2024年显著性检测论文及代码汇总(1)
ACM MM
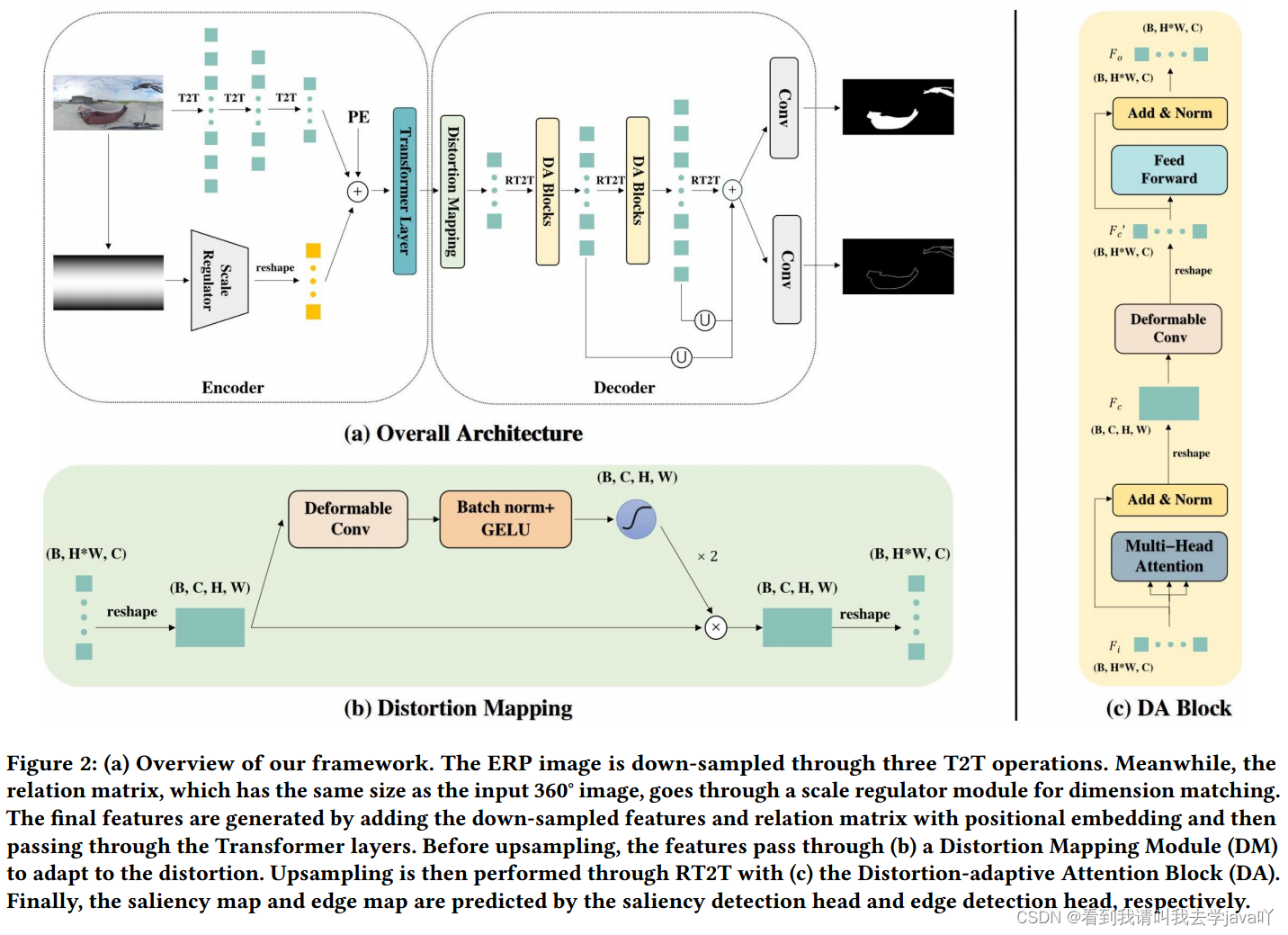
Distortion-aware Transformer in 360° Salient Object Detection
code
Abstacrt:现有的方法无法处理二维等矩投影引起的畸变。本文提出了一个基于Transformer的模型,即DATFormer。首先,引入两个畸变自适应模块。其一是畸变映射模块,预处理全局畸变特征;其二是畸变自适应注意力块,减少多尺度特征的局部畸变。然后,为利用360°数据的独特特征,本文提出一个可学习的关系矩阵,作为位置嵌入的一部分,进一步提高性能。
