Linux——进程创建与进程终止

文章目录
一、进程创建
1、fork函数初识
在linux中fork函数时非常重要的函数,它从已存在进程中创建一个新进程。新进程为子进程,而原进程为父进程。
#include <unistd.h>
pid_t fork(void);
返回值:自进程中返回0,父进程返回子进程id,出错返回-1
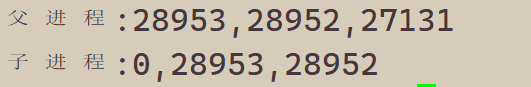
进程调用fork,当控制转移到内核中的fork代码后,内核做:
- 分配新的内存块和内核数据结构给子进程
- 将父进程部分数据结构内容拷贝至子进程
- 添加子进程到系统进程列表当中
- fork返回,开始调度器调度
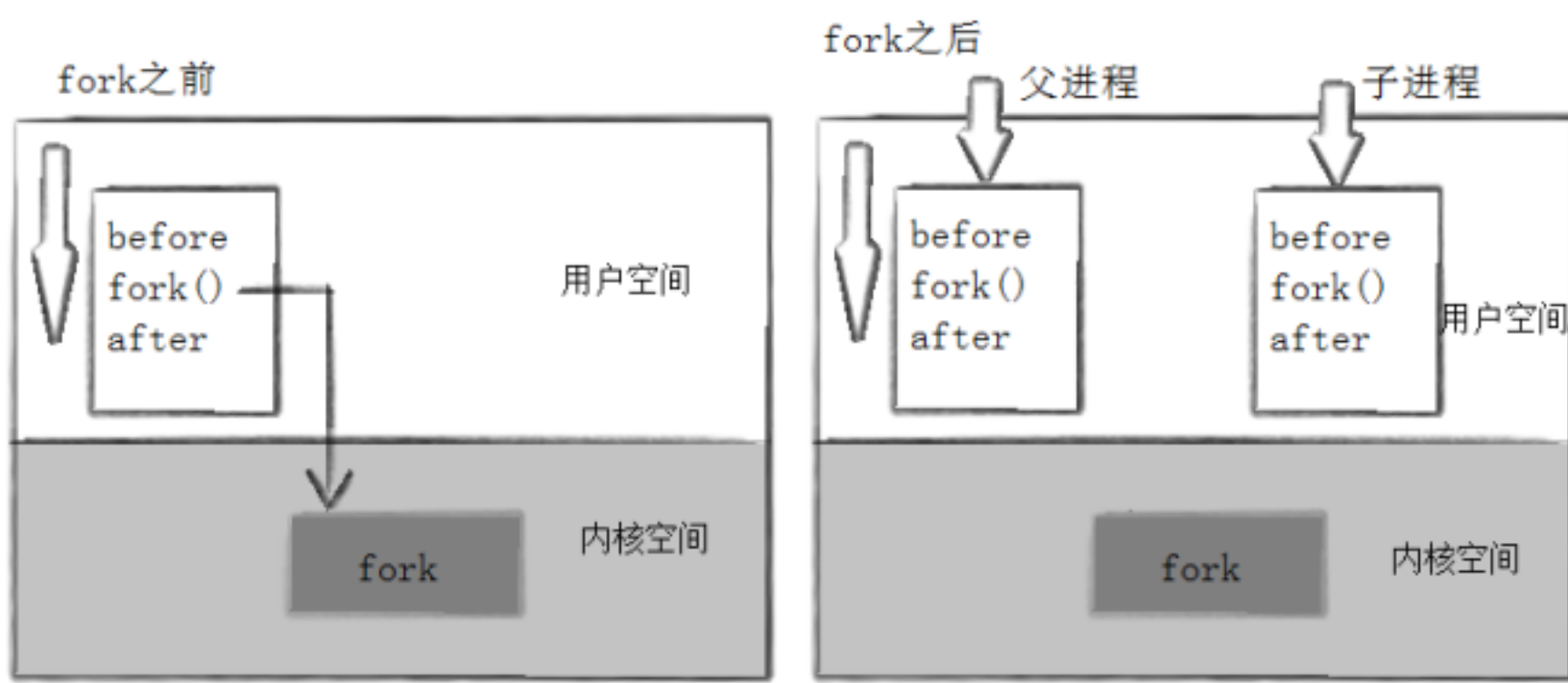
