Feature Prediction Diffusion Model for Video Anomaly Detection 论文阅读
Feature Prediction Diffusion Model for Video Anomaly Detection论文阅读
文章标题:Feature Prediction Diffusion Model for Video Anomaly Detection
文章信息:

发表于:ICCV 2023
原文链接:https://openaccess.thecvf.com/content/ICCV2023/papers/Yan_Feature_Prediction_Diffusion_Model_for_Video_Anomaly_Detection_ICCV_2023_paper.pdf
源代码:https://github.com/daidaidouer/FPDM
Abstract
在视频异常检测是一个重要的研究领域,在实际应用中也是一项具有挑战性的任务。由于缺乏大规模标注的异常事件,大多数现有的视频异常检测(VAD)方法侧重于学习正常样本的分布,以便检测明显偏离的样本作为异常。为了更好地学习正常运动和外观的分布,许多辅助网络被用于提取前景对象或动作信息。这些高层语义特征有效地过滤了背景噪声,减少了其对检测模型的影响。然而,这些额外的语义模型的能力对VAD方法的性能产生了重要影响。受扩散模型(DM)出色的生成和抗噪声能力的启发,本文引入了一种新颖的基于DM的方法来预测用于异常检测的视频帧特征。我们的目标是学习正常样本的分布,而无需涉及任何额外的高层语义特征提取模型。为此,我们构建了两个去噪扩散隐式模块来预测和细化特征。第一个模块专注于特征运动学习,而最后一个专注于特征外观学习。据我们所知,这是第一个基于DM的用于VAD的特征预测方法。DM的强大能力也使得我们的方法能够更准确地预测正常特征,相较于基于非DM的特征预测的VAD方法。广泛的实验证明了所提方法在性能上大大优于最先进的竞争方法。代码可在FPDM上获得。
1. Introduction
视频异常检测(VAD)旨在识别在视频中罕见且与正常行为不同的异常事件。成功检测异常事件,如交通事故、暴力和踩踏事件,在广泛应用于公共安全的视频监控中具有重要意义。然而,由于真实世界中异常事件的种类繁多且难以收集大规模标注数据,VAD是一项具有挑战性的任务。
多年来已经提出了许多视频异常检测(VAD)方法[9,10,14,19,23,33,34,39,45,46,57,62,68,71],以解决这一问题,其中一类学习方法由于相对可获得的正常训练集以及其实现更好性能的能力而受到青睐[44]。这些一类学习的VAD方法假设具有所有样本均为正常的训练数据,并构建不同的模型来学习正常数据的分布。生成建模是这一领域中广泛使用的技术,因为在训练后,正常样本可以比异常更好地生成。生成对抗网络(GAN)[22, 52, 71, 72]和自编码器(AE)[24, 29, 40, 46]是两个流行的框架。尽管这些生成方法在VAD中取得了令人满意的性能,但存在三个主要挑战:(1) 基于GAN/AE的方法具有较弱的生成能力,导致低质量生成图像中的噪音增多,降低了性能,(2) 当前的SOTA方法通常使用一些辅助模型,例如目标检测和动作识别模型,来捕获前景对象或动作信息的特征,因此性能在很大程度上依赖于这些高级语义模型的表示能力,以及(3) 异常事件通常以新颖的外观和/或异常运动为特征,增加了生成模型在这两个方面捕获正常性/异常性的难度。