ICASSP
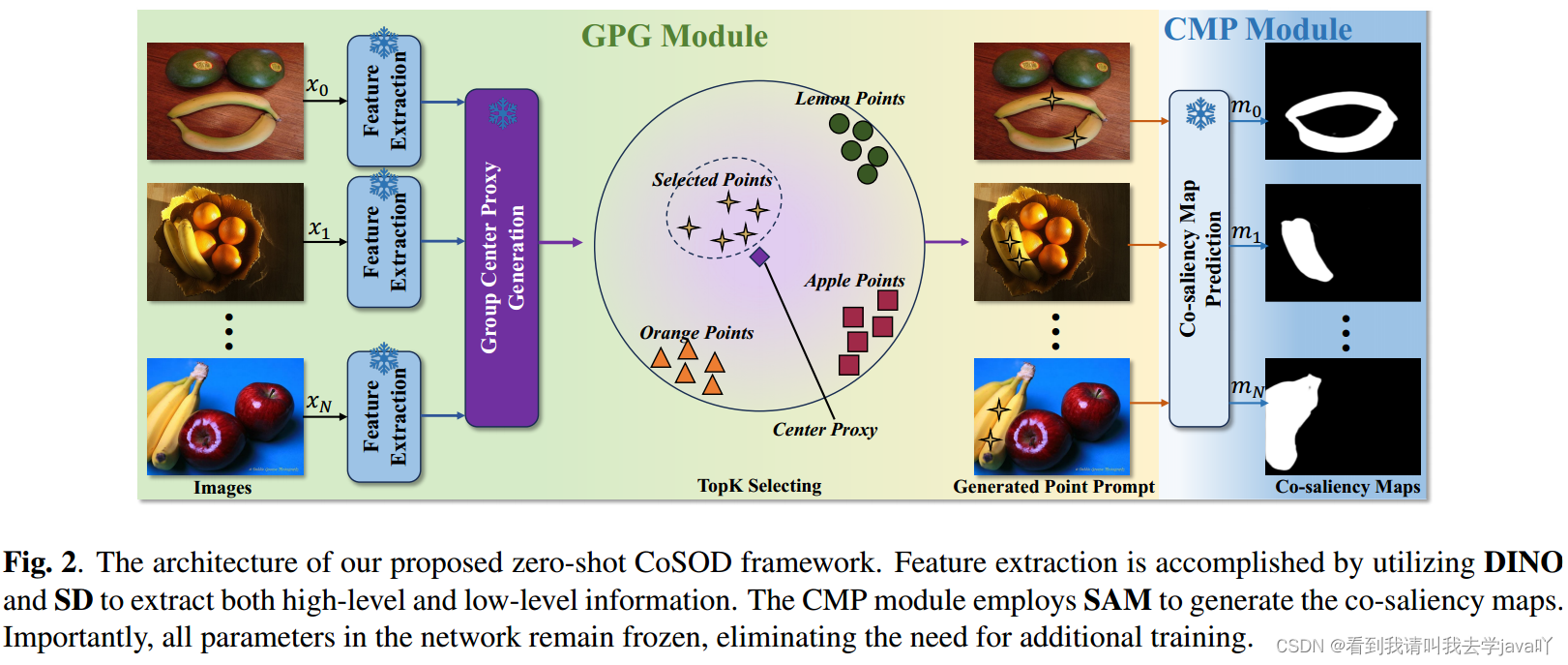
Zero-Shot Co-salient Object Detection Framework
code
Abstacrt:本文构建了第一个Zero-Shot的协同显著性检测框架,无需训练即可利用这些模型。在该框架中引入两个新模块:组提示生成模块GPG、协同显著性图生成模块CMP。
IEEE TIP
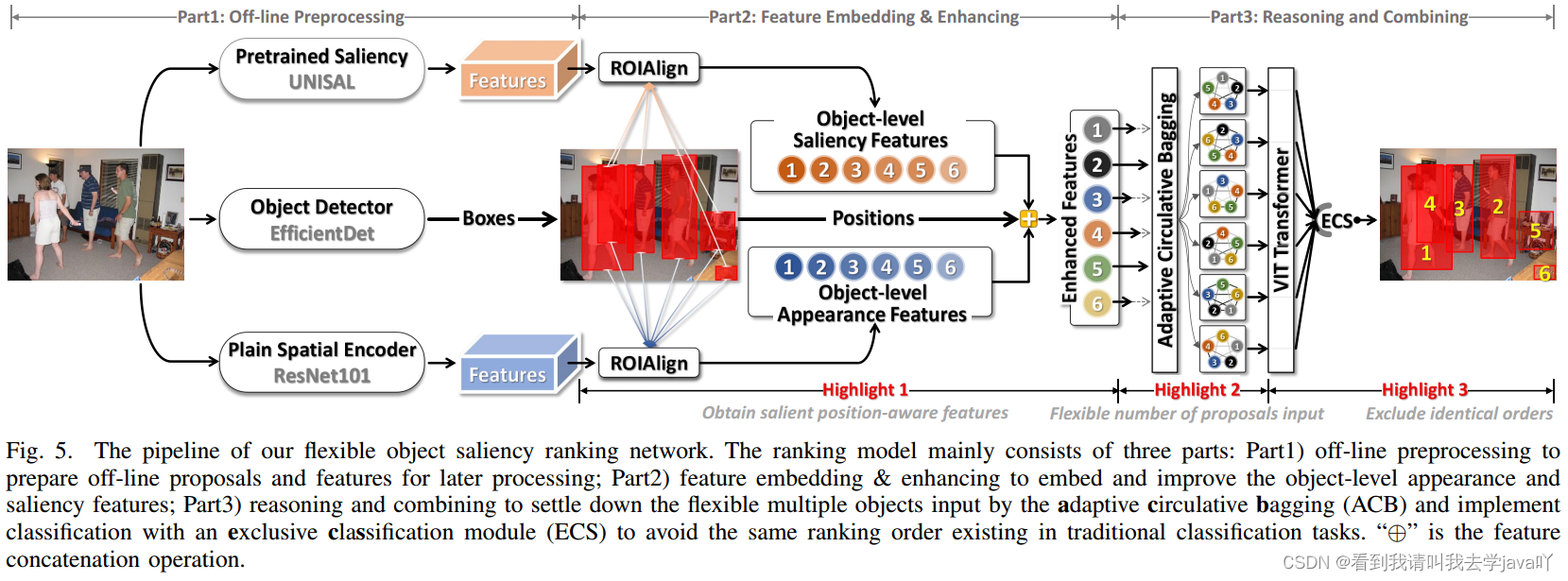
Rethinking Object Saliency Ranking: A Novel Whole-flow Processing Paradigm
code
Abstacrt:本文提出了一个显著性排序范式。首先,由于GT图的构建缺乏理论依据,其显著性物体排序不合理。其次,由于现有的显著性排序模型遵循多任务范式,而不同的任务之间有冲突且难以权衡,因此显著性排序模型受到挑战。最后,现有的基于回归的显著性排序模型依赖于基于实例掩码的显著性排序,导致模型过于复杂。模型需要大量的数据才准确,且难以有效实现。针对这三方面问题,本文探讨其产生原因,提出显著性排序任务的全流程处理范式。
NeurIPS
What Do Deep Saliency Models Learn about Visual Attention?