当一个进程调用fork之后,就有两个二进制代码相同的进程。而且它们都运行到相同的地方。但每个进程都将可以开始它们自己的旅程,看如下程序。
int main( void )
{
pid_t pid;
printf("Before: pid is %d\n", getpid());
if ( (pid=fork()) == -1 )perror("fork()"),exit(1);
printf("After:pid is %d, fork return %d\n", getpid(), pid);
sleep(1);
return 0;
}

这里看到了三行输出,一行before,两行after。进程29768先打印before消息,然后它有打印after。另一个after
消息有29769打印的。注意到进程29769没有打印before,为什么呢?如下图所示
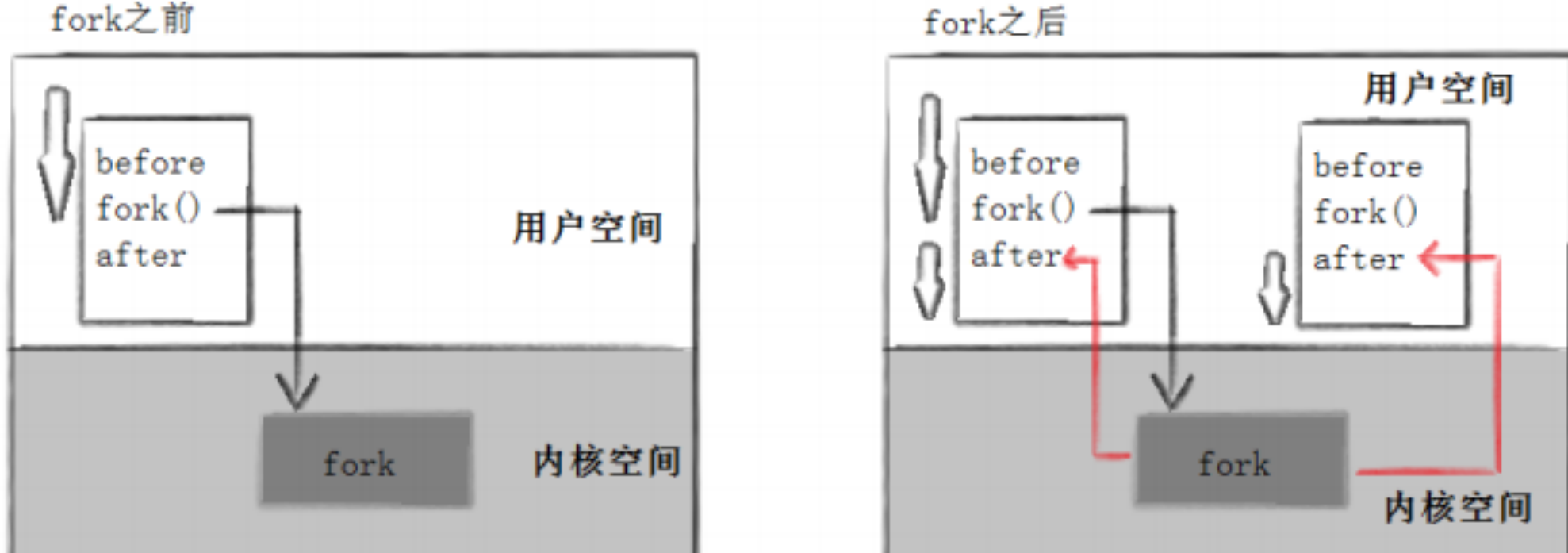
所以,fork之前父进程独立执行,fork之后,父子两个执行流分别执行。注意,fork之后,谁先执行完全由调度器决定。
2、fork函数返回值
子进程返回0。
父进程返回子进程的pid。
3、写时拷贝
通常,父子代码共享,父子再不写入时,数据也是共享的,当任意一方试图写入,便以写时拷贝的方式各自一份副本。具体见下图:
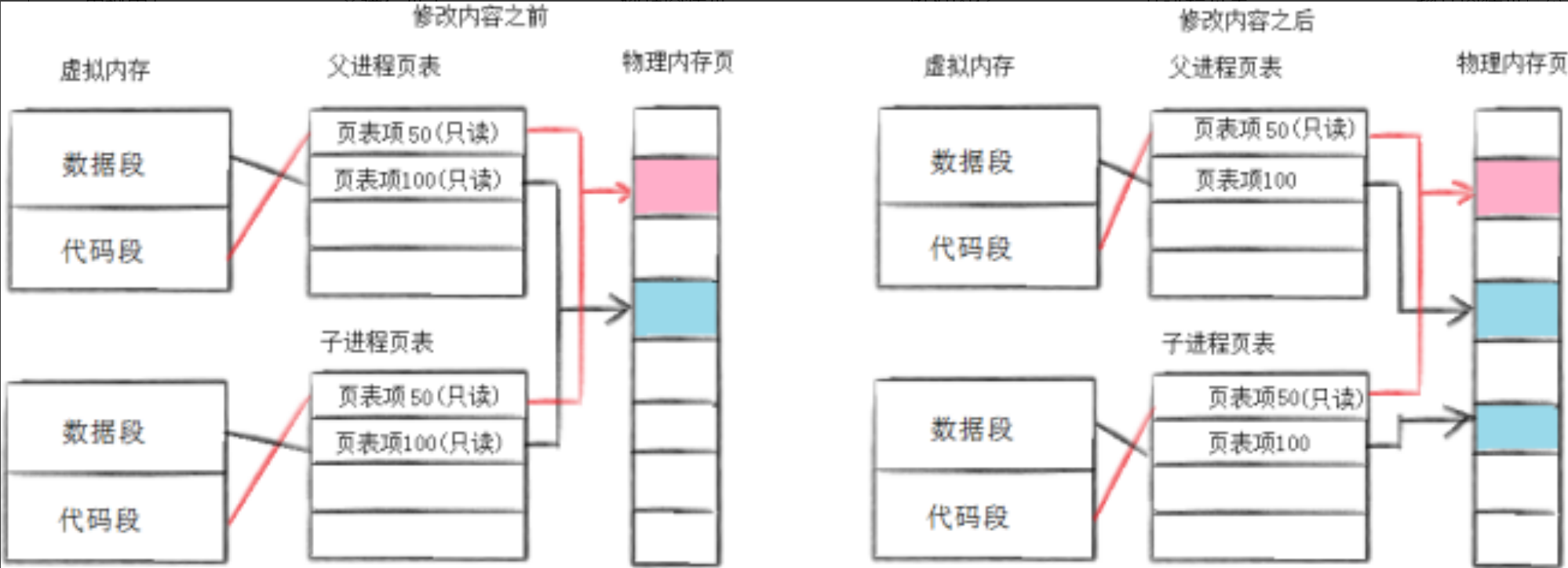
问题是进程是在运行的,OS是如何知道,要进行写时拷贝的。
原来是在今天fork之后,OS会将父子进程的页表权限设置为只读,当父子进程其中一个去修改时,会报错。
这里的报错有两种情况:
一是:真的出错了
二是:权限关闭了
