学习笔记之——3D Gaussian Splatting及其在SLAM与自动驾驶上的应用调研
之前博客介绍了NeRF-SLAM,其中对于3D Gaussian Splatting没有太深入介绍。本博文对3D Gaussian Splatting相关的一些工作做调研。
实验笔记之——基于COLMAP的Instant-NGP与3D Gaussian Splatting的对比-CSDN博客文章浏览阅读1k次,点赞23次,收藏18次。之前博客进行了COLMAP在服务器下的测试实验笔记之——Linux实现COLMAP-CSDN博客学习笔记之——NeRF SLAM(基于神经辐射场的SLAM)-CSDN博客NeRF 所做的任务是 Novel View Synthesis(新视角合成),即在若干已知视角下对场景进行一系列的观测(相机内外参、图像、Pose 等),合成任意新视角下的图像。传统方法中,通常这一任务采用三维重建再渲染的方式实现,NeRF 希望不进行显式的三维重建过程,仅根据内外参直接得到新视角渲染的图像。https://blog.csdn.net/gwplovekimi/article/details/135406537?spm=1001.2014.3001.5501本博文,意在记录本人调研3D Gaussian Splatting的时候做的学习记录(同时也记录了与本人研究方向相关的两个主要领域SLAM与Autonomous Driving中3DGS的paper),部分资料来源于网络,本博文仅仅供本人学习记录用~
目录
GS-SLAM: Dense Visual SLAM with 3D Gaussian Splatting
SplaTAM: Splat, Track & Map 3D Gaussians for Dense RGB-D SLAM
Gaussian-SLAM: Photo-realistic Dense SLAM with Gaussian Splatting
Street Gaussians for Modeling Dynamic Urban Scenes
DrivingGaussian: Composite Gaussian Splatting for Surrounding Dynamic Autonomous Driving Scenes
什么是3D Gaussian Splatting
3D Gaussian Splatting for Real-Time Radiance Field Rendering
3D Gaussian Splatting for Real-Time Radiance Field Rendering
3D Gaussian Splatting是最近NeRF方面的突破性工作,它的特点在于重建质量高的情况下还能接入传统光栅化,优化速度也快(能够在较少的训练时间,实现SOTA级别的NeRF的实时渲染效果,且可以以 1080p 分辨率进行高质量的实时(≥ 30 fps)新视图合成)。开山之作就是论文“3D Gaussian Splatting for Real-Time Radiance Field Rendering”是2023年SIGGRAPH最佳论文。
首先,3DGS可以认为是NeRF的一种,做的任务也是新视图的合成。
对于NeRF而言,它属于隐式几何表达(Implicit Geometry?),顾名思义,不表达点的具体位置,而表示点与点的关系。通过选取空间坐标作为采样点输入,隐式场景将输出这些点的几何密度是多少,颜色是什么。而所谓的神经隐式几何则是用神经网络转换上述输入输出的方法(输入三维空间坐标和观测视角,输出对应点的几何密度和颜色)。把光线上的一系列采样点加权积起来就渲染得到一个像素颜色,这便是NeRF神经辐射场渲染的流程。
此外,何的隐式表达可以分为体积类表达和表面类表达两种:
- 体积类表达:NeRF 属于体积类表达,通过几何密度决定采样点颜色的贡献度。
- 表面类表达:在表面类表达方式中,输入采样点,符号距离函数 SDF 输出空间中距离该点最近的表面的距离,正值表示表面外,负值表示表面内,表面类方法判定越靠近表面的采样点颜色贡献度越高。
既然有隐式,那么就有显式几何表达(?Explicit geometry),就是类似点云、三角mesh这类可以沿着存储空间遍历所有元素。(通过某些方式,真正的把物体上的点都表示出来)
- 对于渲染,NeRF是非常典型的backward mapping过程,即计算出每个像素点受到每个体素影响的方式来生成最终图像,对每个像素,投出一条视线,并累积其颜色和不透明度
- 而3DGaussian Splatting是forward mapping的过程,将每个体素视作一个模糊的球,投影到屏幕上。在Splatting中,我们计算出每个体素如何影响每个像素点
什么是3D高斯?
对于高常说的高斯函数,其实是1D的高斯,也就是正态分布:

它所表达的图像就是一条对称曲线,如下图所示。均值![]() 控制对称轴进而控制图形位置,标准差?
控制对称轴进而控制图形位置,标准差?![]() ?控制密度集中程度。
?控制密度集中程度。

对于一段x区间,进行积分可以得到分布中的数据落在这一区间的概率,其中绝大多数落在![]() 区域(概率是0.9974)。因此,一组
区域(概率是0.9974)。因此,一组![]() 和
和![]() 可以确定一个1D高斯分布函数,进而确定一条1D线段
可以确定一个1D高斯分布函数,进而确定一条1D线段![]() ,通过改变这两个值就可以表达1D数轴上的一根线段。
,通过改变这两个值就可以表达1D数轴上的一根线段。
类似地,将这个思路从1D拓展到3D,那么就可以确定一个椭球的图形,这个椭球分别以xyz轴对称,从对称轴的垂直面切出来的横截面都是椭圆(或圆)。不过由于这个椭球可以旋转移动,所以它的xyz对称轴不一定和世界坐标系重叠。对于标准的3D Gaussians标准形式,是:

它能涵盖空间中任意形状的椭球(包括平移旋转)。其中![]() 是三维列向量坐标,
是三维列向量坐标,![]() 是椭球中心(控制世界空间位置平移),至于协方差矩阵
是椭球中心(控制世界空间位置平移),至于协方差矩阵 则是控制椭球在3轴向的伸缩和旋转(模型空间),其中协方差矩阵的特征向量就是椭球对称轴。
则是控制椭球在3轴向的伸缩和旋转(模型空间),其中协方差矩阵的特征向量就是椭球对称轴。
但是论文中的3D Gaussians表达却不一样:

和标准形式对比可以看到去掉了指数部分前面的尺度系数(不影响椭球几何);默认模型坐标中心在原点,方便旋转放缩,放入世界空间时再加上平移。那么对于初始化这个高斯椭球,目前就只有协方差矩阵![]() 这一个参数了。论文给出了初始化的方法如下表达
这一个参数了。论文给出了初始化的方法如下表达

其中的S是放缩变换(沿着坐标轴的3D向量s);R是旋转变换(可以用四元数q来表达)。这是因为椭球是可以通过将圆球按轴向放缩再旋转。而在使用梯度下降对参数进行优化的时候,就是将梯度传递到s和q中进行优化的。
什么是Splatting?
Splatting(抛雪球(splatting):是计算机图形学中用三维点进行渲染的方法,该方法将三维点视作雪球往图像平面上抛,雪球在图像平面上会留下扩散痕迹,这些点的扩散痕迹叠加在一起就构成了最后的图像,是一种针对点云的渲染方法)的方法进行渲染。
传统光栅化(rasterization)的主要内容之一是将三维三角形映射到投影平面并像素化(将图形或图像的矢量数据转换为像素数据,从而能够在计算机屏幕上显示的过程。通过将图形转换为像素级别,计算机可以更容易地处理和显示图形,同时确保图像在屏幕上以高速率绘制)。光栅化是实现计算机屏幕上图形显示和渲染的关键步骤,能够以非常高的速度生成图像,适用于实时渲染,例如视频游戏和模拟器。
- 光栅化就是把顶点数据转换为片元的过程。片元中的每一个元素对应于帧缓冲区中的一个像素。光栅化其实是一种将几何图元变为二维图像的过程。该过程包含了两部分的工作。第一部分工作:决定窗口坐标中的哪些整型栅格区域被基本图元占用;第二部分工作:分配一个颜色值和一个深度值到各个区域。光栅化过程产生的是片元。
- 之所以是三角形是因为它在图形学中可以看做是几何体的基本形状。三角形在图形学中有很多很好的性质:(1)三角形是最基本的多边形,并且任何其他的多边形都可以拆分为三角形。(2)三个点可以保证他在一个平面如果是四边形四个点就不能保证。(3)它可以很好地用叉积判断一个点是不是在三角形内部(三角形的内外定义特别清晰)。
而对于椭球(就是上面3D高斯获得的表达)的光栅化则需要开发者自己用GPU实现,其中把椭球投影到投影平面后得到的2D图形称为Splatting。Splatting算法与光线投射法不同,是反复对体素的投影叠加效果进行运算。它用一个称为足迹的函数计算每一体素投影的影响范围,用高斯函数定义点或者小区域像素的强度分布,从而计算出其对图像的总体贡献,并加以合成,形成最后的图像。由于这个方法模仿了雪球被抛到墙壁上所留下的一个扩散状痕迹的现象,因而取名为“抛雪球法”。所以,所谓的Splatting就是对高斯进行光栅化~
对于3D高斯的分布函数,在模型空间原点用协方差矩阵![]() 确定了形状与旋转,然后用椭球的中心
确定了形状与旋转,然后用椭球的中心![]() 确定平移到世界空间。为了渲染到画布上需要先view变换(视角的变换)到相机空间,再project变换(透视投影模型?)将透视空间变得和像素对齐才能进行光栅化。而所谓的栅格化可以理解伟将三维投射到平面并进行像素化。论文把这个过程用下面公式来表达
确定平移到世界空间。为了渲染到画布上需要先view变换(视角的变换)到相机空间,再project变换(透视投影模型?)将透视空间变得和像素对齐才能进行光栅化。而所谓的栅格化可以理解伟将三维投射到平面并进行像素化。论文把这个过程用下面公式来表达
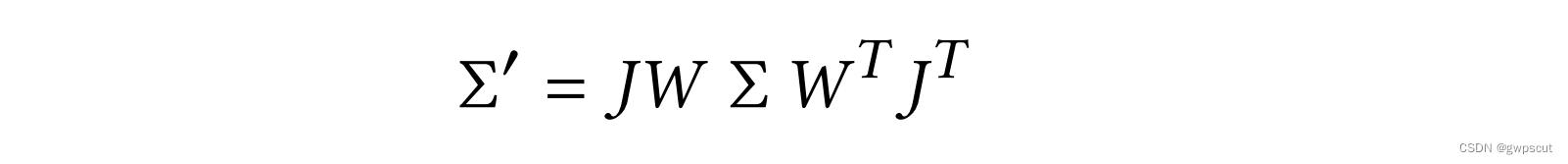
其中,W代表view变换(主要是旋转和平移,都是仿射变换);J代表project变换,对其进行仿射近似,再取雅克比矩阵(Jacobian)。
上面的变换后的分布已经和画布像素对齐,沿着第三维积分则可得到椭球在某一像素上的着色。根据3D高斯的特点,沿着某一轴线积分的结果是一个2D高斯,所以这里可以直接用2D高斯替换积分过程。
交叉优化
本文的核心是对 3D Gaussian 的优化,优化的目的是创建一组密集的 3D Gaussian 以精确地表示场景。优化的参数包括:三维位置 p、透明度 α 各向异性协方差 Σ?和球谐系数 SH (spherical harmonic coefficients) 。这些 ?参数的优化? 和 ?自适应控制高斯模型? 交替进行。

