构建安全可靠的系统:第十六章到第二十章
第四部分:维护系统
原文:Part IV. Maintaining Systems
译者:飞龙
准备应对不舒适情况的组织有更好的机会处理关键事件。
尽管不可能为可能扰乱您组织的每种情况制定计划,但作为综合灾难规划策略的第一步,正如第十六章中所讨论的那样,是务实和可行的。这些步骤包括建立一个事件响应团队,在事件发生之前为系统和人员进行预置,并测试系统和响应计划——这些准备步骤也将有助于为危机管理做好准备,这是第十七章的主题。在处理安全危机时,具有各种技能和角色的人员需要能够有效地合作和沟通,以保持系统运行。
在遭受攻击后,您的组织将需要控制恢复并处理后果,正如第十八章中所讨论的那样。在这些阶段进行一些前期规划也将有助于您进行彻底的响应,并从中吸取教训,以防止再次发生。
为了更全面地了解情况,我们还包括了一些特定章节的背景示例:
-
第十六章讲述了谷歌如何制定应对旧金山湾区毁灭性地震的应急计划的故事。
-
第十七章讲述了一位工程师发现一个他们不认识的服务账户被添加到一个他们以前没有见过的云项目中的故事。
-
第十八章讨论了在面对大规模网络钓鱼攻击等事件时,驱逐攻击者、减轻其即时行动以及进行长期变革之间的权衡。
第十六章:灾难规划
译者:飞龙
由 Michael Robinson 和 Sean Noonan?
与 Alex Bramley 和 Kavita Guliani 一起
复杂系统可能以简单和复杂的方式失败,从意外的服务中断到恶意行为者的攻击,以获取未经授权的访问。您可以通过可靠性工程和安全最佳实践预见和防止其中一些故障,但从长远来看,故障几乎是不可避免的。
与仅仅希望系统能够在灾难或攻击中幸存下来,或者您的员工能够做出合理的响应不同,灾难规划确保您不断努力提高从灾难中恢复的能力。好消息是,制定全面战略的第一步是务实和可行的。
定义“灾难”
很少有人在灾难全面爆发时才意识到灾难。与其偶然发现一栋被大火吞没的建筑物,您更有可能首先看到或闻到烟雾——一些看似微小的迹象,并不一定看起来像灾难。火灾逐渐蔓延,直到您深陷其中,您才意识到情况的极端性。同样,有时候一个小事件——比如第二章中提到的会计错误——可能会引发全面的事件响应。
灾难有各种形式:
-
自然灾害,包括地震、龙卷风、洪水和火灾。这些往往是显而易见的,对系统的影响程度也不同。
-
基础设施灾难,如组件故障或错误配置。这些并不总是容易诊断的,它们的影响可以从小到大。
-
服务或产品中断,这些中断可以被客户或其他利益相关者观察到。
-
服务的退化接近阈值。有时很难识别。
-
外部攻击者可能在被发现之前长时间获得未经授权的访问。
-
敏感数据的未经授权披露。
-
紧急安全漏洞,需要您立即应用补丁来纠正新的、关键的漏洞。这些事件被视为即将发生的安全攻击(见“妥协与漏洞”)。
在本章和下一章中,我们将灾难和危机这两个术语互换使用,意思是任何可能需要宣布事件并采取响应的情况。
动态灾难响应策略
潜在灾难的范围很广,但设计灵活的灾难响应计划将使您能够适应迅速变化的情况。提前考虑可能遇到的情景,已经是为其做准备的第一步。与任何技能一样,您可以通过规划、实践和程序的迭代来磨练灾难响应技能,直到它们变得自然而然。
事件响应不像骑自行车。没有经常性的练习,响应者很难保持良好的肌肉记忆。缺乏练习可能导致断裂的响应和更长的恢复时间,因此经常排练和完善您的灾难响应计划是一个好主意。熟练的事件管理技能让专业人员在事件响应期间自然而然地发挥作用——如果这些技能是第二天性的,专家们就不会为了遵循过程本身而挣扎。
将响应计划分为立即响应、短期恢复、长期恢复和恢复运营等阶段是有帮助的。图 16-1 显示了与灾难恢复相关的一般阶段。
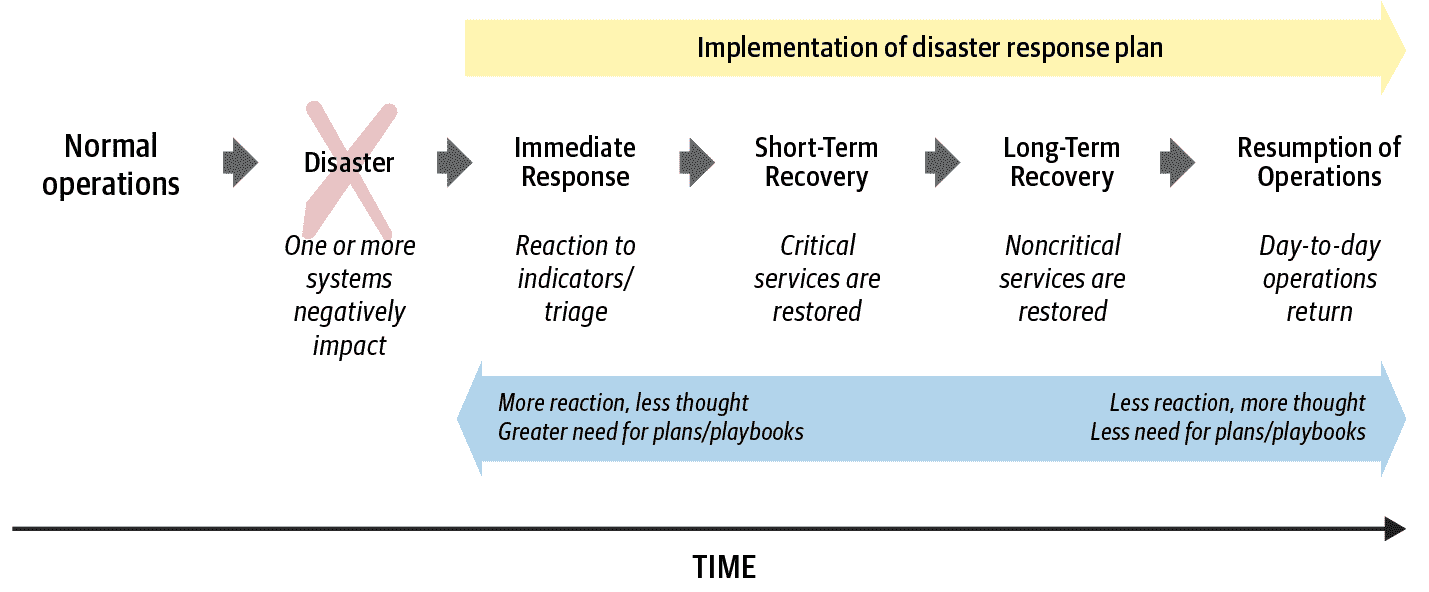
图 16-1:灾难恢复响应工作的阶段
短期恢复阶段应包括为事件制定退出标准,即宣布事件响应完成的标准。成功的恢复可能意味着将服务恢复到完全运行状态,但基础解决方案可能具有提供相同服务水平的新设计。标准还可能要求完全消除风险分析中确定的安全威胁。
在制定应对即时响应、短期和长期恢复以及恢复运营的策略时,您的组织可以通过以下方式做好准备:
-
进行可能影响组织或具有重大影响的潜在灾难的分析
-
建立一个响应团队
-
创建响应计划和详细的操作手册
-
适当配置系统
-
测试您的程序和系统
-
吸收测试和评估的反馈意见
灾难风险分析
进行灾难风险分析是确定组织最关键运营的第一步,这些运营的缺失将导致完全中断。关键运营功能不仅包括重要的核心系统,还包括它们的基础依赖,如网络和应用层组件。灾难风险分析应该确定以下内容:
-
如果受损或离线,可能会使运营陷入瘫痪的系统。您可以将系统分类为任务关键、任务重要或非关键。
-
在应对事件时需要的技术或人力资源。
-
每个系统可能发生的灾难情景。这些情景可以按发生的可能性、频率和对运营的影响(低、中、高或关键)进行分组。
尽管您可能能够直观地对运营进行评估,但更正式的风险评估方法可以避免群体思维,并突出那些并不明显的风险。为了进行彻底的分析,我们建议使用标准矩阵对组织面临的风险进行排名,该矩阵考虑了每种风险发生的概率以及对组织的影响。附录 A 提供了一个样本风险评估矩阵,大型和小型组织都可以根据其系统的具体情况进行调整。
风险评级为您提供了一个关于首要关注的地方的良好经验法则。在对其进行排名后,您应该审查潜在的异常风险清单,例如,一个不太可能发生的事件可能因其潜在影响而被评为关键。您可能还希望征求专家的意见,以审查评估结果,以确定具有隐藏因素或依赖性的风险。
您的风险评估可能会因组织资产的位置而有所不同。例如,日本或台湾的站点应考虑台风,而美国东南部的站点应考虑飓风。随着组织成熟并将容错系统(如冗余互联网电路和备用电源)纳入其系统中,风险评级也可能会发生变化。大型组织应在全球和每个站点级别上进行风险评估,并随着运营环境的变化定期审查和更新这些评估。通过风险评估确定需要保护的系统,您可以准备好创建一个配备工具、程序和培训的响应团队。
建立应急响应团队
有各种方法可以配置应急响应(IR)团队的人员。组织通常以以下几种方式配置这些团队:
-
创建一个专门的全职 IR 团队
-
通过将 IR 职责分配给个人,除了他们现有的工作职能。
-
通过将 IR 活动外包给第三方。
由于预算和规模的限制,许多组织依赖现有员工兼职,一些员工除了执行常规工作职责外,还要在需要时进行事件响应。对于需要更复杂的组织,可能会发现用内部员工配置一个专门的 IR 团队是值得的,以确保响应者始终可用于响应,接受适当的培训,具有必要的系统访问权限,并有足够的时间来应对各种事件。
无论您实现哪种人员配置模型,都可以使用以下技术来创建成功的团队。
确定团队成员和角色
在准备响应计划时,您需要确定将响应事件的核心团队,并明确确定他们的角色。虽然小型组织可能会有来自各个团队的个人贡献者,甚至是一个单一团队来应对每一个事件,但资源更丰富的组织可能会选择为每个功能领域设立一个专门的团队,例如,一个安全响应团队,一个隐私团队,以及一个专注于公共面向站点可靠性的运营团队。
您还可以外包一些功能,同时保留其他功能内部。例如,您可能没有足够的资金和工作量来完全配备内部取证团队,因此您可能会外包该专业知识,同时保留内部的事件响应团队。外包的一个潜在缺点是外部响应者可能无法立即提供帮助。在确定哪些功能保留在内部以及在紧急情况下外包和调用哪些资源时,考虑响应时间是很重要的。
您可能需要以下一些或全部角色来进行事件响应:
事件指挥官
领导对个别事件的响应的个人。
可以重新配置受影响的系统或实现代码以修复错误的人。
公共关系
可以回应公众查询或发布媒体声明的人。这些人经常与传播负责人合作制定信息。
客户支持
可以回应客户查询或主动联系受影响的客户的人。
法律
可以就法律事务提供咨询的律师,例如适用的法律、法规或合同。
隐私工程师
可以解决技术隐私问题的影响的人。
取证专家
可以进行事件重建和归因以确定发生了什么以及如何发生的人。
安全工程师
可以审查事件的安全影响并与 SRE 或隐私工程师合作保护系统的人。
在确定哪些角色将由内部人员担任时,您可能需要实现轮换人员配置模型,其中 IR 团队轮班运作。在事件期间配置轮班人员至关重要,以减轻疲劳并在事件期间提供持续支持。您还可以采用这种模式以提供灵活性,因为主要工作职责随着时间的推移而发展和变化。请记住,这些是角色,而不是个人。一个人在事件期间可能担任多个角色。
确定哪些角色应该由内部人员担任后,您可以创建一个最初的人员名单来组成个别 IR 团队。提前确定这些人有助于澄清角色、责任和所有权,并最大程度地减少混乱和设置时间。确定 IR 团队的冠军也是有帮助的——一个有足够资历承诺资源并消除障碍的人。冠军可以帮助组建团队,并在存在竞争优先级时与高级领导合作。查看第二十一章获取更多信息。
建立团队宪章
IR 团队的宪章应从团队的使命开始,即一句话描述他们将处理的事件类型。使命让读者能够快速了解团队的工作内容。
宪章的范围应描述您所在的工作环境,重点放在技术、最终用户、产品和利益相关者上。这一部分应清楚地定义团队将处理的事件类型,应由内部人员处理的事件,以及应分配给外包团队处理的事件。
为了确保 IR 团队专注于合格事件,组织领导和 IR 冠军就范围达成一致意见非常重要。例如,虽然 IR 团队当然可以回应关于系统防火墙配置和日志启用/验证的个别客户查询,但这些任务可能更适合客户支持团队。
最后,定义团队的成功看起来是非常重要的。换句话说,当 IR 团队的工作完成或可以宣布完成时,您如何知道呢?
建立严重性和优先级模型
严重性和优先级模型可以帮助 IR 团队量化和理解事件的严重性以及响应所需的操作节奏。您应同时使用这两种模型,因为它们是相关的。
严重性模型允许团队根据事件对组织的影响严重程度对事件进行分类。您可以使用五点(0-4)评分来对事件进行排名,其中 0 表示最严重的事件,4 表示最不严重的事件。您应该采用最适合您组织文化的评分标准(颜色、动物等)。例如,如果您使用五点评分标准,网络上的未经授权个人可能被归类为严重性 0 事件,而安全日志的临时不可用可能是严重性 2 事件。在建立模型时,应审查先前执行的风险分析,以便为事件分配适当的严重性评级。这样做将确保不是所有事件都接收到关键或中等严重性评级。准确的评级将帮助事件指挥官在同时报告多个事件时进行优先排序。
优先级模型定义了人员需要多快回应事件。这个模型建立在您对事件严重性的理解之上,也可以使用五点(0-4)评分,其中 0 表示高优先级,4 表示低优先级。优先级决定了所需工作的节奏:评级为 0 的事件需要立即响应,团队成员在处理其他工作之前要先回应这个事件。评级为 4 的事件可以与日常运营工作一起处理。达成一致的优先级模型还有助于保持各个团队和运营负责人的同步。想象一下,一个团队将事件视为优先级 0,而对总体情况了解有限的第二个团队将其视为优先级 2。这两个团队可能会以不同的节奏运作,延迟了适当的事件响应。
通常情况下,一旦了解了事件的严重性,它在事件生命周期内将保持不变。另一方面,优先级可能在事件过程中发生变化。在对事件进行分类和实现关键修复的早期阶段,优先级可能是 0。在关键修复完成后,您可以将优先级降低到 1 或 2,因为工程团队进行清理工作。
为 IR 团队参与设定操作参数
在建立了严重性和优先级模型之后,您可以定义操作参数,描述事件响应团队的日常运作。当团队除了事件响应工作外还执行定期运营工作,或者需要与虚拟团队或外包团队进行沟通时,这变得越来越重要。操作参数确保严重性 0 和优先级 0 的事件得到及时响应。
操作参数可能包括以下内容:
-
对报告的事件最初做出响应的预期时间——例如,在 5 分钟内,30 分钟内,一个小时内,或者在下一个工作日
-
执行初始分类评估并制定响应计划和运营时间表的预期时间
-
服务水平目标(SLOs),以便团队成员了解何时应中断日常工作进行事件响应。
有许多方法可以组织值班轮换,以确保事件响应工作在团队中得到适当的负载平衡,或者根据定期安排的持续工作进行平衡。有关详细讨论,请参阅 SRE 书的第十一章和第十四章,SRE 工作手册的第 8 章和第 9 章,以及 Limoncelli、Chalup 和 Hogan(2014)的第十四章。1
制定响应计划
在严重事件期间做出决策可能具有挑战性,因为响应者试图在有限的信息下迅速工作。精心制定的响应计划可以指导响应者,减少浪费的步骤,并为如何应对不同类别的事件提供一个总体方法。虽然一个组织可能有一项全公司范围的事件响应政策,但 IR 团队需要制定一套涵盖以下主题的响应计划:
事件报告
如何向 IR 团队报告事件。
分类
将响应初始报告并开始分类事件的 IR 团队成员名单。
服务水平目标
关于响应者将采取行动的速度目标的参考。
角色和责任
明确定义 IR 团队参与者的角色和责任。
外联
如何联系可能需要协助事件响应的工程团队和参与者。
沟通
在事件期间进行有效的沟通不是没有提前规划的。您需要建立如何执行以下每一项任务:
-
通知领导有关事件的信息(例如,通过电子邮件、短信或电话),以及这些沟通中应包括的信息。
-
在事件期间进行组织内部沟通,包括响应团队内部和之间的沟通(建立聊天室、视频会议、电子邮件、安全 IRC 频道、错误跟踪工具等)。
-
在必要时与监管机构或执法部门等外部利益相关者进行沟通。您需要与您组织的法律部门和其他部门合作规划和支持这种沟通。考虑为每个外部利益相关者保留联系方式和沟通方法的索引。如果您的 IR 团队足够庞大,您可能需要适当地自动化这些通知机制。
-
向与客户互动的支持团队通报事件。
-
在通信系统不可用时,或者怀疑通信系统受到损害时,如何与响应者和领导进行沟通,而不让对手察觉。
每个响应计划都应概述高级程序,以便受过培训的响应者可以行动。计划应包含对足够详细的 playbook 的引用,受过培训的响应者可以使用它们来执行特定的操作,并且还可能是一个很好的主意概述对特定类别的事件做出响应的总体方法。例如,在处理网络连接问题时,响应计划应包含对要分析的区域和要执行的故障排除步骤的广义概述,并且应引用一个包含如何访问适当网络设备的具体指令的 playbook,例如登录路由器或防火墙。响应计划还可能概述事件响应者确定何时通知高级领导事件以及何时与本地工程团队合作的标准。
创建详细的 playbook
playbook 是响应计划的补充,列出了响应者应如何从头到尾执行特定任务的具体指令。例如,playbook 可能描述如何向响应者授予对某些系统的紧急临时管理访问权限,如何输出和解析特定日志进行分析,或者如何故障转移系统以及何时实现优雅降级。playbook 具有程序性质,应经常修订和更新。它们通常是团队特定的,这意味着对任何灾难的响应可能涉及多个团队通过其自己的特定程序 playbook 进行工作。
确保访问和更新机制已经就位
您的团队应该定义一个存储文档的地方,以便在灾难期间可以使用材料。灾难可能会影响对文档的访问,例如,如果公司服务器离线,所以确保您在紧急情况下可以访问的位置上有副本,并且这些副本保持最新。
系统会进行补丁、更新和重新配置,威胁态势也会发生变化。您可能会发现新的漏洞,并且新的利用程序会出现。定期审查和更新您的响应计划,以确保它们准确并反映任何最近的配置或操作变化。
良好的事件管理需要频繁和健壮的信息管理。团队应该确定一个适合跟踪事件信息和保留事件数据的系统。处理安全和隐私事件的团队可能希望建立一个严格控制访问的系统,而处理服务或产品中断的响应团队可能希望创建一个在公司范围内广泛可访问的系统。
在事件发生之前预置系统和人员
在进行风险分析、创建 IR 团队和记录适当的程序之后,您需要确定在灾难发生之前可以执行的预置活动。确保您考虑了与事件响应生命周期的每个阶段相关的预置活动。通常,预置活动涉及配置具有定义的日志保留、自动响应和明确定义的人工程序的系统。通过了解这些元素,响应团队可以消除数据来源、自动响应和人工响应之间的覆盖间隙。响应计划和 playbook(在前一节中讨论)描述了人类互动所需的大部分内容,但响应者还需要访问适当的工具和基础设施。
为了促进对事件的快速响应,IR 团队应预先确定事件响应的适当访问级别,并提前建立升级程序,以便获取紧急访问的过程不会缓慢和复杂。IR 团队应具有日志分析和事件重建的读取访问权限,以及用于分析数据、发送报告和进行法证检查的工具访问权限。
配置系统
在灾难或事件发生之前,您可以对系统进行多项调整,以减少 IR 团队的初始响应时间。例如:
-
在本地系统中构建容错性并创建故障转移。有关此主题的更多信息,请参见第八章和第九章。
-
部署取证代理,例如GRR代理或EnCase远程代理,跨网络启用日志。这将有助于您的响应和后续的取证分析。请注意,安全日志可能需要长时间的保留期,如第十五章中所讨论的(检测入侵的行业平均时间约为 200 天,而在检测到事件之前删除的日志无法用于调查)。然而,一些国家,如欧盟国家,对日志的保留期有特定要求。在制定保留计划时,请咨询您组织的律师。
-
如果您的组织将备份提交到磁带或其他媒体,请保留一套与用于创建备份的硬件和软件相同的备份,以便在主要备份系统不可用时及时恢复备份。您还应定期进行恢复演练,以确保您的设备、软件和程序正常工作。IR 团队应确定他们将用于与各个域团队(例如电子邮件团队或网络备份团队)合作的程序,以在事件期间测试、验证和执行数据恢复。
-
在紧急情况下,为访问和恢复设置多个备用路径。影响生产网络的中断可能很难恢复,除非您有安全的替代路径来访问网络控制平面。同样,如果发现有人侵入并且不确定公司工作站受到的侵害有多广泛,如果您有一组已知安全的空气隔离系统,您仍然可以信任,那么恢复将更容易。
培训
IR 团队成员应接受严重性/优先级模型、IR 团队的运行模式、响应时间和响应计划和手册的位置的培训。您可以在《SRE 工作手册》第九章中阅读更多关于谷歌对事件响应的方法。
然而,事件响应的培训要求不仅限于 IR 团队。在紧急情况下,一些工程师可能会在不考虑或意识到其行为后果的情况下做出响应。为了减轻这种风险,我们建议对将协助 IR 团队的工程师进行培训,使其了解各种 IR 角色及其责任。我们使用了谷歌的事件管理系统(IMAG),它基于事件指挥系统。IMAG 框架分配了关键角色,如事件指挥官、运营负责人和通信负责人。
培训您的员工识别、报告和升级事件。工程师、客户/用户、自动警报或管理员可能会发现事件。每个报告事件的一方应有单独明确的渠道,公司员工应接受如何何时将事件升级给 IR 团队的培训。这种培训应支持组织的 IR 政策。
工程师在升级之前应有一个有限的时间限制来处理事件。第一响应者可用的时间取决于组织准备接受的风险水平。您可以从 15 分钟的时间窗口开始,并根据需要调整该时间窗口。
您应该在紧急情况发生之前建立决策标准,以确保响应者选择最合乎逻辑的行动方案,而不是在临时决定时做出直觉决定。第一响应者经常面临需要立即决定是否将受损系统脱机或使用何种封锁方法的情况。有关此主题的更多讨论,请参见第十七章。
您应该培训工程师了解,事故响应可能需要解决看似相互矛盾的竞争性优先事项,例如,需要保持最大的正常运行时间和可用性,同时还要保留法医调查的证据。您还应该培训工程师记录其响应活动的笔记,以便他们以后可以区分这些活动和攻击者留下的痕迹。
流程和程序
通过在事故发生之前建立一套流程和程序,您可以大大减少响应时间和响应者的认知负荷。例如,我们建议以下操作:
-
为硬件和软件定义快速采购方法。在紧急情况下,您可能需要额外的设备或资源,例如服务器、软件或发电机燃料。
-
建立外包服务的合同批准流程。对于较小的组织来说,这可能意味着识别外包能力,如法医调查服务。
-
制定政策和程序,在安全事件期间保留证据和日志,防止日志覆盖。有关更多详细信息,请参见第十五章。
深入研究:测试系统和响应计划
一旦您已经创建了组织为应对事件所需的所有材料,如前文所述,评估这些材料的有效性并改进您发现的任何不足是至关重要的。我们建议从多个角度进行测试:
-
评估自动化系统以确保其正常运行。
-
测试流程,消除响应者和工程团队使用的程序和工具中的任何漏洞。
-
培训将在事件期间做出响应的人员,以确保他们具有应对危机的必要技能。
您应该定期进行这些测试,至少每年一次,以确保您的系统、程序和响应在实际紧急情况下是可靠和适用的。
每个组件在将受灾系统恢复到运行状态中发挥着至关重要的作用。即使您的 IR 团队技能非常高,如果没有程序或自动化系统,其应对灾难的能力将是不一致的。如果您的技术程序已记录但不可访问或不可用,它们可能永远不会被实现。测试灾难响应计划的每一层的弹性可以降低这些风险。
对于许多系统,您需要记录减轻威胁的技术程序,定期审计控制(例如,每季度或每年一次)以确保它们仍在实现,并向工程师提供修复列表,以纠正您发现的任何弱点。刚开始进行 IR 规划的组织可能希望调查有关灾难恢复和业务连续性规划的认证,以获得灵感。
审计自动化系统
您应该审计所有关键系统和依赖系统,包括备份系统、日志系统、软件更新程序、警报生成器和通信系统,以确保它们正常运行。完整的审计应确保以下内容:
备份系统正常运行。
备份应该正确创建,存储在安全位置,存储适当的时间,并以正确的权限存储。定期进行数据恢复和验证练习,以确保您可以从备份中检索和使用数据。有关 Google 数据完整性方法的更多信息,请参阅SRE 书籍第 26 章。
事件日志(在上一章中讨论)被正确存储。
这些日志允许响应者在法证调查期间重建事件时构建准确的时间线。您应该根据组织的风险水平和其他适用的考虑因素存储事件日志的时间段。
关键漏洞应及时修补。
审核自动和手动的补丁流程,以减少人为干预的需求和人为错误的可能性。
警报正确生成。
系统生成警报 - 电子邮件警报,仪表板更新,短信等 - 当满足特定标准时。验证每个警报规则,以确保它正确触发。还要确保考虑依赖关系。例如,如果在网络中断期间 SMTP 服务器离线,您的警报会受到什么影响?