所以OS会去判断,如果是第二种情况,OS就会让在物理内存中发生写时拷贝。
4、fork常规用法
一个父进程希望复制自己,使父子进程同时执行不同的代码段。例如,父进程等待客户端请求,生成子
进程来处理请求。
一个进程要执行一个不同的程序。例如子进程从fork返回后,调用exec函数。
5、fork调用失败的原因
系统中有太多的进程
实际用户的进程数超过了限制
二、进程终止
1、进程退出场景
存在三种情况

2、进程常见退出方法
正常终止(可以通过 echo $? 查看进程退出码):
- 从main返回
- 调用exit
- _exit
异常退出
ctrl + c,信号终止
3、_exit函数
#include <unistd.h>
void _exit(int status);
参数:status 定义了进程的终止状态,父进程通过wait来获取该值
说明:虽然status是int,但是仅有低8位可以被父进程所用。所以_exit(-1)时,在终端执行$?发现返回值
是255。
4、exit函数
#include <unistd.h>
void exit(int status);
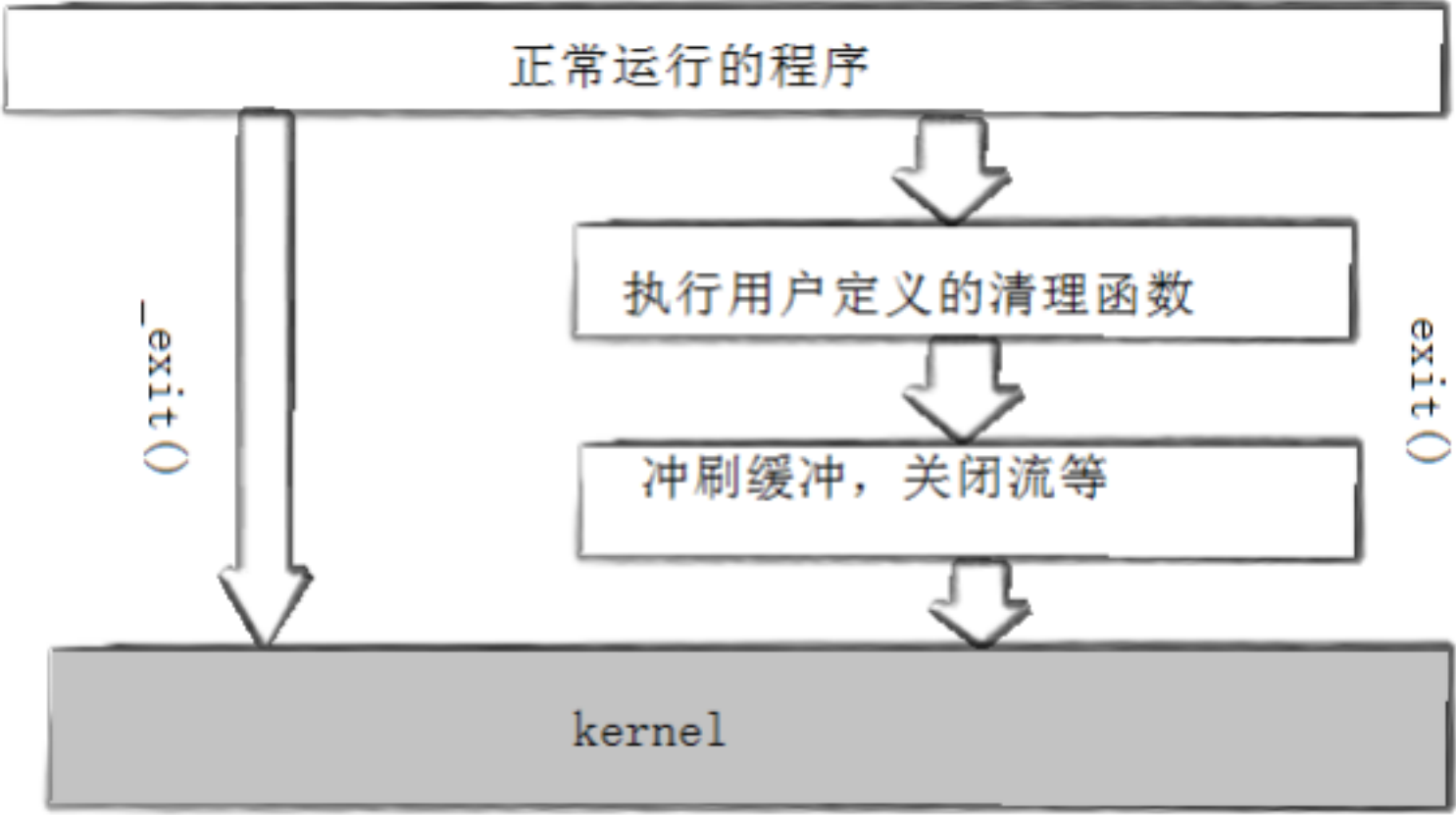
exit最后也会调用exit, 但在调用exit之前,还做了其他工作:
- 执行用户通过 atexit或on_exit定义的清理函数。
- 关闭所有打开的流,所有的缓存数据均被写入
- 调用_exit
5、return退出
return是一种更常见的退出进程方法。执行return n等同于执行exit(n),因为调用main的运行时函数会将main的返
回值当做 exit的参数。
6、退出码VS错误码
退出码
