缓存和缓冲的区别
近期被这两个词汇困扰了,感觉有本质的区别,搜了一些资料,整理如下
计算机内部的几个部分图如下
缓存(cache)
https://baike.baidu.com/item/%E7%BC%93%E5%AD%98
提到缓存(cache),就想到了 cpu 高速缓存,其实最开始的缓存也是这个。
目的就是为了让 cpu 和内存之间的数据交互速度变快设计的。
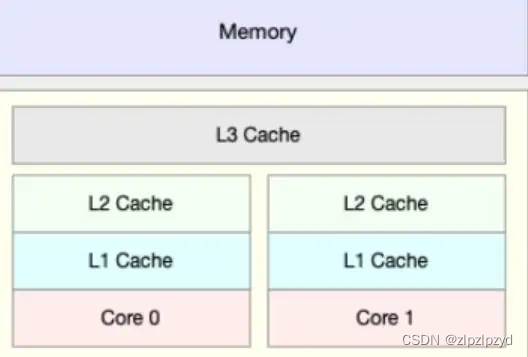
从下到上访问速度依次递减,容量也越来越大。内存的访问速度比 cpu 缓存访问速度慢 100倍。
https://www.zhihu.com/question/349982942/answer/2935754503
其他缓存
浏览器缓存
https://baike.baidu.com/item/%E6%B5%8F%E8%A7%88%E5%99%A8%E7%BC%93%E5%AD%98
之前的时代,网络不发达,带宽小,有了浏览器,打开一个网页需要每次加载页面需要的资源会时间长,后面浏览器的开发者就想到了重复的资源没必要重新加载,就考虑到浏览器缓存。
对于访问的资源如果每个请求后面都加了时间戳就没缓存了(缓存失效),相对于不加对于打开一个页面会发现明显变慢。
内存缓存 redis
对于数据库访问这块,为了减少数据库的访问次数,redis 的大神就想到了在内存中暂存这些数据。
因为内存通常来讲大一些,速度比硬盘快多了,所以在内存上暂存数据是一个不错的选择。
但是 redis 不是只有缓存功能,还有一些其他的功能。
缓冲(buffer)
为了提高内存和硬盘或其他io设备之间数据交换的速度设计的。在上面 cpu 缓存的基础上,硬盘比内存慢了几个数量级。
本质就是在内存上单独开辟了一个数组来存储当前的数据,将对磁盘的操作由随机操作变为顺序操作。由于磁盘的随机操作与顺序操作之间的数量级差距,在执行结果中会看到明显的差距。是用空间换时间的思想的实现。
压缩文件类似原理,将一个文件夹中的多个文件进行压缩,将多个小文件整理为一个文件,在磁盘上空间连续,在传输的过程中感觉快,如果是复制整个文件夹,会发现传输时间相对于压缩文件长,对于那些小文件数量多的情况下特别明显。
java 实现
如下 java.io 自带的原始的缓冲类
BufferedInputStream
package java.io;
public class BufferedInputStream extends FilterInputStream {
private static int DEFAULT_BUFFER_SIZE = 8192;
protected volatile byte buf[];
public BufferedInputStream(InputStream in) {
this(in, DEFAULT_BUFFER_SIZE);
}
}
BufferedOutputStream
package java.io;
public class BufferedOutputStream extends FilterOutputStream {
protected byte buf[];
public BufferedOutputStream(OutputStream out) {
this(out, 8192);
}
} BufferedReader
package java.io;
public class BufferedReader extends Reader {
private Reader in;
private char cb[];
private static int defaultCharBufferSize = 8192;
public BufferedReader(Reader in, int sz) {
super(in);
if (sz <= 0)
throw new IllegalArgumentException("Buffer size <= 0");
this.in = in;
cb = new char[sz];
nextChar = nChars = 0;
}
public BufferedReader(Reader in) {
this(in, defaultCharBufferSize);
}
}
BufferedWriter
package java.io;
public class BufferedWriter extends Writer {
private Writer out;
private static int defaultCharBufferSize = 8192;
public BufferedWriter(Writer out) {
this(out, defaultCharBufferSize);
}
}每个类中声明的缓冲数组在没有指定大小的情况下都是 8192,即 8MB。体现了预读的思想。
https://blog.csdn.net/qingfan_714/article/details/115439234
数据库中的 join buffer
mysql 中针对多表联合查询,在驱动表中会查询出符合要求的数据放在内存中与被驱动表进行嵌套查询。因为数据库的数据存储在磁盘上,由于存储设备与内存数据访问的速度差距,将数据放在内存中暂存是一个很好的选择,但是驱动表的数据需要做筛选,数据量不能多,遵循小表驱动大表原则。
总结
缓存和缓冲都是为了解决计算机的各个部分的访问速度设计的。
针对 cpu 和内存之间的速度慢的问题,设计了 cpu 与内存中间的三个级别的缓存。
针对内存与存储设备之间的速度慢的问题,编码在内存层面设计了缓冲区域将读取或者写入的数据批量处理。将存储设备的随机处理变为顺序处理,是空间换时间思想的实现。
在日常开发中,遇到的问题瓶颈一般是缓冲的问题。因为内存和 cpu 之间的缓存我们无法控制,但是在内存和硬盘层面的缓冲现有的工具无法满足我们可以自己编码处理。
参考链接
https://zhidao.baidu.com/question/7153396.html
https://blog.csdn.net/weixin_42559574/article/details/115290225
https://zhuanlan.zhihu.com/p/376380293
https://www.cnblogs.com/smalldong/p/14337528.html
https://baike.baidu.com/item/%E7%BC%93%E5%86%B2%E6%8A%80%E6%9C%AF/1937843
https://www.cnblogs.com/taking/p/15707375.html
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- initialDownlinkBWP-RedCap不包含pagingSearchSpace,Redcap ue应该怎么监听paging?
- 基于Python + Requests 的Web接口自动化测试框架
- docker 私有仓库
- 贪心算法总结
- 杰理AC63串口收发实例
- datax-自定义json遇到数据库字段名为关键字
- AI扩展手写数字识别应用(二)
- Netty入门基础知识
- 不断发展的识别技术为多个行业带来新机遇
- BasicTable 表格嵌套