通信工具,如聊天客户端,电子邮件,电话会议桥接服务和安全 IRC,按预期工作。
运作良好的通信渠道对于响应团队至关重要。您还应该审核这些工具的故障转移能力,并确保它们保留您需要编写事后分析的消息。
进行非侵入式桌面练习
桌面练习是测试记录程序和评估响应团队表现的非常有价值的工具。这些练习可以作为评估端到端事件响应的起点,并且在实际测试不可行时也很有用 - 例如,引发实际地震。模拟可以从小到大,范围广泛,并且通常是非侵入式的:因为它们不会使系统脱机,所以不会干扰生产环境。
类似于SRE 书籍第十五章中描述的 Wheel of Misfortune 练习,您可以通过呈现参与者各种后续情节变化的事件情景来进行桌面练习。要求参与者描述他们将如何应对情景,以及他们将遵循哪些程序和协议。这种方法可以让参与者发挥他们的决策能力,并获得建设性的反馈。这些练习的开放结构意味着它们可以吸纳各种参与者,包括以下人员:
-
一线工程师,按照详细的手册恢复瘫痪系统的服务
-
高级领导层,就运营方面的业务决策进行决策
-
公共关系专业人士,协调外部沟通
-
律师,提供上下文法律指导,并帮助制定公共沟通
这些桌面练习最重要的一点是挑战响应者,并为所有参与者提供在真正事件发生之前练习相关程序和决策过程的机会。
在实现桌面练习时,以下是一些要考虑的关键特点:
可信度
桌面场景应该是可信的 - 一个引人入胜的情景可以激励参与者跟随而不需要悬置怀疑。例如,一个练习可能假设用户受到网络钓鱼攻击,使对手能够利用用户工作站上的漏洞。您可以基于现实攻击和已知的漏洞和弱点来确定攻击者在网络中移动的关键点。
细节
制定桌面情景的人应该提前研究该情景,引导者应该熟悉事件的细节和对情景的典型响应。为了增加可信度,桌面的创建者可以创建参与者在真实事件中会遇到的文物,如日志文件、客户或用户的报告和警报。
决策点
就像“选择你自己的冒险”故事一样,桌面练习应该有决策点,帮助情节展开。典型的 60 分钟桌面练习包含大约 10-20 个情节决策点,让参与者参与决策,影响练习的结果。例如,如果桌面练习的参与者决定将受损的电子邮件服务器下线,那么在剩下的情景中参与者就不能发送电子邮件通知。
参与者和引导者
尽量使桌面练习尽可能互动。随着练习的展开,引导者可能需要对响应者执行的行动和命令做出回应。与其仅仅讨论他们如何应对事件,参与者应该展示他们将如何应对。例如,如果 IR 手册要求事件响应者将勒索软件攻击升级到取证团队的成员进行调查,同时也要升级到网络安全团队的成员来阻止对敌对网站的流量,那么响应者应该在桌面练习中执行这些程序。“执行响应”有助于事件响应者建立肌肉记忆。引导者应提前熟悉情景,以便在需要时即兴并引导响应者朝正确的方向发展。再次强调,这里的目标是让参与者积极参与情景。
结果
一个成功的桌面练习不应该让参与者感到挫败,而应该以对工作得好和工作不太好的可行反馈结束。参与者和引导者应该能够就事件响应团队的改进领域提出具体建议。在适当的情况下,参与者应该建议对系统和政策进行改变,以解决他们发现的固有弱点。为了确保参与者解决这些建议,创建具体负责人的行动项。
在生产环境中测试响应
虽然桌面练习对模拟各种事件情景很有用,但你需要在真实的生产环境中测试一些事件情景、攻击向量和漏洞。这些测试在安全和可靠性的交汇处运作,通过让 IR 团队了解运营约束、在真实参数下进行实践,并观察他们的响应如何影响生产环境和正常运行时间。
单系统测试/故障注入
与其测试整个系统的端到端,你可以将大型系统分解为单独的软件和/或硬件组件进行测试。测试可以采用各种形式,可以涉及单个本地组件或具有组织范围的单个组件。例如,当一个恶意内部人连接 USB 存储设备到工作站并尝试下载敏感内容时会发生什么?本地日志是否跟踪本地 USB 端口活动?日志是否足够聚合并及时升级,使安全团队能够快速响应?
我们特别建议您通过故障注入进行单系统测试。将故障注入到您的系统中可以让您运行有针对性的测试,而不会干扰整个系统。更重要的是,故障注入框架允许各个团队在不涉及其依赖关系的情况下测试其系统。例如,考虑常用于负载平衡的开源 Envoy HTTP 代理。除了其许多负载平衡功能外,该代理支持故障注入 HTTP 过滤器,您可以使用它来为一部分流量返回任意错误或延迟请求一定时间。使用这种类型的故障注入,您可以测试系统是否正确处理超时,并且超时是否会导致生产中的不可预测行为。
当您在生产环境中发现异常行为时,经过充分练习的故障注入框架可以实现更有结构的调查,您可以以受控的方式重现生产问题。例如,想象以下情景:当公司的用户尝试访问特定资源时,基础设施使用单一来源检查所有认证请求。然后,公司迁移到一个需要对各种来源进行多次认证检查以获取类似信息的服务。结果,客户开始超过这些功能调用的配置超时。认证库的缓存组件内的错误处理错误地将这些超时视为永久性(而不是临时性)故障,触发基础设施中许多其他小故障。通过使用故障注入的已建立的事故响应框架,在一些调用中注入延迟,响应团队可以轻松地重现行为,确认他们的怀疑,并开发修复方案。
人力资源测试
虽然许多测试涉及系统的技术方面,但测试也应考虑人员故障。当特定人员不可用或未能行动时会发生什么?通常,事故响应团队依赖于对组织具有强大机构知识的个人,而不是遵循既定流程。如果关键决策者或经理在响应期间不可用,那么 IR 团队的其他成员将如何继续?
多组件测试
使用分布式系统意味着任何数量的依赖系统或系统组件可能会失败。您需要计划多组件故障并创建相关的事故响应程序。考虑一个依赖于多个组件的系统,每个组件都经过了单独测试。如果两个或更多组件同时失败,那么事故响应的哪些部分必须以不同的方式处理?
思考练习可能不足以测试每个依赖项。在考虑安全环境中的服务中断时,您需要考虑安全问题以及故障场景。例如,当故障切换发生时,系统是否尊重现有的 ACL?有什么保障可以确保这种行为?如果您正在测试授权服务,依赖服务是否会关闭失败?要深入了解这个话题,请参阅第五章。
系统范围的故障/故障切换
除了测试单个组件和依赖项外,还要考虑整个系统失败时会发生什么。例如,许多组织运行主要和次要(或灾难恢复)数据中心。在切换到从次要位置运行之前,您无法确信故障切换策略是否会保护您的业务和安全姿态。谷歌定期对整个数据中心建筑进行电源循环,以测试故障是否会导致用户可见的影响。这种练习确保服务保持在没有特定数据中心位置的情况下运行的能力,并且执行此工作的技术人员在管理断电/通电程序方面经验丰富。
对于在另一个提供商的云基础设施上运行的服务,考虑如果整个可用区域或区域发生故障,您的服务会发生什么情况。
红队测试
除了宣布的测试,谷歌还进行灾难准备演习,称为红队演习:由其信息安全保障组织进行的进攻性测试。类似于 DiRT 演习(参见“DiRT 演习测试紧急访问”),这些演习模拟真实攻击,以测试和改进检测和响应能力,并展示安全问题的业务影响。
红队通常不会提前通知事件响应人员,除了高级领导层。由于红队熟悉谷歌的基础设施,他们的测试比标准网络渗透测试更加有效。由于这些练习是在内部进行的,它们提供了在完全外部攻击(攻击者在谷歌之外)和内部攻击(内部风险)之间取得平衡的机会。此外,红队练习通过测试安全性端到端以及通过攻击(如钓鱼和社会工程)测试人类行为,补充了安全审查。有关红队的更深入探讨,请参阅“特殊团队:蓝队和红队”。
评估响应
在应对实际事件和测试场景时,创建有效的反馈循环非常重要,这样您就不会反复遭受相同的情况。实际事件应该需要具体的事后分析和行动项目;您也可以为测试创建事后分析和相应的行动项目。虽然测试既可以是一种有趣的练习,也可以是一种极好的学习经验,但这种实践需要一些严谨性——跟踪测试的执行情况,并对其影响以及您组织中的人员如何应对测试进行批判性评估是非常重要的。进行一项练习而不实现所学到的教训只是娱乐。
在评估组织对事件和测试的响应时,考虑以下最佳实践:
-
衡量响应。评估者应该能够确定哪些工作得很好,哪些没有。衡量实现响应的每个阶段所需的时间,以便您可以确定纠正措施。
-
编写无过失的事后分析,并专注于如何改进系统、程序和流程。
-
创建反馈循环,以改进现有计划或根据需要制定新计划。
-
收集证据并将其反馀到信号检测中。确保您解决任何发现的差距。
-
为了进行取证分析并解决差距,请确保保存适当的日志和其他相关材料,特别是在进行安全性练习时。
-
评估甚至“失败”的测试。什么有效,你需要改进什么?
-
如“特殊团队:蓝队和红队”中所讨论的,实现颜色团队以确保您的组织能够应对所学到的教训。您可能需要一个混合的紫队,以确保蓝队及时解决红队利用的漏洞,从而防止攻击者重复利用相同的漏洞。您可以将紫队视为漏洞的回归测试。
谷歌的例子
为了使本章描述的概念和最佳实践更具体,这里有一些真实世界的例子。
具有全球影响的测试
2019 年,谷歌对旧金山湾区发生大地震的响应进行了测试。该场景包括模拟对物理设施、交通基础设施、网络组件、公用事业和电力、通信、业务运营和高管决策的影响。我们的目标是测试谷歌对大规模中断的响应以及对全球运营的影响。具体来说,我们测试了以下内容:
-
谷歌如何为地震和多次余震中受伤的人提供立即的急救?
-
谷歌如何向公众提供帮助?
-
员工如何向谷歌的领导层升级信息?在通信中断的情况下,例如,网络中断或局域网/城域网/广域网中断,谷歌如何向员工传播信息?
-
如果员工有利益冲突,例如,如果员工需要照顾家人和家庭,谁会提供现场响应?
-
无法通行的次要道路会对该地区产生什么影响?溢出会对主要道路产生什么影响?
-
谷歌如何为滞留在谷歌校园的员工、承包商和访客提供帮助?
-
谷歌如何评估其建筑物的损坏,其中可能包括破裂的管道、污水问题、破碎的玻璃、停电和破裂的网络连接?
-
如果受影响的团队无法启动权责转移,SRE 和地理区域外的各种工程团队如何接管系统?
-
如何使受影响地理区域之外的领导层能够继续业务运营和做出与业务相关的决策?
DiRT 演习测试紧急访问
有时我们可以同时测试可靠性和安全运营的稳健性。在我们的年度灾难恢复培训(DiRT)演习中,SRE 测试了紧急访问凭证的程序和功能:当标准 ACL 服务中断时,他们能否获得对公司和生产网络的紧急访问?为了增加安全测试层,DiRT 团队还纳入了信号检测团队。当 SRE 启动紧急访问程序时,检测团队能够确认正确的警报触发,并且访问请求是合法的。
行业范围内的漏洞
2018 年,谷歌提前得知 Linux 内核中的两个漏洞,这些漏洞支撑着我们大部分的生产基础设施。通过发送特制的 IP 片段和 TCP 段,SegmentSmack(CVE-2018-5390)或 FragmentSmack(CVE-2018-5391)可以导致服务器执行昂贵的操作。通过使用大量的 CPU 和挂钟时间,这个漏洞可以允许攻击者获得显著的规模提升,超出了正常的拒绝服务攻击——一个通常可以应对 1 Mpps 攻击的服务在大约 50 Kpps 时会崩溃,韧性降低了 20 倍。
灾难规划和准备使我们能够在两个方面减轻风险:技术方面和事件管理方面。在事件管理方面,潜在的灾难如此重大,以至于谷歌指派了一组事件经理全职处理问题。团队需要确定受影响的系统,包括供应商固件图像,并执行一项全面的计划来减轻风险。
在技术方面,SRE 已经为 Linux 内核实现了深度防御措施。一个运行时补丁,或者ksplice,使用函数重定向表来使重新启动新内核变得不必要,可以解决许多安全问题。Google 还保持内核推出纪律:我们定期向整个机器群推送新内核,目标是少于 30 天,并且我们有明确定义的机制,以增加这一标准操作程序的推出速度,如果有必要的话。?
如果我们无法使用 ksplice 修复漏洞,我们可以以较快的速度进行紧急推出。然而,在这种情况下,我们可以使用内核 splice 来解决受影响的两个函数——tcp_collapse_ofo_queue和tcp_prune_ofo_queue。SRE 能够在生产系统中应用 ksplice,而不会对生产环境产生不利影响。由于推出程序已经经过测试和批准,SRE 很快获得了副总裁的批准,在代码冻结期间应用补丁。
结论
当考虑如何从零开始启动灾难恢复测试和计划时,可能会感到可能的方法的数量令人不知所措。然而,即使在小规模上,您也可以应用本章的概念和最佳实践。
首先,确定您最重要的系统或关键数据,然后确定如何应对影响它的各种灾难。您需要确定在没有服务的情况下可以运行多长时间,以及影响它的人员或其他系统的数量。
从这一重要的第一步开始,您可以逐步扩大覆盖范围,形成一个强大的灾难准备战略。从最初的确定和预防引发火灾的火花,您可以逐步应对不可避免的大火。
1 Limoncelli, Thomas A., Strata R. Chalup, and Christina J. Hogan. 2014. 云系统管理实践:设计和操作大型分布式系统。波士顿,马萨诸塞州:Addison-Wesley。
2 这些主题在SRE 书籍第 22 章中有描述。
3 参见SRE 书籍第十四章和SRE 工作手册第九章中的生产特定的实例。
? 参见SRE 书籍第十五章。
? 参见SRE 书籍第十三章。
? 参见 Kripa Krishnan 的文章“应对意外”和她的 USENIX LISA15 演讲“Google 十年的崩溃”。
? 一个打破玻璃机制可以绕过政策,允许工程师快速解决故障。参见“打破玻璃”。
? 第九章讨论了准备组织快速应对事故的其他设计方法。
第十七章:危机管理
译者:飞龙
作者:Matt Linton
与 Nick Soda 和 Gary O’Connor 一起
事件响应对于可靠性和安全事件都至关重要。《SRE 书》的第十四章和《SRE 工作手册》的第九章探讨了与可靠性故障相关的事件响应。我们使用相同的方法——谷歌的事件管理(IMAG)框架——来应对安全事件。
安全事件是不可避免的。行业中有一句常见的格言是“只有两种公司:知道自己受到了侵害的和不知道自己受到了侵害的。”安全事件的结果取决于你的组织做好了多少准备,以及你的响应有多好。为了实现成熟的安全姿态,你的组织需要建立和实践事件响应(IR)能力,正如前一章所讨论的那样。
除了确保未经授权的人无法访问您的系统和数据保持在应有的位置之外,今天的 IR 团队还面临着新的和困难的挑战。随着安全行业朝着更大的透明度1和与用户更开放的需求趋势,这一期望对于习惯于在公众关注的聚光灯下运作的任何 IR 团队来说都是一个独特的挑战。此外,像欧盟的《通用数据保护条例(GDPR)》和与注重安全的客户的服务合同不断推动着调查必须开始、进行和完成的速度的边界。如今,客户要求在最初检测到潜在安全问题后的 24 小时(或更短时间内)内通知他们并不罕见。
事件通知已成为安全领域的核心特性,与云计算的易用性和普及性、工作场所“自带设备”(BYOD)政策的广泛采用以及物联网(IoT)等技术进步并驾齐驱。这些进步为 IT 和安全人员带来了新的挑战,例如对组织所有资产的控制和可见性的限制。
这是危机吗?
并非每个事件都是危机。事实上,如果你的组织状况良好,相对较少的事件应该会演变成危机。一旦发生升级,响应者评估升级的第一步是分诊——利用他们掌握的知识和信息对事件的严重性和潜在后果进行合理和明智的假设。
分诊是急诊医疗界的一项成熟技能。一名急救医生(EMT)到达车祸现场时,首先要确保现场没有进一步伤害的立即风险,然后进行分诊。例如,如果一辆公共汽车与一辆小汽车相撞,已经可以逻辑推断出一些信息。小汽车上的人可能受了重伤,因为与重型公共汽车的碰撞可能会造成很大的伤害。公共汽车可以载有许多乘客,所以乘客可能会受伤。通常情况下,两辆车都不会携带危险化学品。在到达的第一分钟内,急救医生知道他们需要叫更多的救护车,可能要警报重症监护单位,并叫消防部门来解救小车上被困的人。他们可能不需要危险物质清理队。
你的安全响应团队应该使用相同的评估方法来对待不断发生的事件。作为第一步,他们必须估计攻击的潜在严重程度。
事件分诊
在分诊时,负责调查的工程师必须收集基本事实,以帮助决定升级是否属于以下情况之一:
-
一个错误(即误报)
-
一个容易纠正的问题(可能是一次机会性的妥协)
-
一个复杂且可能具有破坏性的问题(比如有针对性的妥协)
他们应该能够使用预定的流程对可预测的问题、错误和其他简单问题进行分诊。更大更复杂的问题,比如有针对性的攻击,可能需要组织和管理的响应。
每个团队都应该有预先计划的标准,以帮助确定什么构成了一起事件。理想情况下,他们应该在事件发生之前确定在他们的环境中哪些风险是严重的,哪些是可以接受的。对事件的响应将取决于事件发生的环境类型,组织预防控制的状态以及其响应程序的复杂性。考虑三个组织如何应对相同的威胁——勒索软件攻击:
-
组织 1拥有成熟的安全流程和分层防御,包括只允许加密签名和批准的软件执行的限制。在这种环境中,众所周知的勒索软件几乎不可能感染机器或在整个网络中传播。如果确实发生,检测系统会发出警报,然后有人进行调查。由于成熟的流程和分层防御,一个工程师可以处理这个问题:他们可以检查是否发生了可疑活动,超出了尝试恶意软件执行,并使用标准流程解决问题。这种情况不需要危机式的事件响应努力。
-
组织 2的销售部门在云环境中举办客户演示,想要了解组织软件的人安装和管理他们的测试实例。安全团队注意到这些用户倾向于犯安全配置错误,导致系统受到威胁。为了不需要人工干预,安全团队建立了一个机制,自动清除并替换受损的云测试实例。在这种情况下,勒索软件蠕虫也不需要太多的取证或事件响应关注。虽然组织 2 没有阻止勒索软件的执行(如组织 1 的情况),但组织 2 的自动化缓解工具可以控制风险。
-
组织 3的分层防御较少,对其系统是否受到威胁的可见性有限。该组织面临着勒索软件在其网络中传播的更大风险,可能无法快速做出响应。在这种情况下,如果蠕虫传播,可能会影响大量业务关键系统,并且组织将受到严重影响,需要大量技术资源来重建受损的网络和系统。这种蠕虫对组织 3 构成严重风险。
虽然这三个组织都在应对相同的风险来源(勒索软件攻击),但它们的分层防御和流程成熟度水平的差异影响了攻击的潜在严重性和影响。虽然组织 1 可能只需要启动一个流程驱动的响应,组织 3 可能面临需要协调的事件管理的危机。随着事件对组织构成严重风险的可能性增加,需要组织多个参与者进行有组织的响应的可能性也增加。
您的团队可以进行一些基本评估,以确定升级是否需要标准的流程驱动方法或危机管理方法。问问自己以下问题:
-
您存储了哪些可能对系统上的某人可访问的数据?这些数据的价值或关键性是什么?
