TTS | NaturalSpeech语音合成论文详解及项目实现【正在更新中】
?----------------------------------🔊 语音合成 相关系列直达 🔊 -------------------------------------
?NaturalSpeech:正在更新中~
?NaturalSpeech2:TTS | NaturalSpeech2语音合成论文详解及项目实现
本文主要是 讲解了NaturalSpeech论文及项目~
论文题目:202205_NaturalSpeech: End-to-End Text to Speech Synthesis with Human-Level Quality
论文地址:[2205.04421] NaturalSpeech: End-to-End Text to Speech Synthesis with Human-Level Quality (arxiv.org)
1.论文详解
(本博客主要讲解系统实现部分,介绍和背景省略,主要讲解论文第三章)
1.1.设计原理
受图像/视频生成的启发,使用VQ-VAE将高维图像压缩为低维表示以方便生成,该模型利用变分自编码器(Variational Auto-Encoder, VAE),将高维语音x压缩为z表示,相应的先验(记作 p(z|y))则从文本序列 y 中获取。
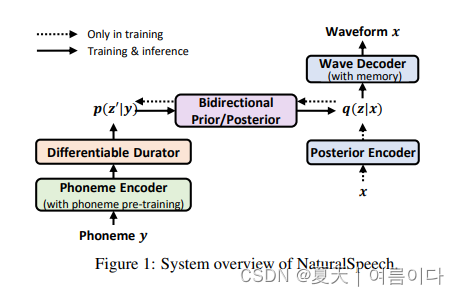
考虑到来自语音的后验比来自文本的先验更加复杂,研究员们设计了几个模块,尽可能近似地对后验和先验进行匹配,从而通过y→p(z|y)→p(x|z)→x实现文本到语音的合成。
- 在音素编码器上利用大规模音素预训练(phoneme pre-training),从音素序列中提取更好的表达。
- 利用由时长预测器和上采样层组成的完全可微分的时长模块(durator),来改进音素的时长建模。
- 基于流模型(flow)的双向先验/后验模块(bidirectional prior/posterior),可以进一步增强先验 p(z|y) 以及降低后验 q(z|x) 的复杂性。
- 基于记忆的变分自编码器(Memory VAE),可降低重建波形所需的后验复杂性。
1.2.音素编码
音素编码器θpho和音素序列y和作为输入,并输出音素隐藏序列,进行大规模音素词典学习,提高音素编码器的表达能力。之前的研究表明,在字母/单词级别进行预学习并将预训练模型应用于音素编码器会导致不一致,并且直接使用音素词典学习具有容量限制,因为音素词汇量太小。为了避免这个问题,使用混合音素预学习,它使用音素和上音素(相邻音素合并在一起)作为模型的输入,如图(c)所示。使用掩码语言建模时,会随机屏蔽一些高音素标记及其对应的音素标记,同时预测掩码音素和高音素。混合音素预训练后,使用预训练模型对TTS系统的音素编码器进行初始化。

1.3.可微分的 Durator
可微分的θdur将音素隐藏序列作为输入,并在帧级输出先前的分布序列,如图(a)所示。事先分发给
用于可微分的由几个模块组成
- 基于音素编码器的持续时间预测器,用于预测每个音素的持续时间
- 一个可训练的上采样层,它利用预测的持续时间来训练投影矩阵,以音素隐藏序列的可微分方式将音素级别缩放到帧级别
- 两个附加线性层,用于计算隐藏的均值和方差。

与TTS模型一起,可以以完全可微的方式优化持续时间预测、可训练的上采样层和均值/方差线性层,以减少与先前持续时间预测的学习推理差异。真实持续时间用于训练,预测持续时间用于推理。它以软灵活的方式更好地利用持续时间,而不是硬缩放,从而减轻了持续时间预测不准确的副作用。
1.4.双向先/后验
如图(b)

?双向前/后验模块是降低后验复杂性。选择流模型作为双向先/后验模型,目标函数是使用 KL 散度损失的简化后验函数,
对比实验

1.4.消融实验

推理延迟
对比了模型模块

2.项目实现
2.0.环境设置
git clone https://github.com/heatz123/naturalspeech
cd naturalspeech
pip install -r requirements.txt
apt-get install espeak
# 准备数据集
# 数据预处理
python preprocess.py --text_index 1 --filelists filelists/ljs_audio_text_train_filelist.txt filelists/ljs_audio_text_val_filelist.txt filelists/ljs_audio_text_test_filelist.txt2.1.数据预处理
2.1.1.LJS数据集
