Kafka-服务端-网络层
Reactor模式
Kafka网络层采用的是Reactor模式,是一种基于事件驱动的模式。熟悉Java编程应该了解JavaNIO提供了实现Reactor模式的API。常见的单线程Java NIO的编程模式如图所示。
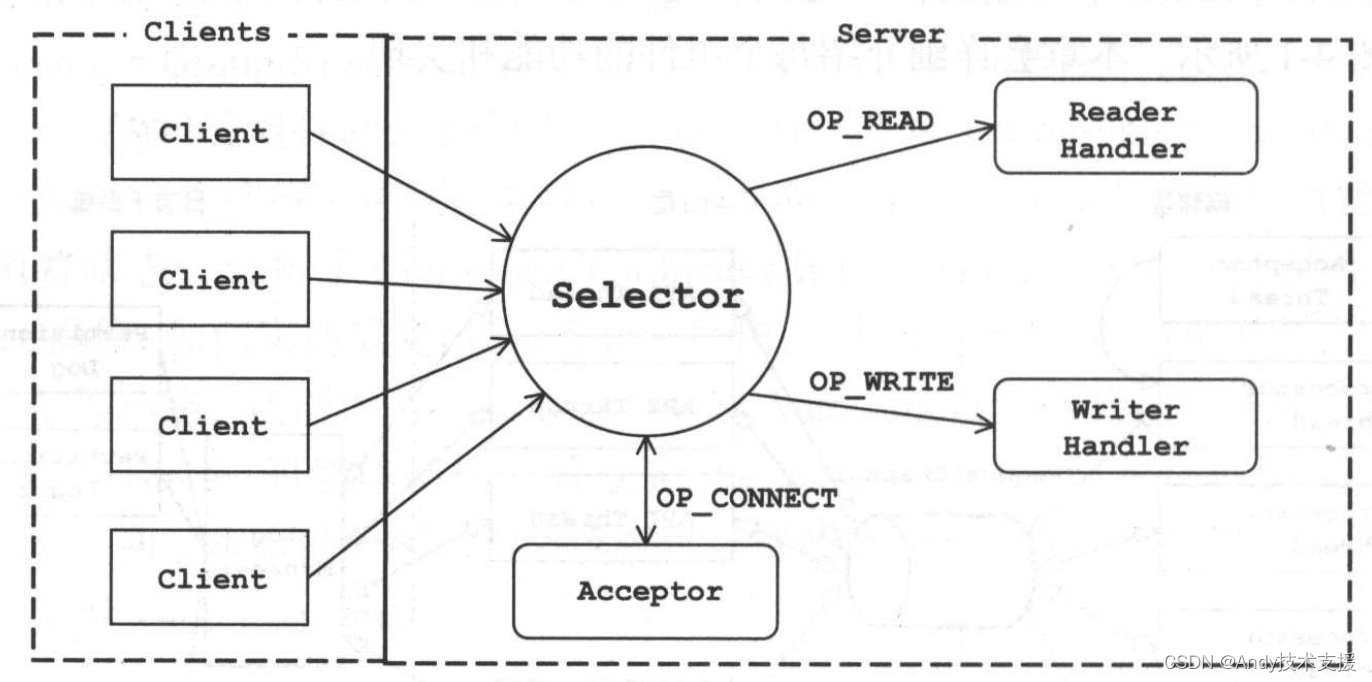
为了满足高并发的需求,也为了充分利用服务器的资源,服务端需要使用多线程来执行业务逻辑。我们对上述架构稍作调整,将网络读写的逻辑与业务处理的逻辑进行拆分,让其由不同的线程池来处理,从而实现多线程处理。设计架构如图所示。
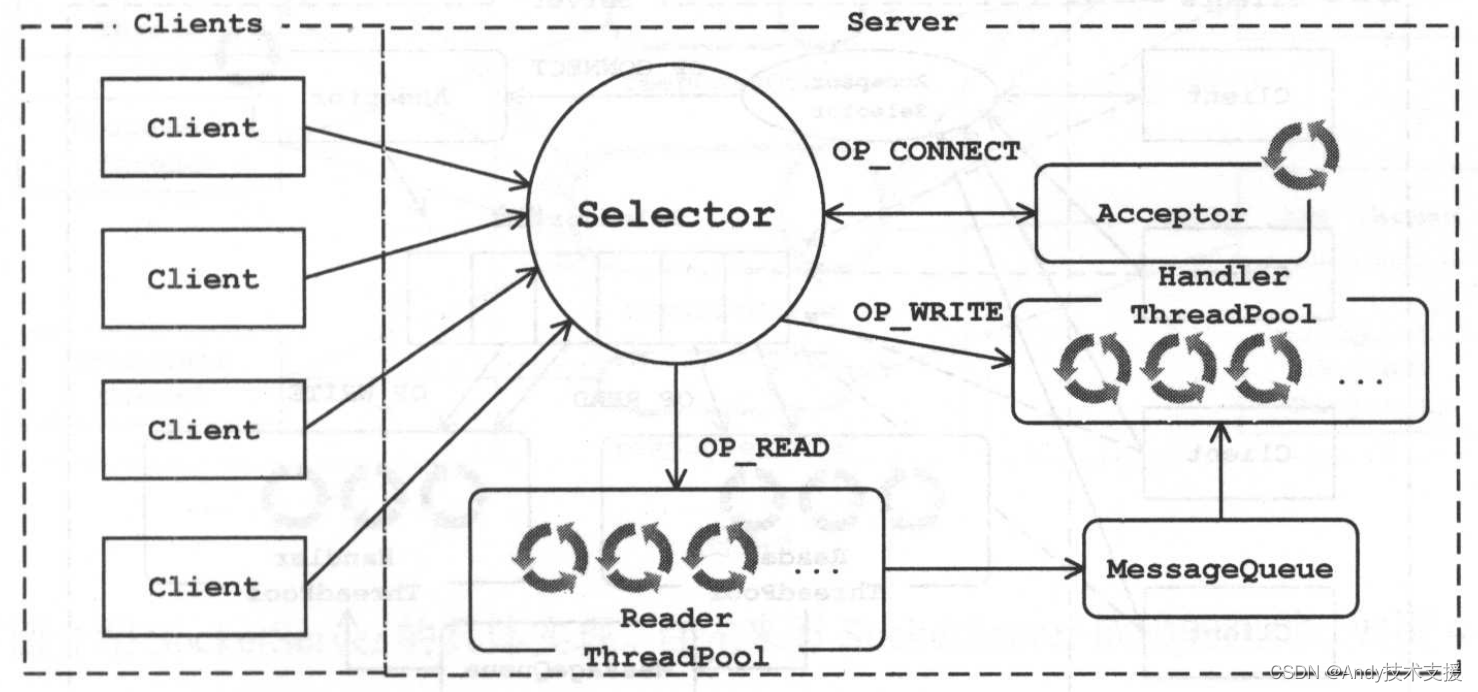
通过将网络处理与业务逻辑进行切分后实现了上述设计,此设计中读取、写入、业务处理都实现了多线程处理,不再存在性能瓶颈。
但是,如果同一时间出现大量I/O事件,单个Selector就可能在分发事件时阻塞(或延时)而成为瓶颈。
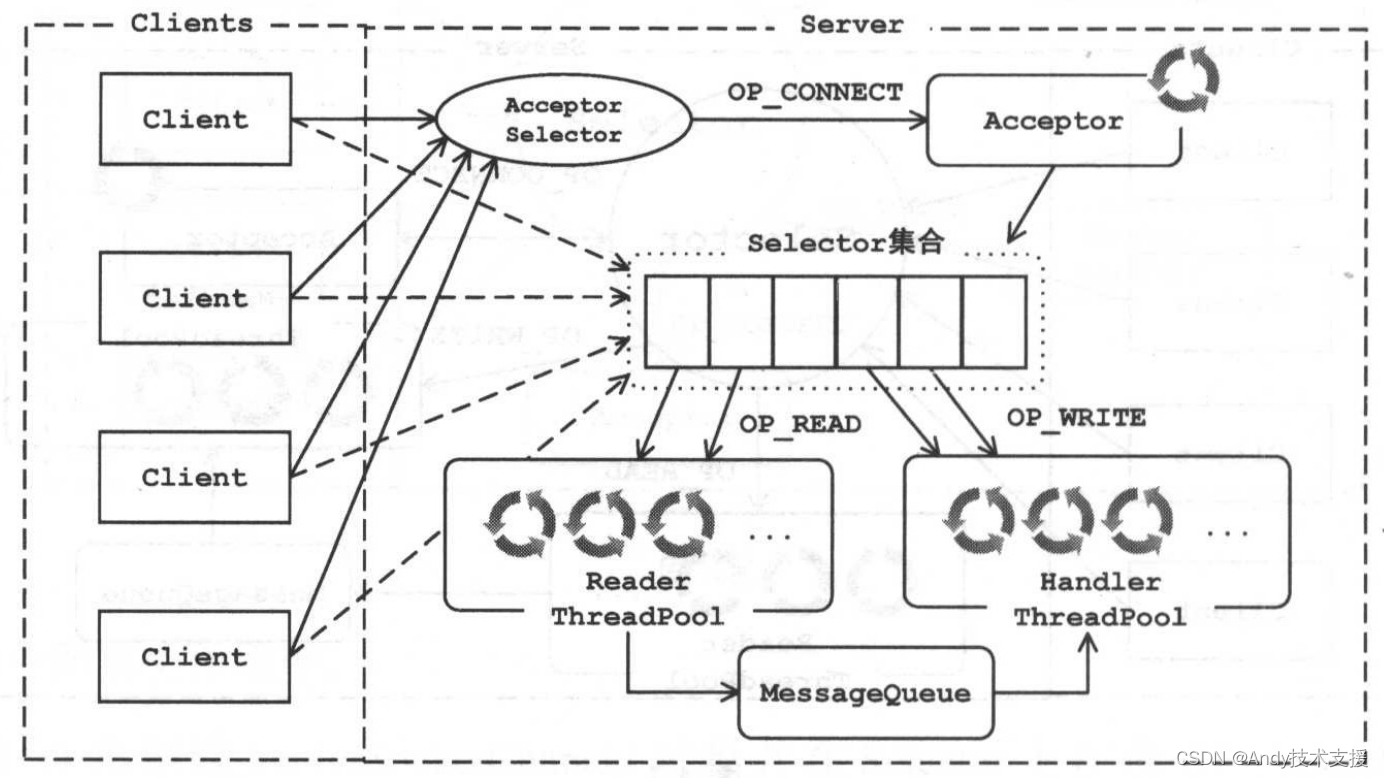
我们可以将上述设计中单独的Selector对象扩展成多个,让它们监听不同的I/O事件,这样就可以避免单个Selector带来的瓶颈问题。设计如图所示。
SocketServer
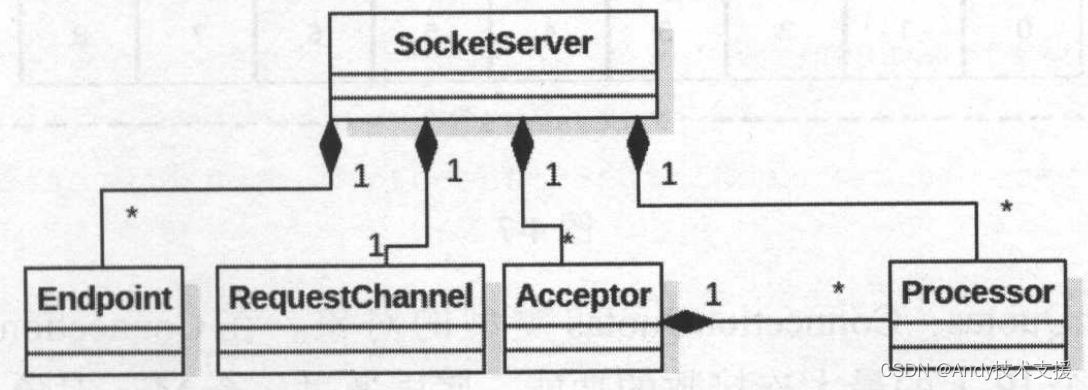
