hadoop hive spark flink 安装
下载地址
ubuntu安装hadoop集群?
准备
| IP地址 | 主机名称 |
| 192.168.1.21 | node1 |
| 192.168.1.22 | node2 |
| 192.168.1.23 | node3 |
?
?
?
?
?上传
hadoop-3.3.5.tar.gz、jdk-8u391-linux-x64.tar.gz
JDK环境
node1、node2、node3三个节点
解压
tar -zxvf?jdk-8u391-linux-x64.tar.gz?

环境变量
?vim /etc/profile.d/JDK.sh
#!/bin/bash
export JAVA_HOME=/usr/local/jdk1.8.0_391
export PATH=$PATH:$JAVA_HOME/bin
jdk生效
source /etc/profile
hosts配置
vim /etc/hosts
192.168.1.21 node1
192.168.1.22 node2
192.168.1.23 node3
创建用户hadoop
adduser hadoop
配置免密登录
node1 hadoop用户中执行
ssh-keygen -t rsa

?cp ~/.ssh/id_rsa.pub ~/.ssh/authorized_keys
复制到其他节点

?确保不需要输入密码
hadoop@node1:~$ ssh node1
hadoop@node1:~$ ssh node2
hadoop@node1:~$ ssh node3
解压安装包
hadoop@node1:~$ mkdir -p apps
hadoop@node1:~$ tar -xzf hadoop-3.3.5.tar.gz -C apps
配置环境变量
export JAVA_HOME=/usr/local/jdk1.8.0_391
export HADOOP_HOME=/home/hadoop/apps/hadoop-3.3.5
export HADOOP_CONF_DIR=/home/hadoop/apps/hadoop-3.3.5/etc/hadoop
export YARN_CONF_DIR=/home/hadoop/apps/hadoop-3.3.5/etc/hadoop
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH?使环境变量生效
hadoop@node1:~$ source ~/.bashrc
配置Hadoop集群
Hadoop软件安装完成后,每个节点上的Hadoop都是独立的软件,需要进行配置才能组成Hadoop集群。Hadoop的配置文件在$HADOOP_HOME/etc/hadoop目录下,主要配置文件有6个:
hadoop-env.sh主要配置Hadoop环境相关的信息,比如安装路径、配置文件路径等;
core-site.xml是Hadoop的核心配置文件,主要配置了Hadoop的NameNode的地址、Hadoop产生的文件目录等信息;
hdfs-site.xml是HDFS分布式文件系统相关的配置文件,主要配置了文件的副本数、HDFS文件系统在本地对应的目录等;
mapred-site.xml是关于MapReduce的配置文件,主要配置MapReduce在哪里运行;
yarn-site.xml是Yarn相关的配置文件,主要配置了Yarn的管理节点ResourceManager的地址、NodeManager获取数据的方式等;
workers是集群中节点列表的配置文件,只有在这个文件里面配置了的节点才会加入到Hadoop集群中,否则就是一个独立节点。
这几个配置文件如果不存在,可以通过复制配置模板的方式创建,也可以通过创建新文件的方式创建。需要保证在集群的每个节点上这6个配置保持同步,可以在每个节点单独配置,也可以在一个节点上配置完成后同步到其他节点。
hadoop-env.sh配置
hadoop@node1:~$ vi $HADOOP_HOME/etc/hadoop/hadoop-env.sh
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export HADOOP_HOME=/home/hadoop/apps/hadoop-3.3.4
export HADOOP_CONF_DIR=/home/hadoop/apps/hadoop-3.3.4/etc/hadoop
export HADOOP_LOG_DIR=/home/hadoop/logs/hadoop
core-site.xml配置
hadoop@node1:~$ vi $HADOOP_HOME/etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/data/hadoop/temp</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>
</configuration>
hdfs-site.xml配置
hadoop@node1:~$ vi $HADOOP_HOME/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/data/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/data/hadoop/hdfs/data</value>
</property>
</configuration>
mapred-site.xml配置
hadoop@node1:~$ vi $HADOOP_HOME/etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_HOME/share/hadoop/mapreduce/*:$HADOOP_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
</configuration>
?yarn-site.xml配置
hadoop@node1:~$ vi $HADOOP_HOME/etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node1</value>
</property>
</configuration>
workers配置
hadoop@node1:~$ vi $HADOOP_HOME/etc/hadoop/workers
node1
node2
node3复制到其他节点
在node1上配置好环境变量及配置文件,可以手动再在其他节点上完成同样的配置,或者直接将node1的文件复制到其他节点。
hadoop@node1:~$ scp -r .bashrc apps node2:~/
hadoop@node1:~$ scp -r .bashrc apps node3:~/
格式化NameNode
在启动集群前,需要对NameNode进行格式化,在node1上执行以下命令:
hadoop@node1:~$ hdfs namenode -format
启动集群
在node1上执行start-all.sh命令启动集群。
hadoop@node1:~$ jps
55936 Jps
hadoop@node1:~$ start-all.sh
WARNING: Attempting to start all Apache Hadoop daemons as hadoop in 10 seconds.
