机器学习与模式处理头歌实训
机器学习 --- 模型评估、选择与验证
第1关:为什么要有训练集与测试集
1、下面正确的是?
A、将手头上所有的数据拿来训练模型,预测结果正确率最高的模型就是我们所要选的模型。
B、将所有数据中的前百分之70拿来训练模型,剩下的百分之30作为测试集,预测结果正确率最高的模型就是我们所要选的模型。
C、将所有数据先随机打乱顺序,一半用来训练模型,一半作为测试集,预测结果正确率最高的模型就是我们所要选的模型。
D、将所有数据先随机打乱顺序,百分之80用来训练模型,剩下的百分之20作为测试集,预测结果正确率最高的模型就是我们所要选的模型。
2、训练集与测试集的划分对最终模型的确定有无影响?
A、有
B、无
1、D? ? ? ? 2、A
第2关:欠拟合与过拟合
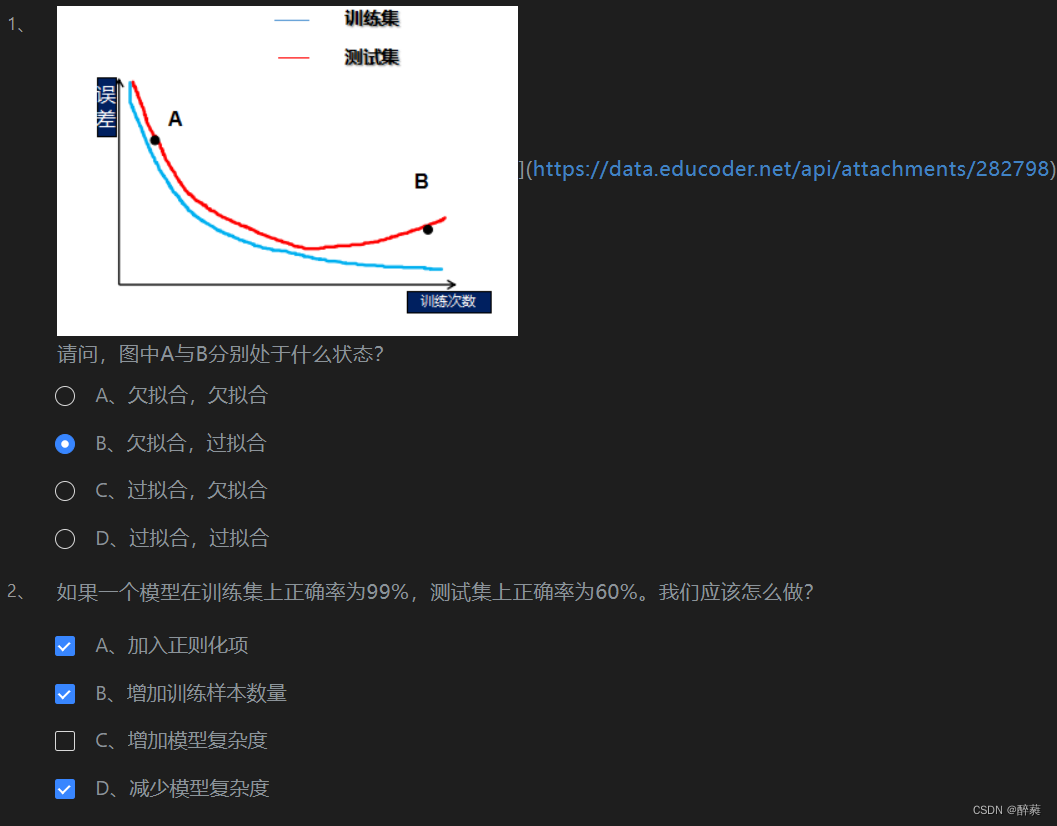 ?第3关:偏差与方差
?第3关:偏差与方差
1、如果一个模型,它在训练集上正确率为85%,测试集上正确率为80%,则模型是过拟合还是欠拟合?其中,来自于偏差的误差为?来自方差的误差为?
