基于机器学习的高考志愿高校及专业分析系统
发布时间:2024年01月14日
本项目在“基于 Python 的高考志愿高校及专业分析系统”基础上补充添加了机器学习算法对高考总问进行预测;
项目采用了网络爬虫技术,从指定的高考信息网站上抓取了各大高校的历年录取分数线数据。
通过精细的数据清洗过程,这些数据被存储于文件系统中,以便进行后续的分析和应用。
本项目的主要目标是为高考生提供一个便捷的信息查询平台,帮助他们根据自己的高考分数选择最适合的高校和专业进行报考。
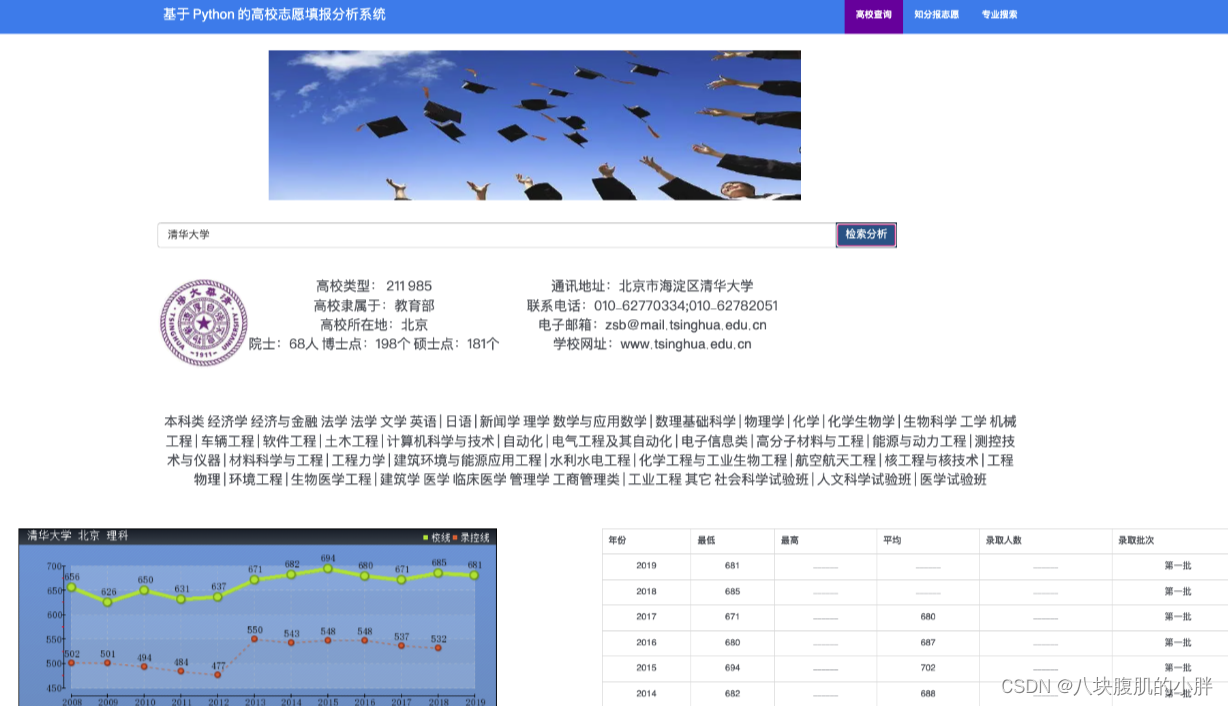
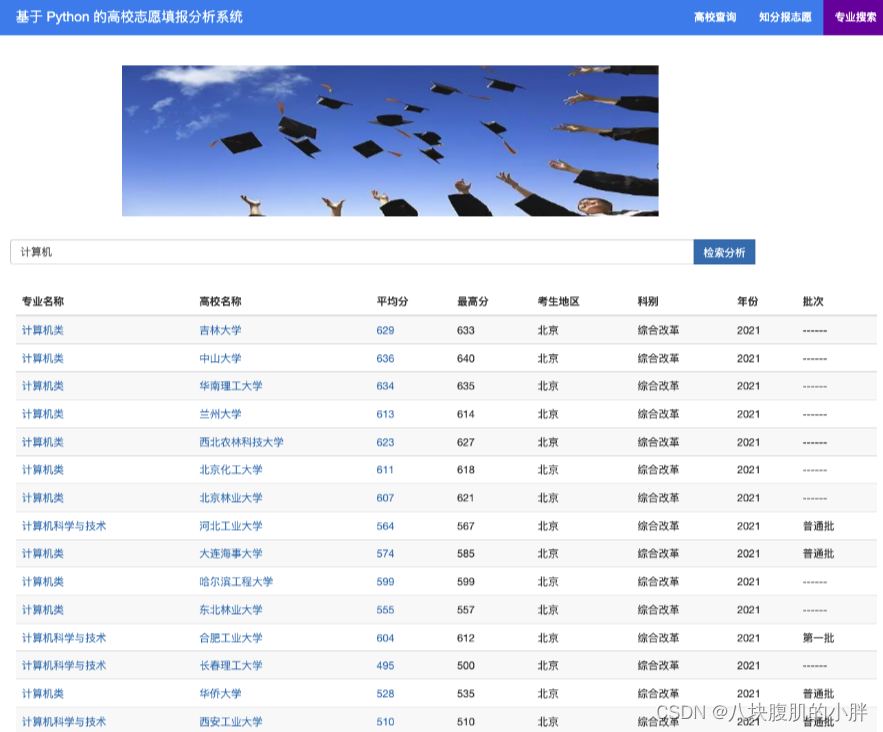
用户可以通过高校名称搜索特定学校的各专业历年录取分数线,或者通过专业名称搜索不同高校该专业的录取情况。
此外,还可以基于自己的高考分数查询可能录取的高校和专业。
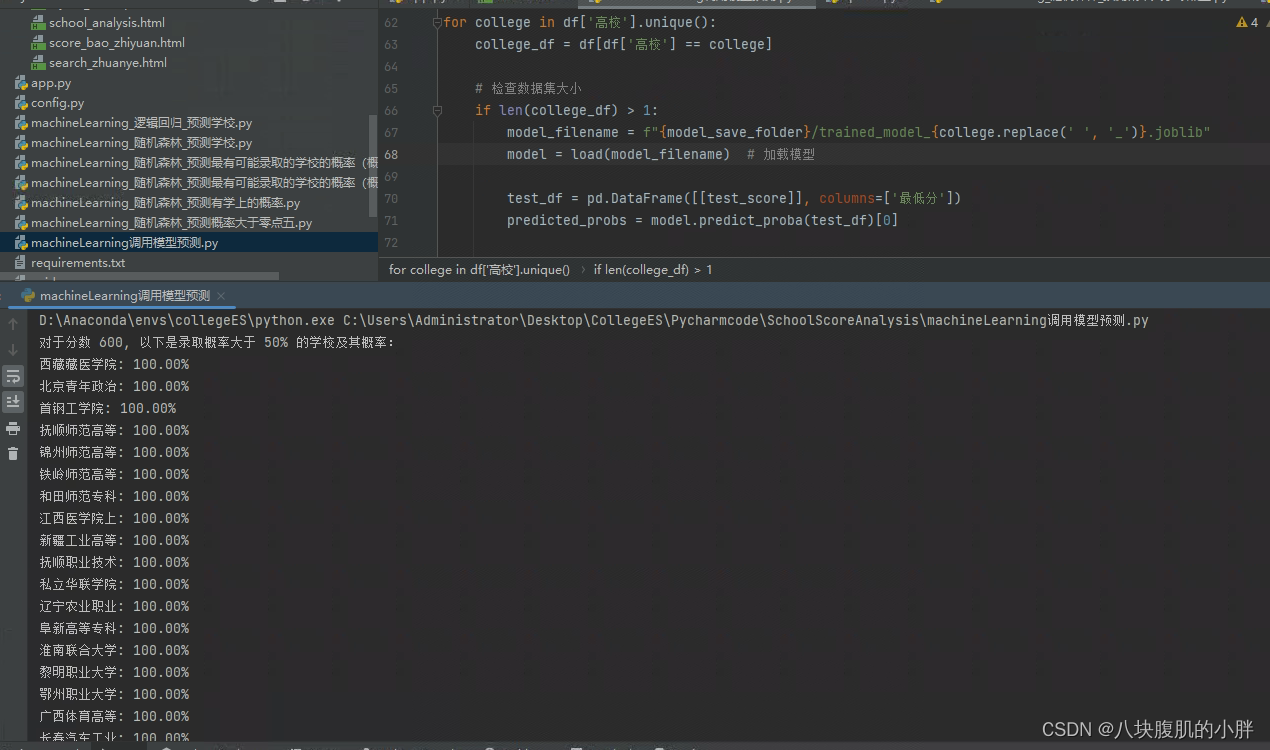
为了实现这些功能,运用了 pandas 和 sklearn 这两个Python库。pandas 用于处理和分析数据,sklearn,用于构建和训练机器学习模型。
在本项目中,特别采用了随机森林算法,用于分析历年数据并预测学生的录取概率。
随机森林算法通过结合多个决策树的预测结果来提高总体的预测准确性和稳定性,从而为学生提供更加准确和可靠的录取概率估计。
此外,本项目还利用了 Flask 框架搭建后端服务,构建了标准的 RESTful API 接口。
