大数据学习之Flink,10分钟带你初步了解Flink
目录
前摘
Flink?是 Apache 基金会旗下的一个开源大数据处理框架,如今已被很多人认为是大数据实时处理的方向和未来
一、认识Flink的Logo
二、了解Flink的起源
Flink 起源于一个叫作 Stratosphere 的项目,它是由 3 所地处柏林的大学和欧洲其他一些大 学共同进行的研究项目,由柏林工业大学的教授沃克尔·马尔科(Volker Markl)领衔开发。2014 年 4 月,Stratosphere 的代码被复制并捐赠给了 Apache 软件基金会,Flink 就是在此基础上被 重新设计出来的。
三、了解Flink的发展
2014 年 8 月,Flink 第一个版本 0.6 正式发布(至于 0.5 之前的版本,那就是在 Stratosphere 名下的了)。与此同时 Fink 的几位核心开发者创办了 Data Artisans 公司, 主要做 Fink 的商业应用,帮助企业部署大规模数据处理解决方案。
2014 年 12 月,Flink 项目完成了孵化,一跃成为 Apache 软件基金会的顶级项目。
2015 年 4 月,Flink 发布了里程碑式的重要版本 0.9.0,很多国内外大公司也正是从这 时开始关注、并参与到 Flink 社区建设的。
2019 年 1 月,长期对 Flink 投入研发的阿里巴巴,以 9000 万欧元的价格收购了 Data Artisans 公司;之后又将自己的内部版本 Blink 开源,继而与 8 月份发布的 Flink 1.9.0 版本进行了合并。自此之后,Flink 被越来越多的人所熟知,成为当前最火的新一代 大数据处理框架。
四、明白Flink的定位
Apache Flink 是一个框架和分布式处理引擎,如图所示,用于对 于无界和有界数据流进行有状态计算。Flink 被设计在所有常见的集群环境中运行,以内存执行速度和任意规模来执行计算。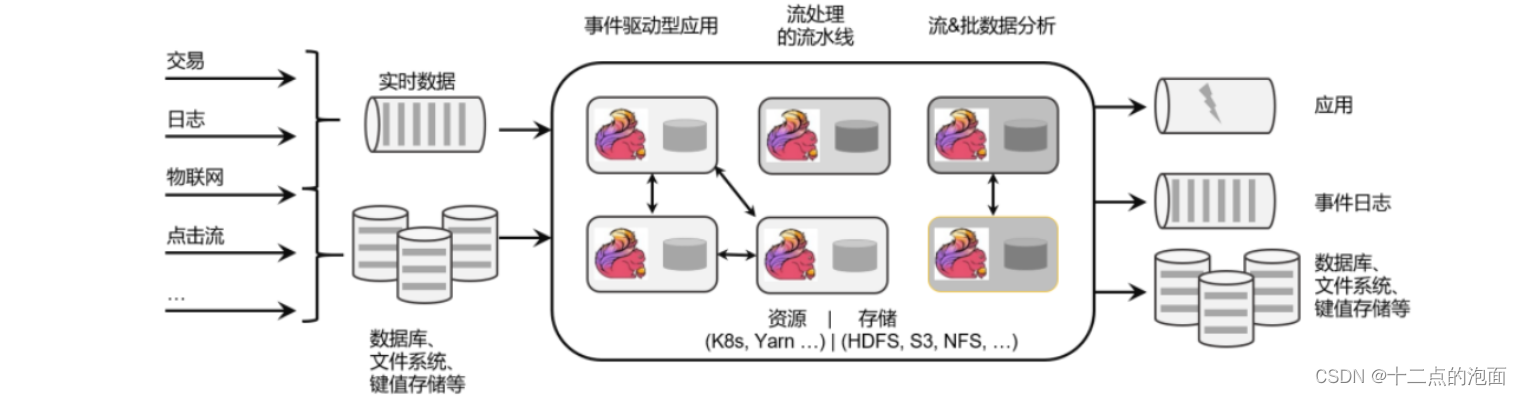
五、Flink主要的应用场景
-
电商和市场营销
举例:实时数据报表、广告投放、实时推荐
-
在电商行业中,网站点击量是统计 PV、UV 的重要来源,也是如今“流量经济”的最主要 数据指标。很多公司的营销策略,比如广告的投放,也是基于点击量来决定的。另外,在网站 上提供给用户的实时推荐,往往也是基于当前用户的点击行为做出的。我们需要的是直接处理 数据流,而 Flink 就可以做到这一点。
-
-
物联网(IOT)
举例:传感器实时数据采集和显示、实时报警,交通运输业
-
物联网是流数据被普遍应用的领域。各种传感器不停获得测量数据,并将它们以流的形式 传输至数据中心。而数据中心会将数据处理分析之后,得到运行状态或者报警信息,实时地显 示在监控屏幕上。所以在物联网中,低延迟的数据传输和处理,以及准确的数据分析通常很关 键。
-
-
物流配送和服务业
举例:订单状态实时更新、通知信息推送
-
在很多服务型应用中,都会涉及订单状态的更新和通知的推送。这些信息基于事件触发, 不均匀地连续不断生成,处理之后需要及时传递给用户。这也是非常典型的数据流的处理
-
-
银行和金融业
举例:实时结算和通知推送,实时检测异常行为
-
银行和金融业是另一个典型的应用行业。在全球化经济中,能够提供 24 小时服务变得越 来越重要。现在交易和报表都会快速准确地生成,我们跨行转账也可以做到瞬间到账,还可以 接到实时的推送通知。这就需要我们能够实时处理数据流。
