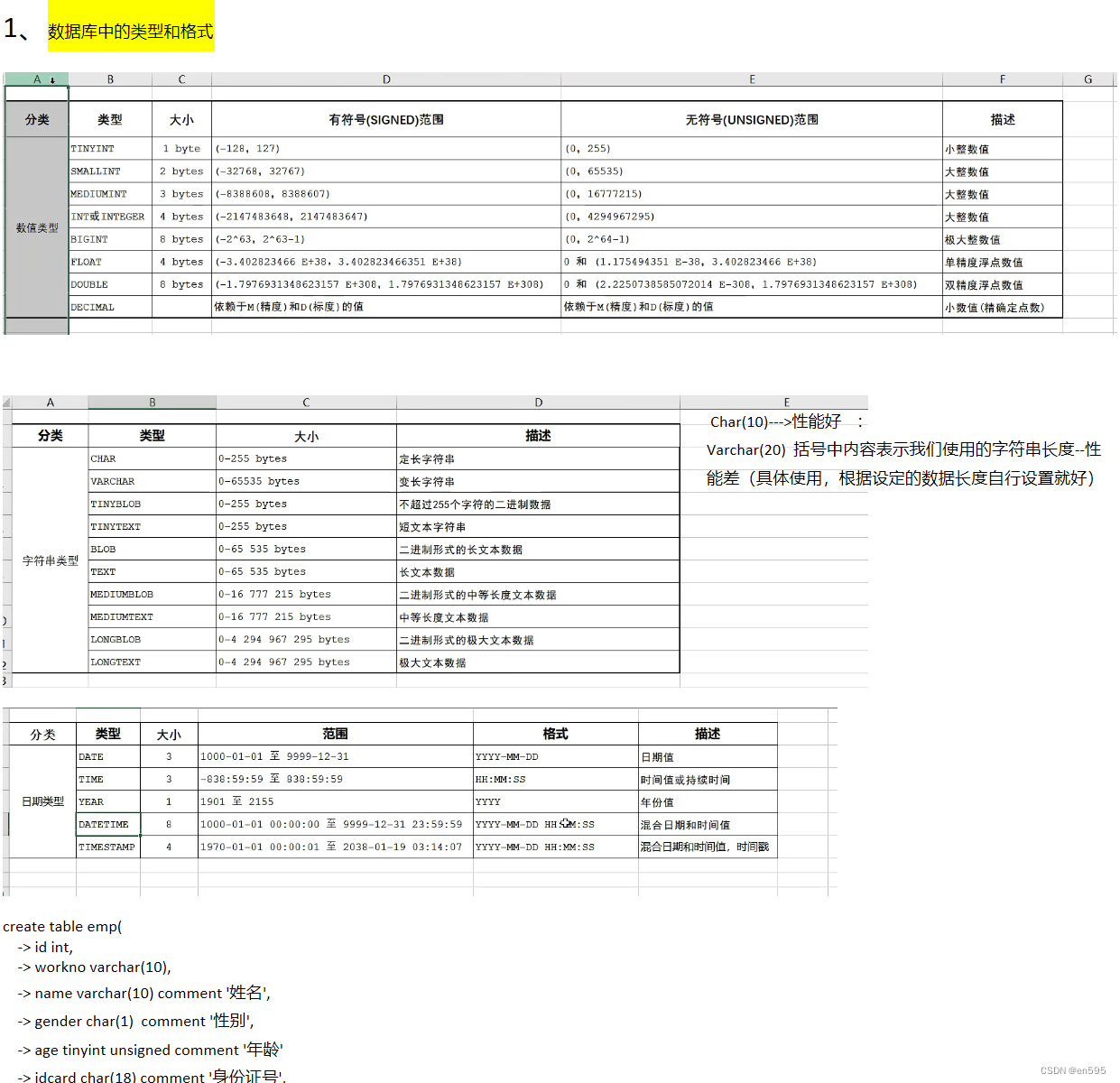
Mysql数据库的基础操作
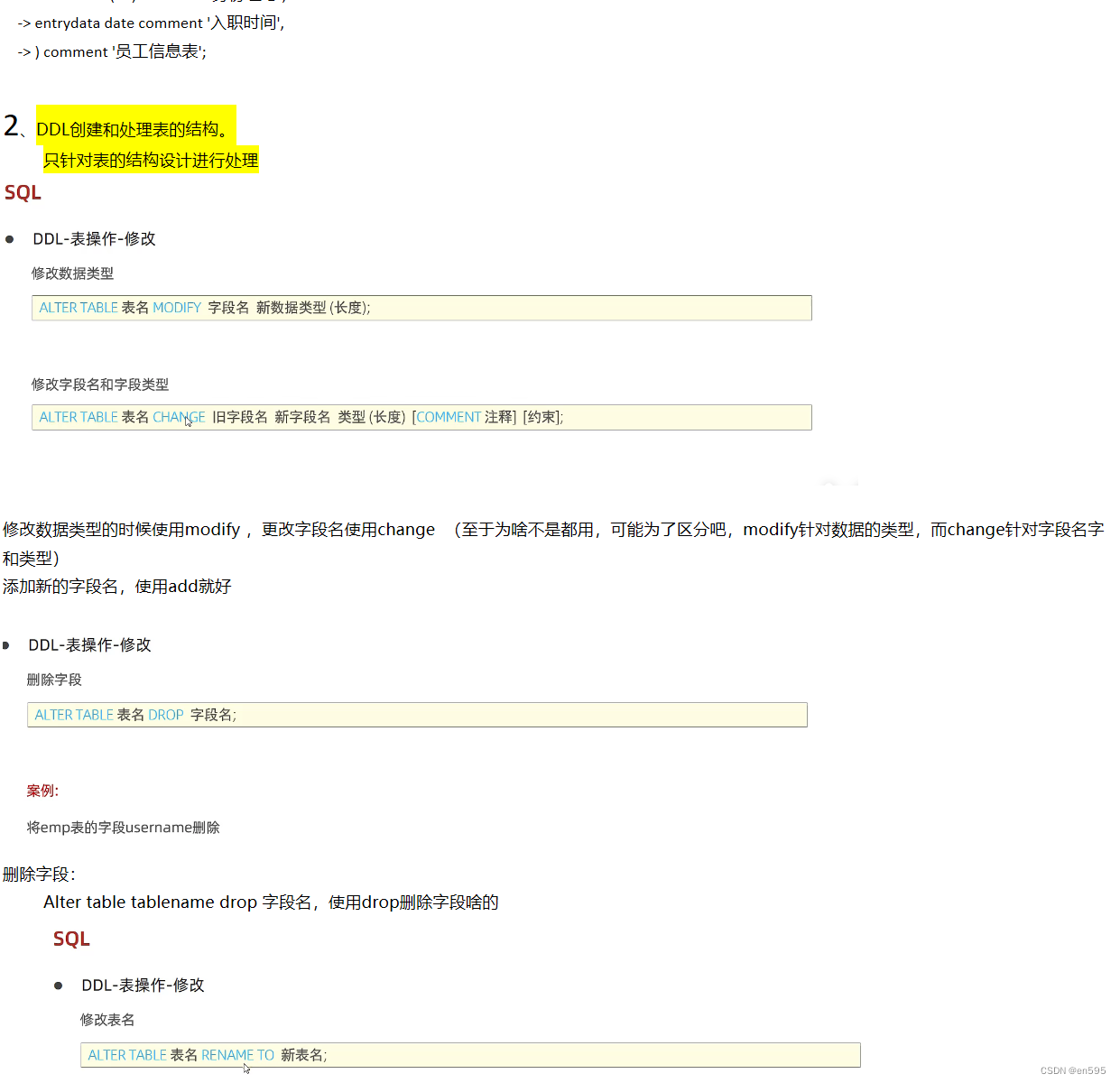