WARNING: This is not a recommended production deployment configuration.
WARNING: Use CTRL-C to abort.
Starting namenodes on [node1]
Starting datanodes
node2: WARNING: /home/hadoop/logs/hadoop does not exist. Creating.
node3: WARNING: /home/hadoop/logs/hadoop does not exist. Creating.
Starting secondary namenodes [node1]
WARNING: YARN_CONF_DIR has been replaced by HADOOP_CONF_DIR. Using value of YARN_CONF_DIR.
Starting resourcemanager
WARNING: YARN_CONF_DIR has been replaced by HADOOP_CONF_DIR. Using value of YARN_CONF_DIR.
Starting nodemanagers
WARNING: YARN_CONF_DIR has been replaced by HADOOP_CONF_DIR. Using value of YARN_CONF_DIR.
node3: WARNING: YARN_CONF_DIR has been replaced by HADOOP_CONF_DIR. Using value of YARN_CONF_DIR.
node2: WARNING: YARN_CONF_DIR has been replaced by HADOOP_CONF_DIR. Using value of YARN_CONF_DIR.
node1: WARNING: YARN_CONF_DIR has been replaced by HADOOP_CONF_DIR. Using value of YARN_CONF_DIR.
hadoop@node1:~$ jps
57329 ResourceManager
57553 NodeManager
57027 SecondaryNameNode
58165 Jps
56437 NameNode
56678 DataNode
验证Hadoop?
上传一个文件到HDFS
hdfs dfs -put .bashrc /
访问HDFS
打开HDFS Web UI查看相关信息,默认端口9870。


访问YARN
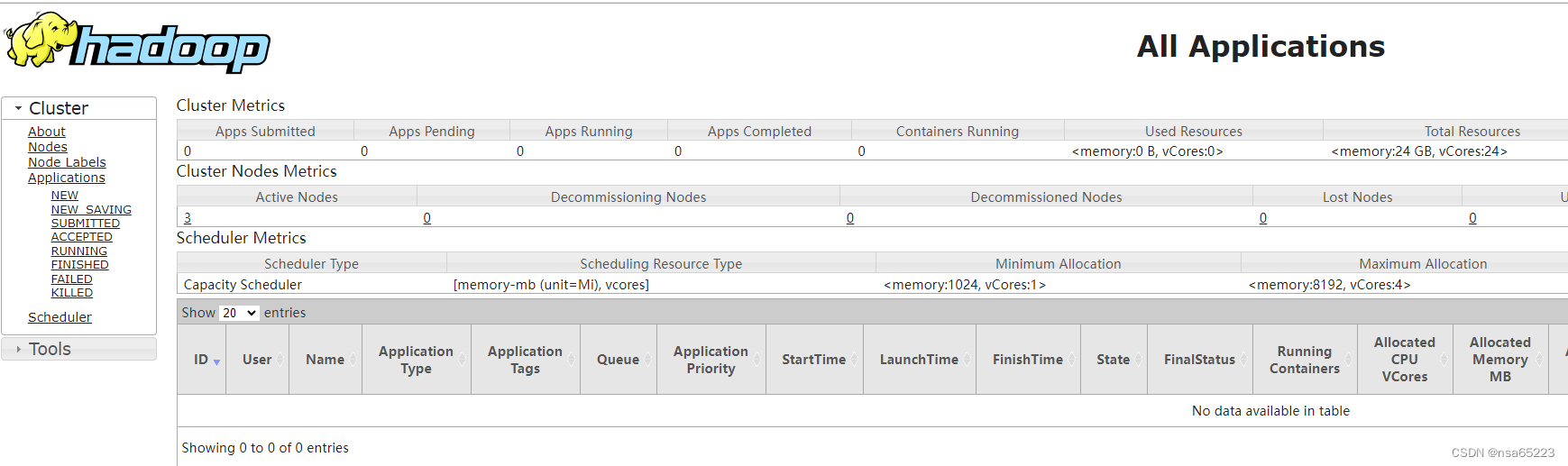
打开YARN Web UI查看相关信息,默认端口8088。?
