写给不耐烦程序员的 JavaScript 指南(五)
第七部分:集合
原文:
exploringjs.com/impatient-js/pt_collections.html译者:飞龙
下一步:30?同步迭代
三十、同步迭代
原文:
exploringjs.com/impatient-js/ch_sync-iteration.html译者:飞龙
-
30.1 同步迭代是什么?
-
30.2 核心迭代构造:可迭代对象和迭代器
-
30.3 手动迭代
- 30.3.1 通过
while迭代可迭代对象
- 30.3.1 通过
-
30.4 实践中的迭代
-
30.4.1 遍历数组
-
30.4.2 遍历集合
-
-
30.5 同步迭代的快速参考
-
30.5.1 可迭代数据源
-
30.5.2 同步迭代语言构造
-
30.1 同步迭代是什么?
同步迭代是一种协议(接口加上使用规则),它连接 JavaScript 中的两组实体:
-
数据源: 一方面,数据以各种形状和大小出现。在 JavaScript 的标准库中,您有线性数据结构数组,有序集合 Set(元素按添加时间排序),有序字典 Map(条目按添加时间排序)等。在库中,您可能会找到树形数据结构等。
-
数据消费者: 另一方面,您有一整类构造和算法,它们只需要顺序访问它们的输入:一次一个值,直到所有值都被访问。例如,
for-of循环和展开到函数调用(通过...)。
迭代协议通过接口Iterable连接这两组:数据源通过它顺序地“传递其内容”;数据消费者通过它获取其输入。

图 18:数据消费者如for-of循环使用接口Iterable。数据源如Arrays实现该接口。
图 18 展示了迭代的工作原理:数据消费者使用接口Iterable;数据源实现它。
 实现接口的 JavaScript 方式
实现接口的 JavaScript 方式
在 JavaScript 中,如果一个对象具有描述的所有方法,它就会实现一个接口。本章提到的接口只存在于 ECMAScript 规范中。
数据的来源和消费者都从这种安排中受益:
-
如果您开发了一个新的数据结构,您只需要实现
Iterable,就可以立即应用一系列工具。 -
如果您编写使用迭代的代码,它将自动适用于许多数据源。
30.2 核心迭代构造:可迭代对象和迭代器
两个角色(由接口描述)构成了迭代的核心(图 19):
-
可迭代对象是其内容可以按顺序遍历的对象。
-
迭代器是用于遍历的指针。

图 19:迭代有两个主要接口:Iterable和Iterator。前者有一个返回后者的方法。
这些是迭代协议接口的类型定义(在 TypeScript 的表示法中):
interface Iterable<T> {
[Symbol.iterator]() : Iterator<T>;
}
interface Iterator<T> {
next() : IteratorResult<T>;
}
interface IteratorResult<T> {
value: T;
done: boolean;
}
这些接口的使用如下:
-
您可以通过其键为
Symbol.iterator的方法向Iterable请求迭代器。 -
Iterator通过其方法.next()返回迭代的值。 -
值不是直接返回的,而是包装在具有两个属性的对象中:
-
.value是迭代的值。 -
.done指示是否已经到达迭代的末尾。在最后一个迭代值之后为true,之前为false。
-
30.3?手动迭代
这是使用迭代协议的示例:
const iterable = ['a', 'b'];
// The iterable is a factory for iterators:
const iterator = iterable[Symbol.iterator]();
// Call .next() until .done is true:
assert.deepEqual(
iterator.next(), { value: 'a', done: false });
assert.deepEqual(
iterator.next(), { value: 'b', done: false });
assert.deepEqual(
iterator.next(), { value: undefined, done: true });
30.3.1?通过while迭代可迭代对象
以下代码演示了如何使用while循环来迭代可迭代对象:
function logAll(iterable) {
const iterator = iterable[Symbol.iterator]();
while (true) {
const {value, done} = iterator.next();
if (done) break;
console.log(value);
}
}
logAll(['a', 'b']);
// Output:
// 'a'
// 'b'
 练习:手动使用同步迭代
练习:手动使用同步迭代
exercises/sync-iteration-use/sync_iteration_manually_exrc.mjs
30.4?实践中的迭代
我们已经看到了如何手动使用迭代协议,这相对来说比较麻烦。但是协议并不是直接使用的 - 它是通过在其之上构建的高级语言构造来使用的。本节展示了这是什么样子。
30.4.1?遍历数组
JavaScript 的数组是可迭代的。这使我们能够使用for-of循环:
const myArray = ['a', 'b', 'c'];
for (const x of myArray) {
console.log(x);
}
// Output:
// 'a'
// 'b'
// 'c'
通过数组模式解构(稍后解释)也在内部使用迭代:
const [first, second] = myArray;
assert.equal(first, 'a');
assert.equal(second, 'b');
30.4.2?遍历集合
JavaScript 的 Set 数据结构是可迭代的。这意味着for-of可以工作:
const mySet = new Set().add('a').add('b').add('c');
for (const x of mySet) {
console.log(x);
}
// Output:
// 'a'
// 'b'
// 'c'
数组解构也是如此:
const [first, second] = mySet;
assert.equal(first, 'a');
assert.equal(second, 'b');
30.5?快速参考:同步迭代
30.5.1?可迭代数据源
以下内置数据源是可迭代的:
-
数组
-
字符串
-
地图
-
集合
-
(浏览器:DOM 数据结构)
迭代对象的属性时,您需要诸如Object.keys()和Object.entries()之类的辅助工具。这是必要的,因为属性存在于与数据结构级别无关的不同级别。
30.5.2?同步迭代语言构造
本节列出了使用同步迭代的构造。
30.5.2.1?迭代的语言构造
-
通过数组模式解构:
const [x,y] = iterable; -
通过
...扩展到函数调用和数组文字中:func(...iterable); const arr = [...iterable]; -
for-of循环:for (const x of iterable) { /*···*/ } -
yield*:function* generatorFunction() { yield* iterable; }
30.5.2.2?将可迭代对象转换为数据结构
-
Object.fromEntries():const obj = Object.fromEntries(iterableOverKeyValuePairs); -
Array.from():const arr = Array.from(iterable); -
new Map()和new WeakMap():const m = new Map(iterableOverKeyValuePairs); const wm = new WeakMap(iterableOverKeyValuePairs); -
new Set()和new WeakSet():const s = new Set(iterableOverElements); const ws = new WeakSet(iterableOverElements);
30.5.2.3?杂项
-
Promise 组合函数:
Promise.all()等。const promise1 = Promise.all(iterableOverPromises); const promise2 = Promise.race(iterableOverPromises); const promise3 = Promise.any(iterableOverPromises); const promise4 = Promise.allSettled(iterableOverPromises);
 测验
测验
查看测验应用程序。
三十一、数组 (Array)
原文:
exploringjs.com/impatient-js/ch_arrays.html译者:飞龙
-
31.1 速查表:数组
-
31.1.1 使用数组
-
31.1.2 数组方法
-
-
31.2 JavaScript 中使用数组的两种方式
-
31.3 基本数组操作
-
31.3.1 创建、读取、写入数组
-
31.3.2 数组的
.length -
31.3.3 通过负索引引用元素
-
31.3.4 清除数组
-
31.3.5 扩展到数组文字[ES6]
-
31.3.6 数组:列出索引和条目[ES6]
-
31.3.7 一个值是数组吗?
-
-
31.4
for-of和数组[ES6]-
31.4.1
for-of:遍历元素 -
31.4.2
for-of:遍历索引 -
31.4.3
for-of:遍历[index, element]对
-
-
31.5 类数组对象
-
31.6 将可迭代对象和类数组值转换为数组
-
31.6.1 通过扩展(
...)将可迭代对象转换为数组 -
31.6.2 通过
Array.from()将可迭代对象和类数组对象转换为数组
-
-
31.7 创建和填充任意长度的数组
-
31.7.1 我们需要创建一个空数组,然后稍后完全填充吗?
-
31.7.2 我们需要创建一个填充有原始值的数组吗?
-
31.7.3 我们需要创建一个填充有对象的数组吗?
-
31.7.4 我们需要创建一个整数范围吗?
-
31.7.5 如果元素都是整数或浮点数,则使用 Typed Array
-
-
31.8 多维数组
-
31.9 更多数组特性(高级)
-
31.9.1 数组索引是(稍微特殊的)属性键
-
31.9.2 数组是字典,可以有空隙
-
-
31.10 添加和移除元素(破坏性和非破坏性)
-
31.10.1 在元素和数组之前添加元素
-
31.10.2 追加元素和数组
-
31.10.3 移除元素
-
-
31.11 方法:迭代和转换(
.find(),.map(),.filter()等)-
31.11.1 迭代和转换方法的回调
-
31.11.2 搜索元素:
.find(),.findIndex() -
31.11.3
.map(): 复制并给元素赋予新值 -
31.11.4
.flatMap(): 映射到零个或多个值 -
31.11.5
.filter(): 仅保留一些元素 -
31.11.6
.reduce(): 从数组中派生值(高级)
-
-
31.12
.sort(): 排序数组-
31.12.1 自定义排序顺序
-
31.12.2 排序数字
-
31.12.3 排序对象
-
-
31.13 快速参考:
Array-
31.13.1
new Array() -
31.13.2
Array的静态方法 -
31.13.3
Array.prototype的方法 -
31.13.4 来源
-
31.1 数组速查表
JavaScript 数组是一种非常灵活的数据结构,用作列表、堆栈、队列、元组(例如对)等。
一些与数组相关的操作会破坏性地改变数组。其他操作会非破坏性地产生对原始内容副本应用了更改的新数组。
31.1.1 使用数组
创建数组,读取和写入元素:
// Creating an Array
const arr = ['a', 'b', 'c']; // Array literal
assert.deepEqual(
arr,
[ // Array literal
'a',
'b',
'c', // trailing commas are ignored
]
);
// Reading elements
assert.equal(
arr[0], 'a' // negative indices don’t work
);
assert.equal(
arr.at(-1), 'c' // negative indices work
);
// Writing an element
arr[0] = 'x';
assert.deepEqual(
arr, ['x', 'b', 'c']
);
数组的长度:
const arr = ['a', 'b', 'c'];
assert.equal(
arr.length, 3 // number of elements
);
arr.length = 1; // removing elements
assert.deepEqual(
arr, ['a']
);
arr[arr.length] = 'b'; // adding an element
assert.deepEqual(
arr, ['a', 'b']
);
通过.push()破坏性地添加元素:
const arr = ['a', 'b'];
arr.push('c'); // adding an element
assert.deepEqual(
arr, ['a', 'b', 'c']
);
// Pushing Arrays (used as arguments via spreading (...)):
arr.push(...['d', 'e']);
assert.deepEqual(
arr, ['a', 'b', 'c', 'd', 'e']
);
通过扩展(...)非破坏性地添加元素:
const arr1 = ['a', 'b'];
const arr2 = ['c'];
assert.deepEqual(
[...arr1, ...arr2, 'd', 'e'],
['a', 'b', 'c', 'd', 'e']
);
清除数组(删除所有元素):
// Destructive – affects everyone referring to the Array:
const arr1 = ['a', 'b', 'c'];
arr1.length = 0;
assert.deepEqual(
arr1, []
);
// Non-destructive – does not affect others referring to the Array:
let arr2 = ['a', 'b', 'c'];
arr2 = [];
assert.deepEqual(
arr2, []
);
循环遍历元素:
const arr = ['a', 'b', 'c'];
for (const value of arr) {
console.log(value);
}
// Output:
// 'a'
// 'b'
// 'c'
循环遍历索引-值对:
const arr = ['a', 'b', 'c'];
for (const [index, value] of arr.entries()) {
console.log(index, value);
}
// Output:
// 0, 'a'
// 1, 'b'
// 2, 'c'
在无法使用数组文字(例如因为我们事先不知道它们的长度或者它们太大)时创建和填充数组:
const four = 4;
// Empty Array that we’ll fill later
assert.deepEqual(
new Array(four),
[ , , , ,] // four holes; last comma is ignored
);
// An Array filled with a primitive value
assert.deepEqual(
new Array(four).fill(0),
[0, 0, 0, 0]
);
// An Array filled with objects
// Why not .fill()? We’d get single object, shared multiple times.