-
潜在受损系统与其他系统之间存在什么信任关系?
-
是否有补偿控制,攻击者也必须突破(并且似乎完好无损)才能利用他们的立足点?
-
攻击是否看起来是商品机会主义恶意软件(例如广告软件),还是看起来更先进或有针对性(例如看起来是为你的组织量身定制的网络钓鱼活动)?
仔细考虑你组织的所有相关因素,并根据这些事实确定组织风险的最高可能水平。
妥协与漏洞
长期以来,IR 团队一直负责应对疑似入侵和妥协事件。但是对于软件和硬件漏洞,也就是安全漏洞呢?你会把系统中新发现的安全漏洞视为尚未被发现的妥协吗?
软件漏洞是不可避免的,你可以为它们制定计划(如第八章中所述)。良好的防御实践在漏洞开始之前消除或限制潜在的负面后果。2如果你计划良好并实现了深度防御和额外的安全层,你就不需要像处理事件那样处理漏洞修复。也就是说,可能需要使用事件响应流程来管理复杂或影响较大的漏洞,这可以帮助你组织并快速响应。
在谷歌,我们通常将具有极端风险的漏洞视为事件。即使漏洞没有被积极利用,尤其严重的漏洞仍然可能引入极端风险。如果你在漏洞被公开披露之前参与修复(这些努力通常被称为协调漏洞披露或 CVDs),操作安全和保密问题可能需要加强响应。另外,如果你在公开披露后匆忙修补系统,保护具有复杂相互依赖关系的系统可能需要紧急努力,部署修复可能会困难且耗时。
一些特别危险的漏洞示例包括 Spectre 和 Meltdown(CVE-2017-5715 和 5753)、glibc(CVE-2015-0235)、Stagefright(CVE-2015-1538)、Shellshock(CVE-2014-6271)和 Heartbleed(CVE-2014-0160)。
掌握你的事件
现在我们已经讨论了分类和风险评估的过程,接下来的三节假设“大事”已经发生:你已经确定或怀疑受到了有针对性的妥协,需要进行全面的事件响应。
第一步:不要惊慌!
许多应对者将严重事件升级与不断上升的恐慌感和肾上腺素飙升联系在一起。消防、救援和医疗领域的紧急应对人员在基础培训中被告知不要在紧急情况下奔跑。奔跑不仅会增加现场事故的可能性,使问题变得更糟,还会给应对者和公众灌输恐慌感。类似地,在安全事件中,匆忙行动所获得的额外几秒钟很快就会被计划失败的后果所掩盖。
尽管谷歌的 SRE 和安全团队执行事件管理的方式类似,但在开始安全事件的危机管理响应和可靠性事件(如故障)之间存在差异。当发生故障时,值班的 SRE 准备采取行动。他们的目标是快速找到错误并修复它们,以恢复系统到良好状态。最重要的是,系统并不知道自己的行为,并且不会抵制被修复。
在潜在的妥协中,攻击者可能会密切关注目标组织采取的行动,并在响应者试图修复问题时对抗他们。在没有进行全面调查之前尝试修复系统可能是灾难性的。因为典型的 SRE 工作不具备这种风险,SRE 通常的响应是先修复系统,然后记录他们从失败中学到的东西。例如,如果工程师提交了一个破坏生产环境的更改列表(CL),SRE 可能会立即采取行动来撤销 CL,使问题消失。问题解决后,SRE 将开始调查发生了什么。而安全响应则要求团队在尝试纠正事情之前完成对发生情况的全面调查。
作为安全事件响应者,您的第一个任务是控制自己的情绪。在升级的前五分钟内,深呼吸,让任何恐慌的感觉过去,提醒自己需要一个计划,并开始考虑下一步。虽然立即做出反应的愿望很强烈,但实际上,事后分析很少报告说,如果员工早五分钟做出反应,安全响应就会更有效。更有可能的是,提前进行一些额外的规划将增加更大的价值。
开始您的响应
在谷歌,一旦工程师确定他们面临的问题是一个事件,我们就会遵循一个标准流程。这个流程称为谷歌的事件管理,在SRE 工作手册的第九章中有详细描述,以及我们应用该协议的故障和事件的案例研究。本节描述了如何使用 IMAG 作为标准框架来管理安全妥协。
首先,快速回顾一下:如前一章所述,IMAG 基于一种称为事件指挥系统(ICS)的正式流程,该流程被全球的消防、救援和警察机构使用。像 ICS 一样,IMAG 是一个灵活的响应框架,足够轻便以管理小事件,但又能够扩展到包括大规模和广泛的问题。我们的 IMAG 计划旨在规范流程,以确保在事件处理的三个关键领域(指挥、控制和通信)取得最大成功。
管理事件的第一步是指挥。在 IMAG 中,我们通过发布声明来做到这一点:“我们的团队宣布涉及X的事件,我是事件指挥官(IC)。”明确地说“这是一个事件”可能看起来简单,甚至可能是不必要的,但为了避免误解,明确是指挥和通信的核心原则。以声明开始您的事件是对齐每个人期望的第一步。事件复杂而不寻常,涉及高度紧张,并且发生速度很快。参与其中的人需要专注。高管应该被通知,团队可能会忽略或绕过正常流程,直到事件得到控制。
在响应者接管并成为 IC 之后,他们的工作是保持对事件的控制。IC 指挥响应,并确保人们始终朝着特定目标前进,以便危机中的混乱和不确定性不会使团队偏离轨道。为了保持控制,IC 和他们的领导必须与所有参与者保持卓越的通信。
谷歌使用 IMAG 作为各种事件的通用响应框架。所有值班工程师(理想情况下)都接受相同基本知识的培训,并学习如何使用它们来扩展和专业地管理响应。虽然 SRE 和安全团队的重点可能不同,但最终,拥有相同的响应框架使这两个团队能够在压力下无缝合作,当与陌生团队合作可能最困难时。
建立您的事件团队
根据 IMAG 模型,一旦宣布发生事故,宣布事故的人要么成为事故指挥官,要么从其他可用的工作人员中选择一个 IC。无论选择哪种路线,都要明确指定这项任务,以避免响应者之间的误解。被指定为 IC 的人也必须明确承认他们接受了这项任务。
接下来,IC 将评估需要立即采取的行动,以及谁可以担任这些角色。您可能需要一些熟练的工程师来启动调查。大型组织可能会有一个专门的安全团队;非常大型的组织甚至可能会有一个专门的事件响应团队。小型组织可能会有一个专门的安全人员,或者有人在其他运营责任之外兼职处理安全事务。
无论组织的规模或构成如何,IC 都应该找到熟悉潜在受影响系统的员工,并将这些人员委派为事件响应团队。如果事件规模扩大并需要更多人员,最好指定一些领导人负责调查的某些方面。几乎每个事件都需要一个运营负责人(OL):战术上的对应和 IC 的合作伙伴。虽然 IC 专注于制定实现事件响应进展所需的战略目标,OL 专注于实现这些目标并确定如何实现。大多数执行调查、修复和打补丁系统等技术人员应该向 OL 汇报。
您可能需要填补的其他主要角色包括以下内容:
管理联络人
您可能需要有人立即做出艰难的决定。您的组织中谁可以决定必要时关闭一个产生收入的服务?谁可以决定让员工回家或撤销其他工程师的凭证?
法律负责人
您的事件可能会引发您需要帮助回答的法律问题。您的员工是否有增强的隐私期望?例如,如果您认为有人通过其网络浏览器下载了恶意软件,您是否需要额外的权限来检查他们的浏览器历史记录?如果您认为他们通过个人浏览器配置文件下载了恶意软件怎么办?
沟通负责人
根据事件的性质,您可能需要与客户、监管机构等进行沟通。擅长沟通的专业人员可能是您响应团队的重要补充。
深入探讨:运营安全
在危机管理的背景下,*运营安全(OpSec)*指的是保持响应活动秘密的做法。无论您是在怀疑妥协、内部滥用调查还是危险漏洞的工作,如果公开存在可能导致广泛利用的危险漏洞,您可能会有需要保密的信息,至少在有限的时间内。我们强烈建议您今天就建立一个 OpSec 计划——在您遇到事件之前——这样您就不必在最后一分钟匆忙制定计划。一旦秘密泄露,就很难重新获得。
IC 最终负责确保保密规则得到制定、传达和遵守。要求参与调查的每个团队成员都应该接受简要介绍。您可能有特定的数据处理规则,或者对使用哪些通信渠道有期望。例如,如果您怀疑您的电子邮件服务器在违规范围内,您可能会禁止员工之间就违规进行电子邮件交流,以防攻击者能够看到这些对话。
作为最佳实践,我们建议您的 IC 为每个事件响应团队成员制定具体的指导。每个团队成员在开始处理事件之前应该审查并确认这些指导。如果您没有清楚地向所有相关方传达保密规则,您就有可能发生信息泄漏或过早披露。
除了保护响应活动免受攻击者的影响外,一个良好的操作安全性计划还解决了如何在不进一步暴露组织的情况下进行响应。考虑一下,一个攻击者入侵了您公司员工的帐户,并试图从服务器的内存中窃取其他密码。如果在调查期间系统管理员使用管理凭据登录受影响的机器,攻击者会很高兴。提前计划如何在不给攻击者提供额外杠杆的情况下访问数据和机器是很重要的。一种方法是提前部署远程取证代理到所有系统。这些软件包可以为授权的响应者提供一条访问路径,让他们可以在不通过登录系统的方式冒风险获取取证物证。
向攻击者透露您已发现他们的攻击的后果可能很严重。一个决心要在您的调查之外持续存在的攻击者可能会保持安静。这会使您失去对他们妥协程度的宝贵洞察,并可能导致您错过他们的一个(或多个)立足点。而已经完成目标并且不想保持安静的攻击者可能会在发现您的行动后尽可能地摧毁您的组织!
以下是一些常见的操作安全性错误:
-
在可能让攻击者监视响应活动的媒介(如电子邮件)中传达或记录事件。
-
登录被入侵的服务器。这会向攻击者暴露潜在有用的身份验证凭据。
-
连接到并与攻击者的“命令和控制”服务器进行交互。例如,不要尝试通过从正在进行调查的机器下载来访问攻击者的恶意软件。您的行为将在攻击者的日志中显得异常,并可能警告他们您的调查。此外,不要对攻击者的机器进行端口扫描或域查找(这是新手响应者常犯的错误)。
-
在调查完成之前锁定受影响用户的帐户或更改密码。
-
在了解攻击的全部范围之前将系统下线。
-
允许攻击者可能窃取的相同凭据访问您的分析工作站。
在您的操作安全性响应中考虑以下良好的做法:
-
尽可能进行面对面的会议和讨论。如果需要使用聊天或电子邮件,使用新的机器和基础设施。例如,面临未知程度的妥协的组织可能会建立一个新的临时基于云的环境,并部署与其常规设备不同的机器(例如,Chromebook)供响应者进行通信。理想情况下,这种策略提供了一个干净的环境,可以在攻击者的视线之外进行聊天、记录和交流。
-
在可能的情况下,确保您的机器配置了远程代理或基于密钥的访问方法。这样可以在不泄露登录凭据的情况下收集证据。
-
在请求他人帮助时,要明确和明确地说明保密性——除非您告诉他们,否则他们可能不知道特定信息应该保密。
-
在调查的每个步骤中,考虑一个精明的攻击者可能从您的行动中得出的结论。例如,入侵 Windows 服务器的攻击者可能会注意到一波突然的组策略收紧,并得出他们已经被发现的结论。
为了更大的利益而交换良好的操作安全性
在保持您的事件响应保密的一般建议中有一个明显的例外:如果您面临即将到来且明确可识别的风险。如果您怀疑对一个如此关键以至于重要数据、系统甚至生命可能处于危险之中的系统进行了妥协,可能会有正当理由采取极端措施。在处理作为事件的漏洞或错误的情况下,有时该漏洞可能如此容易被利用并且如此广为人知(例如,Shellshock^(3)),以至于关闭或完全禁用系统可能是保护它的最佳方式。这样做当然会让您的攻击者和其他人明显地意识到出现了问题。
这些重大决定和组织权衡不太可能仅由事件指挥官做出,除非在极端危险的情况下(例如,关闭电网控制系统以防止灾难)。通常,组织内的高管做出这样的决定。然而,当这些决定被辩论时,事件指挥官是房间里的专家,他们的建议和安全专业知识至关重要。在一天结束时,组织在危机中的许多决策并不是关于做出正确的决定;而是在一系列次优选择中做出最佳可能的选择。
深入探讨:调查过程
调查安全妥协涉及尝试通过攻击的每个阶段来追溯攻击者的步骤。理想情况下,您的 IR 团队(由分配到该工作的任何工程师组成)将尝试在多个任务之间保持紧密的努力循环。? 这一努力侧重于确定组织的所有受影响部分,并尽可能多地了解发生了什么事情。
数字取证是指确定攻击者可能在设备上采取的所有行动的过程。取证分析师(进行取证的工程师,最好是经过专门培训和经验的人)分析系统的所有部分,包括可用的日志,以确定发生了什么事情。分析师可能会执行以下一些或所有的调查步骤:
取证成像
制作与受损系统连接的任何数据存储设备的安全只读副本(和校验和)。这样可以在副本被拍摄时将数据保留在已知状态,而不会意外覆盖或损坏原始磁盘。法庭诉讼通常需要原始磁盘的取证图像作为证据。
内存成像
制作系统内存的副本(或在某些情况下,运行二进制文件的内存)。内存可能包含许多数字证据,这些证据在调查过程中可能会有用,例如进程树、正在运行的可执行文件,甚至攻击者可能已加密的文件密码。
文件刻录
提取磁盘内容,以查看是否可以恢复某些文件类型,特别是可能已被删除的文件,例如攻击者试图删除的日志。一些操作系统在删除文件时不会将文件内容清零。相反,它们只会取消文件名的链接,并将磁盘区域标记为以后重用。因此,您可能能够恢复攻击者试图删除的数据。
日志分析
调查与日志中出现的与系统相关的事件,无论是在系统本身还是来自其他来源。网络日志可能显示谁何时与系统交谈;来自其他服务器和台式机的日志可能显示其他活动。
恶意软件分析
对攻击者使用的工具进行分析,以确定这些工具的功能、工作原理以及这些工具可能与哪些系统进行通信。此分析的数据通常反馈给进行取证和检测工作的团队,以提供有关系统可能已被入侵的潜在迹象的更好见解。
在数字取证中,事件之间的关系与事件本身一样重要。
取证分析师所做的大部分工作都是为了获取证据,以建立取证时间线的目标。?通过收集按时间顺序排列的事件列表,分析师可以确定攻击者活动的相关性和因果关系,证明这些事件发生的原因。
分片调查
如果你有足够的人员来同时支持多个努力(参见“并行化事件”),考虑将你的努力分成三个轨道,每个轨道负责一个重要的调查部分。例如,你的 OL 可能会将他们的临时团队分成三个小组:
-
一个取证小组调查系统并确定攻击者触及的系统。
-
一个逆向小组研究可疑的二进制文件,确定作为妥协指标(IOCs)的唯一指纹。?
-
一个狩猎小组搜索所有系统,寻找这些指纹。该组在识别嫌疑系统时随时通知取证组。
图 17-1 显示了各组之间的关系。OL 负责保持这些团队之间的紧密反馈循环。
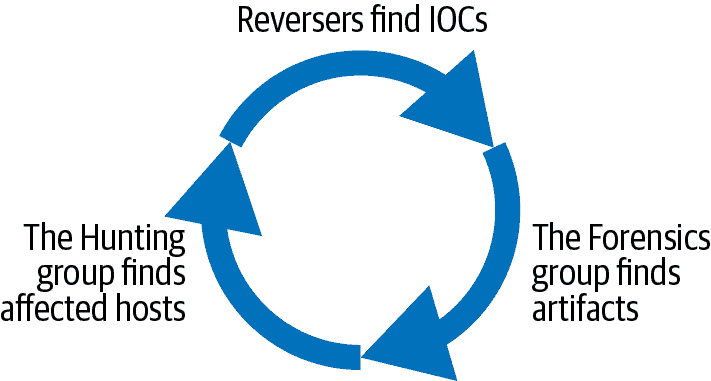
图 17-1:调查组之间的关系
最终,你发现新线索的速度会放缓。在这一点上,IC 决定是时候转向补救了。你是否已经学到了所有需要学到的东西?可能没有。但你可能已经学到了所有需要知道的东西,以成功地清除攻击者并保护他们追求的数据。确定在哪里划线可能很困难,因为涉及到所有未知因素。做出这个决定很像知道何时停止加热一袋爆米花:当爆裂之间的间隔明显增加时,你应该在整袋爆米花烧焦之前离开。在进行补救之前,需要进行大量的规划和协调。第十八章会更详细地介绍这一点。
控制事件
一旦宣布事件并分配了团队成员的责任,IC 的工作就是保持工作顺利进行。这项任务涉及预测响应团队的需求,并在问题出现之前解决这些需求。为了有效,IC 应该把所有的时间都用来控制和管理事件。如果作为 IC,你发现自己在检查日志、执行快速取证任务或以其他方式参与运营,那么是时候退后一步重新评估你的优先事项了。如果没有人掌舵,船肯定会偏离航线甚至坠毁。
并行化事件
理想情况下,经验丰富的 IR 团队可以通过将事件响应过程的所有部分分解并同时运行,尽可能地并行化事件。如果你预料到在事件生命周期中会有未分配的任务或需要的信息,就指派某人完成任务或为工作做准备。例如,你可能还没有准备好与执法部门或第三方公司分享你的取证结果,但如果你计划在将来分享你的发现,你的原始调查笔记将没有帮助。指派某人在调查进行过程中准备一个经过编辑和可共享的指标列表。
在进行取证调查的早期阶段开始准备清理环境可能看起来有些违反直觉,但如果你有可用的工作人员,那么现在是分配这项任务的好时机。IMAG 允许您随时创建自定义角色,因此您可以在事件的任何时候分配修复主管(RL)角色。RL 可以在运营团队发现受损区域时开始研究这些区域。凭借这些信息,RL 可以制定清理和修复这些受损区域的计划。当运营团队完成他们的调查时,IC 将已经制定了清理计划。在这一点上,他们可以启动下一阶段的工作,而不是当场决定下一步该怎么做。同样,如果您有可用的工作人员,现在就指定某人开始事后分析也不为时过早。
借用编程构造,大型事件中的 IC 角色看起来像是通过while循环的一组步骤:
(While the incident is still ongoing):
1\. Check with each of your leads:
a. What’s their status?
b. Have they found new information that others may need to act upon?
c. Have they hit any roadblocks?
d. Do they need more personnel or resources?
e. Are they overwhelmed?
f. Do you spot any issues that may pop up later or cause problems?
g. How’s the fatigue level of each of your leads? Of each team?
2\. Update status documents, dashboards, or other information sources.
3\. Are relevant stakeholders (executives, legal, PR, etc.) informed?
4\. Do you need any help or additional resources?
5\. Are any tasks that could be done in parallel waiting?
6\. Do you have enough information to make remediation and cleanup
decisions?
7\. How much time does the team need before they can give the next
set of updates?
8\. Is the incident over?
Loop to beginning.