在本项目中,包含了ljs数据集的预处理文件,所以不用单独处理,下载数据集命令
wget https://data.keithito.com/data/speech/LJSpeech-1.1.tar.bz2
tar -xf LJSpeech-1.1.tar.bz2
ln -s LJSpeech-1.1/wavs/ DUMMY1

下载数据集后,要将数据集改为以下格式(也就是将文件夹重命名为DUMMY1)
cd durations
tar -xf durations.tar.bz2
将文件夹改为如下格式
2.1.2.自己的数据集
首先确认语言,如果是中文就需要将vits中对于中文的处理代码复制到text文件夹下
mandarin.py【附录1】
在text/cleaners.py中添加数据预处理
①添加所需要引用的包:例如
- from text.mandarin import number_to_chinese, chinese_to_bopomofo, latin_to_bopomofo, chinese_to_romaji, chinese_to_lazy_ipa, chinese_to_ipa, chinese_to_ipa2
②添加数据处理代码,例如
- chinese_cleaners【附录2】
- korean_cleaners
-
cjke_cleaners(中日韩英)【附录3】
?复制ljs.json文件,重命名为自己的文件(自定义名称),对数据进行处理
python preprocess_texts.py --text_index 1 --filelists filelists/自己数据_train_filelist.txt filelists/自己数据_val_filelist.txt
# python preprocess_texts.py --text_index 1 --filelists filelists/cjke_history_train_filelist.txt filelists/cjke_history_val_filelist.txt --text_cleaners cjke_cleaners2且数据与数据名称相对应

2.2.训练
2.2.1.训练LJS数据集
python train.py -c configs/ljs.json -m [run_name] --warmup
# python train.py -c configs/ljs.json -m ljs_ns --warmup?
2.2.2.训练自己的数据集
将之前的vits的预训练模型保存到
python train.py -c configs/history.json -m his_ns2.3.推理
3.Naturalspeech与VITS的区别
Naturalspeech 是一种基于 VAE 的模型,它采用多种技术来改进先验并简化后验。它与 VITS 在几个方面不同,包括:
- 音素预训练:Naturalspeech 在大型文本语料库上使用预训练的音素编码器,该编码器是通过对音素序列进行掩码语言建模获得的。
- 可微的后验器:后验在帧级别操作,而前验在音素级别操作。Naturalspeech 使用可微分的 durator 来弥合长度差异,从而扩展柔软而灵活的功能。
- 双向前/后:自然语音通过归一化流来减少后部并增强先验,这在两个方向上映射,具有向前和向后损失。
- 基于记忆的VAE:通过使用Q-K-V注意力的记忆库进一步增强了先验。
错误与解决
【PS1】ValueError: too many values to unpack (expected 2)

?数据预处理格式不对
数据格式根据自己选择的方式
如果是man
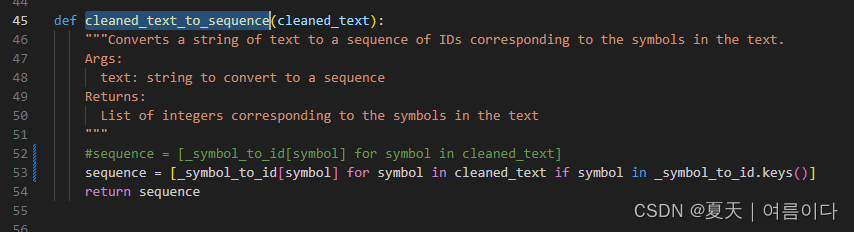
【PS2】KeyError: '`'

?将naturalspeech/text/__init__.py中的cleaned_text_to_sequence改为
sequence = [_symbol_to_id[symbol] for symbol in cleaned_text if symbol in _symbol_to_id.keys()]
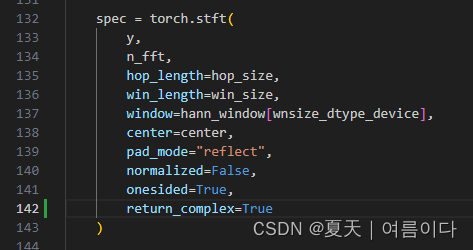
【PS3】RuntimeError: stft requires the return_complex parameter be given for real inputs, and will further require that return_complex=True in a future PyTorch release.?
