[PyTorch][chapter 8][李宏毅深度学习][Back propagation]
前言:
? ? ? ? ? ? ? 反向传播算法(英:Backpropagation algorithm,简称:BP算法)是一种监督学习算法,常被用来训练多层感知机。 它用于计算梯度计算中,降低误差。
? ? ??
目录:
- ?? ?链式法则
- ? ? 模型简介(Model)
- ? ? 损失函数,梯度
- ? ? 手写例子
- ? ? min-batch
一? 链式法则
? ? ? 链式法则是反向传播算法里面的核心。
? ? ?case1:?, x,y,z 都是scalar
? ? ? ? ? ? ? ? ??![]() ? ? ?
? ? ?
? ? ? ? ? ? ? ? ? ? ?? ? ? ??
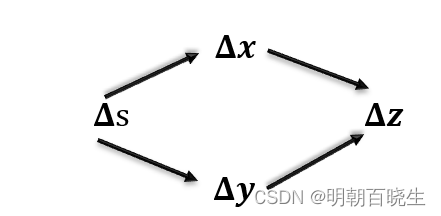
? ? ? case2:??,s,x,y,z 都是scalar
? ? ? ? ? ? ? ? ? ?
? ? ? ? ? ? ? ? ? ? ? ?
? ? ? case3:? ?x,y,z 都是向量vector
? ? ? ? ? ? ? ? ? ?
? ? ? ? ? ? ? ? ? ??
二? 模型(Model)
以常用的网络模型DNN 为例:


?激活函数为?
?总的层数为 L
三? ? 损失函数,梯度
? ? ? ?3.1 损失函数
? ? ? ? ? ?
? ? ? ?3.2 梯度更新
? ? ? ? ? ? ? ?梯度计算分为两步:
? ?Forward pass, Backward pass
? ? ? ? ?a Forward pass
? ? ? ? ? ? ? ?假设?
:
? ? ? ? ? ? 利用微分和迹的关系很容易得到
? ? ? ? ?
? ? ? ? ? b? Backward pass??
? ? ? ? ? ? ? ?假设为最后一层L
? ? ? ? ? ? ? ? ?
? ? ? ? ? ? ? ? ? ? ? ?
? ? ? ? ? ? ? ? ? ? ??
? ? ? ? ? ? 我们用数学归纳法,第L层的
已经求出, 假设第l+1层的
已经求出来了,那么我们如何求出第l层的
呢?
? ? ? ? ? ? ? ??
? ? ? ? ? ? ? ? ? ??
? ? ? ? ? ? ? ? ? ??
? ? ? ? ? ? ? ? ? ??
? ? ? ? ? ? ? ? ? ??

