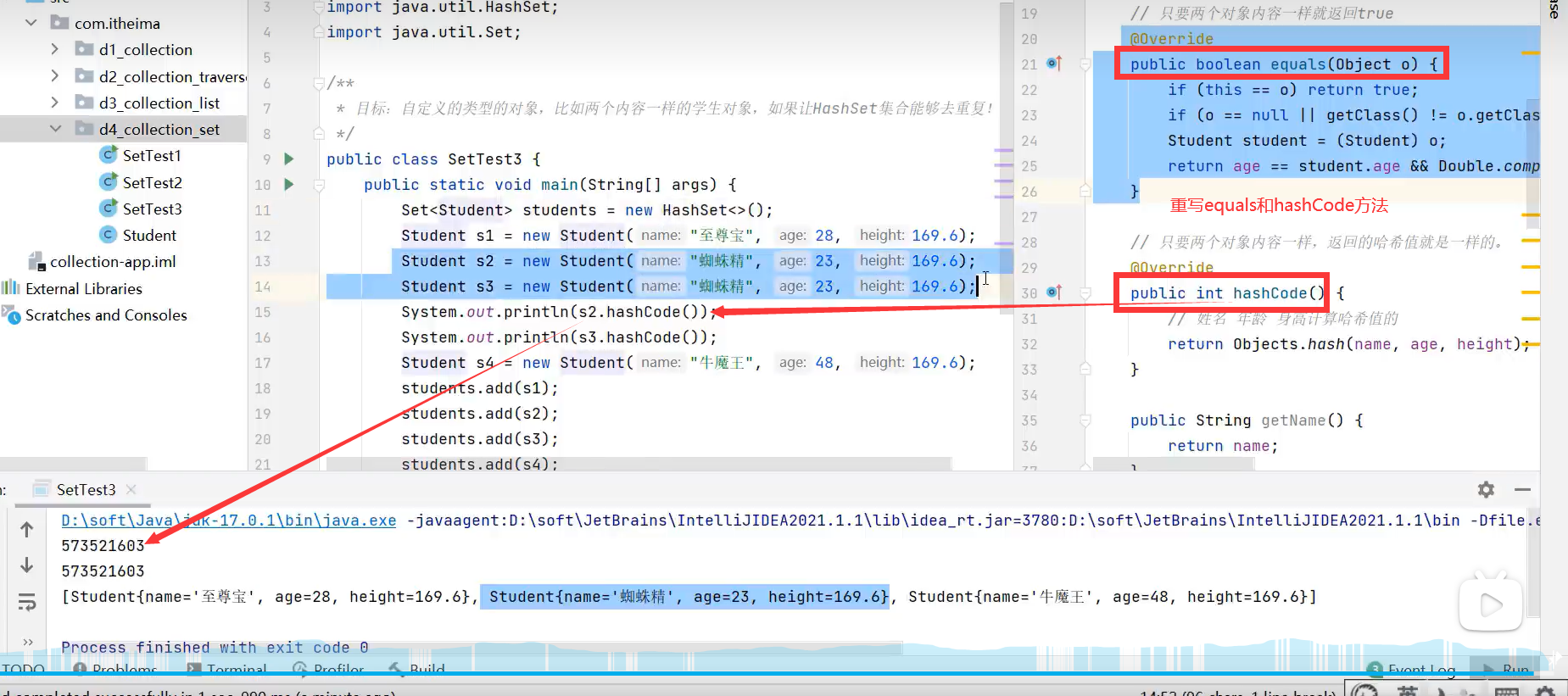
从运行结果可以看到,姓名为蜘蛛精,年龄等于23,身高为169.6的两个对象被认为成一个对象,添加时只会添加一个。
了解哈希值概念

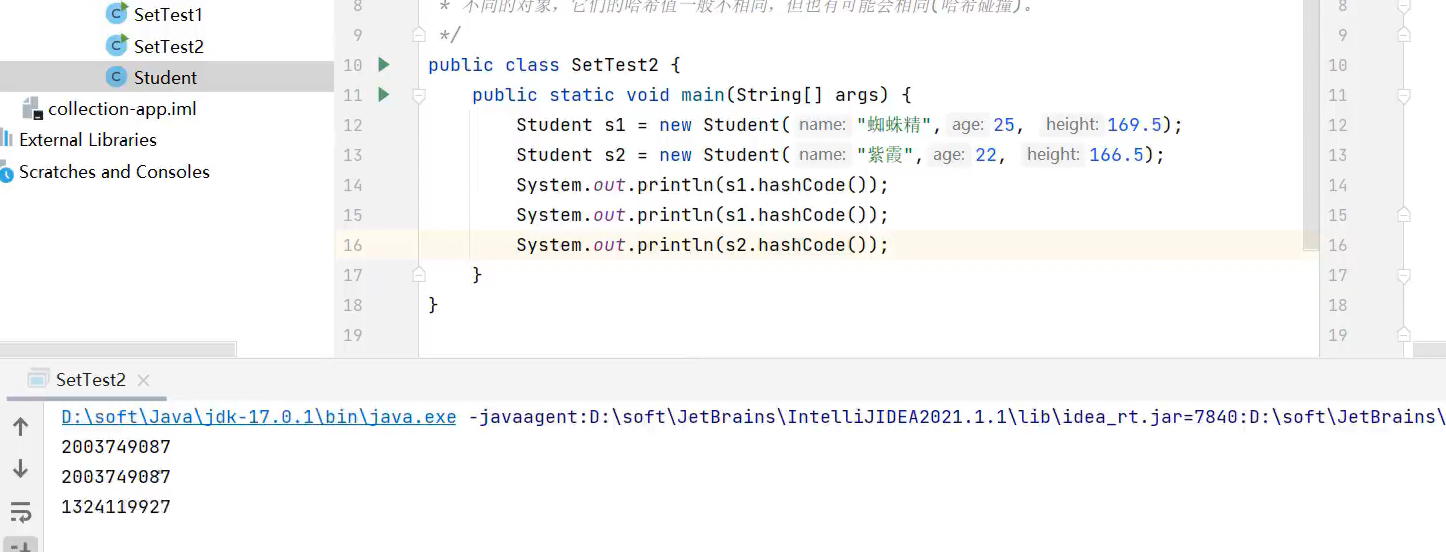
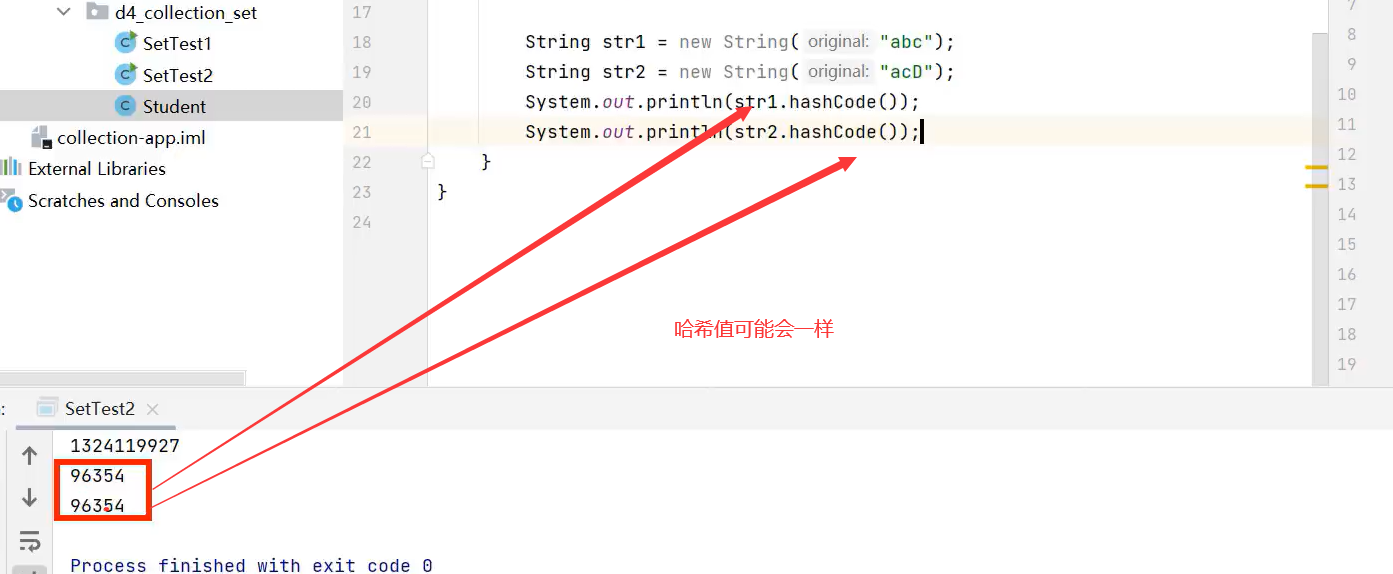
2.LinkedHashSet
底层代码基于哈希表(数组、链表和红黑树)及双链表

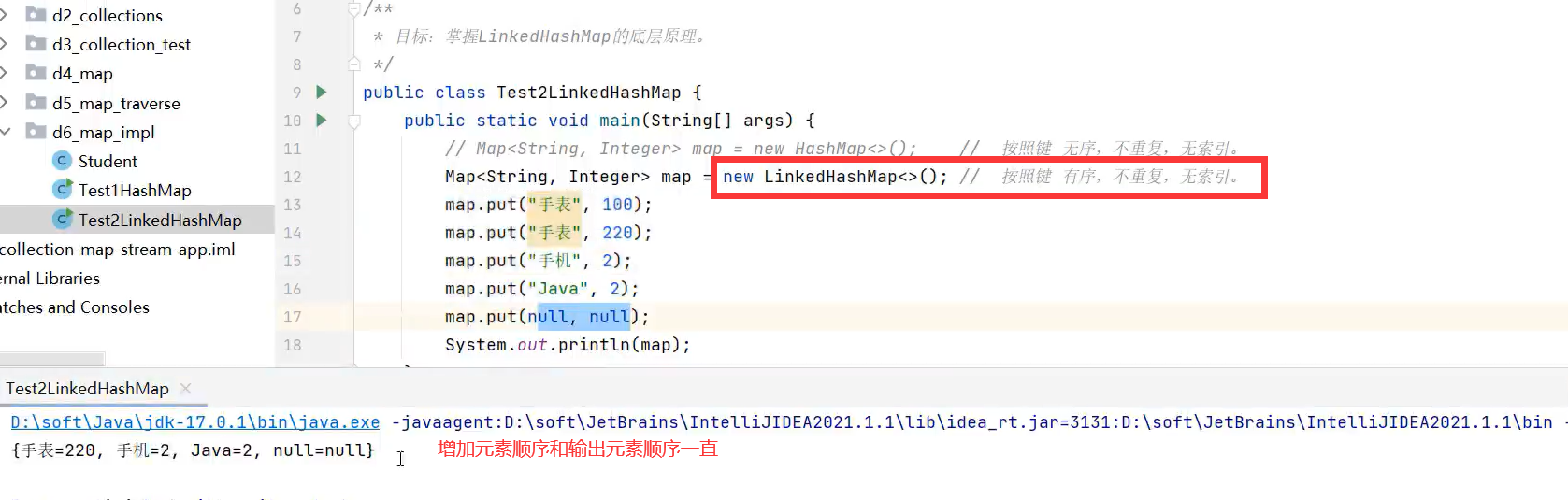