前端界面则是通过结合 Bootstrap、ECharts 和 jQuery 来实现的。这些技术的结合不仅确保了用户界面的友好性和互动性,还使得数据的展示更加直观和生动。
通过调用后端接口,前端实现了数据的动态加载和可视化展示,提高了用户体验。
本项目通过综合运用网络爬虫技术、数据清洗、机器学习分析以及全栈式的网站开发,为高考生提供了一个全面、便捷、直观的高校及专业选择辅助工具。通过这个平台,高考生可以更加科学和合理地规划自己的未来教育道路。

文章来源:https://blog.csdn.net/qq_39671636/article/details/135583288
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- LiveGBS流媒体平台GB/T28181功能-国标级联对接海康大华宇视华为等上级平台选择通道支持只看已选只看未选
- (四)STM32F407 cubemx定时器PWM驱动tb6612
- 使用强化学习提升扩散模型;轻量级LLM无损加速模块;使用RL动态调整Transformer每层参数量;Lumiere文本生成视频
- 【攻防世界misc】CatFlag
- 记录--移动端 H5 Tab 如何滚动居中
- 微信小程序的支付流程
- 为什么应用市场不会更新程序了
- 速学python·常量和表达式
- Word插件-大珩助手-手写电子签名
- C# .Net学习笔记—— 加密和解密算法