总之,主要贡献有三个:
- 我们引入了一种基于扩散模型的方法,用于预测语音活动检测(VAD)中每个样本的特征。据我们所知,这是首个利用扩散模型进行视频异常检测的工作。
- 我们设计了两种DDIM模块,分别从正常样本中进行运动和外观学习,以保证预测特征的生成质量。
- 该模型以2D图像作为输入,没有辅助的语义网络,同时实现了高度可比的性能,利用高层次的3D语义特征的方法。
在四个公开的视频异常检测数据集上的实验结果表明,我们的方法大大优于基于图像特征的VAD同行,并表现出良好的方法使用3D语义特征。
2. Related work
针对不同的应用场景,根据训练样本的标注情况,视频异常检测方法大致可以分为半监督、单类和无监督VAD三类。由于我们的方法属于单类类型,因此我们只回顾单类VAD方法。
早期的单类VAD方法是两步方法,其中特征提取和学习分离。他们首先使用手工制作的特征描述符来呈现每个帧,例如3D梯度特征[38],梯度直方图(HOG)[16],直方图光流(霍夫)[16],词袋(BOW)等,然后构建一个浅层模型来学习正态分布,例如基于字典的模型[75],概率模型[13,41]和重建模型[16,38,75]。这些传统方法的缺点是手工制作的特征性能差。随着深度学习的发展[35,36,64 -67],基于卷积神经网络的方法紧随其后。CNN将特征提取和学习集成到端到端框架中[42,43,70]。这些基于CNN的方法大多属于生成方法,其中模型对正态性应用特征学习,并根据生成样本与原始样本之间的差异检测异常。生成对抗网络(GAN)[20,51,73]和基于自动编码器的网络(AE)[25,27,56]被广泛用于这种正常的特征学习。基于这些框架,提出了记忆模块[24]和特征预测模块[33]来增强特征学习的能力。为了进一步提高性能,一些高级特征提取模型,例如,采用对象检测[23,37]、动作识别[62]和光流[33]来获得前景或运动信息以用于正常性的学习。辅助模型为这些VAD方法带来了好处,同时增加了对语义表示的依赖性。
近年来,扩散模型在许多生成性任务上取得了最好的表现,成为研究的热点[5,17,26,49,53]。计算机视觉中已经出现了许多应用,例如图像修复[7,15,54]、图像处理[47]、图像超分辨率[7,18]和图像到图像转换[50,76]。这些应用程序最先进的性能证实了基于DM的模型具有非凡的生成能力。为了进一步将DMS扩展到主流的计算机视觉任务,已经提出了一些基于DM的潜在表示学习方法,如用于目标检测的DiffusionDet[12]、用于分割的SegDiff[2]和用于分类的SBG分类器[77]。