【隐私保护】Presidio简化了PII匿名化
自我介绍
- 做一个简单介绍,酒架年近48 ,有20多年IT工作经历,目前在一家500强做企业架构.因为工作需要,另外也因为兴趣涉猎比较广,为了自己学习建立了三个博客,分别是【全球IT瞭望】,【架构师酒馆】和【开发者开聊】,有更多的内容分享,谢谢大家收藏。
- 企业架构师需要比较广泛的知识面,了解一个企业的整体的业务,应用,技术,数据,治理和合规。之前4年主要负责企业整体的技术规划,标准的建立和项目治理。最近一年主要负责数据,涉及到数据平台,数据战略,数据分析,数据建模,数据治理,还涉及到数据主权,隐私保护和数据经济。 因为需要,比如数据资源入财务报表,另外数据如何估值和货币化需要财务和金融方面的知识,最近在学习财务,金融和法律。打算先备考CPA,然后CFA,如果可能也想学习法律,备战律考。
- 欢迎爱学习的同学朋友关注,也欢迎大家交流。微信小号【ca_cea】

匿名化的背景和如何构建匿名器
随着GDPR在欧洲实施后的各种法规,正确处理敏感信息,特别是个人身份信息(PII)成为许多公司的要求。在本文中,我们将讨论什么是PII,以及如何在非结构化数据(尤其是文本)中匿名化PII。我们还将演示使用Microsoft Presidio的文本匿名器的示例实现,这是一个提供快速PII识别和匿名模块的开源库。本文分为以下几个部分:
- 背景:隐私和匿名
- 现有的匿名技术
- 使用Microsoft Presidio自定义PII匿名器
- 结论、链接和参考文献
跳到任何你觉得最有趣的部分!
背景
早在19世纪50年代,数据保护和隐私保护技术就已被研究和应用,当时美国人口普查局开始从公开的美国公民人口普查数据中删除个人数据。自从早期使用诸如添加随机噪声或聚合之类的简单技术以来,已经提出并改进了各种模型。隐私权是一项基本人权。根据字典的定义,它是
个人或群体将自己或关于自己的信息隐藏起来,从而有选择地表达自己的能力。
哪些个人信息被视为可能导致个人隐私受损的敏感信息?2018年,欧盟推出了最严厉的隐私和安全法《通用数据保护条例》(GDPR)。GDPR将个人数据定义为
“任何与可以直接或间接识别的个人有关的信息。姓名和电子邮件地址显然是个人数据。位置信息、种族、性别、生物特征数据、宗教信仰、网络cookie和政治观点也可以是个人数据”
根据一条信息是否可以直接或间接用于重新识别个人,可以将上述信息分为直接标识符和准标识符
- -直接标识符:个人唯一的一组变量(姓名、地址、电话号码或银行账户),可用于直接识别受试者。
- -准识别者:孤立地无法重新识别的信息(如性别、国籍或居住城市),但与其他准识别者和背景知识相结合时可以重新识别。
现有的匿名技术
数据保护法规使公司和个人在利用数据获取见解和保护隐私之间不断斗争。然而,匿名化技术可以应用于数据集,因此不可能识别特定的个人。这样,这些数据集将不再属于数据保护法规的范围。
匿名化结构化数据
当涉及到结构化数据的匿名化时,已经建立了隐私的数学模型,如K-匿名或差分隐私。
