基于web的亚热带常见自然林病虫害识别系统——数据集与数据集划分
概要
本篇文章先为病虫害识别进行数据的分类,划分训练集,划分为三个数据集,病虫害的数据集我已经放在我的资源里面,有需要的小伙伴可以自己下载。
声明: 我的数据集照片都是自己拍摄的不是在网络上面下载的,拍摄照片不易,需要收一点点费用哈😁
数据收集
为了系统能够准确识别出自然生长的树木病虫害的情况,训练模型所采集的数据样本一定要具有代表性,所以树叶的采集对于模型的生成至关重要。故采集地点选择在广东省惠州市罗浮山自然保护区,该保护区地理位置处在亚热带地区。采集时间为 2022 年 2 月份,此时正值早春,各种病虫害都处在高发期前期,此时刚好是
识别病虫害进行提前防止的时期。整个采集过程为期7天,总计病虫害样本图像10000张,过滤后可使用照片 5000 张。本文主要对以下亚热带自然林的树进行了叶片采摘。第一类是对野生荔枝树,采用的取样方法是:在同一保护区针对自然生长的荔枝树不同品种与大致相近树龄的数目进行不同病虫害的树叶进行采集。采集顺序为正常荔枝树树叶(475 张图像)、瘿螨病荔枝叶(562 张图像)、患有叶瘿蚊病害荔枝树叶(569 张图像)。第二类是对野生黄皮树树叶图像进行采集。根据黄皮树的生长规律,病虫害的常见性选取叶斑病(558 张图像)、褐斑病(207 张图像)、健康(506 张图像)进行采集。第三类是对野生油茶树树叶图像进行采集。根据油茶树的生长规律,病虫害的常见性选取炭疽病,炭疽病采集 462 张图像数据,油茶健康采集 149 张图像数据。各类种植物的数据集一共包含 3 大类,3 个大类分别是荔枝树叶、黄皮树叶、油茶树图片一共是 9 个 G,如图所示:
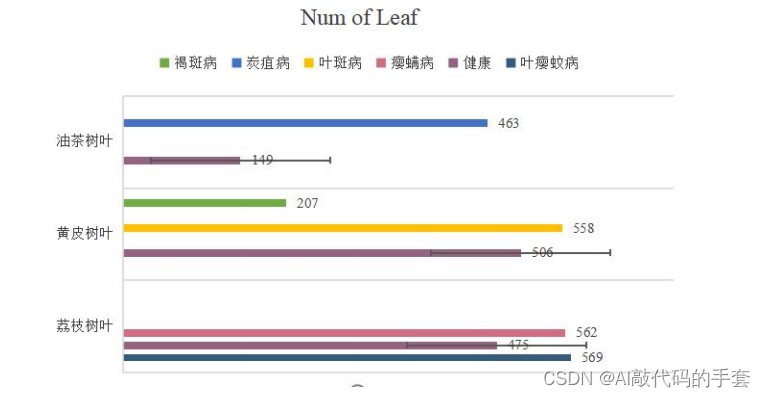
在图片采集完成后,过滤掉不清晰的叶片图像,对采集的图片依次进行编号,把叶片进行归类,以便神经网络的训练。
数据集划分
当我们准备好数据时候,需要创建三个文件夹,用于读取源数据文件夹,生成划分好的文件夹,分为trian、val、test三个文件夹进行
读取源数据文件夹,生成划分好的文件夹,分为trian、val、test三个文件夹进行
:param src_data_folder: 源文件夹
:param target_data_folder: 目标文件夹
:param train_scale: 训练集比例
:param val_scale: 验证集比例
:param test_scale: 测试集比例

技术代码
import os
import random
from shutil import copy2
def data_set_split(src_data_folder, target_data_folder, train_scale=0.8, val_scale=0.2, test_scale=0.0):
'''
读取源数据文件夹,生成划分好的文件夹,分为trian、val、test三个文件夹进行
:param src_data_folder: 源文件夹
:param target_data_folder: 目标文件夹
:param train_scale: 训练集比例
:param val_scale: 验证集比例
:param test_scale: 测试集比例
:return:
'''
print("开始数据集划分")
class_names = os.listdir(src_data_folder)
# 在目标目录下创建文件夹
split_names = ['train', 'val', 'test']
for split_name in split_names:
split_path = os.path.join(target_data_folder, split_name)
if os.path.isdir(split_path):
pass
else:
os.mkdir(split_path)
# 然后在split_path的目录下创建类别文件夹
for class_name in class_names:
class_split_path = os.path.join(split_path, class_name)
if os.path.isdir(class_split_path):
pass
else:
os.mkdir(class_split_path)
# 按照比例划分数据集,并进行数据图片的复制
# 首先进行分类遍历
for class_name in class_names:
current_class_data_path = os.path.join(src_data_folder, class_name)
current_all_data = os.listdir(current_class_data_path)
current_data_length = len(current_all_data)
current_data_index_list = list(range(current_data_length))
random.shuffle(current_data_index_list)
train_folder = os.path.join(os.path.join(target_data_folder, 'train'), class_name)
val_folder = os.path.join(os.path.join(target_data_folder, 'val'), class_name)
test_folder = os.path.join(os.path.join(target_data_folder, 'test'), class_name)
train_stop_flag = current_data_length * train_scale
val_stop_flag = current_data_length * (train_scale + val_scale)
current_idx = 0
train_num = 0
val_num = 0
test_num = 0
for i in current_data_index_list:
src_img_path = os.path.join(current_class_data_path, current_all_data[i])
if current_idx <= train_stop_flag:
copy2(src_img_path, train_folder)
# print("{}复制到了{}".format(src_img_path, train_folder))
train_num = train_num + 1
elif (current_idx > train_stop_flag) and (current_idx <= val_stop_flag):
copy2(src_img_path, val_folder)
# print("{}复制到了{}".format(src_img_path, val_folder))
val_num = val_num + 1
else:
copy2(src_img_path, test_folder)
# print("{}复制到了{}".format(src_img_path, test_folder))
test_num = test_num + 1
current_idx = current_idx + 1
print("*********************************{}*************************************".format(class_name))
print(
"{}类按照{}:{}:{}的比例划分完成,一共{}张图片".format(class_name, train_scale, val_scale, test_scale, current_data_length))
print("训练集{}:{}张".format(train_folder, train_num))
print("验证集{}:{}张".format(val_folder, val_num))
print("测试集{}:{}张".format(test_folder, test_num))
if __name__ == '__main__':
src_data_folder = "E:/bsdata/bch_data" # todo 修改你的原始数据集路径
target_data_folder = "E:/bsdata/new_data" # todo 修改为你要存放的路径
data_set_split(src_data_folder, target_data_folder)
小结
本文图像数据划分方法:数据划分图像在搜集过程当中就是按照同类基本放在同一个文件夹,数据分离是将数据划分成训练集与验证集,该系统的模型数据集将会使用 80%用于训练,20%用于验证。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Python如何实现微信支付功能代码示例
- 206.反转链表
- 真核微生物基因组质量评估工具EukCC的安装和详细使用方法
- 海塞矩阵(Hessian matrix)全解
- 2024.1.3 Spark on Yarn部署方式与工作原理
- 黑马Java 集合(下)
- uniapp小程序图片横向滚动,无限循环,跑马灯效果,鼠标悬浮停止。无需组件,非swiper单屏滚动,仅CSS+html
- 如何用Excel制作一张能在网上浏览的动态数据报表
- echart图表之圆盘 pie 单盘 带有刻度的圆盘满盘
- QT C++调用python传递RGB图像和三维数组,并接受python返回值(图像)