Kafka的网络层是采用多线程、多个Selector的设计实现的。核心类是SocketServer,其中包含一个Acceptor用于接受并处理所有的新连接,每个Acceptor对应多个Processor线程,每个Processor线程拥有自己的Selector,主要用于从连接中读取请求和写回响应。每个Acceptor对应多个Handler线程,主要用于处理请求并将产生响应返回给Processor线程。Processor线程与Handler线程之间通过RequestChannel进行通信。整个网络层的结构如图所示。
下面介绍SocketServer的具体实现。首先来看SocketServer依赖的组件,如图所示。
AbstractServerThread
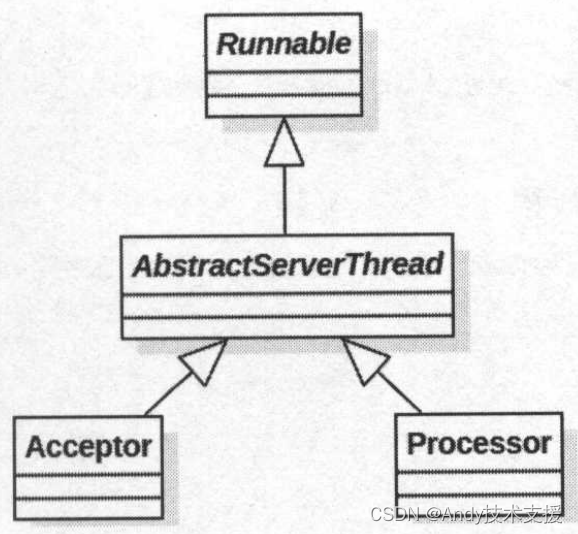
Acceptor和Processor都继承了AbstractServerThread,如图所示,AbstractServerThread是实现了Runnable接口的抽象类。在AbstractServerThread中为Acceptor和Processor提供了一些启动关闭相关的控制类方法。
Acceptor
Acceptor的主要功能是接收客户端建立连接的请求,创建Socket连接并分配给Processor处理。
Acceptor中有两个比较重要的字段:一个是Java NIO Selector,注意不要与前面介绍的KSelector混淆;二是用于接收客户端请求的ServerSocketChannel对象。在创建Acceptor时会初始化上面两个字段,同时还会创建并启动其管理的Processors线程。