OODA 循环是与事件相关的决策制定的另一个相关框架:响应者应该观察、定位、决策和行动。这是一个有用的记忆法,提醒您仔细考虑新信息,思考它如何适用于您事件的整体情况,有意识地决定行动方案,然后才采取行动。
移交
没有人能够长时间不间断地解决一个问题而不出现问题。大多数时候,我们遇到的危机需要时间来解决。在响应者之间顺利地传递工作是必不可少的,并有助于建立安全和可靠的文化(参见第二十一章)。
对抗大型森林火灾是在体力和情感上都非常具有挑战性的,可能需要数天、数周甚至数月。为了对抗这样的火灾,加利福尼亚州林业和消防局将其分为“区域”,并为每个区域指定一个事件指挥官。每个区域的 IC 都会为其区域制定长期目标和实现目标的短期目标。他们将可用资源分配到不同的班次中,这样当一组团队工作时,另一组团队就休息,并准备在第一组团队疲惫时接替他们的工作。
当灭火工作的人员接近极限时,IC 从所有团队负责人那里收集状态更新,并指定新的团队负责人来取代他们。然后,IC 向新的团队负责人简要介绍整体目标、他们的任务、他们预期完成的具体目标、可用资源、安全隐患和其他相关信息。然后,新的团队负责人和他们的工作人员接替上一班的工作人员。每位新负责人都会迅速与前任负责人沟通,以确保他们没有遗漏任何相关事实。疲惫的工作人员现在可以休息,而灭火工作可以继续进行。
安全事件响应并不像灭火那样需要体力,但您的团队会经历类似的情绪和与压力相关的疲惫。当有必要时,将工作移交给其他人是至关重要的。最终,疲惫的响应者会开始犯错误。如果团队工作了足够长的时间,他们会犯的错误会比他们纠正的错误还要多——这种现象通常被称为边际效益递减法则。员工疲劳不仅仅是善待您的团队的问题;疲劳可能会通过错误和低士气削弱您的响应。为了避免过度工作,我们建议将班次(包括 IC 班次)限制在不超过 12 小时的连续工作时间内。
如果你有大量员工并希望加快响应速度,考虑将响应团队分成两个较小的小组。这些团队可以在事件解决之前每天 24 小时进行响应。如果你没有大量员工,你可能需要接受响应速度较慢的风险,以便让员工回家休息。虽然小团队可以在“英雄模式”下工作更长时间,但这种模式是不可持续的,结果质量较低。我们建议你非常节制地使用英雄模式。
考虑一个在美洲、亚太和欧洲地区都有团队的组织。这种组织可以安排“追随太阳”轮换,以便根据时间表不断地有新的响应者参与事件,如图 17-2 所示。规模较小的组织可能会有类似的时间表,但地点更少,轮换时间更长,或者可能是一个地点,一半的运营人员在夜班工作,以保持响应,而另一半休息。
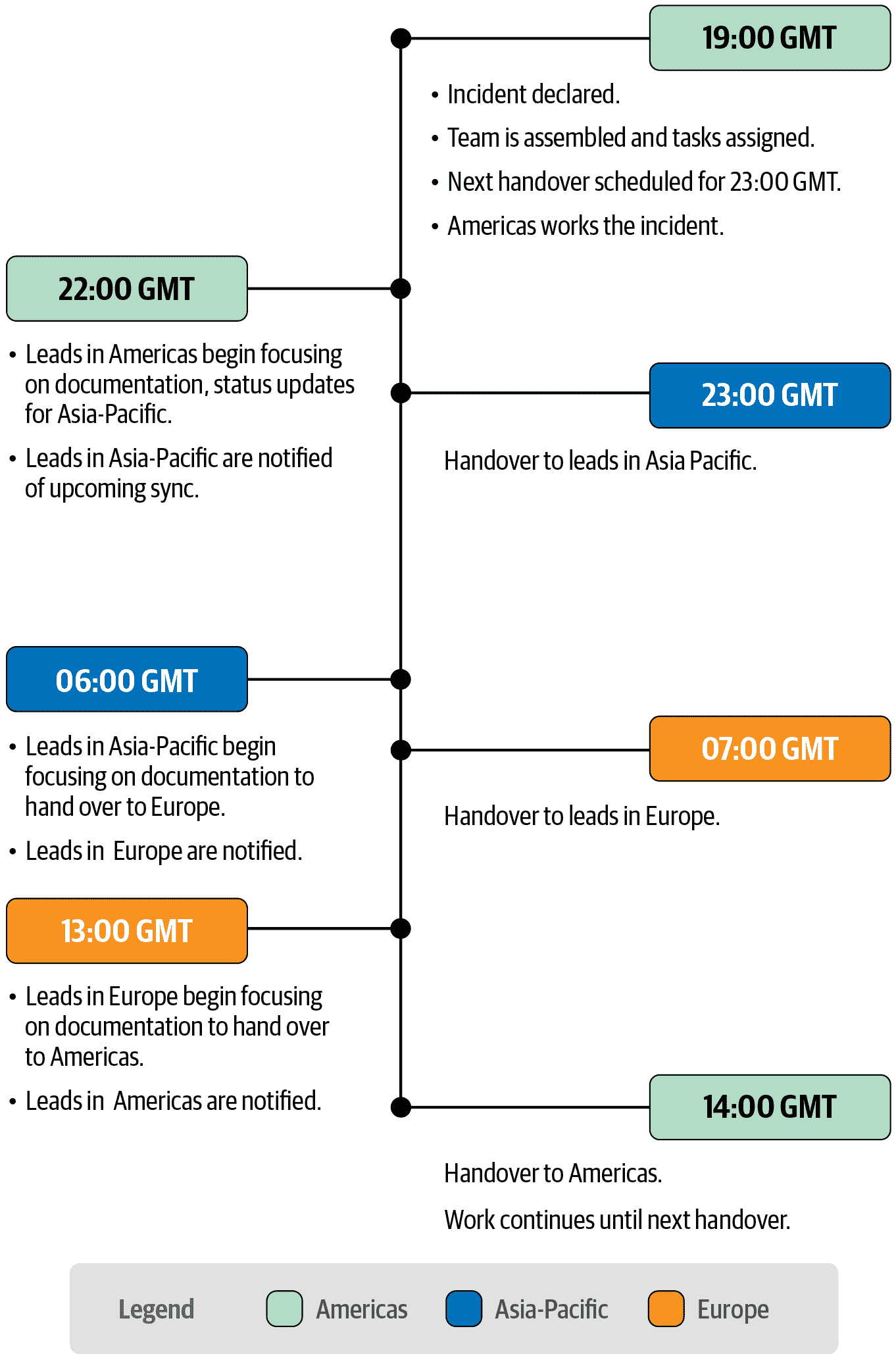
图 17-2:追随太阳轮换
IC 应该提前准备好事件交接。交接包括更新跟踪文档、证据笔记和文件,以及在班次期间保留的任何其他书面记录。提前安排好交接的物流、时间和沟通方式。会议应该以当前事件状态和调查方向的总结开始。你还应该包括每个负责人(运营、通信等)向他们对应的接替者进行正式交接。
你应该向接替团队传达的信息取决于事件。在谷歌,我们发现离任团队的 IC 问自己“如果我不是要把这个调查交给你,我接下来会花 12 小时做什么?”这个问题的答案应该在交接会议结束之前由接替团队的 IC 给出。
例如,交接会议的议程可能如下所示:
-
[离任 IC] 指派一人做笔记,最好是来自接替团队的人。
-
[离任 IC] 总结当前状态。
-
[离任 IC] 概述如果他们没有交接事件,接下来 12 小时 IC 会做的任务。
-
[所有与会者] 讨论这个问题。
-
[接替 IC] 概述你预期在接下来的 12 小时内处理的任务。
-
[接替 IC] 确定下次会议的时间。
士气
在任何重大事件中,指挥官需要保持团队士气。这个责任经常被忽视,但是至关重要。事件可能会带来压力,每个工程师对这些高压情况的反应都会不同。有些人会迎接挑战并积极参与,而其他人会发现高强度的努力和模糊不清的情况让他们深感沮丧,他们最想做的就是离开事件现场回家。
作为 IC,不要忘记激励、鼓励和跟踪团队的整体情绪状态是实现积极事件结果的关键因素。以下是在危机中保持士气的一些建议:
吃饭
当你的响应团队努力取得进展时,饥饿势必会袭来。这会降低团队的效率,可能会让人们感到不安。提前计划休息时间和尽可能带来食物。这有助于在需要时保持团队的愉快和专注。
睡觉
人类也适用边际效益递减法则。随着疲惫的产生,您的员工在时间推移中会变得不那么有效,每个成员都会超过自己的疲劳极限点。在这一点之后,继续工作可能会导致更多的错误而不是进展,使事件响应倒退。密切关注响应者的疲劳情况,并确保他们在需要时有休息时间。领导者甚至可能需要介入,以确保那些没有意识到自己需要休息的人也能休息。
减压
当机会出现时,例如,如果团队正在等待文件阵列完成重建,无法同时取得进展,可以让大家一起进行减压活动。几年前,在谷歌发生一起特别大规模且持续时间较长的事件时,响应团队花了一个小时的时间用锤子和液氮粉碎了一个损坏的硬盘。多年后,参与其中的团队回忆起这个活动作为响应的一个亮点。
观察倦怠
作为一名 IC,您应该积极观察团队(包括自己)是否出现倦怠的迹象。一名关键工程师是否开始变得更加愤世嫉俗?员工是否表达了对挑战无法克服的恐惧?这可能是他们第一次处理重大事件,他们可能有很多恐惧。与他们坦诚交谈,并确保他们理解您的期望以及他们如何满足这些期望。如果团队成员需要休息,而您有人可以替代他们,可以提供休息时间。
以身作则
领导者公开表达的现实但积极的展望对于设定团队对成功的期望是非常有帮助的。这种展望鼓励团队,并让他们觉得他们可以实现目标。此外,响应团队的成员可能怀疑是否真的鼓励自我关怀(例如,充分进食和睡眠),直到他们看到 IC 或 OL 公开这样做作为最佳实践。
沟通
在事件响应中涉及的所有技术问题中,沟通仍然是最具挑战性的。即使在最好的情况下,与同事和团队之外的其他人进行有效的沟通也可能很困难。在受到压力、紧迫的截止日期和安全事件的高风险的情况下,这些困难可能会加剧,并迅速导致延迟或错过响应。以下是您可能遇到的一些主要沟通挑战,以及管理它们的建议。
注意
许多优秀的书籍都全面涵盖了沟通主题。为了更深入地了解沟通,我们推荐尼克·摩根的《你能听到我吗?》(哈佛商业评论出版社,2018 年)和艾伦·奥尔达的《如果我理解了你,我会有这种表情吗?》(兰登书屋,2017 年)。
误解
响应者之间的误解很可能构成您沟通问题的主要部分。习惯一起工作的人可能会对未说出的事情做出假设。不习惯一起工作的人可能会使用陌生的行话、不同团队之间意义不同的首字母缩略词,或者假设一个实际上并不普遍的共同参照系。
例如,拿短语“当攻击得到缓解时,我们可以重新启动服务。”来说。对产品团队来说,这可能意味着一旦攻击者的工具被删除,系统就可以安全使用。对安全团队来说,这可能意味着在进行完整调查并得出结论表明攻击者不再能存在于环境中,或者返回环境之前,系统才能安全使用。
当您发现自己在处理事件时,作为一个经验法则,始终明确和过度沟通是有帮助的。解释当您要求某事或设定期望时,即使您认为对方应该知道您的意思。在前面段落的例子中,即使您认为对方应该知道您的意思,也不妨说一下,“当我们确信所有回路都已修复,并且攻击者不再能够访问我们的系统时,我们可以重新启动服务。”请记住,沟通的责任通常属于沟通者——只有他们才能确保他们正在与之沟通的人收到预期的信息。
避免性语言
避免在紧张局势下表达确定性的另一个常见沟通错误是使用避免性语言。当人们在紧张的情况下被期望给出建议,但又没有信心时,他们往往倾向于在陈述中加入限定词。在不确定的情况下避免表达确定性,比如说“我们相当确定找到了所有的恶意软件”,可能会让人感到更安全,但避免性语言往往会使情况变得模糊,并导致决策者的不确定性。再次强调,明确和过度沟通是最好的解决办法。如果您的 IC 问您是否已经确定了所有攻击者的工具,“我们相当确定”是一个含糊的回答。最好的回答是,“我们对我们的服务器、NAS、电子邮件和文件共享感到肯定,但对我们的托管系统不太有信心,因为我们在那里的日志可见性较低。”
会议
要在事件中取得进展,您需要让人们一起协调他们的努力。与事件响应中的关键参与者进行定期、快速的同步会议是一种特别有效的方式,可以保持对正在发生的一切的控制和可见性。IC、OL、公司律师和一些关键高管可能每两到四个小时开一次会,以确保团队能够迅速适应任何新的发展。
我们建议严格限制这些会议的与会者。如果您的会议室或视频会议室里挤满了人,而只有少数人在发言,其他人在听或查看电子邮件,那么您的邀请名单就太长了。理想情况下,事件负责人应该参加这些会议,而其他人则应该完成需要完成的任务。会议结束后,负责人可以更新各自的团队。
虽然会议通常是共同工作的必要部分,但管理不当的会议会危及您的进展。我们强烈建议 IC 在每次会议开始时都提前制定一个议程。这可能看起来是一个显而易见的步骤,但在持续事件的肾上腺素飙升和压力下很容易忘记。以下是谷歌在安全事件启动会议上使用的一个示例议程:
-
【IC】委派一人做笔记。
-
【IC】所有与会者介绍自己,从 IC 开始:
-
名称
-
团队
-
角色
-
【IC】参与规则:
-
您是否需要考虑保密性?
-
是否有特定的操作安全问题需要考虑?
-
谁负责做决定?谁应该参与决策过程?谁不应该参与?
-
让您的负责人知道您是否在切换任务/完成某事。
-
【IC】描述当前状态:我们正在解决什么问题?
-
【所有人】讨论问题。
-
【IC】总结行动和责任人。
-
【IC】询问小组:
-
我们是否需要任何其他资源?
-
我们需要牵涉其他任何团队吗?
-
有什么障碍吗?
-
【IC】确定下次同步会议的时间和预期出席人员:
-
谁是必需的?
-
谁是可选的?
以下是进行中的同步会议:
-
【IC】委派一人做笔记。
-
【IC 或运营主管】总结当前状态。
-
【IC】从每个与会者/活动线程接收更新。
-
【IC】讨论下一步。
-
【运营主管】分配任务,并让每个人重复他们认为自己要做的事情。
-
【IC】确定下次会议的时间。
-
【运营主管】更新行动追踪器。
在两个示例议程中,IC 指定了一名记录员。通过经验,我们已经了解到,记录员对于保持调查的顺利进行至关重要。负责人忙于处理会议中出现的所有问题,没有精力来做好记录。在事件发生时,你经常会忘记你认为自己会记住的事项。这些记录在撰写事后总结时也变得非常宝贵。请记住,如果事件涉及任何法律后果,您将希望就最佳管理此信息的方式与您的法律团队进行咨询。
向正确的人员提供正确细节水平的信息
确定传达的正确细节水平是事件沟通的一个重大挑战。多个层次的多个人员将需要了解与事件相关的某些内容,但出于操作安全的原因,他们可能不能或不应该知道所有细节。请注意,对事件只有模糊了解的员工可能会进行填补信息的行为。员工之间的谣言很快就会在组织外传播时变得错误和有害。
长期进行的调查可能需要向以下人员提供不同细节水平的频繁更新:
高管和高级领导
他们应该收到关于进展、障碍和潜在后果的简短、简洁的更新。
IR 团队
这个团队需要关于调查的最新信息。
未参与事件的组织人员
您的组织可能需要决定告知人员的内容。如果您告知所有员工有关事件,您可能能够请求他们的帮助。另一方面,这些人可能会传播您意料之外的信息。如果您不告知组织人员有关事件,但他们无论如何发现了,您可能需要处理谣言。
客户
客户可能有法律上的权利在一定时间内被告知事件,或者您的组织可能选择自愿通知他们。如果响应涉及关闭对客户可见的服务,他们可能会有问题并要求答案。
法律/司法系统参与者
如果您将事件升级给执法部门,他们可能会有问题,并且可能开始要求您最初没有打算分享的信息。
为了帮助管理所有这些需求,而不会不断分散 IC 的注意力,我们建议任命一名沟通负责人(CL)。CL 的核心工作是随着事件的发展保持对事件的了解,并向相关利益相关者准备沟通。CL 的主要责任包括以下内容:
-
与销售、支持和其他内部合作伙伴团队合作,回答他们可能有的任何问题。
-
为高管、法律人员、监管机构和其他监督角色准备简报。
-
与新闻和公关合作,确保人们在必要时获得准确和及时的关于事件的陈述。确保响应团队之外的人员不发表相互矛盾的声明。
-
对事件信息的传播保持持续和谨慎的关注,以便事件人员遵守任何“需要知道”的准则。
CL 将希望考虑与领域专家、外部危机沟通顾问或其他需要帮助管理与事件相关信息的人联系,以最小化延迟。
将所有内容整合在一起
本节通过演示一个任何规模的组织可能遇到的妥协情况,将本章内容联系在一起。考虑这样一个情景,一个工程师发现一个他不认识的服务账户被添加到一个他以前没有见过的云项目中。中午,他将自己的担忧上升到了安全团队。经过初步调查,安全团队确定一个工程师的账户很可能已经被入侵。使用之前提出的建议和最佳实践,让我们从头到尾走一遍你可能如何应对这样的妥协。
分类
你响应的第一步是分类。从最坏的情况假设开始:安全团队的怀疑是正确的,工程师的账户被入侵了。使用特权访问查看敏感的内部信息和/或用户数据的攻击者将是一个严重的安全漏洞,因此你宣布了一起事件。
宣布事件
作为事件指挥官,你通知安全团队其他成员:
-
发生了一起事件。
-
你将承担 IC 的角色。
-
你需要团队的额外支持来进行调查。
通信和运营安全
既然你已经宣布了事件,组织中的其他人——高管、法律部门等——需要知道事件正在进行中。如果攻击者入侵了你组织的基础设施,给这些人发邮件或聊天可能是有风险的。遵循运营安全的最佳实践。假设你的应急计划要求使用组织信用卡在与你组织无关的云环境中注册一个商业账户,并为每个参与事件的人创建账户。为了创建和连接到这个环境,你使用了与你组织的管理基础设施没有连接的全新重建的笔记本电脑。
使用这个新环境,你给你的高管和关键的法律人员打电话,告诉他们如何获得安全的笔记本电脑和云账户,以便他们可以通过电子邮件和聊天参与。由于所有当前的应对人员都在办公室附近,你使用附近的会议室讨论事件的细节。
开始事件
作为 IC,你需要指派工程师进行调查,所以你要求安全团队中具有取证经验的工程师担任运营主管。你的新 OL 立即开始他们的取证调查,并根据需要招募其他工程师。他们首先从云环境中收集日志,重点关注服务账户凭证被添加的时间段。在确认凭证是在工程师离开办公室的时间段内由工程师的账户添加后,取证团队得出结论,该账户已被入侵。
取证团队现在从仅调查嫌疑账户转变为调查账户被添加时周围的所有其他活动。团队决定收集与被入侵账户相关的所有系统日志,以及工程师的笔记本电脑和工作站。团队确定这项调查可能需要一个分析师相当长的时间,因此他们决定增加更多的人手并分配工作。
你的组织没有一个庞大的安全团队,因此没有足够的熟练的取证分析师来充分分配取证任务。然而,你有了解他们系统的系统管理员,并且可以帮助分析日志。你决定将这些系统管理员分配给取证团队。你的 OL 通过电子邮件联系他们,要求通过电话讨论“一些事情”,并在通话中全面介绍情况。OL 要求系统管理员从组织中的任何系统收集与被入侵账户相关的所有日志,而取证团队则分析笔记本电脑和台式机。
到了下午 5 点,很明显调查将比你的团队能够继续工作的时间长得多。作为 IC,你正确地预计到你的团队在解决事件之前会变得疲惫并开始犯错误,因此你需要制定一个交接或连续性计划。你通知你的团队,他们有四个小时的时间来完成尽可能多的日志和主机分析。在此期间,你保持与领导和法律部门的最新信息,并与 OL 联系,看看他们的团队是否需要额外的帮助。
在晚上 9 点的团队同步会议上,OL 透露他们的团队已经找到了攻击者的初始入口点:一封非常精心制作的钓鱼邮件发送给工程师,工程师被骗以运行一个命令,下载了攻击者的后门并建立了持久的远程连接。
交接
到了晚上 9 点的团队同步会议,许多解决问题的工程师已经工作了 12 个小时甚至更长时间。作为一名勤勉的 IC,你知道继续以这样的速度工作是有风险的,而且这个事件将需要更多的努力。你决定交接一些工作。虽然你的组织在旧金山总部之外没有一个完整的安全团队,但在伦敦有一些资深员工。
你告诉你的团队用接下来的一个小时来完成他们的发现文档,同时你联系伦敦团队。伦敦办公室的一名资深工程师被任命为下一任 IC。作为即将离任的 IC,你向接替的 IC 简要介绍了你迄今为止学到的一切。在获得所有与事件相关的文件的所有权并确保伦敦团队了解下一步之后,伦敦 IC 确认他们将负责直到第二天早上 9 点 PST。旧金山团队松了一口气,回家休息。在夜间,伦敦团队继续调查,重点是分析攻击者执行的后门脚本和行动。
交接事件
第二天早上 9 点,旧金山和伦敦团队进行交接同步。在夜间,伦敦团队取得了很多进展。他们确定受损工作站上运行的脚本安装了一个简单的后门,使攻击者能够从远程机器登录并开始查看系统。注意到工程师的 shell 历史记录包括登录到云服务账户,对手利用了保存的凭据,并将自己的服务账户密钥添加到管理令牌列表中。
在这样做之后,他们没有对工作站采取进一步行动。相反,云服务日志显示,攻击者直接与服务 API 进行了交互。他们上传了一个新的机器镜像,并在新的云项目中启动了数十个该虚拟机的副本。伦敦团队尚未分析任何正在运行的镜像,但他们审计了所有现有项目中的凭据,并确认他们所知道的恶意服务账户和 API 令牌是唯一无法验证为合法的凭据。
得到伦敦团队的更新后,你确认了新的信息,并确认自己将接任 IC 的职责。接下来,你提炼新的信息,并向高管和法律部门提供简明扼要的更新。你还向团队介绍了新的发现。
尽管你知道攻击者对生产服务拥有管理访问权限,但你还不知道用户数据是否存在风险或受到影响。你给你的取证团队一个新的高优先级任务:查看攻击者可能对现有生产机器采取的所有其他行动。
准备沟通和纠正
随着调查的进行,你决定是时候将事件响应的一些组件并行化。如果攻击者可能访问了你组织的用户数据,你可能需要通知用户。你还需要减轻攻击。你选择了一位技术写作能力强的同事担任沟通负责人(CL)。你要求一位不参与取证工作的系统管理员成为整改负责人(RL)。
与组织的律师合作,CL 起草了一篇博客文章,解释了发生了什么以及潜在的客户影响。尽管还有许多空白(比如“<填写此处>数据被<填写此处>”),但提前准备好并获得批准的结构可以帮助你在了解全部细节时更快地传达你的信息。
与此同时,RL 制定了组织已知受攻击者影响的每一项资源清单,以及清理每个资源的方案。即使你知道工程师的密码并没有在最初的钓鱼邮件中泄露,你也需要更改他们的账户凭据。为了安全起见,你决定防范尚未发现但可能随后出现的后门。你复制了工程师的重要数据,然后擦除了他们的主目录,在新安装的工作站上创建了一个新的主目录。
随着你的应对工作的进行,你的团队得知攻击者并没有访问任何生产数据,这让大家都松了一口气!攻击者启动的额外虚拟机似乎是一群挖矿服务器,用于挖掘数字货币并将资金转入攻击者的虚拟钱包。你的 RL 指出,你可以删除这些机器,或者如果你希望以后向执法部门报告事件,也可以对这些机器进行快照和归档。你还可以删除创建这些机器的项目。
结束
到了下午中期,你的团队已经没有了线索。他们搜索了可能受到恶意 API 密钥影响的每一个资源,制定了减轻方案,并确认攻击者没有触及任何敏感数据。幸运的是,这只是一次机会主义的挖矿行为,攻击者并不关心你的任何数据,只是想在别人的账单上使用大量计算能力。你的团队决定是时候执行你的整改计划了。在与法律和领导层核实关闭事件决定得到他们的批准后,你向团队发出了行动的信号。