/naturalspeech/utils/mel_processing.py
return_complex=True
【PS4】TypeError: mel() takes 0 positional arguments but 5 were given
库版本问题,此时 librosa版本是0.10.0改为0.9.1或者0.8.0
pip install librosa==0.9.1
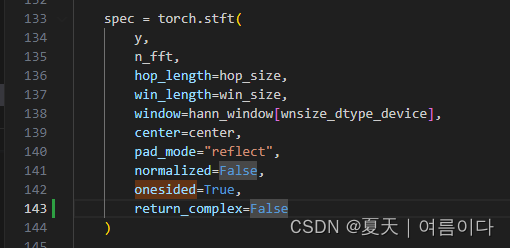
【PS5】RuntimeError: mat1 and mat2 shapes cannot be multiplied (80x513 and 1x513)
pytorch包太新了导致的修改mel_processing.py,
83行【onesided=True后增加,return_complex=False】
143行【onesided=True后增加,return_complex=False】
错误总结
出现【PS345】问题的根本原因是torch版本是2.0.1,如果是1.13.1版本不会出现相关问题。
附录
【附录1】中文普通话处理代码
import os
import sys
import re
from pypinyin import lazy_pinyin, BOPOMOFO
import jieba
import cn2an
import logging
# List of (Latin alphabet, bopomofo) pairs:
_latin_to_bopomofo = [(re.compile('%s' % x[0], re.IGNORECASE), x[1]) for x in [
('a', 'ㄟˉ'),
('b', 'ㄅㄧˋ'),
('c', 'ㄙㄧˉ'),
('d', 'ㄉㄧˋ'),
('e', 'ㄧˋ'),
('f', 'ㄝˊㄈㄨˋ'),
('g', 'ㄐㄧˋ'),
('h', 'ㄝˇㄑㄩˋ'),
('i', 'ㄞˋ'),
('j', 'ㄐㄟˋ'),
('k', 'ㄎㄟˋ'),
('l', 'ㄝˊㄛˋ'),
('m', 'ㄝˊㄇㄨˋ'),
('n', 'ㄣˉ'),
('o', 'ㄡˉ'),
('p', 'ㄆㄧˉ'),
('q', 'ㄎㄧㄡˉ'),
('r', 'ㄚˋ'),
('s', 'ㄝˊㄙˋ'),
('t', 'ㄊㄧˋ'),
('u', 'ㄧㄡˉ'),
('v', 'ㄨㄧˉ'),
('w', 'ㄉㄚˋㄅㄨˋㄌㄧㄡˋ'),
('x', 'ㄝˉㄎㄨˋㄙˋ'),
('y', 'ㄨㄞˋ'),
('z', 'ㄗㄟˋ')
]]
# List of (bopomofo, romaji) pairs:
_bopomofo_to_romaji = [(re.compile('%s' % x[0]), x[1]) for x in [
('ㄅㄛ', 'p?wo'),
('ㄆㄛ', 'p?wo'),
('ㄇㄛ', 'mwo'),
('ㄈㄛ', 'fwo'),
('ㄅ', 'p?'),
('ㄆ', 'p?'),
('ㄇ', 'm'),
('ㄈ', 'f'),
('ㄉ', 't?'),
('ㄊ', 't?'),
('ㄋ', 'n'),
('ㄌ', 'l'),
('ㄍ', 'k?'),
('ㄎ', 'k?'),
('ㄏ', 'h'),
('ㄐ', '??'),
('ㄑ', '??'),
('ㄒ', '?'),
('ㄓ', '?`?'),
('ㄔ', '?`?'),
('ㄕ', 's`'),
('ㄖ', '?`'),
('ㄗ', '??'),
('ㄘ', '??'),
('ㄙ', 's'),
('ㄚ', 'a'),
('ㄛ', 'o'),
('ㄜ', '?'),
('ㄝ', 'e'),
('ㄞ', 'ai'),
('ㄟ', 'ei'),
('ㄠ', 'au'),
('ㄡ', 'ou'),
('ㄧㄢ', 'yeNN'),
('ㄢ', 'aNN'),
('ㄧㄣ', 'iNN'),
('ㄣ', '?NN'),
('ㄤ', 'aNg'),
('ㄧㄥ', 'iNg'),
('ㄨㄥ', 'uNg'),
('ㄩㄥ', 'yuNg'),
('ㄥ', '?Ng'),
('ㄦ', '??'),
('ㄧ', 'i'),
('ㄨ', 'u'),
('ㄩ', '?'),
('ˉ', '→'),
('ˊ', '↑'),
('ˇ', '↓↑'),
('ˋ', '↓'),
('˙', ''),
(',', ','),
('。', '.'),
('!', '!'),
('?', '?'),
('—', '-')
]]
