HBase基础知识(一):HBase简介、HBase数据模型与基本架构
第1章HBase简介
1.1HBase定义
HBase是一种分布式、可扩展、支持海量数据存储的NoSQL数据库。
1.2HBase数据模型
逻辑上,HBase的数据模型同关系型数据库很类似,数据存储在一张表中,有行有列。但从HBase的底层物理存储结构(K-V)来看,HBase更像是一个multi-dimensionalmap。
1.2.1HBase逻辑结构
字典序:按位比较。
下图是一张表,但是一张表往往会被切分开来,分配在不同区域。
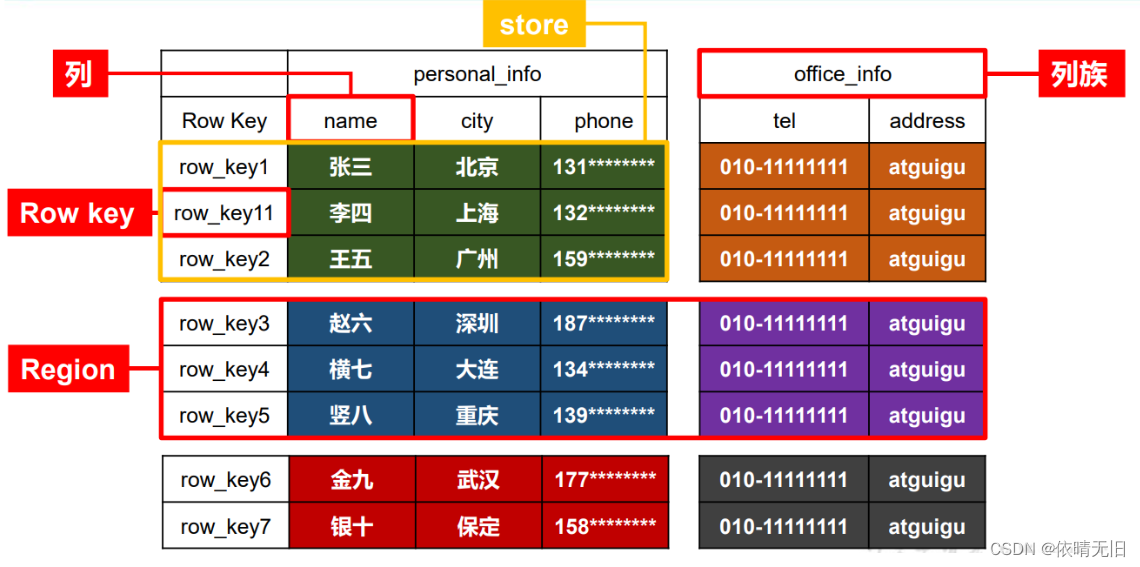
1.2.2HBase物理存储结构
该数据结构是对上图的store的一个详解
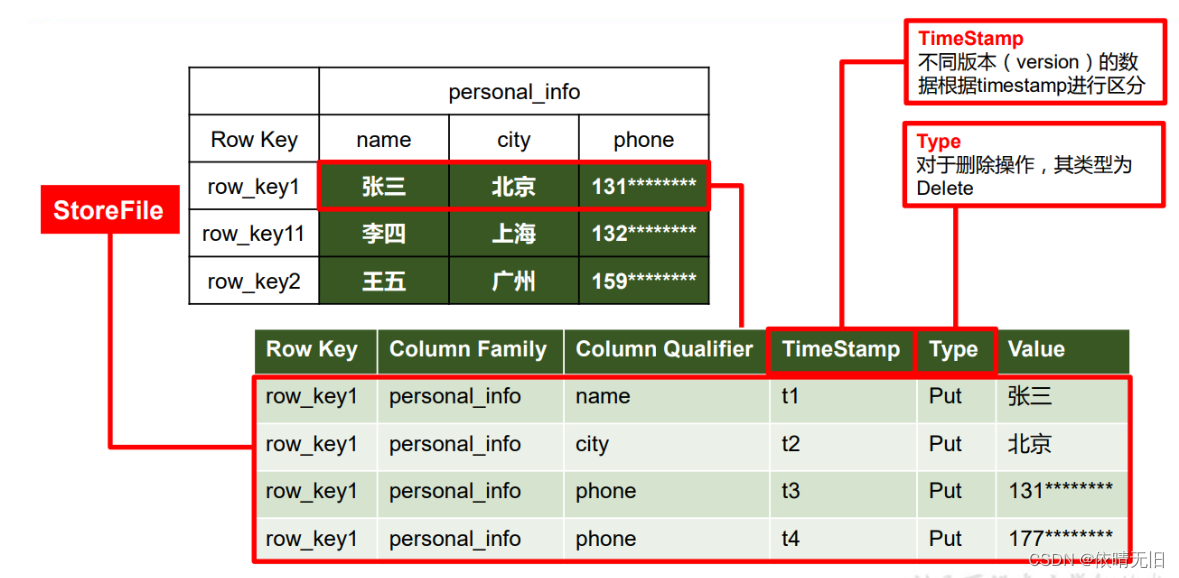
1.2.3数据模型
1)NameSpace
命名空间,类似于关系型数据库的DatabBase(数据库)概念,每个命名空间下有多个表。HBase有两个自带的命名空间,分别是hbase和default,hbase中存放的是HBase内置的表,default表是用户默认使用的命名空间。
2)Region
类似于关系型数据库的表概念。不同的是,HBase定义表时只需要声明列族即可,不需要声明具体的列。这意味着,往HBase写入数据时,字段可以动态、按需指定。因此,和关系型数据库相比,HBase能够轻松应对字段变更的场景。
3)Row
HBase表中的每行数据都由一个RowKey和多个Column(列)组成,数据是按照RowKey的字典顺序存储的,并且查询数据时只能根据RowKey进行检索,所以RowKey的设计十分重要。
4)Column
HBase中的每个列都由ColumnFamily(列族)和ColumnQualifier(列限定符)进行限定,例如info:name,info:age。建表时,只需指明列族,而列限定符无需预先定义。
5)TimeStamp
用于标识数据的不同版本(version),每条数据写入时,如果不指定时间戳,系统会自动为其加上该字段,其值为写入HBase的时间。