A、欠拟合,5%,5%? ? ? ? ? ? ? ? ? ? ? ?√? B、欠拟合,15%,5%
C、过拟合,15%,15%? ? ? ? ? ? ? ? ? ?D、过拟合,5%,5%
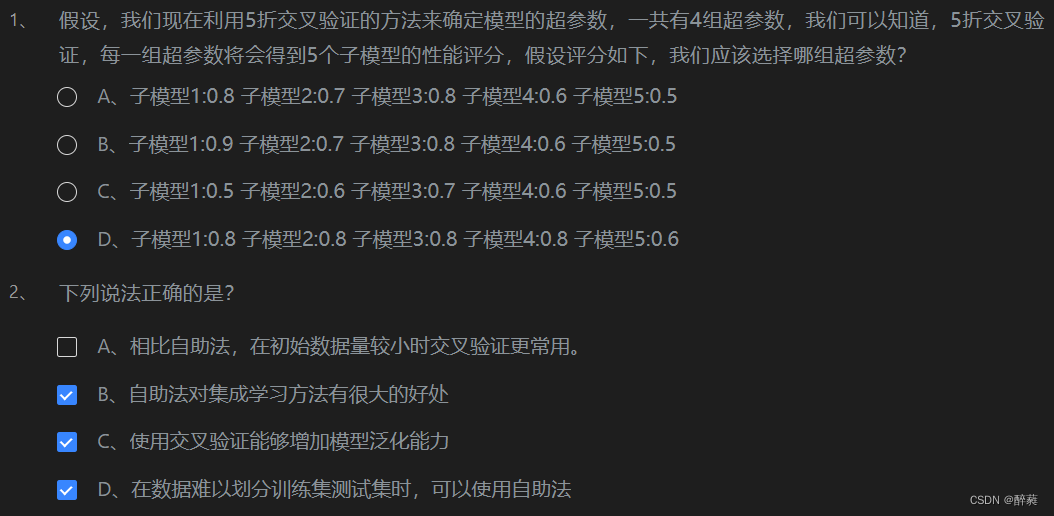
第4关:验证集与交叉验证
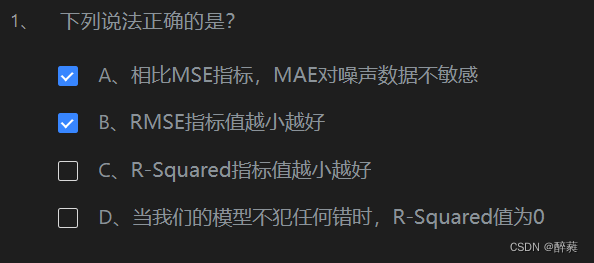
第5关:衡量回归的性能指标
 ?
?
第6关:准确度的陷阱与混淆矩阵
任务描述
本关任务:填写 python 代码,完成 confusion_matrix 函数实现二分类混淆矩阵的构建。
import numpy as np
def confusion_matrix(y_true, y_predict):
'''
构建二分类的混淆矩阵,并将其返回
:param y_true: 真实类别,类型为ndarray
:param y_predict: 预测类别,类型为ndarray
:return: shape为(2, 2)的ndarray
'''
#********* Begin *********#
def TN(y_true, y_predict):
return np.sum((y_true == 0) & (y_predict == 0))
def FP(y_true, y_predict):
return np.sum((y_true == 0) & (y_predict == 1))
def FN(y_true, y_predict):
return np.sum((y_true == 1) & (y_predict == 0))
def TP(y_true, y_predict):
return np.sum((y_true == 1) & (y_predict == 1))
return np.array([
[TN(y_true, y_predict), FP(y_true, y_predict)],
[FN(y_true, y_predict), TP(y_true, y_predict)]
])
#********* End *********#
?第7关:精准率与召回率
任务描述
本关任务:填写 python 代码,完成 precision_score 函数和 recall_score 函数分别实现计算精准率和召回率。
相关知识
为了完成本关任务,你需要掌握:
- 精准率;
- 召回率。
import numpy as np
def precision_score(y_true, y_predict):
'''
计算精准率并返回
:param y_true: 真实类别,类型为ndarray
:param y_predict: 预测类别,类型为ndarray
:return: 精准率,类型为float
'''
#********* Begin *********#
def TP(y_true, y_predict):
return np.sum((y_true ==1)&(y_predict == 1))
def FP(y_true,y_predict):
return np.sum((y_true ==0)&(y_predict==1))
tp =TP(y_true, y_predict)
fp =FP(y_true, y_predict)
try:
return tp /(tp+fp)
except:
return 0.0
#********* End *********#
def recall_score(y_true, y_predict):
'''
计算召回率并召回
:param y_true: 真实类别,类型为ndarray
:param y_predict: 预测类别,类型为ndarray
:return: 召回率,类型为float
'''
#********* Begin *********#
def FN(y_true, y_predict):
return np.sum((y_true ==1)&(y_predict == 0))
def TP(y_true,y_predict):