# List of (romaji, ipa) pairs:
_romaji_to_ipa = [(re.compile('%s' % x[0], re.IGNORECASE), x[1]) for x in [
('?y', '?'),
('??y', '??'),
('??y', '??'),
('NN', 'n'),
('Ng', '?'),
('y', 'j'),
('h', 'x')
]]
# List of (bopomofo, ipa) pairs:
_bopomofo_to_ipa = [(re.compile('%s' % x[0]), x[1]) for x in [
('ㄅㄛ', 'p?wo'),
('ㄆㄛ', 'p?wo'),
('ㄇㄛ', 'mwo'),
('ㄈㄛ', 'fwo'),
('ㄅ', 'p?'),
('ㄆ', 'p?'),
('ㄇ', 'm'),
('ㄈ', 'f'),
('ㄉ', 't?'),
('ㄊ', 't?'),
('ㄋ', 'n'),
('ㄌ', 'l'),
('ㄍ', 'k?'),
('ㄎ', 'k?'),
('ㄏ', 'x'),
('ㄐ', 't??'),
('ㄑ', 't??'),
('ㄒ', '?'),
('ㄓ', 'ts`?'),
('ㄔ', 'ts`?'),
('ㄕ', 's`'),
('ㄖ', '?`'),
('ㄗ', 'ts?'),
('ㄘ', 'ts?'),
('ㄙ', 's'),
('ㄚ', 'a'),
('ㄛ', 'o'),
('ㄜ', '?'),
('ㄝ', '?'),
('ㄞ', 'a?'),
('ㄟ', 'e?'),
('ㄠ', 'ɑ?'),
('ㄡ', 'o?'),
('ㄧㄢ', 'j?n'),
('ㄩㄢ', '??n'),
('ㄢ', 'an'),
('ㄧㄣ', 'in'),
('ㄩㄣ', '?n'),
('ㄣ', '?n'),
('ㄤ', 'ɑ?'),
('ㄧㄥ', 'i?'),
('ㄨㄥ', '??'),
('ㄩㄥ', 'j??'),
('ㄥ', '??'),
('ㄦ', '??'),
('ㄧ', 'i'),
('ㄨ', 'u'),
('ㄩ', '?'),
('ˉ', '→'),
('ˊ', '↑'),
('ˇ', '↓↑'),
('ˋ', '↓'),
('˙', ''),
(',', ','),
('。', '.'),
('!', '!'),
('?', '?'),
('—', '-')
]]
# List of (bopomofo, ipa2) pairs:
_bopomofo_to_ipa2 = [(re.compile('%s' % x[0]), x[1]) for x in [
('ㄅㄛ', 'pwo'),
('ㄆㄛ', 'p?wo'),
('ㄇㄛ', 'mwo'),
('ㄈㄛ', 'fwo'),
('ㄅ', 'p'),
('ㄆ', 'p?'),
('ㄇ', 'm'),
('ㄈ', 'f'),
('ㄉ', 't'),
('ㄊ', 't?'),
('ㄋ', 'n'),
('ㄌ', 'l'),
('ㄍ', 'k'),
('ㄎ', 'k?'),
('ㄏ', 'h'),
('ㄐ', 't?'),
('ㄑ', 't??'),
('ㄒ', '?'),
('ㄓ', 't?'),
('ㄔ', 't??'),
('ㄕ', '?'),
('ㄖ', '?'),
('ㄗ', 'ts'),
('ㄘ', 'ts?'),
('ㄙ', 's'),
('ㄚ', 'a'),
('ㄛ', 'o'),
('ㄜ', '?'),
('ㄝ', '?'),
('ㄞ', 'a?'),
('ㄟ', 'e?'),
('ㄠ', 'ɑ?'),
('ㄡ', 'o?'),
('ㄧㄢ', 'j?n'),
('ㄩㄢ', 'y?n'),
('ㄢ', 'an'),
('ㄧㄣ', 'in'),
('ㄩㄣ', 'yn'),
('ㄣ', '?n'),
('ㄤ', 'ɑ?'),
('ㄧㄥ', 'i?'),
('ㄨㄥ', '??'),
('ㄩㄥ', 'j??'),
('ㄥ', '??'),
('ㄦ', '??'),
('ㄧ', 'i'),
('ㄨ', 'u'),
('ㄩ', 'y'),
('ˉ', '?'),
('ˊ', '??'),
('ˇ', '???'),
('ˋ', '??'),
('˙', ''),
(',', ','),
('。', '.'),
('!', '!'),
('?', '?'),
('—', '-')
]]
def number_to_chinese(text):
numbers = re.findall(r'\d+(?:\.?\d+)?', text)
for number in numbers:
text = text.replace(number, cn2an.an2cn(number), 1)
return text
def chinese_to_bopomofo(text):
text = text.replace('、', ',').replace(';', ',').replace(':', ',')
words = jieba.lcut(text, cut_all=False)
text = ''
for word in words:
bopomofos = lazy_pinyin(word, BOPOMOFO)
if not re.search('[\u4e00-\u9fff]', word):
text += word
continue
for i in range(len(bopomofos)):
bopomofos[i] = re.sub(r'([\u3105-\u3129])$', r'\1ˉ', bopomofos[i])
if text != '':
text += ' '
text += ''.join(bopomofos)
return text
def latin_to_bopomofo(text):
for regex, replacement in _latin_to_bopomofo:
text = re.sub(regex, replacement, text)
return text
def bopomofo_to_romaji(text):
for regex, replacement in _bopomofo_to_romaji:
text = re.sub(regex, replacement, text)
return text
def bopomofo_to_ipa(text):
for regex, replacement in _bopomofo_to_ipa:
text = re.sub(regex, replacement, text)
return text
def bopomofo_to_ipa2(text):
for regex, replacement in _bopomofo_to_ipa2:
text = re.sub(regex, replacement, text)
return text
def chinese_to_romaji(text):
text = number_to_chinese(text)
text = chinese_to_bopomofo(text)
text = latin_to_bopomofo(text)
text = bopomofo_to_romaji(text)
text = re.sub('i([aoe])', r'y\1', text)
text = re.sub('u([ao?e])', r'w\1', text)
text = re.sub('([?s?]`[??]?)([→↓↑ ]+|$)',
r'\1?`\2', text).replace('?', '?`')
text = re.sub('([?s][??]?)([→↓↑ ]+|$)', r'\1?\2', text)
return text
def chinese_to_lazy_ipa(text):
text = chinese_to_romaji(text)
for regex, replacement in _romaji_to_ipa:
text = re.sub(regex, replacement, text)
return text
def chinese_to_ipa(text):
text = number_to_chinese(text)
text = chinese_to_bopomofo(text)
text = latin_to_bopomofo(text)
text = bopomofo_to_ipa(text)
text = re.sub('i([aoe])', r'j\1', text)
text = re.sub('u([ao?e])', r'w\1', text)
text = re.sub('([s?]`[??]?)([→↓↑ ]+|$)',
r'\1?`\2', text).replace('?', '?`')
text = re.sub('([s][??]?)([→↓↑ ]+|$)', r'\1?\2', text)
return text
def chinese_to_ipa2(text):
text = number_to_chinese(text)