这些区分任务通常需要更强大的模型,不容易受到背景的干扰。因此,这些方法在不同任务上的成功验证了数据挖掘的抗噪声能力。早期的扩散模型,如去噪扩散概率模型(DDPM),由于马尔可夫过程通过微小的修正转换数据分布,在采样阶段需要相当多的去噪步骤。为了加快采样过程,已经提出了许多加速扩散方法[30,53,74]。去噪扩散隐式模型(DDIM)因其无需训练的特性而被广泛应用。DDIM不需要额外的训练,可以直接应用先进的采样算法,步骤更少,保真度更高。因此,基于DDIM的方法更有可能在实际中被采用。
3. Method
我们的主要动机是设计一种基于扩散模型的方法,以便在没有3D特征提取网络的帮助下很好地学习正常运动和外观的分布。在推理阶段,正常样本的特征比异常样本的特征更容易被优化模型预测。
如图2所示,我们的框架包含三个部分,即帧编码器、特征预测扩散模块和特征细化扩散模块。首先,我们使用一个编码器来提取每一帧的特征。任何预训练的CNN都可以用作编码器。
在这里,我们采用了[48]中的轻量编码器,因为:
(1)输出特征图的大小在空间上比原始图像的大小小64倍,并且只包含四个通道,这大大减少了后续扩散模块的计算,
(2)该编码器的预训练是无监督的,这更容易获得。
为了预测特征,我们设计了两个基于DDIM的模块来预测和细化每帧的特征。注意,DDIM具有与DDPM相同的训练过程,但在采样阶段更有效,因为它采用跳步隐式采样器,而不是逐步提取噪声信息。特征预测扩散模块侧重于学习运动的分布,特征细化扩散模块侧重于外观分布学习。
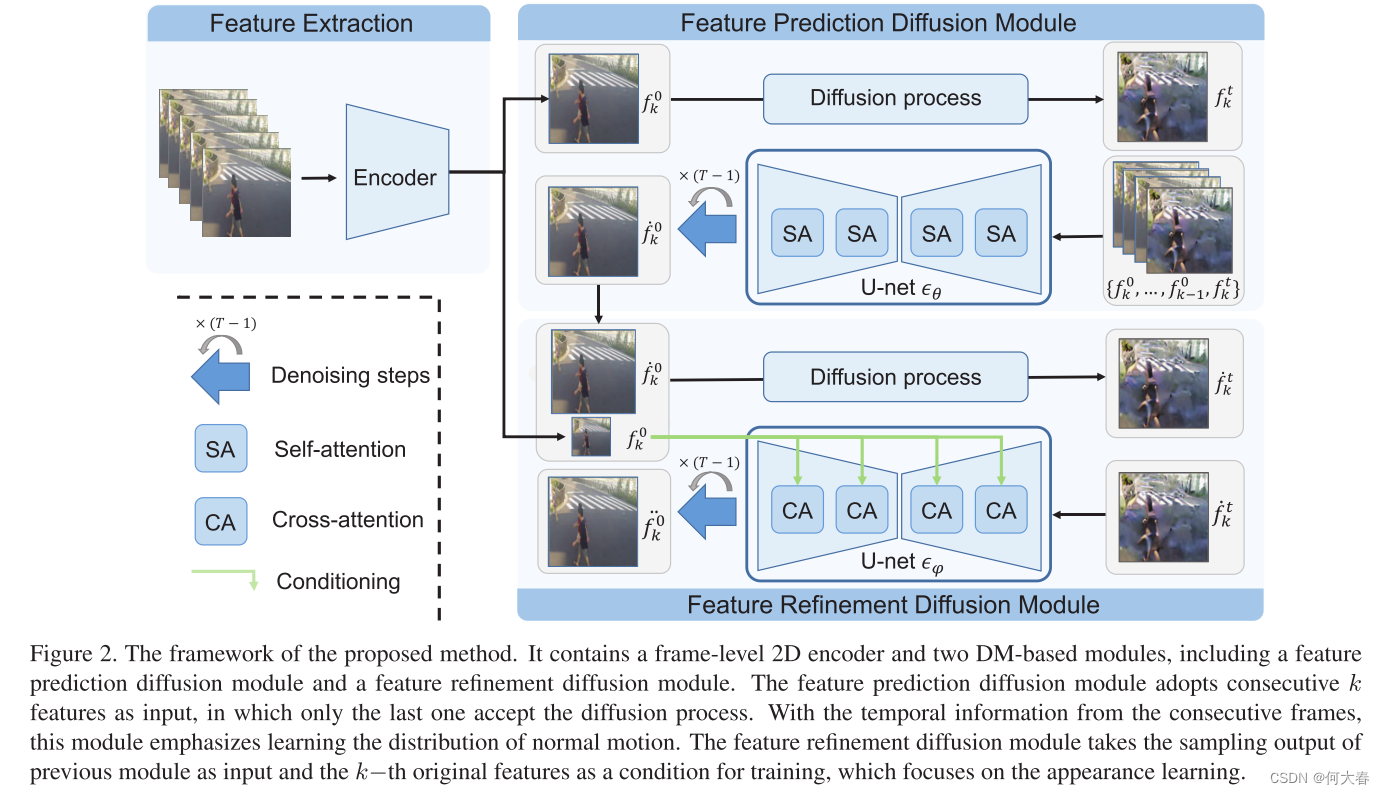
3.1. Problem Formulation
该问题旨在解决的是通过给定几个连续的视频帧来生成一个特征,然后估计该特征是否属于学习的分布。形式上,给定具有k个连续帧 X X X={ x 1 x_1 x1?, x 2 x_2 x2?,···, x k x_k xk?}的视频剪辑,我们的目标是预测第k帧的特征,简称为 f ¨ ( x k ) \ddot{f}(x_k) f¨?(xk?)和 f ˙ k \dot{f}_k f˙?k?。我们使用 f ˙ k \dot{f}_k f˙?k?和 f ¨ ( x k ) \ddot{f}(x_k) f¨?(xk?)来表示特征预测和细化扩散模块的输出。由于涉及到时间步,我们用 f k t f_k^t fkt?表示时间步长t时第k帧的特征。因此, f k 0 f^0_k fk0?指的是时间步长0处的第k个特征,其等同于 f k f_k fk?。与原始特征 f k f_k fk?相比,第k帧的异常分数可以通过 f k f_k fk?与 f ¨ k \ddot{f}_k f¨?k?之间的均方误差来计算。
3.2. Feature prediction diffusion module
公式有点复杂,简单来说就是图中的过程:
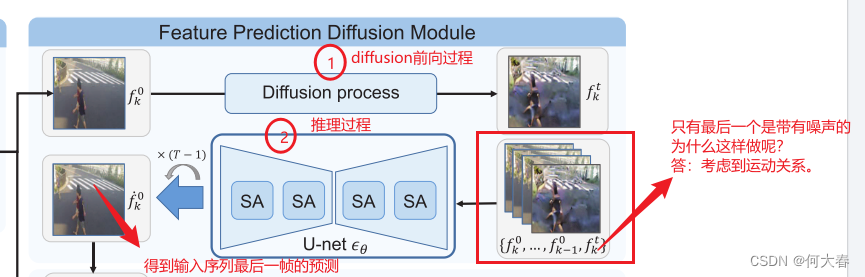
与之前采用k个样本预测第k+1个样本的工作不同,我们将1到k-1帧的特征{
f
1
0
,
f
2
0
,
?