return np.sum((y_true ==1)&(y_predict==1))
fn =FN(y_true, y_predict)
tp =TP(y_true, y_predict)
try:
return tp /(tp+fn)
except:
return 0.0
#********* End *********#
第8关:F1 Score
任务描述
本关任务:填写 python 代码,完成 f1_score 函数实现计算 F1 Score。
import numpy as np
def f1_score(precision, recall):
'''
计算f1 score并返回
:param precision: 模型的精准率,类型为float
:param recall: 模型的召回率,类型为float
:return: 模型的f1 score,类型为float
'''
#********* Begin *********#
try:
return 2*precision*recall / (precision+recall)
except:
return 0.0
#********* End ***********#
?第9关:ROC曲线与AUC
任务描述
本关任务:填写 python 代码,完成 AUC 函数实现计算 AUC。
import numpy as np
def calAUC(prob, labels):
'''
计算AUC并返回
:param prob: 模型预测样本为Positive的概率列表,类型为ndarray
:param labels: 样本的真实类别列表,其中1表示Positive,0表示Negtive,类型为ndarray
:return: AUC,类型为float
'''
#********* Begin *********#
a= list(zip(prob,labels))
rank =[values2 for values1,values2 in sorted(a, key=lambda x:x[0])]
rankList=[i+1 for i in range(len(rank))if rank[i] ==1]
posNum =0
negNum =0
for i in range(len(labels)):
if(labels[i]==1):
posNum+=1
else:
negNum+=1
auc= (sum(rankList)-(posNum*(posNum+1))/2)/(posNum*negNum)
return auc
#********* End *********#
第10关:sklearn中的分类性能指标
任务描述
本关任务:使用 sklearn 完成对模型分类性能的评估。
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, roc_auc_score
def classification_performance(y_true, y_pred, y_prob):
'''
返回准确度、精准率、召回率、f1 Score和AUC
:param y_true:样本的真实类别,类型为`ndarray`
:param y_pred:模型预测出的类别,类型为`ndarray`
:param y_prob:模型预测样本为`Positive`的概率,类型为`ndarray`
:return:
'''
#********* Begin *********#
return accuracy_score(y_true, y_pred),precision_score(y_true, y_pred),recall_score(y_true, y_pred),f1_score(y_true, y_pred),roc_auc_score(y_true, y_prob)
#********* End *********#
机器学习 --- 绪论
第1关:什么是机器学习
第2关:机器学习的常见术语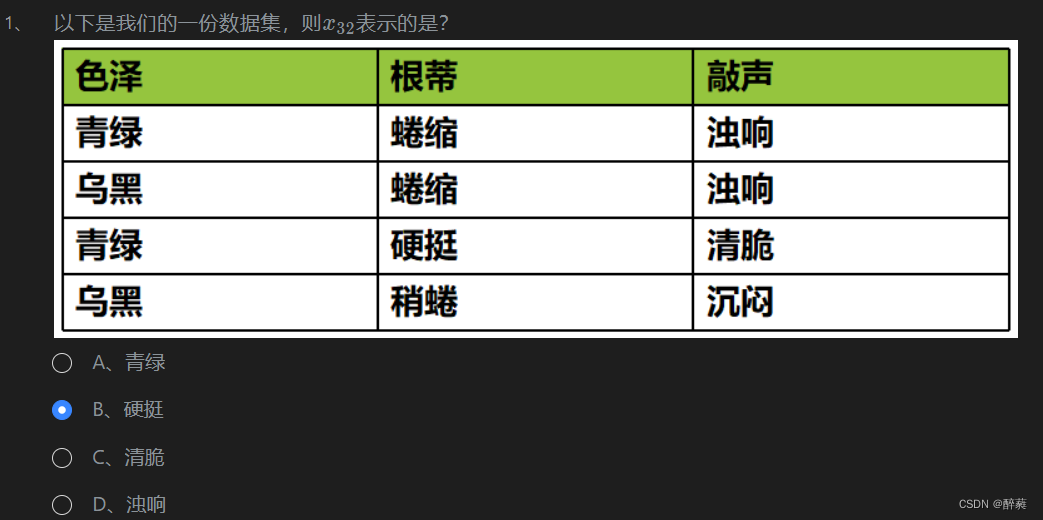 ?