完成了取证任务后,运营团队现在根据整改计划分配任务,并尽快完成,确保攻击者被迅速而彻底地关闭。然后,他们花了下午的时间写下他们的观察结果以供事后分析。最后,你(IC)进行了简报,团队中的每个人都有机会讨论事件的进展。你明确地传达了事件已经结束,不再需要紧急响应。在每个人回家休息之前,你最后的任务是向伦敦团队简报,让他们也知道事件已经结束。
解决方案
-
事故管理在规模化时,成为一门独立的艺术,与一般项目管理和较小的事故响应工作有所不同。通过专注于流程、工具和适当的组织结构,可以组建一个能够以当今市场所需的速度有效应对任何危机的团队。无论您是一个小型组织,其工程师和核心团队根据需要成为临时响应团队,还是一个全球范围内设有响应团队的大型组织,或者介于两者之间,您都可以应用本章描述的最佳实践,有效高效地应对安全威胁。并行化您的事故响应和取证工作,并使用 ICS/IMAG 专业管理团队,将帮助您可扩展、可靠地应对任何突发事件。
-
例如,参见 Google 的透明报告。
-
在 Google 的设计审查中,一位工程师建议说:“有两种软件开发人员:那些对 Ghostscript 进行了沙箱隔离的人,和那些本应该对 Ghostscript 进行沙箱隔离的人。”
-
Shellshock 是一个远程利用漏洞,非常简单易部署,以至于在发布几天后,数百万台服务器已经受到积极攻击。
-
这种紧密的工作循环在步骤之间有最小的延迟,以至于没有人因为等待别人完成他们的部分而无法完成自己的部分。
-
反向工程时间轴是系统上发生的所有事件的列表,理想情况下是以与调查相关的事件为中心,按事件发生的时间顺序排列。
-
恶意软件逆向工程是相当专业的工作,并不是所有组织都有熟练掌握这种实践的人员。
-
如果一个人没有接触到实际信息,他们往往会编造一些东西。
第十八章:恢复和事后
译者:飞龙
由 Alex Perry,Gary O’Connor 和 Heather Adkins
与 Nick Soda
如果您的组织遭遇严重事件,您会知道如何恢复吗?谁来执行恢复,他们知道要做出什么决定吗? SRE 书的第十七章和 SRE 工作手册的第九章讨论了预防和管理服务中断的做法。这些做法中的许多做法也与安全相关,但是从安全攻击中恢复具有独特的元素,特别是当事件涉及主动恶意攻击者时(参见第二章)。因此,虽然本章提供了处理许多种恢复工作的一般概述,但我们特别强调恢复工程师需要了解有关安全攻击的内容。
正如我们在第八章和第九章中讨论的,根据良好设计原则构建的系统可以抵御攻击并且易于恢复。无论系统是单个计算实例、分布式系统还是复杂的多层应用程序,都是如此。为了促进恢复,良好构建的系统还必须与危机管理策略相结合。如前一章所述,有效的危机管理需要在继续威慑攻击者的同时恢复任何受损资产到已知(可能改进的)良好状态之间取得微妙的平衡。本章描述了良好的恢复检查表所包含的微妙考虑,以实现这些目标。
根据我们的经验,恢复工程师通常是每天设计、实现和维护这些系统的人。在攻击期间,您可能需要召集安全专家担任特定角色,例如执行取证活动、对安全漏洞进行分类或做出微妙的决定,但将系统恢复到已知良好状态需要来自每天与系统一起工作的专业知识。事件协调和恢复工作之间的合作允许安全专家和恢复工程师双向共享信息以恢复系统。
从安全攻击中恢复往往涉及比预先计划的 playbooks 能够适应的更模糊的环境。攻击者可以在攻击过程中改变他们的行为,恢复工程师可能会犯错或发现关于他们的系统的意外特征或细节。本章介绍了一种动态的恢复方法,旨在匹配您的攻击者的灵活性。
恢复行为也可以成为推动改进安全姿态的强大工具。恢复采取短期战术缓解和长期战略改进的形式。我们在本章中介绍了一些思考安全事件、恢复和下一个事件之间的静默期之间的连续性的方式。
恢复物流
如前一章所讨论的,良好管理的事件受益于并行化响应。并行化在恢复过程中尤其有益。参与恢复工作的人员应与调查事件的人员不同,原因有几个:
-
事件的调查阶段通常是耗时且详细的,需要长时间的专注。在持续的事件中,调查团队通常需要休息,而恢复工作开始时。
-
事件的恢复阶段可能在您的调查仍在进行中开始。因此,您需要能够并行工作的独立团队,彼此之间提供信息。
-
进行调查所需的技能可能与进行恢复工作所需的技能不同。
在准备恢复并考虑您的选择时,您应该建立一个正式的团队结构。根据事件的范围,这个团队可以小到一个人,也可以大到整个组织。对于更复杂的事件,我们建议创建协调机制,如正式团队、频繁会议、共享文档存储库和同行评审。许多组织通过使用冲刺、Scrum 团队和紧密的反馈循环,将恢复团队的运作模式建模在其现有的敏捷开发流程上。
从复杂事件中组织良好的恢复可能看起来像精心编排的芭蕾舞表演,不同个体在恢复过程中的行动相互影响。重要的是,恢复芭蕾中的舞者们要避免踩到彼此的脚。因此,您应该明确定义准备、审查和执行恢复的角色,确保每个人都了解操作风险,并且参与者经常进行面对面的沟通。
随着事件的进展,事件指挥官(IC)和运营负责人(OL)应任命一名纠正负责人(RL)开始规划恢复,如第十七章所述。RL 应与 IC 密切协调,制定恢复检查表,以确保恢复工作与调查的其他部分保持一致。RL 还负责组建具有相关专业知识的团队,并制定恢复检查表(在“恢复检查表”中讨论)。
在谷歌,执行恢复的团队是日常构建和运行系统的团队。这些人包括 SRE、开发人员、系统管理员、帮助台人员和管理常规流程(如代码审计和配置审查)的相关安全专家。
信息管理和沟通在恢复过程中是成功响应的重要组成部分。原始事件轨迹、草稿笔记、恢复检查表、新的操作文档以及有关攻击本身的信息将是重要的文档。确保这些文档对恢复团队可用,但对攻击者不可用;使用类似空气隔离的计算机进行存储。例如,您可以使用诸如 bug 跟踪系统、基于云的协作工具、白板,甚至贴在墙上的便签卡等信息管理工具的组合。确保这些工具不在攻击者可能威胁到您系统的最广泛范围之内。考虑从便签卡开始,并在确保没有恢复团队成员的机器受到威胁后添加独立的服务提供商。
良好的信息管理是确保顺利恢复的另一个关键方面。使用每个人都可以访问并实时更新的资源,以便在问题出现或检查表项完成时进行更新。如果您的恢复计划只能由您的纠正负责人访问,这将成为快速执行的障碍。
在恢复系统的同时,保持关于恢复过程中发生的事情的可靠记录也很重要。如果您在途中犯了错误,您的审计轨迹将帮助您解决任何问题。指定专门的记录员或文档专家可能是一个好主意。在谷歌,我们利用技术撰稿人来优化我们的恢复工作中的信息管理。我们建议阅读第二十一章,其中讨论了更多的组织方面。
恢复时间表
开始恢复阶段的最佳时间因调查性质而异。如果受影响的基础设施至关重要,您可能会选择几乎立即从攻击中恢复过来。这在从拒绝服务攻击中恢复时经常发生。另外,如果您的事件涉及攻击者完全控制您的基础设施,您可能会几乎立即开始规划恢复,但只有在完全了解攻击者所做的事情后才执行计划。本章讨论的恢复流程适用于任何恢复时间线:在调查仍在进行时,调查阶段结束后,或者在这两个阶段都进行时。
对事件的足够了解和了解恢复范围将决定采取哪种路线。通常,在启动恢复操作时,调查团队已经开始了事后分析文档(可能是初步原始笔记的形式),恢复团队在进行过程中更新。该文档中的信息将指导恢复团队的规划阶段(参见“规划恢复”),这应该在启动恢复之前完成(参见“启动恢复”)。
由于最初的计划可能随着时间而发展,规划和执行恢复可能会重叠。但是,您不应该在没有某种计划的情况下开始恢复工作。同样,我们建议在进行恢复之前创建恢复检查表。恢复工作完成后,您的恢复后行动(参见“恢复后”)应该尽快开始。在这两个阶段之间允许时间过长可能会导致您忘记先前行动的细节,或者推迟必要的中长期修复工作。
规划恢复
您的恢复工作的目标是减轻攻击并使系统恢复到正常运行状态,并在此过程中应用任何必要的改进。复杂的安全事件通常需要并行化事件管理,并设置结构化团队来执行事件的不同部分。
恢复规划过程将依赖调查团队发现的信息,重要的是在采取行动之前仔细规划恢复。在这些情况下,一旦您对攻击者所做的事情有足够的基线信息,您应该立即开始规划恢复。以下各节描述了一些准备最佳实践和常见陷阱。
确定恢复范围
您如何定义事件的恢复将取决于您遇到的攻击类型。例如,从单个机器上的勒索软件等较小问题中恢复可能相对简单:您只需重新安装系统。然而,要从在整个网络上存在的国家行为者以及窃取敏感数据的攻击者那里恢复,您将需要来自组织各个部门的多种恢复策略和技能。请记住,恢复所需的工作量可能与攻击的严重程度或复杂性不成比例。一家对简单勒索软件攻击毫无准备的组织可能最终会有许多受损的机器,并需要进行资源密集型的恢复工作。
要从安全事件中启动恢复,您的恢复团队需要完整的系统、网络和数据受到攻击的清单。他们还需要足够的关于攻击者战术、技术和程序(TTPs)的信息,以识别可能受到影响的任何相关资源。例如,如果您的恢复团队发现配置分发系统已被入侵,那么这个系统就在恢复范围内。从这个系统接收配置的任何系统也可能在范围内。因此,调查团队需要确定攻击者是否修改了任何配置,以及这些配置是否被推送到其他系统。
正如在第十七章中提到的,理想情况下,指挥官会指派某人在调查早期为缓解文档维护行动项目(在“事后检讨”中讨论)。缓解文档和随后的事后检讨将确定解决妥协根本原因的步骤。您需要足够的信息来优先处理行动项目,并将其分类为短期缓解措施(如修补已知漏洞)或战略性的长期变更(如更改构建流程以防止使用易受攻击的库)。
为了了解如何在未来保护这些资产,您应该检查每个直接或间接受到影响的资产,以及攻击者的行为。例如,如果攻击者能够利用 Web 服务器上的一个易受攻击的软件堆栈,您的恢复将需要了解攻击的方式,以便您可以修补运行该软件包的任何其他系统中的漏洞。同样,如果攻击者通过钓鱼用户的帐户凭据获得访问权限,您的恢复团队需要计划如何阻止另一个攻击者明天做同样的事情。请注意了解攻击者可能能够利用哪些资产进行未来的攻击。您可以考虑制作攻击者的行为和恢复工作的可能防御措施清单,就像我们在第二章中所做的那样(参见表 2-3)。您可以将此清单用作操作文档,以解释为什么要引入某些新的防御措施。
汇总受损资产和短期缓解措施的清单需要进行紧密的沟通和反馈循环,涉及您的事后笔记、调查团队和事件指挥官。您的恢复团队需要尽快了解新的调查发现。如果调查和恢复团队之间的信息交换不高效,攻击者可以绕过缓解措施。您的恢复计划还应该考虑到您的攻击者可能仍然存在并观察您的行动。
深入探讨:恢复考虑
在设计事件的恢复阶段时,您可能会遇到一些难以回答的开放性问题。本节涵盖了一些常见的陷阱和关于如何平衡权衡的想法。这些原则对于经常处理复杂事件的安全专家来说会感到熟悉,但这些信息对于参与恢复工作的任何人都是相关的。在做出决定之前,请问自己以下问题。
您的攻击者将如何回应您的恢复工作?
您的缓解和恢复清单(参见“恢复清单”和“示例”)将包括切断攻击者与您资源的任何连接,并确保他们无法返回。实现这一步骤需要进行微妙的平衡,需要对攻击有近乎完美的了解,并制定一个执行驱逐的坚实计划。一个错误可能导致攻击者采取您未能预料或看到的额外行动。
考虑这个例子:在事件中,您的调查团队发现攻击者已经妥协了六个系统,但团队无法确定最初的攻击是如何开始的。甚至不清楚您的攻击者是如何首次访问您的系统的。您的恢复团队制定并执行了一个重建这六个受损系统的计划。在这种情况下,恢复团队在没有完全了解攻击是如何开始、攻击者将如何回应,或者攻击者是否仍在其他系统上活动的情况下行动。仍在活动中的攻击者将能够从其在另一个受损系统中的位置看到您已经将这六个系统下线,并可能继续破坏其余可访问的基础设施。
除了损害您的系统外,攻击者还可以窃听电子邮件、错误跟踪系统、代码更改、日历和其他资源,这些资源您可能希望用来协调您的恢复。根据事件的严重程度和您正在恢复的妥协类型,您可能希望使用对攻击者不可见的系统进行调查和恢复。
考虑一个协调使用即时消息系统的恢复团队,而其中一个团队成员的帐户已被攻击。攻击者也登录并观看聊天,可以在恢复过程中看到所有私人通信 - 包括调查的任何已知元素。攻击者甚至可能推断出恢复团队不知道的信息。您的攻击者可能利用这些知识以不同的方式妥协更多系统,绕过调查团队可能具有的所有可见性。在这种情况下,恢复团队应该建立一个新的即时消息系统,并部署新的机器 - 例如,廉价的 Chromebook - 用于响应者通信。
这些例子可能看起来很极端,但它们阐明了一个非常简单的观点:在攻击的另一侧有一个人在对您的事件响应做出反应。您的恢复计划应考虑在了解攻击者的访问权限并采取行动以最小化进一步危害的风险。
注意
今天,安全事件响应者普遍认为,在驱逐攻击者之前,您应该等到对攻击有全面的了解。这可以防止攻击者观察您的缓解措施,并帮助您进行防御性响应。
尽管这是一个好建议,但要谨慎应用。如果您的攻击者已经在做一些危险的事情(例如获取敏感数据或破坏系统),您可能会选择在完全了解他们的行动之前采取行动。如果您选择在完全了解攻击者的意图和攻击范围之前驱逐攻击者,那么您就进入了一场国际象棋游戏。做好准备,并知道您需要采取的步骤以达到将军!
如果您正在处理复杂的事件,或者有活跃的攻击者正在与您的系统交互,您的恢复计划应包括与调查团队的紧密整合,以确保攻击者无法重新访问您的系统或绕过您的缓解措施。确保告知调查团队您的恢复计划 - 他们应该确信您的计划将阻止攻击。
您的恢复基础设施或工具是否受到妥协?
在恢复计划的早期阶段,确定您需要进行响应的基础设施和工具,并询问调查团队他们是否认为这些恢复系统已被妥协。他们的答案将决定您是否可以进行安全的恢复,以及您可能需要为更完整的响应做准备的额外补救步骤。
例如,假设攻击者已经入侵了您网络上的几台笔记本电脑和管理它们设置的配置服务器。在这种情况下,您需要在重建任何受损的笔记本电脑之前为配置服务器制定一个补救计划。同样,如果攻击者已经在您的自定义备份恢复工具中引入了恶意代码,您需要找到他们的更改并将代码恢复到正常状态,然后再恢复任何数据。
更重要的是,您必须考虑如何恢复资产——无论是位于目前受攻击者控制的基础设施上的系统、应用程序、网络还是数据。在攻击者控制基础设施的情况下恢复资产可能会导致同一攻击者再次威胁。在这种情况下的常见恢复模式是建立一个“干净”或“安全”的资产版本,例如一个与任何受损版本隔离的干净网络或系统。这可能意味着完全复制整个基础设施,或者至少是其中的关键部分。
回到我们的一个受损配置服务器的例子,您可以选择创建一个隔离网络,并使用全新的操作系统安装重建这个系统。然后您可以手动配置系统,以便您可以从中引导新的机器,而不会引入任何受攻击者控制的配置。
攻击的变体有哪些?
假设您的调查团队报告说,攻击者利用了缓冲区溢出漏洞来攻击您的网络服务基础设施。虽然攻击者只能访问一个系统,但您知道其他 20 台服务器也在运行相同有缺陷的软件。在规划恢复过程时,您应该处理已知受损的系统,但还要考虑另外两个因素:其他 20 台服务器是否也受到攻击,以及您将如何在将来减轻所有这些机器的漏洞影响。
同样值得考虑的是,您的系统是否(在短期内)容易受到您当前经历的攻击类型的变体的影响。在缓冲区溢出的例子中,您的恢复规划应该寻找基础设施中任何相关的软件漏洞——无论是相关的漏洞类别,还是另一个软件中相同的漏洞。这一考虑在自定义代码或使用共享库的情况下尤为重要。我们在第十三章中介绍了几种测试变体的选项,比如模糊测试。
如果您使用的是开源或商业软件,并且测试变体超出了您的控制范围,希望维护软件的人已经考虑了可能的攻击变体并实现了必要的保护措施。值得检查软件堆栈其他部分的可用补丁,并将广泛的升级作为恢复的一部分。
您的恢复是否会重新引入攻击向量?
许多恢复方法旨在将受影响的资源恢复到已知的良好状态。这一努力可能依赖于系统镜像、存储在代码库中的源代码或配置。您恢复的一个关键考虑因素应该是您的恢复操作是否会重新引入使系统容易受攻击的攻击向量,或者是否会使您已经取得的耐久性或安全性进展倒退。考虑一个包含有漏洞软件的系统镜像,允许攻击者威胁系统。如果您在恢复过程中重用这个系统镜像,您将重新引入有漏洞的软件。
这种漏洞重新引入是许多环境中的常见陷阱,包括依赖于通常由整个系统快照组成的“黄金镜像”的现代云计算和内部环境。在系统重新上线之前,重要的是更新这些黄金镜像并删除受损的快照,无论是在源头还是安装后立即进行。
如果攻击者能够修改您的恢复基础设施的部分内容(例如,存储在源代码仓库中的配置),并且您使用这些受损的设置恢复系统,那么您将通过保留攻击者的更改来使恢复倒退。将系统恢复到良好状态可能需要很长时间,以避免这种倒退。这也意味着您需要仔细考虑攻击时间轴:攻击者何时进行了修改,您需要回溯多久来撤销他们的更改?如果无法确定攻击者进行修改的确切时间,您可能需要并行从头开始重建基础设施的大部分。
注
在从传统备份(如磁带备份)中恢复系统或数据时,您应该考虑您的系统是否也备份了攻击者的修改。您应该销毁或隔离包含攻击者证据的任何备份或数据快照,以供以后分析。
您有哪些缓解选择?
在系统中遵循弹性设计的良好实践(参见第九章)可以帮助您快速从安全事件中恢复。如果您的服务是分布式系统(而不是单片二进制),您可以相对快速、容易地对各个模块应用安全修复:您可以对有缺陷的模块执行“就地”更新,而不会对周围的模块引入重大风险。同样,在云计算环境中,您可以建立机制来关闭受损的容器或虚拟机,并迅速用已知良好的版本替换它们。
然而,根据攻击者已经妥协的资产(如机器、打印机、摄像头、数据和账户),您可能会发现自己只剩下一些不太理想的缓解选择。您可能需要决定哪个选项是最不好的,并为短期内永久驱逐攻击者离开系统而承担不同程度的技术债务。例如,为了阻止攻击者的访问,您可能选择手动向路由器的实时配置添加拒绝规则。为了防止攻击者看到您所做的更改,您可能会绕过正常的程序,不经同行审查和跟踪版本控制系统就进行此类更改。在这种情况下,您应该在将新的防火墙规则添加到配置的规范版本之前禁用自动规则推送。您还应该设置一个提醒,在未来的某个时候重新启用这些自动规则推送。
在决定是否在短期缓解措施中接受技术债务以驱逐攻击者时,问问自己以下问题:
-
我们可以多快(以及何时)替换或移除这些短期缓解措施?换句话说,这些技术债务会持续多久?
-
组织是否致力于在其寿命期间维护缓解措施?拥有新技术债务的团队是否愿意接受这笔债务,并在以后通过改进来偿还?
-
缓解措施会影响我们系统的正常运行时间吗?我们会超出错误预算吗?
-
组织中的人如何识别这种缓解措施是短期的?考虑将缓解措施标记为以后要删除的技术债务,以便任何其他在系统上工作的人都能看到其状态。例如,向代码添加注释和描述性的提交或推送消息,以便依赖新功能的任何人知道它在未来可能会发生变化或消失。
-
对于没有关于事件领域专业知识的未来工程师来说,他们如何证明这种缓解措施不再必要,并且可以在不带来风险的情况下将其移除?
-
如果短期缓解措施长时间保持(无论是意外还是情况所致),其效果会有多大?想象一下,攻击者已经入侵了您的数据库之一。您决定在对数据进行清理和迁移至新系统的同时保持数据库在线。您的短期缓解措施是将数据库隔离在一个单独的网络上。问问自己:如果迁移需要六个月而不是原定的两周,效果会怎样?组织中的人会不会忘记数据库曾经受到攻击,并意外地将其重新连接到安全网络?
-
领域专家是否已经确定了您对前面问题的答案中存在的漏洞?