Acceptor.accept()方法实现了对OP_ACCEPT事件的处理,它会创建SocketChannel并将其交给Processoraccept方法处理,同时还会增加ConnectionQuotas中记录的连接数。
Processor
Processor主要用于完成读取请求和写回响应的操作,Processor不参与具体业务逻辑的处理。Processor的核心字段如下所述,在创建Processor对象时会初始化这些字段。
- newConnections:ConcurrentLinkedQueue[SocketChannel]类型,其中保存了由此Processor处理的新建的SocketChannel。
- inflightResponses:保存未发送的响应。有读者可能会将inflightResponses与客户端的InFlightRequests进行类比,但也要注意其区别,客户端并不会对服务端发送的响应消息再次发送确认,所以infightResponse中的响应会在发送成功后移除,而InFlightRequests中的请求是在收到响应后才移除。
- selector:KSelector类型,负责管理网络连接。
- requestChannel:Processor与Handler线程之间传递数据的队列。
在Acceptoraccept方法中创建的SocketChannel会通过Processor.accept方法交给Processor进行处理。
Processoraccpet方法接收到一个新的SocketChannel时会先将其放入newConnections队列中,然后会唤醒Processor线程来处理newConnections队列。
注意,newConnections队列由Acceptor线程和Processor线程并发操作,所以选择线程安全的ConcurrentLinkedQueue。
在Processor.run()方法中实现了从网络连接上读写数据的功能。run()方法的流程如图所示。

如果Response是SendAction类型,表示该Response需要发送给客户端,则查找对应的KafkaChannel,为其注册OP_WRITE事件,并将KafkaChannel.send字段指向待发送的Response对象。
同时还会将Response从responseQueue队列中移出,放入infightResponses中。如果关心OP_WRITE事件的取消时机,可以回顾KafkaChannel.send方法,即发送完一个完整的响应后,会取消此连接注册的OP_WRITE事件。
如果Response是NoOpAction类型,表示此连接暂无响应需要发送,则为KafkaChannel注册OP_READ,允许其继续读取请求。
如果Response是CloseConnectionAction类型,则关闭对应的连接。
RequestChannel
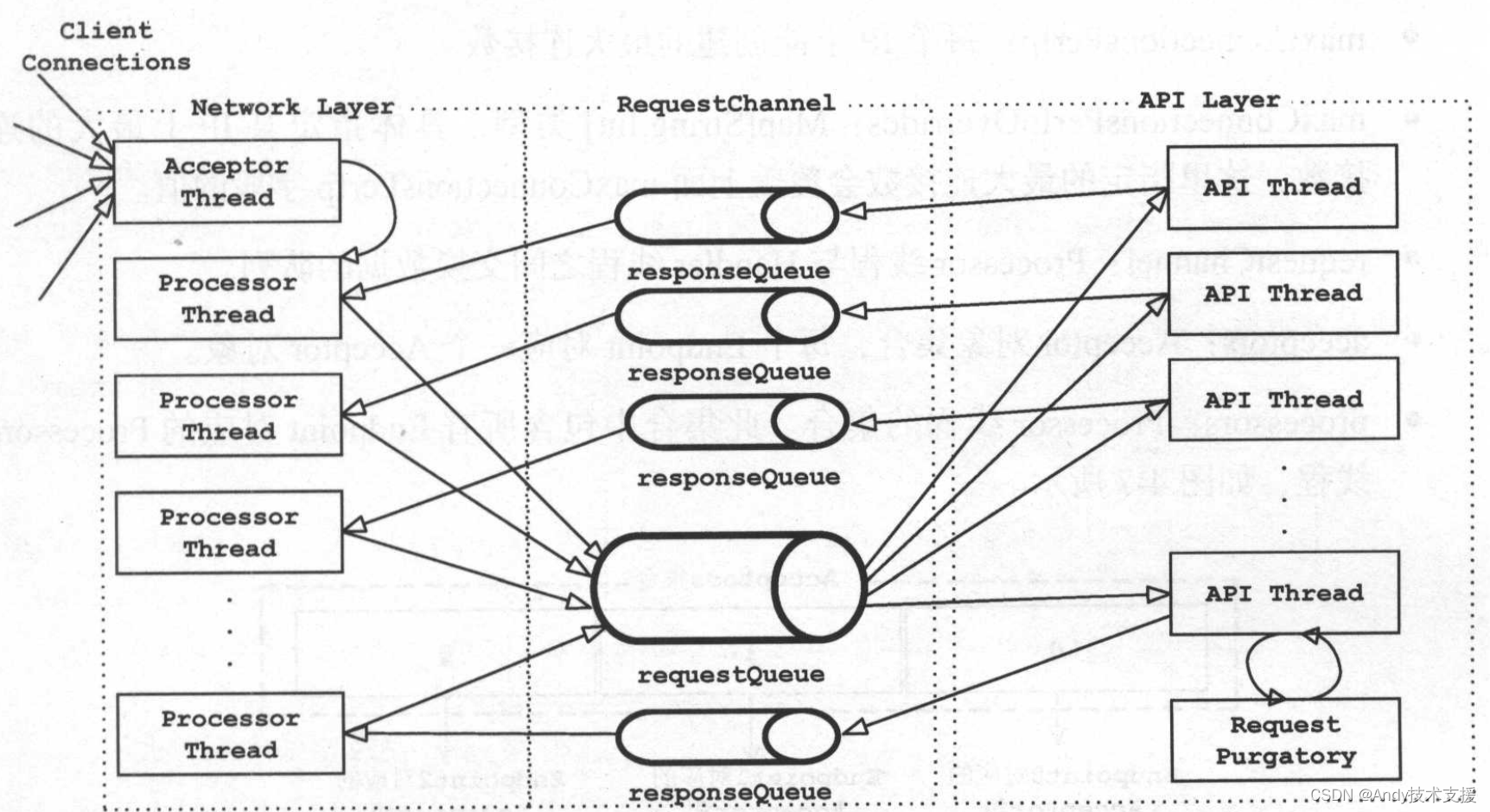