assert.deepEqual(
Array.from({length: four}, () => ({})),
[{}, {}, {}, {}]
);
// A range of integers
assert.deepEqual(
Array.from({length: four}, (_, i) => i),
[0, 1, 2, 3]
);
31.1.2 数组方法
本节简要概述了数组 API。本章末尾有更全面的快速参考。
从现有数组派生新数组:
> ['■','●','▲'].slice(1, 3)
['●','▲']
> ['■','●','■'].filter(x => x==='■')
['■','■']
> ['▲','●'].map(x => x+x)
['▲▲','●●']
> ['▲','●'].flatMap(x => [x,x])
['▲','▲','●','●']
在给定索引处删除数组元素:
// .filter(): remove non-destructively
const arr1 = ['■','●','▲'];
assert.deepEqual(
arr1.filter((_, index) => index !== 1),
['■','▲']
);
assert.deepEqual(
arr1, ['■','●','▲'] // unchanged
);
// .splice(): remove destructively
const arr2 = ['■','●','▲'];
arr2.splice(1, 1); // start at 1, delete 1 element
assert.deepEqual(
arr2, ['■','▲'] // changed
);
计算数组的摘要:
> ['■','●','▲'].some(x => x==='●')
true
> ['■','●','▲'].every(x => x==='●')
false
> ['■','●','▲'].join('-')
'■-●-▲'
> ['■','▲'].reduce((result,x) => result+x, '●')
'●■▲'
> ['■','▲'].reduceRight((result,x) => result+x, '●')
'●▲■'
反转和填充:
// .reverse() changes and returns `arr`
const arr = ['■','●','▲'];
assert.deepEqual(
arr.reverse(), arr
);
// `arr` was changed:
assert.deepEqual(
arr, ['▲','●','■']
);
// .fill() works the same way:
assert.deepEqual(
['■','●','▲'].fill('●'),
['●','●','●']
);
.sort()也修改数组并返回它:
// By default, string representations of the Array elements
// are sorted lexicographically:
assert.deepEqual(
[200, 3, 10].sort(),
[10, 200, 3]
);
// Sorting can be customized via a callback:
assert.deepEqual(
[200, 3, 10].sort((a,b) => a - b), // sort numerically
[ 3, 10, 200 ]
);
查找数组元素:
> ['■','●','■'].includes('■')
true
> ['■','●','■'].indexOf('■')
0
> ['■','●','■'].lastIndexOf('■')
2
> ['■','●','■'].find(x => x==='■')
'■'
> ['■','●','■'].findIndex(x => x==='■')
0
在开头或结尾添加或删除元素:
// Adding and removing at the start
const arr1 = ['■','●'];
arr1.unshift('▲');
assert.deepEqual(
arr1, ['▲','■','●']
);
arr1.shift();
assert.deepEqual(
arr1, ['■','●']
);
// Adding and removing at the end
const arr2 = ['■','●'];
arr2.push('▲');
assert.deepEqual(
arr2, ['■','●','▲']
);
arr2.pop();
assert.deepEqual(
arr2, ['■','●']
);
31.2 在 JavaScript 中使用数组的两种方式
在 JavaScript 中有两种使用数组的方式:
-
固定布局数组:以这种方式使用,数组具有固定数量的索引元素。每个元素可以具有不同的类型。
-
序列数组:以这种方式使用,数组具有可变数量的索引元素。每个元素具有相同的类型。
实际上,这两种方式经常混合使用。
值得注意的是,序列数组非常灵活,我们可以将它们用作(传统的)数组、堆栈和队列。稍后我们会看到。
31.3 基本数组操作
31.3.1 创建、读取、写入数组
创建数组的最佳方式是通过数组文字:
const arr = ['a', 'b', 'c'];
数组文字以方括号[]开始和结束。它创建一个包含三个元素:‘a’,'b’和’c’的数组。
数组文字中允许并忽略尾随逗号:
const arr = [
'a',
'b',
'c',
];
要读取数组元素,我们将索引放在方括号中(索引从零开始):
const arr = ['a', 'b', 'c'];
assert.equal(arr[0], 'a');
要更改数组元素,我们将索引分配给数组:
const arr = ['a', 'b', 'c'];
arr[0] = 'x';
assert.deepEqual(arr, ['x', 'b', 'c']);
数组索引的范围为 32 位(不包括最大长度):[0, 232?1]
31.3.2 数组的.length
每个数组都有一个属性.length,可用于读取和更改(!)数组中的元素数量。
数组的长度始终是最高索引加一:
> const arr = ['a', 'b'];
> arr.length
2
如果我们在长度的索引处写入数组,我们将添加一个元素:
> arr[arr.length] = 'c';
> arr
[ 'a', 'b', 'c' ]
> arr.length
3
另一种(破坏性地)附加元素的方法是通过数组方法.push():
> arr.push('d');
> arr
[ 'a', 'b', 'c', 'd' ]
如果我们设置.length,我们正在修剪数组,删除元素:
> arr.length = 1;
> arr
[ 'a' ]
 练习:通过
练习:通过.push()删除空行
exercises/arrays/remove_empty_lines_push_test.mjs
31.3.3 通过负索引引用元素
几种数组方法支持负索引。如果索引为负数,则将其添加到数组的长度以产生可用索引。因此,.slice()的以下两个调用是等效的:它们都从最后一个元素开始复制arr。
> const arr = ['a', 'b', 'c'];
> arr.slice(-1)
[ 'c' ]
> arr.slice(arr.length - 1)
[ 'c' ]
31.3.3.1 .at(): 读取单个元素(支持负索引)[ES2022]
数组方法.at()返回给定索引处的元素。它支持正数和负数索引(-1指最后一个元素,-2指倒数第二个元素等):
> ['a', 'b', 'c'].at(0)
'a'
> ['a', 'b', 'c'].at(-1)
'c'
相比之下,方括号运算符[]不支持负索引(并且不能更改,因为那样会破坏现有的代码)。它将它们解释为非元素属性的键:
const arr = ['a', 'b', 'c'];
arr[-1] = 'non-element property';
// The Array elements didn’t change:
assert.deepEqual(
Array.from(arr), // copy just the Array elements
['a', 'b', 'c']
);
assert.equal(
arr[-1], 'non-element property'
);
31.3.4 清除数组
清除(清空)一个数组,我们可以将其.length设置为零:
const arr = ['a', 'b', 'c'];
arr.length = 0;
assert.deepEqual(arr, []);
或者我们可以将一个新的空数组赋给存储数组的变量:
let arr = ['a', 'b', 'c'];
arr = [];
assert.deepEqual(arr, []);
后一种方法的优点是不会影响指向相同数组的其他位置。但是,如果我们确实想要为所有人重置共享的数组,那么我们需要前一种方法。
31.3.5 扩展到数组文字[ES6]
在数组文字中,扩展元素由三个点(...)后跟一个表达式组成。它导致表达式被评估然后被迭代。每个迭代的值都成为额外的数组元素 - 例如:
> const iterable = ['b', 'c'];
> ['a', ...iterable, 'd']
[ 'a', 'b', 'c', 'd' ]
这意味着我们可以使用扩展来创建数组的副本并将可迭代对象转换为数组:
const original = ['a', 'b', 'c'];
const copy = [...original];
const iterable = original.keys();
assert.deepEqual(
[...iterable], [0, 1, 2]
);
然而,对于前面的两种用例,我发现Array.from()更具有自我描述性,并更喜欢它:
const copy2 = Array.from(original);
assert.deepEqual(
Array.from(original.keys()), [0, 1, 2]
);
扩展也方便将数组(和其他可迭代对象)连接到数组中:
const arr1 = ['a', 'b'];
const arr2 = ['c', 'd'];
const concatenated = [...arr1, ...arr2, 'e'];
assert.deepEqual(
concatenated,
['a', 'b', 'c', 'd', 'e']);
由于扩展使用迭代,只有当值可迭代时才有效:
> [...'abc'] // strings are iterable
[ 'a', 'b', 'c' ]
> [...123]
TypeError: 123 is not iterable
> [...undefined]
TypeError: undefined is not iterable
 扩展和
扩展和Array.from()产生浅层副本
通过扩展或通过Array.from()复制数组是浅层的:我们在新数组中获得新条目,但值与原始数组共享。浅层复制的后果在§28.4“扩展到对象字面量(...)[ES2018]”中得到了证明。
31.3.6 数组:列出索引和条目[ES6]
方法.keys()列出数组的索引:
const arr = ['a', 'b'];
assert.deepEqual(
Array.from(arr.keys()), // (A)
[0, 1]);
.keys()返回一个可迭代对象。在 A 行,我们将该可迭代对象转换为数组。
列出数组索引与列出属性不同。前者产生数字;后者产生字符串化的数字(除了非索引属性键):
const arr = ['a', 'b'];
arr.prop = true;
assert.deepEqual(
Object.keys(arr),
['0', '1', 'prop']);
方法.entries()列出数组的内容为[索引,元素]对:
const arr = ['a', 'b'];
assert.deepEqual(
Array.from(arr.entries()),
[[0, 'a'], [1, 'b']]);
31.3.7 是否值为数组?
以下是检查值是否为数组的两种方法:
> [] instanceof Array
true
> Array.isArray([])
true
instanceof通常很好。如果值可能来自另一个领域,我们需要Array.isArray()。粗略地说,领域是 JavaScript 全局范围的一个实例。一些领域彼此隔离(例如,浏览器中的 Web Workers),但也有一些领域之间可以移动数据 - 例如,浏览器中的同源 iframe。x instanceof Array检查x的原型链,因此如果x是来自另一个领域的数组,则返回false。
typeof将数组归类为对象:
> typeof []
'object'
31.4 for-of和数组[ES6]
我们已经在本书的早期遇到了for-of循环。本节简要回顾了如何在数组中使用它。
31.4.1 for-of:遍历元素
以下for-of循环遍历数组的元素:
for (const element of ['a', 'b']) {
console.log(element);
}
// Output:
// 'a'
// 'b'
31.4.2 for-of:遍历索引
这个for-of循环遍历数组的索引:
for (const element of ['a', 'b'].keys()) {
console.log(element);
}
// Output:
// 0
// 1
31.4.3 for-of:遍历[索引,元素]对
以下for-of循环遐射[索引,元素]对。解构(稍后描述)为我们提供了在for-of头部设置index和element的便捷语法。
for (const [index, element] of ['a', 'b'].entries()) {
console.log(index, element);
}
// Output:
// 0, 'a'
// 1, 'b'
31.5 类似数组的对象
一些适用于数组的操作仅需要最低限度:值必须只是类似数组。类似数组的值是具有以下属性的对象:
-
.length:保存类似数组对象的长度。 -
[0]:保存索引 0 处的元素(等等)。请注意,如果我们使用数字作为属性名称,它们总是被强制转换为字符串。因此,[0]检索其键为'0'的属性的值。
例如,Array.from()接受类数组对象并将其转换为数组:
// If we omit .length, it is interpreted as 0
assert.deepEqual(
Array.from({}),
[]);
assert.deepEqual(
Array.from({length:2, 0:'a', 1:'b'}),
[ 'a', 'b' ]);
Array-like 对象的 TypeScript 接口是:
interface ArrayLike<T> {
length: number;
[n: number]: T;
}
{kind=link}
在 ES6 之前,类数组对象很常见;现在我们很少见到它们。
31.6?将可迭代对象和类数组值转换为数组
将可迭代对象和类数组值转换为数组有两种常见的方法:
-
扩展为数组
-
Array.from()
我更喜欢后者-我觉得它更加自解释。
31.6.1?通过扩展(...)将可迭代对象转换为数组
在数组字面量内,通过...扩展将任何可迭代对象转换为一系列数组元素。例如:
// Get an Array-like collection from a web browser’s DOM
const domCollection = document.querySelectorAll('a');
// Alas, the collection is missing many Array methods
assert.equal('map' in domCollection, false);
// Solution: convert it to an Array
const arr = [...domCollection];
assert.deepEqual(
arr.map(x => x.href),
['https://2ality.com', 'https://exploringjs.com']);
转换起作用是因为 DOM 集合是可迭代的。
31.6.2?通过Array.from()将可迭代对象和类数组对象转换为数组
Array.from()可以以两种模式使用。
31.6.2.1?Array.from()的模式 1:转换
第一种模式具有以下类型签名:
.from<T>(iterable: Iterable<T> | ArrayLike<T>): T[]
Iterable接口显示在同步迭代章节。ArrayLike接口出现在本章前面。
使用单个参数,Array.from()将任何可迭代对象或类数组转换为数组:
> Array.from(new Set(['a', 'b']))
[ 'a', 'b' ]
> Array.from({length: 2, 0:'a', 1:'b'})
[ 'a', 'b' ]
31.6.2.2?Array.from()的模式 2:转换和映射
Array.from()的第二种模式涉及两个参数:
.from<T, U>(
iterable: Iterable<T> | ArrayLike<T>,
mapFunc: (v: T, i: number) => U,
thisArg?: any)
: U[]
在这种模式下,Array.from()做了几件事:
-
它遍历
iterable。 -
它调用
mapFunc与每个迭代的值。可选参数thisArg指定了mapFunc的this。 -
它将
mapFunc应用于每个迭代的值。 -
它将结果收集到一个新数组中并返回它。
换句话说:我们从类型为T的可迭代元素转换为类型为U的数组。
这是一个例子:
> Array.from(new Set(['a', 'b']), x => x + x)
[ 'aa', 'bb' ]
31.7?创建和填充任意长度的数组
创建数组的最佳方式是通过数组字面量。但是,我们并不总是能够使用数组字面量:数组可能太大,我们可能在开发过程中不知道其长度,或者我们可能希望保持其长度的灵活性。那么我推荐以下技术来创建和可能填充数组。
31.7.1?我们需要创建一个稍后完全填充的空数组吗?
> new Array(3)
[ , , ,]
请注意,结果有三个holes(空槽) - 数组字面量中的最后一个逗号总是被忽略。
31.7.2?我们需要创建一个填充有原始值的数组吗?
> new Array(3).fill(0)
[0, 0, 0]
注意:如果我们使用.fill()与一个对象,那么每个数组元素将引用此对象(共享它)。
const arr = new Array(3).fill({});
arr[0].prop = true;
assert.deepEqual(
arr, [
{prop: true},
{prop: true},
{prop: true},
]);
下一小节将解释如何修复这个问题。
31.7.3?我们需要创建一个填充有对象的数组吗?
> new Array(3).fill(0)
[0, 0, 0]
对于大尺寸,临时数组可能会消耗大量内存。以下方法没有这个缺点,但是不够自描述:
> Array.from({length: 3}, () => ({}))
[{}, {}, {}]
我们使用临时的类数组对象而不是临时数组。
31.7.4?我们需要创建一个整数范围吗?