恢复检查表
一旦您确定了恢复的范围,您应该列出您的选择(如“启动恢复”中所讨论的),并仔细考虑您需要做出的权衡。这些信息构成了您的恢复检查表的基础(或者根据事件的复杂程度可能有多个检查表)。您进行的每项恢复工作都应该利用常规和经过测试的做法。彻底记录和分享您的恢复步骤可以让参与事件响应的人更容易合作并就恢复计划提供建议。一份记录完善的检查表还可以让您的恢复团队确定可以并行化的工作领域,并帮助您协调工作。
如图 18-1 中的模板恢复检查表所示,检查表上的每一项都对应一个单独的任务,以及完成该任务所需的相应技能。? 恢复团队的成员可以根据自己的技能来领取任务。然后,事件指挥官可以确信所有已完成的恢复步骤都已经被勾选。
您的检查表应包含所有相关细节,比如用于恢复的具体工具和命令。这样,当您开始清理工作时,所有团队成员都将对需要完成的任务有清晰、达成一致的指导,并知道完成的顺序。检查表还应考虑在计划失败时需要的任何清理步骤或回滚程序。我们将在本章末尾的实例中使用图 18-1 中的模板检查表。

图 18-1. 检查表模板
启动恢复
在发生安全事件后,系统的安全可靠恢复在很大程度上依赖于有效的流程,比如精心构建的检查表。根据您正在处理的事件类型,您需要考虑有效的技术选项。您的缓解和恢复工作的目标是将攻击者从您的环境中驱逐出去,确保他们无法返回,并使您的系统更加安全。第九章涵盖了提前将恢复选项设计到系统中的原则。本节涵盖了在考虑这些原则的情况下执行恢复的实际现实,以及做出某些决定的利弊。
隔离资产(隔离)
隔离(也称为*隔离)是减轻攻击影响的一种非常常见的技术。一个经典的例子是将恶意二进制文件移动到隔离文件夹的防病毒软件,文件权限会阻止系统上的其他任何东西读取或执行该二进制文件。隔离也常用于隔离单个受损的主机。您可以在网络层面(例如,通过禁用交换机端口)或主机本身(例如,通过禁用网络)对主机进行隔离。甚至可以使用网络分割来隔离整个受损机器的网络——许多 DoS 响应策略会将服务从受影响的网络中移开。
如果你需要让受损的基础设施继续运行,隔离资产也可能是有用的。考虑这样一个场景:你的一个关键数据库已经受到了攻击。由于它的重要性,你需要在减轻过程中保持数据库在线——也许这个数据库是使命关键的,并且需要几周时间来重建,你的组织不想为此关闭整个业务。你可以通过将数据库隔离在自己的网络上,并对它可以发送和接收的网络流量(来自互联网和你的基础设施的其他部分)进行限制,来减少攻击者的影响。
一个警告:让受损的资产在线上是一种顽固的技术债务。如果你不及时解决这个债务,并且让它们在线上的时间超过预期,这些受损的资产可能会造成重大损害。这可能会发生出于几个原因:因为这是隔离数据的唯一副本(没有备份),因为替换隔离资产存在挑战,或者因为在事件的忙碌中人们简单地忘记了受损的资产。在最坏的情况下,你的组织中的新人(或者事件中的新人)甚至可能会取消隔离受损的资源!
考虑一些标记这些资产受损的方法,比如在设备上使用高度可见的贴纸,或者保持一个最新的隔离系统的 MAC 地址列表,并监控这些地址是否出现在你的网络上。贴纸可以主动避免重复使用,而地址列表可以快速地进行反应性移除。确保你的恢复清单和事后总结覆盖了任何隔离资产是否安全和永久地得到了补救。
系统重建和软件升级
考虑以下难题:你在三个系统上发现了攻击者的恶意软件,并且正在进入事件的恢复阶段。为了驱逐攻击者,你是删除恶意软件并让系统继续运行,还是重新安装系统?根据你的系统的复杂性和关键性,你可能需要考虑这些选项之间的权衡。一方面,如果受影响的系统是使命关键的,并且难以重建,你可能会倾向于删除攻击者的恶意软件并继续前进。另一方面,如果攻击者安装了多种类型的恶意软件,而你并不知道所有的恶意软件,你可能会错过全面清理的机会。通常,从头开始重新安装系统并使用已知的良好镜像和软件是最佳解决方案。
如果你使用可靠和安全的设计原则来操作你的环境,重建系统或升级软件应该相对简单。第九章提供了一些关于了解系统状态的提示,包括主机管理和固件。
例如,如果你使用的系统具有硬件支持的引导验证,可以通过加密的信任链一直到操作系统和应用程序(Chromebook 是一个很好的例子),那么恢复系统只是一个简单的断电重启的问题,这将使系统返回到一个已知的良好状态。像 Rapid 这样的自动发布系统(如SRE 书第八章中讨论的)也可以提供一种可靠和可预测的方式来在恢复过程中应用软件更新。在云计算环境中,你可以依靠即时的容器和软件发布来用安全的标准镜像替换任何受损的系统。
如果您在没有源代码控制系统或标准系统镜像来管理配置或使用已知良好版本的系统的情况下进入事件的恢复阶段,请考虑将这些机制作为短期恢复计划的一部分引入。有一些开源选项可用于管理系统构建,例如Bazel;配置,例如Chef;以及应用程序集成和部署,例如Helm用于 Kubernetes。在短时间内采用新的解决方案可能一开始看起来令人望而生畏,而在设置这些解决方案时,您可能需要对正确的配置进行初步尝试。如果弄清楚正确的配置需要时间和精力,而这会牺牲其他重要的技术工作,您可能需要稍后完善您的配置。确保您仔细考虑您为了短期安全而积累的技术债务,并制定改进这些新系统设置的计划。
数据清理
根据您的事件范围,您应该确认攻击者没有篡改您的源代码、二进制文件、图像和配置,或者您用于构建、管理或发布它们的系统。清理系统生态系统的一种常见技术是从其原始来源(如开源或商业软件提供商)、备份或未被篡改的版本控制系统中获取已知的良好副本。一旦您获得了已知的良好副本,您可以对您想要使用的版本进行校验和比较,以确保其与已知的良好状态和软件包一致。如果您的旧良好副本托管在受损的基础设施上,请确保您非常有信心,知道攻击者何时开始篡改您的系统,并确保审查您的数据来源。
代码来源的强大二进制溯源(如第十四章中所讨论的)使恢复更加简单。想象一下,您发现攻击者在您的构建系统上使用的glibc库中引入了恶意代码。您需要识别在“风险”时间范围内构建的所有二进制文件,这些二进制文件部署在哪里,以及它们具有的任何依赖关系。在进行这项检查时,清楚地标记已知的受损代码、库和二进制文件。您还应该创建测试,以防止您重新引入有漏洞或后门的代码。这些预防措施将确保您的恢复团队中的其他人在恢复过程中不会无意中使用受损的代码,也不会意外地重新引入有漏洞的版本。
您还应该检查攻击者是否篡改了任何应用程序级别的数据,例如数据库中的记录。如第九章所述,确保备份的强大加密完整性会增加您对这些备份的信心,并使您能够确保您需要与潜在受损的实时数据进行比较的任何比较都是准确的。调和攻击者所做的更改可能也会非常复杂,并且可能需要您构建特殊的工具。例如,为了利用部分恢复,您可能需要定制工具将从备份中获取的文件或记录拼接到您的生产系统中,同时进行同时的完整性检查。理想情况下,在制定可靠性策略时,您应该构建和测试这些工具。
恢复数据
恢复过程通常依赖于支持一系列操作的工具,例如回滚、恢复、备份、隔离重建和事务回放。“持久数据”讨论了安全存储用于这些操作的数据。
许多这些工具都有参数,可以在进展速度和数据安全之间进行交易。除非这些工具经常针对真实的生产规模工作负载进行测试,否则我们不建议更改这些参数的默认值。测试、暂存或(更糟糕的是)模拟不能真实地测试基础设施系统。例如,很难真实地模拟内存缓存填充所需的延迟,或者负载平衡估算器在真实的生产条件之外稳定所需的时间。这些参数因服务而异,由于延迟通常在监控数据中可见,您应该在事件之间调整这些设置。当您试图从敌对的安全攻击中恢复时,处理一个行为不端的工具就像面对一个新的攻击者一样具有挑战性。
您可能已经有监控措施来检测由软件错误导致的重大数据丢失。也有可能您的攻击者避免触发这些警报。即便如此,审查这些日志总是值得的:数据可能会确定攻击开始的拐点。如果指标显示了这样的拐点,那么您现在有了一个独立的下限,可以确定要跳过多少个备份。
不足够旧的现场恢复备份可能会重新激活在事件期间备份的任何妥协。如果检测入侵花费了一些时间,您最旧的“安全”备份可能已经被覆盖。如果是这样,数据整治可能是您唯一的选择。
恢复的备份可能包含被意外修改的数据和被损坏的数据。这种损坏可能是由恶意更改(攻击者)或随机事件(例如磁带损坏或硬盘故障)引起的。重建数据的工具往往专注于从随机损坏或恶意损坏中恢复,但不是两者兼顾。了解您的恢复和重建工具提供的功能,以及方法的局限性非常重要。否则,数据恢复的结果可能不符合您的期望。使用常规的完整性程序,例如根据已知的良好加密签名验证恢复的数据,将有所帮助。最终,冗余和测试是应对随机事件的最佳防御措施。
凭据和秘密轮换
攻击者常常会劫持您基础设施中使用的现有帐户,以冒充合法用户或服务。例如,进行密码钓鱼攻击的攻击者可能会尝试获取他们可以用来登录到您系统的帐户凭据。同样,通过诸如传递哈希的技术,攻击者可以获取和重复使用凭据,包括管理员帐户的凭据。第九章讨论了另一种情况:SSH authorized_keys文件的妥协。在恢复过程中,您通常需要通过诸如密钥轮换(例如 SSH 认证中使用的密钥)的方法来轮换系统、用户、服务和应用帐户的凭据。根据您的调查结果,辅助设备(例如网络设备和带外管理系统)以及云端服务(如 SaaS 应用程序)也可能在范围之内。
您的环境可能有其他需要关注的秘密,例如用于数据静态加密和用于 SSL 的加密密钥。如果您的前端 Web 服务基础设施受到破坏或者可能被攻击者访问,您可能需要考虑轮换 SSL 密钥。如果在攻击者窃取密钥后您不采取行动,他们可能会使用密钥进行中间人攻击。同样,如果数据库中记录的加密密钥在受损的数据库服务器上,最安全的方法是轮换密钥并重新加密数据。
加密密钥通常也用于应用级通信。如果攻击者可以访问存储这些应用级密钥的系统,你需要对密钥进行轮换。仔细考虑存储 API 密钥的位置,比如你用于云服务的密钥。将服务密钥存储在源代码或本地配置文件中是一个常见的漏洞:如果攻击者可以访问这些文件,他们以后可以访问其他环境。作为恢复的一部分,你应该确定攻击者是否可以访问这些文件(尽管可能无法证明他们被访问),并保守而经常地轮换这些服务密钥。
根据情况,凭证轮换可能需要谨慎执行。对于单个被钓鱼的账户,要求用户更改密码可能是一个简单的任务。然而,如果攻击者可以访问各种账户,包括管理员账户,或者你不确定他们可能已经 compromise 了哪些账户,你可能需要轮换所有用户的凭证。在创建恢复清单时,确保列出重置账户的顺序,优先考虑管理员凭证、已知被 compromise 的账户以及授予对敏感资源访问权限的账户。如果你有大量的系统用户,你可能需要通过一次性事件中断所有用户。
凭证轮换的另一个复杂之处在于,如果你的组织处理实践不够严密,一次攻击和应对可能会使情况变得更糟。假设你的公司使用集中系统(如 LDAP 数据库或 Windows Active Directory)来管理员工账户。其中一些系统会存储密码历史记录(通常是经过哈希和加盐的)。通常,系统会保留密码历史记录,以便你可以将新密码与旧密码进行比较,并防止用户随时间重新使用密码。如果攻击者可以访问所有哈希密码并破解这些密码,他们可能能够推断用户更新密码的模式。例如,如果用户在每个密码中使用了一年(password2019,password2020 等),攻击者可能能够预测下一个密码。当密码更改是你的补救策略的一部分时,这可能是危险的。
如果你可以接触到安全专家,最好在制定恢复计划时咨询他们。这些专家可以进行威胁建模,并提供如何改进你的凭证处理实践的建议。他们可能会建议通过采用双因素认证来消除复杂的密码方案的需要。
恢复后
一旦你驱逐了攻击者并完成了恢复,下一步是过渡出事故并考虑发生的长期影响。如果你经历了像单个员工账户或单个系统被 compromise 这样的小事件,恢复阶段和事后可能相对简单。如果你经历了一个更严重的事件,影响更大,恢复和事后阶段可能会更加广泛。
在 2009 年的奥罗拉行动之后,谷歌着手对其环境进行系统性和战略性的改变。我们有些改变是在一夜之间完成的,而其他一些改变,比如 BeyondCorp 和我们与 FIDO 联盟合作,推动广泛采用使用安全密钥的双因素认证,需要更多的时间。你的事后分析应该区分短期内和长期内你可以实现的目标。
事后分析
对于处理事件的团队来说,保留关于他们工作的笔记是一个良好的做法,之后可以整合到官方的事后总结中。每个事后总结都应包括一份行动项目清单,解决你在事件中发现的根本问题。一个强大的事后总结涵盖了攻击者利用的技术问题,并且认识到了改进事件处理的机会。此外,你应该记录与这些行动项目相关的时间框架和努力,并决定哪些行动项目属于短期和长期路线图。我们在 SRE 书的第十五章中详细介绍了无过失的事后总结,但这里有一些额外的关注安全的问题需要考虑:
-
事件的主要影响因素是什么?环境中是否存在其他变体和类似问题,你可以解决?
-
哪些测试或审计流程应该更早地检测到这些因素?如果它们还不存在,你是否可以建立这样的流程来捕捉未来类似的因素?
-
这一事件是否被预期的技术控制(如入侵检测系统)检测到?如果没有,你如何改善检测系统?
-
事件被发现和应对的速度有多快?这是否在可接受的时间范围内?如果不是,你如何改善你的响应时间?
-
重要数据是否受到足够的保护,以阻止攻击者访问?你应该引入哪些新的控制措施?
-
恢复团队是否能够有效地使用工具,包括源代码版本控制、部署、测试、备份和恢复服务?
-
团队在恢复过程中绕过了哪些正常程序,比如正常测试、部署或发布流程?你现在可能需要应用什么补救措施?
-
是否对基础设施或工具进行了临时缓解的更改,现在需要重构?
-
在事件和恢复阶段,你识别并记录了哪些错误,现在需要解决?
-
行业和同行群体中存在哪些最佳实践,可以在防范、检测或应对攻击的任何阶段帮助你?
我们建议制定一套明确的行动项目清单,明确指定所有者,并按照短期和长期举措的顺序进行排序。短期举措通常比较简单,实现起来不需要太长时间,并且解决的问题范围相对较小。我们通常称这些行动项目为“低挂果”,因为你可以轻松地识别和解决它们。例如,添加双因素身份验证、缩短应用补丁的时间或建立漏洞发现程序。
长期的举措可能会融入到你的组织安全姿态改进的整体计划策略中。这些行动项目通常更基本地影响你的系统和流程的运作方式,例如成立专门的安全团队、部署骨干加密或改变操作系统选择。
在理想的情况下,从妥协到安全姿态改进的完整事件生命周期将在下一次事件发生之前完成。然而,请记住,在上一次事件之后的例行稳定状态期间也是下一次事件之前的例行状态。事件活动的这段时间是你学习、适应、识别新威胁并为下一次事件做准备的机会。本书的最后部分专注于在这些例行状态期间改进和维护你的安全姿态。
例子
以下的工作示例展示了事后分析、恢复清单的建立以及恢复执行的关系,以及长期缓解措施如何融入更大的安全计划。这些示例并未涵盖所有的事件响应考虑,而是侧重于如何在驱逐攻击者、减轻他们的即时行动和进行长期变更之间进行权衡。
受损的云实例
场景:贵组织使用的基于网络的软件包在云提供商的基础设施中用于为用户流量提供服务的虚拟机(VM)存在常见的软件漏洞。一名机会主义的攻击者使用漏洞扫描工具发现了您的易受攻击的网络服务器并利用了它们。一旦攻击者接管了虚拟机,他们就会利用它们发起新的攻击。
在这种情况下,修复负责人使用了调查小组的笔记,确定团队需要修补软件,重新部署虚拟机,并关闭受损的实例。修复负责人还确定,短期的缓解措施应该发现并解决相关的漏洞。图 18-2 提供了这一事件的一个假设恢复清单。出于简洁起见,我们省略了具体的命令和执行步骤,而您的实际恢复清单应包括这些细节。

图 18-2. 受损云实例的恢复清单
恢复完成后,由所有参与事件的人共同开发的事故事后分析确定了需要一个正式的漏洞管理计划,以便及时主动地发现和修补已知问题。这一建议被纳入了改善组织安全姿态的长期战略中。
大规模钓鱼攻击
场景:在七天内,攻击者对贵组织发起了密码钓鱼攻击,而贵组织并未使用双因素认证。70%的员工上当受骗。攻击者使用这些密码读取了贵组织的电子邮件,并向媒体泄露了敏感信息。
作为这种情况下的 IC,您面临着许多复杂性:
-
调查小组确定,攻击者尚未尝试使用密码访问除电子邮件之外的任何系统。
-
贵组织的 VPN 和相关 IT 服务,包括云系统的管理,使用独立的认证系统与电子邮件服务不同。然而,许多员工在不同服务之间共享密码。
-
攻击者表示他们将在未来几天对贵组织采取更多行动。
与修复负责人合作,您必须权衡快速驱逐攻击者(通过取消他们对电子邮件的访问权限)和确保攻击者在此期间无法访问任何其他系统之间的权衡。这项恢复工作需要精确的执行,图 18-3 提供了一个假设的清单。同样,出于简洁起见,我们省略了确切的命令和程序,但您的真实清单应包括这些细节。

图 18-3. 大规模钓鱼攻击的恢复清单
恢复完成后,您的正式事后分析强调了以下需求:
-
更广泛地在关键通信和基础设施系统上使用双因素认证
-
单点登录解决方案
-
员工关于钓鱼攻击的教育
贵组织还注意到需要一名 IT 安全专家为您提供建议标准最佳实践。这一建议被纳入了改善贵组织安全姿态的长期战略中。
需要复杂恢复的有针对性攻击
情景:你并不知情,攻击者已经能够访问你的系统一个多月了。他们窃取了用于保护与客户在网上通信的 SSL 密钥,向你的源代码中插入了后门,以每笔交易中盗取 0.02 美元,并监视你组织中高管的电子邮件。
作为 IC,你面临着许多复杂性:
-
你的调查团队不清楚攻击是如何开始的,或者攻击者如何继续访问你的系统。
-
你的攻击者可以监视高管和事件响应团队的活动。
-
你的攻击者可以修改源代码并部署到生产系统。
-
你的攻击者已经能够访问存储 SSL 密钥的基础设施。
-
与客户进行的加密网络通信可能会受到损害。
-
你的攻击者已经窃取了钱。
我们不会为这种相当复杂的攻击提供详细的恢复检查表,而是会专注于事件的一个非常重要的方面:需要并行恢复。与 RL 合作,你需要为这些问题中的每一个创建一个恢复检查表,以便更好地协调恢复步骤。在此期间,你还需要与正在了解攻击者过去和当前行动的调查团队保持联系。
例如,你的努力可能需要一些或所有以下恢复团队(你可能还可以想到其他的):
电子邮件团队
这个团队将切断攻击者对电子邮件系统的访问,并确保他们无法重新进入。团队可能需要重置密码,引入双因素认证等。
源代码团队
这个团队将确定如何切断对源代码的访问,清理受影响的源代码文件,并重新部署经过清理的代码到生产系统。为了完成这项工作,团队需要知道攻击者何时在生产环境中更改了源代码,以及是否存在安全版本。这个团队还需要确保攻击者没有对持久版本控制历史进行更改,并且不能进行额外的源代码更改。
SSL 密钥团队
这个团队将确定如何安全地部署新的 SSL 密钥到网络服务基础设施。为了完成这项工作,团队需要知道攻击者是如何获取密钥的,并且如何防止未经授权的访问。
客户数据团队
这个团队将确定攻击者可能访问到了哪些客户信息,以及是否需要进行补救措施,比如客户密码更改或会话重置。这个补救团队可能还与客户支持、法律和相关人员提出的任何其他问题密切相关。
调和团队
这个团队将研究每笔交易中被盗取的 0.02 美元的影响。你是否需要在数据库中追加记录以适应长期的财务记录?这个团队可能还与财务和法律人员提出的任何其他问题密切相关。
在这种复杂的事件中,通常需要在恢复过程中做出不太理想的选择。例如,考虑需要切断公司电子邮件访问权限的团队。他们可能有一些选择,比如关闭电子邮件系统,锁定所有账户,或者并行启动一个新的电子邮件系统。这些选项都会对组织造成一定影响,可能会提醒攻击者,并且可能并不一定解决攻击者最初获取访问权限的问题。恢复和调查团队需要密切合作,找到适合情况的前进路径。
结论
-
恢复是你的事件响应过程中一个独特而关键的步骤,需要一个精通自己领域的专门团队。在规划恢复时需要考虑许多方面:你的攻击者会如何反应?谁执行什么行动,何时执行?你对用户说什么?你的恢复过程应该是并行的,精心计划的,并且与你的事件指挥官和调查团队定期同步。你的恢复工作应该始终以驱逐攻击者、纠正妥协和提高系统整体安全性和可靠性的最终目标为导向。每次妥协都应该产生能够帮助你改善组织长期安全状况的教训。
-
从安全事件中恢复的主题在许多资源中都有很好的覆盖,比如NIST SP 800-184,即《网络安全事件恢复指南》。NIST 指南强调了通过提前创建各种类型预期事件的强大恢复检查表来提前计划的必要性。它还提供了关于测试这些计划的说明。这是一个很好的通用参考,但你可能会发现在危机时期实现其严格的建议是具有挑战性的。
-
或者三个臭皮匠的小品,如果你没有一个有良好记录的计划!