1、数据库的数据类型和结构设置,修改等
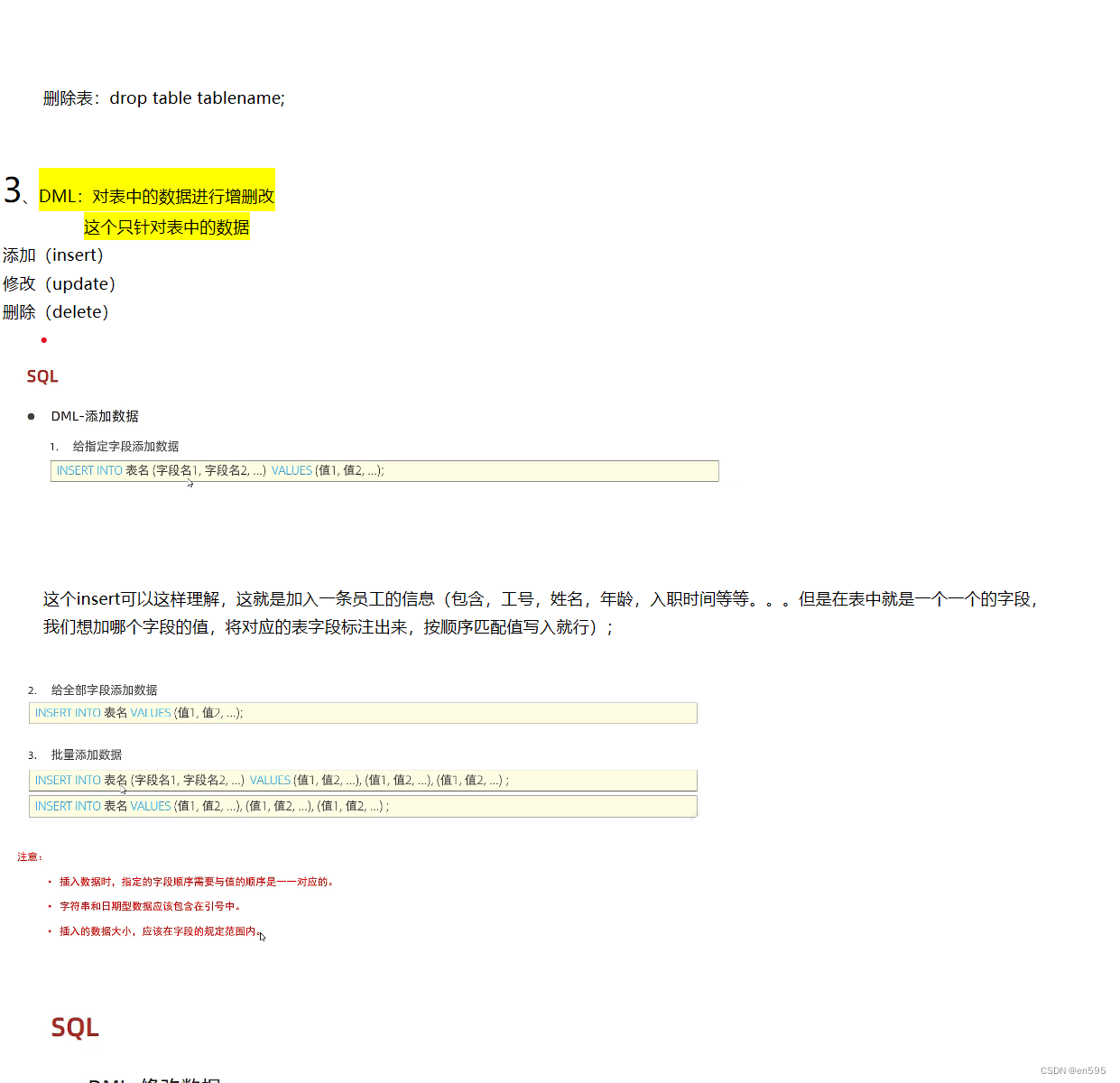
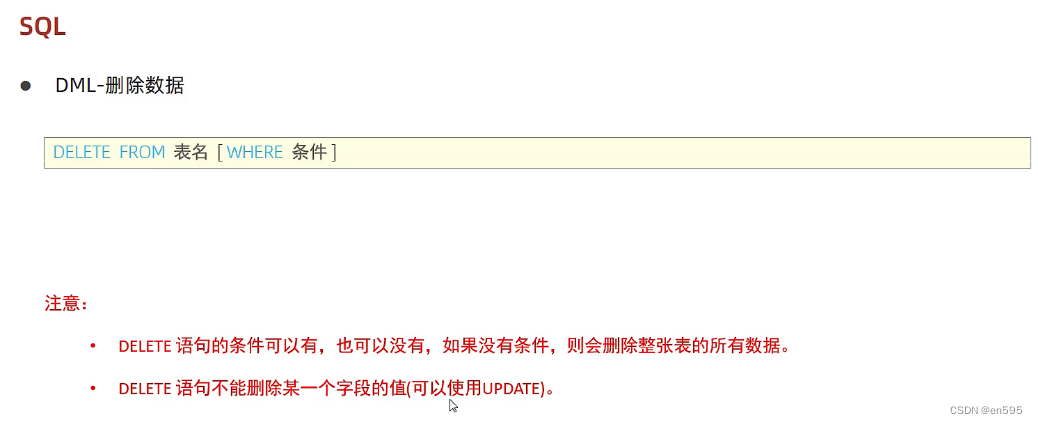
DML:针对数据的增删改

