理解LSTM一种递归神经网络(RNN)
1 递归神经网络结构
一个简单的传统神经网络结构如下图所示:
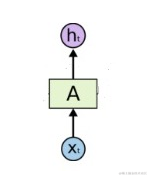
给他一些输入x0,x1,x2 … xt, 经过神经元作用之后得到一些对应的输出h0,h1,h2 … ht。每次的训练,神经元和神经元之间不需要传递任何信息。
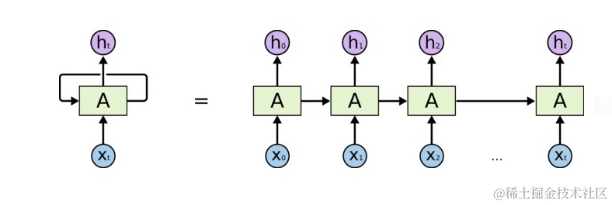
递归神经网络和传统神经网络不同的一个点在于,每次的训练,神经元和神经元之间需要传递一些信息。本次的训练,神经元需要使用上一次神经元作用之后的状态信息。类似递归函数一样。
3 传统RNN的瓶颈
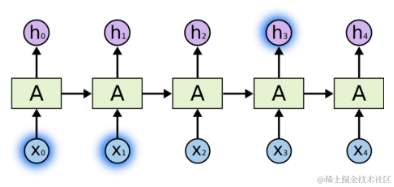
如果我们尝试预测这句话 “云飘在天空”里的最后一个词,我们只需要参考之前的几个词,就可以很容易的得出结果是“天空“,
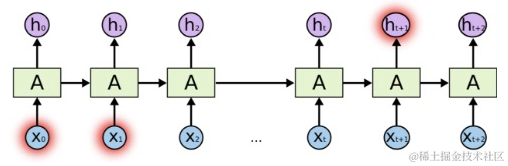
但是有些时候,我们需要之前的更多内容才可以得出结果。假设我们想要预测这句话 ”我家小狗从小接受握手训练,所以现在会和人握手”里的最后一个词,最近的几个词只能帮助我们限制最后一词的范围,如果想进一步缩小这个范围,就需要更多之前的内容。当需要的之前内容越来越多时, RNN恐怕很难处理了。
4 LSTM网络
LSTM是一种特殊的RNN, 用来解决长期依赖问题。和传统的RNN一样,网络结构是重复的,每次的训练,神经元和神经元之间需要传递一些信息。传统的RNN,每个重复的模块里都有一个简单tanh层。
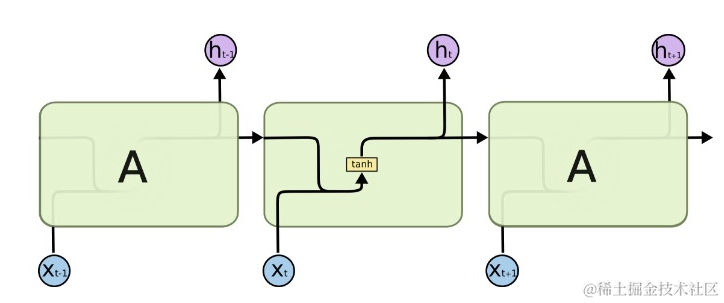
LSTM拥有同样的结构,唯一不同的地方在于每个模块里面的结构不同,它里面有4个网络层,以一种特殊方式的相互作用。
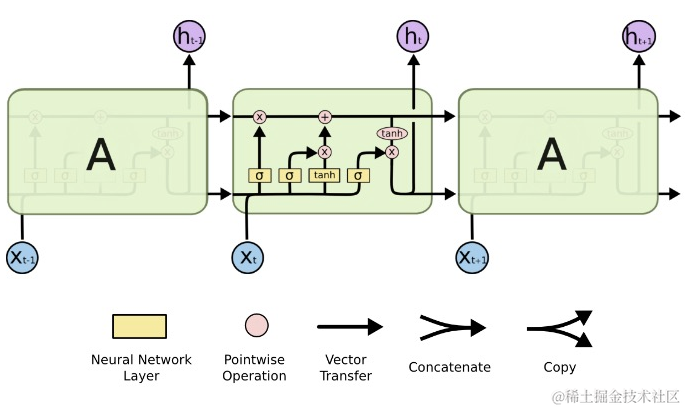
5 具体怎样相互作用
状态单元(cell state) 可以长期保存某些状态,cell state的值通过忘记门层(forget gate),输入门层(input gate layer), 更新门层来控制实现保留多少旧状态,更新多少新的状态。
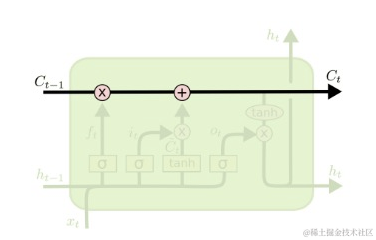
上图中Ct-1就是上一次神经元传递过来的状态信息,Ct就是经过本次神经元作用之后更新的状态信息,然后继续往后传递。
6 忘记门层(fortget gate layer),输入门层(input gate layer)
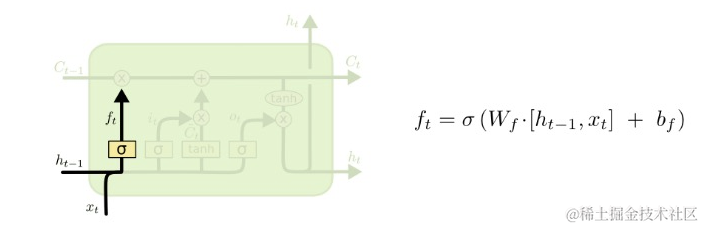
首先fortget gate layer使用Ht-1和Xt的值, 经过sigmoid函数作用之后,值ft落在0~1之间,用来控制需要忘记多少Ct-1里的内容,0到1之间的值相当于一个百分比。
接着input gate layer同样使用Ht-1和Xt的值,经过sigmoid函数作用之后,值it落在01之间,然后经过tanh函数作用之后,值![img]()落在-11之间,-1到1之间的值相当于是减少多少或者增加多少信息。
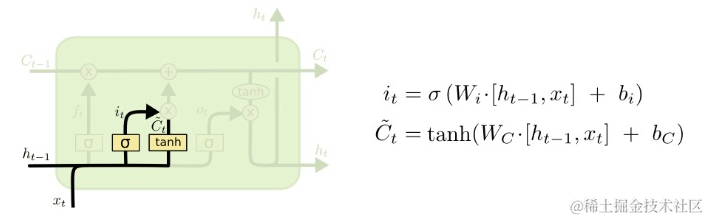
7 更新层(update layer)
接着通过下图中的函数来更新本单元里的Ct,用来传递到下一个单元里去。函数中加号左边用的算式用来控制需要忘记多少Ct-1里的内容,加号右边的算式用来控制需要改变多少本单元里的内容是减少还是增加,最后相加的结果Ct用来传递到下一个单元里去。
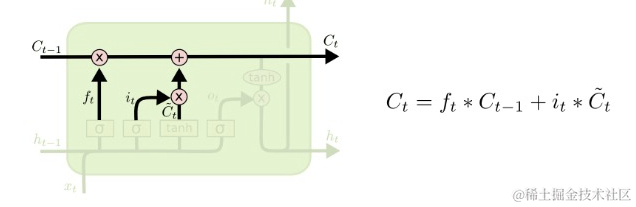
8 输出层(output layer)
接着我们需要决定输出什么,使用Ht-1和Xt的值,经过sigmoid函数作用之后,值Ot落在0~1之间 。然后使用Ct的值,经过tanh函数作用之后,值变成-1~1之间,接着乘以Ot,这样就可以控制想要输出的那一部分内容了,变成下一个单元的Ht-1。
在线教程
- 麻省理工学院人工智能视频教程 – 麻省理工人工智能课程
- 人工智能入门 – 人工智能基础学习。Peter Norvig举办的课程
- EdX 人工智能 – 此课程讲授人工智能计算机系统设计的基本概念和技术。
- 人工智能中的计划 – 计划是人工智能系统的基础部分之一。在这个课程中,你将会学习到让机器人执行一系列动作所需要的基本算法。
- 机器人人工智能 – 这个课程将会教授你实现人工智能的基本方法,包括:概率推算,计划和搜索,本地化,跟踪和控制,全部都是围绕有关机器人设计。
- 机器学习 – 有指导和无指导情况下的基本机器学习算法
- 机器学习中的神经网络 – 智能神经网络上的算法和实践经验
- 斯坦福统计学习

