搜索与图论第一期 DFS(深度优先搜索)
发布时间:2024年01月11日
前言
DFS这部分难度不大,大家应该完全掌握!!!
一、DFS的基本内容
内容:
深度优先遍历图的方法是,从图中某顶点v出发:
(1)访问顶点v;
(2)依次从v的未被访问的邻接点出发,对图进行深度优先遍历;直至图中和v有路径相通的顶点都被访问;
(3)若此时图中尚有顶点未被访问,则从一个未被访问的顶点出发,重新进行深度优先遍历,直到图中所有顶点均被访问过为止
深度优先搜索是一种在开发爬虫早期使用较多的方法。它的目的是要达到被搜索结构的叶结点(即那些不包含任何超链的HTML文件) 。在一个HTML文件中,当一个超链被选择后,被链接的HTML文件将执行深度优先搜索,即在搜索其余的超链结果之前必须先完整地搜索单独的一条链。深度优先搜索沿着HTML文件上的超链走到不能再深入为止,然后返回到某一个HTML文件,再继续选择该HTML文件中的其他超链。当不再有其他超链可选择时,说明搜索已经结束。
模板:
void DFS(int step){
if(满足边界条件){
相应操作
}
for(尝试每种可能){
if(满足条件){
标记
继续下一步DFS(step + 1)
恢复初始状态(回溯的时候需要)
}
}
}二、例题
1.全排列
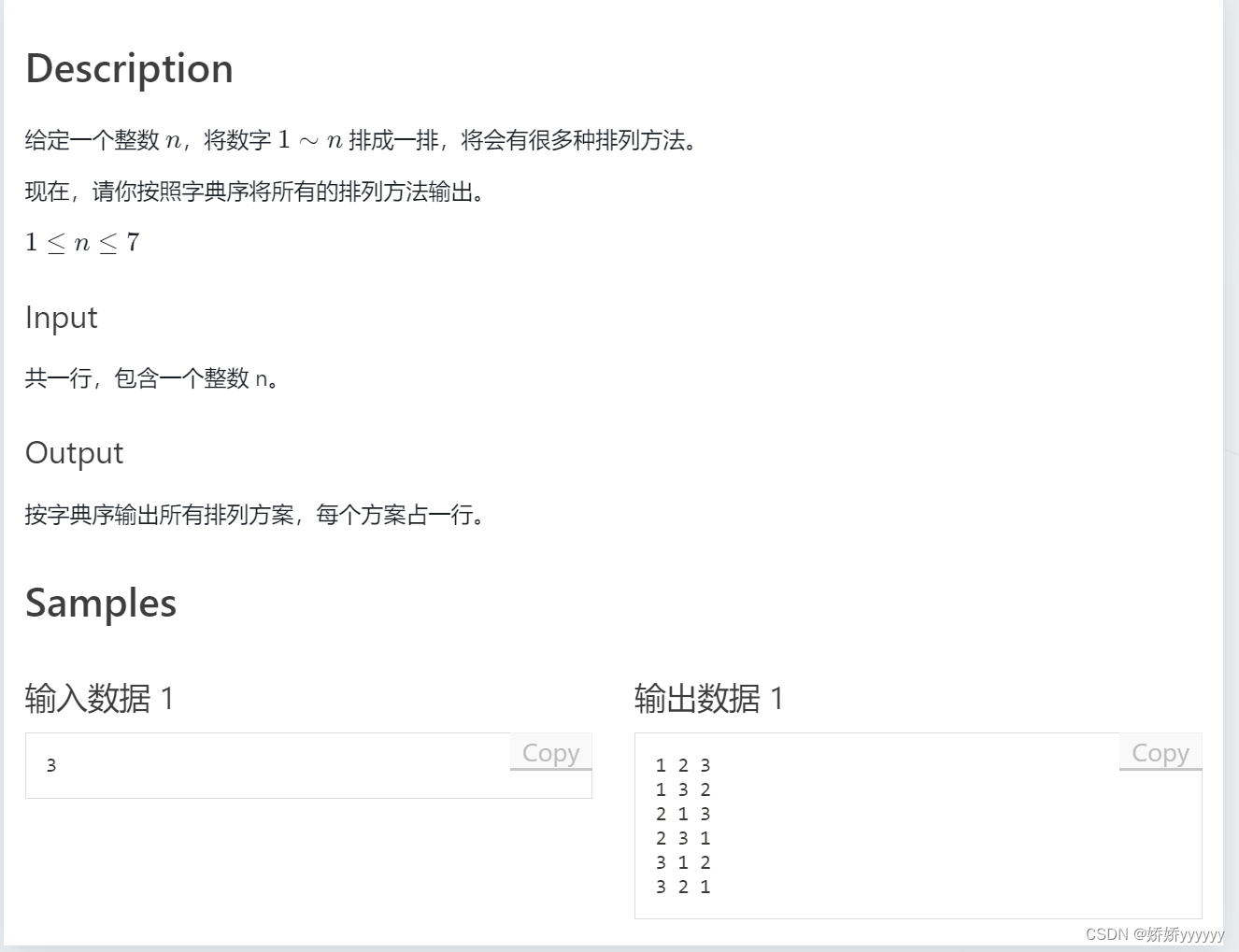
AC代码:
DFS:
#include <iostream>
using namespace std;
const int N = 10;
int n;
int path[N];
bool st[N];//true表示这个点已经用过了,false表示这个点没用过
void dfs(int u) {