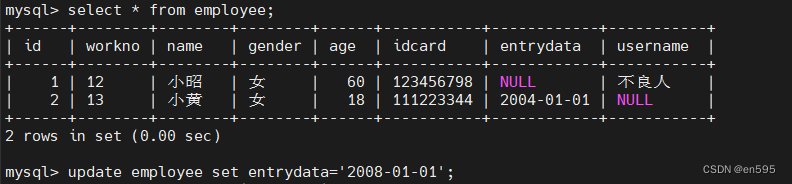
where条件更像是这一条命令中的限制条件,如果不带where条件的时候,相当于针对全表所有字段进行操作
DQL; 数据查询语言
1、查询关键词使用?? select
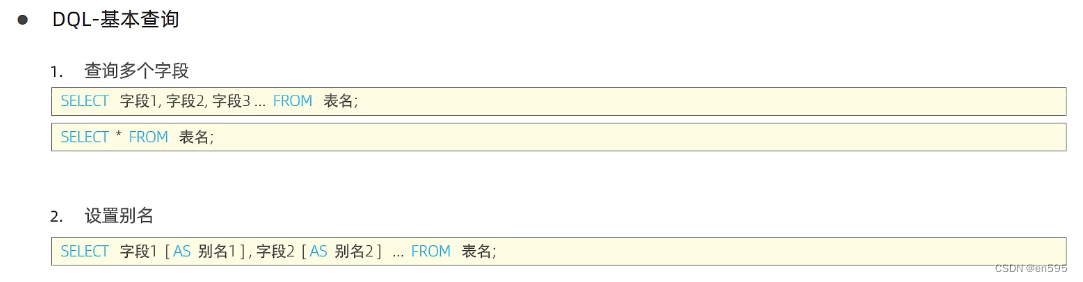
这个里面第一条好处理,就是字段的数据,查哪个写那个就行;
第二条:非必要时刻不是必须的,就好像第一条命令行方式,没有别名,(反过来说,很多时候,可能复杂查询等操作需要用到它);