?
?
,
f
k
?
1
0
f^0_1,f^0_ 2,···,f^0_{k?1}
f10?,f20?,???,fk?10?}和第k帧的噪声特征
f
k
t
f^t_k
fkt?一起作为输入,预测特征
f
˙
k
0
\dot{f}_k^0
f˙?k0?。为此,我们构建了一个特征预测扩散模块,通过使用隐式采样[53]逐步去除
f
k
t
f^t_k
fkt?的噪声,以生成
f
˙
k
0
\dot{f}_k^0
f˙?k0?。
对于训练,我们的扩散模型的目标是学习近似原始数据分布
q
θ
(
f
0
)
q_θ(f^0)
qθ?(f0)的分布
p
θ
(
f
0
)
p_θ(f^0)
pθ?(f0)。在前向过程中,后验
q
(
f
1
:
T
∣
f
0
)
q(f^{1:T}| f^0)
q(f1:T∣f0)固定到马尔可夫链:
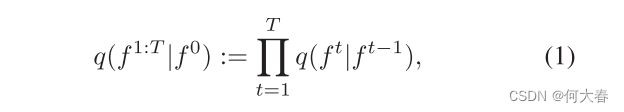
其中t ∈ [1,T]是时间步长,并且:
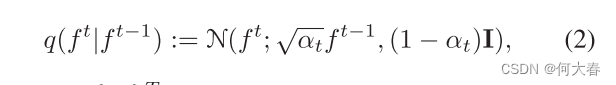
其中
α
t
∈
α_t ∈
αt?∈{
α
t
α_t
αt?}
t
=
1
T
^T_{t=1}
t=1T?是控制
f
t
?
1
f^{t?1}
ft?1的百分比的时间表,
(
1
?
α
t
)
(1-α_t)
(1?αt?)控制噪声的百分比。随着时间步长t的增大,
α
t
α_t
αt?减小。基于这些性质,
f
t
f_t
ft?可以由
f
0
f_0
f0?和标准高斯噪声的线性组合表示如下:
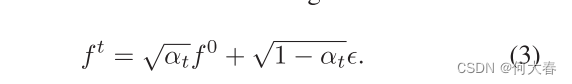
为了学习分布
p
θ
(
f
0
)
p_θ(f^0)
pθ?(f0),我们基于LDM [49]构建了一个U网扩散网络
?
θ
(
?
)
\epsilon_θ(·)
?θ?(?)。为了更好地预测特征,我们修改LDM的两个部分:
(1)我们丢弃潜在条件部分并将所有的交叉注意层修改为传统的注意层,
(2)每个输入样本包含k个特征{
f
1
0
,
f
2
0
,
?
?
?
,
f
k
t
f^0_1,f^0_ 2,···,f^t_k
f10?,f20?,???,fkt?},其中仅第k个特征被应用扩散前向过程。这种修改有两个原因:
(1)我们希望从正常样本中学习特征的分布,而不涉及任何其他潜在条件
(2)结合前一帧的连续特征,我们可以向
?
θ
(
?
)
\epsilon_θ(·)
?θ?(?)提供运动信息,使这个扩散模块专注于特征运动学习。
根据文献[26,53],在训练中使用了目标函数的简化版本,其定义如下:
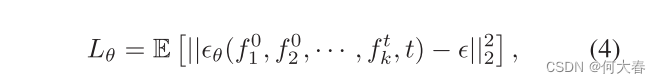
其中,t是时间步长,
?
θ
(
?
,
t
)
\epsilon_θ(·,t)
?θ?(?,t)是时间t处的预测噪声。用Eq.(3)到EQ.(4)当给定足够的特征样本和随机时间步长t 0∈ [ 1,T ]时,参数θ可以得到优化。
对于相反的过程,在时间t-1的第k个样本的特征可以通过以下公式在给定{
f
1
0
,
f
2
0
,
.
.
