一致性协议浅析
Paxos
简介
Paxos 发明者是大名鼎鼎的 Lesile Lamport。Lamport 虚拟了一个叫做 Paxos 的希腊城邦,城邦按照议会民主制的政治模式制定法律。在 Lesile Lamport 的论文中,提出了 Basic Paxos、Multi Paxos、Fast Paxos 三种模型。
Basic Paxos 角色介绍
Client:系统外部角色,请求发起者,类比于民众。
Proposer:接收 Client 请求,向集群提出提议(Propose)。并在冲突发生时,起到冲突调节的作用。类比于议员,替民众提出议案。
Acceptor(Voter):提议投票和接收者,只有在形成法定人数(Quorum)时,提议才会最终被接受,类比于国会。
Learner:提议接受者,backup 备份,对集群一般没什么影响,类比于记录员。
Basic Paxos 步骤、阶段(phases)
阶段简介
- phase 1a:Prepare
proposer 提出一个提案,编号为 N,此 N 大于这个 proposer 之前提出提案的编号,请求 acceptor 的 quorum 接受。 - phase 1b:Promise
如果 N 大于此 acceptor 之前接受的任何提案编号则接受,否则拒绝。 - phase 2a:Accept
如果到达了多数派,proposer 会发出 accept 请求,此请求包含提案编号 N,以及提案内容。 - phase 2b: Accepted
如果此 acceptor 在此期间没有收到任何编号大于 N 的提案,则接受此提案内容,否则忽略。
基本流程图解

部分节点失败,但是达到了 Quorum
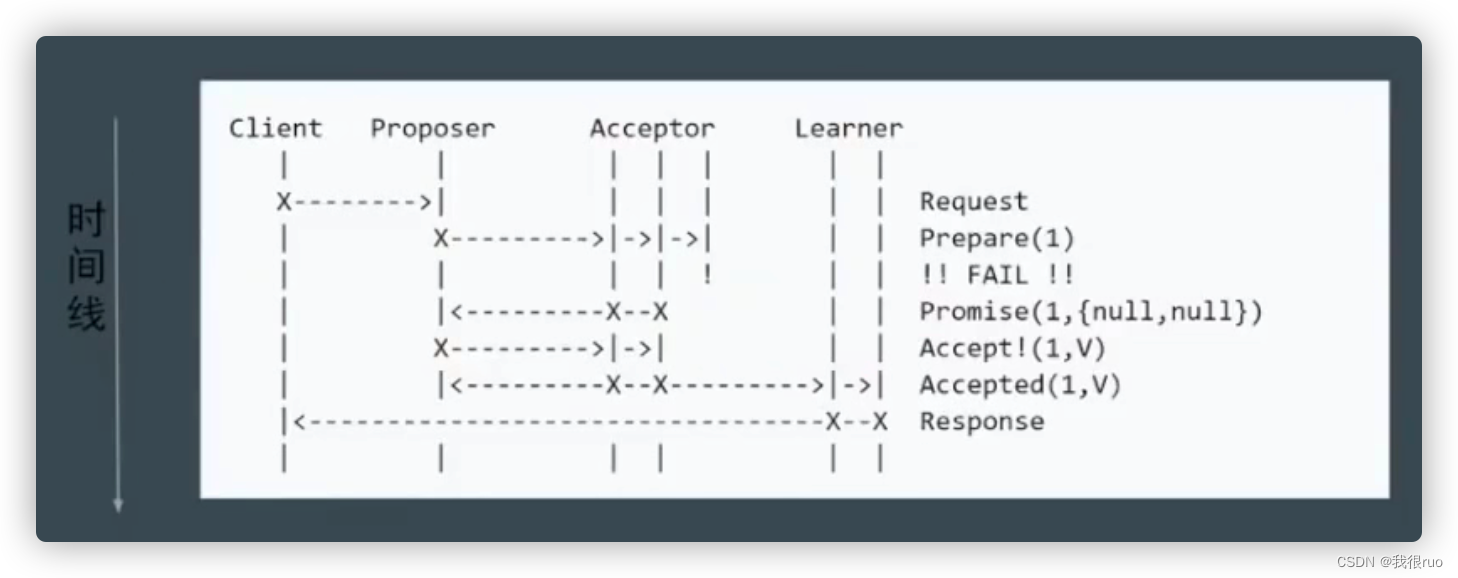
Proposer 失败
proposer 失败后议案不会被记录,重提成功后才会记录。

潜在问题:活锁(live lock 或 dueling)
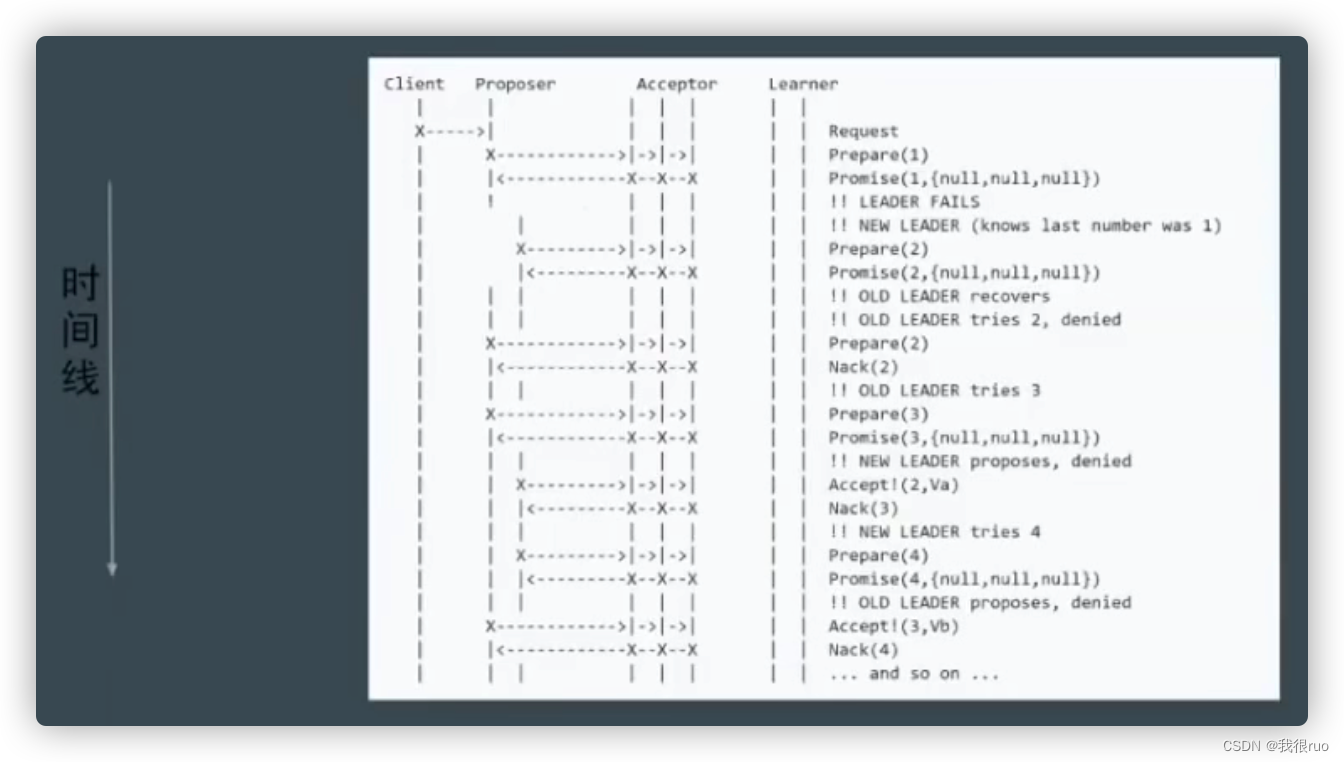
解决方案:被拒绝后等待 random timeout。
由于原生的 Paxos 协议低效,在生产中基本没有实践。实际应用更多的是 Paxos 的简化版本。
Multi Paxos
简化 1 —— Proposer 唯一
- 只有第一轮写入时需要进行提议(共需两轮 RPC)。
- 后续写入时只需要一轮 RPC 即可。
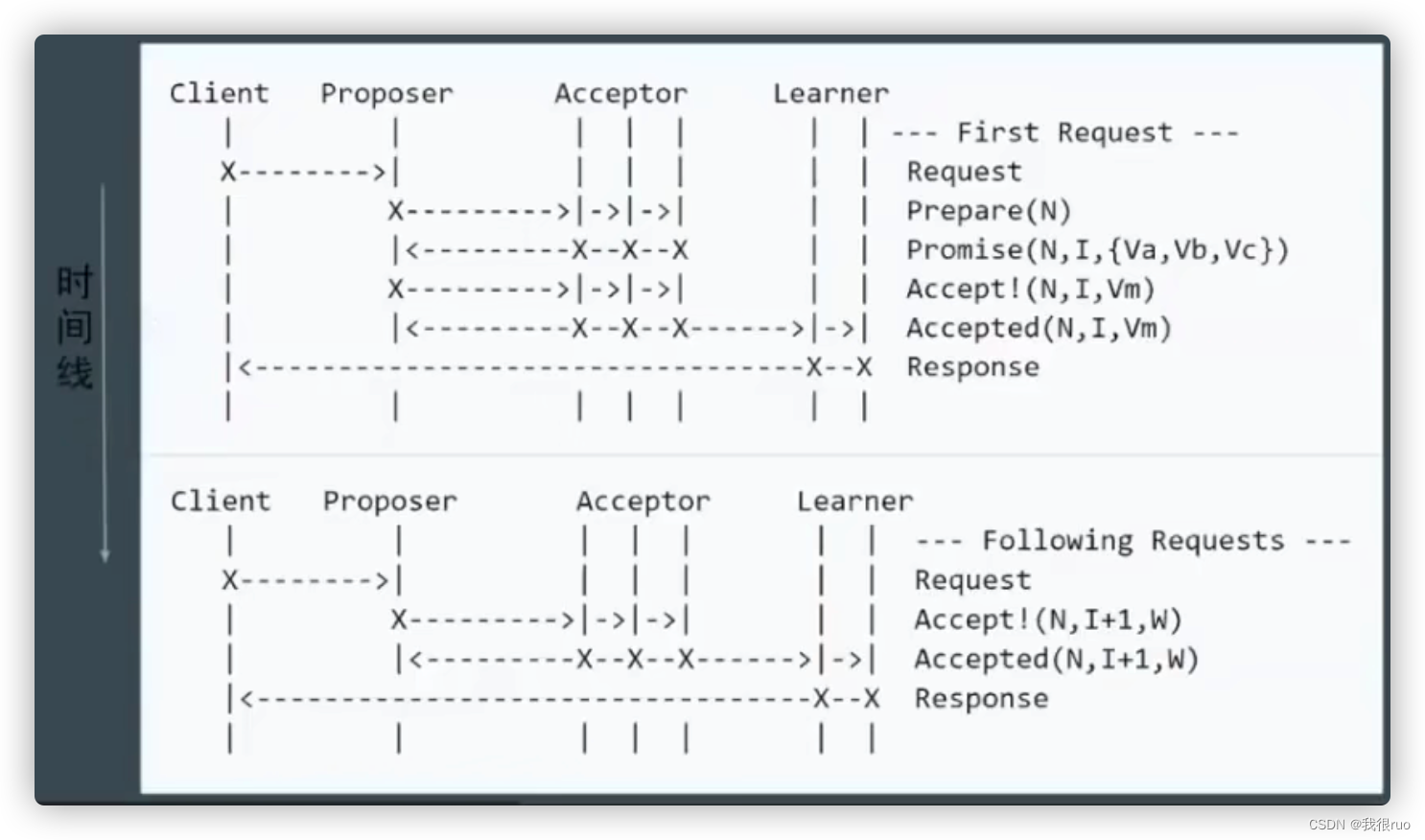
简化 2 —— 减少角色
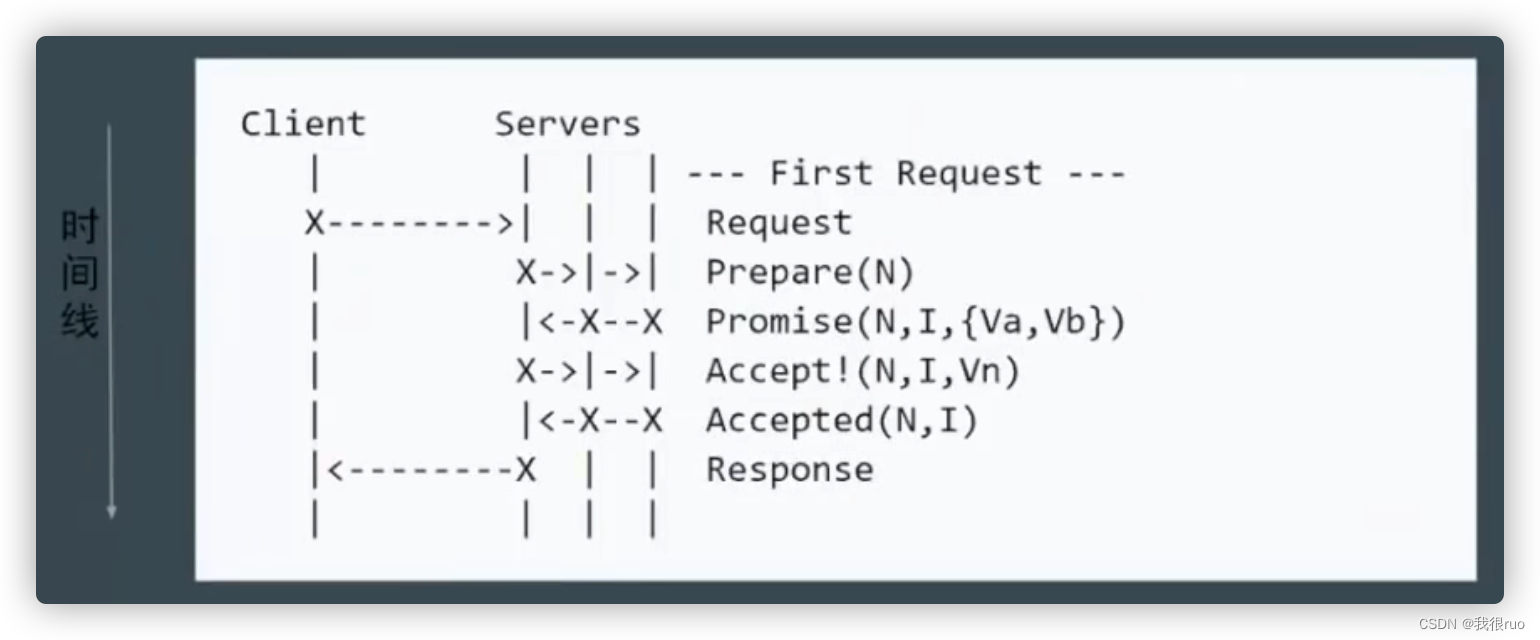
Raft、Paxos 可以理解为 Multi Paxos 的衍生版本。