?
第3关:机器学习的主要任务?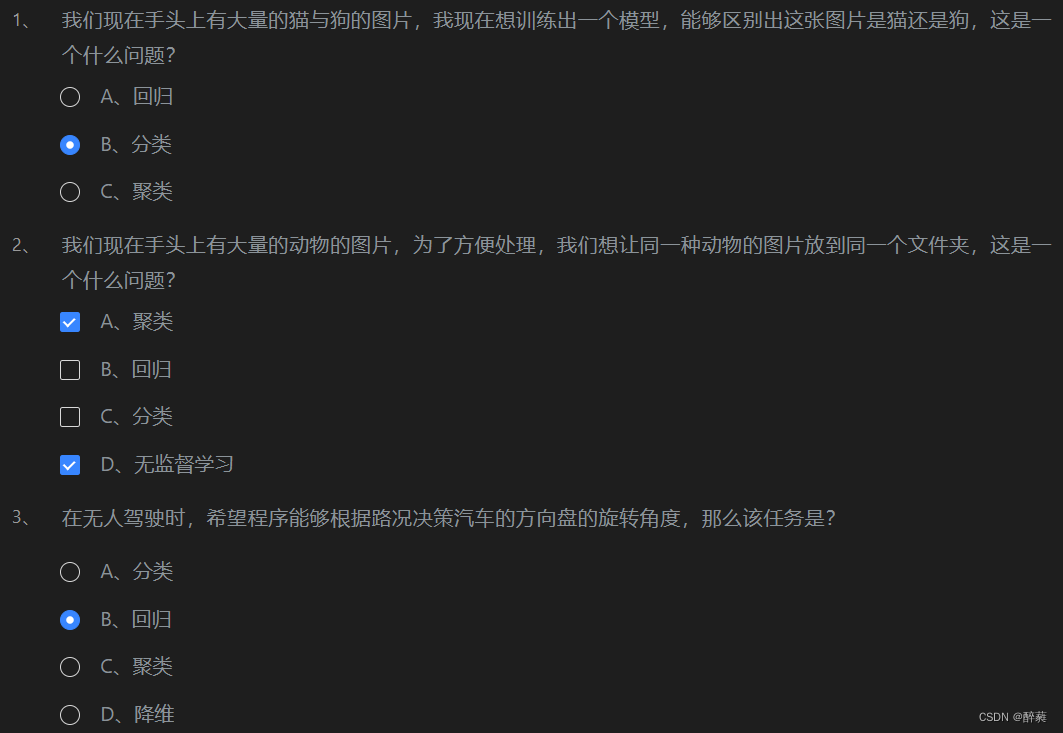
机器学习 --- 朴素贝叶斯分类器?