function createRange(start, end) {
return Array.from({length: end-start}, (_, i) => i+start);
}
assert.deepEqual(
createRange(2, 5),
[2, 3, 4]);
这是一个替代的、稍微巧妙的创建以零开头的整数范围的技术:
/** Returns an iterable */
function createRange(end) {
return new Array(end).keys();
}
assert.deepEqual(
Array.from(createRange(4)),
[0, 1, 2, 3]);
这是因为.keys()将holes视为undefined元素并列出它们的索引。
31.7.5?如果元素都是整数或浮点数,使用 Typed Array
在处理整数或浮点数数组时,我们应该考虑Typed Arrays,这是为此目的而创建的。
31.8?多维数组
JavaScript 没有真正的多维数组;我们需要求助于其元素为数组的数组:
function initMultiArray(...dimensions) {
function initMultiArrayRec(dimIndex) {
if (dimIndex >= dimensions.length) {
return 0;
} else {
const dim = dimensions[dimIndex];
const arr = [];
for (let i=0; i<dim; i++) {
arr.push(initMultiArrayRec(dimIndex+1));
}
return arr;
}
}
return initMultiArrayRec(0);
}
const arr = initMultiArray(4, 3, 2);
arr[3][2][1] = 'X'; // last in each dimension
assert.deepEqual(arr, [
[ [ 0, 0 ], [ 0, 0 ], [ 0, 0 ] ],
[ [ 0, 0 ], [ 0, 0 ], [ 0, 0 ] ],
[ [ 0, 0 ], [ 0, 0 ], [ 0, 0 ] ],
[ [ 0, 0 ], [ 0, 0 ], [ 0, 'X' ] ],
]);
31.9?更多数组特性(高级)
在本节中,我们将研究在使用数组时不经常遇到的现象。
31.9.1?数组索引是(稍微特殊的)属性键
你可能会认为数组元素很特殊,因为我们是通过数字访问它们的。但是用于这样做的方括号运算符[]与用于访问属性的运算符相同。它将任何值(不是符号)强制转换为字符串。因此,数组元素(几乎)是正常属性(A 行),并且使用数字或字符串作为索引并不重要(B 和 C 行):
const arr = ['a', 'b'];
arr.prop = 123;
assert.deepEqual(
Object.keys(arr),
['0', '1', 'prop']); // (A)
assert.equal(arr[0], 'a'); // (B)
assert.equal(arr['0'], 'a'); // (C)
更让事情变得更加混乱的是,这只是语言规范定义事物的方式(如果你愿意的话,这是 JavaScript 的理论)。大多数 JavaScript 引擎在幕后进行优化,并确实使用实际的整数来访问数组元素(如果你愿意的话,这是 JavaScript 的实践)。
用于数组元素的属性键(字符串!)称为索引。如果将字符串str转换为 32 位无符号整数,然后再转换回原始值,则该字符串是一个索引。写成一个公式:
ToString(ToUint32(str)) === str
31.9.1.1?列出索引
在列出属性键时,索引被特殊对待 – 它们总是首先出现,并且像数字一样排序('2'出现在'10'之前):
const arr = [];
arr.prop = true;
arr[1] = 'b';
arr[0] = 'a';
assert.deepEqual(
Object.keys(arr),
['0', '1', 'prop']);
请注意,.length,.entries()和.keys()将数组索引视为数字,并忽略非索引属性:
assert.equal(arr.length, 2);
assert.deepEqual(
Array.from(arr.keys()), [0, 1]);
assert.deepEqual(
Array.from(arr.entries()), [[0, 'a'], [1, 'b']]);
我们使用Array.from()将.keys()和.entries()返回的可迭代对象转换为数组。
31.9.2?数组是字典,可以有空洞
我们在 JavaScript 中区分两种数组:
-
如果所有索引
i,其中 0 ≤i<arr.length,都存在,则数组arr是密集的。也就是说,索引形成一个连续的范围。 -
如果索引范围中有空洞,则数组是稀疏的。也就是说,一些索引是缺失的。
JavaScript 中的数组可以是稀疏的,因为数组实际上是从索引到值的字典。
推荐:避免空洞
到目前为止,我们只看到了密集的数组,确实建议避免空洞:它们使我们的代码更加复杂,并且数组方法处理不一致。此外,JavaScript 引擎优化了密集数组,使它们更快。
31.9.2.1?创建空洞
当分配元素时,我们可以通过跳过索引来创建空洞:
const arr = [];
arr[0] = 'a';
arr[2] = 'c';
assert.deepEqual(Object.keys(arr), ['0', '2']); // (A)
assert.equal(0 in arr, true); // element
assert.equal(1 in arr, false); // hole
在 A 行,我们使用Object.keys(),因为arr.keys()将空洞视为undefined元素,并且不会显示它们。
创建空洞的另一种方法是跳过数组文字中的元素:
const arr = ['a', , 'c'];
assert.deepEqual(Object.keys(arr), ['0', '2']);
我们也可以删除数组元素:
const arr = ['a', 'b', 'c'];
assert.deepEqual(Object.keys(arr), ['0', '1', '2']);
delete arr[1];
assert.deepEqual(Object.keys(arr), ['0', '2']);
31.9.2.2?数组操作如何处理空洞?
遗憾的是,数组操作处理空洞的方式有很多不同。
一些数组操作会删除空洞:
> ['a',,'b'].filter(x => true)
[ 'a', 'b' ]
一些数组操作会忽略空洞:
> ['a', ,'a'].every(x => x === 'a')
true
一些数组操作会忽略但保留空洞:
> ['a',,'b'].map(x => 'c')
[ 'c', , 'c' ]
一些数组操作将空洞视为undefined元素:
> Array.from(['a',,'b'], x => x)
[ 'a', undefined, 'b' ]
> Array.from(['a',,'b'].entries())
[[0, 'a'], [1, undefined], [2, 'b']]
Object.keys()的工作方式与.keys()不同(字符串 vs. 数字,空洞没有键):
> Array.from(['a',,'b'].keys())
[ 0, 1, 2 ]
> Object.keys(['a',,'b'])
[ '0', '2' ]
这里没有规则需要记住。如果数组操作如何处理空洞很重要,最好的方法是在控制台中进行快速测试。
31.10?添加和删除元素(破坏性和非破坏性)
JavaScript 的Array非常灵活,更像是数组、堆栈和队列的组合。本节探讨了添加和删除数组元素的方法。大多数操作都可以进行破坏性(修改数组)和非破坏性(生成修改后的副本)。
31.10.1?前置元素和数组
在下面的代码中,我们破坏性地将单个元素前置到arr1,并将数组前置到arr2:
const arr1 = ['a', 'b'];
arr1.unshift('x', 'y'); // prepend single elements
assert.deepEqual(arr1, ['x', 'y', 'a', 'b']);
const arr2 = ['a', 'b'];
arr2.unshift(...['x', 'y']); // prepend Array
assert.deepEqual(arr2, ['x', 'y', 'a', 'b']);
扩展让我们将一个数组推入arr2。
通过扩展元素进行非破坏性的前置:
const arr1 = ['a', 'b'];
assert.deepEqual(
['x', 'y', ...arr1], // prepend single elements
['x', 'y', 'a', 'b']);
assert.deepEqual(arr1, ['a', 'b']); // unchanged!
const arr2 = ['a', 'b'];
assert.deepEqual(
[...['x', 'y'], ...arr2], // prepend Array
['x', 'y', 'a', 'b']);
assert.deepEqual(arr2, ['a', 'b']); // unchanged!
31.10.2?附加元素和数组
在下面的代码中,我们破坏性地将单个元素附加到arr1,并将数组附加到arr2:
const arr1 = ['a', 'b'];
arr1.push('x', 'y'); // append single elements
assert.deepEqual(arr1, ['a', 'b', 'x', 'y']);
const arr2 = ['a', 'b'];
arr2.push(...['x', 'y']); // (A) append Array
assert.deepEqual(arr2, ['a', 'b', 'x', 'y']);
扩展(...)让我们将一个数组推入arr2(A 行)。
通过扩展元素进行非破坏性的附加:
const arr1 = ['a', 'b'];
assert.deepEqual(
[...arr1, 'x', 'y'], // append single elements
['a', 'b', 'x', 'y']);
assert.deepEqual(arr1, ['a', 'b']); // unchanged!
const arr2 = ['a', 'b'];
assert.deepEqual(
[...arr2, ...['x', 'y']], // append Array
['a', 'b', 'x', 'y']);
assert.deepEqual(arr2, ['a', 'b']); // unchanged!
31.10.3?删除元素
这些是移除数组元素的三种破坏性方式:
// Destructively remove first element:
const arr1 = ['a', 'b', 'c'];
assert.equal(arr1.shift(), 'a');
assert.deepEqual(arr1, ['b', 'c']);
// Destructively remove last element:
const arr2 = ['a', 'b', 'c'];
assert.equal(arr2.pop(), 'c');
assert.deepEqual(arr2, ['a', 'b']);
// Remove one or more elements anywhere:
const arr3 = ['a', 'b', 'c', 'd'];
assert.deepEqual(arr3.splice(1, 2), ['b', 'c']);
assert.deepEqual(arr3, ['a', 'd']);
.splice()在本章末尾的快速参考中有更详细的介绍。
通过剩余元素的解构,我们可以非破坏性地从数组的开头移除元素(解构在后面有介绍)。
const arr1 = ['a', 'b', 'c'];
// Ignore first element, extract remaining elements
const [, ...arr2] = arr1;
assert.deepEqual(arr2, ['b', 'c']);
assert.deepEqual(arr1, ['a', 'b', 'c']); // unchanged!
遗憾的是,剩余元素必须在数组中的最后。因此,我们只能用它来提取后缀。
{kind=link}
exercises/arrays/queue_via_array_test.mjs
31.11?方法:迭代和转换(.find(),.map(),.filter()等)
在本节中,我们将介绍用于迭代数组和转换数组的数组方法。
31.11.1?迭代和转换方法的回调
所有迭代和转换方法都使用回调。前者将所有迭代值传递给它们的回调;后者询问它们的回调如何转换数组。
这些回调的类型签名如下:
callback: (value: T, index: number, array: Array<T>) => boolean
也就是说,回调有三个参数(可以自由忽略其中任何一个):
-
value是最重要的。此参数保存当前正在处理的迭代值。 -
index还可以告诉回调迭代值的索引。 -
array指向当前数组(方法调用的接收者)。有些算法需要引用整个数组,例如搜索答案。此参数使我们能够为这些算法编写可重用的回调。
回调预期返回的内容取决于传递给它的方法。可能的情况包括:
-
.map()用其回调返回的值填充其结果:> ['a', 'b', 'c'].map(x => x + x) [ 'aa', 'bb', 'cc' ] -
.find()返回其回调返回true的第一个数组元素:> ['a', 'bb', 'ccc'].find(str => str.length >= 2) 'bb'
这两种方法稍后将更详细地描述。
31.11.2?搜索元素:.find(),.findIndex()
.find()返回其回调返回真值的第一个元素(如果找不到任何内容,则返回undefined):
> [6, -5, 8].find(x => x < 0)
-5
> [6, 5, 8].find(x => x < 0)
undefined
.findIndex()返回其回调返回真值的第一个元素的索引(如果找不到任何内容,则返回-1):
> [6, -5, 8].findIndex(x => x < 0)
1
> [6, 5, 8].findIndex(x => x < 0)
-1
.findIndex()可以实现如下:
function findIndex(arr, callback) {
for (const [i, x] of arr.entries()) {
if (callback(x, i, arr)) {
return i;
}
}
return -1;
}
31.11.3?.map():在给元素新值的同时复制
.map()返回接收者的修改副本。副本的元素是将map的回调应用于接收者的元素的结果。
所有这些都可以通过示例更容易理解:
> [1, 2, 3].map(x => x * 3)
[ 3, 6, 9 ]
> ['how', 'are', 'you'].map(str => str.toUpperCase())
[ 'HOW', 'ARE', 'YOU' ]
> [true, true, true].map((_x, index) => index)
[ 0, 1, 2 ]
.map()可以实现如下:
function map(arr, mapFunc) {
const result = [];
for (const [i, x] of arr.entries()) {
result.push(mapFunc(x, i, arr));
}
return result;
}
exercises/arrays/number_lines_test.mjs
31.11.4?.flatMap():映射到零个或多个值
Array<T>.prototype.flatMap()的类型签名是:
.flatMap<U>(
callback: (value: T, index: number, array: T[]) => U|Array<U>,
thisValue?: any
): U[]
.map()和.flatMap()都接受一个函数callback作为参数,控制如何将输入数组转换为输出数组:
-
使用
.map(),每个输入数组元素都被转换为一个输出元素。也就是说,callback返回一个单一值。 -
使用
.flatMap(),每个输入数组元素都被转换为零个或多个输出元素。也就是说,callback返回一个值的数组(也可以返回非数组值,但这很少见)。
这是.flatMap()的实际应用:
> ['a', 'b', 'c'].flatMap(x => [x,x])
[ 'a', 'a', 'b', 'b', 'c', 'c' ]
> ['a', 'b', 'c'].flatMap(x => [x])
[ 'a', 'b', 'c' ]
> ['a', 'b', 'c'].flatMap(x => [])
[]
在探讨如何实现此方法之前,我们将首先考虑使用情况。
31.11.4.1?用例:同时过滤和映射
数组方法.map()的结果始终与调用它的数组长度相同。也就是说,它的回调不能跳过它不感兴趣的数组元素。.flatMap()具有这样做的能力,在下一个示例中非常有用。
我们将使用以下函数processArray()创建一个数组,然后通过.flatMap()进行过滤和映射:
function processArray(arr, callback) {
return arr.map(x => {
try {
return { value: callback(x) };
} catch (e) {
return { error: e };
}
});
}
接下来,我们通过processArray()创建一个数组results:
const results = processArray([1, -5, 6], throwIfNegative);
assert.deepEqual(results, [
{ value: 1 },
{ error: new Error('Illegal value: -5') },
{ value: 6 },
]);
function throwIfNegative(value) {
if (value < 0) {
throw new Error('Illegal value: '+value);
}
return value;
}
现在我们可以使用.flatMap()来提取results中的值或错误:
const values = results.flatMap(
result => result.value ? [result.value] : []);
assert.deepEqual(values, [1, 6]);
const errors = results.flatMap(
result => result.error ? [result.error] : []);
assert.deepEqual(errors, [new Error('Illegal value: -5')]);
31.11.4.2?用例:将单个输入值映射到多个输出值
数组方法.map()将每个输入数组元素映射到一个输出元素。但是如果我们想要将其映射到多个输出元素呢?
