深入浅出图解C#堆与栈 C# Heap(ing) VS Stack(ing) 第二节 栈基本工作原理
深入浅出图解C#堆与栈 C# HeapingVS Stacking第二节 栈基本工作原理
- [深入浅出图解C#堆与栈 C# Heap(ing) VS Stack(ing) 第一节 理解堆与栈](https://mp.csdn.net/mdeditor/101021023)
- [深入浅出图解C#堆与栈 C# Heap(ing) VS Stack(ing) 第二节 栈基本工作原理](https://mp.csdn.net/mdeditor/101022949#)
- [深入浅出图解C#堆与栈 C# Heap(ing) VS Stack(ing) 第三节 栈与堆,值类型与引用类型](https://mp.csdn.net/mdeditor/101023885#)
- [深入浅出图解C#堆与栈 C# Heap(ing) VS Stack(ing) 第四节 参数传递对堆栈的影响 1](https://mp.csdn.net/mdeditor/101026168#)
- [深入浅出图解C#堆与栈 C# Heap(ing) VS Stack(ing) 第四节 参数传递对堆栈的影响 2](https://mp.csdn.net/mdeditor/101027584#)
- [深入浅出图解C#堆与栈 C# Heap(ing) VS Stack(ing) 第五节 引用类型复制问题及用克隆接口ICloneable修复](https://mp.csdn.net/mdeditor/101028008#)
- [深入浅出图解C#堆与栈 C# Heap(ing) VS Stack(ing) 第六节 理解垃圾回收GC,提搞程序性能](https://mp.csdn.net/mdeditor/101029557#)
- 第二篇栈基本工作原理
深入浅出图解C#堆与栈 C# Heap(ing) VS Stack(ing) 第一节 理解堆与栈
深入浅出图解C#堆与栈 C# Heap(ing) VS Stack(ing) 第二节 栈基本工作原理
深入浅出图解C#堆与栈 C# Heap(ing) VS Stack(ing) 第三节 栈与堆,值类型与引用类型
深入浅出图解C#堆与栈 C# Heap(ing) VS Stack(ing) 第四节 参数传递对堆栈的影响 1
深入浅出图解C#堆与栈 C# Heap(ing) VS Stack(ing) 第四节 参数传递对堆栈的影响 2
深入浅出图解C#堆与栈 C# Heap(ing) VS Stack(ing) 第五节 引用类型复制问题及用克隆接口ICloneable修复
深入浅出图解C#堆与栈 C# Heap(ing) VS Stack(ing) 第六节 理解垃圾回收GC,提搞程序性能
第二篇栈基本工作原理
前言
虽然在.Net Framework 中我们不必考虑内在管理和垃圾回收(GC),但是为了优化应用程序性能我们始终需要了解内存管理和垃圾回收(GC)。另外,了解内存管理可以帮助我们理解在每一个程序中定义的每一个变量是怎样工作的。
简介
这一节介绍栈的基本工作原理。
两个黄金规则
1.引用类型永远存储在堆里。
2.值类型和指针永远存储在它们声明时所在的堆或栈里。
栈工作原理
栈:如第一节所说,在代码运行时负责跟踪每一个线程的所在(什么被调用了)。你可以把它想象成一个线程“状态”,而每一个线程都有它自己的栈。当我们的代码执行一次方法调用,线程开始执行寄存在方法(method)表里的JIT编译过的指令,并且把该方法的参数存放到当前线程栈里。然后,随着代码的执行每遇见方法中的变量,该变量都会被放到栈的最上面,如此重复把所有变量都放到栈上,当然引用类型只存放指针。
为了方便理解,让我们看代码与图例。
执行 下面的方法:

下面是栈里发生的情况. 有必要提醒的是,我们现在假设当前代码产生的栈存储会放到所有既有项(栈里已经存储的数据)之上。一旦我们开始执行该方法,方法参数pValue会被放到栈上(以后的文章里会介绍参数传递)。
注意:方法并不存在栈里,图只是为了阐述原理而放的引用。
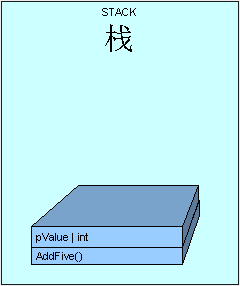
下一步,控制(线程执行方法)被传递到寄存在方法类型表里的AddFive()方法对应的指令集中。如果方法是第一次被触发,会执行JIT编译。

随着方法的执行,栈会分配一块内存给变量result存放。

方法执行完成,返回result。

该次任务在栈里所占的所有内存将被清理,仅一个指针被移动到AddFive()开始时所在的可用内存地址上。接着会执行栈里AddFive()下面一个方法(图里看不到)。

在这个例子当中,变量result被放到了栈里。事实上,方法体内每次定义的值类型变量都会被放到栈里。
当然值类型有时候也会被放到堆里,我们将会在下一节提到。
总结
栈可以想像成一个严格顺序执行的序列,不允许跳跃穿插访问。栈有自我清理功能。本文以执行一个简单C#方法为例阐述了栈的基本工作原理。下一节继续介绍堆栈工作原理以及一个更复杂一些的例子。
译文连接:https://blog.csdn.net/leewhoee/article/details/16934737
原文链接:https://www.c-sharpcorner.com/article/C-Sharp-heaping-vs-stacking-in-net-part-i/
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 智慧公厕:城市公共厕所环境卫生管理的智慧引擎
- 人工智能“自然语言及语音处理设计开发工程师”证书报名条件及报考流程
- Django开发_1_设置镜像源
- C/C++ 基础函数
- 生成式AI将有助于推动软件开发的进步和发展
- 区域负责人常用的ChatGPT通用提示词模板
- 基于微信小程序的毕业设计——社区宠物管理系统(附源码+论文)
- 喝不完的葡萄酒该怎么保存才好呢?
- Python学习笔记第七十四天(OpenCV安装)
- SSE[Server-Sent Events]实现页面流式数据输出(模拟ChatGPT流式输出)