通过两个变量记住首尾元素的数组索引,这样遍历时会通过首元素的数组索引找到第一个元素,接着通过双链表访问下一个元素。
3.TreeSet

示例代码:

2.Map接口集合(HashMap、LinkedHashMap和TreeMap实现类)



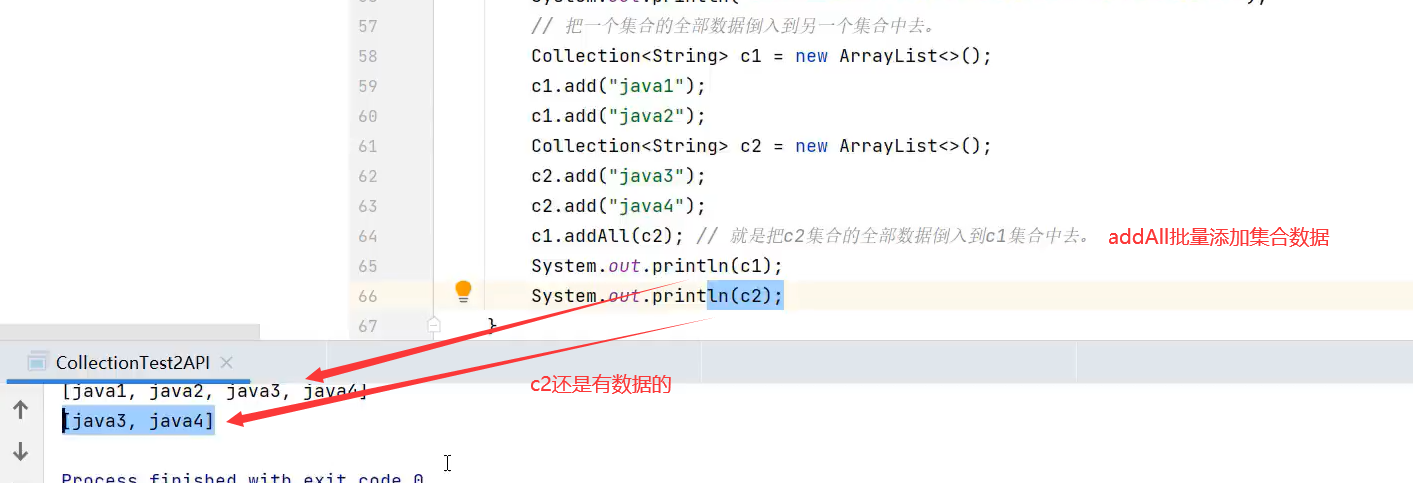
Map集合常用方法(扩展方法putAll()可以将另一个map集合添加到本map去)
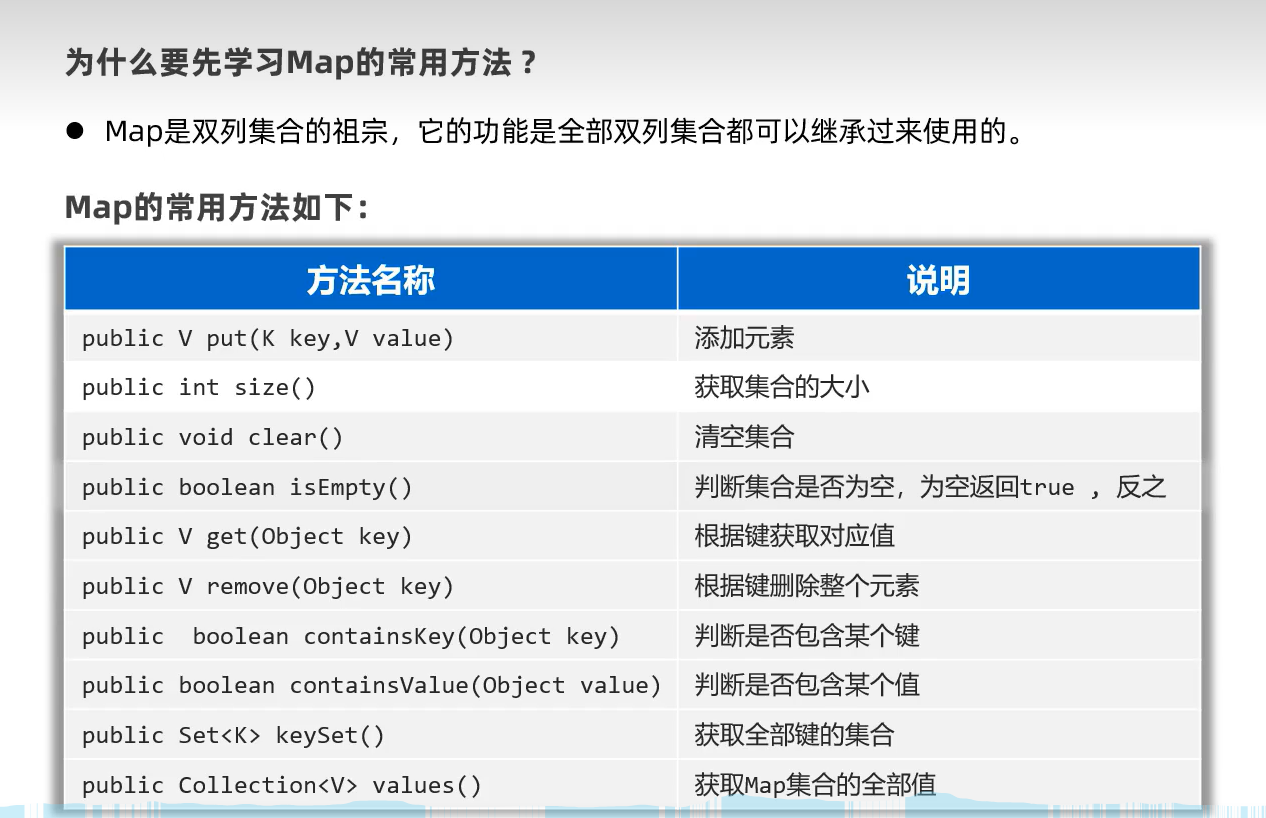
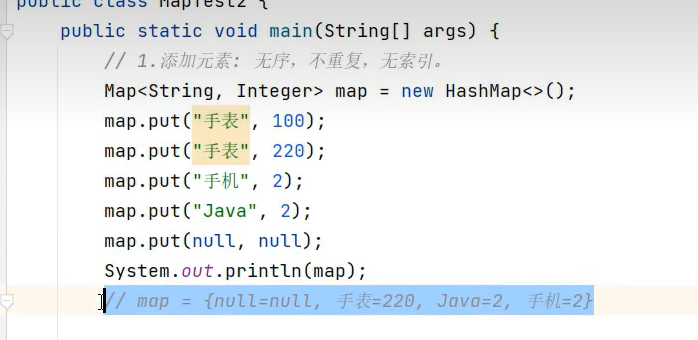
示例代码:
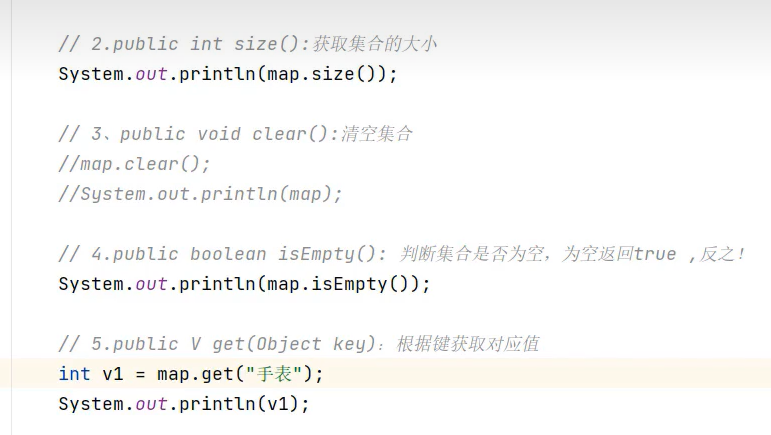
不存在该键时,get方法会返回null
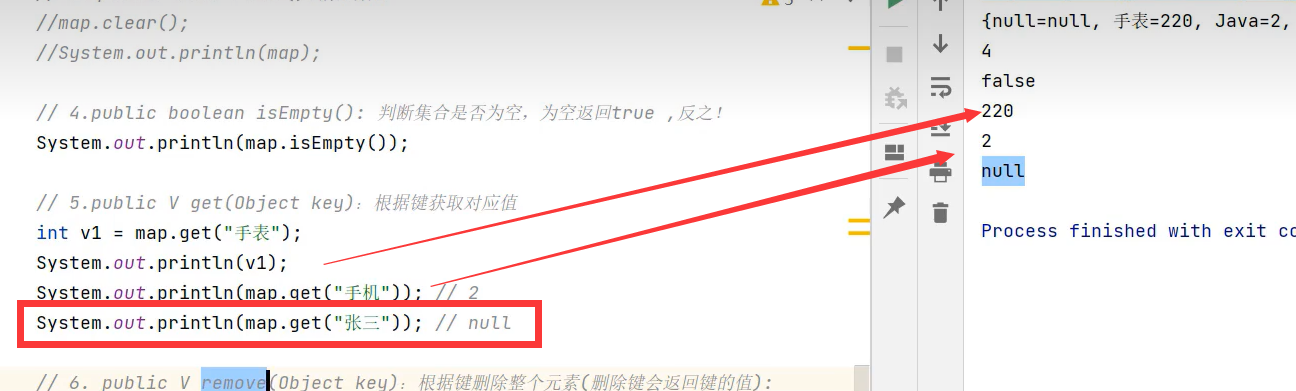
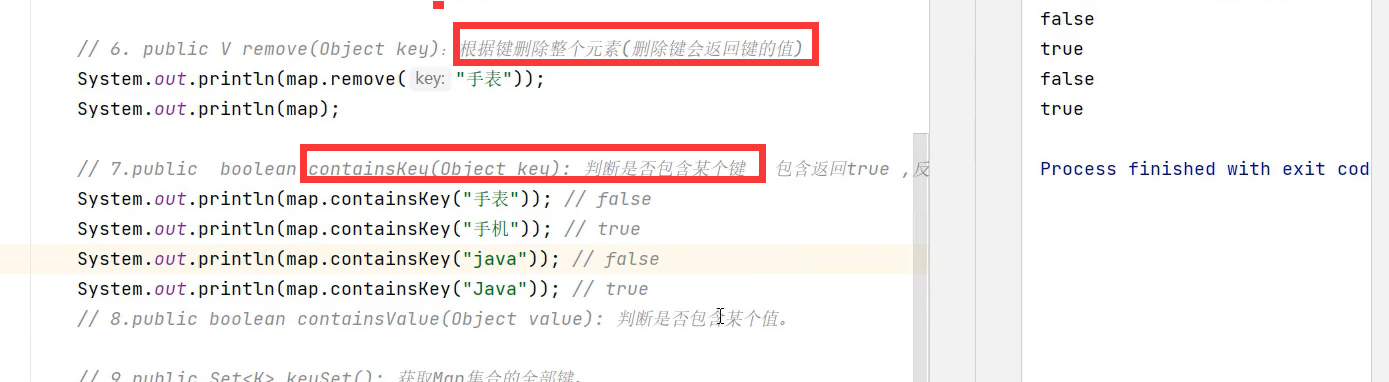


注意:values()方法获取map值的集合,其返回值为Collection,原因是值可以重复,而键不可以重复,所以keySet()方法会返回Set集合。
扩展方法:

putall()方法可以将另一个map集合的全部数据添加到该map集合中去,若有重复的键会进行覆盖
Map集合的遍历方式