这在以下示例中变得必要:
> stringsToCodePoints(['many', 'a', 'moon'])
['m', 'a', 'n', 'y', 'a', 'm', 'o', 'o', 'n']
我们想要将字符串数组转换为 Unicode 字符(代码点)数组。以下函数通过.flatMap()实现了这一点:
function stringsToCodePoints(strs) {
return strs.flatMap(str => Array.from(str));
}
31.11.4.3 一个简单的实现
我们可以如下实现.flatMap()。注意:这个实现比内置版本更简单,例如,执行了更多的检查。
function flatMap(arr, mapFunc) {
const result = [];
for (const [index, elem] of arr.entries()) {
const x = mapFunc(elem, index, arr);
// We allow mapFunc() to return non-Arrays
if (Array.isArray(x)) {
result.push(...x);
} else {
result.push(x);
}
}
return result;
}
 练习:
练习:.flatMap()
-
exercises/arrays/convert_to_numbers_test.mjs -
exercises/arrays/replace_objects_test.mjs
31.11.5 .filter(): 仅保留一些元素
数组方法.filter()返回一个数组,其中收集了回调返回真值的所有元素。
例如:
> [-1, 2, 5, -7, 6].filter(x => x >= 0)
[ 2, 5, 6 ]
> ['a', 'b', 'c', 'd'].filter((_x,i) => (i%2)===0)
[ 'a', 'c' ]
.filter()可以如下实现:
function filter(arr, filterFunc) {
const result = [];
for (const [i, x] of arr.entries()) {
if (filterFunc(x, i, arr)) {
result.push(x);
}
}
return result;
}
 练习:通过
练习:通过.filter()删除空行
exercises/arrays/remove_empty_lines_filter_test.mjs
31.11.6 .reduce(): 从数组中派生值(高级)
方法.reduce()是计算数组arr的“摘要”的强大工具。摘要可以是任何类型的值:
-
一个数字。例如,
arr的所有元素的总和。 -
一个数组。例如,
arr的副本,其中每个元素都是原始元素的两倍。 -
等等。
reduce在函数式编程中也被称为foldl(“从左向右折叠”),并且在那里很受欢迎。一个警告是它可能使代码难以理解。
.reduce()具有以下类型签名(在Array<T>中):
.reduce<U>(
callback: (accumulator: U, element: T, index: number, array: T[]) => U,
init?: U)
: U
T是数组元素的类型,U是摘要的类型。这两者可能相同,也可能不同。accumulator只是“summary”的另一个名称。
为了计算数组arr的摘要,.reduce()将所有数组元素逐个传递给它的回调函数:
const accumulator_0 = callback(init, arr[0]);
const accumulator_1 = callback(accumulator_0, arr[1]);
const accumulator_2 = callback(accumulator_1, arr[2]);
// Etc.
callback将先前计算的摘要(存储在其参数accumulator中)与当前数组元素组合,并返回下一个accumulator。.reduce()的结果是最终的累加器 - 在访问所有元素后callback的最后结果。
换句话说:callback 承担了大部分工作;.reduce() 只是以一种有用的方式调用它。
我们可以说回调将数组元素折叠到累加器中。这就是为什么这个操作在函数式编程中被称为“折叠”的原因。
31.11.6.1 第一个例子
让我们看一个.reduce()的示例:函数addAll()计算数组arr中所有数字的总和。
function addAll(arr) {
const startSum = 0;
const callback = (sum, element) => sum + element;
return arr.reduce(callback, startSum);
}
assert.equal(addAll([1, 2, 3]), 6); // (A)
assert.equal(addAll([7, -4, 2]), 5);
在这种情况下,累加器保存了callback已经访问过的所有数组元素的总和。
在 A 行中,结果6是如何从数组中派生出来的?通过以下对callback的调用:
callback(0, 1) --> 1
callback(1, 2) --> 3
callback(3, 3) --> 6
注:
-
第一个参数是当前累加器(从
.reduce()的参数init开始)。 -
第二个参数是当前数组元素。
-
结果是下一个累加器。
-
callback的最后结果也是.reduce()的结果。
或者,我们可以通过for-of循环来实现addAll():
function addAll(arr) {
let sum = 0;
for (const element of arr) {
sum = sum + element;
}
return sum;
}
很难说哪种实现“更好”:基于.reduce()的实现更加简洁,而基于for-of的实现可能更容易理解 - 尤其是对于不熟悉函数式编程的人来说。
31.11.6.2 通过.reduce()查找索引的示例
以下函数是数组方法.indexOf()的实现。它返回给定的searchValue在数组arr中第一次出现的索引:
const NOT_FOUND = -1;
function indexOf(arr, searchValue) {
return arr.reduce(
(result, elem, index) => {
if (result !== NOT_FOUND) {
// We have already found something: don’t change anything
return result;
} else if (elem === searchValue) {
return index;
} else {
return NOT_FOUND;
}
},
NOT_FOUND);
}
assert.equal(indexOf(['a', 'b', 'c'], 'b'), 1);
assert.equal(indexOf(['a', 'b', 'c'], 'x'), -1);
.reduce()的一个限制是我们无法提前完成(在for-of循环中,我们可以break)。在这里,一旦找到结果,我们总是立即返回结果。
31.11.6.3 例子:数组元素加倍
函数double(arr)返回inArr的副本,其中的每个元素都乘以 2:
function double(inArr) {
return inArr.reduce(
(outArr, element) => {
outArr.push(element * 2);
return outArr;
},
[]);
}
assert.deepEqual(
double([1, 2, 3]),
[2, 4, 6]);
我们通过将其推入来修改初始值[]。double()的非破坏性、更加功能性的版本如下:
function double(inArr) {
return inArr.reduce(
// Don’t change `outArr`, return a fresh Array
(outArr, element) => [...outArr, element * 2],
[]);
}
assert.deepEqual(
double([1, 2, 3]),
[2, 4, 6]);
这个版本更加优雅,但也更慢,使用的内存更多。
 练习:
练习:.reduce()
-
通过
.reduce()进行map():exercises/arrays/map_via_reduce_test.mjs -
通过
.reduce()进行filter():exercises/arrays/filter_via_reduce_test.mjs -
通过
.reduce()计算countMatches():exercises/arrays/count_matches_via_reduce_test.mjs
31.12?.sort(): 排序数组
.sort()具有以下类型定义:
sort(compareFunc?: (a: T, b: T) => number): this
默认情况下,.sort()对元素的字符串表示进行排序。这些表示通过<进行比较。这个操作符进行词典顺序比较(第一个字符最重要)。我们可以看到在对数字进行排序时:
> [200, 3, 10].sort()
[ 10, 200, 3 ]
在对人类语言字符串进行排序时,我们需要意识到它们是根据它们的代码单元值(字符代码)进行比较的:
> ['pie', 'cookie', 'éclair', 'Pie', 'Cookie', 'éclair'].sort()
[ 'Cookie', 'Pie', 'cookie', 'pie', 'éclair', 'éclair' ]
所有无重音的大写字母都排在所有无重音的小写字母之前,后者排在所有重音字母之前。如果我们想要人类语言的正确排序,我们可以使用Intl,JavaScript 国际化 API。
.sort()就地排序;它会更改并返回其接收者:
> const arr = ['a', 'c', 'b'];
> arr.sort() === arr
true
> arr
[ 'a', 'b', 'c' ]
31.12.1?自定义排序顺序
我们可以通过参数compareFunc自定义排序顺序,该参数必须返回一个数字,即:
-
如果
a < b则为负 -
如果
a === b则为零 -
如果
a > b则为正
 记住这些规则的提示
记住这些规则的提示
负数小于零(等等)。
31.12.2?排序数字
我们可以使用这个辅助函数来排序数字:
function compareNumbers(a, b) {
if (a < b) {
return -1;
} else if (a === b) {
return 0;
} else {
return 1;
}
}
assert.deepEqual(
[200, 3, 10].sort(compareNumbers),
[3, 10, 200]);
以下是一个快速而肮脏的替代方法。
> [200, 3, 10].sort((a,b) => a - b)
[ 3, 10, 200 ]
这种方法的缺点是:
-
这是神秘的。
-
如果
a-b变成一个很大的正数或负数,就会有数值溢出或下溢的风险。
31.12.3?排序对象
如果我们想要对对象进行排序,我们还需要使用比较函数。例如,以下代码显示了如何按年龄对对象进行排序。
const arr = [ {age: 200}, {age: 3}, {age: 10} ];
assert.deepEqual(
arr.sort((obj1, obj2) => obj1.age - obj2.age),
[{ age: 3 }, { age: 10 }, { age: 200 }] );
 练习:按名称对对象进行排序
练习:按名称对对象进行排序
exercises/arrays/sort_objects_test.mjs
31.13?Array快速参考
传奇:
-
R:方法不改变数组(非破坏性)。 -
W:方法改变了数组(破坏性)。
31.13.1?new Array()
new Array(n)创建一个包含n个空位的长度为n的数组:
// Trailing commas are always ignored.
// Therefore: number of commas = number of holes
assert.deepEqual(new Array(3), [,,,]);
new Array()创建一个空数组。但是,我建议始终使用[]。
31.13.2?Array的静态方法
-
Array.from<T>(iterable: Iterable<T> | ArrayLike<T>): T[]^([ES6]) -
Array.from<T,U>(iterable: Iterable<T> | ArrayLike<T>, mapFunc: (v: T, k: number) => U, thisArg?: any): U[]^([ES6])将可迭代对象或类数组对象转换为数组。可选地,输入值可以在添加到输出数组之前通过
mapFunc进行转换。例子:
> Array.from(new Set(['a', 'b'])) // iterable [ 'a', 'b' ] > Array.from({length: 2, 0:'a', 1:'b'}) // Array-like object [ 'a', 'b' ] -
Array.of<T>(...items: T[]): T[]^([ES6])这个静态方法主要用于
Array的子类,它作为自定义数组文字:class MyArray extends Array {} assert.equal( MyArray.of('a', 'b') instanceof MyArray, true);
31.13.3?Array.prototype的方法
-
.at(index: number): T | undefined^([R, ES2022])返回
index处的数组元素。如果index为负,则在使用之前将其添加到.length(-1变为this.length-1等)。> ['a', 'b', 'c'].at(0) 'a' > ['a', 'b', 'c'].at(-1) 'c' -
.concat(...items: Array<T[] | T>): T[]^([R, ES3])返回一个新的数组,该数组是接收者和所有
items的连接。非数组参数(例如以下示例中的'b')将被视为具有单个元素的数组。> ['a'].concat('b', ['c', 'd']) [ 'a', 'b', 'c', 'd' ] -
.copyWithin(target: number, start: number, end=this.length): this^([W, ES6])将索引范围从(包括)
start到(不包括)end的元素复制到以target开头的索引。重叠部分被正确处理。> ['a', 'b', 'c', 'd'].copyWithin(0, 2, 4) [ 'c', 'd', 'c', 'd' ]如果
start或end为负数,则将其添加到.length。 -
.entries(): Iterable<[number, T]>^([R, ES6])返回一个可迭代的[index, element]对。
> Array.from(['a', 'b'].entries()) [ [ 0, 'a' ], [ 1, 'b' ] ] -
.every(callback: (value: T, index: number, array: Array<T>) => boolean, thisArg?: any): boolean^([R, ES5])如果
callback对每个元素返回一个真值,则返回true。否则,返回false。一旦接收到一个假值,它就会停止。这个方法对应于数学中的全称量化(“对于所有”,?)。> [1, 2, 3].every(x => x > 0) true > [1, -2, 3].every(x => x > 0) false相关方法:
.some()(“存在”)。 -
.fill(value: T, start=0, end=this.length): this^([W, ES6])将
value分配给start和end之间(包括start但不包括end)的每个索引。> [0, 1, 2].fill('a') [ 'a', 'a', 'a' ]注意:不要使用这个方法来用对象
obj填充数组;然后每个元素将引用obj(共享它)。在这种情况下,最好使用Array.from()。 -
.filter(callback: (value: T, index: number, array: Array<T>) => any, thisArg?: any): T[]^([R, ES5])返回一个只包含
callback返回真值的元素的数组。> [1, -2, 3].filter(x => x > 0) [ 1, 3 ] -
.find(predicate: (value: T, index: number, obj: T[]) => boolean, thisArg?: any): T | undefined^([R, ES6])结果是
predicate返回真值的第一个元素。如果没有这样的元素,则结果是undefined。> [1, -2, 3].find(x => x < 0) -2 > [1, 2, 3].find(x => x < 0) undefined -
.findIndex(predicate: (value: T, index: number, obj: T[]) => boolean, thisArg?: any): number^([R, ES6])结果是
predicate返回真值的第一个元素的索引。如果没有这样的元素,则结果是-1。> [1, -2, 3].findIndex(x => x < 0) 1 > [1, 2, 3].findIndex(x => x < 0) -1 -
.flat(depth = 1): any[]^([R, ES2019])“展平”一个数组:它会进入嵌套在输入数组中的数组,并创建一个副本,其中它发现的所有值都被移动到顶层,直到达到
depth级别或更低级别。> [ 1,2, [3,4], [[5,6]] ].flat(0) // no change [ 1, 2, [3,4], [[5,6]] ] > [ 1,2, [3,4], [[5,6]] ].flat(1) [1, 2, 3, 4, [5,6]] > [ 1,2, [3,4], [[5,6]] ].flat(2) [1, 2, 3, 4, 5, 6] -
.flatMap<U>(callback: (value: T, index: number, array: T[]) => U|Array<U>, thisValue?: any): U[]^([R, ES2019])结果是通过调用原始数组的每个元素的
callback()并连接它返回的数组产生的。> ['a', 'b', 'c'].flatMap(x => [x,x]) [ 'a', 'a', 'b', 'b', 'c', 'c' ] > ['a', 'b', 'c'].flatMap(x => [x]) [ 'a', 'b', 'c' ] > ['a', 'b', 'c'].flatMap(x => []) [] -
.forEach(callback: (value: T, index: number, array: Array<T>) => void, thisArg?: any): void^([R, ES5])为每个元素调用
callback。['a', 'b'].forEach((x, i) => console.log(x, i)) // Output: // 'a', 0 // 'b', 1通常使用
for-of循环更好:它更快,支持break,并且可以迭代任意可迭代对象。 -
.includes(searchElement: T, fromIndex=0): boolean^([R, ES2016])如果接收器有一个值为