人工智能书籍
- OpenCV(中文版).(布拉德斯基等)
- OpenCV+3计算机视觉++Python语言实现+第二版
- OpenCV3编程入门 毛星云编著
- 数字图像处理_第三版
- 人工智能:一种现代的方法
- 深度学习面试宝典
- 深度学习之PyTorch物体检测实战
- 吴恩达DeepLearning.ai中文版笔记
- 计算机视觉中的多视图几何
- PyTorch-官方推荐教程-英文版
- 《神经网络与深度学习》(邱锡鹏-20191121)
- …

第一阶段:零基础入门(3-6个月)
新手应首先通过少而精的学习,看到全景图,建立大局观。 通过完成小实验,建立信心,才能避免“从入门到放弃”的尴尬。因此,第一阶段只推荐4本最必要的书(而且这些书到了第二、三阶段也能继续用),入门以后,在后续学习中再“哪里不会补哪里”即可。

第二阶段:基础进阶(3-6个月)
熟读《机器学习算法的数学解析与Python实现》并动手实践后,你已经对机器学习有了基本的了解,不再是小白了。这时可以开始触类旁通,学习热门技术,加强实践水平。在深入学习的同时,也可以探索自己感兴趣的方向,为求职面试打好基础。

第三阶段:工作应用

这一阶段你已经不再需要引导,只需要一些推荐书目。如果你从入门时就确认了未来的工作方向,可以在第二阶段就提前阅读相关入门书籍(对应“商业落地五大方向”中的前两本),然后再“哪里不会补哪里”。


本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Codeforces Round 919 (Div. 2) D题 偏移量,二分,子问题
- 自动驾驶自动换道ALC功能规范
- Linux chmod命令
- HTML基础知识 【一篇就够】
- WebOffice在VUE/Electron网页在线编辑Office之用只读方式打开Word文档
- VSCode 搭建Java开发环境
- 飞行器Nz与Ny公式推导
- JS的异步与程序性能相关问题
- JavaScript异常处理详解
- 大数据技术原理与应用期末考试题