if (u == n) {//当走到最后一个位置的时候,说明此时已经把所有位置填满了,就输出
for (int i = 0; i < n; i++)
printf("%d ", path[i]);
puts("");
return ;
}
for (int i = 1; i <= n; i++)//没走到最后一个位置,就枚举一下当前这个位置可以填哪些数
if (!st[i]) {//如果当前这个数没有被用过
path[u] = i;//把i放到当前这个位置上去
st[i] = true;//记录i已经被用过了
dfs(u + 1);//递归到下一层
// path[u] = 0;恢复现场
st[i] = false;//恢复现场
}
}
int main() {
cin >> n;
dfs(0);
return 0;
}调库:
#include<iostream>
using namespace std;
#include<algorithm>
#include<vector>
vector<int>v;
int n;
int main()
{
cin>>n;
for(int i=1;i<=n;i++){
v.push_back(i);
}
do{
for(int i=0;i<n;i++){
cout<<v[i]<<" ";
}
cout<<endl;
}while(next_permutation(v.begin(),v.end()));
return 0;
}2.n皇后问题:
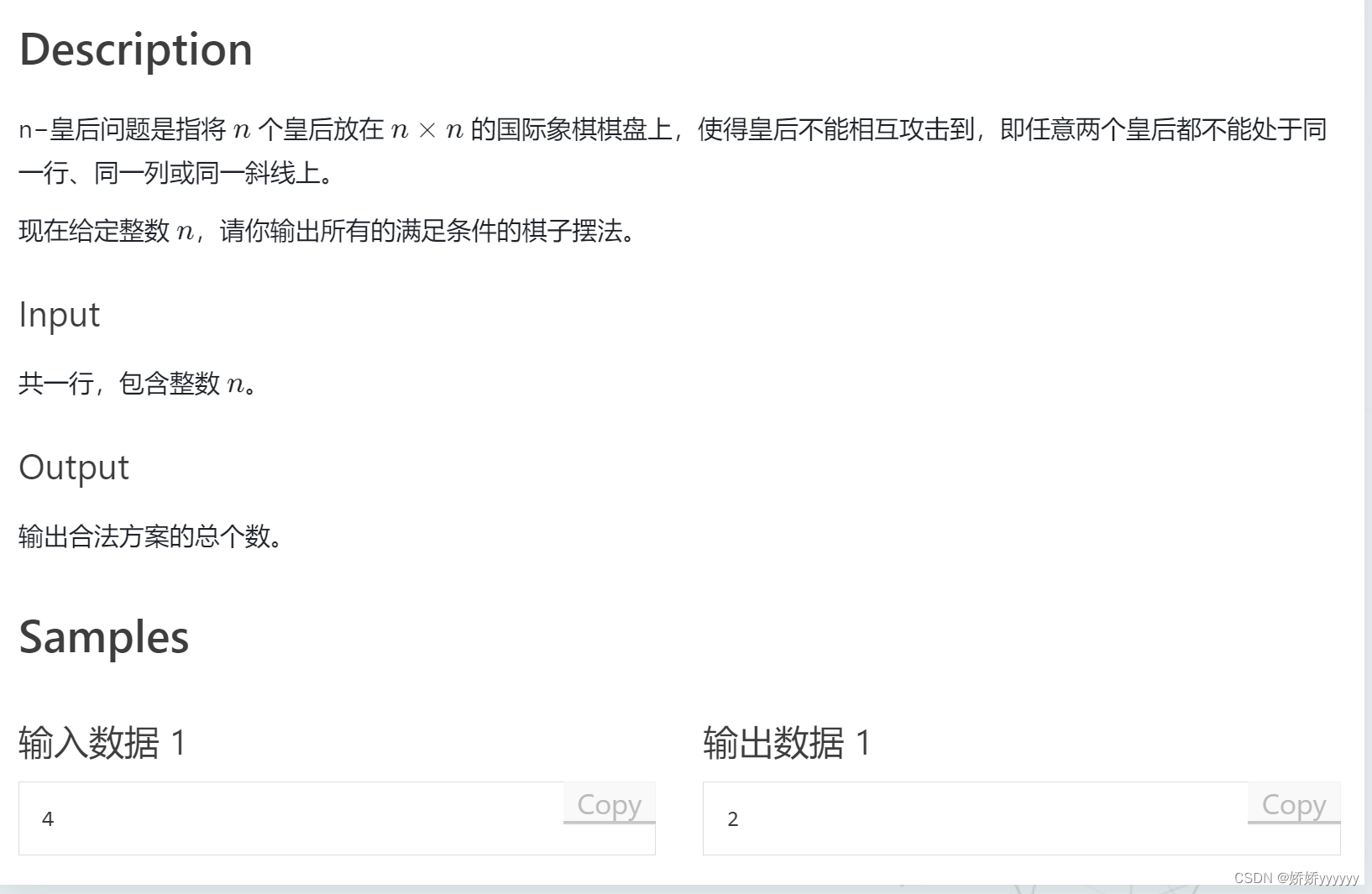
AC代码:
#include<bits/stdc++.h>
using namespace std;
int a[11],n,cnt;
bool check(int x, int y)
{