.
,
f
k
t
f^0_1,f^0 _2,...,f^t_k
f10?,f20?,...,fkt?}的情况下生成一次:
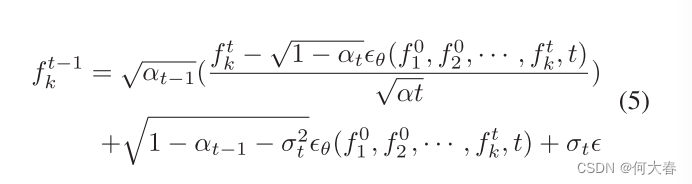
其中,
α
t
α_t
αt? ∈{
α
t
{α_t}
αt?}
t
=
1
T
^T_{t=1}
t=1T?是控制每个步骤的附加噪声的时间表。在采样阶段,第(t-1)步将特征{
f
1
0
,
f
2
0
,
?
?
?
,
f
k
t
f^0_1,f^0_2,···,f^t_k
f10?,f20?,???,fkt?}作为输入来预测
f
k
t
?
1
f^{t-1}_k
fkt?1?。
对反向过程的连续监督可以有效地保证运动预测,但它可能会错过一些外观细节,因为无噪声的k-1特征有助于运动学习,同时对外观学习有影响。为此,我们创建另一个DDIM模块来细化外观信息。
3.3. Feature refinement diffusion module
上一个模块考虑了运动关系,但是外观信息被忽略,为了让生成的最后一帧更接近真实值,又设计了这个模块,简单来说还是下面的图片过程:
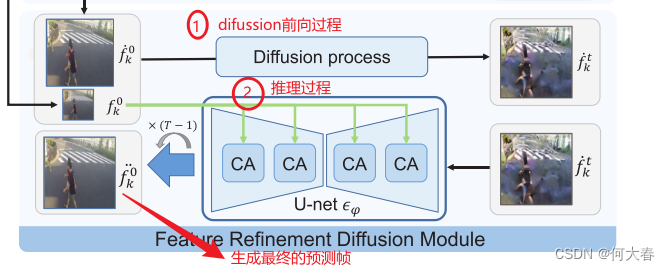
我们在预测模块旁边构建了一个特征细化扩散模块。该精化模型强调学习特征的外观分布。同样,我们采用基于LDM的U-net作为细化的扩散网络,其中的条件部分被保持。我们将前一个预测模块的输出,即去噪特征
f
˙
k
0
\dot{f}_k^0
f˙?k0?作为输入,并使用第k帧的原始特征
f
k
0
f^0_k
fk0?作为条件,以生成表示为
f
¨
k
0
\ddot{f}_k^0
f¨?k0?的细化特征。条件
f
k
0
f^0_k
fk0?用于交叉注意以保证特征外观学习。特征细化扩散模块的目标是学习一个近似于
q
(
f
0
)
q(f^0)
q(f0)的分布
p
φ
(
f
0
)
p_φ(f^0)
pφ?(f0)。
与先前的特征预测模块相同,后验 q ( f ˙ 1 : T ∣ f ˙ 0 ) q(\dot{f}^{1:T}| \dot{f}^0) q(f˙?1:T∣f˙?0)固定到马尔可夫链,并且在给定 f ˙ 0 \dot{f}^0 f˙?0和高斯噪声 ? \epsilon ?的情况下,可以按方程(3)计算时刻t处的输入 f ˙ t \dot{f}^t f˙?t。
为了使细化网络
?
φ
\epsilon_φ
?φ? 专注于外观学习,我们通过在基础的 UNet 主干网络中引入交叉注意力机制,并将原始特征
f
k
0
f^0_k
fk0?作为条件传入交叉注意力层。我们对特征
f
k
0
f^0_k
fk0? 进行展平,然后使用线性变换得到一个 d-维向量
f
k
0
^
\widehat{f^0_k}
fk0?
? ,交叉注意力的实现如下:
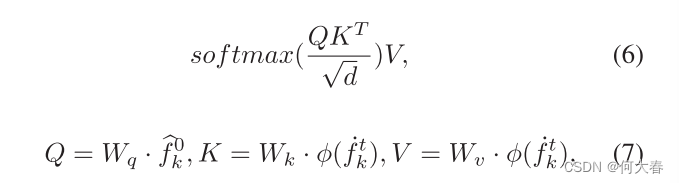
其中
W
k
W_k
Wk?、
W
q
W_q
Wq?、
W
v
W_v
Wv?是可学习的投影矩阵,
?