四? ?简单DNN 网络例子
?4.1 说明:
? ? ? ? ? 这里面随机生成5张图形,分别对应手写数字1,2,3,4,5。
简单的了解一下如何快速搭建一个DNN Model, 梯度如何计算,更新的.
?
# -*- coding: utf-8 -*-
"""
Created on Fri Dec 15 17:21:35 2023
@author: chengxf2
"""
import torch
from torch import nn
from torch import optim
class DNN(nn.Module):
'''
它是一个序列容器,是nn.Module的子类。
`nn.Sequential` 中的层是有顺序的,而且严格按照其顺序执行
相邻两个层连接必须保证前一个层的输出与后一个层的输入相匹配。
'''
def __init__(self):
super(DNN, self).__init__()
self.net = nn.Sequential(
nn.Linear(in_features=28*28, out_features=500),
nn.Sigmoid(),
nn.Linear(in_features=500, out_features=10),
nn.Sigmoid()
)
def forward(self, input):
output = self.net(input)
return output
def train():
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = DNN()
criteon = torch.nn.CrossEntropyLoss(reduction='mean')
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
batch_size= 5
data = torch.rand((batch_size,28*28))
epochs = 2
target = torch.tensor([0,1,2,3,4])
target = target.to(device)
for epoch in range(epochs):
yHat = model(data)
loss = criteon(yHat, target)
loss.backward()
print("\n loss ",loss)
optimizer.step()
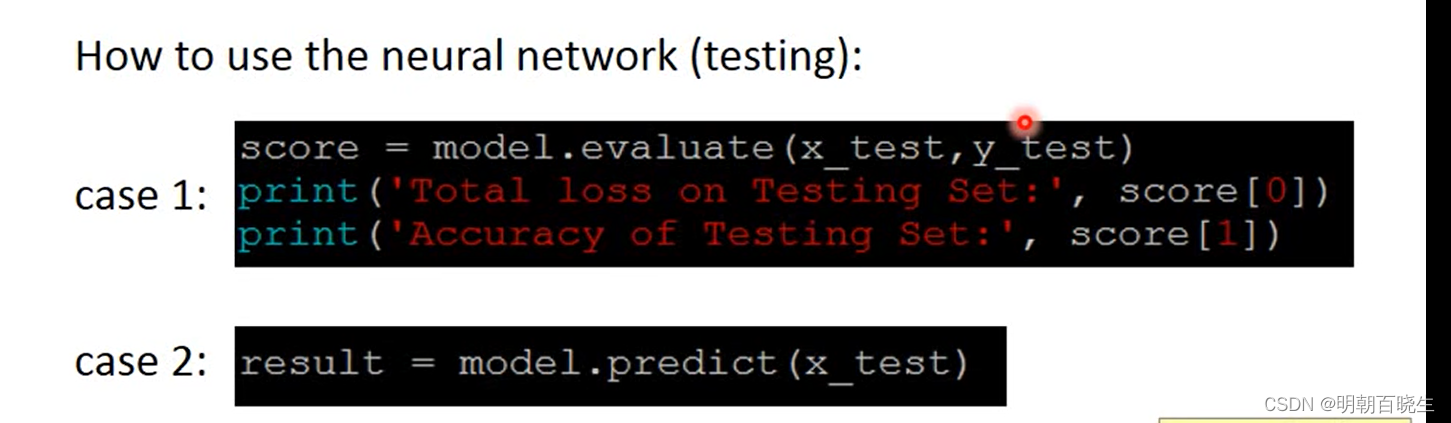
if __name__ == "__main__":
train()
?
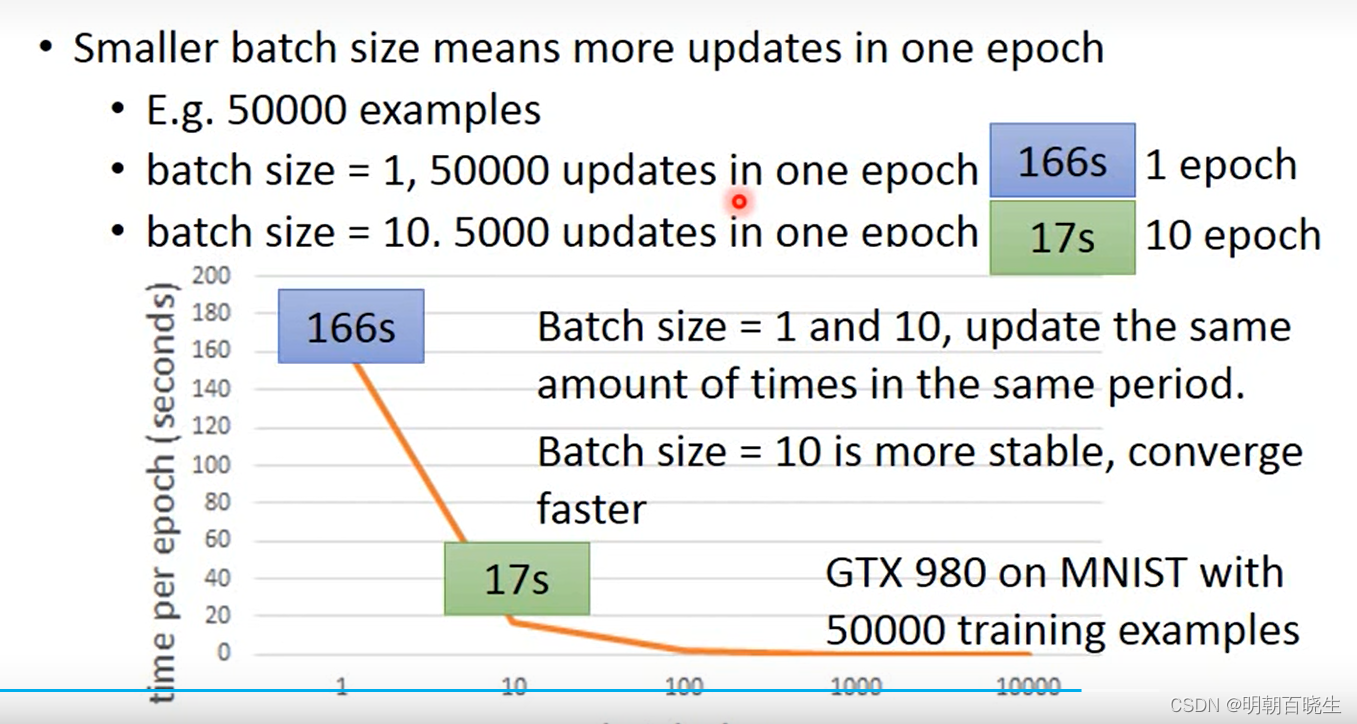
五? min-batch
? 在深度学习训练中,数据集我们通常采用min-batch 方案

? ? 我们采用随机梯度方法,是为了加快运算速度。
但是GPU 可以并行运算,所以可以采用min-batch 方法进行梯度计算。
? ?使用min-batch 有个限制:
? ? 1: 硬件限制 batch 不能超过硬件大小
? ? 2:? ? batch 不能太大,否则容易陷入到局部极小值点,采用小的batch 可以有一定的随机性
每次出发点都不一样,一定概率跳过局部极小值点
参考:
7: Backpropagation_哔哩哔哩_bilibili
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 代码量代码行数统计工具cloc的正确使用(windows平台亲测有效,本人踩过坑,文中提到!)
- CDH 6.3.2集成flink 1.18 zookeeper版本不匹配Flink-yarn启动失败
- BEECMS靶场 -->漏洞挖掘
- 基于Spring的枚举类+策略模式设计(以实现多种第三方支付功能为例)
- 特征工程-特征处理(一)
- PHP接口自动化测试框架实现
- 更新R版本到4.xxx
- 力扣每日一题---1547. 切棍子的最小成本
- 2866. 美丽塔 II --力扣 --JAVA
- FPGA的MARK_DEBUG调试之波形抓取