for(int i=1;i<=x;i++){
if(a[i]==y) return false;
if(a[i]+i==x+y) return false;
if(i-a[i]==x-y) return false;
}//两条对角线 以及列数
return true;
}
void dfs(int row)
{
if(row==n+1){
cnt++;
return ;
}
for(int i=1;i<=n;i++){
if(check(row,i)){
a[row]=i;//row为行 i为列
dfs(row+1);
a[row]=0;
}
}
}
int main()
{
cin>>n;
dfs(1);
cout<<cnt<<endl;
return 0;
}总结
DFS算法还是挺重要的,希望大家能够熟练掌握,感谢大家的观看!!!
文章来源:https://blog.csdn.net/2301_80882026/article/details/135495579
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 你见过哪些目瞪口呆的 Java 代码技巧?
- 用户管理第2节课--idea 2023.2 后端--实现基本数据库操作(操作user表) -- 自动生成 --【本人】
- BAPI_ALM_ORDER_MAINTAIN -- 创建维修工单
- Vue3 将el-table中的数据导出为excel并下载
- 地质灾害监测预警解决方案
- Linux 线程安全 (1)
- 云计算HCIE学习和考试过程经验分享
- 流量卡使用误区:流量卡归属地影响网速?你OUT了
- .NET 8.0 发布到 IIS
- C#中创建包含括号的数据表字段的处理方法