注意:图中的球谐系数 SH (spherical harmonic coefficients) 来表示每个高斯的颜色 ,不同视角颜色不同。
参数优化使用 SGD 连续迭代完成,每一轮迭代时都会渲染图像并将其与真实的训练视图做比较。α使用 Sigmoid 激活函数来限制 (0, 1) 的范围;Σ使用指数激活函数激活;p使用指数衰减调度技术 (exponential decay scheduling technique) 进行优化。模型的损失函数是 L1 与 D-SSIM 项的组合:

自适应控制
在 3D Gaussian Splatting 中,场景表示是通过多个高斯模型叠加而成的。在早期迭代次数较少时,会出现 重建不足 (under-reconstruction) 的问题,即高斯模型没有完全覆盖小规模的几何体,此时需要复制高斯模型进行覆盖;在后期迭代次数较多时,会出现 重建过度 (over-reconstruction) 的问题,即高斯模型超出小规模几何体的范围,此时需要将该高斯模型一分为二。这就是自适应控制 Gaussians:
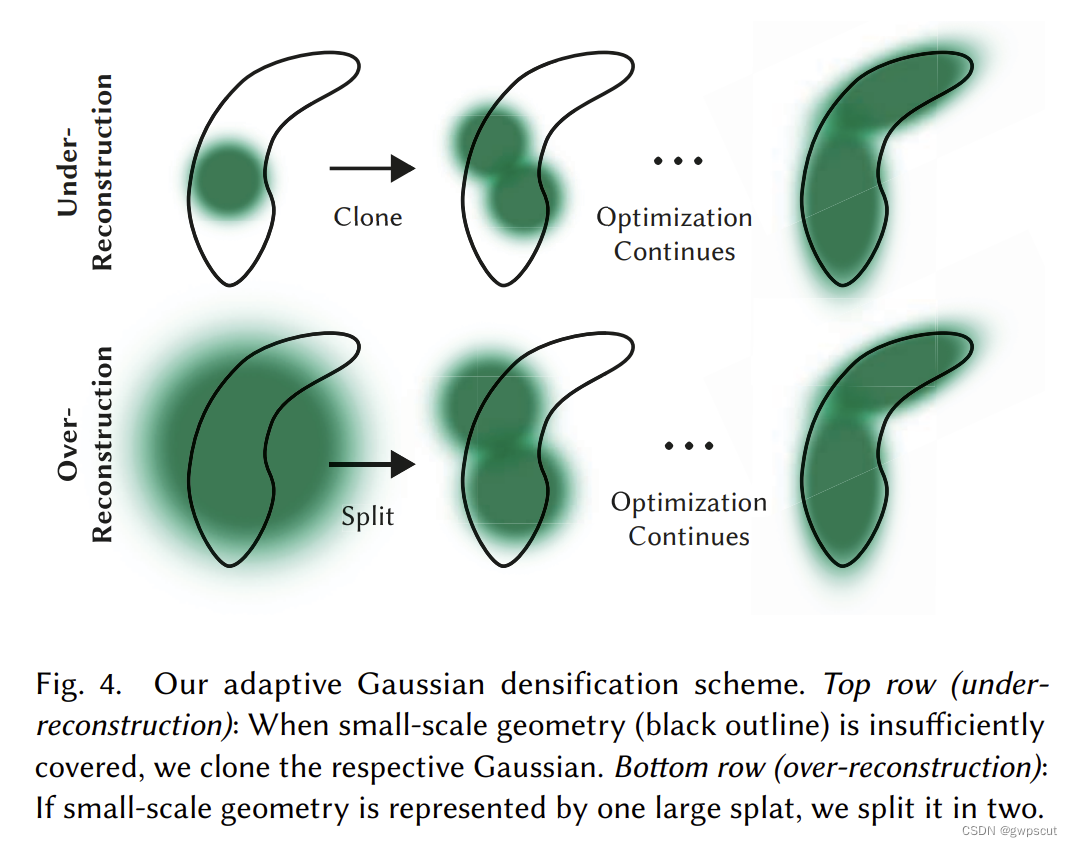
从初始化 Gaussians 为稀疏的 SfM 点云开始,通过自适应地控制高斯模型的数量和它们在单位体积上的密度,逐渐从稀疏的高斯模型集合过渡到更密集且能够更好地表示场景的集合。该过程主要关注 under-reconstruction 和 over-reconstruction 的区域,即具有较大的视图空间位置梯度的区域。直观理解来看,是因为这些区域尚未完全重建好,因此优化算法试图移动高斯函数以进行修正。under-reconstruction 和 over-reconstruction 的区别是 over-reconstruction 区域的 Gaussian 方差大,因为数据的变化幅度较大。对于视图空间的位置梯度大于阈值 𝜏pos 的区域,需要对该高斯模型进行稠密化 (densify) 操作:
- under-reconstruction 区域:高斯模型没有完全覆盖小规模的几何体,此时需要复制高斯模型并将其沿位置梯度方向移动,以覆盖几何体。
- over-reconstruction 区域:高斯模型超出小规模几何体的范围,此时需要将该拆分高斯模型只覆盖几何体。
快速可微光栅化
Gaussians 快速可微光栅化是为了快速实现整体渲染和排序,从而实现近似 α \alphaα-blending 并且不再限制能够接收梯度的 splats 的数量。为了达到目的,对 Gaussian splats 进行分块 (tile) 处理,将该光栅化过程命名为 基于分块的光栅化 (tile-based rasterization)。
- 首先将 2D 屏幕分割成 16×16 个 tile,然后为每个 tile 筛选视锥体 (view frustum) 内的 3D Gaussian:每个视锥体内只保留置信度大于 99% 的高斯模型;设置一个保护带 (guard band) 剔除位于极端位置的高斯模型,如均值接近近平面或在视锥体之外;
- 根据每个 Gaussian 重叠的 tile 数量来实例化,为其分配 key 值(key 值结合了该 Gaussian 所在 tile 的 ID 和对应视域的深度);
- 使用 GPU Radix sort 根据 key 值对 Gaussians 进行排序(其实就是按高斯模型到图像平面的深度值);
- 将排好序的 Gaussians 从近到远向对应 tile 上做 Splatting。然后在每个 tile 上对高斯模型留下的 splat 做堆叠(类似 α-blending,累积 α 和 c),直到所有像素的不透明度都饱和(α=1);
-
优化参数时,按每个 tile 堆叠的 splat 对应的 Gaussians 的顺序反向传播;
系统的框图如下所示:系统首先对SfM产生的稀疏点云进行初始化,创建3D高斯模型,然后借助相机外参(就是pose了)将点投影到图像平面上(即Splatting),接着用可微光栅化,渲染得到图像。得到渲染图像Image后,将其与Ground Truth图像比较求loss,并沿蓝色箭头反向传播。蓝色箭头向上,更新3D高斯中的参数,向下送入自适应密度控制中,更新点云。