- K-匿名。是由Pierangela Samarati和Latanya Sweeney2于1998年引入的。如果一个人所包含的每个信息在数据集中都不能与至少k-1个其他个体区分,那么掩码数据集具有k-匿名性。可以使用两种方法来实现k匿名。一种是抑制,从数据集中完全删除属性的值;另一种是泛化,将属性的特定值替换为更通用的值。
- L-多样性。是k-匿名性的进一步扩展。如果我们把一个数据集中具有相同准标识符的行集合放在一起,每个敏感属性至少有l个不同的值,那么我们可以说这个数据集具有l多样性。
- 差异隐私。是由微软研究公司的Cynthia Dwork于2006年提出的。3如果一个过程或算法的输出大致相同,无论是否有一个人贡献了他或她的数据,它都是一种过程或算法所满足的属性。换言之,仅仅通过观察差异私人分析的输出,就无法确定特定个体是否在数据集中。有了差异隐私,我们可以在不了解个人信息的情况下了解有关群体的有用信息。
- 计算数据集统计数据(如均值、方差或执行某些聚合)的算法可以被视为不同的私有算法。它也可以通过在数据中添加噪声来实现。差分隐私使用参数epsilon来调节隐私和数据集有用性之间的权衡。
还有一些众所周知的技术要应用于结构化数据库中进行匿名化:
- 屏蔽:删除、加密或隐藏私有标识符
- 假名化:用假名或假值替换私有标识符
- 泛化:用更多的基因替换特定的标识符值
匿名化非结构化数据
匿名化非结构化数据(如文本或图像)的过程是一项更具挑战性的任务。它需要检测非结构化数据中的敏感信息,然后对其应用匿名化技术。由于非结构化数据的性质,直接使用简单的基于规则的模型可能不会有很好的性能。例外情况是电子邮件或电话号码,可以通过基于模式的方法(如RegEx)非常有效地检测和匿名。其他挑战包括各国标识符的类型不同。因此,很难设计出一个适用于所有用例的一刀切的系统。典型的标识符类型包括以上章节中提到的内容——姓名、电子邮件、驾驶执照等。除此之外,您还可以在此处找到有关敏感信息类型的详尽列表。
除了基于规则的方法外,自然语言处理(NLP)技术也被应用于文本匿名化。特别是用于命名实体识别(NER)任务的技术。这是一种序列标记任务。这种情况下的标签指示令牌(如单词)是否对应于命名实体,如PERSON、LOCATION或DATE。
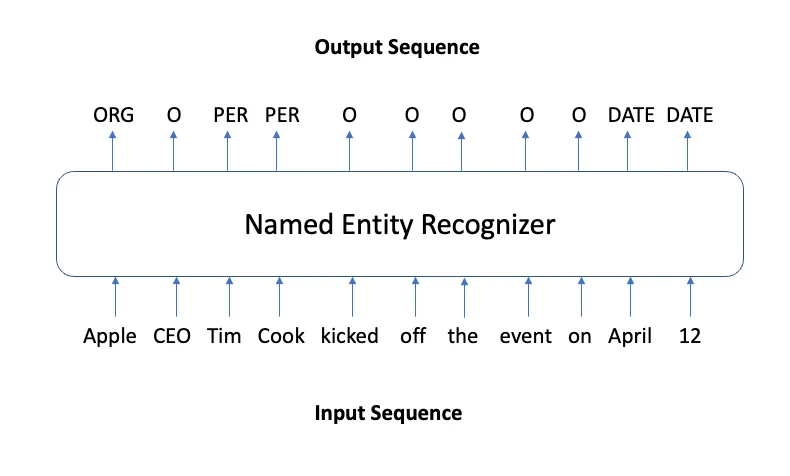
一些神经模型在具有通用命名实体的数据集上的NER任务上实现了最先进的性能。当他们在包含各种类型个人信息的医学领域数据上接受训练时,他们也可以在这些数据上获得最先进的性能。这些模型架构包括具有字符嵌入的递归神经网络? 或双向变压器?. SpaCy也有一个NER模型。它是一个RoBERTa语言模型,在Ontonotes数据集上进行了微调,包含18个命名的实体类别,如PERSON、GPE、CARDINAL、LOCATION等(请参阅此处的实体类型完整列表)。另一个开箱即用的工具是Presidio。这是一个由微软开发的匿名SDK,它依赖于基于规则和NER的模型来检测和屏蔽PII。支持的实体列表可以在此处找到。
识别PII后会发生什么?
