kafka之集群工作机制理解
? ? ? ? 回想一下,我们搭建kafka集群是如何搭建?修改kafka得配置文件,多个Kafka服务注册到同一个zookeeper集群上的节点,会自动组成集群。
? ? ? ? 学习服务端原理,通常我们是去读服务端的那些抽象的代码,但是Kafka为了保证高吞吐,高性能,高可扩展的三高架构,很多具体设计都是相当复杂的。如果直接跳进去学习研究,估计我们很快就会晕头转向。那么有没有一些可见的东西让我们更具体的理解Kafka的Broker运行机制呢?
? ? ? ?kafka依赖于zookeeper,Kafka会将每个服务的不同之处,也就是状态信息,保存到Zookeeper中。通过Zookeeper中的数据,指导每个Kafka进行与其他Kafka节点不同的业务逻辑。而将状态信息抽离后,剩下的数据,就可以直接存在Kafka本地,所有Kafka服务都以相同的逻辑运行。这种状态信息分离的设计,让Kafka有非常好的集群扩展性。
zk中存的kafka的数据:

? ? ? ? 既然kafka依赖这么多的存储数据,那么我们就从可见的存储数据的角度来理解分析一下Kafka的Broker运行机制。
1. kafka在zookeeper中整体的数据
????????Kafka将状态信息保存在Zookeeper中,这些状态信息记录了每个Kafka的Broker服务与另外的Broker服务有什么不同。通过这些差异化的功能,共同体现出集群化的业务能力。这些数据,需要在集群中各个Broker之间达成共识,因此,需要存储在一个所有集群都能共同访问的第三方存储中。
????????这些共识数据需要保持强一致性,这样才能保证各个Broker的分工是同步、清晰的。而基于CP实现的Zookeeper就是最好的选择。另外,Zookeeper的Watcher机制也可以很好的减少Broker读取Zookeeper的次数。
????????Kafka在Zookeeper上管理了哪些数据呢?这个问题可以先回顾一下Kafka的整体集群状态结构,然后再去Zookeeper上验证。
????????? Kafka的整体集群结构如下图。其中红色字体标识出了重要的状态信息。
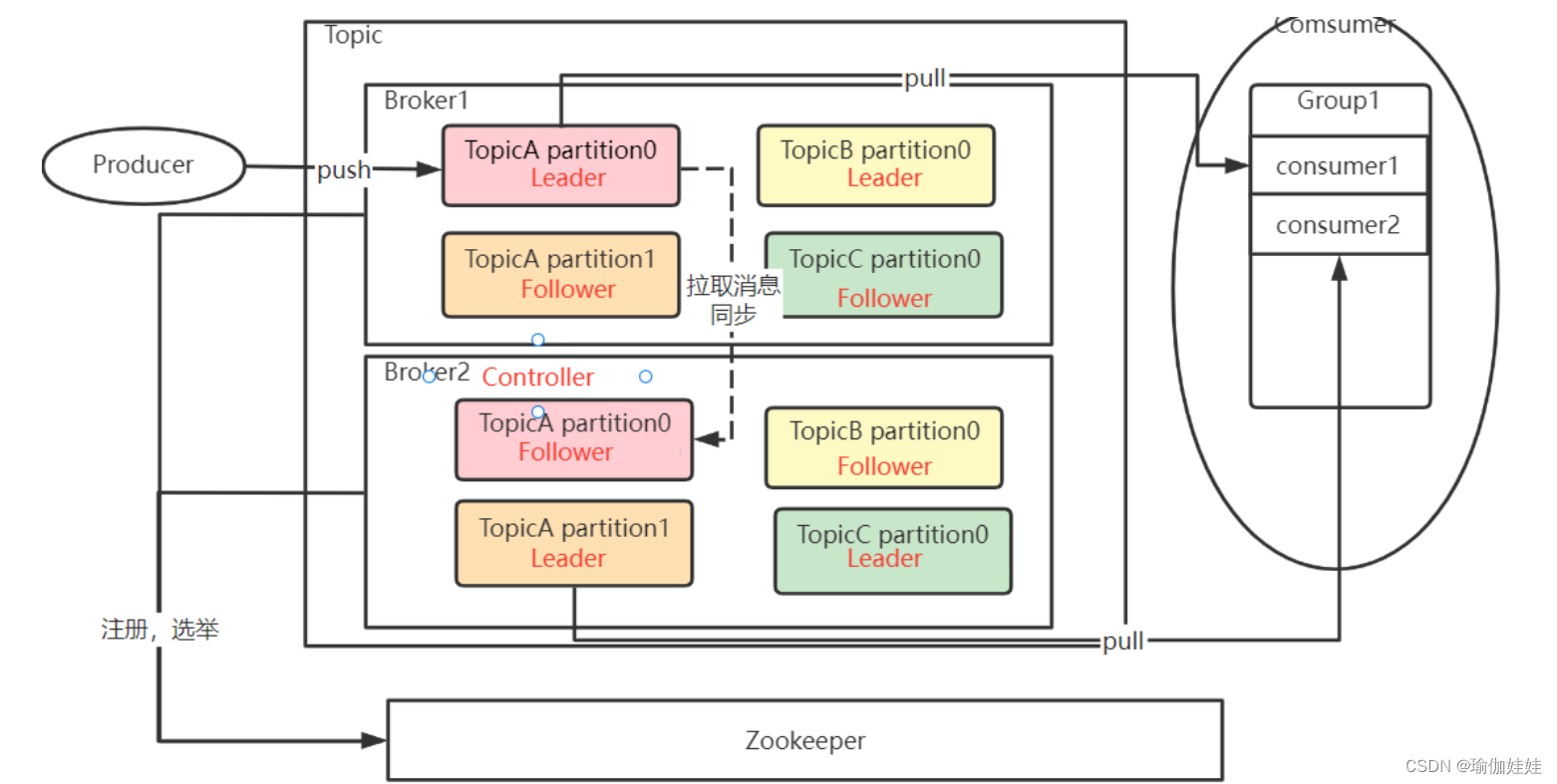
? Kafka的集群中,最为主要的状态信息有两个:
一个是在多个Broker中,需要选举出一个Broker,担任Controller角色。由Controller角色来管理整个集群中的分区和副本状态。
另一个是在同一个Topic下的多个Partition中,需要选举出一个Leader角色。由Leader角色的Partition来负责与客户端进行数据交互。
这些状态信息都被Kafka集群注册到了Zookeeper中。Zookeeper数据整体如下图:
 ?