具体而言,即从已有点云模型出发,以每个点为中心,建立可学习的3D高斯表达,用Splatting的方法进行渲染,实现了高分辨率的实时渲染,其中包含三个关键步骤:
- 3D高斯场景表示:从相机校准过程中产生的稀疏点开始(初始化伟sfm产生的稀疏点云),用3D高斯(3D Gaussians)表示场景,3D高斯保留连续体积辐射场的理想属性以进行场景优化,同时避免了在空白空间中进行不必要的计算。
- 交错优化和密度控制:对3D高斯各种属性(如位置、不透明度、各向异性协方差和球面谐波系数)进行了交错优化/密度控制,特别优化了各向异性协方差(anisotropic covariance,指的是从各个方向上看过去,物体的外观表现都不同)以实现场景的准确表示。
- 快速可见性感知渲染算法:开发了一种快速可见性感知渲染算法(fast visibility-aware rendering algorithm),该算法支持各向异性抛雪球(anisotropic splatting),既能加速训练,又能保持高质量进行实时渲染。
3DGS in SLAM
3DGS结合的意义其实就是NeRF与SLAM结合的意义了~
NeRF-based SLAM方法区别于之前的方法单点替代方法,端到端的替代传统SLAM,没有特征提取,直接操作原始像素值,无论是隐式还是显式的环境表达都可以进行微分,但存在渲染速度慢、图像质量不高、定位精度欠佳等问题~
而基于3D Gaussian Splatting的SLAM方法全面继承了NeRF-based SLAM方法的上述优点(无手工特征提取、可微分),在实时性和定位精度上表现优秀,在渲染速度和渲染质量上更是一骑绝尘!(特别是Gaussian-SLAM更明显了)
GS-SLAM: Dense Visual SLAM with 3D Gaussian Splatting
首先这个首页图的对比就非常的明显了,实时性来看GS-SLAM可以高达386FPS远超其他方法(但这个仅仅是渲染的速度,整个SLAM框架的运行速度和定位精度没有提升太多),而恢复的纹理效果,说实话不细看呢看不出太大差别,但是细看发现网格上纹理恢复,GS-SLAM确实要sharp一些~

这篇论文提出了第一个?SLAM中使用3D Gaussians表示的GS-SLAM。它有利于在效率和准确性之间取得更好的平衡。与最近的NeRF-based SLAM方法相比,GS-SLAM使用了一个实时可微的splatting渲染管道,为地图优化和RGB - D重新绘制提供了显著的加速比。具体来说,我们提出了一种自适应的扩展策略(Adaptive expansion strategy ),添加新的或删除有噪声的3D高斯,以便有效地重建新的观测场景几何,并改善先前观测区域的建图。这种策略对于扩展3D高斯表示来重建整个场景至关重要,而不是在现有的方法中合成一个静态物体。此外,在位姿跟踪过程中,设计了一种有效的由粗到精(coarse-to-fine)的技术来选择可靠的3D高斯表示来优化相机位姿,从而减少运行时间并实现鲁棒估计。
传统的NeRF-SLAM存在两个问题:定位精度低与渲染慢,这篇论文解决是后者。GS-SLAM的输入是RGBD序列和相机内参,将3D场景建模为3D高斯,利用3D高斯splatting渲染RGB和Depth,计算光度损失和深度损失来优化位姿和场景,输出是相机位姿和稠密场景。主要创新在于,GS-SLAM不使用隐式特征表示地图,而是利用3D高斯表示场景,使用基于splatting的光栅化来渲染图像,这个过程非常快(简而言之就是类似NeRF-SLAM把3DGS用到SLAM)。

关于3D Gaussian的表示前面已经讲得比较深入,这里就不再复述了。作者将场景表示成下面的形式
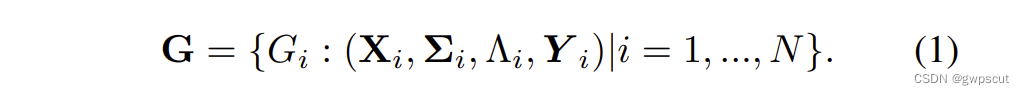
其中N表示帧数,X表示3D坐标,Σ表示协方差(包含了高斯椭球的旋转与尺度/形状信息),Λ表示不透明度,Y表示球谐系数(颜色、外观信息):
再对高斯椭球进行了建模后,通过splatting就可以将高斯椭球投影到2D平面进行渲染。
- 对于每个pixel的颜色,通过按深度顺序对高斯进行排序并执行前向混合渲染(α-blending rendering)来呈现的,过程如下:

其中的ci就是代表这个高斯的颜色(通过学习Y Spherical Harmonics coefficients来获得的),而这里的αi是通过将2D协方差Σ′与不透明度Λi相乘计算得到的密度。所谓的2D协方差Σ′由下面公式获得(就是将3D高斯投影到2D平面,P是camera pose,J是the Jacobian of the affine approximation of the projective function):

同样地,深度的渲染如下:

这里的di表示第i个3D高斯的中心深度,该深度是通过在相机坐标系统中投影到z轴得到的。
接下来就看看如何自适应的扩展3D Gaussian mapping,也就是什么时候会添加/删除3D高斯?
每个关键帧都会做3D高斯的更新和优化,每次获得关键帧位姿,先决定是否添加/删除3D高斯,然后计算光度损失和深度损失来优化场景。
- (添加)具体来说,每来一个关键帧,先用现有3D高斯去渲染当前帧RGBD图像,计算累计不透明度,如果累计值低于阈值,或者渲染深度值跟当前深度图差距太大,就认为看到了新场景,添加新3D高斯。
- (删除)在添加新3D高斯后,检查了当前相机视锥中所有可见的3D高斯,然后降低位置不在场景表面附近的3D高斯的不透明度,也就相当于删除了。

对于pose tracking。GS-SLAM没有用单独的SLAM模块来估计位姿,而是使用损失函数同时优化场景和位姿,定位只用了光度损失,BA同时用了光度损失和深度损失。虽然GS-SLAM更侧重建图速度的提升,但是也做了很多位姿优化的策略。
所谓的由粗到精的位姿优化,作者认为渲染的RGB图像有大量伪影,因此直接拿整张图象来优化位姿会导致很大漂移。所以GS-SLAM的做法是,先渲染一个1/2分辨率的图像,用这个粗糙图像计算光度损失得到位姿,再用这个粗糙位姿去选择/过滤3D高斯表征。然后用更新的3D高斯去渲染全分辨率图像,再次计算光度损失优化位姿。
实验效果如下,首先是pose tracking的精度对比,可以发现没有太大的提升,特别是表格2跟orbslam2对比,差太远了,要知道orbslam2在robotics领域已经不算好的性能了

而mapping精度(建图的精度,深度恢复的精度)的对比如下

而重建的稠密性能方法,并不是很平滑(比如office3,感觉没有Vox-Fusion好,)
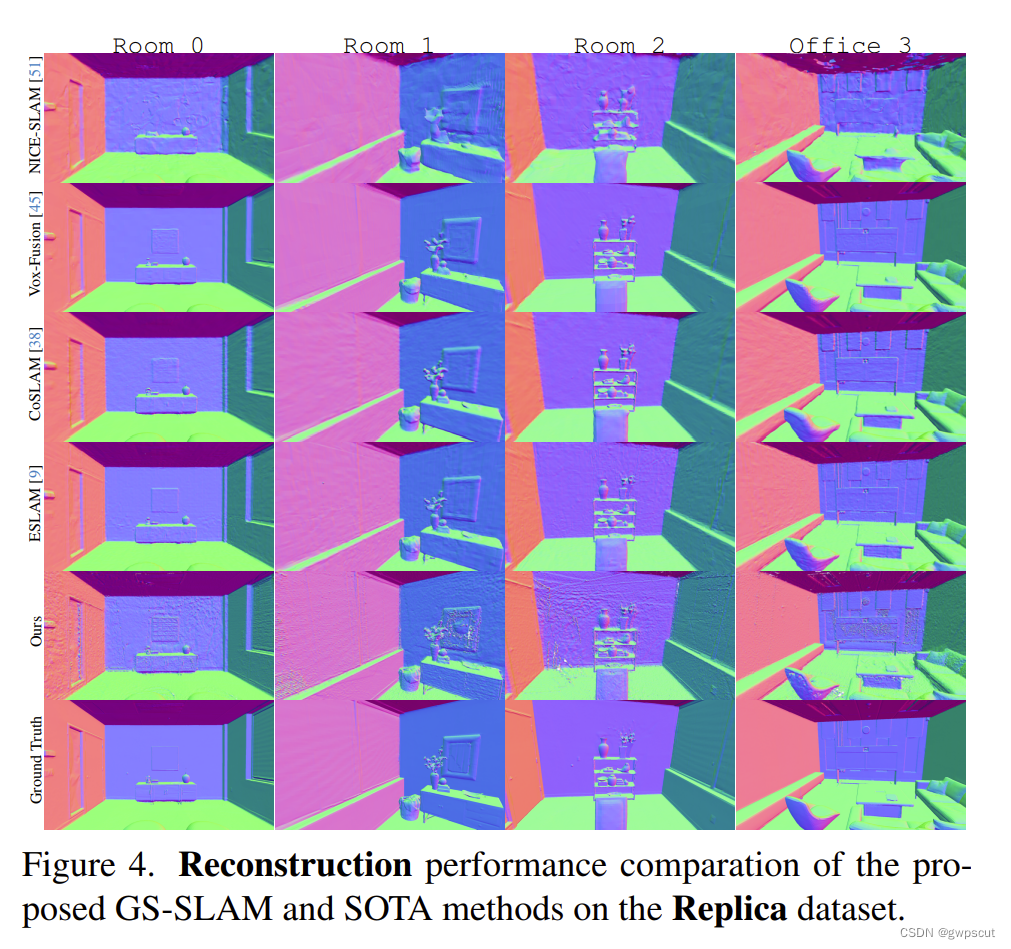
而渲染的质量方面如下图。虽然上面的平滑性没那么好,但是渲染的质量上,看着要清晰些(要细看才明显hhh)


而mapping的定量分析(恢复的效果),效果就确实是最好的~PSNR上比其他方法都好上不少~
而运行时间、参数量、内存占用的对比,GS-SLAM整体的运行速度不是太快,而且场景占用的内存也太大了,这就是3GS论文中提到的mapping特别是大场景mapping下memory问题。