2、查询语句

3、聚合函数:


这个说是聚合,实际上就是对单列的数据进行简单处理,最大最小值啥的,这个如果记录员工系统还是可以的。
4、分组查询:



having可以对聚合函数的结果进行筛选。
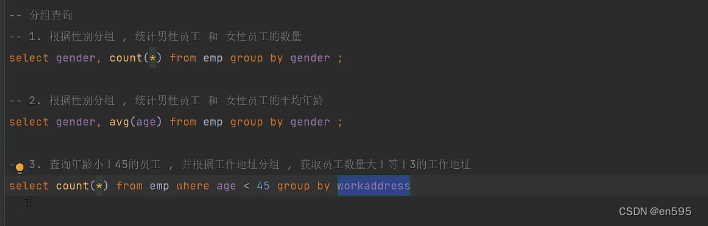


比如第四条指令:查询年龄小于45 的,根据工作地址分组,获取员工数量大于等于3的 地址项;(最后只是查询哪个地址居住的员工数大于等于3)
1、每个select命令行查询的结果,就是一个临时的表格,我们的查询条件最后就是其中的一条属性。我们需要显示的是哪些字段的内容,就放在select之后,这个位置的参数是会在新表中打印出来的。像workaddress 和count(*)直接就显示出来了。成为临时表的字段。
而having? (自我感觉可以理解成,我们需要查询带有什么属性的数据,就相当于是对查询结果的临时表格进行一次特殊筛选)

//个人理解:
分组也可以这样理解:分组查询中,最大的限制条件就是组的字段名(group by【分组字段】);或者最大查找范围是分组字段名的范围。
其他被查找的内容和函数计算都是这次查询结果的属性。(被聚合函数计算的内容更像是我们在临时表中给数据信息增加一条我们需要的信息)。
而having在这个基础上,给我们添加了一个可以进一步筛选的方式(一般就是使用这个新添加的聚合函数信息,作为条件进行筛选)。

注:可以给新的聚合函数条件设置个别名,这样就不会直接打印count(*) 这样的了。方便使用
自己从b站Mysql视频学习记录。原先用Note记录,格式有不同,后面修改。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 爬虫-9-selenium自动化
- 《动手学深度学习》学习笔记 第6章 卷积神经网络
- [GDOUCTF 2023]EZ WEB
- 小埋公司的IPO方案的题解
- QT 信号和槽
- 力扣-移动零
- SUMO Reward Points v29.8.0WooCommerce 奖励系统插件WORDPRESS积分奖励系统
- 在 CentOS 上使用 Docker 运行 RabbitMQ
- OceanBase 4.2特性解读:Show Trace全链路跟踪,助力快速问题定位与精准诊断
- ES2022新特性:Object.hasOwn()以及判断对象是否具有属性的6个方法