searchElement的元素,则返回true,否则返回false。搜索从索引fromIndex开始。> [0, 1, 2].includes(1) true > [0, 1, 2].includes(5) false -
.indexOf(searchElement: T, fromIndex=0): number^([R, ES5])返回第一个严格等于
searchElement的元素的索引。如果没有这样的元素,则返回-1。从索引fromIndex开始搜索,接着访问更高的索引。> ['a', 'b', 'a'].indexOf('a') 0 > ['a', 'b', 'a'].indexOf('a', 1) 2 > ['a', 'b', 'a'].indexOf('c') -1 -
.join(separator = ','): string^([R, ES1])通过连接所有元素的字符串表示来创建一个字符串,用
separator分隔它们。> ['a', 'b', 'c'].join('##') 'a##b##c' > ['a', 'b', 'c'].join() 'a,b,c' -
.keys(): Iterable<number>^([R, ES6])返回接收器的键的可迭代对象。
> Array.from(['a', 'b'].keys()) [ 0, 1 ] -
.lastIndexOf(searchElement: T, fromIndex=this.length-1): number^([R, ES5])返回最后一个严格等于
searchElement的元素的索引。如果没有这样的元素,则返回-1。从索引fromIndex开始搜索,接着访问更低的索引。> ['a', 'b', 'a'].lastIndexOf('a') 2 > ['a', 'b', 'a'].lastIndexOf('a', 1) 0 > ['a', 'b', 'a'].lastIndexOf('c') -1 -
.map<U>(mapFunc: (value: T, index: number, array: Array<T>) => U, thisArg?: any): U[]^([R, ES5])返回一个新的数组,其中每个元素都是将
mapFunc应用于接收器的相应元素的结果。> [1, 2, 3].map(x => x * 2) [ 2, 4, 6 ] > ['a', 'b', 'c'].map((x, i) => i) [ 0, 1, 2 ] -
.pop(): T | undefined^([W, ES3])移除并返回接收器的最后一个元素。也就是说,它将接收器的末尾视为一个堆栈。与
.push()相反。> const arr = ['a', 'b', 'c']; > arr.pop() 'c' > arr [ 'a', 'b' ] -
.push(...items: T[]): number^([W, ES3])向接收器的末尾添加零个或多个
items。也就是说,它将接收器的末尾视为一个堆栈。返回值是更改后接收器的长度。与.pop()相反。> const arr = ['a', 'b']; > arr.push('c', 'd') 4 > arr [ 'a', 'b', 'c', 'd' ]我们可以通过展开(
...)数组来推送一个数组作为参数:> const arr = ['x']; > arr.push(...['y', 'z']) 3 > arr [ 'x', 'y', 'z' ] -
.reduce<U>(callback: (accumulator: U, element: T, index: number, array: T[]) => U, init?: U): U^([R, ES5])此方法生成接收者的摘要:它将所有数组元素提供给
callback,callback将当前摘要(在参数accumulator中)与当前数组元素组合并返回下一个accumulator:const accumulator_0 = callback(init, arr[0]); const accumulator_1 = callback(accumulator_0, arr[1]); const accumulator_2 = callback(accumulator_1, arr[2]); // Etc..reduce()的结果是在访问所有数组元素后callback的最后结果。> [1, 2, 3].reduce((accu, x) => accu + x, 0) 6 > [1, 2, 3].reduce((accu, x) => accu + String(x), '') '123'如果没有提供
init,则使用索引 0 处的数组元素,并首先访问索引 1 处的元素。因此,数组的长度必须至少为 1。 -
.reduceRight<U>(callback: (accumulator: U, element: T, index: number, array: T[]) => U, init?: U): U^([R, ES5])与
.reduce()类似,但是以相反的顺序访问数组元素,从最后一个元素开始。> [1, 2, 3].reduceRight((accu, x) => accu + String(x), '') '321' -
.reverse(): this^([W, ES1])重新排列接收者的元素,使其按相反顺序排列,然后返回接收者。
> const arr = ['a', 'b', 'c']; > arr.reverse() [ 'c', 'b', 'a' ] > arr [ 'c', 'b', 'a' ] -
.shift(): T | undefined^([W, ES3])删除并返回接收者的第一个元素。与
.unshift()相反。> const arr = ['a', 'b', 'c']; > arr.shift() 'a' > arr [ 'b', 'c' ] -
.slice(start=0, end=this.length): T[]^([R, ES3])返回一个新的数组,其中包含接收者的索引位于
start和end之间(包括start但不包括end)的元素。> ['a', 'b', 'c', 'd'].slice(1, 3) [ 'b', 'c' ] > ['a', 'b'].slice() // shallow copy [ 'a', 'b' ]允许负索引,并添加到
.length:> ['a', 'b', 'c'].slice(-2) [ 'b', 'c' ] -
.some(callback: (value: T, index: number, array: Array<T>) => boolean, thisArg?: any): boolean^([R, ES5])如果
callback对至少一个元素返回真值,则返回true。否则,它返回false。一旦收到真值,它就会停止。此方法对应于数学中的存在量词(“存在”,?)。> [1, 2, 3].some(x => x < 0) false > [1, -2, 3].some(x => x < 0) true相关方法:
.every()(“对于所有”)。 -
.sort(compareFunc?: (a: T, b: T) => number): this^([W, ES1])对接收者进行排序并返回。默认情况下,它对元素的字符串表示进行排序。它按字典顺序和字符的代码单元值(字符代码)进行排序:
> ['pie', 'cookie', 'éclair', 'Pie', 'Cookie', 'éclair'].sort() [ 'Cookie', 'Pie', 'cookie', 'pie', 'éclair', 'éclair' ] > [200, 3, 10].sort() [ 10, 200, 3 ]我们可以通过
compareFunc自定义排序顺序,它返回一个数字:-
如果
a < b,则为负数 -
如果
a === b,则为零 -
如果
a > b,则为正数
对于对数字进行排序的技巧(存在数值溢出或下溢的风险):
> [200, 3, 10].sort((a, b) => a - b) [ 3, 10, 200 ]
.sort()是稳定的自 ECMAScript 2019 以来,排序保证是稳定的:如果元素被排序视为相等,则排序不会改变这些元素的顺序(相对于彼此)。
-
-
.splice(start: number, deleteCount=this.length-start, ...items: T[]): T[]^([W, ES3])在索引
start处,它删除deleteCount个元素并插入items。它返回已删除的元素。> const arr = ['a', 'b', 'c', 'd']; > arr.splice(1, 2, 'x', 'y') [ 'b', 'c' ] > arr [ 'a', 'x', 'y', 'd' ]start可以为负数,如果是负数,则将其添加到.length:> ['a', 'b', 'c'].splice(-2, 2) [ 'b', 'c' ] -
.toString(): string^([R, ES1])通过
String()将所有元素转换为字符串,用逗号分隔它们并返回结果。> [1, 2, 3].toString() '1,2,3' > ['1', '2', '3'].toString() '1,2,3' > [].toString() '' -
.unshift(...items: T[]): number^([W, ES3])将
items插入到接收者的开头,并在此修改后返回其长度。> const arr = ['c', 'd']; > arr.unshift('e', 'f') 4 > arr [ 'e', 'f', 'c', 'd' ] -
.values(): Iterable<T>^([R, ES6])返回接收者的值的可迭代对象。
> Array.from(['a', 'b'].values()) [ 'a', 'b' ]
31.13.4?来源
 测验
测验
请参阅测验应用程序。
三十二、Typed Arrays:处理二进制数据(高级)
原文:
exploringjs.com/impatient-js/ch_typed-arrays.html译者:飞龙
-
32.1 API 的基础](ch_typed-arrays.html#the-basics-of-the-api)
-
32.1.1 Typed Arrays 的用例](ch_typed-arrays.html#use-cases-for-typed-arrays)
-
32.1.2 核心类:
ArrayBuffer、Typed Arrays、DataView](ch_typed-arrays.html#the-core-classes-arraybuffer-typed-arrays-dataview) -
32.1.3 使用 Typed Arrays](ch_typed-arrays.html#using-typed-arrays)
-
32.1.4 使用 DataViews](ch_typed-arrays.html#using-dataviews)
-
-
32.2 元素类型](ch_typed-arrays.html#element-types)
-
32.2.1 处理溢出和下溢](ch_typed-arrays.html#handling-overflow-underflow)
-
32.2.2 字节顺序](ch_typed-arrays.html#endianness)
-
-
32.3 Typed Arrays 的更多信息](ch_typed-arrays.html#more-information-on-typed-arrays)
-
32.3.1
?ElementType?Array.from()的静态方法 -
32.3.2 Typed Arrays 是可迭代的](ch_typed-arrays.html#typed-arrays-are-iterable)
-
32.3.3 Typed Arrays vs. normal Arrays](ch_typed-arrays.html#typed-arrays-vs.-normal-arrays)
-
32.3.4 转换 Typed Arrays 为普通数组](ch_typed-arrays.html#converting-typed-arrays-to-and-from-normal-arrays)
-
32.3.5 连接 Typed Arrays](ch_typed-arrays.html#concatenating-typed-arrays)
-
-
32.4 索引与偏移的快速参考](ch_typed-arrays.html#typed-arrays-indices-offsets)
-
32.5 ArrayBuffer 的快速参考](ch_typed-arrays.html#quick-reference-arraybuffers)
-
32.5.1
new ArrayBuffer()](ch_typed-arrays.html#new-arraybuffer) -
32.5.2
ArrayBuffer的静态方法](ch_typed-arrays.html#static-methods-of-arraybuffer) -
32.5.3
ArrayBuffer.prototype的属性](ch_typed-arrays.html#properties-of-arraybuffer.prototype)
-
-
32.6 Typed Arrays 的快速参考](ch_typed-arrays.html#quick-reference-typed-arrays)
-
32.6.1
TypedArray<T>的静态方法](ch_typed-arrays.html#static-methods-of-typedarrayt) -
32.6.2
TypedArray<T>.prototype的属性 -
32.6.3
new ?ElementType?Array()](ch_typed-arrays.html#new-elementtypearray) -
32.6.4 ?ElementType?Array 的静态属性
-
32.6.5
?ElementType?Array.prototype的属性
-
-
32.7 DataView 的快速参考](ch_typed-arrays.html#quick-reference-dataviews)
-
32.7.1
new DataView()](ch_typed-arrays.html#new-dataview) -
32.7.2
DataView.prototype的属性
-
32.1 API 的基础
网络上的许多数据都是文本:JSON 文件、HTML 文件、CSS 文件、JavaScript 代码等。JavaScript 通过其内置的字符串很好地处理这些数据。
然而,在 2011 年之前,它并不擅长处理二进制数据。Typed Array Specification 1.0于 2011 年 2 月 8 日推出,提供了处理二进制数据的工具。随着 ECMAScript 6,Typed Arrays 被添加到核心语言,并获得了以前仅适用于普通数组的方法(.map()、.filter()等)。
32.1.1 Typed Arrays 的用例
Typed Arrays 的主要用例包括:
-
处理二进制数据:管理图像数据、操作二进制文件、处理二进制网络协议等。
-
与本机 API 交互:本机 API 通常以二进制格式接收和返回数据,在 ES6 之前的 JavaScript 中无法很好地存储或操作这些数据。这意味着每当您与此类 API 通信时,数据都必须在 JavaScript 和二进制之间进行转换。类型化数组消除了这一瓶颈。与本机 API 通信的一个例子是 WebGL,最初为其创建了类型化数组。文章“类型化数组的历史”(由 Ilmari Heikkinen 为 HTML5 Rocks 撰写)的部分“类型化数组:浏览器中的二进制数据”有更多信息。
32.1.2 核心类:ArrayBuffer,类型化数组,DataView
类型化数组 API 将二进制数据存储在ArrayBuffer的实例中:
const buf = new ArrayBuffer(4); // length in bytes
// buf is initialized with zeros
ArrayBuffer 本身是一个黑匣子:如果您想访问其数据,必须将其包装在另一个对象中 - 视图对象。有两种类型的视图对象可用:
-
类型化数组:让您将数据作为具有相同类型的索引序列的元素访问。示例包括:
-
Uint8Array:元素为无符号 8 位整数。无符号表示它们的范围从零开始。 -
Int16Array:元素为有符号 16 位整数。有符号表示它们具有符号,可以是负数,零或正数。 -
Float32Array:元素为 32 位浮点数。
-
-
DataViews:让您将数据解释为各种类型(
Uint8,Int16,Float32等),您可以在任何字节偏移处读取和写入。
图 20 显示了 API 的类图。
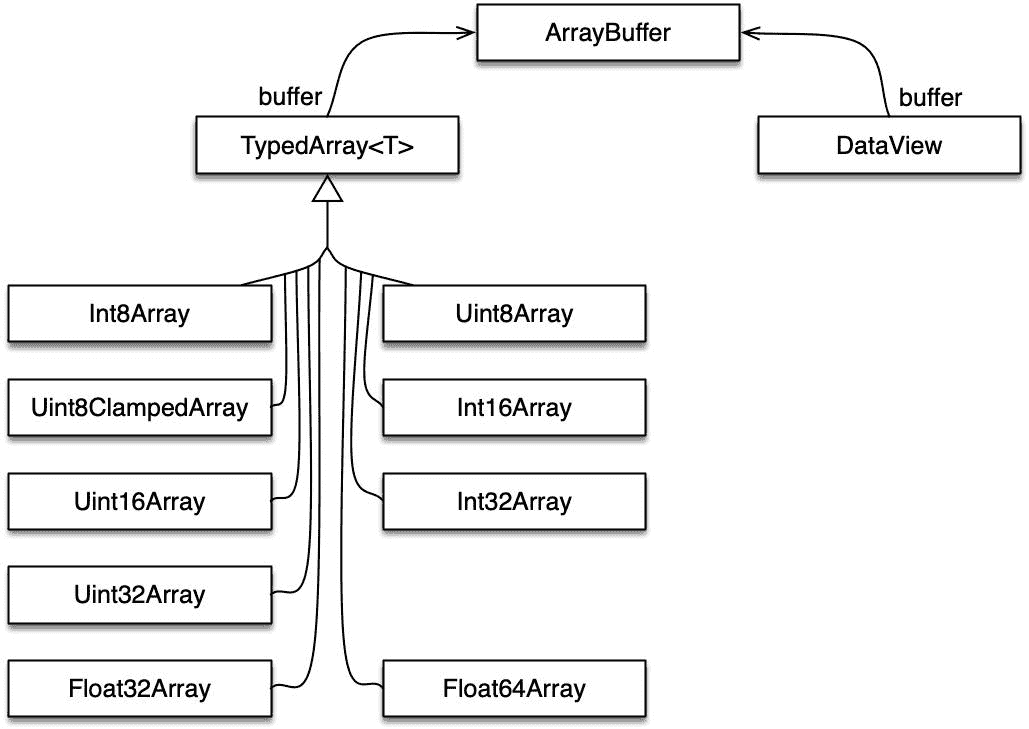
图 20:类型化数组 API 的类。
32.1.3 使用类型化数组
类型化数组与普通数组的使用方式基本相同,但有一些显著的区别:
-
类型化数组将它们的数据存储在 ArrayBuffers 中。
-
所有元素都初始化为零。
-
所有元素具有相同的类型。将值写入类型化数组会将它们强制转换为该类型。读取值会产生普通数字或大整数。
-
类型化数组的长度是不可变的;它不能被更改。
-
类型化数组不能有空洞。
32.1.3.1 创建类型化数组
以下代码显示了创建相同类型化数组的三种不同方式:
// Argument: Typed Array or Array-like object
const ta1 = new Uint8Array([0, 1, 2]);
const ta2 = Uint8Array.of(0, 1, 2);
const ta3 = new Uint8Array(3); // length of Typed Array
ta3[0] = 0;
ta3[1] = 1;
ta3[2] = 2;
assert.deepEqual(ta1, ta2);
assert.deepEqual(ta1, ta3);
32.1.3.2 包装的 ArrayBuffer
const typedArray = new Int16Array(2); // 2 elements
assert.equal(typedArray.length, 2);
assert.deepEqual(
typedArray.buffer, new ArrayBuffer(4)); // 4 bytes
32.1.3.3 获取和设置元素
const typedArray = new Int16Array(2);
assert.equal(typedArray[1], 0); // initialized with 0
typedArray[1] = 72;
assert.equal(typedArray[1], 72);
32.1.4 使用 DataViews
这就是 DataViews 的使用方式:
const dataView = new DataView(new ArrayBuffer(4));
assert.equal(dataView.getInt16(0), 0);
assert.equal(dataView.getUint8(0), 0);
dataView.setUint8(0, 5);
32.2 元素类型
表 20:类型化数组 API 支持的元素类型。
| 元素 | 类型化数组 | 字节 | 描述 | |
|---|---|---|---|---|
Int8 | Int8Array | 1 | 8 位有符号整数 | ES6 |
Uint8 | Uint8Array | 1 | 8 位无符号整数 | ES6 |
Uint8C | Uint8ClampedArray | 1 | 8 位无符号整数 | ES6 |
| (夹紧转换) | ES6 | |||
Int16 | Int16Array | 2 | 16 位有符号整数 | ES6 |
Uint16 | Uint16Array | 2 | 16 位无符号整数 | ES6 |
Int32 | Int32Array | 4 | 32 位有符号整数 | ES6 |