SplaTAM: Splat, Track & Map 3D Gaussians for Dense RGB-D SLAM
SplaTAM Splat, Track Map 3D Gaussians for Dense RGB-D SLAM
SplaTAM应该跟上面的GS-SLAM是同期的论文,都说自己是第一篇将3DGS用到RGB-D SLAM的工作。首页图的效果上来看好像不错,渲染的速度达到了400FPS(GS-SLAM是386),深度的恢复、纹理的恢复效果都不错~宣称可以实现sub-cm级别的定位精度。同时这个工作也开源了~(后续额外再进行复现吧)
对于NeRF-SLAM主要存在的缺点是计算量大以及大场景遗忘问题(catastrophic forgetting),这里个人的观点是:确实3DGS的计算效率更高,更快(这也是论文提到的fast rendering,400FPS)。而它解决场景遗忘问题的方式是采用显式表达,这就是它的另外的缺陷(memory的问题)了吧~
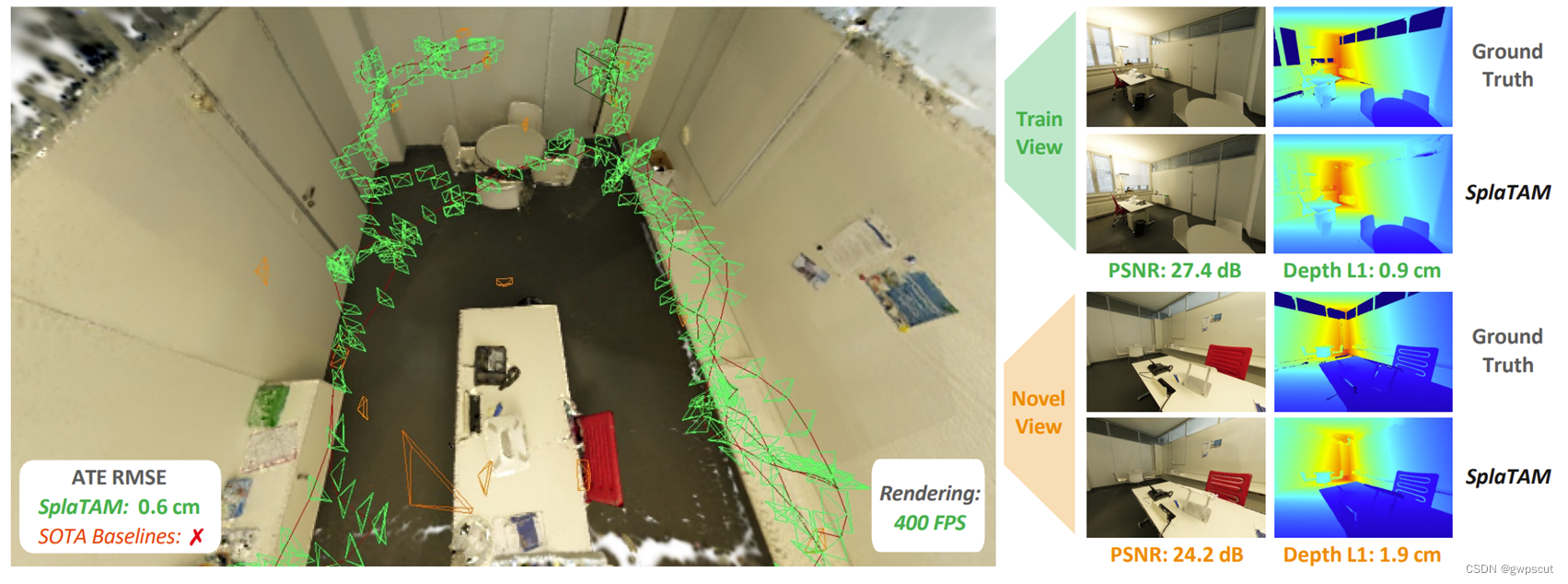
论文的主要贡献如下:
- 作者通过引入一些因子来实现更快的光栅化(rasterization)进而实现更宽的渲染,其中包括了去掉view-dependent appearance 以及使用isotropic Gaussians.
- 已有地图的空间边界可以通过仅在过去观察到的场景的部分区域添加高斯来轻松控制(就是地图的扩张了,感觉所谓的第二个和第三个contribution都仅仅是用了3D Gaussian带来的,并没有像GS-SLAM有设计新的高斯添加与删除的策略)
- 由于场景由具有物理3D位置、颜色和大小的高斯表示,因此参数和渲染之间存在直接的、几乎是线性的(投影)梯度流。由于相机运动可以被看作是保持相机静止并移动场景,我们还可以直接对相机参数进行梯度,这使得快速优化成为可能。基于神经网络的表示形式不具备这一特性,因为梯度需要通过(潜在的多个)非线性神经网络层进行传递。(这个contribution应该就是指用了3DGS来优化位姿更简单?那如果是这样,所谓的contribution2、3、4都是用了3DGS带来的好处,而contribution1则是在3DGS上做了点小改进)
但这里有一点,就是introduction提到了其中一个motivation是unobserved/novel camera viewpoint的处理,这也是原来3DGS的limitations之一,但contribution中好像没有对这个东东做介绍啊,感觉这篇论文到introduction这里其实是远不如GS-SLAM的,说了一堆漂亮的词语。本质上就是用了3DGS,其他的改进相对GS-SLAM少些。
理论部分其实就是GS-SLAM的简写版本(当然也是一点不一样,但是没有什么看的必要了,直接看实验效果好了)
定位精度上,仔细对比下会发现比GS-SLAM有一点点提升

而mapping方面(表格3有深度恢复的精度,表格2仅仅有恢复的相似度)。有意思的新实验是分为了train view与novel view的恢复效果对比(仔细跟GS-SLAM对比应该是各有千秋吧)

下面是有novel view的,这算是一个新的基准了,用novel view来验证恢复的效果
表格2的渲染性能是在作为输入传递的相同训练视图上进行评估的,方法可以简单地具有较高的容量并过拟合这些图像。因此,更好的评估方法是进行新视角渲染的评估。然而,所有当前的SLAM基准测试都没有一个独立于SLAM算法估计的相机轨迹的保留图像集,因此它们无法用于这个目的。因此,我们利用新的高质量ScanNet++数据集建立了一个新的评估基准。
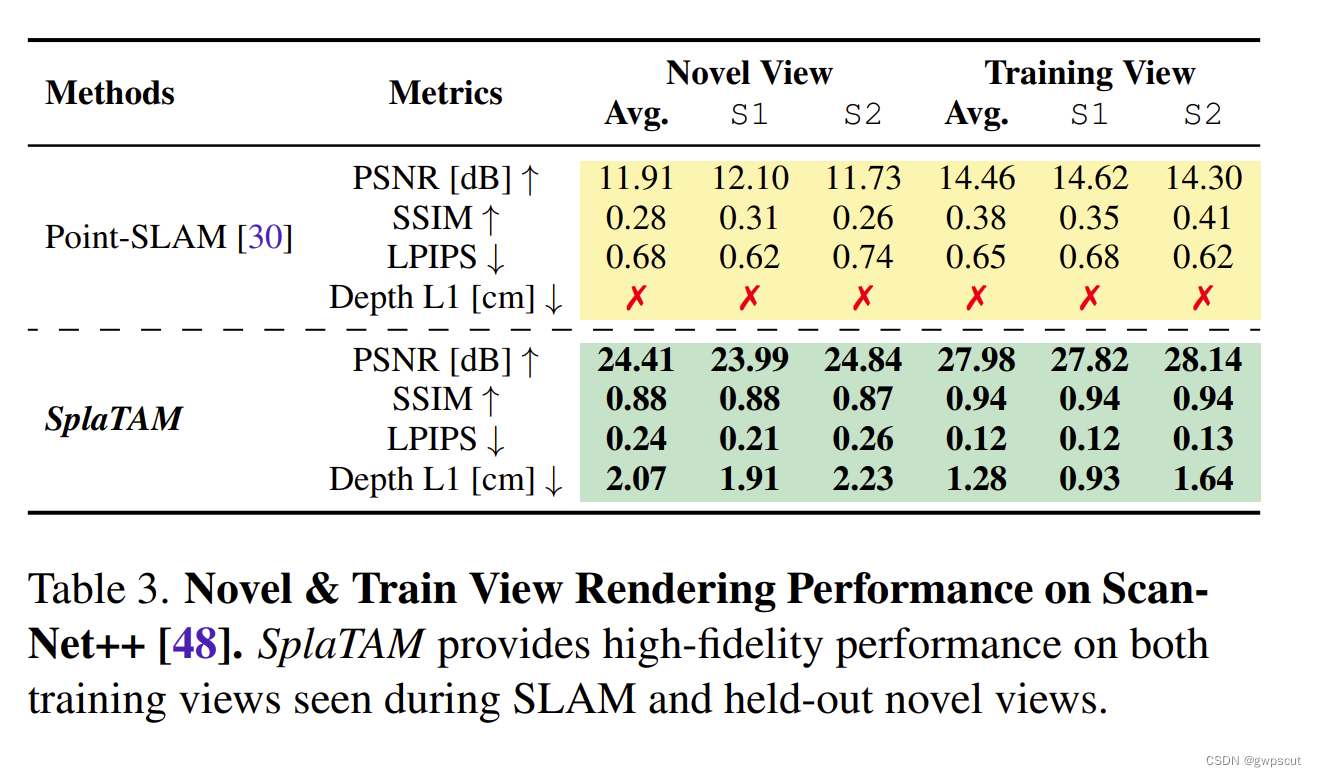