退出码就是进程运行结束返回的数字
其中0代表成功
!0代表出错了,具体的数值代表不同的原因


我们可以发现第一次,看进程退出码为10,后来就成了0,这是因为错误码只会保存最新的一次,后来由于上面指令执行成功了,所以变为了0。
main函数的退出码是可以被父进程获取的,用来判断子进程的运行结果
错误码
错误码通常是衡量一个库函数,或者一个系统调用一个一个函数的调用情况
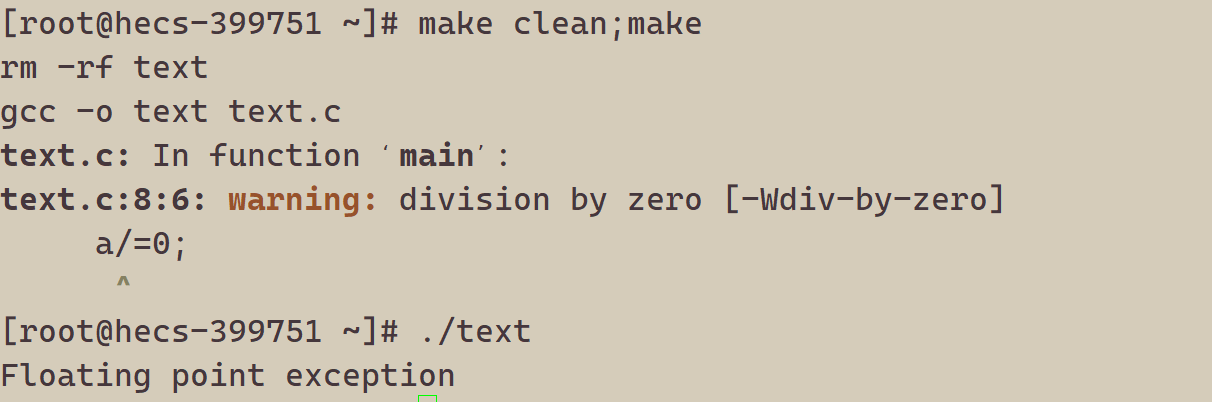
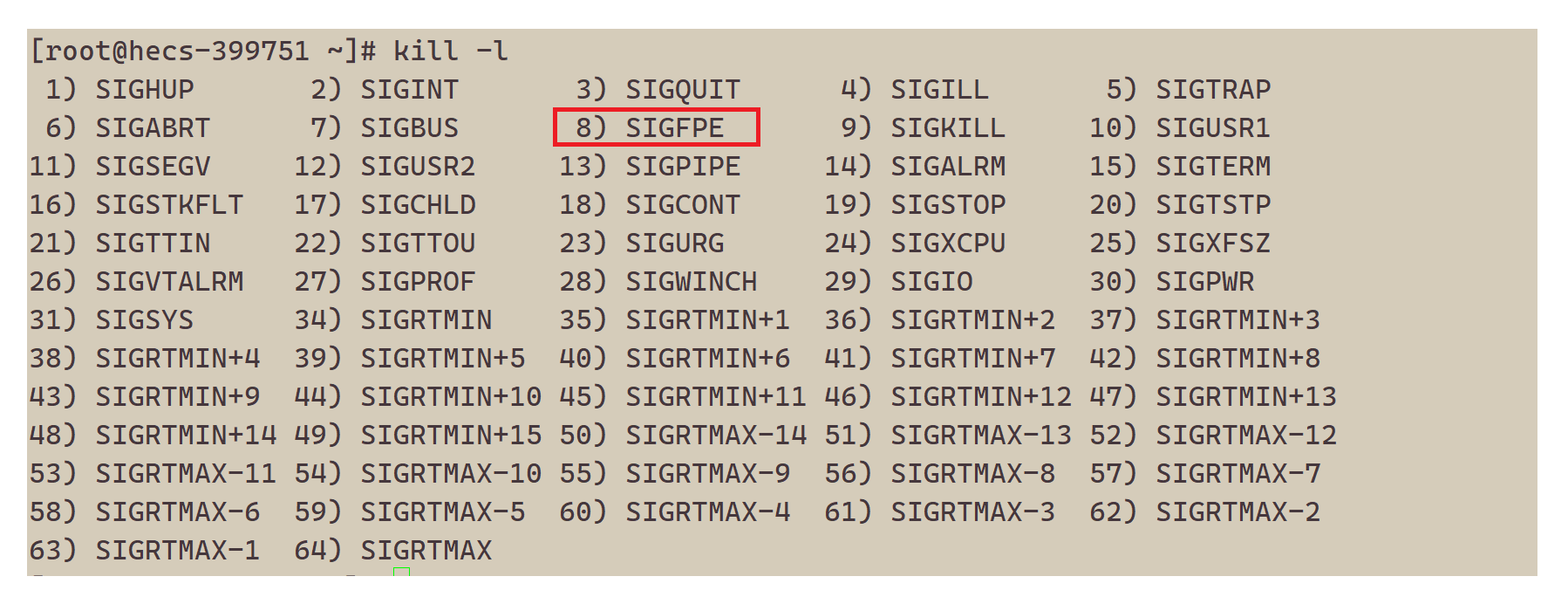
下面我们来验证一个结论,进程出现异常的本质是由于受到对应的信号,自己终止了。
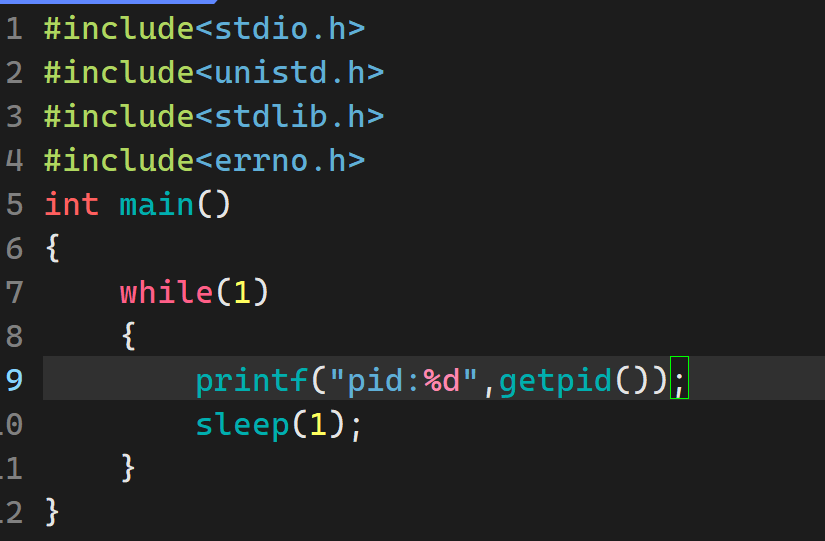
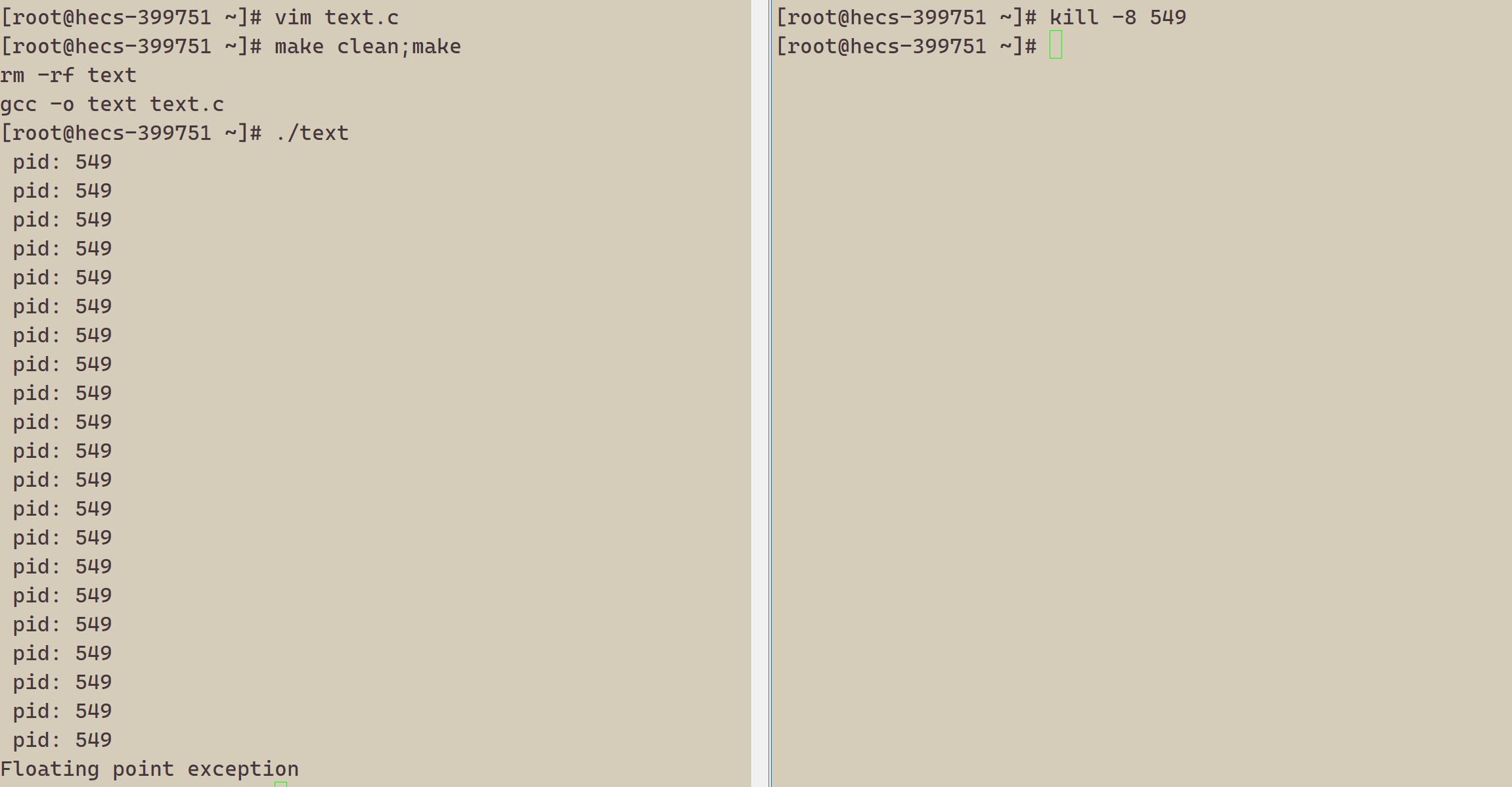
最后我们可以得出,父进程通过两个数字来判断子进程是否受到异常结束,或者成功输出。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 如何在 Linux 命令行中运行 Python 脚本?
- 财务分析进阶篇:终于有人把利润分析怎么做给讲清了!
- ESD静电保护二极管ESD5B5.0ST1G的优点有哪些?
- 【Python】使用tkinter设计开发Windows桌面程序记事本(5)
- 【面试突击】分布式锁、幂等性问题实战
- AOP springboot
- HarmonyOS开发FA应用模型下多个页面的声明方式
- 【Linux】shell外壳和权限
- 基于51单片机的模拟量输入输出通道实验
- 录屏功能怎么打开?简单操作,一学就会!