相关命令
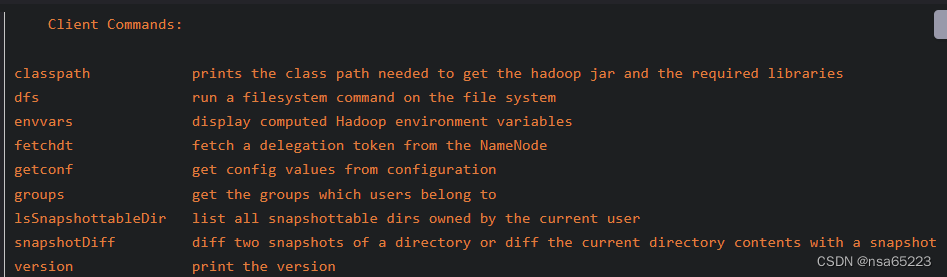
HDFS相关的命令
操作HDFS使用的命令是hdfs,命令格式为:
Usage: hdfs [OPTIONS] SUBCOMMAND [SUBCOMMAND OPTIONS]
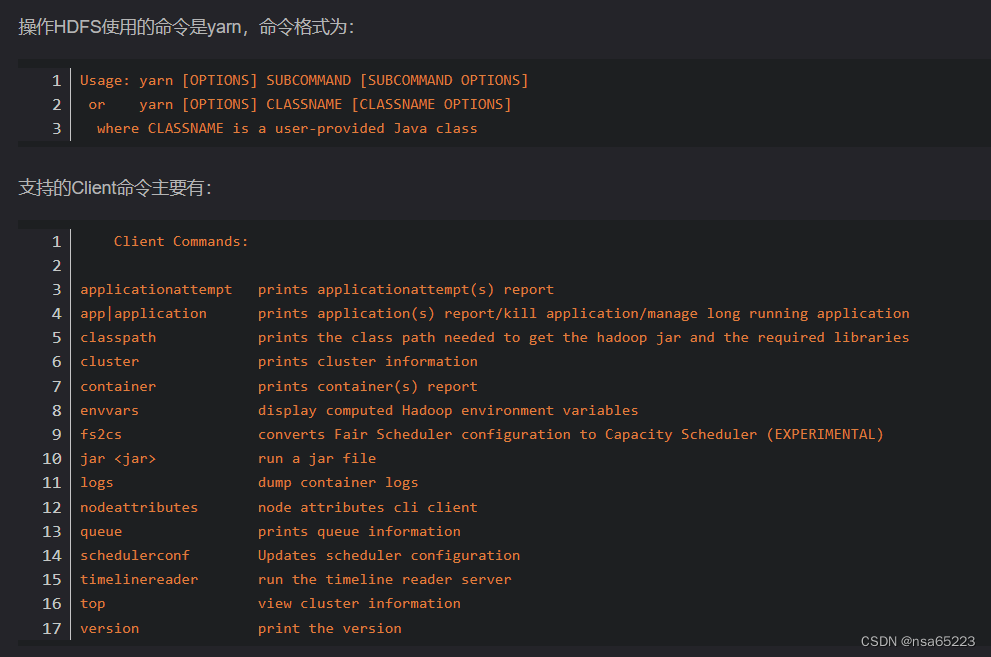
YARN相关的命令?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【RIME-CNN-LSTM-Attention预测】基于雾凇算法优化卷积神经网络结合注意力机制的长短记忆网络实现风电功率多输入单输出回归预测附matlab实现
- 系列十六、抽象类 & 接口
- NC的运行环境 类
- NLP论文阅读记录 - wos | 01 使用深度学习对资源匮乏的语言进行抽象文本摘要
- 初始化数组
- 【Java】——期末复习题库(十一)
- DDOS 攻击是什么?有哪些常见的DDOS攻击?
- 华为HCIA课堂笔记第四章 网络层协议与IP编址
- RING BUFFER
- CSDN Markdown 教程