6)Cell
由{rowkey,columnFamily:columnQualifier,timeStamp}唯一确定的单元。cell中的数据是没有类型的,全部是字节码形式存贮。
1.3HBase基本架构
不完整版
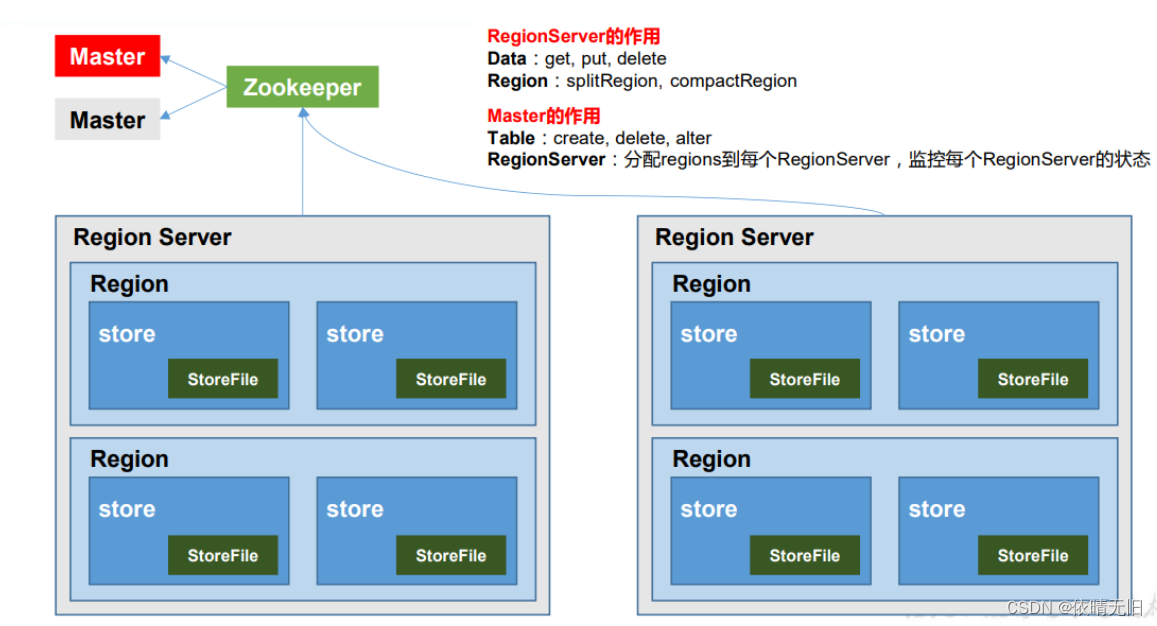
架构角色:
1)RegionServer
RegionServer为Region的管理者,其实现类为HRegionServer,主要作用如下:对于数据的操作:get,put,delete;对于Region的操作:splitRegion、compactRegion。
2)Master
Master是所有RegionServer的管理者,其实现类为HMaster,主要作用如下:对于表的操作:create,delete,alter对于RegionServer的操作:分配regions到每个RegionServer,监控每个RegionServer的状态,负载均衡和故障转移。
3)Zookeeper
HBase通过Zookeeper来做Master的高可用、RegionServer的监控、元数据的入口以及集群配置的维护等工作。
4)HDFS
HDFS为HBase提供最终的底层数据存储服务,同时为HBase提供高可用的支持。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- django基础学习
- XAgent的部署及运行
- Java中 String和StringBuffer和StringBuilder区别
- 第二天使用seleninum创建创建员工
- RK3568开发笔记(十一):开发版buildroot固件移植一个ffmpeg播放rtsp的播放器Demo
- JavaScript暂时性死区问题记录
- 【Kafka每日一问】Kafka如何保证消息不丢失?
- 第一个程序:HelloWorld——IDEA 使用
- selenium3+python3环境搭建
- nodejs01