Uint32 | Uint32Array | 4 | 32 位无符号整数 | ES6 |
BigInt64 | BigInt64Array | 8 | 64 位有符号整数 | ES2020 |
BigUint64 | BigUint64Array | 8 | 64 位无符号整数 | ES2020 |
Float32 | Float32Array | 4 | 32 位浮点 | ES6 |
Float64 | Float64Array | 8 | 64 位浮点 | ES6 |
Tbl. 20 列出了可用的元素类型。这些类型(例如Int32)出现在两个位置:
-
在类型化数组中,它们指定元素的类型。例如,
Int32Array的所有元素都具有类型Int32。元素类型是类型化数组唯一不同的方面。 -
在 DataViews 中,它们是访问其 ArrayBuffers 的透镜,当您使用
.getInt32()和.setInt32()等方法时。
元素类型 Uint8C 是特殊的:它不受 DataView 支持,只存在于启用 Uint8ClampedArray。这种类型化数组被 canvas 元素使用(它替换了 CanvasPixelArray)并且应该尽量避免使用。Uint8C 和 Uint8 之间唯一的区别是如何处理溢出和下溢(如下一小节中所解释的)。
类型化数组和数组缓冲区使用数字和大整数来导入和导出值:
-
BigInt64和BigUint64类型通过大整数处理。例如,setter 接受大整数,getter 返回大整数。 -
所有其他元素类型都通过数字处理。
32.2.1?处理溢出和下溢
通常,当一个值超出了元素类型的范围时,会使用模算术将其转换为范围内的值。对于有符号和无符号整数来说,这意味着:
-
最高值加一会转换为最低值(对于无符号整数为 0)。
-
最低值减一会转换为最高值。
以下函数有助于说明转换的工作原理:
function setAndGet(typedArray, value) {
typedArray[0] = value;
return typedArray[0];
}
无符号 8 位整数的模转换:
const uint8 = new Uint8Array(1);
// Highest value of range
assert.equal(setAndGet(uint8, 255), 255);
// Overflow
assert.equal(setAndGet(uint8, 256), 0);
// Lowest value of range
assert.equal(setAndGet(uint8, 0), 0);
// Underflow
assert.equal(setAndGet(uint8, -1), 255);
有符号 8 位整数的模转换:
const int8 = new Int8Array(1);
// Highest value of range
assert.equal(setAndGet(int8, 127), 127);
// Overflow
assert.equal(setAndGet(int8, 128), -128);
// Lowest value of range
assert.equal(setAndGet(int8, -128), -128);
// Underflow
assert.equal(setAndGet(int8, -129), 127);
夹紧转换是不同的:
-
所有下溢的值都转换为最低值。
-
所有溢出的值都转换为最高值。
const uint8c = new Uint8ClampedArray(1);
// Highest value of range
assert.equal(setAndGet(uint8c, 255), 255);
// Overflow
assert.equal(setAndGet(uint8c, 256), 255);
// Lowest value of range
assert.equal(setAndGet(uint8c, 0), 0);
// Underflow
assert.equal(setAndGet(uint8c, -1), 0);
32.2.2?字节顺序
每当一个类型(如 Uint16)被存储为多个字节的序列时,字节顺序 都很重要:
-
大端:最重要的字节先出现。例如,
Uint16值 0x4321 存储为两个字节 - 首先是 0x43,然后是 0x21。 -
小端:最不重要的字节先出现。例如,
Uint16值 0x4321 存储为两个字节 - 首先是 0x21,然后是 0x43。
字节顺序往往固定在每个 CPU 架构上,并且在本机 API 中保持一致。类型化数组用于与这些 API 进行通信,这就是为什么它们的字节顺序遵循平台的字节顺序并且不能更改的原因。
另一方面,协议和二进制文件的字节顺序是变化的,但在格式上是固定的,跨平台一致。因此,我们必须能够访问任一字节顺序的数据。DataView 用于这种情况,并且让您在获取或设置值时指定字节顺序。
-
大端表示法是数据网络中最常见的约定;互联网协议套件的协议字段,如 IPv4、IPv6、TCP 和 UDP,以大端顺序传输。因此,大端字节顺序也被称为网络字节顺序。
-
小端存储在微处理器中很受欢迎,部分原因是因特尔公司对微处理器设计的重大历史影响。
还有其他可能的排序方式。这些通常被称为 中端 或 混合端。
32.3?有关类型化数组的更多信息
在本节中,?ElementType?Array 代表 Int8Array、Uint8Array 等。ElementType 是 Int8、Uint8 等。
32.3.1?静态方法 ?ElementType?Array.from()
这种方法的类型签名是:
.from<S>(
source: Iterable<S>|ArrayLike<S>,
mapfn?: S => ElementType, thisArg?: any)
: ?ElementType?Array
.from() 将 source 转换为 this 的实例(类型化数组)。
例如,普通数组是可迭代的,并且可以使用这种方法进行转换:
assert.deepEqual(
Uint16Array.from([0, 1, 2]),
Uint16Array.of(0, 1, 2));
类型化数组也是可迭代的:
assert.deepEqual(
Uint16Array.from(Uint8Array.of(0, 1, 2)),
Uint16Array.of(0, 1, 2));
source 也可以是一个 类数组对象:
assert.deepEqual(
Uint16Array.from({0:0, 1:1, 2:2, length: 3}),
Uint16Array.of(0, 1, 2));
可选的 mapfn 允许您在它们成为结果的元素之前转换 source 的元素。为什么要一次完成两个步骤 映射 和 转换?与通过 .map() 分别进行映射相比,有两个优势:
-
不需要中间数组或类型化数组。
-
在不同精度的类型化数组之间进行转换时,出错的可能性较小。
继续阅读有关第二个优势的解释。
32.3.1.1?陷阱:在类型化数组类型之间进行映射转换时
静态方法 .from() 可以选择同时在类型化数组类型之间进行映射和转换。如果使用该方法,出错的可能性较小。
为了理解这一点,让我们首先将一个具有更高精度的 Typed Array 转换为一个具有更高精度的 Typed Array。如果我们使用.from()进行映射,结果会自动正确。否则,您必须先转换,然后再映射。
const typedArray = Int8Array.of(127, 126, 125);
assert.deepEqual(
Int16Array.from(typedArray, x => x * 2),
Int16Array.of(254, 252, 250));
assert.deepEqual(
Int16Array.from(typedArray).map(x => x * 2),
Int16Array.of(254, 252, 250)); // OK
assert.deepEqual(
Int16Array.from(typedArray.map(x => x * 2)),
Int16Array.of(-2, -4, -6)); // wrong
如果我们从具有较低精度的 Typed Array 转换为具有较低精度的 Typed Array,通过.from()进行映射会产生正确的结果。否则,我们必须先映射,然后再转换。
assert.deepEqual(
Int8Array.from(Int16Array.of(254, 252, 250), x => x / 2),
Int8Array.of(127, 126, 125));
assert.deepEqual(
Int8Array.from(Int16Array.of(254, 252, 250).map(x => x / 2)),
Int8Array.of(127, 126, 125)); // OK
assert.deepEqual(
Int8Array.from(Int16Array.of(254, 252, 250)).map(x => x / 2),
Int8Array.of(-1, -2, -3)); // wrong
问题在于,如果我们通过.map()进行映射,那么输入类型和输出类型是相同的。相反,.from()从任意输入类型转换为您通过其接收器指定的输出类型。
32.3.2 Typed Arrays 是可迭代的
Typed Arrays 是可迭代的。这意味着你可以使用for-of循环和其他基于迭代的机制:
const ui8 = Uint8Array.of(0, 1, 2);
for (const byte of ui8) {
console.log(byte);
}
// Output:
// 0
// 1
// 2
ArrayBuffers 和 DataViews 不可迭代。
32.3.3 Typed Arrays vs. 普通数组
Typed Arrays 与普通数组非常相似:它们具有.length,可以通过方括号操作符[]访问元素,并且具有大多数标准数组方法。它们与普通数组的不同之处在于:
-
Typed Arrays 有缓冲区。Typed Array
ta的元素不存储在ta中,而是存储在一个关联的 ArrayBuffer 中,可以通过ta.buffer访问:const ta = new Uint16Array(2); // 2 elements assert.deepEqual( ta.buffer, new ArrayBuffer(4)); // 4 bytes -
Typed Arrays 初始化为零:
-
new Array(4)创建一个没有任何元素的普通数组。它只有四个空洞(索引小于.length且没有关联元素)。 -
new Uint8Array(4)创建一个所有元素都为 0 的 Typed Array。
assert.deepEqual(new Uint8Array(4), Uint8Array.of(0, 0, 0, 0)); -
-
所有 Typed Array 的元素都具有相同的类型:
-
设置元素会将值转换为该类型。
const ta = new Uint8Array(1); ta[0] = 257; assert.equal(ta[0], 1); // 257 % 256 (overflow) ta[0] = '2'; assert.equal(ta[0], 2); -
获取元素返回数字或大整数。
const ta = new Uint8Array(1); assert.equal(ta[0], 0); assert.equal(typeof ta[0], 'number');
-
-
Typed Array 的
.length是从其 ArrayBuffer 派生的,永远不会改变(除非切换到不同的 ArrayBuffer)。 -
普通数组可以有空洞;Typed Arrays 不能。
32.3.4 将 Typed Arrays 转换为普通数组
要将普通数组转换为 Typed Array,可以将其传递给 Typed Array 构造函数(接受类似数组的对象和 Typed Arrays)或?ElementType?Array.from()(接受可迭代对象和类似数组的对象)。例如:
const ta1 = new Uint8Array([0, 1, 2]);
const ta2 = Uint8Array.from([0, 1, 2]);
assert.deepEqual(ta1, ta2);
要将 Typed Array 转换为普通数组,可以使用Array.from()或扩展(因为 Typed Arrays 是可迭代的):
assert.deepEqual(
[...Uint8Array.of(0, 1, 2)], [0, 1, 2]
);
assert.deepEqual(
Array.from(Uint8Array.of(0, 1, 2)), [0, 1, 2]
);
32.3.5 连接 Typed Arrays
Typed Arrays 没有.concat()方法,像普通数组一样。解决方法是使用它们的重载方法.set():
.set(typedArray: TypedArray, offset=0): void
.set(arrayLike: ArrayLike<number>, offset=0): void
它将现有的typedArray或arrayLike复制到接收器中,索引为offset。TypedArray是所有具体 Typed Array 类的虚构抽象超类。
以下函数使用该方法将零个或多个 Typed Arrays(或类似数组的对象)复制到resultConstructor的实例中:
function concatenate(resultConstructor, ...arrays) {
let totalLength = 0;
for (const arr of arrays) {
totalLength += arr.length;
}
const result = new resultConstructor(totalLength);
let offset = 0;
for (const arr of arrays) {
result.set(arr, offset);
offset += arr.length;
}
return result;
}
assert.deepEqual(
concatenate(Uint8Array, Uint8Array.of(1, 2), [3, 4]),
Uint8Array.of(1, 2, 3, 4));
32.4 快速参考:索引 vs. 偏移
为了准备 ArrayBuffers、Typed Arrays 和 DataViews 的快速参考,我们需要了解索引和偏移之间的区别:
-
方括号操作符
[]的索引:只能使用非负索引(从 0 开始)。在普通数组中,写入负索引会创建属性:
const arr = [6, 7]; arr[-1] = 5; assert.deepEqual( Object.keys(arr), ['0', '1', '-1']);在 Typed Arrays 中,写入负索引会被忽略:
const tarr = Uint8Array.of(6, 7); tarr[-1] = 5; assert.deepEqual( Object.keys(tarr), ['0', '1']); -
ArrayBuffers、Typed Arrays 和 DataViews 的方法的索引:每个索引都可以是负数。如果是负数,则将其添加到实体的长度以产生实际索引。因此,
-1指的是最后一个元素,-2指的是倒数第二个元素,依此类推。普通数组的方法工作方式相同。const ui8 = Uint8Array.of(0, 1, 2); assert.deepEqual(ui8.slice(-1), Uint8Array.of(2)); -
传递给 Typed Arrays 和 DataViews 方法的偏移量必须是非负的-例如:
const dataView = new DataView(new ArrayBuffer(4)); assert.throws( () => dataView.getUint8(-1), { name: 'RangeError', message: 'Offset is outside the bounds of the DataView', });
参数是索引还是偏移量只能通过查看文档来确定;没有简单的规则。
32.5 快速参考:ArrayBuffers
ArrayBuffers 存储二进制数据,可以通过 Typed Arrays 和 DataViews 访问。
32.5.1 new ArrayBuffer()
构造函数的类型签名是:
new ArrayBuffer(length: number)
通过new调用此构造函数会创建一个容量为length字节的实例。这些字节最初都是 0。
您无法更改 ArrayBuffer 的长度;您只能创建一个具有不同长度的新 ArrayBuffer。
32.5.2?ArrayBuffer的静态方法
-
ArrayBuffer.isView(arg: any)如果
arg是一个对象并且是 ArrayBuffer 的视图(即,如果它是 Typed Array 或 DataView),则返回true。
32.5.3?ArrayBuffer.prototype的属性
-
get .byteLength(): number返回此 ArrayBuffer 的容量(以字节为单位)。
-
.slice(startIndex: number, endIndex=this.byteLength)创建一个新的 ArrayBuffer,其中包含此 ArrayBuffer 的字节,其索引大于或等于
startIndex且小于endIndex。start和endIndex可以是负数(参见§32.4“快速参考:索引 vs. 偏移量”)。
32.6?快速参考:Typed Arrays
各种 Typed Array 对象的属性分两步介绍:
-
TypedArray:首先,我们看一下所有 Typed Array 类的抽象超类(在本章开头的类图中显示)。我称这个超类为TypedArray,但它无法直接从 JavaScript 访问。TypedArray.prototype包含所有 Typed Arrays 的方法。 -
?ElementType?Array:具体的 Typed Array 类称为Uint8Array,Int16Array,Float32Array等。这些是您通过new,.of和.from()使用的类。
32.6.1?TypedArray<T>的静态方法
两个静态TypedArray方法都被其子类(Uint8Array等)继承。TypedArray是抽象的。因此,您总是通过子类使用这些方法,子类是具体的,可以直接实例化。
-
.from<S>(source: Iterable<S>|ArrayLike<S>, mapfn?: S => T, thisArg?: any) : instanceof this将可迭代对象(包括数组和 Typed Arrays)或类似数组的对象转换为
this的实例(instanceof this是我发明的,用于表达这个事实)。assert.deepEqual( Uint16Array.from([0, 1, 2]), Uint16Array.of(0, 1, 2));可选的
mapfn允许您在它们成为结果的元素之前转换source的元素。assert.deepEqual( Int16Array.from(Int8Array.of(127, 126, 125), x => x * 2), Int16Array.of(254, 252, 250)); -
.of(...items: bigint[]): instanceof this(BigInt64Array,BigUint64Array) -
.of(...items: number[]): instanceof this(所有其他 Typed Arrays)创建一个新的
this实例,其元素为items(强制转换为元素类型)。assert.deepEqual( Int16Array.of(-1234, 5, 67), new Int16Array([-1234, 5, 67]) );