-
六、流式数据处理的发展和演变
1.?流处理和批处理
数据处理有不同的方式
容易想到,处理数据流,当然应该“来一个就处理一个”,这种数据处理模式就叫作流处 理;因为这种处理是即时的,所以也叫实时处理。与之对应,处理批量数据自然就应该一批读 入、一起计算,这种方式就叫作批处理,也叫作离线处理。
流数据更真实地反映了我们的生活方式。真实场景中产生的,一般都是数据流。显然, 对于流式数据,用流处理是最好、也最合理的方式。
2. 传统事务处理
2.1传统事务处理架构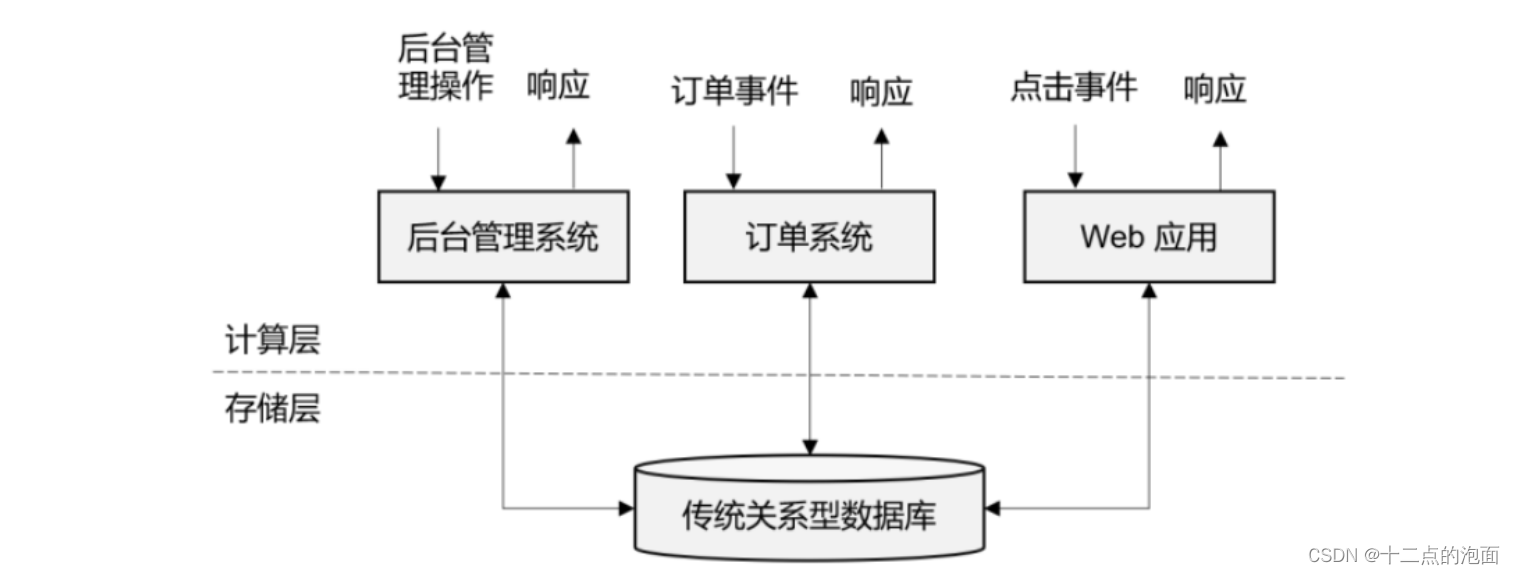
系统所处理的连续不断的事件,其实就是一个数据流。 而对于每一个事件,系统都在收到之后进行相应的处理,这也是符合流处理的原则的。所以可 5 以说,传统的事务处理,就是最基本的流处理架构。
3. 有状态的流处理
我们可以把需要的额外数据保存成一个“状态”,然后针对这条数据进行处理,并且更新 状态。在传统架构中,这个状态就是保存在数据库里的。这就是所谓的“有状态的流处理”。 为了加快访问速度,我们可以直接将状态保存在本地内存,如图所示。当应用收到一 个新事件时,它可以从状态中读取数据,也可以更新状态。而当状态是从内存中读写的时候, 这就和访问本地变量没什么区别了,实时性可以得到极大的提升。
4. Lambda 架构
以 Storm 为代表的第一代分布式开源流处理器,主要专注于具有毫秒延迟的事件处理,特 点就是一个字“快”;而对于准确性和结果的一致性,是不提供内置支持的,因为结果有可能 取决于到达事件的时间和顺序。另外,第一代流处理器通过检查点来保证容错性,但是故障恢 复的时候,即使事件不会丢失,也有可能被重复处理——所以无法保证“exactly-once”。
补:这里的“exactly-once”在我的大数据学习之Flink、快速搞懂Flink的容错机制!!!中的状态一致性级别里有讲到,想了解直接点击上方蓝色链接跳转
与批处理器相比,可以说第一代流处理器牺牲了结果的准确性,用来换取更低的延迟。而 批处理器恰好反过来,牺牲了实时性,换取了结果的准确
我们自然想到,如果可以让二者做个结合,不就可以同时提供快速和准确的结果了吗?正 是基于这样的思想,Lambda 架构被设计出来,如图所示。我们可以认为这是第二代流处 理架构,但事实上,它只是第一代流处理器和批处理器的简单合并。
Lambda 架构主体是传统批处理架构的增强。它的“批处理层”(Batch Layer)就是由传统 的批处理器和存储组成,而“实时层”(Speed Layer)则由低延迟的流处理器实现。数据到达 之后,两层处理双管齐下,一方面由流处理器进行实时处理,另一方面写入批处理存储空间, 等待批处理器批量计算。流处理器快速计算出一个近似结果,并将它们写入“流处理表”中。 而批处理器会定期处理存储中的数据,将准确的结果写入批处理表,并从流处理表中删除不准 确的结果。最终,应用程序会合并流处理表和批处理表中的结果,并展示出来。
6.4.1 Lambda的优点
-
Lambda 架构兼具了批处理器和第一代流处理器的特点
-
同时保证了 低延迟和结果的准确性
6.4.2 Lambda的缺点
-
Lambda 架构本身就很难建立和维 护
-