Processor线程与Handler线程之间传递数据是通过RequestChannel完成的。
在RequestChannel中包含了一个requestQueue队列和多个responseQueues队列,每个Processor线程对应一个responseQueue。
Processor线程将读取到的请求存入requestQueue中,Handler线程从requestQueue队列中取出请求进行处理;Handler线程处理请求产生的响应会存放到Processor对应的responseQueue中,Processor线程从其对应的responseQueue中取出响应并发送给客户端。RequestChannel的结构如图所示。
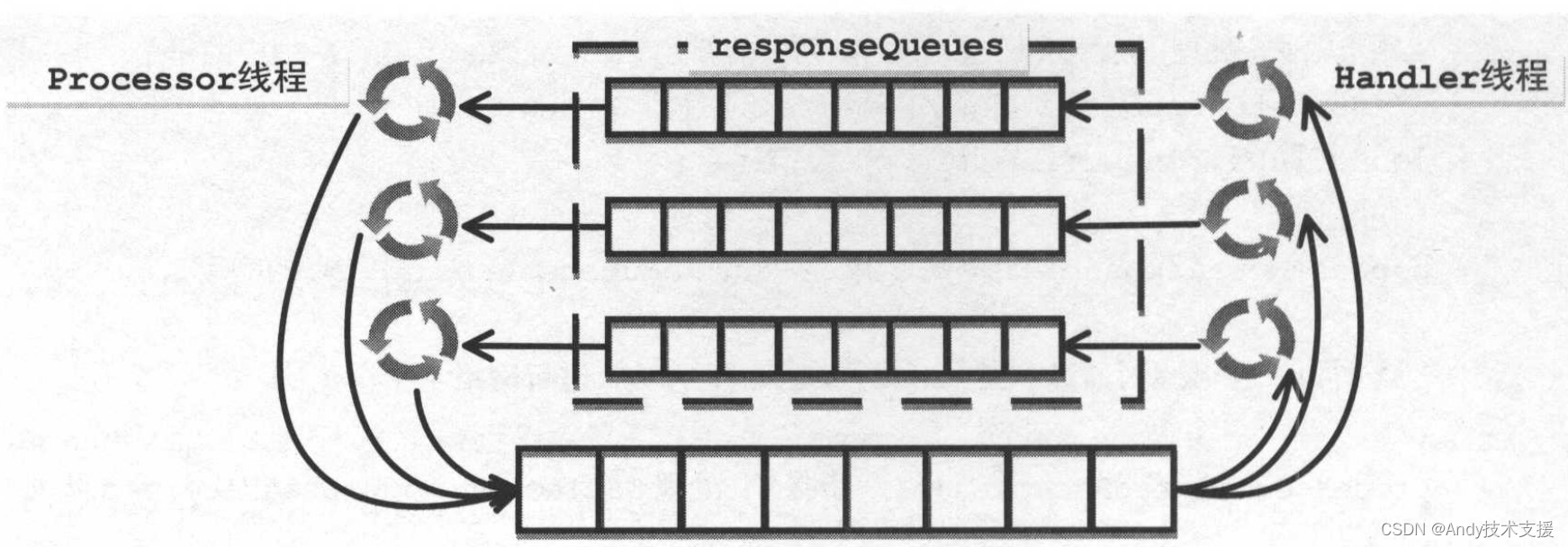
在RequestChannel中保存的是RequestChannel.Request和RequestChannel.Response两个类的对象。
RequestChannel.Request会对请求进行解析,形成requestld(请求类型 ID)、header(请求头)、body(请求体)等字段,供Handler线程使用,并提供了一些记录操作时间的字段供监控程序使用。
RequestChannel.Response需要注意其responseAction字段,有SendAction、NoOpAction、CloseConnectionAction三种 类 型。