第1关:条件概率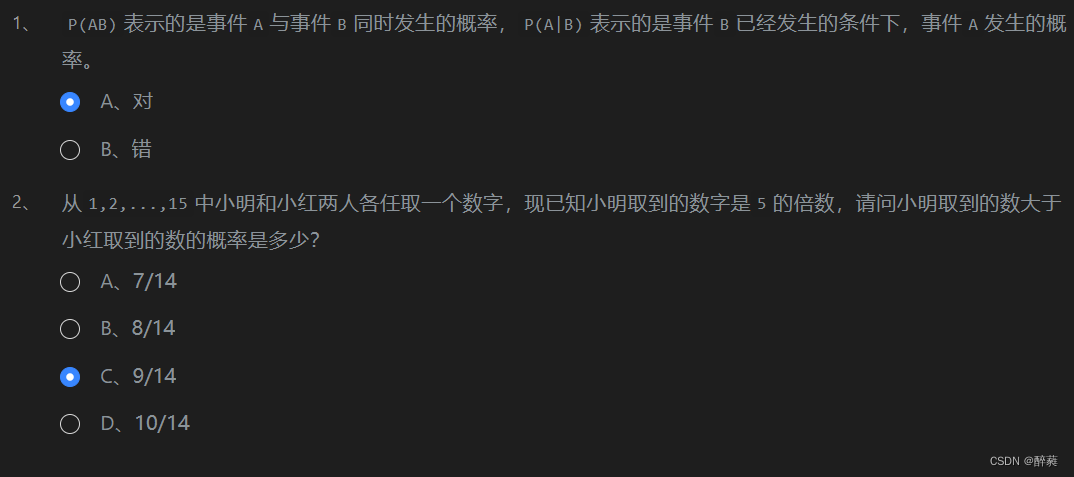
第2关:贝叶斯公式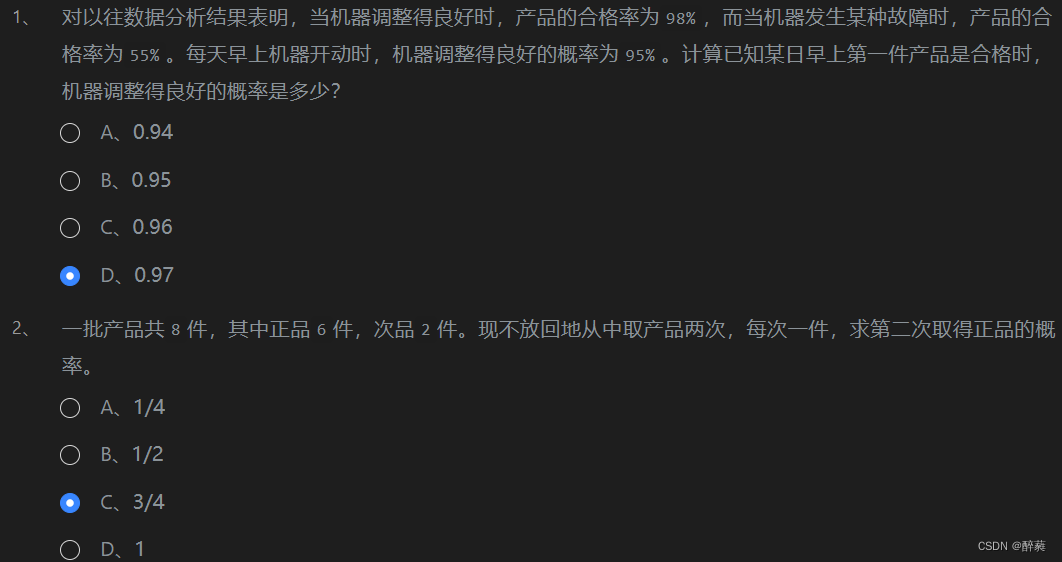 第3关:朴素贝叶斯分类算法流程
第3关:朴素贝叶斯分类算法流程
任务描述
本关任务:填写
python代码,完成fit与predict函数,分别实现模型的训练与预测。
import numpy as np
class NaiveBayesClassifier(object):
def __init__(self):
'''
self.label_prob表示每种类别在数据中出现的概率
例如,{0:0.333, 1:0.667}表示数据中类别0出现的概率为0.333,类别1的概率为0.667
'''
self.label_prob = {}
'''
self.condition_prob表示每种类别确定的条件下各个特征出现的概率
例如训练数据集中的特征为 [[2, 1, 1],
[1, 2, 2],
[2, 2, 2],
[2, 1, 2],
[1, 2, 3]]
标签为[1, 0, 1, 0, 1]
那么当标签为0时第0列的值为1的概率为0.5,值为2的概率为0.5;
当标签为0时第1列的值为1的概率为0.5,值为2的概率为0.5;
当标签为0时第2列的值为1的概率为0,值为2的概率为1,值为3的概率为0;
当标签为1时第0列的值为1的概率为0.333,值为2的概率为0.666;
当标签为1时第1列的值为1的概率为0.333,值为2的概率为0.666;
当标签为1时第2列的值为1的概率为0.333,值为2的概率为0.333,值为3的概率为0.333;
因此self.label_prob的值如下:
{
0:{
0:{
1:0.5
2:0.5
}
1:{
1:0.5
2:0.5
}
2:{
1:0
2:1
3:0
}
}
1:
{
0:{
1:0.333
2:0.666
}
1:{
1:0.333
2:0.666
}
2:{
1:0.333
2:0.333
3:0.333
}
}
}
'''
self.condition_prob = {}
def fit(self, feature, label):
'''
对模型进行训练,需要将各种概率分别保存在self.label_prob和self.condition_prob中
:param feature: 训练数据集所有特征组成的ndarray
:param label:训练数据集中所有标签组成的ndarray
:return: 无返回
'''
#********* Begin *********#
row_num=len(feature)
col_num=len(feature[0])
for c in label:
if c in self.label_prob:
self.label_prob[c]+=1;
else:
self.label_prob[c]=1;
for key in self.label_prob.keys():
self.label_prob[key]/=row_num
self.condition_prob[key]={}
for i in range(col_num):
self.condition_prob[key][i]={}
for k in np.unique(feature[:,i],axis=0):
self.condition_prob[key][i][k]=0
for i in range(len(feature)):
for j in range(len(feature[i])):
if feature[i][j] in self.condition_prob[label[i]]:
self.condition_prob[label[i]][j][feature[i][j]]+=1
else:
self.condition_prob[label[i]][j][feature[i][j]]=1
for label_key in self.condition_prob.keys():
for k in self.condition_prob[label_key].keys():
total=0
for v in self.condition_prob[label_key][k].values():
total+=v
for kk in self.condition_prob[label_key][k].keys():
self.condition_prob[label_key][k][kk]/=total
#********* End *********#