它需要我们对一个应用程序,做出两套语义上等效的逻辑实现,因为批处理和流处 理是两套完全独立的系统,它们的 API 也完全不同。为了实现一个应用,付出了双倍的工作 量,这对程序员显然不够友好。
5. 新一代流处理器
在原有流处理器的基础上,新一代分布式开源流处理器诞生了。为了与之前的系统 区分,我们一般称之为第三代流处理器,代表当然就是 Flink
-
这一代系统完美解决了乱序数据对结果正确性所造成的影响。
-
这一 代系统还做到了精确一次(exactly-once)的一致性保障,是第一个具有一致性和准确结果的 开源流处理器。
-
另外,先前的流处理器仅能在高吞吐和低延迟中二选一,而新一代系统能够同 时提供这两个特性。
-
所以可以说,这一代流处理器仅凭一套系统就完成了 Lambda 架构两套系 统的工作,它的出现使得 Lambda 架构黯然失色。
-
除了低延迟、容错和结果准确性之外,新一代流处理器还在不断添加新的功能,例如高可 用的设置,以及与资源管理器(如 YARN 或 Kubernetes)的紧密集成等等。
七、Flink的特性总结
1. Flink 的核心特性
-
高吞吐和低延迟。每秒处理数百万个事件,毫秒级延迟。
-
结果的准确性。Flink 提供了事件时间(event-time)和处理时间(processing-time) 语义。对于乱序事件流,事件时间语义仍然能提供一致且准确的结果。
-
精确一次(exactly-once)的状态一致性保证。
-
可以连接到最常用的存储系统,如 Apache Kafka、Apache Cassandra、Elasticsearch、 JDBC、Kinesis 和(分布式)文件系统,如 HDFS 和 S3。
-
高可用。本身高可用的设置,加上与 K8s,YARN 和 Mesos 的紧密集成,再加上从故 障中快速恢复和动态扩展任务的能力,Flink 能做到以极少的停机时间实现 7×24 全 天候运行。
-
能够更新应用程序代码并将作业(jobs)迁移到不同的 Flink 集群,而不会丢失应用 程序的状态。
2. 分层API
Flink 还是一个非常易于开发的框架,因为它拥有易于使用的分 层 API
八、Flink VS Spark
1.?二者区别
1.1 数据处理架构
从根本上说,Spark 和 Flink 采用了完全不同的数据处理方式。可以说,两者的世界观是 截然相反的。
-
Spark 以批处理为根本,并尝试在批处理之上支持流计算;在 Spark 的世界观中,万物皆 批次,离线数据是一个大批次,而实时数据则是由一个一个无限的小批次组成的。所以对于流 处理框架 Spark Streaming 而言,其实并不是真正意义上的“流”处理,而是“微批次”

-
而 Flink 则认为,流处理才是最基本的操作,批处理也可以统一为流处理。在 Flink 的世 界观中,万物皆流,实时数据是标准的、没有界限的流,而离线数据则是有界限的流。
-
无界数据流(Unbounded Data Stream)
所谓无界数据流,就是有头没尾,数据的生成和传递会开始但永远不会结束,如图所 示。我们无法等待所有数据都到达,因为输入是无界的,永无止境,数据没有“都到达”的时 候。所以对于无界数据流,必须连续处理,也就是说必须在获取数据后立即处理。在处理无界 流时,为了保证结果的正确性,我们必须能够做到按照顺序处理数据。
-
有界数据流(Bounded Data Stream)