一种方法是用伪值替换标识符。例如,如果一个人的姓名或电话号码在“我叫Amy,我的号码是85562333”这样的句子中被识别,那么匿名文本可以是“我的名字是<person_name>,我的电话号码是<phone_number>”。这种方法简单明了,但也有一些缺点。当对所有相同的实体类型使用一个值时,我们会丢失重要信息。在这个例子中,我们不知道这个人的性别是什么。根据匿名文本的使用情况,可能需要保留此类信息。或者,当涉及到地址时,人们希望在一定程度上保持地理分布。
另一种方法是用代理值替换检测到的实体。它可以从每个实体类型的预定列表中随机采样,也可以根据某些规则进行采样。还有一些Python包,如Faker,可以生成合成地址或名称用作代理值。
使用Microsoft Presidio自定义PII匿名器
当我们将PII匿名化应用于现实世界的应用程序时,可能会有不同的业务需求,这使得直接使用预训练的模型具有挑战性。例如,想象一下,挪威的一家公司联系你,希望你为他们开发一个文本匿名器。他们希望它支持英文和挪威文中的匿名PII。除了常见的PII实体外,您还需要检测遵循某些校验和规则的挪威国民身份证号码。预先训练的NER模型很好,但如果不使用额外的标记数据来微调模型以获得良好的性能,就无法轻松添加新的实体类型。因此,有一个工具可以利用预先训练的模型,并且很容易定制和扩展功能,这是很好的。
微软Presidio是一个开源SDK,正是这样做的。根据他们的说法,
Presidio支持针对特定业务需求的可扩展性和可定制性,允许组织通过民主化去识别技术和引入决策透明度,以更简单的方式保护隐私。
它有两个主要部分——分析器和匿名器。Analyzer是一种基于Python的服务,用于检测文本中的PII实体。它利用命名实体识别、正则表达式、基于规则的逻辑和校验和多种语言的相关上下文。例如,它使用预定义的基于Regex模式的电子邮件和IP地址识别器,以及SpaCy自然语言处理模型来构建命名实体的识别器。
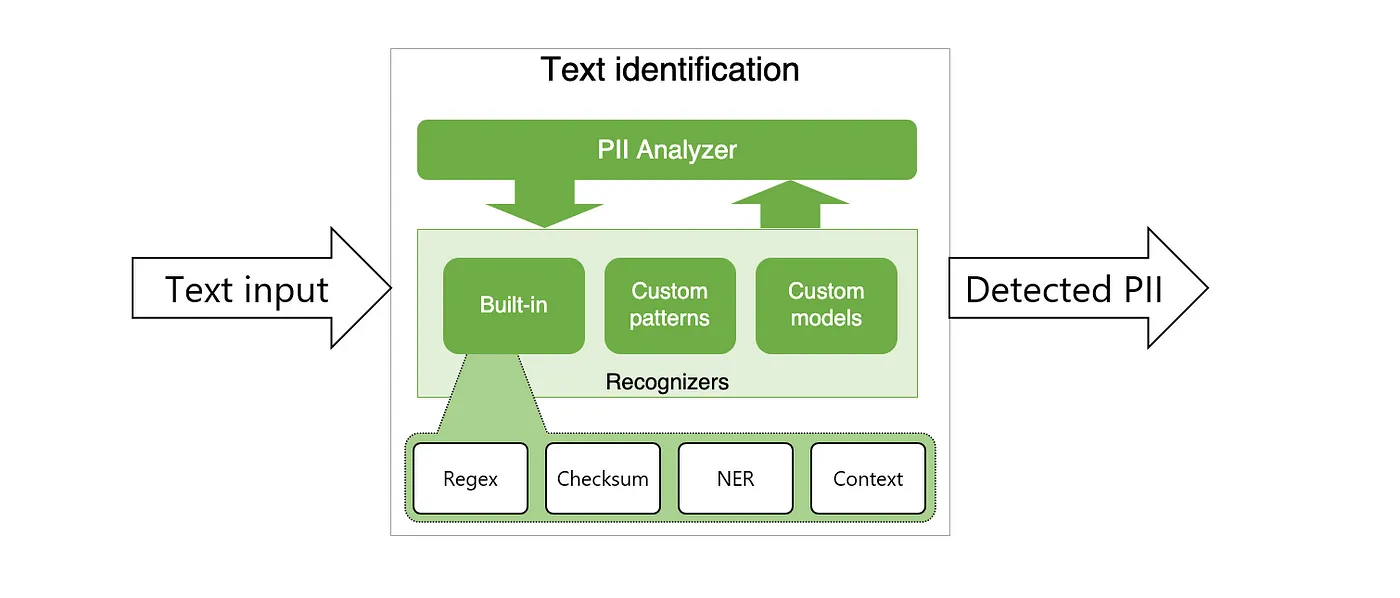
Presidio Analyzer (image from the?Presidio documentation)
匿名器也是一个基于python的服务。它通过应用某些运算符(如替换、掩码和密文),将检测到的PII实体匿名化为所需值。默认情况下,它直接在文本中用其实体类型(如<EMAIL>或<PHONE_NUMBER>)替换检测PII。但人们可以自定义它,为不同类型的实体提供不同的匿名逻辑。
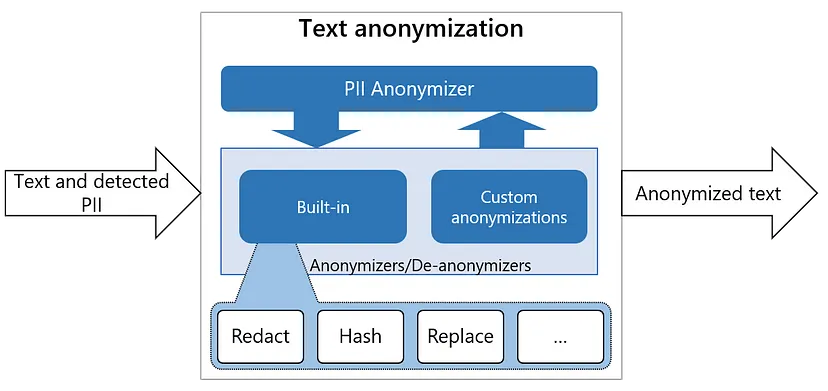
首先,按照此处的说明安装Presidio后,使用它就像调用默认的AnalyzerEngine和AnonymizerEngine一样简单:
from presidio_analyzer import AnalyzerEngine
from presidio_anonymizer import AnonymizerEngine
text="My phone number is 212-555-5555"
# Set up the engine, loads the NLP module (spaCy model by default)
# and other PII recognizers
analyzer = AnalyzerEngine()
# Call analyzer to get results
results = analyzer.analyze(text=text,
entities=["PHONE_NUMBER"],
language='en')
print(results)
# Analyzer results are passed to the AnonymizerEngine for anonymization
anonymizer = AnonymizerEngine()