32.6.2?TypedArray<T>.prototype的属性
Typed Array 方法接受的索引可以是负数(它们的工作方式类似于传统的数组方法)。偏移量必须是非负的。详情请参见§32.4“快速参考:索引 vs. 偏移量”。
32.6.2.1?特定于 Typed Arrays 的属性
以下属性特定于 Typed Arrays;普通数组没有这些属性:
-
get .buffer(): ArrayBuffer返回支持此 Typed Array 的缓冲区。
-
get .length(): number返回此 Typed Array 缓冲区中的元素长度。
-
get .byteLength(): number返回此 Typed Array 缓冲区的字节大小。
-
get .byteOffset(): number返回此 Typed Array 在其 ArrayBuffer 内“开始”的偏移量。
-
.set(typedArray: TypedArray, offset=0): void -
.set(arrayLike: ArrayLike<bigint>, offset=0): void(BigInt64Array,BigUint64Array) -
.set(arrayLike: ArrayLike<number>, offset=0): void(所有其他 Typed Arrays)将第一个参数的所有元素复制到此 Typed Array。参数的索引 0 的元素写入此 Typed Array 的索引
offset(依此类推)。有关类似数组的更多信息,请参阅§31.5“类似数组”。 -
.subarray(startIndex=0, endIndex=this.length): TypedArray<T>返回一个新的 Typed Array,其缓冲区与此 Typed Array 相同,但范围(通常)更小。如果
startIndex是非负数,则结果 Typed Array 的第一个元素是this[startIndex],第二个是this[startIndex+1](依此类推)。如果startIndex为负数,则会进行适当转换。
32.6.2.2?数组方法
以下方法基本上与普通数组的方法相同:
-
.at(index: number): T | undefined^([R, ES2022]) -
.copyWithin(target: number, start: number, end=this.length): this^([W, ES6]) -
.entries(): Iterable<[number, T]>^([R, ES6]) -
.every(callback: (value: T, index: number, array: TypedArray<T>) => boolean, thisArg?: any): boolean^([R, ES6]) -
.fill(value: T, start=0, end=this.length): this^([W, ES6]) -
.filter(callback: (value: T, index: number, array: TypedArray<T>) => any, thisArg?: any): T[]^([R, ES6]) -
.find(predicate: (value: T, index: number, obj: T[]) => boolean, thisArg?: any): T | undefined^([R, ES6]) -
.findIndex(predicate: (value: T, index: number, obj: T[]) => boolean, thisArg?: any): number^([R, ES6]) -
.forEach(callback: (value: T, index: number, array: TypedArray<T>) => void, thisArg?: any): void^([R, ES6]) -
.includes(searchElement: T, fromIndex=0): boolean^([R, ES2016]) -
.indexOf(searchElement: T, fromIndex=0): number^([R, ES6]) -
.join(separator = ','): string^([R, ES6]) -
.keys(): Iterable<number>^([R, ES6]) -
.lastIndexOf(searchElement: T, fromIndex=this.length-1): number^([R, ES6]) -
.map<U>(mapFunc: (value: T, index: number, array: TypedArray<T>) => U, thisArg?: any): U[]^([R, ES6]) -
.reduce<U>(callback: (accumulator: U, element: T, index: number, array: T[]) => U, init?: U): U^([R, ES6]) -
.reduceRight<U>(callback: (accumulator: U, element: T, index: number, array: T[]) => U, init?: U): U^([R, ES6]) -
.reverse(): this^([W, ES6]) -
.slice(start=0, end=this.length): T[]^([R, ES6]) -
.some(callback: (value: T, index: number, array: TypedArray<T>) => boolean, thisArg?: any): boolean^([R, ES6]) -
.sort(compareFunc?: (a: T, b: T) => number): this^([W, ES6]) -
.toString(): string^([R, ES6]) -
.values(): Iterable<T>^([R, ES6])
有关这些方法的工作原理的详细信息,请参阅§31.13.3“Array.prototype 的方法”。
32.6.3?new ?ElementType?Array()
每个类型化数组构造函数都有一个遵循?ElementType?Array模式的名称,其中?ElementType?是表格中的元素类型之一。这意味着类型化数组有 11 个构造函数:
-
Float32Array,Float64Array -
Int8Array,Int16Array,Int32Array,BigInt64Array -
Uint8Array,Uint8ClampedArray,Uint16Array,Uint32Array,BigUint64Array
每个构造函数都有四个重载版本-它的行为取决于它接收的参数数量以及它们的类型:
-
new ?ElementType?Array(buffer: ArrayBuffer, byteOffset=0, length=0)创建一个新的
?ElementType?Array,其缓冲区为buffer。它从给定的byteOffset开始访问缓冲区,并具有给定的length。请注意,length计算类型化数组的元素(每个元素 1-8 个字节),而不是字节。 -
new ?ElementType?Array(length=0)创建一个具有给定
length和适当缓冲区的新?ElementType?Array。缓冲区的大小以字节为单位:length * ?ElementType?Array.BYTES_PER_ELEMENT -
new ?ElementType?Array(source: TypedArray)创建一个
?ElementType?Array的新实例,其元素具有与source的元素相同的值,但被强制转换为ElementType。 -
new ?ElementType?Array(source: ArrayLike<bigint>)(BigInt64Array,BigUint64Array) -
new ?ElementType?Array(source: ArrayLike<number>)(所有其他类型化数组)创建一个新的
?ElementType?Array的实例,其元素具有与source的元素相同的值,但被强制转换为ElementType。有关类似数组的对象的更多信息,请参阅§31.5“类似数组的对象”。
32.6.4??ElementType?Array的静态属性
-
?ElementType?Array.BYTES_PER_ELEMENT: number计算存储单个元素所需的字节数:
> Uint8Array.BYTES_PER_ELEMENT 1 > Int16Array.BYTES_PER_ELEMENT 2 > Float64Array.BYTES_PER_ELEMENT 8
32.6.5??ElementType?Array.prototype的属性
-
.BYTES_PER_ELEMENT: number与
?ElementType?Array.BYTES_PER_ELEMENT相同。
32.7?快速参考:DataViews
32.7.1?new DataView()
-
new DataView(buffer: ArrayBuffer, byteOffset=0, byteLength=buffer.byteLength-byteOffset)创建一个新的 DataView,其数据存储在 ArrayBuffer
buffer中。默认情况下,新的 DataView 可以访问整个buffer。最后两个参数允许您更改这一点。
32.7.2?DataView.prototype的属性
在本节的其余部分,?ElementType?指的是:
-
Int8,Int16,Int32,BigInt64 -
Uint8,Uint16,Uint32,BigUint64 -
Float32,Float64
这些是DataView.prototype的属性:
-
get .buffer(): ArrayBuffer返回此 DataView 的 ArrayBuffer。
-
get .byteLength(): number返回此 DataView 可以访问多少字节。
-
get .byteOffset(): number返回此 DataView 开始访问其缓冲区中的字节的偏移量。
-
.get?ElementType?(byteOffset: number, littleEndian=false): bigint(BigInt64,BigUint64).get?ElementType?(byteOffset: number, littleEndian=false): number(所有其他元素类型)从此 DataView 的缓冲区中读取值。
-
.set?ElementType?(byteOffset: number, value: bigint, littleEndian=false): void(BigInt64,BigUint64).set?ElementType?(byteOffset: number, value: number, littleEndian=false): void(所有其他元素类型)将
value写入此 DataView 的缓冲区。
三十三、地图(Map)
原文:
exploringjs.com/impatient-js/ch_maps.html译者:飞龙
-
33.1?使用地图
-
33.1.1?创建地图
-
33.1.2?复制地图
-
33.1.3?处理单个条目
-
33.1.4?确定地图的大小并清除它
-
33.1.5?获取地图的键和值
-
33.1.6?获取地图的条目
-
33.1.7?按插入顺序列出:条目、键、值
-
33.1.8?在地图和对象之间转换
-
-
33.2?示例:计算字符
-
33.3?关于地图键的一些细节(高级)
- 33.3.1?哪些键被视为相等?
-
33.4?地图操作缺失
-
33.4.1?映射和过滤地图
-
33.4.2?组合地图
-
-
33.5?快速参考:
Map<K,V>-
33.5.1?构造函数
-
33.5.2?
Map<K,V>.prototype:处理单个条目 -
33.5.3?
Map<K,V>.prototype:处理所有条目 -
33.5.4?
Map<K,V>.prototype:迭代和循环 -
33.5.5?本节的来源
-
-
33.6?常见问题:地图
-
33.6.1?何时应该使用地图,何时应该使用对象?
-
33.6.2?何时我会使用对象作为地图中的键?
-
33.6.3?地图为什么保留插入顺序?
-
33.6.4?地图为什么有
.size,而数组有.length?
-
在 ES6 之前,JavaScript 没有字典的数据结构,并且(滥用)对象作为从字符串到任意值的字典。ES6 引入了地图,这是从任意值到任意值的字典。
33.1?使用地图
Map的实例将键映射到值。单个键值映射称为条目。
33.1.1?创建地图
有三种常见的创建地图的方法。
首先,您可以使用没有任何参数的构造函数创建一个空地图:
const emptyMap = new Map();
assert.equal(emptyMap.size, 0);
其次,您可以将可迭代对象(例如数组)传递给构造函数的键值“对”(具有两个元素的数组):
const map = new Map([
[1, 'one'],
[2, 'two'],
[3, 'three'], // trailing comma is ignored
]);
第三,.set()方法向地图添加条目,并且是可链接的:
const map = new Map()
.set(1, 'one')
.set(2, 'two')
.set(3, 'three');
33.1.2?复制地图
正如我们将在后面看到的,地图也是键值对的可迭代对象。因此,您可以使用构造函数创建地图的副本。该副本是浅层的:键和值是相同的;它们不是重复的。
const original = new Map()
.set(false, 'no')
.set(true, 'yes');
const copy = new Map(original);
assert.deepEqual(original, copy);
33.1.3?处理单个条目
.set()和.get()用于写入和读取值(给定键)。
const map = new Map();
map.set('foo', 123);
assert.equal(map.get('foo'), 123);
// Unknown key:
assert.equal(map.get('bar'), undefined);
// Use the default value '' if an entry is missing:
assert.equal(map.get('bar') ?? '', '');
.has()检查地图是否具有具有给定键的条目。.delete()删除条目。
const map = new Map([['foo', 123]]);
assert.equal(map.has('foo'), true);
assert.equal(map.delete('foo'), true)
assert.equal(map.has('foo'), false)
33.1.4?确定地图的大小并清除它
.size包含地图中的条目数。.clear()删除地图的所有条目。
const map = new Map()
.set('foo', true)
.set('bar', false)
;
assert.equal(map.size, 2)
map.clear();
assert.equal(map.size, 0)
33.1.5?获取地图的键和值
.keys()返回地图的键的可迭代对象:
const map = new Map()
.set(false, 'no')
.set(true, 'yes')
;
for (const key of map.keys()) {
console.log(key);
}
// Output:
// false
// true
我们使用Array.from()将.keys()返回的可迭代对象转换为数组:
assert.deepEqual(
Array.from(map.keys()),
[false, true]);
.values()的工作原理类似于.keys(),但是针对值而不是键。
33.1.6?获取地图的条目
.entries()返回地图的条目的可迭代对象。
const map = new Map()
.set(false, 'no')
.set(true, 'yes')
;
for (const entry of map.entries()) {
console.log(entry);
}
// Output:
// [false, 'no']
// [true, 'yes']
Array.from() 将 .entries() 返回的可迭代对象转换为数组:
assert.deepEqual(
Array.from(map.entries()),
[[false, 'no'], [true, 'yes']]);
地图实例也是条目的可迭代对象。在下面的代码中,我们使用 解构 来访问 map 的键和值:
for (const [key, value] of map) {
console.log(key, value);
}
// Output:
// false, 'no'
// true, 'yes'
33.1.7?按插入顺序列出:条目、键、值
地图记录了条目创建的顺序,并在列出条目、键或值时遵守该顺序:
const map1 = new Map([
['a', 1],
['b', 2],
]);
assert.deepEqual(
Array.from(map1.keys()), ['a', 'b']);
const map2 = new Map([
['b', 2],
['a', 1],
]);
assert.deepEqual(
Array.from(map2.keys()), ['b', 'a']);
33.1.8?在地图和对象之间转换
只要地图只使用字符串和符号作为键,就可以将其转换为对象(通过 Object.fromEntries()):
const map = new Map([
['a', 1],
['b', 2],
]);
const obj = Object.fromEntries(map);
assert.deepEqual(
obj, {a: 1, b: 2});
您还可以使用字符串或符号键将对象转换为地图(通过 Object.entries()):
const obj = {
a: 1,
b: 2,
};
const map = new Map(Object.entries(obj));
assert.deepEqual(
map, new Map([['a', 1], ['b', 2]]));
33.2?示例:计算字符
countChars() 返回一个将字符映射到出现次数的地图。
function countChars(chars) {
const charCounts = new Map();
for (let ch of chars) {
ch = ch.toLowerCase();
const prevCount = charCounts.get(ch) ?? 0;
charCounts.set(ch, prevCount+1);
}
return charCounts;
}
const result = countChars('AaBccc');
assert.deepEqual(
Array.from(result),
[
['a', 2],
['b', 1],
['c', 3],
]
);
33.3?关于地图键的一些细节(高级)
任何值都可以是一个键,甚至是一个对象:
const map = new Map();
const KEY1 = {};
const KEY2 = {};
map.set(KEY1, 'hello');
map.set(KEY2, 'world');
assert.equal(map.get(KEY1), 'hello');
assert.equal(map.get(KEY2), 'world');
33.3.1?哪些键被认为是相等的?