个人感觉这篇论文的性能分析上不如GS-SLAM客观(没有memory之类的对比,而速度3DGS比nerf快那是很正常的),不过可惜GS-SLAM没有开源啦,不然应该是比这个工作更有学习的价值的
Gaussian Splatting SLAM
Gaussian Splatting SLAM
这篇论文也是说自己是首次将3DGS用到SLAM中(单目或RGB-D),当然了相比起前面两个工作都是RGBD的,这个工作确实是第一个实现是单目场景的3DGS-SLAM。而所设计的SLAM方法以3fps实时运行,利用高斯体作为唯一的3D表示,3D Gaussian与camera pose一同联合优化。
从下面的首页图可以看到,第一对于透明物体的恢复效果还是蛮不错的,其次可以开可视化3D gaussian shaded(应该就是把高斯模型给可视化出来?这点是十分直观的,期待可以早点开源,看下代码~)

在3DGS中,场景由大量带有具体方向(orientation)、伸长度(elongation)、颜色(colour)和不透明度(opacity)的高斯体组成。此前用于视觉SLAM的其他世界/地图中心场景表示包括:占用网格(occupancy)或符号距离函数(SDF),体素网格(voxel grids)、meshes、点云(point or surfel clouds)或神经场等。这些方式各有各的缺点:首先采用网格占用(occupancy grid map)了大量内存,而且分辨率有限,即使八叉树或散列可以提高效率,但它们也无法得到大的提升(那难道3GSS比栅格地图要好?);而meshes需要进行困难、不规则的拓扑融合新信息;点云则是不连续的,很难进行融合或者优化;采用神经场(NeRF)的方式则需要花费大量时间进行逐像素光线投射来渲染。
作者证明了3DGS克服了上述方法缺点。作为一种SLAM表示,它与点云最为相似,并继承了它们的效率、局部性和轻松扭曲或修改的能力。然而,它还以平滑、连续可微分的方式表示几何:大量高斯体的稠密云合并在一起,共同定义了一个连续的体绘制函数。最重要的是,目前的显卡设计可以将大量高斯体通过滚雪球法栅格化高效渲染。这种快速、可微分的渲染对我们系统中的跟踪和地图优化循环至关重要。(个人觉得,这部分很好的阐述了3DGS的优势,建议读读原文,此处翻译可能不够传神)
论文的contribution主要有以下:
- 首先导出了相对于3D高斯体建图的相机姿势的解析雅可比矩阵,并展示这可以无缝集成到现有的可微分栅格化渲染流程中,以优化相机姿态与场景几何。
- 其次,引入了一种新的高斯体形状正则化方法(novel Gaussian shape regularisation),以确保几何一致性,作者发现这对于增量重建非常重要。
- 作者提出了一种新的高斯资源分配和裁剪方法(Gaussian resource allocation and pruning method,这大概就是下面表格4验证中memory consumption得以减少的原因?),以保持几何简洁并实现准确的相机跟踪。
算法的框图如下所示

采用3DGS,它使用一组各向异性的高斯体来建立地图。每个高斯体包含光学属性:颜色和不透明度。为了连续的三维表示,在世界坐标系中定义了其均值、协方差,以及表示高斯体的位置和椭球形状。通过抛雪球法和融合多个高斯体,可以合成一个像素颜色。3DGS通过栅格化遍历高斯体,而不是沿相机射线进行行进,因此会跳过空白区域。 在栅格化过程中,采用抛雪球法,使3D高斯体退化成2D高斯体。3D高斯体在世界坐标系中与图像平面上的2D高斯体之间的关系通过投影变换确立。(这部分跟上面的GS-SLAM差不多)
- 相机位姿的优化:在跟踪阶段,只优化当前的相机姿态,不更新场景表示。使用不同的残差函数来度量相机姿态与 3D 高斯地图之间的对齐程度,根据输入是单目还是 RGB-D 来选择使用光度残差、几何残差或两者的组合。给出了相机姿态对 3D 高斯的解析雅可比,实现了快速而稳健的跟踪。(相当于推到出pose对应的雅各比矩阵,然后在3DGS优化的时候可以优化这个pose)
- 关键帧:在关键帧阶段,根据两帧之间的 3D 高斯共视性来选择和管理关键帧,保证关键帧的多样性和非冗余性。在每个关键帧处,插入新的 3D 高斯来捕捉新出现的场景元素和细节。同时,剪掉多余的或不稳定的 3D 高斯,保持场景的清晰和准确:
- 建图:图的目的是保持连贯的3D结构并优化新插入的高斯体。在建图过程中,使用当前窗口中的关键帧来重建当前可见的区域。另外,为了防止全局地图被遗忘,在每次迭代中随机选择两个过去的关键帧。3DGS的栅格化不对视图射线方向的高斯体施加任何约束,即使有深度观测。这在新视角合成的情况下是没有问题的,只要视点选择得足够合理;但是,在连续的SLAM中,这会导致很多伪影,增加跟踪的难度。为了引导模型生成更接近球形的高斯体,作者引入了一个各向同性的正则化项。如下图所示,这样可以避免高斯体在视图方向上过度拉伸,从而减少新视图中的伪影,并提高相机跟踪的效果。
作者还设计了各向异性正则化(这也是3DGS原文提到的,还没做的做工作)效果如下图所示。上:接近训练视角的渲染(看键盘)。下:没有(左)和有(右)各向同性损失的新视角渲染(从键盘的一侧看)。当光度约束不足时,高斯体倾向于沿着观察方向拉长,在新视角中产生伪影,并影响相机跟踪。

接下来看看实验的效果:
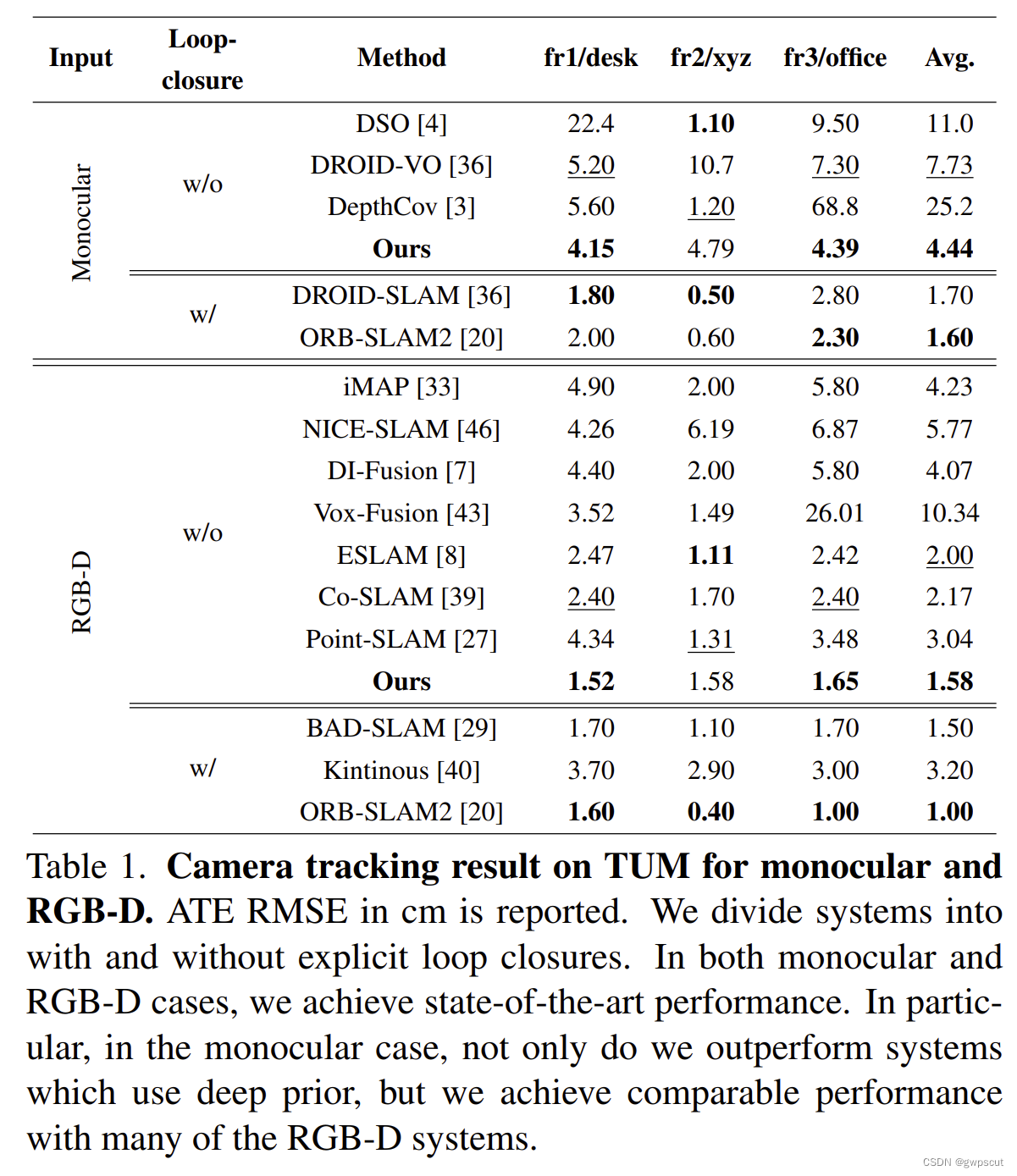
与其他方法在TUM RGB-D数据集上的相机跟踪结果比较。在单目和RGB-D情况下,本文都取得了最好的性能。特别是在单目情况下,不仅超过了使用深度先验的系统,而且与许多RGB-D系统的性能相当。并且在RGB-D下跟orbslam2也差不多
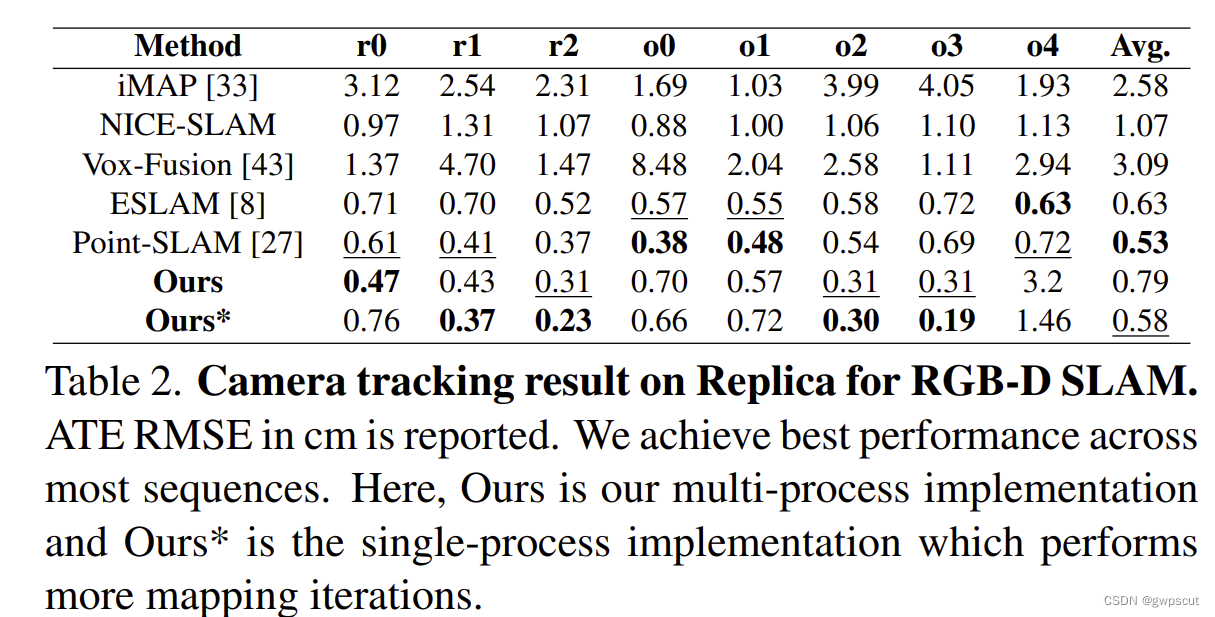
而在Replica数据集上使用RGB-D SLAM的相机跟踪结果比较。在大多数序列上取得了最好的性能。这里,Ours是多进程实现,Ours*是执行更多建图迭代的单进程实现。
下面看看内存占用情况,这大概是因为高斯资源分配和裁剪方法带来的提升?而在GS-SLAM中则是由于使用过多的高斯点云导致memory消耗大。