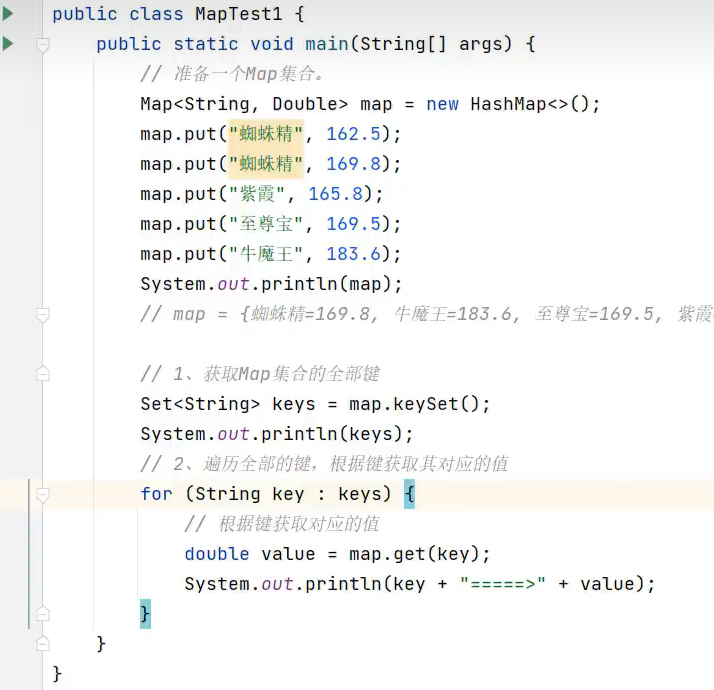
1.键找值遍历

示例代码
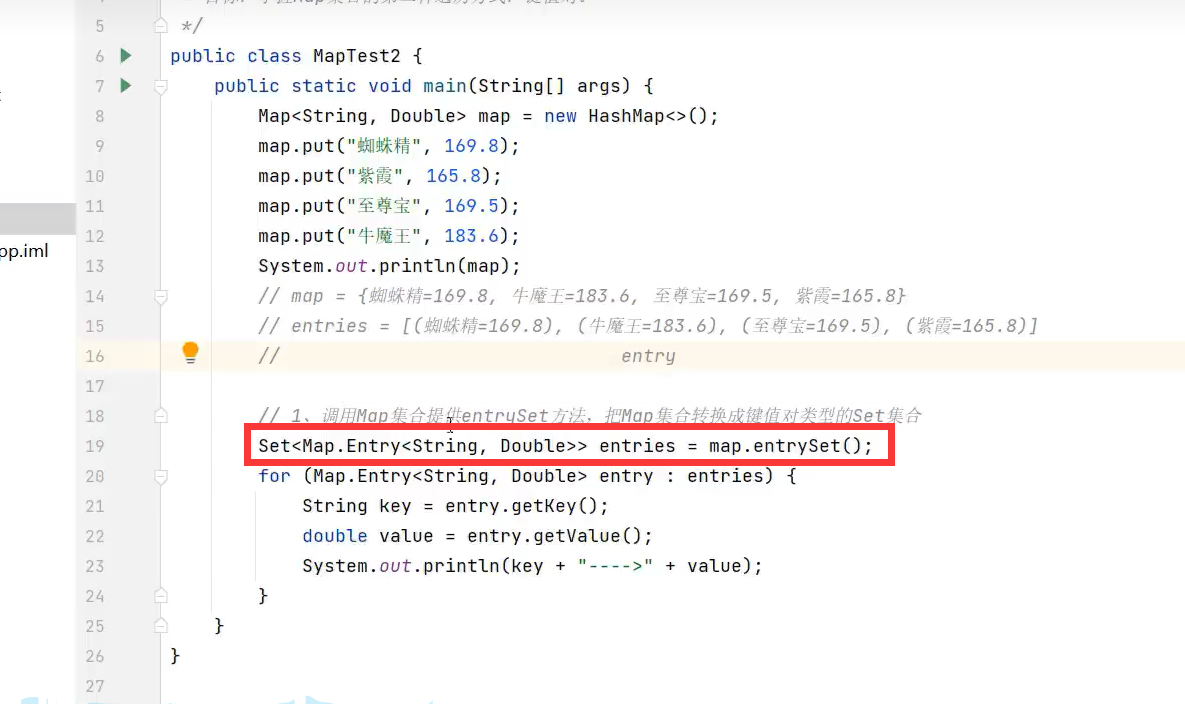
2.键值对遍历(entrySet(),getKey(),getValue())
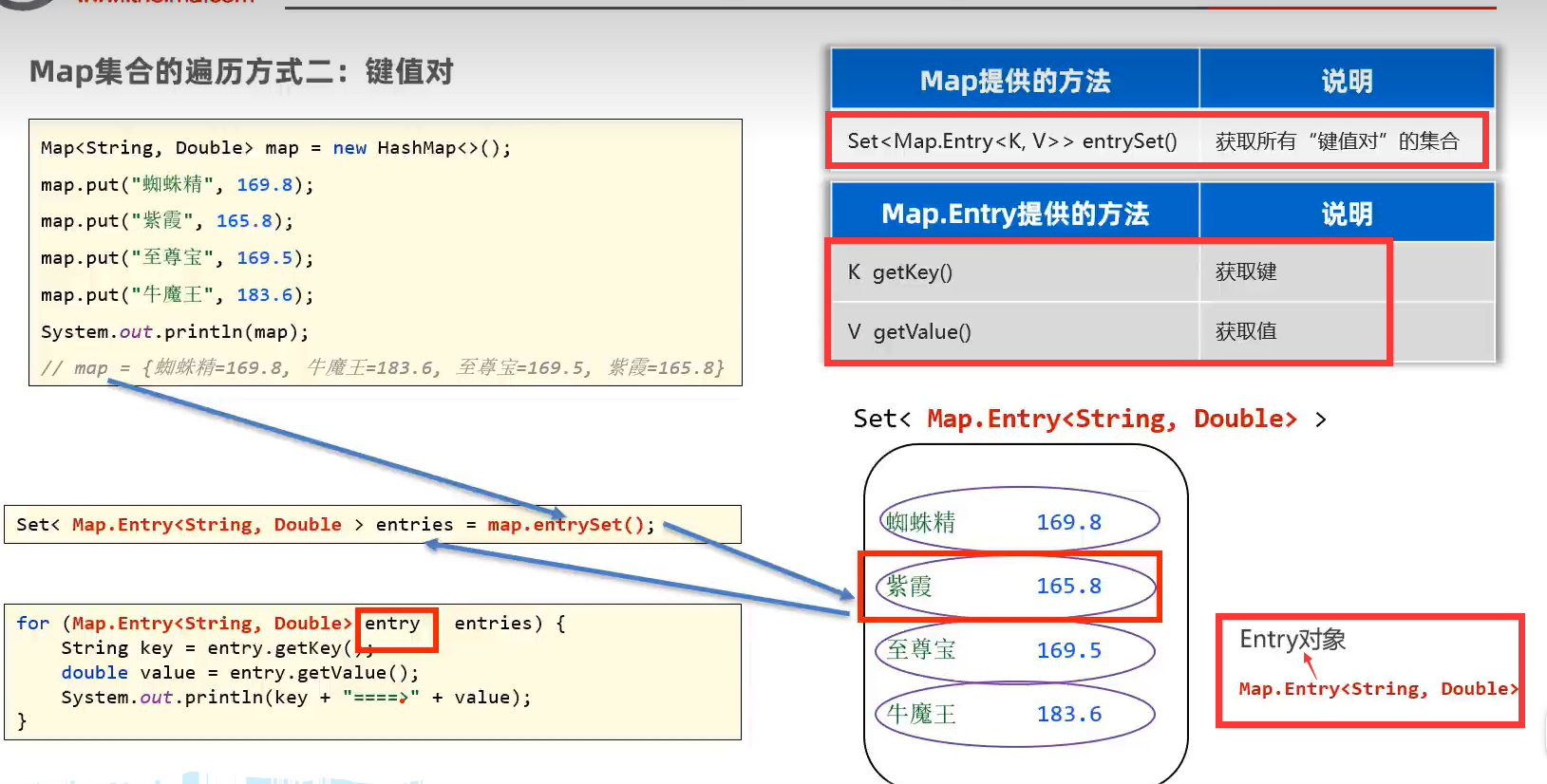
示例代码
3.forEach遍历(简洁,配合Lambda)
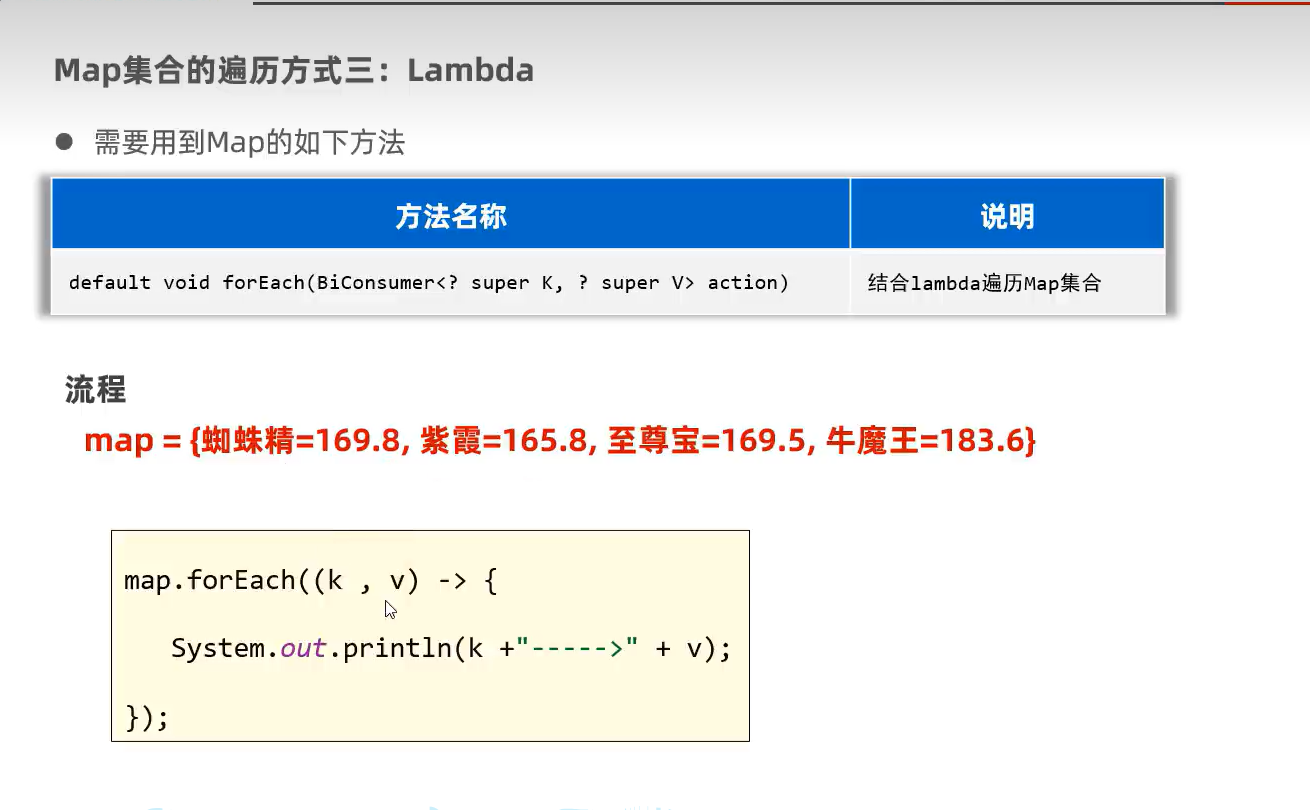
示例代码:
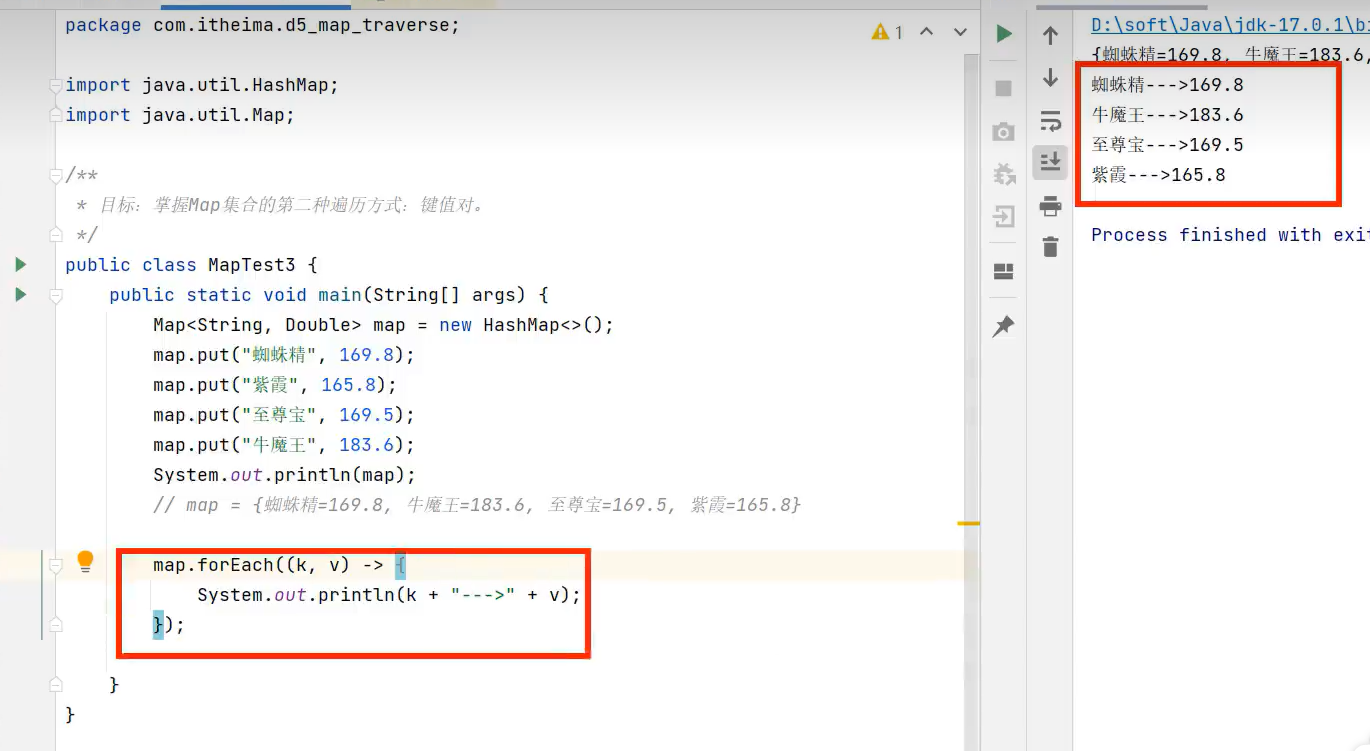