-
错误预算在 SRE 书的第三章中有描述。
-
你如何实现“不用键盘”的简报取决于你,但这个练习的主要目的是要得到观众的全神贯注和参与。在事件发生期间,响应者可能会不断地关注运行脚本或状态仪表板,这很诱人。要执行微妙和复杂的恢复,很重要的一点是在简报期间要得到每个人的全神贯注,这样每个人都在同一页面上。
-
根据攻击者的复杂程度和攻击的深度,你可能需要考虑重新安装 BIOS 和重新格式化硬盘,甚至更换物理硬件。例如,从 UEFI rootkits 中恢复可能很困难,正如ESET Research 关于 LoJax 的白皮书中所描述的那样。
-
Pass-the-hash是一种技术,允许攻击者在本地从一台机器上窃取的凭据(NTLM 或 LanMan 哈希)在网络上重播,以登录到其他系统,而无需使用用户的明文密码。
-
将云服务密钥存储在本地文件和源代码中并不被认为是最佳实践。有关在 GitHub 中暴露服务密钥的最新系统研究,请参见 Meli, Michael, Matthew R. McNiece, and Bradley Reaves. 2019. “How Bad Can It Git? Characterizing Secret Leakage in Public GitHub Repositories.” Proceedings of the 26th Annual Networked and Distributed Systems Security Symposium. https://oreil.ly/r65fM。
-
存储密码的最安全方式是使用专门设计用于密码哈希的盐化密钥派生函数,比如scrypt或Argon2。与仍然常见的盐化 SHA-1 等密码哈希方法不同,这些函数提供了对常见密码恢复攻击的保护,从预先填充的查找表到低成本的专用硬件。即使使用强密码哈希,最佳实践也是确保这些哈希本身在静止状态下使用受保护的密钥进行加密,以增加潜在对手的另一个障碍。
? 有关谷歌为自身和用户实现安全密钥的更多信息,请参阅 Lang, Juan 等人。2016 年。“安全密钥:现代网络的实用密码学第二因素。”第 20 届国际金融密码学和数据安全会议论文集:422-440。https://oreil.ly/bL9Fm。
第五部分:组织和文化
原文:Part V. Organization and Culture
译者:飞龙
本书中强调的工程实践将帮助您的组织构建安全可靠的系统,只有在整个组织投入安全可靠文化的情况下,您的努力才会有效。文化是每个组织的强大而独特的定义性组成部分,您不应低估其在推动变革中的作用。
本书的第五部分着重于实现迄今为止所提出方法的文化方面。Chrome 是 Google 旗下首个拥有专门安全团队的产品,积极推动安全为中心的文化。我们从该团队的案例研究开始,重点关注其在 Chrome 的受欢迎和成功中的作用。在第二十章中,我们提出组织中的每个人都对安全和可靠性负有责任。安全专家的角色应该是实现需要专业知识的安全特定技术,并制定最佳实践、政策和培训。第二十一章通过讨论促进健康的安全可靠文化的策略来结束本书。
第十九章:案例研究:Chrome 安全团队
原文:19. Case Study: Chrome Security Team
译者:飞龙
作者:Parisa Tabriz
与 Susanne Landers 和 Paul Blankinship
背景和团队演变
2006 年,Google 成立了一个团队,旨在在不到两年的时间内构建一个开源的 Windows 浏览器,该浏览器将比市场上的其他浏览器更安全、更快速和更稳定。这是一个雄心勃勃的目标,并提出了独特的安全挑战:
-
现代网络浏览器的复杂性与操作系统类似,它们的大部分功能被认为是安全关键的。
-
客户端和 Windows 软件与 Google 当时大部分现有产品和系统提供有所不同,因此 Google 中央安全团队内部的可转移安全专业知识有限。
-
由于该项目打算开始并且主要保持开源,因此它具有独特的开发和运营要求,不能依赖于 Google 的企业安全实践或解决方案。
这个浏览器项目最终于 2008 年作为 Google Chrome 推出。自那时起,Chrome 被认为是重新定义了在线安全标准,并成为世界上最受欢迎的浏览器之一。
在过去的十年中,Chrome 的安全组织经历了四个大致的演变阶段:
团队 v0.1
Chrome 在 2008 年正式推出之前并没有正式建立安全团队,而是依赖于工程团队内部的专业知识,以及来自 Google 中央安全团队和第三方安全供应商的咨询。最初的推出并不是没有安全漏洞的——事实上,在公开发布的头两周内发现了许多关键的缓冲区溢出!许多最初的推出漏洞符合开发人员在时间紧迫的情况下试图发布针对性能优化的 C++代码而产生的缺陷模式。浏览器应用程序和 Web 平台的实现也存在漏洞。发现漏洞,修复它们,编写测试以防止回归,并最终设计它们消失是一个成熟团队的正常过程。
团队 v1.0
公开测试版发布一年后,随着浏览器的实际使用开始增长,一个专门的 Chrome 安全团队应运而生。这个最初的安全团队由来自 Google 中央安全团队和新员工的工程师组成,利用了 Google 建立的最佳实践和规范,并从组织外部带来了新的观点和经验。
团队 v2.0
2010 年,Chrome 推出了漏洞奖励计划(VRP)以表彰来自更大安全研究社区的贡献。对 VRP 公告的压倒性回应为安全团队的早期发展提供了一个有用的孵化器。Chrome 最初基于 WebKit——一个之前并没有受到太多安全审查的开源 HTML 渲染引擎,因此团队最初的任务之一是应对大量外部漏洞报告。当时,Chrome 的工程团队非常精简,还不太熟悉整个 WebKit 代码库,因此安全团队发现,解决漏洞的最迅速方法通常是直接着手,建立对代码库的专业知识,并自行修复许多漏洞!
这些早期决定最终对团队未来的文化产生了重大影响。它将安全团队建立为不是孤立的顾问或分析师,而是作为安全专家的混合工程团队。这种混合方法最大的优势之一在于它提供了关于如何将安全开发纳入每个 Chrome 工程师日常流程的独特和实用的见解。
团队 v3.0
到 2012 年,Chrome 的使用量进一步增长,团队的雄心也增长了,攻击者的关注也增加了。为了帮助在不断增长的 Chrome 项目中扩展安全性,核心安全团队建立、社会化并发布了一套核心安全原则。
2013 年,引入了一名工程经理并雇佣了更多致力于安全的工程师之后,团队举行了一次离岸会议,反思他们的工作,定义了团队使命,并就他们想要解决的更大的安全问题以及潜在解决方案进行头脑风暴。这次定义使命的练习导致了一份表述团队共同目标的声明:为 Chrome 用户提供尽可能安全的平台,以浏览网络,并在网络上推进安全性。
在 2013 年的离岸会议上,为了包容地进行头脑风暴,每个人都在便利贴上写下了自己的想法。团队集体整理了这些想法,以确定主题,从而建立了一些持续关注的重点工作领域。这些重点领域包括以下内容:
安全审查
安全团队定期与其他团队协商,帮助设计和评估新项目的安全性,并审查代码库中的安全敏感变更。安全审查是团队的共同责任,并有助于促进知识传递。团队通过撰写文档、举办安全培训,并担任 Chrome 代码的安全关键部分的所有者来扩展这项工作。
发现和修复漏洞
拥有数百万行安全关键代码和数百名全球开发人员不断进行更改,团队投资于一系列方法,以帮助每个人尽快找到和修复漏洞。
架构和利用缓解
团队意识到永远无法预防所有安全漏洞,因此他们投资于安全设计和架构项目,以最小化任何单个漏洞的影响。由于 Chrome 可在流行的桌面和移动操作系统上使用(例如 Microsoft Windows、macOS、Linux、Android 和 iOS),这些操作系统本身不断发展,这需要持续的针对特定操作系统的投资和策略。
可用安全性
无论团队对 Chrome 软件和用于构建它的系统有多么自信,它们仍然需要考虑用户(毕竟是可犯错误的)如何以及何时做出关乎安全的决定。鉴于浏览器用户的数字素养范围广泛,团队投资于帮助用户在浏览网页时做出安全决策,使安全更易用。
Web 平台安全
除了 Chrome 之外,团队还致力于提升为构建 Web 应用程序的开发人员的安全性,以便任何人都能更轻松地在 Web 上构建安全体验。
为每个重点领域确定负责任的领导者,以及后来的专门经理,有助于建立更具可扩展性的团队组织。重点领域的领导者重视灵活性、团队范围的信息共享和项目协作,以确保没有个人或重点领域与其他重点领域隔离。
寻找和留住优秀的人才——那些关心团队使命和核心原则,并且与他人合作良好的人——至关重要。团队中的每个人都参与招聘、面试,并为他们的队友提供持续的成长导向反馈。拥有合适的人才比任何组织细节都更重要。
在实际寻找候选人方面,团队大量利用了个人网络,并不断努力培养和扩大那些来自不同背景的人的网络。我们还将一些实习生转为全职员工。偶尔,我们会冷调那些在会议上发言或其发表的作品显示他们关心网络和构建大规模产品的个人。在公开工作的一个优势是,我们可以将潜在候选人指向Chromium 开发者维基上我们团队努力和最近成就的细节,这样他们可以快速了解团队的工作、挑战和文化。
重要的是,我们追求并考虑了那些对安全感兴趣,但在其他领域具有专业知识或成就的个人。例如,我们雇佣了一名具有丰富 SRE 背景的工程师,他对保护人们安全的使命非常关心,并且对学习安全感兴趣。这种多样化的经验和观点被广泛认为是团队成功的关键因素之一。
在接下来的几节中,我们将分享更多关于 Chrome 核心安全原则如何在实践中应用的见解。这些原则对于 Chrome 来说仍然是相关的(约 2020 年),就像它们在 2012 年首次撰写时一样重要。
安全是团队的责任
Chrome 具有如此强烈的安全重点的一个关键原因是,我们将安全作为核心产品原则,并建立了一个安全被视为团队责任的文化。
尽管 Chrome 安全团队有幸几乎完全专注于安全,团队成员意识到他们永远无法为 Chrome 的所有安全负责。相反,他们努力将安全意识和最佳实践融入到每个参与产品开发的人的日常习惯和流程中。系统设计约定旨在使易用、快速和明晰的路径成为安全路径。这通常需要额外的前期工作,但最终导致了更有效的长期合作。
实践中的一个例子是团队处理安全漏洞的方式。所有工程师,包括安全团队成员,都会修复漏洞并编写代码。如果安全团队只是发现并报告漏洞,他们可能会失去对编写无漏洞代码或修复漏洞有多么困难的感触。这也有助于缓解安全工程师不参与传统工程任务时可能出现的“我们”与“他们”的心态。
随着团队超越了早期的漏洞应急阶段,它开始努力发展更加积极主动的安全方法。这意味着投入时间建立和维护模糊测试基础设施和开发人员工具,使其更快速、更容易地识别引入漏洞的变更并进行撤销或修复。开发人员能够快速识别新漏洞,修复起来就更容易,对最终用户的影响也更小。
除了为开发人员创建有用的工具,团队还为工程团队创造了积极的激励机制来进行模糊测试。例如,组织每年的模糊测试比赛并提供奖品,并创建模糊测试教程来帮助任何工程师学习如何进行模糊测试。组织活动并简化贡献的方式有助于人们意识到他们不需要成为“安全专家”来提高安全性。Chrome 的模糊测试基础设施起步较小,只是一个工程师桌子下的一台电脑。截至 2019 年,它支持了 Google 和全球范围内的模糊测试。除了模糊测试,安全团队还构建和维护安全基础库(例如安全数字库),以便任何人实现变更的默认方式都是安全的方式。
安全团队成员经常向个人或其经理发送同行奖金或积极反馈,当他们注意到有人在模拟强大的安全实践时。由于安全工作有时会被忽视或对最终用户不可见,因此额外努力直接或与职业目标一致地予以认可有助于为更好的安全性设立积极激励。
独立于策略,如果组织尚未认为安全是核心价值和共同责任,就需要更基本的反思和讨论来证明安全和可靠性对组织的核心目标的重要性。
帮助用户安全地浏览网络
有效的安全性不应依赖于任何最终用户的专业知识。任何拥有大规模用户群的产品都需要仔细平衡可用性、功能和其他业务约束。在大多数情况下,Chrome 的目标是使安全性对用户几乎是不可见的:我们进行透明更新,我们倾向于安全默认设置,并且我们不断努力使安全决策成为易于决策的决策,并帮助用户避免不安全的决策。
在团队 v3.0 阶段,我们共同承认我们在可用安全方面存在一系列问题,这些问题源于人类与软件的互动。例如,我们知道用户正在成为社会工程和网络钓鱼攻击的受害者,我们对 Chrome 的安全警告效果表示担忧。我们想解决这些问题,但团队中的人性化软件专业知识有限。我们决定需要有策略地雇佣更多的可用安全专业知识,并与一个对新角色感兴趣的内部候选人偶然取得联系。
当时,这位候选人处于研究科学家的职业阶梯上,Chrome 在招聘方面没有先例。尽管最初有所保留,但我们说服了领导层雇佣这位候选人,强调候选人的学术专长和多元化观点实际上是团队的资产,并且对于增强其现有技能组是必要的。与用户体验(UX)团队密切合作,这位新加入我们团队的成员继续建立了 Chrome 可用安全的重点领域。最终,我们雇佣了更多的 UX 设计师和研究人员,帮助我们更深入地了解用户的安全和隐私需求。我们了解到,安全专家,由于他们对计算机系统和网络运作方式的高度理解,往往对用户面临的许多挑战视而不见。
速度至关重要
用户安全取决于快速检测安全漏洞并在攻击者利用之前向用户提供修复程序。Chrome 最重要的安全功能之一是快速自动更新。从早期开始,安全团队与技术项目经理(TPM)密切合作,他们建立了 Chrome 的发布流程并管理了每个新版本的质量和可靠性。发布 TPM 测量崩溃率,确保高优先级错误的及时修复,小心谨慎地推进发布,当工程师们进展太快时进行反对,并努力以合理的速度将可靠性或安全性改进的发布推送给用户。
早期,我们利用 Pwn2Own 和后来的 Pwnium 黑客大赛作为强制性手段,以查看我们是否能在 24 小时内发布和部署关键的安全修复。(我们可以。)这需要与发布 TPM 团队的强大合作伙伴关系和大量的帮助和支持,尽管我们证明了这种能力,但由于 Chrome 在深度防御方面的投资,我们很少需要使用它。
深度防御设计
无论团队有多快能够检测和修复 Chrome 中的任何单个安全漏洞,这些漏洞都可能发生,特别是考虑到 C++的安全缺陷和浏览器的复杂性。由于攻击者不断提升他们的能力,Chrome 不断投资于开发利用缓解技术和帮助避免单点故障的架构。团队创建了一个活跃的按风险分级的组件图,以便任何人都可以推理出 Chrome 的安全架构和各种防御层,以指导他们的工作。
实践中深度防御的最好例子之一是持续投资于沙盒能力。Chrome 最初采用了多进程架构和沙盒化的渲染器进程。这阻止了恶意网站接管用户整个计算机,这对于当时的浏览器架构来说是一个重大进步。在 2008 年,来自网络的最大威胁是恶意网页利用浏览器妥协在用户的机器上安装恶意软件,而 Chrome 的架构成功地解决了这个问题。
但是,随着计算机使用的发展,随着云计算和网络服务的普及,越来越多的敏感数据已经转移到了在线。这意味着跨网站数据窃取可能与本地机器的妥协一样重要。攻击重点从“渲染器妥协安装恶意软件”转移到“渲染器妥协窃取跨站点数据”并不清楚,但团队知道这样做的动机是存在的,使这种转变是不可避免的。有了这一认识,2012 年,团队启动了站点隔离项目,以提高沙盒化的状态以隔离各个站点。
最初,团队预测站点隔离项目需要一年才能完成,但我们的估计偏差超过了五倍!这样的估计错误往往会引起高层管理对项目的关注,这是有充分理由的。团队定期向领导和各利益相关者阐明了项目的深度防御动机、进展情况以及为什么比最初预期的工作量更大的原因。团队成员还展示了对整体 Chrome 代码健康的积极影响,这有利于 Chrome 的其他部分。所有这些都使团队有额外的保护来捍卫项目,并在多年内向高级利益相关者传达其价值,直到最终公开发布。(巧合的是,站点隔离部分缓解了推测执行漏洞,这些漏洞是在 2018 年发现的。)
由于深度防御工作不太可能导致用户可见的变化(如果做得正确),因此领导层更需要积极管理、认可和投资这些项目。
保持透明并与社区互动
透明度自一开始就是 Chrome 团队的核心价值观。我们不会淡化安全影响或用悄无声息的修复来掩盖漏洞,因为这样做对用户毫无益处。相反,我们为用户和管理员提供了他们需要准确评估风险的信息。安全团队发布了处理安全问题的方式,披露了 Chrome 及其依赖项中修复的所有漏洞,无论是内部发现还是外部发现,并且在可能的情况下,在发布说明中列出了每个已修复的安全问题。
除了漏洞,我们还与公众分享季度总结,并通过外部讨论邮件列表(security-dev@chromium.org)与用户互动,以便任何人都可以向我们发送想法、问题或参与正在进行的讨论。我们积极鼓励个人在会议或安全聚会上分享他们的工作,或通过他们的社交网络参与。我们还通过 Chrome 的漏洞奖励计划和安全会议赞助与更大的安全社区互动。Chrome 之所以更安全,要归功于许多不认为自己是团队一部分的人的贡献,我们尽力承认和奖励这些贡献,确保适当的归因并支付货币奖励。
在谷歌内部,我们组织了一年一度的团队外出会议,将 Chrome 安全团队与中央安全团队和其他嵌入式团队(例如,Android 的安全团队)联系起来。我们还鼓励谷歌内的安全爱好者在 Chrome 上做 20%的工作(反之亦然),或者找到与 Chromium 项目上的学术研究人员合作的机会。
在开放环境中工作使团队能够分享其工作、成就和想法,并获得反馈或在谷歌之外追求合作。所有这些有助于推动对浏览器和网络安全的共同理解。团队多年来努力增加 HTTPS 采用率的努力是如何沟通变化并与更大的社区合作可以导致生态系统变化的一个例子。
结论
Chrome 团队在项目的早期阶段确定安全性是核心原则,并随着团队和用户基数的增长扩大了投资和策略。Chrome 安全团队在浏览器推出仅一年后正式成立,随着时间的推移,其角色和责任变得更加明确定义。团队阐明了使命和一套核心安全原则,并为其工作建立了关键的重点领域。
将安全性作为团队责任,拥抱透明度,并与 Chrome 之外的社区互动有助于创建和推进以安全为中心的文化。追求快速创新导致了一个动态的产品,并有能力灵活应对不断变化的环境。深度防御设计有助于保护用户免受一次性错误和新型攻击。考虑安全的人类因素,从最终用户体验到招聘流程,帮助团队扩大对安全的理解并解决更复杂的挑战。愿意直面挑战并从错误中学习使团队能够努力使默认路径也成为安全路径。
1 谷歌在 2019 年初开源了其OSS-Fuzz 服务的模糊后端ClusterFuzz。
第二十章:理解角色和责任
原文:20. Understanding Roles and Responsibilities
译者:飞龙
由 Heather Adkins,Cyrus Vesuna,Hunter King,Felix Gr?bert 和 David Challoner 撰写
与 Susanne Landers,Steven Roddis,Sergey Simakov,Shylaja Nukala,Janet Vong,Douglas Colish,Betsy Beyer 和 Paul Blankinship 合作
正如本书多次强调的那样,构建系统是一个过程,而改进安全性和可靠性的过程依赖于人。这意味着构建安全可靠的系统涉及解决两个重要问题:
-
谁负责组织的安全和可靠性?
-
安全和可靠性工作如何整合到组织中?
这些问题的答案高度依赖于您组织的目标和文化(下一章的主题)。以下部分概述了如何思考这些问题的一些高层指导,并提供了谷歌多年来如何处理这些问题的见解。
谁负责安全和可靠性?