text = chinese_to_bopomofo(text)
text = latin_to_bopomofo(text)
text = bopomofo_to_ipa2(text)
text = re.sub(r'i([aoe])', r'j\1', text)
text = re.sub(r'u([ao?e])', r'w\1', text)
text = re.sub(r'([??]??)([????? ]+|$)', r'\1?\2', text)
text = re.sub(r'(s??)([????? ]+|$)', r'\1?\2', text)
return text
附录2 中文
def chinese_cleaners(text):
'''Pipeline for Chinese text'''
text = number_to_chinese(text)
text = chinese_to_bopomofo(text)
text = latin_to_bopomofo(text)
text = re.sub(r'([ˉˊˇˋ˙])$', r'\1。', text)
return text附录3 多语言处理
def cjke_cleaners(text):
text = re.sub(r'\[ZH\](.*?)\[ZH\]', lambda x: chinese_to_lazy_ipa(x.group(1)).replace(
'?', 't?').replace('?', 'ts').replace('?an', '??n')+' ', text)
text = re.sub(r'\[JA\](.*?)\[JA\]', lambda x: japanese_to_ipa(x.group(1)).replace('?', 't?').replace(
'?', 'ts').replace('?an', '??n').replace('?', 'dz')+' ', text)
text = re.sub(r'\[KO\](.*?)\[KO\]',
lambda x: korean_to_ipa(x.group(1))+' ', text)
text = re.sub(r'\[EN\](.*?)\[EN\]', lambda x: english_to_ipa2(x.group(1)).replace('ɑ', 'a').replace(
'?', 'o').replace('?', 'e').replace('?', 'i').replace('?', 'u')+' ', text)
text = re.sub(r'\s+$', '', text)
text = re.sub(r'([^\.,!\?\-…~])$', r'\1.', text)
return text
def cjke_cleaners2(text):
text = re.sub(r'\[ZH\](.*?)\[ZH\]',
lambda x: chinese_to_ipa(x.group(1))+' ', text)
text = re.sub(r'\[JA\](.*?)\[JA\]',
lambda x: japanese_to_ipa2(x.group(1))+' ', text)
text = re.sub(r'\[KO\](.*?)\[KO\]',
lambda x: korean_to_ipa(x.group(1))+' ', text)
text = re.sub(r'\[EN\](.*?)\[EN\]',
lambda x: english_to_ipa2(x.group(1))+' ', text)
text = re.sub(r'\s+$', '', text)
text = re.sub(r'([^\.,!\?\-…~])$', r'\1.', text)
return text自定义requirements.txt
Cython>=0.29.21
librosa>=0.8.0
matplotlib>=3.3.1
numpy>=1.18.5
phonemizer>=2.2.1
scipy>=1.5.2
tensorboard>=2.3.0
torch>=1.6.0
torchvision>=0.7.0
Unidecode>=1.1.1
pysoundfile==0.9.0.post1
jamo==0.4.1
ko_pron==1.3
g2pk2
mecab
python-mecab-ko
?
参考文献
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!