当请求放入RequestChannel.requestQueue之后,会有多个Handler线程并发处理从其中取出请求处理,那如何保证客户端请求的顺序性呢?在Processorrun方法,其中有多处注册/取消OP_READ事件以及注册/取消OP_WRITE事件的操作,通过这些操作的组合可以保证每个连接上只有一个请求和一个对应的响应,从而实现请求的顺序性。
现在回头来总结一个请求数据从生产者发送到服务端的流转过程,如图所示。
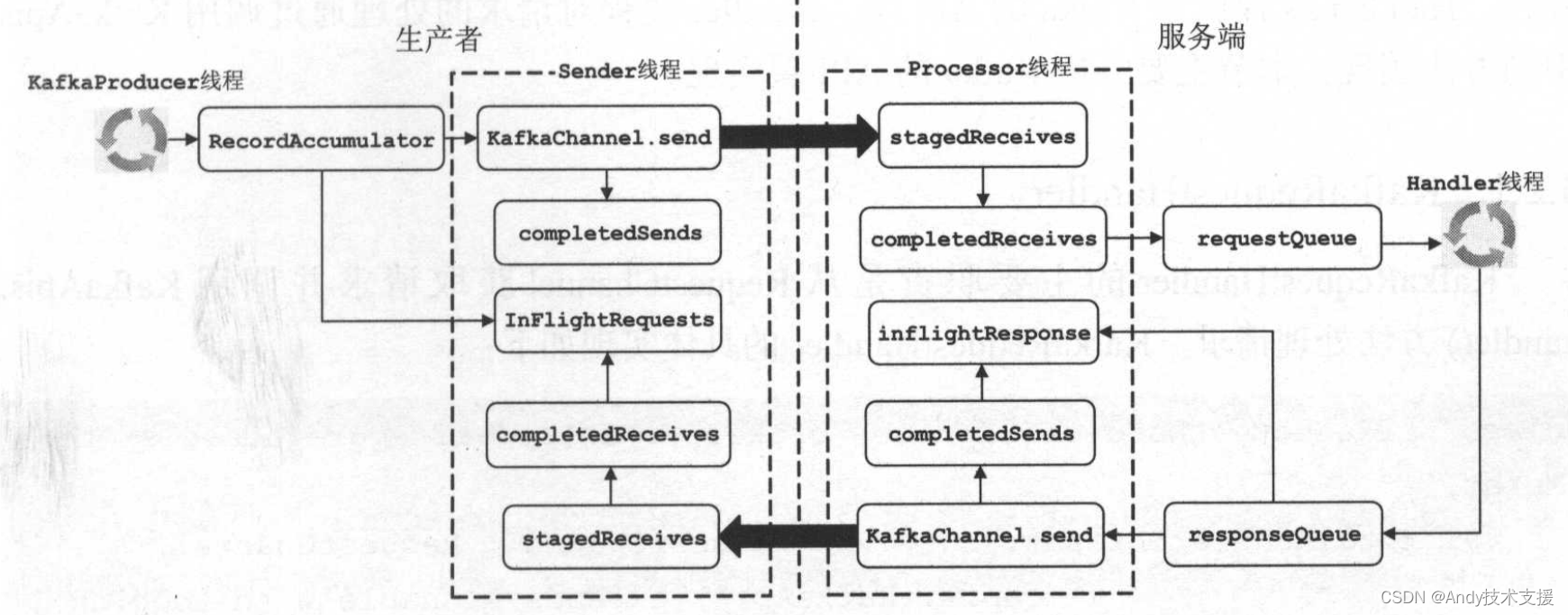
KafkaProducer线程创建ProducerRecord后,会将其缓存进RecordAccumulator。
Sender线程从RecordAccumulator中获取缓存的消息,放入KafkaChannel.send字段中等待发送,同时放入InFlightRequests队列中等待响应。
之后,客户端会通过KSelector将请求发送出去。
在服务端,Processor线程使用KSelector读取请求并暂存到stageReceives队列中,KSelector.poll方法结束后,请求被移转移到completeReceives队列中。之后,Processor将请求进行一些解析操作后,放入RequestChannel.requestQueue队列。
Handler线程会从RequestChannel.requestQueue队列中取出请求进行处理,将处理之后生成的响应放入RequestChannel.responseQueue队列。
Processor线程从其对应的RequestChannel.responseQueue队列中取出响应并放入inflightResponses队列中缓存,当响应发送出去之后会将其从inflightResponse中删除。生产者读取响应的过程与服务端读取请求的过程类似,主要的区别是生产者需要对InFlightRequest中的请求进行确认。
Kafka网络层的设计原理和实现就介绍到这里了。在高性能的分布式框架中经常采用这种Reactor模式的设计,例如,HDFS RPC框架的服务端、ZooKeeper等。也有实现了Reactor模式的框架,例如,Netty和Mina。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Java复习_2
- PostgreSQL.conf配置文件详解
- js 生成分享码或分享口令
- 中国人民大学与加拿大女王大学金融硕士适合什么样的群体呢?
- linux: netstat 与 ss 用法详解
- 源码级详解Spring的三级缓存,循环依赖的处理流程
- AUTOSAR组织引入了Rust语言的原因是什么?有哪些好处?与C++相比它有什么优点?并推荐一些入门学习Rust语言链接等
- MySQL数据库
- 限流原理与实践:固定窗口、滑动窗口、漏桶与令牌桶解析
- 【华为机试】2023年真题B卷(python)-数列描述