下面看看渲染的效果对比。在Replica上使用RGB-D SLAM方法的渲染性能比较。论文的方法在大多数渲染指标上都优于现有的方法,而渲染的帧率更是高达769,跟前面几个工作差不多,但是比NeRF的快上很多了~

Gaussian-SLAM: Photo-realistic Dense SLAM with Gaussian Splatting
Gaussian-SLAM Photo-realistic Dense SLAM with Gaussian Splatting
这篇工作通过提出新的策略用于初始化和优化高斯斑点,进一步地将高斯斑点扩展以编码几何信息,来实现pose tracking。同样是采用RGBD作为输入的。而视觉效果上比传统的NeRF-SLAM好上不少,这比较impressive~
额外思考:由于3DGS是显式表达,可以进行场景的editing,故此本身就有利于做slam的下游任务(比如运动规划,语义理解)
本文的贡献如下:
-
使用3DGS作为场景表示的稠密RGBD SLAM方法,使得在实际场景中可以获得领先的渲染结果,并且具有更快的渲染速度。
-
将3DGS扩展以更好地编码几何信息,使其在单目设置中可以实现超越辐射场的重建。
-
由于将原始的3DGS从离线方法调整为在线方法并非直截了当,作者提出了一种在线学习方法(online learning method),用于将地图分割成子地图,并引入高效的初始化和优化策略。
-
进一步通过光度误差最小化来实现使用3DGS进行帧到模型(frame-to-model)跟踪。
论文再讲完related work之后对3DGS以及它的limitation进行了介绍(这部分的分析干货满满~)首先指出了offline 3DGS的一些性质在SLAM问题中是不利的,进而引出为什么要修改成online learning(那其实也变相的指出了上面几个或者其他直接用3DGS来做SLAM的缺陷,这样看来这篇论文的理论深度高于前面几篇了~)
单个3D Gaussian在一个空间物理点![]() 的作用如下公式表述:
的作用如下公式表述:
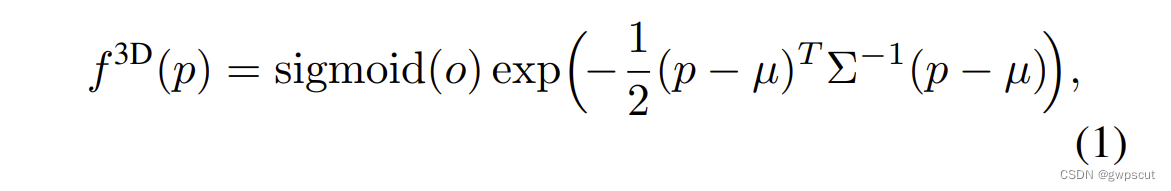
其中,![]() 是3D高斯的均值,协方差矩阵
是3D高斯的均值,协方差矩阵![]() 由尺度(椭球形状)
由尺度(椭球形状)![]() 以及旋转
以及旋转![]() 组成。而是
组成。而是![]() 透明度。通过下面公式将3D高斯投影到图像平面
透明度。通过下面公式将3D高斯投影到图像平面
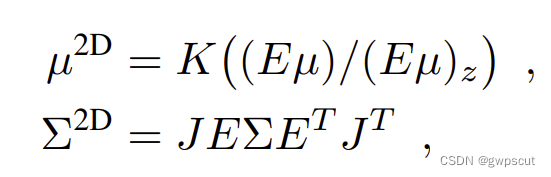
其中,K是内参,E是外参(也就是camera-to-world coordinate),J是公式2(point projection)的雅可比矩阵,也就是
而每个pixel的颜色受所有与从特定像素发射的射线相交的高斯函数的影响。颜色被计算为投影的3D高斯的加权平均值:

其中,V是影响当前pixel的高斯集合。![]() 是
是![]() 的等价物(只是将3D均值和协方差矩阵替换为2D splatted版本)。
的等价物(只是将3D均值和协方差矩阵替换为2D splatted版本)。![]() 是每个高斯的RGB颜色。沿像素的射线投影的每个项都受透射率项的降权影响,该项考虑了先前遇到的高斯的影响。
是每个高斯的RGB颜色。沿像素的射线投影的每个项都受透射率项的降权影响,该项考虑了先前遇到的高斯的影响。
采用3DGS来做SLAM的限制:
- (Seeding strategy for online SLAM)在线SLAM的初始化策略:如上所述,原始的初始化策略基于一个表面点的稀疏点云,并在优化过程中动态地创建和删除高斯。这种迭代动态行为可能导致映射迭代和计算时间的大幅变化,这对于SLAM来说是不太理想的。
- (Online optimization)在线优化:一个简单的在线实现可能只是在所有帧上进行优化,但对于较长的序列,这对于实时帧率来说会变得太慢。(本质上就是太多高斯一起优化,不行,计算量过大了)。
- (Catastrophic forgetting in online optimization)在线优化中的灾难性遗忘:为了避免随着每个新帧而导致每帧映射的线性增长,一种替代方法是仅使用当前帧优化高斯场景表示。虽然优化会迅速收敛以很好地适应新的训练帧,但先前映射的视图将严重退化。这不仅是高斯形状,包括尺度和方向,还包括球谐颜色编码(颜色),其中局部函数调整可能会显著改变球形域中其他区域的函数值。(如果只用一个,那就会产生遗忘)
- (Highly randomized solution)高度随机化的解决方案:在离线和在线情况下,splatting optimizatio的结果高度依赖于高斯的初始化。在优化过程中,高斯可能会在不同方向上突然增长,具体取决于相邻的高斯。最后,3D高斯的固有对称性允许在不影响损失函数的情况下进行参数修改,导致非唯一的解决方案,这通常是优化中不希望出现的特性。(也就是容易出现多个解)。
- (Poor extrapolation capabilities)差劲的外推能力:与上一个问题相关,高斯通常会不受控制地扩展到未观察到的区域。在离线设置中,良好的视图覆盖通常会很好地约束大多数高斯,但在稀疏视图SLAM设置中,新视图经常包含由先前不受约束的高斯引起的伪影。(也就是所谓的,视角覆盖不够,就会产生很多伪影)
- (Limited geometric accuracy)有限的几何精度:在单目设置中使用Gaussian splatting时,其编码精确几何结构的能力有限。虽然在具有多个视图的受限制的设置中几何估计相对较好,但从单摄像头设置中得到的深度图对于3D重建是无效的。(因此论文让3DGS编码辐射场以及几何细节结构)
论文的框图如下图所示。在给定估计的相机姿态的情况下,进行如下的映射过程。首先,对输入点云进行子采样,并根据子地图的密度估算活动子地图中新的3D高斯的位置。在将这个稀疏的新3D高斯集合添加到活动子地图高斯点云后,它们进行联合优化。利用差分光栅化器渲染所有贡献于活动子地图的关键帧的深度图和彩色图像。通过对输入RGBD帧施加深度、颜色重新渲染和正则化损失,对3D高斯的参数进行优化。

