MATLAB实现系统聚类分析数学建模算法
发布时间:2024年01月12日
系统聚类(Hierarchical Clustering)是一种用于对数据进行聚类的方法,也叫层次聚类,其主要特点是通过构建层次结构的树形图(树状图或树状结构)来表示数据点之间的关系。这种层次结构可以是自上而下的划分(分裂),也可以是自下而上的合并。系统聚类方法不需要预先设定聚类的数量,而是通过构建层次结构树,形成不同层次的聚类。
系统聚类的基本思想是:
1. **开始阶段:** 将每个数据点视为一个独立的簇。
2. **迭代过程:** 通过计算数据点之间的相似性或距离,合并或分裂簇,形成新的簇。
3. **层次结构的构建:** 通过反复迭代,建立层次结构,形成树状图。
4. **划分聚类:** 可以通过设定阈值,将层次结构树划分为不同层次的簇。
系统聚类可以分为两大类:
1. **凝聚性聚类(Agglomerative Clustering):** 从底层开始,逐渐合并相似的数据点或簇,形成一个大的簇。这是一种自下而上的合并过程。
2. **分裂性聚类(Divisive Clustering):** 从顶层开始,逐渐分裂簇,形成小的簇。这是一种自上而下的划分过程。
系统聚类的常见距离度量包括欧氏距离、曼哈顿距离、切比雪夫距离等。合并或分裂的策略可以基于最小距离、最大距离、平均距离等。
系统聚类的优势在于它不需要事先确定聚类的数量,并且可以通过层次结构图直观地展示不同层次的聚类结果。然而,由于其计算复杂度较高,对于大规模数据集可能效率较低。另外,系统聚类对初始簇的选择敏感,因此可能受到初始条件的影响。

MATLAB的代码实现如下:
clc, clear, close all
a=load('anli10_1.txt');
b=zscore(a); %数据标准化
r=corrcoef(b) %计算相关系数矩阵
%d=tril(1-r); d=nonzeros(d)'; %另外一种计算距离方法
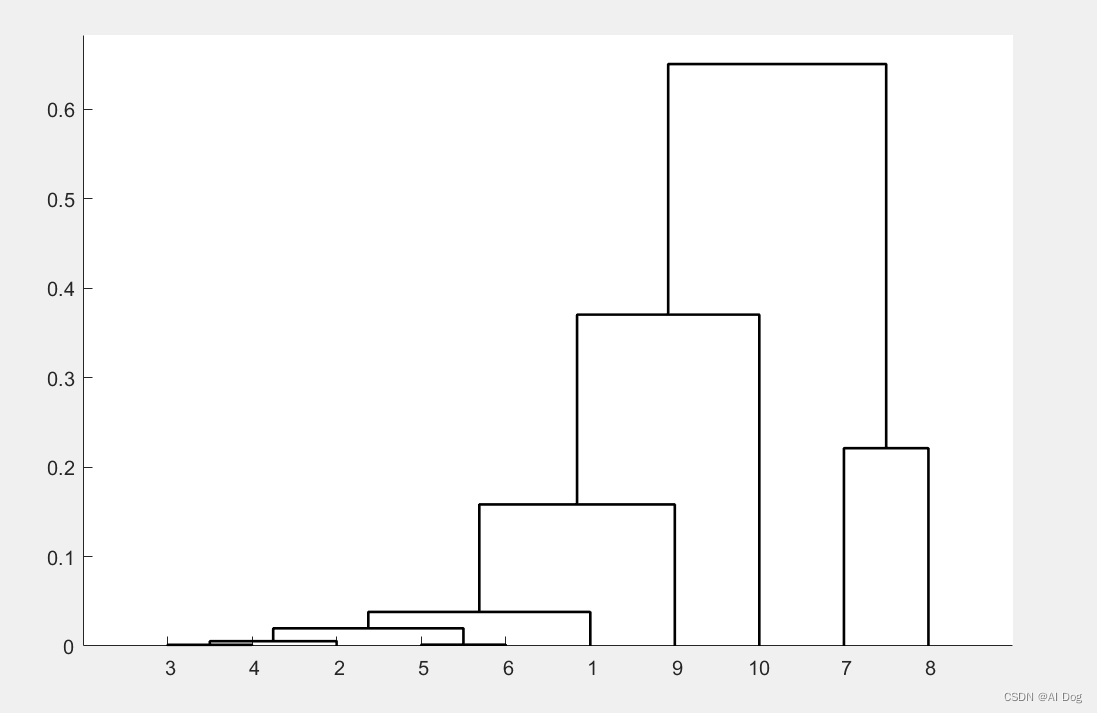
z=linkage(b','average','correlation'); %按类平均法聚类
h=dendrogram(z); %画聚类图
set(h,'Color','k','LineWidth',1.3) %把聚类图线的颜色改成黑色,线宽加粗
T=cluster(z,'maxclust',6) %把变量划分成6类
for i=1:6
tm=find(T==i); %求第i类的对象
fprintf('第%d类的有%s\n',i,int2str(tm')); %显示分类结果
end
结果如下:

clc,clear, close all
a = load('anli10_1.txt');
a(:,[3:6])=[]; %删除数据矩阵的第3列~第6列,即使用变量1,2,7,8,9,10
b=zscore(a); %数据标准化
z=linkage(b,'average'); %按类平均法聚类
h=dendrogram(z); %画聚类图
set(h,'Color','k','LineWidth',1.3) %把聚类图线的颜色改成黑色,线宽加粗
for k=3:5
fprintf('划分成%d类的结果如下:\n',k)
T=cluster(z,'maxclust',k); %把样本点划分成k类
for i=1:k
tm=find(T==i); %求第i类的对象
fprintf('第%d类的有%s\n',i,int2str(tm')); %显示分类结果
end
fprintf('**********************************\n');
end


文章来源:https://blog.csdn.net/weixin_58438203/article/details/135525015
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Vue3地图选点组件
- 网络安全(黑客)—自学
- 筛选数据-第15届蓝桥第三次STEMA测评Scratch真题精选
- 基于微信小程序+SSM+MySQL的个人健康数据管理系统小程序(附论文)
- Py之jupyter_client:jupyter_client的简介、安装、使用方法之详细攻略
- 【华为OD题库-105】滑动窗口最大值-java
- SpringCloud微服务之间如何进行调用通信的?
- YACS(上海计算机学会竞赛平台)2022年12月月赛——星号三角阵(二)
- JVM问题分析处理手册
- AI对决:ChatGPT与文心一言的深度比较