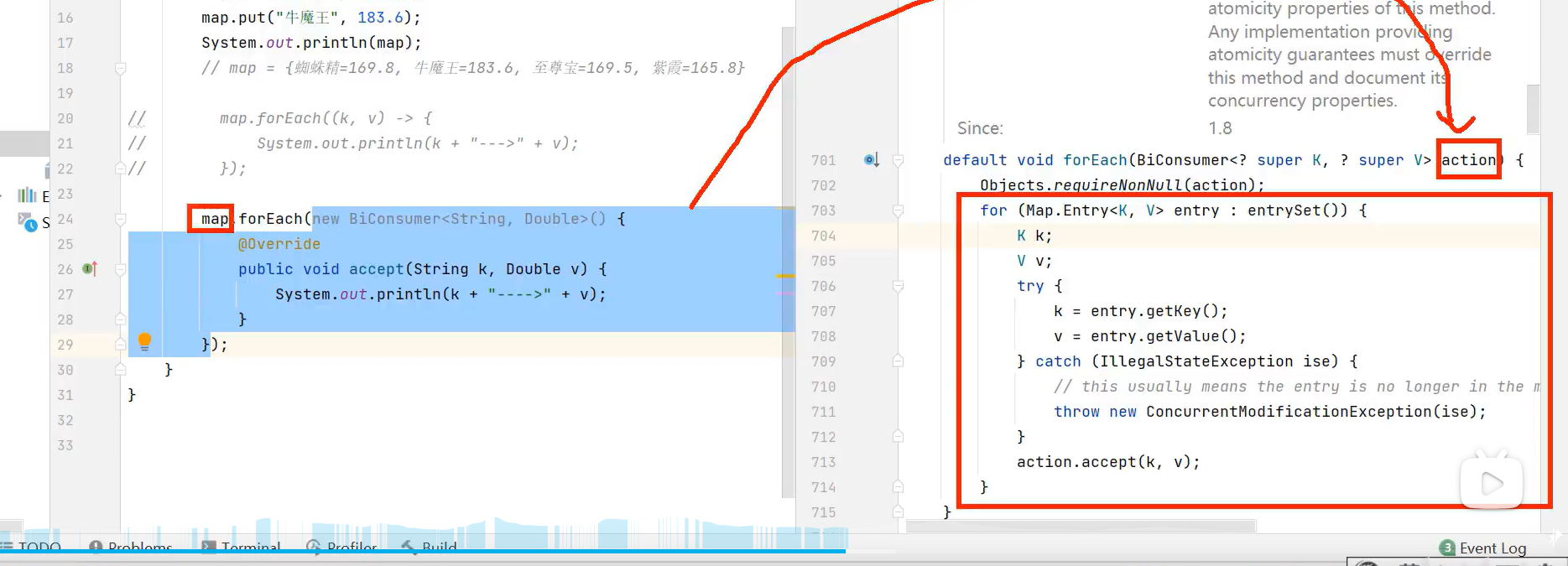
forEach源代码
1.HashMap
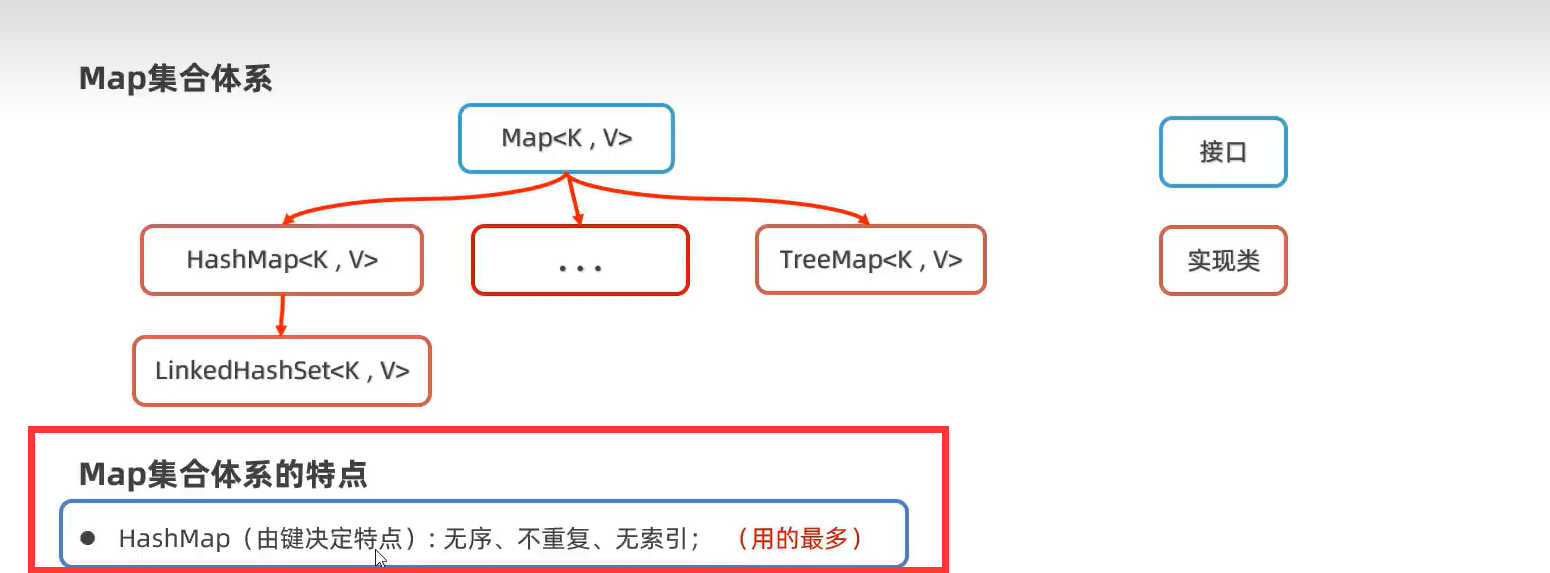
用的方法就一般就是父类Map的方法
只不过Set集合只要键,没要值而已

用键的哈希值来求余,而不是用值,因为键是唯一的

示例代码:
重写equals和hashCode方法来判断对象是否相同,以保证map的键不重复
2.LinkedHashMap

LinkedHashSet底层原理就是LinkedHashMap,只不过链表中只存储键,不存储值罢了。