(
f
˙
k
t
)
\phi(\dot{f}_k^t)
?(f˙?kt?)φ(stecft k)是每个交叉注意层的输入特征图。对于不同的交叉注意层,
f
k
0
^
\widehat{f^0_k}
fk0?
?是不变的,这为特征学习提供了一致的外观监督。损失函数也是DDIM的简化版本,定义为:
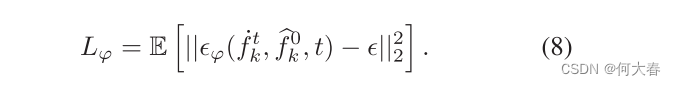
对于逆过程,我们可以通过以下方式获得t-1时间步长的特征:
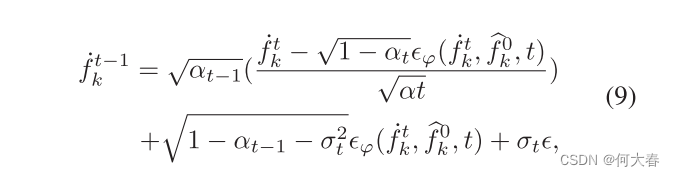
其中,参数
α
\alpha
α和
σ
\sigma
σ与方程 (5) 中的相同。在特定的时间步 t,通过方程 (9) 可以获得经过细化的特征
f
¨
k
0
\ddot{f}_k^0
f¨?k0?。
为了进行测试,我们使用MSE来计算
f
k
0
f^0_k
fk0?和原始特征
f
¨
k
0
\ddot{f}_k^0
f¨?k0?之间的异常分数,定义为:
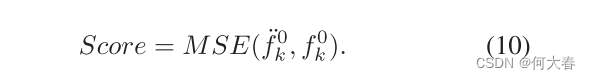
在训练阶段,我们分别训练两个扩散模块,即在预测模块收敛后再训练细化模块。这是因为细化模块的输入是预测模块的采样输出,在训练初期质量较低。联合学习对细化模块的性能有负面影响(参见表格3的结果)。因此,我们采用了分开训练的策略。训练和推断的伪代码如算法1所示。

4. Experiments and discussions
4.1. Datasets
在四个视频异常检测数据集上进行了实证评估:
- CUHK Avenue
- ShanghaiTech
- UCF-Crime
- UBnormal
ShanghaiTech和UCF-Crime是大规模真实世界的VAD数据集,UBnormal是一个生成的数据集。
4.2. Performance evaluation metrics
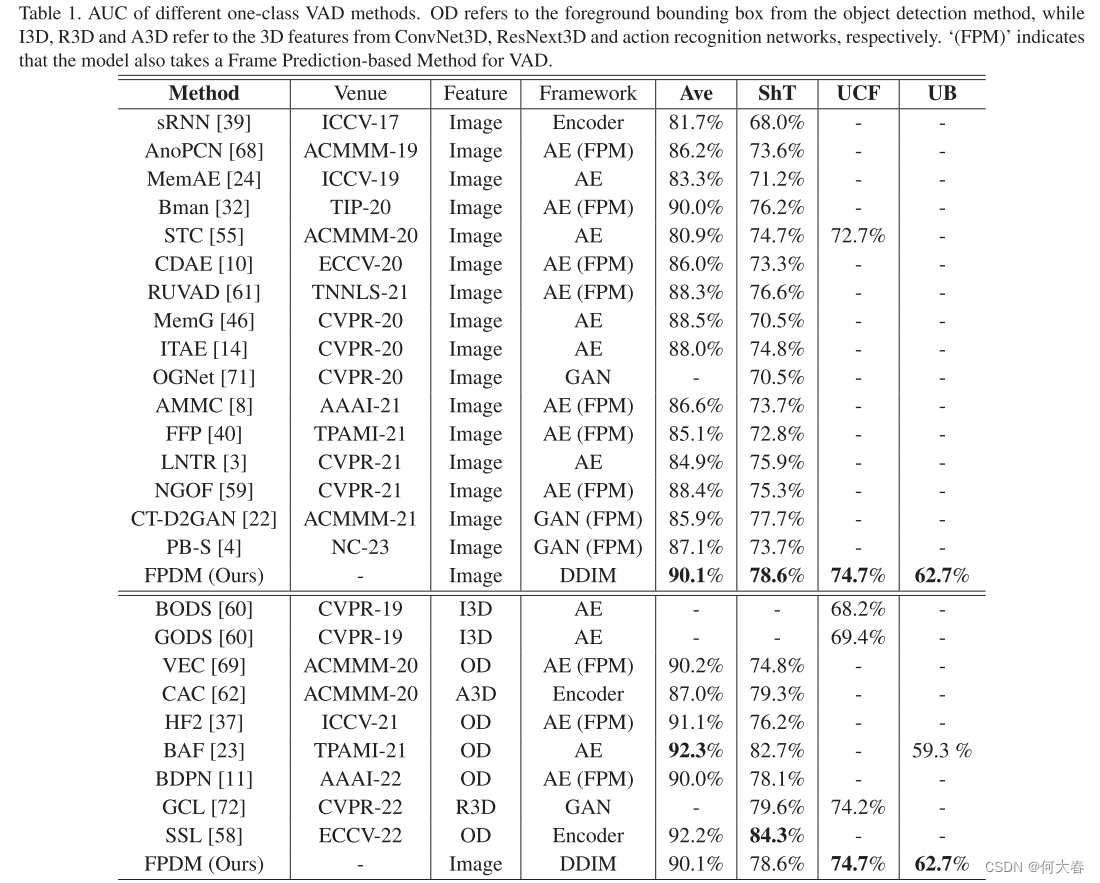
和之前的很多工作一样采用AUC作为评价指标,结果如表1:
表1. 不同的一类语音活动检测(VAD)方法的AUC。OD指的是来自目标检测方法的前景边界框,而I3D、R3D和A3D分别指ConvNet3D、ResNext3D和动作识别网络的3D特征。 ‘(FPM)’ 表示该模型还采用了基于帧预测的方法进行VAD。
4.3. Implementation details