def predict(self, feature):
'''
对数据进行预测,返回预测结果
:param feature:测试数据集所有特征组成的ndarray
:return:
'''
# ********* Begin *********#
result=[]
for i,f in enumerate(feature):
prob=np.zeros(len(self.label_prob.keys()))
ii=0
for label,label_prob in self.label_prob.items():
prob[ii]=label_prob
for j in range(len(feature[0])):
prob[ii]*=self.condition_prob[label][j][f[j]]
ii+=1
result.append(list(self.label_prob.keys())[np.argmax(prob)])
return np.array(result)
#********* End *********#
第4关:拉普拉斯平滑
任务描述
本关任务:填写
python代码,完成fit函数,实现模型训练功能。**(PS:fit函数中没有平滑处理的话是过不了关的哦)**
import numpy as np
class NaiveBayesClassifier(object):
def __init__(self):
'''
self.label_prob表示每种类别在数据中出现的概率
例如,{0:0.333, 1:0.667}表示数据中类别0出现的概率为0.333,类别1的概率为0.667
'''
self.label_prob = {}
'''
self.condition_prob表示每种类别确定的条件下各个特征出现的概率
例如训练数据集中的特征为 [[2, 1, 1],
[1, 2, 2],
[2, 2, 2],
[2, 1, 2],
[1, 2, 3]]
标签为[1, 0, 1, 0, 1]
那么当标签为0时第0列的值为1的概率为0.5,值为2的概率为0.5;
当标签为0时第1列的值为1的概率为0.5,值为2的概率为0.5;
当标签为0时第2列的值为1的概率为0,值为2的概率为1,值为3的概率为0;
当标签为1时第0列的值为1的概率为0.333,值为2的概率为0.666;
当标签为1时第1列的值为1的概率为0.333,值为2的概率为0.666;
当标签为1时第2列的值为1的概率为0.333,值为2的概率为0.333,值为3的概率为0.333;
因此self.label_prob的值如下:
{
0:{
0:{
1:0.5
2:0.5
}
1:{
1:0.5
2:0.5
}
2:{
1:0
2:1
3:0
}
}
1:
{
0:{
1:0.333
2:0.666
}
1:{
1:0.333
2:0.666
}
2:{
1:0.333
2:0.333
3:0.333
}
}
}
'''
self.condition_prob = {}
def fit(self, feature, label):
'''
对模型进行训练,需要将各种概率分别保存在self.label_prob和self.condition_prob中
:param feature: 训练数据集所有特征组成的ndarray
:param label:训练数据集中所有标签组成的ndarray
:return: 无返回
'''
#********* Begin *********#
row_num=len(feature)
col_num=len(feature[0])
unique_label_count=len(set(label))
for c in label:
if c in self.label_prob:
self.label_prob[c]+=1
else:
self.label_prob[c]=1
for key in self.label_prob.keys():
self.label_prob[key]+=1
self.label_prob[key]/=(unique_label_count+row_num)
self.condition_prob[key]={}
for i in range(col_num):
self.condition_prob[key][i]={}
for k in np.unique(feature[:,i],axis=0):
self.condition_prob[key][i][k]=1
for i in range(len(feature)):