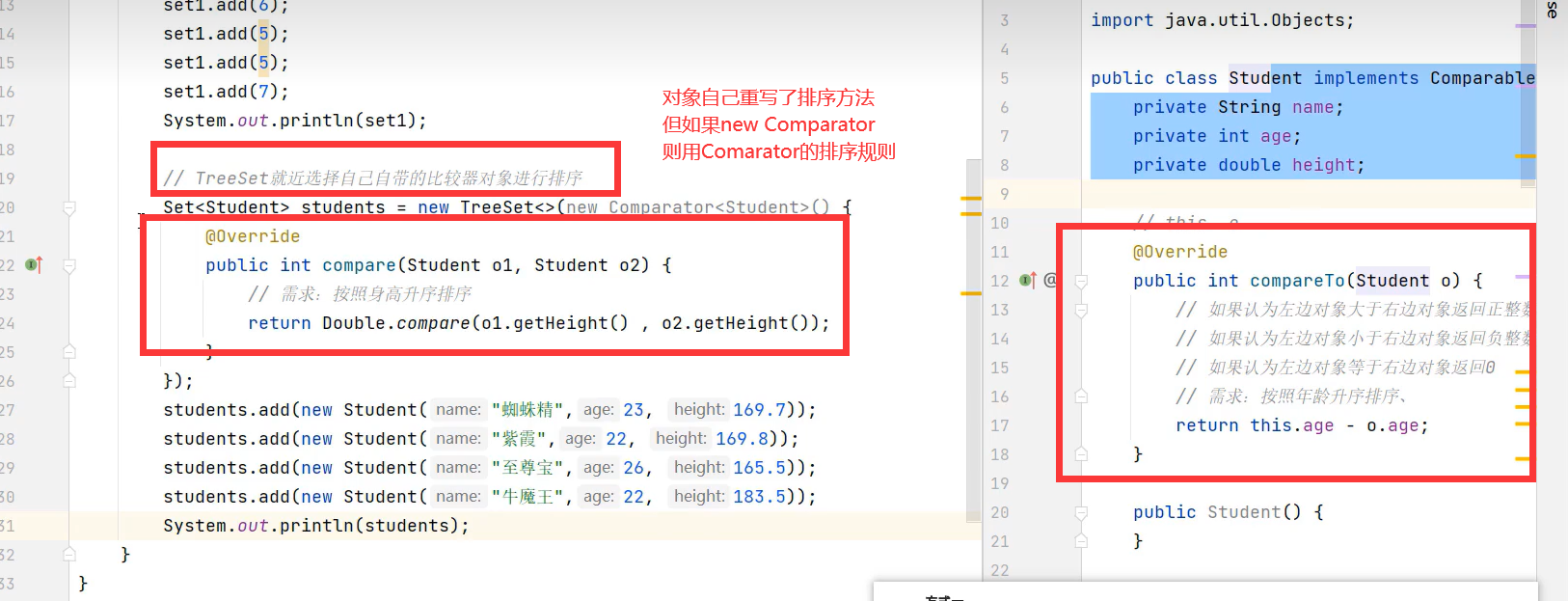
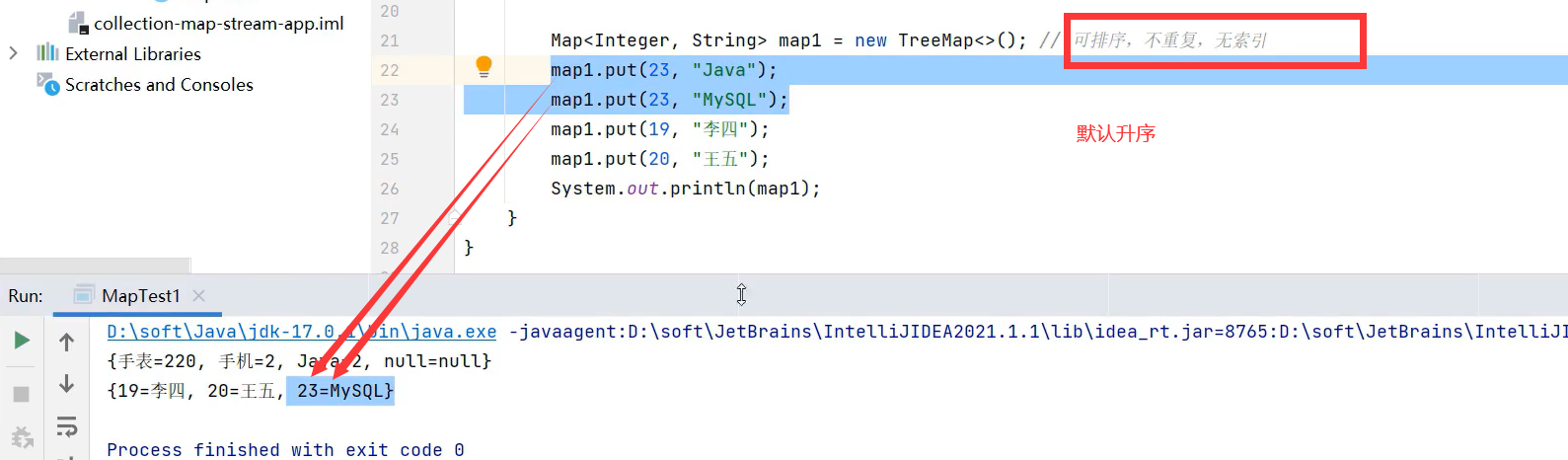
3.TreeMap
TreeSet底层原理就是TreeMap,只不过链表中只存储键,不存储值罢了。

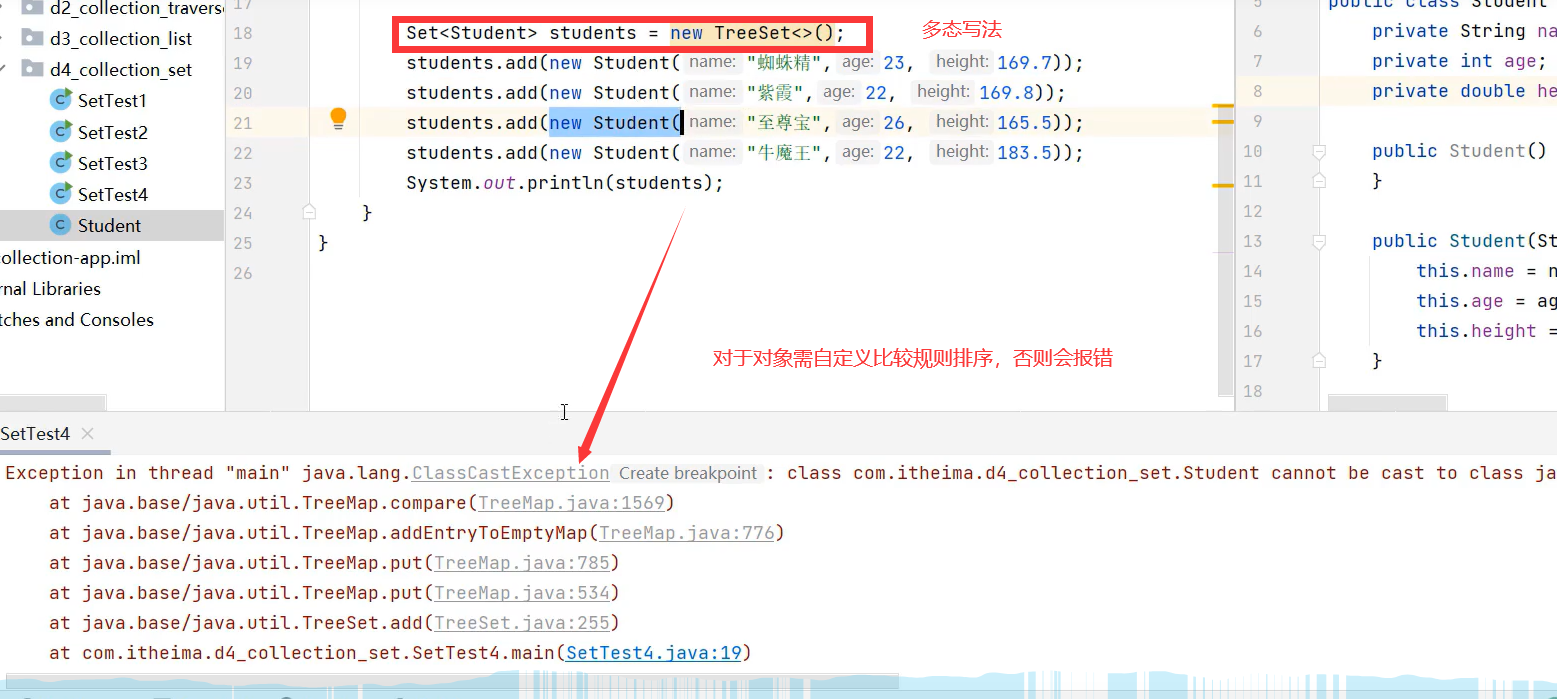
未让对象指定排序会报错:ClassCastException
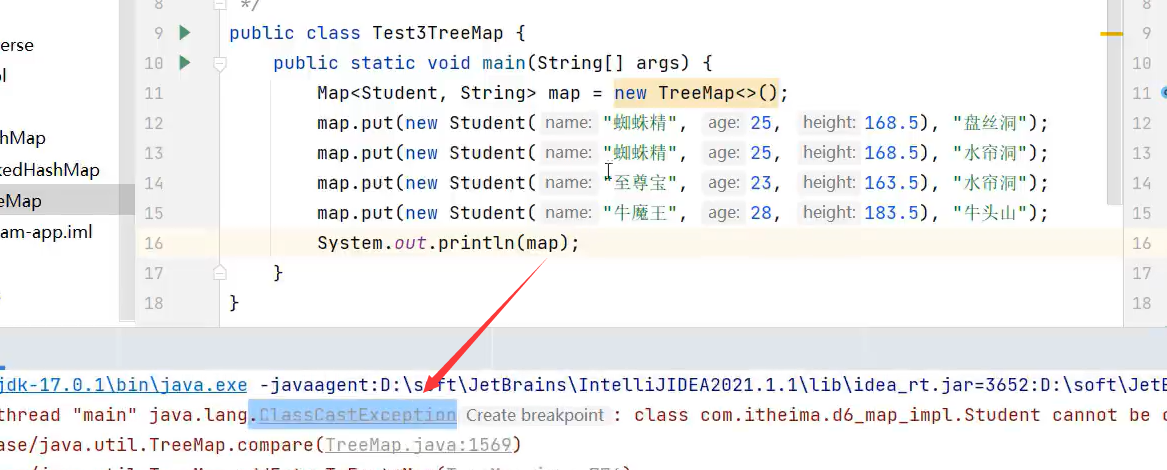
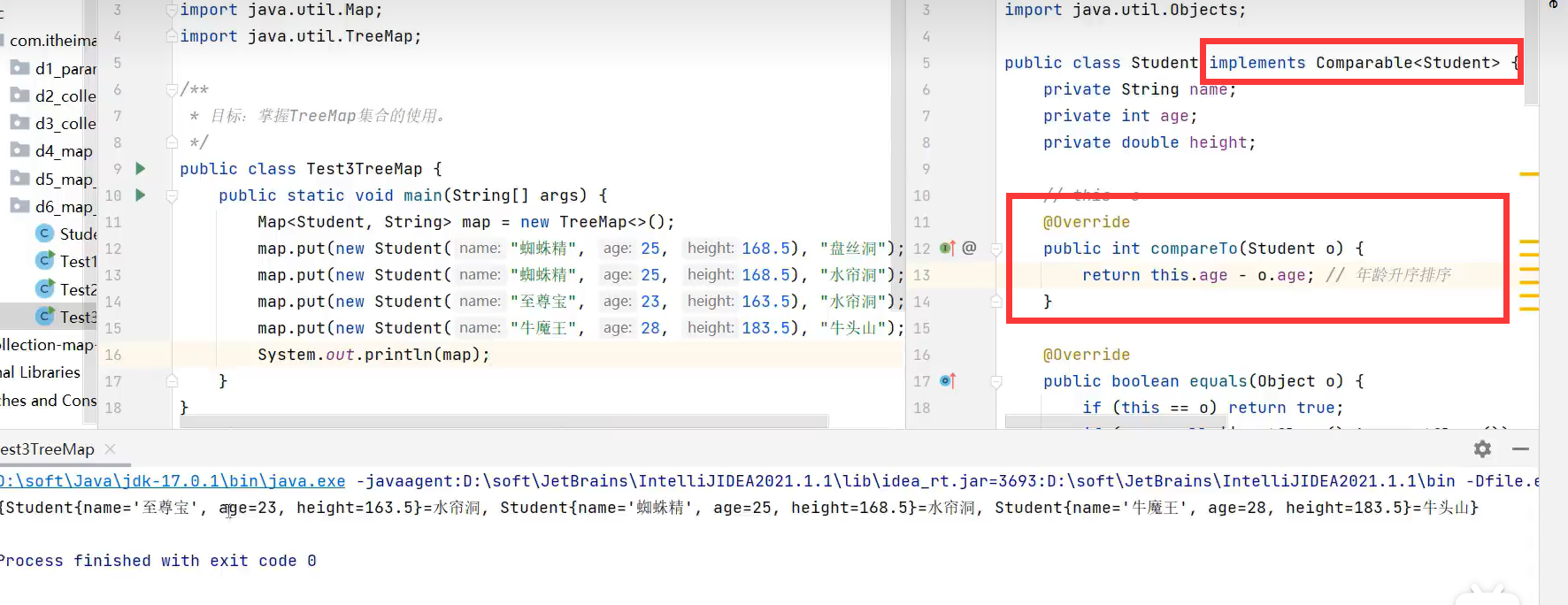