首先为了解决遗忘问题同时也让高斯mapping过程高效,论文将输入序列分为子图(解决了上面问题的第2和第3点)。每个子图的建模如下(这部分跟GS-SLAM有点像,只是GS-SLAM没有分子图而已)
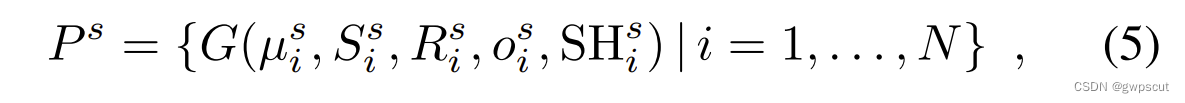
而关于上面的问题1,就是作者提出的Novel strategies for seeding 3DGS(具体实现及意义可能有源码会更好理解吧~)。
为了抵消灾难性遗忘,作者优化活动子地图以能够渲染给定子地图中看到的所有关键帧的深度和颜色。
而对于上面的问题6,作者将几何和颜色同时进行编码,实际上应该就是额外多一个优化几何的函数。公式6作为颜色的supervision而公式7作为深度图的supervision,因此引入了几何的约束。
![]()
而tracking部分测试通过RGBD odometry初始化然后通过frame-to-model 来进一步优化pose。
接下来看看实验结果。首先是渲染的性能:

论文提出的算法统一达到了最好。
而深度恢复的性能也不错
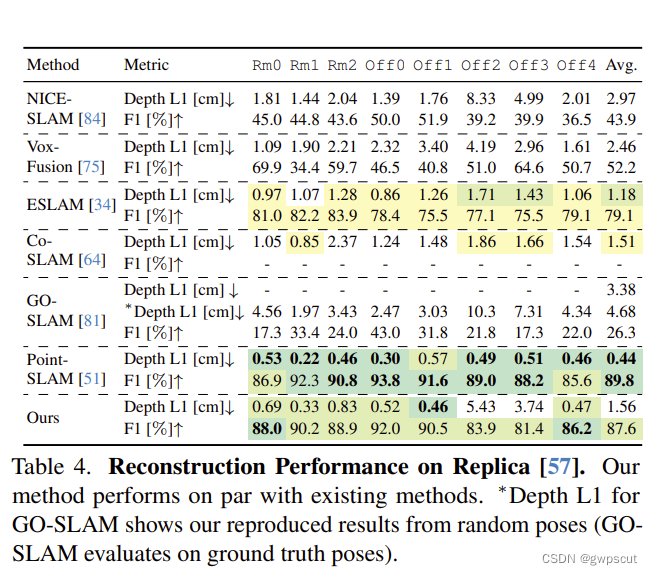
至于定位精度虽然没有跟传统方法比,但比起其他方法也是有提升

下面表格则是对比了传统方法了

恢复的视觉效果是非常不错的

速率分析:

Photo-SLAM: Real-time Simultaneous Localization and Photorealistic Mapping for Monocular, Stereo, and RGB-D Cameras
这个工作从题目就可以看到是针对单目、双目、RGB-D三种情况下的3DGS-SLAM了,从下面的首页图可以看到,其进一步的刷新了渲染的帧率,高达1000FPS!

最近在NeRF-SLAM系统展现了在联合定位和照片级别视图重建(photorealistic view reconstruction)方面有重大的进展。然而,现有的方法完全依赖于隐式表示,因此资源需求巨大,无法在便携设备上运行,这与SLAM的原始意图相背离。本文提出了Photo-SLAM,一个具有hyper primitives map的新型SLAM框架。具体而言,我们同时利用显式几何特征进行定位,并学习隐式光度特征来表示观察环境的纹理信息。除了基于几何特征的actively densifying hyper primitives外,我们还引入了一种基于高斯金字塔的训练方法(Gaussian-Pyramid-based training method),逐步学习多层次(多尺度)特征,提高了照片级mapping性能。
框图如下所示,看着有点像各种技术的结合体。所谓hyper primitives map由ORB特征、rotation,scaling,density以及spherical harmonic (SH) coefficients(颜色)组成。这个hyper primitives map使得可以通过因子图来求解位姿同时通过后向传播渲染图像与原图的loss来学习mapping。而image渲染是通过3DGS来实现的。进一步地通过Gaussian-Pyramid-based training method来提升mapping的性能

定位部分是通过orb特征点来建立2D-2D以及2D-3D的约束,然后构建因子图来求解。mapping部分分为了geometry以及photorealistic mapping。前者跟localization结合感觉就是一个orbslam。而后者就是用3DGS来做。
而对于photorealistic mapping用了稀疏的geometry mapping 来进行致密化(感觉就像是ORBSLAM的稀疏特征点用来做3DGS),同时设计了一个Gaussian-Pyramid-based training method来让效果变得更好。
而果然实验部分就写了

感觉其实就是OrbeezSLAM的3DGS版本了hhh~
下面看看实验效果吧。作者这个实验还是比较的丰富的,定位精度方面呢竟然超越了orbslam3(不过或许是orbslam3本就不太如orbslam2吧hhh)。而mapping方面效果是比较好的.而memory方面好像没有3DGS所提及存在的问题,可能是因为用的高斯模型不多(初始化3DGS模型点就不多?)

当然在tum数据集下却没有orbslam3好了

定性效果如下,确实效果是不错的~

3DGS in?Autonomous Driving
Street Gaussians for Modeling Dynamic Urban Scenes
这篇论文主要解决了从单目视频中建模动态城市街道场景的问题。最近的方法对NeRF进行了扩展,将跟踪的车辆的姿态融入到动画车辆中,实现了动态城市街道场景的真实感视图合成。但其训练和渲染速度较慢,且对跟踪的车辆位姿精度要求较高(依赖于the accuracy of the tracked bounding boxes),具有很大的局限性。因此,本文引入了一种新的显式场景表示方法--Street Gaussians,它解决了所有这些限制。具体来说,动态的城市街道被表示为一组带有semantic logits(语义标签)和3D高斯的点云,每个点云与前景车辆或背景相关联。为了对前景物体车辆的动态进行建模,每个物体点云都用可优化的跟踪姿态进行优化,并为动态外观建立了动态球谐模型(dynamic spherical harmonics model)。显式表示允许简单地组成目标车辆和背景,这反过来又允许在半小时的训练时间内进行133 FPS ( 1066 × 1600分辨率)的场景编辑操作和渲染。
这篇论文的关键点是利用点云来构建动态场景。将城市街道分为静态的背景以及运动的车辆,然后分布进行3D Gaussians建模。对于动态的前景,用优化后的车辆位姿来将几何结构建模成一系列的点。其中的每个点存储为3D Gaussians参数。而随时间变化的外观就用4D的spherical harmonics model 来表达(输入时间序列,就会估算其颜色信息)。
同时,基于这个场景的表达,作者也开发了跟踪位姿的优化策略(但还是需要optimizable input pose,简而言之就是位姿输入是要的,但是不精确的也行,因为它可以进行优化)。
它的系统框图如下图所示:将动态的城市街道场景表示为一组基于点的背景和前景对象,并具有可优化的跟踪的车辆位姿。每个点被分配一个3D高斯,包括位置、不透明度和由旋转和尺度组成的协方差来表示几何形状。为了表示外观,为每个背景点分配了一个球谐模型,而前景点则与一个动态球谐模型相关联。基于点的显式表示允许单独模型的简单组合,这可以实现高质量图像和语义地图(如果在训练过程中提供2D语义信息的话)的实时渲染,以及用于编辑应用程序的前景对象分解。