遵循许多先前的研究工作[24, 34, 45],图像的输入尺寸设置为256×256。由于编码器有四个2×下采样层,每个样本的最终特征图的大小为32×32×4。根据视频异常检测中第一个预测框架的设置,我们使用四个连续的相邻帧来预测第五帧[33]。具体而言,我们为训练和测试创建一个立方体,其中包含四个原始特征和来自第五个特征的噪声特征。我们使用DDIM [53]中推荐的 α \alpha α 和 σ \sigma σ的设置。在训练阶段,将训练轮数 S S S 设置为60,包括开始时的12个热身轮数,时间步长 T T T 和学习率分别设置为1k和 1 0 ? 5 10^{-5} 10?5。在推理阶段,我们采用200步的采样计划 T ′ T' T′,即按照[53]的设置, T ′ T' T′中的每一步相当于 T T T 中的五步。此外,我们将 t t t 设置为 0.25 T ′ 0.25T' 0.25T′ 以进行采样,因为在[28, 63]中发现这是最佳设置。因此,与DDPM相比,采样阶段加速了20倍。
5. Conclusions
本文引入了首个用于视频异常检测的特征预测扩散模型(DDIM)。我们进一步设计了两个DDIM模块,即特征预测扩散模块和特征细化扩散模块,用于从正常样本中学习运动和外观。令人印象深刻的是,尽管我们的模型将图像作为输入以预测用于异常检测的特征,但与利用高级3D语义特征的方法相比,它表现出竞争性的性能。广泛的实证结果还表明,我们的方法在对抗最先进的基于2D图像特征的VAD模型方面具有优越性。
阅读总结
difussion那一块还不是很了解,还需要多学习。
创新点主要是首次将difussion引入到了视频异常检测领域,当然感觉最近的VAD论文好几个都说自己首次。看了一下用difussion做VAD的感觉还是不算多的,有潜力。
2d的VAD检测基本上有去考虑运动和外观的重建,这篇也是。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【数据结构】归并排序的非递归写法和计数排序
- linux远程服务器上下载模型等
- Java String转byte[]
- 【终极教程】cocos2dx-js 分批次混淆压缩js文件
- 数据分析的基本步骤
- 解析工会排队:动静奖励结合的魅力
- xgboost对密西西比数据集csv文件进行预测
- BIND9配置及配置文件参数详解
- 2024年煤炭生产经营单位(安全生产管理人员)证考试题库及煤炭生产经营单位(安全生产管理人员)试题解析
- 6 UVM Object