?
? 对于Kafka往Zookeeper上注册的这些节点,大部分都是比较简明的。
比如/brokers/ids下,会记录集群中的所有BrokerId,

/topics目录下,会记录当前Kafka的Topic相关的Partition分区等信息。
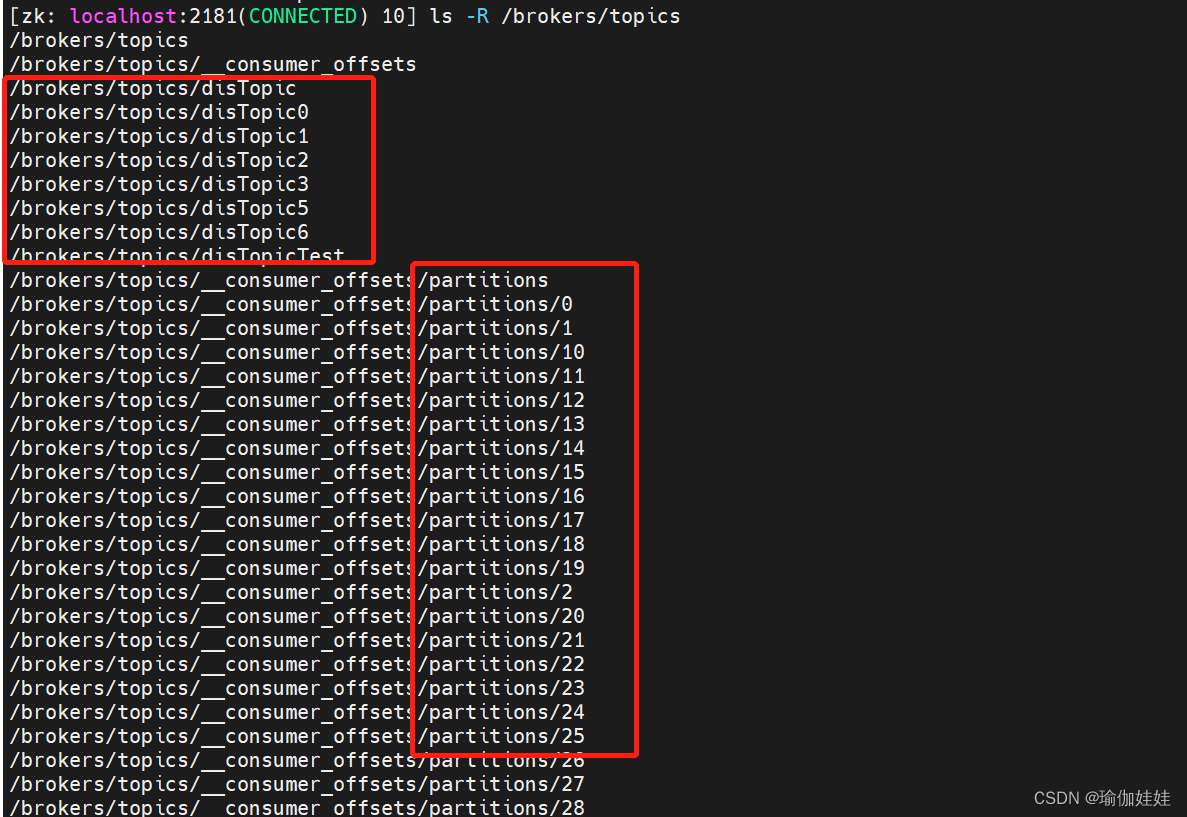
下面就从这些Zookeeper的基础数据开始,来逐步梳理Kafka的Broker端的重要流程?
为了方便我们看数据,后续主要用Zookeeper客户端工具: prettyZoo。来明了的看kafka存在zk上的数据结构。
2.?Controller Broker选举机制
3.?Leader Partition选举机制
4、Leader Partition自动平衡机制
5、Partition故障恢复机制
6、HW一致性保障-Epoch更新机制
内容更新中~
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 认定双软企业的好处有哪些?
- Docker安装【学习Docker(十)】Docker SQLServer的安装与卸载、基本命令
- Python之字符编码汇总
- 信通院联合发布《数字孪生城市白皮书 (2023年)》解析
- “二龙四虎”六所高校,电气工程及自动化毕业的,妥妥进国家电网
- 要编译Android 12系统的开机Logo,你需要执行以下步骤:
- 大数据相关软件的安装指南(超详细的图文教程)
- 《尚贤达猎头网站流量统计模块》,通过HTTP自定义模块实时获取asp.net网站访问流量,并保存到数据库
- odbc连接mysql数据库
- 基于ssm国学文化网站的设计与制作系统论文