在一个组织中谁负责安全和可靠性?我们认为安全和可靠性应该整合到系统的生命周期中;因此,它们是每个人的责任。我们希望挑战这样一个神话,即组织应该把这些问题的负担完全放在专门的专家身上。
如果可靠性和安全性被委托给一个无法要求其他团队进行安全相关更改的孤立团队,同样的失败将反复发生。他们的任务可能开始感到像西西弗斯一样——重复而无效。
我们鼓励组织将可靠性和安全性作为每个人的责任:开发人员,SRE,安全工程师,测试工程师,技术负责人,经理,项目经理,技术作家,高管等等。这样,第四章中描述的非功能性需求将成为整个组织在整个系统生命周期中的关注焦点。
专家的角色
如果每个人都对安全和可靠性负责,那么您可能会想:安全专家或可靠性专家的角色究竟是什么?根据一种观点,构建特定系统的工程师应该主要关注其核心功能。例如,开发人员可能会专注于为基于手机的应用程序构建一组关键用户体验。在开发团队的工作之外,一个以安全为重点的工程师将从攻击者的角度审视该应用程序,以破坏其安全性。一个以可靠性为重点的工程师可以帮助理解依赖链,并根据这些依赖链确定应该测量哪些指标,这些指标将导致客户满意和符合 SLA 的系统。这种分工在许多开发环境中很常见,但重要的是这些角色应该共同合作,而不是孤立工作。
为了进一步扩展这个想法,根据系统的复杂性,组织可能需要具有专业经验的人员来做细微的判断。由于不可能构建一个绝对安全、能够抵御所有攻击的系统,或者一个完全可靠的系统,专家的建议可以帮助引导开发团队。理想情况下,这些指导应该整合到开发生命周期中。这种整合可以采取多种形式,安全和可靠性专家应该直接与开发人员或其他专家合作,以改进系统的每个阶段。1 例如,安全咨询可以在多个阶段进行:
-
*项目开始时的安全设计审查,以确定如何整合安全性
-
持续的安全审计以确保产品按照安全规范正确构建
-
测试以查看独立人员可以发现的漏洞
安全专家应负责实现需要专业知识的安全特定技术。加密是一个典型的例子:“不要自己编写加密”是一个常见的行业口头禅,旨在阻止有抱负的开发人员实现他们自己的解决方案。加密实现,无论是在库中还是在硬件中,都应该留给专家。如果你的组织需要提供安全服务(例如通过 HTTPS 的网络服务),请使用业界公认和经过验证的解决方案,而不是尝试编写自己的加密算法。专业的安全知识也可能需要实现其他类型的高度复杂的安全基础设施,例如自定义身份验证、授权和审计(AAA)系统,或者新的安全框架以防止常见的安全漏洞。
可靠性工程师(如 SRE)最适合开发集中式基础设施和全公司自动化。SRE 书的第七章讨论了水平解决方案的价值和演变,并展示了能够促进产品开发和发布的关键软件如何演变成平台。
最后,安全和可靠性专家可以制定适合你组织工作流程的最佳实践、政策和培训。这些工具应该赋予开发人员采用最佳实践和实现有效的安全和可靠性实践的能力。专家应该努力建立组织的知识智囊团,不断学习行业发展并提高更广泛的意识(参见“意识文化”)。通过创造意识,专家可以帮助组织以迭代的方式变得更加安全和可靠。例如,谷歌有针对 SRE 和安全的教育计划,为这些特定角色的新员工提供基本的知识水平。除了向全公司提供课程材料外,我们还为员工提供许多关于这些主题的自学课程。
了解安全专业知识
任何试图在组织中雇佣安全专业人员的人都知道这项任务可能具有挑战性。如果你自己不是安全专家,那么在雇佣安全专家时应该寻找什么?医学专业人员提供了一个很好的类比:大多数人对人类健康的基本原理有一般了解,但许多人在某个时候会专攻某个领域。在医学领域,家庭医生或全科医生通常负责初级护理,但更严重的疾病可能需要神经学、心脏病学或其他领域的专家。同样,所有安全专业人员通常掌握一般知识,但他们也倾向于在一些特定领域专攻。
在雇佣安全专家之前,了解组织需要的技能类型非常重要。如果你的组织很小,例如,如果你是一家初创公司或一个开源项目,一名综合性专家可能可以满足你的许多需求。随着组织的成长和发展,其安全挑战可能变得更加复杂,需要增加专业化。表 20-1 介绍了谷歌早期历史上需要相应安全专业知识的一些关键时刻。
表 20-1. Google 历史上关键时刻需要的安全专业知识
| 公司里程碑 | 需要的专业知识 | 安全挑战 |
|---|---|---|
| Google 搜索(1998)Google 搜索为用户提供查找公开信息的能力。 | 一般 | 搜索查询日志数据保护 |
| 防止拒绝服务攻击 | ||
| 网络和系统安全 | ||
| Google AdWords(2000)Google AdWords(Google Ads)使广告商能够在 Google 搜索和其他产品上展示广告。 | 一般 | |
| 数据安全 | 金融数据保护 | |
| 网络安全 | 法规合规 | |
| 系统安全 | 复杂的网络应用程序 | |
| 应用安全 | 身份 | |
| 合规和审计 | 账户滥用 | |
| 反欺诈 | 欺诈和内部滥用 | |
| 隐私 | ||
| 拒绝服务 | ||
| 内部风险 | ||
| 博客(2003 年)博客是一个允许用户托管自己的网页的平台。 | 通用数据安全 | |
| 网络安全 | 拒绝服务 | |
| 系统安全 | 平台滥用 | |
| 应用程序安全 | 复杂的网络应用程序 | |
| 内容滥用 | ||
| 谷歌邮箱(Gmail)(2004 年)Gmail 是谷歌的免费网络邮件系统,高级功能可通过付费的 GSuite 账户获得。 | 通用隐私 | |
| 数据安全 | 保护静态和传输中的高度敏感用户内容 | |
| 网络安全 | 涉及高能力外部攻击者的威胁模型 | |
| 系统安全 | 复杂的网络应用程序 | |
| 应用程序安全 | 身份系统 | |
| 密码学 | 账户滥用 | |
| 反垃圾邮件 | 电子邮件垃圾邮件和滥用 | |
| 反滥用 | 拒绝服务 | |
| 事件响应 | 内部滥用 | |
| 内部风险 | 企业需求 | |
| 企业安全 |
认证和学术
一些安全专家寻求获得他们感兴趣领域的认证。全球各地的机构提供面向安全的行业认证,这些认证可以很好地表明一个人对于发展相关职业技能和学习关键概念的兴趣。这些认证通常涉及标准化的基于知识的测试。一些认证需要最少一定数量的课堂、会议或工作经验。几乎所有认证在一定时间后会过期,或要求持有人刷新最低要求。
这些标准化的测试机制不一定能证明某人在您组织的安全角色中取得成功的能力,因此我们建议采取一种平衡的方法来评估安全专家,综合考虑他们的所有资格:他们的实际经验、认证和个人兴趣。虽然认证可能表明某人通过考试的能力,但我们见过持有证书的专业人士在应用知识解决问题时遇到困难。与此同时,早期职业候选人或从其他专业角色转入该领域的候选人可能会利用认证快速提升他们的知识。对于对该领域有浓厚兴趣或在开源项目中有实际经验(而不是工作经验)的早期职业候选人来说,他们可能能够迅速增加价值。
由于安全专家的需求越来越大,许多行业和大学一直在开发和完善以安全为重点的学术项目。一些机构提供涵盖多个安全领域的通用安全学位。其他学位项目专注于特定的安全领域(这对博士生来说很常见),还有一些提供了关于网络安全问题和公共政策、法律和隐私等领域重叠课程的混合课程。与认证一样,我们建议在考虑候选人的学术成就时,要考虑他们的实际经验和您组织的需求。
例如,您可能希望首先聘请一名经验丰富的专业人士作为您的第一位安全招聘,并在团队建立并能够提供指导时聘请早期职业人才。另外,如果您的组织正在解决一个小众的技术问题(比如保护自动驾驶汽车),一位在特定研究领域有深入知识但工作经验较少的新博士毕业生可能会很好地适应这个角色。
将安全整合到组织中
知道何时开始从事安全工作更多的是一门艺术而不是科学。关于这个话题的意见很多,也各不相同。然而,可以肯定的是,你越早开始考虑安全,你就会越好。更具体地说,多年来我们观察到一些情况很可能会促使组织(包括我们自己)开始建立安全计划:
-
当一个组织开始处理个人敏感数据,比如敏感用户活动日志、财务信息、健康记录或电子邮件时
-
当一个组织需要建立高度安全的环境或定制技术,比如在网页浏览器中定制安全功能时
-
当法规要求遵守标准(比如萨班斯-奥克斯法案、PCI DSS 或 GDPR)或相关审计时
-
当一个组织与客户有合同要求,尤其是关于泄露通知或最低安全标准的要求时
-
在妥协或数据泄露期间或之后(理想情况下是之前)
-
作为对同行业内同行妥协的反应
总的来说,你会希望在满足这些条件之前,尤其是在数据泄露之前,就开始着手处理安全问题!在这样的事件发生之前实现安全措施要比之后简单得多。例如,如果你的公司计划推出一个接受在线支付的新产品,你可能需要考虑为该功能选择一个专业的供应商。审查供应商并确保他们有良好的数据处理实践将需要时间。
想象一下,你选择了一个集成在线支付系统不安全的供应商。数据泄露可能会导致法规罚款、客户信任的丧失,以及工程师重新实现系统的生产力损失。许多组织在此类事件后停止存在。
同样,想象一下,你的公司正在与一个有额外数据处理要求的合作伙伴签订新合同。假设,你的法律团队可能会建议你在签署合同之前实现这些要求。如果你延迟了额外的保护措施,并因此遭受了泄露,会发生什么?
在考虑安全计划的成本和公司可以投入该计划的资源时,通常会出现相关问题:实现安全的成本有多高,公司是否负担得起?虽然本章无法深入探讨这个非常复杂的话题,但我们将强调两个主要的要点。
首先,为了使安全有效,必须仔细平衡组织的其他要求。为了让这一准则更具体化,我们可以通过关闭数据中心、网络、计算设备等来使谷歌几乎 100%免受恶意行为的影响。虽然这样做可以实现高水平的安全性,但谷歌将不再拥有客户,并将消失在失败公司的历史中。可用性是安全的核心原则!为了制定合理的安全策略,你需要了解业务运营所需的内容(对于大多数公司来说,赚取利润所需的内容)。找到业务需求和充分的安全控制之间的平衡。
其次,安全是每个人的责任。你可以通过将一些安全流程分配给受影响最严重的团队来降低一些安全流程的成本。例如,考虑一个公司有六个产品,每个产品都有一个产品团队,并由 20 个防火墙保护。在这种情况下,一个常见的方法是让一个中央安全团队维护所有 120 个防火墙的配置。这种设置要求安全团队对六种不同产品有广泛的了解——这是导致最终可靠性问题或系统变更延迟的原因,所有这些都会增加你的安全计划的成本。另一种方法是将操作自动配置系统的责任分配给安全团队,该系统接受、验证、批准并推送六个产品团队提出的防火墙变更。这样,每个产品团队都可以有效地提出小的变更供审查,并扩展配置过程。这种优化可以节省时间,甚至通过在人为参与之前及时发现错误来提高系统的可靠性。
由于安全是组织生命周期的一个重要组成部分,组织的非技术领域也需要早期考虑安全。例如,董事会经常审查他们监督的实体的安全和隐私实践。在数据泄露后的诉讼中,比如 2017 年对雅虎的股东诉讼,正在推动这一趋势。在准备安全路线图时,一定要考虑这些类型的利益相关者在您的流程中。
最后,重要的是建立维持对当前问题及其优先级的持续理解的流程。当安全被视为一个持续的过程时,就需要对企业面临的风险进行持续评估。为了随着时间的推移迭代深度防御安全控制,您需要将风险评估纳入软件开发生命周期和安全实践中。接下来的部分将讨论一些实际的策略。
嵌入安全专家和安全团队
多年来,我们看到许多公司在组织内部的哪里嵌入安全专家和安全团队进行了实验。这些配置范围从完全嵌入产品团队内的安全专家(参见第十九章)到完全集中的安全团队。谷歌的中央安全团队在组织上配置为这两种选项的混合体。
许多公司在决策方面也有不同的问责安排。我们看到首席信息安全官(CISO)和其他负责安全的领导角色向几乎每个 C 级高管汇报:CEO、CFO、CIO 或 COO、公司的总法律顾问、工程副总裁,甚至 CSO(首席安全官,通常也负责物理安全)。没有正确或错误的配置,您的组织所做的选择将高度依赖于对您的安全工作最有效的因素。
本节的其余部分提供了多年来我们成功使用的配置选项的一些细节。虽然我们是一家大型科技公司,但其中许多组件在中小型组织中也同样有效。但是,我们想象这种配置可能不适用于金融公司或公用事业公司,那里对安全的问责可能有不同的利益相关者和驱动因素。您的情况可能有所不同。
示例:在谷歌嵌入安全
在谷歌,我们首先建立了一个作为产品工程同行的中央安全组织。该组织的负责人是工程部门的高级领导(副总裁)。这创造了一个报告结构,其中安全被视为工程的盟友,但也允许安全团队有足够的独立性来提出问题并解决冲突,而不会受到其他领导可能存在的利益冲突的影响。这类似于谷歌的 SRE 组织与产品开发团队保持独立的报告链的方式。通过这种方式,我们建立了一个专注于改进的开放和透明的参与模型。否则,您可能会面临以下特点的团队:
-
由于发布被过度优先考虑,无法提出严重问题
-
被视为需要通过沉默发布来规避的阻碍门
-
由于文档不足或代码访问受限而放缓
谷歌的中央安全团队依赖于标准流程,如工单系统,与组织的其他部门进行交互,当团队需要请求设计审查、访问控制变更等。要了解这个工作流程的运作方式,请参见“谷歌的智能引入系统”。
随着谷歌的发展,将“安全冠军”嵌入到各个产品工程对等组中也变得很有用。安全冠军成为促进中央安全团队和产品团队合作的门户。在开始时,这个角色非常适合在组织中地位良好并对安全感兴趣或有安全背景的高级工程师。这些工程师还成为产品安全倡议的技术负责人。随着产品团队变得更加复杂,这个角色被分配给高级决策者,如董事或副总裁,这个人可以做出艰难的决定(比如在发布和安全修复之间取得平衡),获取资源并解决冲突。
在安全冠军模型中,建立和达成参与流程和责任非常重要。例如,中央团队可能会继续进行设计审查和审核,制定组织范围的安全政策和标准,构建安全的应用程序框架(见第十三章),并设计最小权限方法等共同基础设施(见第五章)。分布式安全冠军是这些活动的关键利益相关者,并应帮助决定这些控制在其产品团队中的工作方式。安全冠军还推动其各自产品团队内的政策、框架、基础设施和方法的实现。这种组织配置需要通过团队宪章、跨职能会议、邮件列表、聊天频道等建立紧密的沟通循环。
由于谷歌和 Alphabet 规模庞大,除了中央安全团队和分布式安全冠军外,我们还为更复杂的产品设立了特殊的分散安全团队。例如,Android 安全团队位于 Android 工程组织内。Chrome 也有类似的模式(见第十九章)。这意味着 Android 和 Chrome 安全团队负责其各自产品的端到端安全,包括决定产品特定的标准、框架、基础设施和方法。这些专门的安全团队运行产品安全审查流程,并有特殊的程序来加固产品。例如,Android 安全团队已经努力加固了媒体堆栈,并从集成的安全和工程方法中受益。
在所有这些模型中,安全团队的开放和可接近性非常重要。除了安全审查流程外,在项目生命周期中,开发人员需要及时和一致的安全相关问题反馈,以便从专业人员那里获得帮助。我们在第二十一章中解决了许多关于这些互动的文化问题。
特殊团队:蓝队和红队
安全团队通常使用颜色来标记他们在保护组织中的角色。所有这些以颜色编码的团队都致力于共同的目标,即改善公司的安全姿态。
蓝队主要负责评估和加固软件和基础设施。他们还负责在成功攻击发生时进行检测、封锁和恢复。蓝队成员可以是组织中任何一个致力于保卫组织的人,包括构建安全可靠系统的人。
红队进行攻击性安全演练:模拟真实对手的端到端攻击。这些演练揭示了组织防御的弱点,并测试其检测和防御攻击的能力。
通常,红队关注以下内容:
特定目标
例如,红队可能试图利用客户账户数据(或更具体地说,找到并将客户账户数据外泄到一个安全的目的地)。这些练习与对手的操作方式非常相似。
监视
目的是确定你的检测方法是否能够检测到对手的侦察行为。监视也可以作为未来目标导向参与的地图。
定向攻击
目的是证明那些据称是理论的、极不可能被利用的安全问题的利用是可行的。因此,你可以确定哪些问题值得建立防御。
在开始红队计划之前,一定要确保获得可能受到这些练习影响的组织部分的支持,包括法律和高管。这也是定义边界的好时机——例如,红队不应访问客户数据或干扰生产服务,并且他们应该使用数据窃取和服务中断的近似值(例如,只通过破坏测试账户的数据)。这些边界需要在进行真实练习和建立合作团队可以接受的时间和范围之间取得平衡。当然,你的对手不会尊重这些边界,所以红队应该特别注意那些没有得到很好保护的关键领域。
一些红队会与蓝队分享他们的攻击计划,并与他们密切合作,以快速全面地了解检测情况。这种关系甚至可以通过一个紫队来正式化,桥接这两者。如果你正在进行许多练习并希望快速行动,或者想要将红队活动分配给产品工程师,这可能会很有用。这种配置也可以激发红队去寻找他们可能不会考虑的地方。设计、实现和维护系统的工程师最了解系统,并且通常对系统的弱点有直观的认识。
红队不是漏洞扫描或渗透测试团队。漏洞扫描团队寻找软件和配置中可预测和已知的弱点,可以自动扫描。渗透测试团队更专注于发现大量的漏洞和测试人员试图利用它们。他们的范围更窄,专注于特定产品、基础设施组件或流程。由于这些团队主要测试组织安全防御的预防和一些检测方面,他们的典型参与持续几天。
相比之下,红队的参与是目标导向的,通常持续几周。他们的目标是特定的目标,比如知识产权或客户数据的外泄。他们的范围广泛,使用任何必要手段来实现他们的目标(在安全限制内),穿越产品、基础设施和内部/外部边界。
在一定时间内,优秀的红队可以实现他们的目标,通常不会被发现。与其将成功的红队攻击视为对糟糕或无效的业务部门的评判,不如利用这些信息以无过失的方式更好地了解一些更复杂的系统。利用红队练习的机会更好地了解这些系统是如何相互连接和共享信任边界的。红队旨在帮助加强威胁模型并建立防御。
注意
由于他们并不完全模仿外部攻击者的行为,红队攻击并不是对你的检测和响应能力的完美测试。特别是如果红队由对系统已有知识的内部工程师组成,这一点尤为真实,因为他们试图渗透的系统。
您也不可能频繁地进行红队攻击,以提供对攻击的实时视图或对检测和响应团队的统计显著指标。红队旨在发现正常测试无法发现的罕见边缘情况。尽管存在所有的警告,定期进行红队演习是了解您的安全姿态的一种好方法。
您还可以利用红队来教导设计、实现和维护系统的人员对抗敌对心态。直接将这些人员嵌入攻击团队,例如通过一个小范围的项目,将使他们第一手了解攻击者如何审查系统可能存在的漏洞并绕过防御。他们可以在以后将这些知识注入团队的开发过程中。
与红队合作有助于更好地了解您的组织安全姿态,并制定实现有意义的风险降低项目的路线图。通过了解您当前的风险容忍度的影响,您可以确定是否需要进行调整。
外部研究人员
检查和改进您的安全姿态的另一种方法是与发现系统漏洞的外部研究人员和爱好者密切合作。正如我们在第二章中提到的,这是了解您的系统的一种有用方式。
许多公司通过建立“漏洞奖励计划(VRPs)”与外部研究人员合作,也俗称为“漏洞赏金计划”。这些计划提供奖励,以换取对系统漏洞的负责披露,这些奖励可能是现金形式,也可能不是。? Google 的第一个 VRP 始于 2006 年,提供了一件 T 恤和一个简单的感谢信息放在我们的公共网页上。通过奖励计划,您可以扩大对安全相关漏洞的搜索范围,超出您的直接组织,并与更多的安全研究人员合作。
在开始 VRP 之前,首先了解找到和解决常规安全问题的基础知识,通过彻底的审查和基本的漏洞扫描可以找到。否则,您最终会支付外部人员来发现您自己的团队本来可以轻松发现的漏洞。这不是 VRP 的预期目的。它还有一个缺点,即可能有多个研究人员向您报告同一个问题。
了解如何建立漏洞赏金计划需要一些前期工作。如果选择运行漏洞赏金计划,可以按照以下基本步骤进行:
-
确定您的组织是否准备好进行这项计划。
-
确定系统的目标范围。例如,您可能无法针对公司系统。
-
确定支付水平并留出资金用于支付。1?
-
考虑是否要运行内部漏洞赏金计划或者雇佣专门从事这些计划的组织。
-
如果要自己运行,建立漏洞接收、分类、调查、验证、跟进和修复的流程。根据我们的经验,您可以估计这个过程大约需要 40 个小时来处理每个严重的问题,不包括修复。
-
制定付款流程。记住,报告者可能来自世界各地,而不仅仅是您的本国。您需要与您的法律和财务团队合作,了解您的组织可能存在的任何限制。
-
启动,学习和迭代。
每个漏洞赏金计划都面临一些可能的挑战,包括以下内容:
需要调整被报告问题的火管
根据您的行业声誉、攻击面、支付金额和发现漏洞的难易程度,您可能会收到大量报告。事先了解您的组织需要做出怎样的响应。
报告质量差
如果大多数工程师都在追踪基本问题或非问题,那么赏金计划可能会变得繁重。我们发现这对于 Web 服务尤其如此,因为许多用户配置错误的浏览器并且“发现”了实际上并不是 bug 的 bug。安全研究人员不太可能出现在这个范围内,但有时很难事先辨别 bug 报告者的资格。
语言障碍
漏洞研究人员不一定会用您的母语向您报告 bug。语言翻译工具在这里可能会有所帮助,或者您的组织可能有人了解报告者使用的语言。
漏洞披露指南
披露漏洞的规则并没有得到普遍认同。研究人员应该公开他们所知道的吗,如果是的话,何时?研究人员应该给您的组织多长时间来修复 bug?哪些类型的发现会得到奖励,哪些类型不会?在这里有许多不同意见的“正确”方法。以下是一些进一步阅读的建议:
-
谷歌安全团队已经撰写了一篇关于负责任披露的博客文章。11
-
Project Zero 是谷歌内部的漏洞研究团队,他们也撰写了一篇关于数据驱动披露政策更新的博客文章。
-
奥卢大学安全编程小组提供了一系列有用的漏洞披露出版物。
-
国际标准化组织(ISO)提供了漏洞披露的建议。
准备好及时解决研究人员向您报告的问题。还要意识到他们可能发现已被恶意行为者积极利用了一段时间的问题,在这种情况下,您可能还需要解决安全漏洞。
结论
安全和可靠性是由流程和实践的质量或缺失所创造的。人是这些流程和实践最重要的推动者。有效的员工能够跨角色、部门和文化边界进行协作。我们生活在一个未知未来且对手不可预测的世界。在一天结束时,确保您组织中的每个人都对安全和可靠性负责是最好的防御!
1 在 SRE 工作手册的第十八章中描述的发展轨迹展示了经验丰富的 SRE 在整个产品生命周期中提供的价值。
2 2002 年的萨班斯-奥克斯法案(公众公司会计改革和投资者保护法)为美国上市公司设定了有关其会计实践的标准,并包括信息安全主题。支付卡行业数据安全标准为保护信用卡信息设定了最低指导方针;任何进行此类支付处理的人都需要遵守合规要求。《通用数据保护条例》是一项关于个人数据处理的欧盟法规。
3 一些知名的组织在遭受攻击后破产或申请破产,比如 Code Spaces 和美国医疗收费机构。
? 在美国,高管和董事会越来越被迫对其组织的安全负责。普渡大学康科德法学院撰写了一篇关于这一趋势的好文章。
? 参见 SRE 书中的第 31 章。
? 这种颜色方案源自美国军方。
? 欲了解更多有关紫队的信息,请参阅 Brotherston, Lee, 和 Amanda Berlin 所著的 2017 年作品Defensive Security Handbook: Best Practices for Securing Infrastructure。Sebastopol, CA: O’Reilly Media。
? 通过在无过失的事后分析文化基础上建立,如SRE 书籍第十五章所述。
? 请参阅谷歌研究员 sirdarckcat 的有关奖励的博客文章,以获得更多哲学观点。
1? 欲进一步阅读,请参阅 sirdarckcat 关于漏洞定价的文章。
11 sirdarckcat 还撰写了一篇关于漏洞披露的文章。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 目标检测YOLO实战应用案例100讲-基于深度学习的实时车道线与目标检测多任务实现(下)
- 基于 InternLM 和 LangChain 搭建你的知识库
- Matplotlib_4.文字图例尽眉目
- MYSQL篇--索引高频面试题
- 面试必备!机器学习模型全面总结!
- 数字化转型的必备工具——易点易动固定资产管理系统
- 用React给XXL-JOB开发一个新皮肤(一):环境搭建和项目初始化
- 解决指指针指向头节点进行free操作之后头节点丢失问题
- C++经典程序
- 工业计算机应用——物流行业