anonymized_text = anonymizer.anonymize(text=text,analyzer_results=results)
print(anonymized_text)
AnalyzerEngine协调PII的检测。它的一些最重要的属性包括:
- registry:RecognizerRegistry,包含要在文本上使用的所有预定义或自定义的识别器
- nlp_engine:nlp模块的抽象,包括对文本中的令牌的处理功能
- supported_languages:支持的语言列表
对于我们前面提到的场景,使用默认的分析器是不够的,我们需要通过添加以下自定义来创建自己的自定义分析器引擎。
1.额外的语言支持
默认情况下,Presidio使用英文文本。但由于在我们的案例中,我们也将处理挪威语文本,我们需要将挪威语添加到Presidio的NlpEngineProvider的配置中。
from presidio_analyzer.nlp_engine import NlpEngineProvider
nlp_config= {
"nlp_engine_name": "spacy",
"models": [
{"lang_code": "no", "model_name": "nb_core_news_md"},
{"lang_code": "en", "model_name": "en_core_web_md"},
],
}
provider = NlpEngineProvider(nlp_configuration=nlp_config)
这是SpaCy上的挪威语模型管道。在运行分析器之前,还需要下载语言模型。
2.添加挪威电话号码识别器
Presidio中有一组预定义的识别器。请参阅此处的详细实体列表。我们可以选择加载部分或全部。Presidio的一个优点是可以很容易地添加适合自己用例的识别器。在下面的示例中,我们为挪威电话号码添加了一个以+47国家代码开头的识别器,因为默认的电话号码识别器不支持所有国家代码。
provider = NlpEngineProvider(nlp_configuration=PiiAnonymizer._nlp_config())
nlp_engine_with_norwegian = provider.create_engine()
# need to change supported_regions for NO phone number
phone_recognizer_no = PhoneRecognizer(
supported_language="no", supported_regions=phonenumbers.SUPPORTED_REGIONS
)
registry = RecognizerRegistry()
registry.load_predefined_recognizers(
nlp_engine=nlp_engine_with_norwegian, languages="no"
)
registry.add_recognizer(phone_recognizer_no)
3.添加挪威国民身份识别器
挪威身份证号码包含一个人的生日和一些遵循某些规则的数字(请参阅此处的详细规则)。我们可以为挪威ID识别器创建一个类,该类以以下方式扩展了Presidio的EntityRecognizer:
from typing import List
from presidio_analyzer import EntityRecognizer, RecognizerResult
from presidio_analyzer.nlp_engine import NlpArtifacts
import datetime
class NorwegianIDRecognizer(EntityRecognizer):
expected_confidence_level = 0.7
def load(self) -> None:
"""No loading is required."""