code
Abstacrt:本文提出一个分析框架,阐述显著性模型被学习的隐式特征,隐式特征对显著性模型的贡献的解释和量化。本文将隐式特征分解为与语义属性明确对齐的可解释基,将显著性预测重述为一种加权组合。本团队从不同角度进行广泛分析,包括语义的正权重和负权重、训练数据和框架设计的影响、微调的渐进影响和SOTA模型的常见失败案例。此外,本团队通过研究不同场景下的视觉注意力特征,以展示该框架的有效性,例如自闭症谱系障碍ADS的非典型注意力、情绪刺激下的注意力和随时间变化的注意力。

WACV
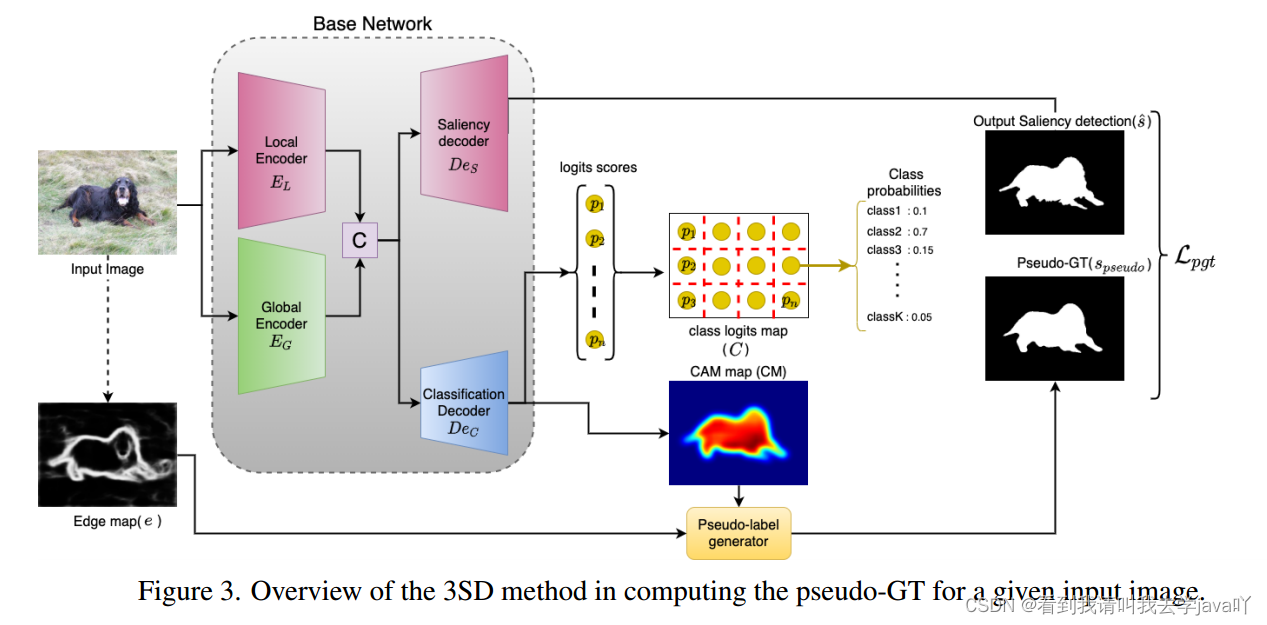
3SD: Self-Supervised Saliency Detection With No Labels
code
Abstacrt:最近的研究表明,从分类任务中提取的特征提供了重要的显著性线索,例如目标的结构和语义信息。本文提出了一个自监督模型,即3SD,利用这一思想,通过在显著性检测的同时,为自监督分类任务添加一个分支,以获得类激活图CAM。CAM与边缘图用于生成伪GT。具体来说,本文提出一种用于分类任务的基于多图像pacth对比学习。相比于在整张图像上进行分类的朴素学习,带有对比损失的multi-patch分类提升了CAM的质量。
数据集
NeurIPS
DVSOD: RGB-D Video Salient Object Detection
code
Abstacrt:为更好地实现多模态的信息融合,本团队构建了DViSal数据集,以推动RGB-D视频显著性检测领域(DVSOD)的进一步研究。该数据集具有237个全标注的RGB-D视频,包括对象和实例级标注,边界框和涂鸦。

WACV
Salient Object Detection for Images Taken by People With Vision Impairments
Dataset
Abstacrt:本文构建了一个新的数据集,即VizWiz-SalientObject,使用视觉受损的人拍摄的图像。与7个现有的数据集相比,VizWiz-SalientObject是目前最大的数据集(即32,000张人工标注的图像)并包含独特特征。

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- sql_lab之sqli中的搜索型注入
- Java 中操作字符串都有哪些类?它们之间有什么区别?
- Linux的启动与进程管理[上]
- 如果你也在用ZK,那这个导致集群挂掉的坑一定得注意!
- 多线程select并发
- 2023-12-02青少年软件编程(Python语言)等级考试试卷(二级)解析
- Python Request源码解读之 adapters.py
- 手把手教你从阿里云容器仓库拉取镜像
- Git常用命令
- 代码随想录训练营day43| 1049. 最后一块石头的重量 II 494. 目标和 474.一和零...