大多数地图操作需要检查一个值是否等于其中一个键。它们通过内部操作 SameValueZero 来进行,它的工作方式类似于 ===,但认为 NaN 等于它自己。
因此,您可以像任何其他值一样在地图中使用 NaN 作为键:
> const map = new Map();
> map.set(NaN, 123);
> map.get(NaN)
123
不同的对象总是被认为是不同的。这是无法改变的事情(但是 - 配置键相等性在 TC39 的长期路线图上)。
> new Map().set({}, 1).set({}, 2).size
2
33.4?缺失的地图操作
33.4.1?映射和过滤地图
您可以对数组进行 .map() 和 .filter(),但对于地图没有这样的操作。解决方法是:
-
将地图转换为 [键,值] 对的数组。
-
地图或过滤数组。
-
将结果转换回地图。
我将使用以下地图来演示它是如何工作的。
const originalMap = new Map()
.set(1, 'a')
.set(2, 'b')
.set(3, 'c');
映射 originalMap:
const mappedMap = new Map( // step 3
Array.from(originalMap) // step 1
.map(([k, v]) => [k * 2, '_' + v]) // step 2
);
assert.deepEqual(
Array.from(mappedMap),
[[2,'_a'], [4,'_b'], [6,'_c']]);
过滤 originalMap:
const filteredMap = new Map( // step 3
Array.from(originalMap) // step 1
.filter(([k, v]) => k < 3) // step 2
);
assert.deepEqual(Array.from(filteredMap),
[[1,'a'], [2,'b']]);
Array.from() 将任何可迭代对象转换为数组。
33.4.2?合并地图
没有合并地图的方法,这就是为什么我们必须使用类似于上一节的解决方法。
让我们合并以下两个地图:
const map1 = new Map()
.set(1, '1a')
.set(2, '1b')
.set(3, '1c')
;
const map2 = new Map()
.set(2, '2b')
.set(3, '2c')
.set(4, '2d')
;
要合并 map1 和 map2,我们创建一个新数组,并将 map1 和 map2 的条目(键值对)扩展(...)到其中(通过迭代)。然后我们将数组转换回地图。所有这些都在 A 行中完成:
const combinedMap = new Map([...map1, ...map2]); // (A)
assert.deepEqual(
Array.from(combinedMap), // convert to Array for comparison
[ [ 1, '1a' ],
[ 2, '2b' ],
[ 3, '2c' ],
[ 4, '2d' ] ]
);
 练习:合并两个地图
练习:合并两个地图
exercises/maps/combine_maps_test.mjs
33.5?快速参考:Map<K,V>
注意:为了简洁起见,我假装所有键都具有相同的类型 K,所有值都具有相同的类型 V。
33.5.1?构造函数
-
new Map<K, V>(entries?: Iterable<[K, V]>)^([ES6])如果您不提供参数
entries,则会创建一个空地图。如果您提供一个 [键,值] 对的可迭代对象,则这些对将作为条目添加到地图中。例如:const map = new Map([ [ 1, 'one' ], [ 2, 'two' ], [ 3, 'three' ], // trailing comma is ignored ]);
33.5.2?Map<K,V>.prototype: 处理单个条目
-
.get(key: K): V^([ES6])返回此地图中将
key映射到的value。如果在此地图中没有键key,则返回undefined。const map = new Map([[1, 'one'], [2, 'two']]); assert.equal(map.get(1), 'one'); assert.equal(map.get(5), undefined); -
.set(key: K, value: V): this^([ES6])将给定的键映射到给定的值。如果已经有一个键是
key的条目,它将被更新。否则,将创建一个新条目。此方法返回this,这意味着您可以链接它。const map = new Map([[1, 'one'], [2, 'two']]); map.set(1, 'ONE!') .set(3, 'THREE!'); assert.deepEqual( Array.from(map.entries()), [[1, 'ONE!'], [2, 'two'], [3, 'THREE!']]); -
.has(key: K): boolean^([ES6])返回此地图中是否存在给定的键。
const map = new Map([[1, 'one'], [2, 'two']]); assert.equal(map.has(1), true); // key exists assert.equal(map.has(5), false); // key does not exist -
.delete(key: K): boolean^([ES6])如果有一个键是
key的条目,它将被移除并返回true。否则,什么也不会发生,并返回false。const map = new Map([[1, 'one'], [2, 'two']]); assert.equal(map.delete(1), true); assert.equal(map.delete(5), false); // nothing happens assert.deepEqual( Array.from(map.entries()), [[2, 'two']]);
33.5.3?Map<K,V>.prototype: 处理所有条目
-
get .size: number^([ES6])返回此地图有多少条目。
const map = new Map([[1, 'one'], [2, 'two']]); assert.equal(map.size, 2); -
.clear(): void^([ES6])从此地图中删除所有条目。
const map = new Map([[1, 'one'], [2, 'two']]); assert.equal(map.size, 2); map.clear(); assert.equal(map.size, 0);
33.5.4?Map<K,V>.prototype: 迭代和循环
迭代和循环都是按照条目添加到地图的顺序进行的。
-
.entries(): Iterable<[K,V]>^([ES6])返回一个可迭代对象,其中每个条目都有一个[key, value]对。这些对是长度为 2 的数组。
const map = new Map([[1, 'one'], [2, 'two']]); for (const entry of map.entries()) { console.log(entry); } // Output: // [1, 'one'] // [2, 'two'] -
.forEach(callback: (value: V, key: K, theMap: Map<K,V>) => void, thisArg?: any): void^([ES6])第一个参数是一个回调,对此地图中的每个条目调用一次。如果提供了
thisArg,则对每次调用都将其设置为this。否则,将this设置为undefined。const map = new Map([[1, 'one'], [2, 'two']]); map.forEach((value, key) => console.log(value, key)); // Output: // 'one', 1 // 'two', 2 -
.keys(): Iterable<K>^([ES6])返回此地图中所有键的可迭代对象。
const map = new Map([[1, 'one'], [2, 'two']]); for (const key of map.keys()) { console.log(key); } // Output: // 1 // 2 -
.values(): Iterable<V>^([ES6])返回此地图中所有值的可迭代对象。
const map = new Map([[1, 'one'], [2, 'two']]); for (const value of map.values()) { console.log(value); } // Output: // 'one' // 'two' -
[Symbol.iterator](): Iterable<[K,V]>^([ES6])迭代地图的默认方式。与
.entries()相同。const map = new Map([[1, 'one'], [2, 'two']]); for (const [key, value] of map) { console.log(key, value); } // Output: // 1, 'one' // 2, 'two'
33.5.5 本节的来源
33.6 常见问题:地图
33.6.1 何时应该使用地图,何时应该使用对象?
如果您需要一个类似字典的数据结构,其键既不是字符串也不是符号,那么您别无选择,必须使用地图。
然而,如果您的键是字符串或符号,则必须决定是否使用对象。一个粗略的一般指导原则是:
-
是否有一组在开发时已知的键?
然后使用对象
obj,并通过固定键访问值:const value = obj.key; -
键的集合是否可以在运行时更改?
然后使用地图
map,并通过存储在变量中的键访问值:const theKey = 123; map.get(theKey);
33.6.2 何时应该将对象用作地图中的键?
通常希望地图键通过值进行比较(如果两个键具有相同的内容,则认为它们相等)。这排除了对象。但是,对象作为键有一个用例:将数据外部附加到对象上。但是,WeakMaps 更适合这种用例,其中条目不会阻止键被垃圾回收(有关详细信息,请参阅下一章)。
33.6.3 为什么地图保留插入条目的顺序?
原则上,地图是无序的。排序条目的主要原因是列出条目、键或值的操作是确定性的。例如,这有助于测试。
33.6.4 为什么地图有.size,而数组有.length?
在 JavaScript 中,可索引的序列(例如数组和字符串)具有.length,而不可索引的集合(例如地图和集合)具有.size:
-
.length基于索引;它始终是最高索引加一。 -
.size计算集合中元素的数量。
 测验
测验
参见测验应用程序。
三十四、WeakMaps (WeakMap) (高级)
原文:
exploringjs.com/impatient-js/ch_weakmaps.html译者:飞龙
-
34.1?WeakMaps 是黑盒
-
34.2?WeakMap 的键是弱引用
-
34.2.1?所有 WeakMap 的键必须是对象
-
34.2.2?用例:将值附加到对象
-
-
34.3?示例
-
34.3.1?通过 WeakMaps 缓存计算结果
-
34.3.2?在 WeakMaps 中保持私有数据
-
-
34.4?WeakMap API
WeakMaps 类似于 Maps,但有以下区别:
-
它们是黑盒,只有拥有 WeakMap 和键的人才能访问值。
-
WeakMap 的键是弱引用:如果一个对象是 WeakMap 的键,它仍然可以被垃圾回收。这让我们可以使用 WeakMap 来附加数据到对象上。
接下来的两节将更详细地讨论这意味着什么。
34.1?WeakMaps 是黑盒
不可能检查 WeakMap 内部的内容:
-
例如,你不能迭代或循环遍历键、值或条目。你也不能计算大小。
-
此外,你也不能清除 WeakMap - 你必须创建一个新的实例。
这些限制实现了一个安全属性。引用Mark Miller:
WeakMap/键对值的映射只能被拥有 WeakMap 和键的人观察或影响。使用
clear(),只拥有 WeakMap 的人将能够影响 WeakMap 和键到值的映射。
34.2?WeakMap 的键是弱引用
WeakMap 的键被称为弱引用:通常,如果一个对象引用另一个对象,那么只要前者存在,后者就不能被垃圾回收。但是对于 WeakMap 来说,情况不同:如果一个对象是键,而且没有其他地方引用它,那么它可以在 WeakMap 仍然存在的情况下被垃圾回收。这也导致相应的条目被移除(但没有办法观察到)。
34.2.1?所有 WeakMap 的键必须是对象
所有 WeakMap 的键必须是对象。如果使用原始值,会报错:
> const wm = new WeakMap();
> wm.set(123, 'test')
TypeError: Invalid value used as weak map key
如果使用原始值作为键,WeakMaps 将不再是黑盒。但是鉴于原始值永远不会被垃圾回收,你也不会从弱引用键中获益,可以使用普通的 Map。
34.2.2?用例:将值附加到对象
这是 WeakMaps 的主要用例:你可以使用它们来外部附加值到对象上 - 例如:
const wm = new WeakMap();
{
const obj = {};
wm.set(obj, 'attachedValue'); // (A)
}
// (B)
在 A 行,我们将一个值附加到obj。在 B 行,obj可能已经被垃圾回收,尽管wm仍然存在。这种将值附加到对象的技术等同于将该对象的属性存储在外部。如果wm是一个属性,前面的代码将如下所示:
{
const obj = {};
obj.wm = 'attachedValue';
}
34.3?示例
34.3.1?通过 WeakMaps 缓存计算结果
使用 WeakMaps,你可以将先前计算的结果与对象关联起来,而不必担心内存管理。下面的函数countOwnKeys()就是一个例子:它在 WeakMap cache中缓存先前的结果。
const cache = new WeakMap();
function countOwnKeys(obj) {
if (cache.has(obj)) {
return [cache.get(obj), 'cached'];
} else {
const count = Object.keys(obj).length;
cache.set(obj, count);
return [count, 'computed'];
}
}
如果我们使用这个函数和一个对象obj,你会发现结果只在第一次调用时计算,而第二次调用时使用了缓存值:
> const obj = { foo: 1, bar: 2};
> countOwnKeys(obj)
[2, 'computed']
> countOwnKeys(obj)
[2, 'cached']
34.3.2?在 WeakMaps 中保持私有数据
在下面的代码中,WeakMaps _counter和_action用于存储Countdown实例的虚拟属性的值:
const _counter = new WeakMap();
const _action = new WeakMap();
class Countdown {
constructor(counter, action) {
_counter.set(this, counter);
_action.set(this, action);
}
dec() {
let counter = _counter.get(this);
counter--;
_counter.set(this, counter);
if (counter === 0) {
_action.get(this)();
}
}
}
// The two pseudo-properties are truly private:
assert.deepEqual(
Object.keys(new Countdown()),
[]);
这是Countdown的使用方式:
let invoked = false;
const cd = new Countdown(3, () => invoked = true);
cd.dec(); assert.equal(invoked, false);
cd.dec(); assert.equal(invoked, false);
cd.dec(); assert.equal(invoked, true);
 练习:WeakMaps 用于私有数据
练习:WeakMaps 用于私有数据
exercises/weakmaps/weakmaps_private_data_test.mjs
34.4?WeakMap API
WeakMap的构造函数和四个方法与它们的Map等价物一样工作:
-
new WeakMap<K, V>(entries?: Iterable<[K, V]>)^([ES6]) -
.delete(key: K) : boolean^([ES6]) -
.get(key: K) : V^([ES6]) -
.has(key: K) : boolean^([ES6]) -
.set(key: K, value: V) : this^([ES6])
 测验
测验
查看测验应用。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- JSP内置对象(9大内置对象和4种作用域)
- 公共卫生改善_智慧公厕系统解决方案_提升公卫体验
- Python:类型标注解决循环引用问题most likely due to a circular import
- STM32入门教程-2023版【2-2】总结新建工程顺序及工程架构
- Java物资采购网站(毕设源码+mysql+lw)
- 学生成绩管理系统,医院管理系统,在线考试系统,招聘信息管理系统,超市管理系统,校园志愿者管理系统,企业员工管理系统,SSM校园二手交易网站,高校图书馆座位预约系统,人事管理系统,私人健身教练预约管理系
- 无懈可击的防泄密之旅:迅软DSE在民营银行的成功实践
- 【手写数据库toadb】01 开发数据库内核准备阶段-开发环境准备
- 【梅西迭代姊妹篇2】BCH码和m序列参数估计(梅西迭代算法求多项式的C语言实现)
- 数据结构线性表之顺序表