pass
def analyze(
self, text: str, entities: List[str], nlp_artifacts: NlpArtifacts
) -> List[RecognizerResult]:
"""
Analyzes test to find tokens which represent a valid Norwegian ID number
"""
results = []
for token in nlp_artifacts.tokens:
if token.is_digit and self._is_valid(token):
result = RecognizerResult(
entity_type="NORWEGIAN_ID",
start=token.idx,
end=token.idx + len(token),
score=self.expected_confidence_level,
)
results.append(result)
return results
def _is_valid(self, tok):
# check first
day = int(tok[:2])
month = int(tok[2:4])
year = int(tok[4:6])
try:
datetime.datetime(year=year, month=month, day=day)
except ValueError as e:
print(e)
return False
return True
最后,把所有东西放在一起,我们有了定制的分析仪:
provider = NlpEngineProvider(nlp_configuration=PiiAnonymizer._nlp_config())
nlp_engine_with_norwegian = provider.create_engine()
# need to change supported_regions for NO phone number
phone_recognizer_no = PhoneRecognizer(
supported_language="no", supported_regions=phonenumbers.SUPPORTED_REGIONS
)
id_recognizer_no = NorwegianIDRecognizer(supported_entities=["NORWEGIAN_ID"], supported_language="no")
registry = RecognizerRegistry()
registry.load_predefined_recognizers(
nlp_engine=nlp_engine_with_norwegian, languages="no"
)
registry.add_recognizer(phone_recognizer_no)
registry.add_recognizer(id_recognizer_no)
# Pass the created NLP engine and supported_languages to the AnalyzerEngine
analyzer = AnalyzerEngine(
registry=registry,
nlp_engine=nlp_engine_with_norwegian,
supported_languages=SUPPORTED_LANG,
)
当我们运行分析器来分析一段文本时(通过调用analyzer.analyze(text),可选地给出一个要识别的实体类型列表),文本将通过我们定义的识别器管道。我们可以添加三种主要类型的识别器——基于模式的识别器、基于规则的识别器和外部识别器。在本例中,我们需要添加基于规则的识别器。基于规则的识别器利用NLP工件,这些工件是由NLP引擎产生的令牌相关信息,如引理、POS标签或实体,用于识别PII。
对于已识别的PII,它将返回一个包含详细信息的字典:
{
'entity_type': 'NORWEGIAN_ID',
'start': 74,
'end': 85,
'score': 0.95
}
在匿名化方面,我们可以通过文本中的类型<NORWEGIAN_ID>直接屏蔽PII实体,并获得类似“我的ID是<NORWEGIAN_ID]”的信息,或者我们可以向匿名化器提供自定义运算符的字典。例如,我们可以创建一个随机的11位数字来替换ID。此外,我们还可以使用faker等包来生成合成名称。
from faker import Faker
from presidio_anonymizer.entities import OperatorConfig
faker = Faker()
def fake_name(x):
return PiiAnonymizer.faker.name()
def random_digit(x):
return str(random.randint(10000000000, 99999999999))
def custom_oprators():
"""
Custom operators for the Anonymizer
:return: operator dictionary
"""
config = {
"NORWEGIAN_ID": OperatorConfig(
"custom",{"lambda": random_digit },),
"PERSON": OperatorConfig("custom", {"lambda": fake_name})}
return config
analyzer = AnalyzerEngine()
anonymizer = AnonymizerEngine()
analyzer_result = analyzer.analyze(
text=text,
entities=entities,
language=lang,
)
anonymizer_result = anonymizer.anonymize(
text=text, analyzer_results=analyzer_result,
operators=custom_operators()
)
用一些例子测试匿名器
为了测试匿名器的性能,我们可以从LinkedIn上找到挪威语和英语的招聘信息。他们通常有许多PII实体。一些示例文本如下所示(注意:此处发布的是经过编辑的版本,因此不包含任何真实的标识符)。
{
"input": [
{
"text": "Please do not hesitate to reach out to our Senior Recruiter, Amy Ruban , at amy.ruban@cognite.com or our Director of Engineering, Rebecca Wiborg Seyfarth , at rebecca.wiborg.seyfarth@cognite.com.",
"lang": "en"
},
{
"text": "Er du nysgjerrig? Ta kontakt med Susanne Ohlsson, ansvarlig for rekruttering i Stretch.\n\nsusanne.ohlsson@stretch.se eller +46 (0)707 73 05 18",
"lang": "no"
},
{
"text": "If you have questions regarding the position or application process, please contact Mats Herman Hjelmtvedt at +47 22 01 58 30",
"lang": "en"
},
{
"text": "Pia-Ina Houge, IT Sjef\tPolitih?gskolen , Oslo, Norge\nE-post : pia-ina.houge@phs.no\nTlf: 94623136\nBorghild Gronlund, IT Sjef\tNorsonic AS, Tranby, Norge\nE-post: bgronlund@norsonic.com \nTlf. 98 56 73 59\n?ivind Kise, IT Sjef\tGarderobe-Mannen AS, Fredrikstad, Norge\nE-post: oivind@garderobemannen.no \nTlf. 92 33 95 66\n",
"lang": "unknown"
},
{
"text": "For n?rmere informasjon om stillingen, kontakt: forskningsleder Vilde Bernstr?m, e-post vilde@oslomet.no , eller Elisabeth N?rgaard, instituttdirekt?r, mobil 90074612",
"lang": "no"
}
],
"mode": "tagged_text"
}
将样本文本提交给我们的匿名器管道,我们获得了以下结果:
{
"output": {
"output": [
{
"tagged_text": "Please do not hesitate to reach out to our Senior Recruiter, <PERSON> , at <EMAIL_ADDRESS> or our Director of Engineering, <PERSON> , at <EMAIL_ADDRESS>."