for j in range(len(feature[i])):
if feature[i][j] in self.condition_prob[label[i]]:
self.condition_prob[label[i]][j][feature[i][j]]+=1
for label_key in self.condition_prob.keys():
for k in self.condition_prob[label_key].keys():
total=len(self.condition_prob[label_key][k].keys())
for v in self.condition_prob[label_key][k].values():
total+=v
for kk in self.condition_prob[label_key][k].keys():
self.condition_prob[label_key][k][kk]/=total
#********* End *********#
def predict(self, feature):
'''
对数据进行预测,返回预测结果
:param feature:测试数据集所有特征组成的ndarray
:return:
'''
result = []
# 对每条测试数据都进行预测
for i, f in enumerate(feature):
# 可能的类别的概率
prob = np.zeros(len(self.label_prob.keys()))
ii = 0
for label, label_prob in self.label_prob.items():
# 计算概率
prob[ii] = label_prob
for j in range(len(feature[0])):
prob[ii] *= self.condition_prob[label][j][f[j]]
ii += 1
# 取概率最大的类别作为结果
result.append(list(self.label_prob.keys())[np.argmax(prob)])
return np.array(result)
第5关:新闻文本主题分类
任务描述
本关任务:使用
sklearn完成新闻文本主题分类任务。
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.feature_extraction.text import TfidfTransformer
def news_predict(train_sample, train_label, test_sample):
'''
训练模型并进行预测,返回预测结果
:param train_sample:原始训练集中的新闻文本,类型为ndarray
:param train_label:训练集中新闻文本对应的主题标签,类型为ndarray
:param test_sample:原始测试集中的新闻文本,类型为ndarray
:return 预测结果,类型为ndarray
'''
#********* Begin *********#
vec=CountVectorizer()
train_sample=vec.fit_transform(train_sample)
test_sample=vec.transform(test_sample)
tfidf=TfidfTransformer()
train_sample=tfidf.fit_transform(train_sample)
test_sample=tfidf.transform(test_sample)
mnb=MultinomialNB(alpha=0.01)
mnb.fit(train_sample,train_label)
predict=mnb.predict(test_sample)
return predict
#********* End *********#
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 数据库管理-第126期 如何将数据从11g弄到19c上(202301223)
- 第9章 改进三维曲面图的显示方式-1
- 5.ROC-AUC机器学习模型性能的常用的评估指标
- c++多类别nms
- UML-用例图
- 企微消息群发工具:高效管理企业微信沟通的新宠
- 软通测试岗面试内部资料
- 使用IntelliJ IDEA进行Python开发配置
- 详解C++位图/布隆过滤器+海量数据处理
- 【小白专用】winform启动界面+登录窗口 更新2024.1.1