让对象自定义排序规则的方式1
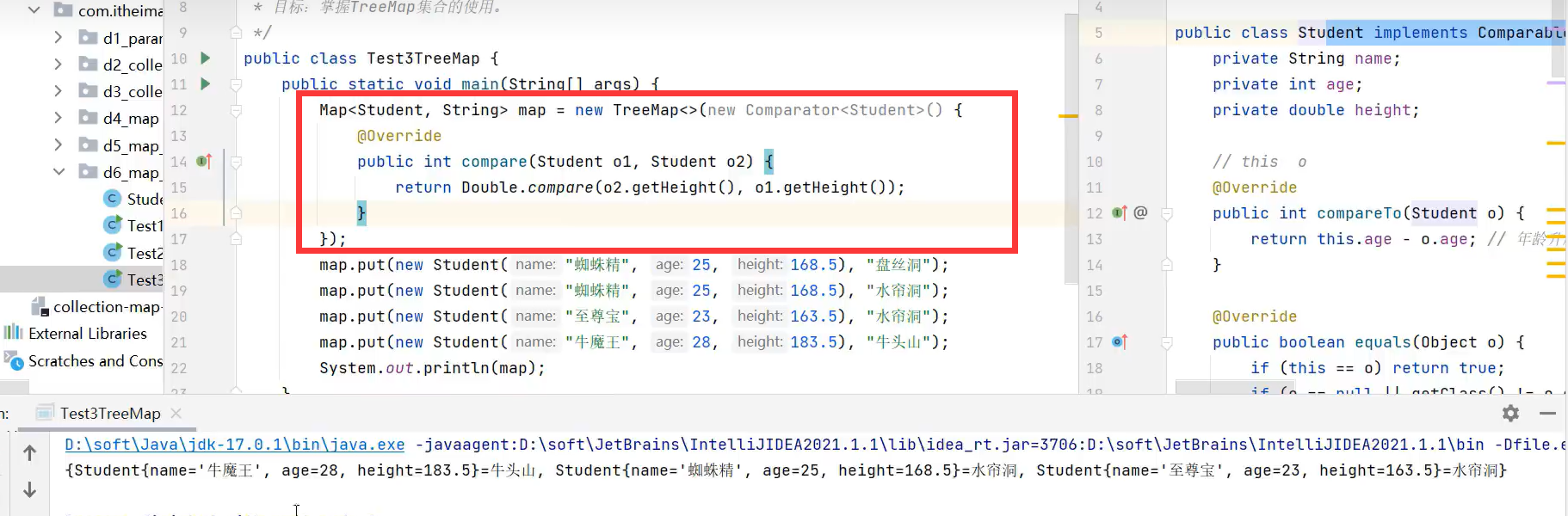
让对象自定义排序规则的方式2:TreeMap构造器内部new Comarpator指定排序规则
3.集合的嵌套
集合中包括集合

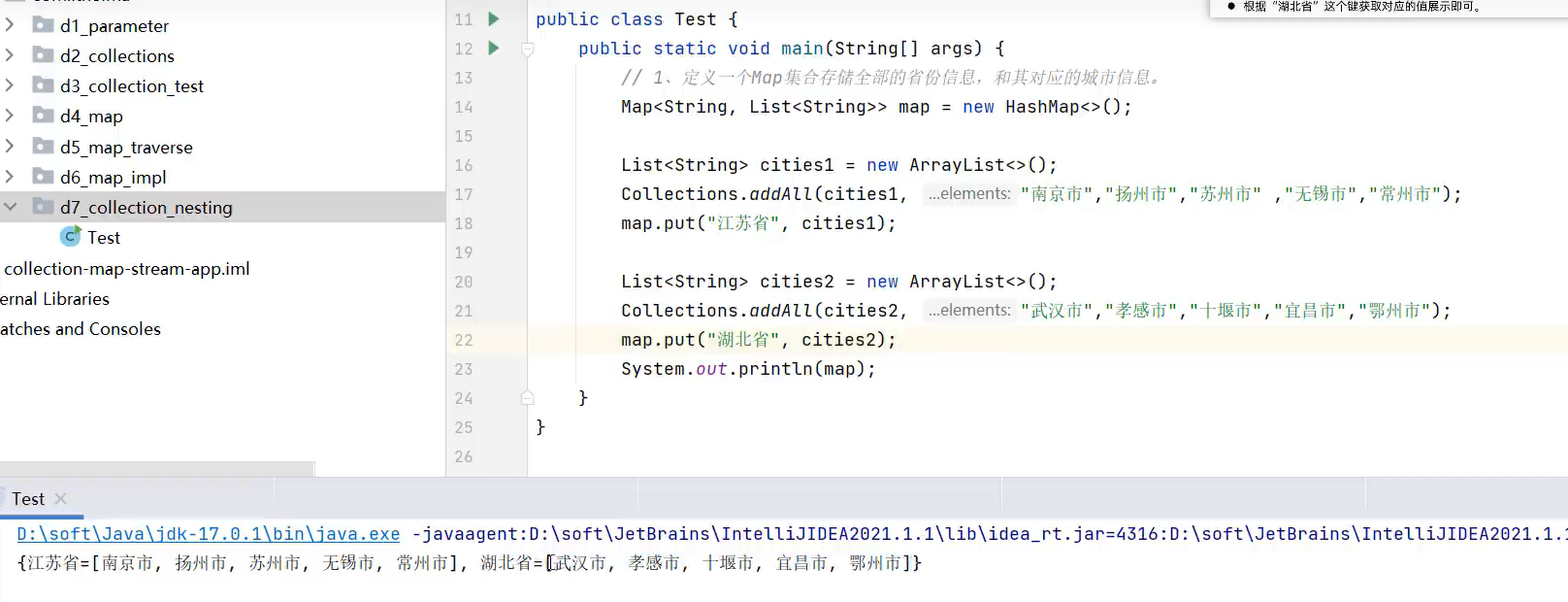
遍历嵌套的集合
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- boost.circular_buffer的使用和介绍
- bootstrap5开发房地产代理公司Hamilton前端页面
- A connection was successfully established with the server...证书链是由不受信任的颁发机构颁发的。
- 养老智慧服务平台设计与实现-附源码071526
- 【C语言】随机数生成详解,手把手教你,保姆级!!!
- 《作家天地》期刊投稿邮箱投稿方式
- 状态空间模型(SSM)是近来一种备受关注的 Transformer 替代技术
- python ffmpeg将mp4文件实时转码为ts,并指定pid等信息,输出到udp
- 如何用Jmeter做性能测试
- 深度学习入门——卷积神经网络CNN基本原理+实战