接下来看看实验效果,定量分析的指标确实都比其他方法好些。
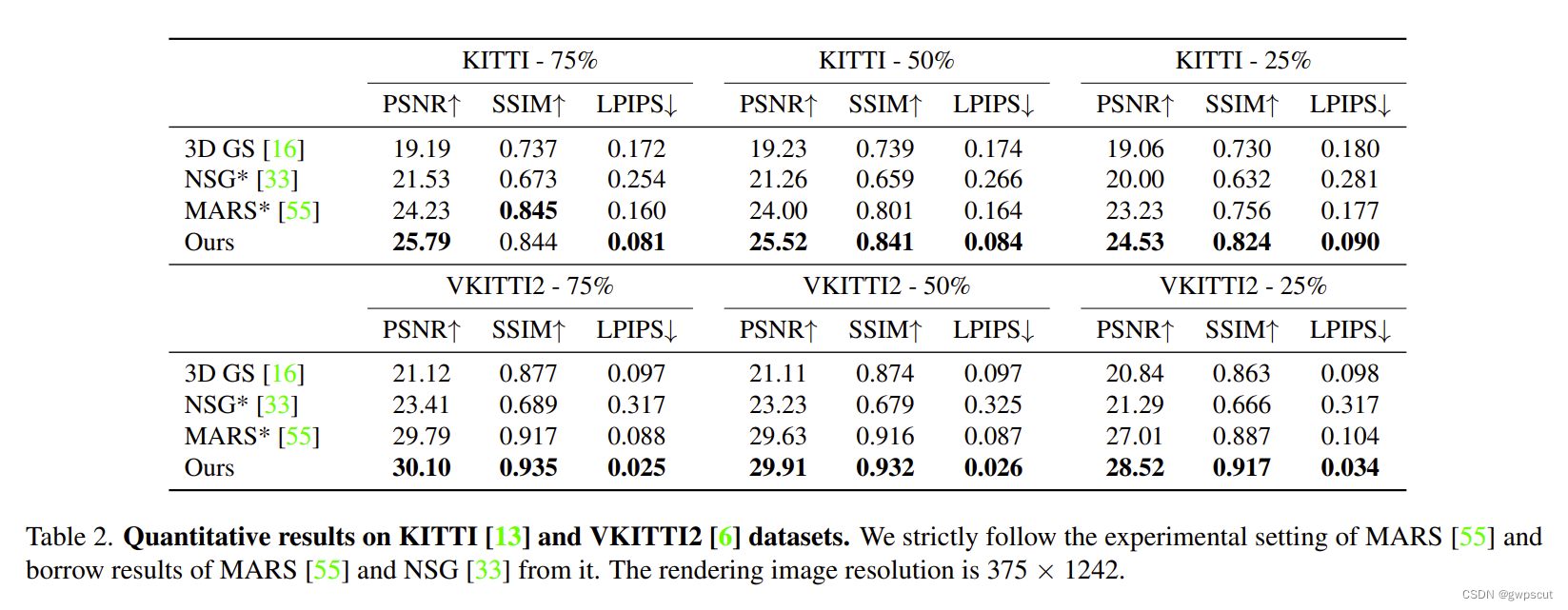
而定性分析可以看到视觉效果确实很些,特别是通过网页的互动图片,展示更加明显。

此外,还支持物体分离、场景编辑以及语义分割等等。
看这篇论文原本想得到的inspiration是:3DGS的原文说它memory方面比nerf要大上不少,特别是大场景。而对于自动驾驶估计是更明显的,但是本文没有做分析~期待有深入分析这一点的工作~
DrivingGaussian: Composite Gaussian Splatting for Surrounding Dynamic Autonomous Driving Scenes
本文提出 DrivingGaussian,这是第一个基于 Composite Gaussian Splatting 的大规模动态驾驶场景的表示和建模框架。对于具有移动物体的复杂场景,本文首先使用增量静态3D高斯 (incremental static 3D Gaussians) 顺序渐进地对整个场景的静态背景进行建模 (类似于上面的Street Gaussians)。然后,本文利用复合动态高斯图(composite dynamic Gaussian graph) 来处理多个移动物体,单独重建每个物体并恢复它们在场景中的准确位置和遮挡关系。本文进一步使用 LiDAR 先验进行 Gaussian Splatting 来重建具有更多细节的场景并保持全景一致性(panoramic consistency)。
论文的主要贡献就是引入了两个新颖的模块,包括增量静态3D高斯 (Incremental Static 3D Gaussians) 和复合动态高斯图(Composite Dynamic Gaussian Graphs)。前者增量地重建静态背景,而后者则使用高斯图对多个动态物体进行建模。在激光雷达先验的辅助下,该方法有助于在大规模驾驶场景中恢复完整的几何形状。
论文的框架如下图所示,左:DrivingGaussian 从多传感器获取连续数据,包括多相机图像和 LiDAR。中:为了表示大规模动态驾驶场景,本文提出了 Composite Gaussian Splatting ,它由两个部分组成。第一部分增量地重建广泛的静态背景,而第二部分使用高斯图构造多个动态物体并将它们动态地集成到场景中。右图:DrivingGaussian 在多个任务和应用场景中展示了良好的性能。
本文的关键思想是使用来自多个传感器的顺序数据对复杂的驾驶场景进行分层建模。本文采用 Composite Gaussian Splatting 将整个场景分解为静态背景和动态物体,分别重建每个部分。具体来说,首先使用增量静态3D高斯从环视多相机视图顺序构建综合场景。然后,本文采用复合动态高斯图来单独重建每个运动物体,并基于高斯图将它们动态地集成到静态背景中。在此基础上,通过 Gaussian Splatting 进行全局渲染,捕捉现实世界中的遮挡关系,包括静态背景和动态物体。此外,本文在 GS 表示中加入了 LiDAR 先验,与利用随机初始化或SfM生成的点云相比,它能够恢复更精确的几何形状并保持更好的多视图一致性。

对于composite Gaussian splatting本人不是特别感兴趣,所以此处就不深入学习原理了,这里单纯看看采用LiDAR prior。
基本的3D-GS尝试通过运动结构(SfM)初始化高斯。然而,用于自动驾驶的无界城市场景包含许多多尺度的背景和前景。然而,它们仅通过极为稀疏的视图被瞥见,导致几何结构的错误和不完整恢复。因此采用LiDAR点来提供3DGS的初始化。
首先合并多帧LiDAR扫描,以获取场景的完整点云。然后遵从COLMAP的方法,从每个图像中提取图像特征![]() 。接下来,将LiDAR点投影到周围的图像上。对于每个LiDAR点l,我们将其坐标转换为相机坐标系,并通过投影与相机图像平面的2D像素进行匹配:
。接下来,将LiDAR点投影到周围的图像上。对于每个LiDAR点l,我们将其坐标转换为相机坐标系,并通过投影与相机图像平面的2D像素进行匹配:

其中![]() 是图像的2D pixel,R和T是平移和变换矩阵,K是相机的内参。值得注意的是,来自LiDAR的点可能会被投影到跨越多个图像的多个像素上。因此,我们选择到图像平面最短欧氏距离的点,并将其保留为投影点,分配颜色。将密集束调整(DBA)扩展到多摄像头设置,并获取更新的LiDAR点。这样看来是将雷达点作为特征点了,因为场景太大,远处的点很难提取成特征。
是图像的2D pixel,R和T是平移和变换矩阵,K是相机的内参。值得注意的是,来自LiDAR的点可能会被投影到跨越多个图像的多个像素上。因此,我们选择到图像平面最短欧氏距离的点,并将其保留为投影点,分配颜色。将密集束调整(DBA)扩展到多摄像头设置,并获取更新的LiDAR点。这样看来是将雷达点作为特征点了,因为场景太大,远处的点很难提取成特征。
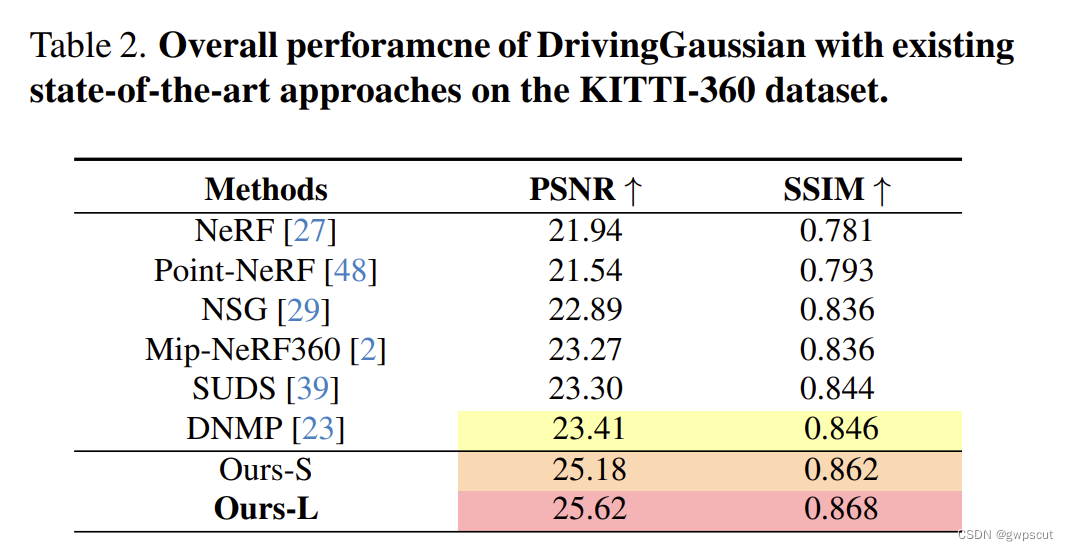
实验效果如下:DrivingGaussian 实现了环视动态自动驾驶场景的逼真渲染性能。其他的方法要么在大范围背景中产生 unpleasant 伪影和模糊,要么难以重建动态物体和详细的场景几何形状。 DrivingGaussian 引入了 Composite Gaussian Splatting 来有效地表示复杂的环视驾驶场景中的静态背景和多个动态物体。 DrivingGaussian 能够跨多相机高质量合成环视视图,并促进长期动态场景重建。

从实验效果来看,采用sfm或lidar点的性能好像相差不大

参考资料
[NeRF坑浮沉记]3D Gaussian Splatting入门:如何表达几何 - 知乎
计算机图形学入门(九)-几何(基本表示方法:隐式和显式)_计算机视觉中的显式和隐式的区别-CSDN博客
现代计算机图形学基础二:光栅化(Rasterization) - 知乎
3D Gaussian Splatting:用于实时的辐射场渲染-CSDN博客
3D Gaussian Splatting | Yin的笔记本
3D Gaussian Splatting源码解读 - 知乎
3D Gaussian Splatting cuda源码解读 - 知乎
100倍加速!GS-SLAM:最新开源的超快NeRF SLAM! - 知乎
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!