对应的,有界数据流有明确定义的开始和结束,如图所示,所以我们可以通过获取所 有数据来处理有界流。处理有界流就不需要严格保证数据的顺序了,因为总可以对有界数据集 进行排序。有界流的处理也就是批处理。

-
Spark 基于微批处理的方式做同步总有一个“攒批”的过程,所以会有额外开销,因此无法在 流处理的低延迟上做到极致。
在低延迟流处理场景,Flink 已经有明显的优势。
而在海量数据 的批处理领域,Spark 能够处理的吞吐量更大,加上其完善的生态和成熟易用的 API,目前同样优势比较明显。
1. 2 数据模型和运行架构
Spark 和 Flink 在底层实现最主要的差别就在于数据模型不同。 Spark 底层数据模型是弹性分布式数据集(RDD),
Spark Streaming 进行微批处理的底层 接口 DStream,实际上处理的也是一组组小批数据 RDD 的集合。可以看出,Spark 在设计上本 身就是以批量的数据集作为基准的,更加适合批处理的场景。
而 Flink 的基本数据模型是数据流(DataFlow),以及事件(Event)序列。Flink 基本上是 完全按照 Google 的 DataFlow 模型实现的,所以从底层数据模型上看,Flink 是以处理流式数 据作为设计目标的,更加适合流处理的场景。
数据模型不同,对应在运行处理的流程上,自然也会有不同的架构。Spark 做批计算,需 要将任务对应的 DAG 划分阶段(Stage),一个完成后经过 shuffle 再进行下一阶段的计算。而 Flink 是标准的流式执行模式,一个事件在一个节点处理完后可以直接发往下一个节点进行处 理。
2. Spark 还是 Flink
批处理领 域 Spark 称王,而在流处理方面 Flink 当仁不让。具体到项目应用中,不仅要看是流处理还是 批处理,还需要在延迟、吞吐量、可靠性,以及开发容易度等多个方面进行权衡。
如果在工作中需要从 Spark 和 Flink 这两个主流框架中选择一个来进行实时流处理,我们 更加推荐使用 Flink,主要的原因有:
-
Flink 的延迟是毫秒级别,而 Spark Streaming 的延迟是秒级延迟
-
Flink 提供了严格的精确一次性语义保证
-
Flink 的窗口 API 更加灵活、语义更丰富
-
Flink 提供事件时间语义,可以正确处理延迟数据
补:时间语义在我的另一篇CSDN文章8 分钟看完这 7000+ 字,Flink 时间窗口和时间语义这对好朋友你一定搞得懂!外送窗口计算和水印一并搞懂!!!有讲到,可以直接点击蓝色链接跳转了解
-
Flink 提供了更加灵活的可对状态编程的 API。
补:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- DB2数据库基本介绍
- 千帆起航:探索百度智能云千帆AppBuilder在AI原生应用开发中的革新之路
- Adapter调参:提高NLP模型泛化能力的有效方法
- C++参悟:数值运算相关
- 【Ansys | Fluent】Fluent 15.0及Fluent 22 安装报错问题解决
- 【Linux】多线程编程
- 【信息论与编码】习题-填空题
- 【花雕动手做】ASRPRO语音识别(27)---语音0#串口输出字符串
- CVE-2023-49070:Apache Ofbiz XML-RPC远程命令执行漏洞复现[附POC]
- C语言之实现贪吃蛇小游戏篇