},
{
"tagged_text": "Er du nysgjerrig? Ta kontakt med <PERSON>, ansvarlig for rekruttering i Stretch.\n\n<EMAIL_ADDRESS> eller <PHONE_NUMBER>"
},
{
"tagged_text": "If you have questions regarding the position or application process, please contact <PERSON> at <PHONE_NUMBER>"
},
{
"tagged_text": "<PERSON>, IT Sjef\tPolitih?gskolen , <LOCATION>, Norge\nE-post : <EMAIL_ADDRESS>\nTlf: <DATE_TIME>\n<PERSON>, IT Sjef\tNorsonic AS, Tranby, Norge\nE-post: <EMAIL_ADDRESS> \nTlf. <PHONE_NUMBER>\n<PERSON>, IT <PERSON>\tGarderobe-Mannen AS, <LOCATION>, Norge\nE-post: <EMAIL_ADDRESS> \nTlf. <PHONE_NUMBER>\n"
},
{
"tagged_text": "For n?rmere informasjon om stillingen, kontakt: forskningsleder <PERSON>, e-post <EMAIL_ADDRESS> , eller <PERSON>, instituttdirekt?r, mobil <PHONE_NUMBER>"
}
]
}
}
正如我们所看到的,对于英文文本,匿名器具有非常好的性能,可以检测所有的姓名、电子邮件和电话号码。对于具有适当文本语法的挪威文本,检测性能也非常好。然而,当涉及到挪威语文本时,这不是一个合适的句子,例如第4个例子,我们可以看到它有点挣扎,并将电话号码与日期混淆。对于那些对更详细的性能评估感兴趣的人,请查看本文,他们在维基百科文本中的一个小的手动标记数据集上应用Presidio进行了一项研究。
结论
在这篇文章中,我们讨论了隐私和PII的背景,并展示了如何使用Presidio来构建自定义的PII匿名器。对真实世界文本的研究结果是有希望的。我们可以寻求进一步的改进。我们可以用更强大的语言模型来替换底层语言模型,以便在NER上获得更好的性能。为了识别更多不同国家定义的PII实体,我们还可以添加更多基于规则的识别器。
最后注释:
我们看到越来越多的客户对正确处理PII感兴趣,因此我们非常感谢像Presidio这样的优秀开源库,它们使我们能够利用最先进的技术来解决这个问题。
查看我的Github存储库中定制的匿名器的完整实现。它还包括将其作为Docker应用程序运行并部署到AWS的脚本。感谢您阅读这篇文章!我很想听听你对这个话题的看法!
本文:【隐私保护】Presidio简化了PII匿名化 | 开发者开聊
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 相册管理系统(JSP+java+springmvc+mysql+MyBatis)
- 基于模块自定义扩展字段的后端逻辑实现(二)
- 系列十一、Spring Security登录接口兼容JSON格式登录
- SSL证书是什么?为什么需要SSL证书?
- 有趣的代码——剪刀、石头、布小游戏的代码实现
- Tcpdump 抓包分析指令使用方法
- JAVA代码审计(函数定位)
- LeetCode刷题(文章链接汇总)
- Rust 注释规则
- 模糊测试:使用随机输入破坏事物