Raft
简介
由于 Paxos 协议复杂、不易实现,且效率低,Raft 协议作为 Paxos 协议的简化版应运而生。Raft 协议划分成为了 3 个子问题,并重新定义了以下角色:
- Leader。
- Follower。
- Candidate。
问题1. Leader Election
(1)leader 通过心跳包证明存活,发送心跳的同时也可以发送同步内容。
(2)follower 未检测到心跳时会发起选取成为 candidate。
(3)多个 candidate 竞选且最高得票数相同时,则等待 random time 后继续发起选举。
问题2. Log Replication
(1)不同服务器的 Log 中,如果两个 Log 项目具有相同的全局索引编号以及相同的 Term 编号则这两个项目对应的操作命令也一定相同。—— 由 leader 保证。
(2)不同服务器的 Log 中,如果两个 Log 项目具有相同的全局索引编号以及相同的 Term 编号,那么 Log 中这个项目之前的所有前趋 Log 项目都完全相同。—— 由复制规则保证
Raft 日志提交的过程有点类似两阶段原子提交协议 2PC,不过和 2PC 的最大区别是,Raft 要求超过一半节点同意即可 commited,2PC 要求所有节点同意才能 commited。
Raft 算法规定 follower 强制复制 leader 的日志,即 follower 不一致日志都会被 leader 的日志覆盖,最终 follower 和 leader 保持一致。简单的说,从前向后寻找 follower 和 leader 第一个公共 LogIndex 的位置,然后从这个位置开始,follower 强制复制 leader 的日志。
问题3. Safety 如何保证
(1)Election Safety 选举安全性:避免脑裂问题
选举安全性要求一个任期 Term 内只能有一个 leader,即不能出现脑裂现象,否者 raft 的日志复制原则很可能出现数据覆盖丢失的问题。Raft 算法通过规定若干投票原则来解决这个问题:
- 一个任期内,follower 只会投票一次票,且先来先得;
- Candidate 存储的日志至少要和 follower 一样新;
- 只有获得超过半数投票才有机会成为 leader;
(2)Leader Append-Only 日志只能由 leader 添加修改
Raft 算法规定,所有的数据请求都要交给 leader 节点处理,要求:
- leader 只能追加日志,不能覆盖日志;
- 只有 leader 的日志项才能被提交,follower 不能接收写请求和提交日志;
- 只有已经提交的日志项,才能被应用到状态机中;
- 选举时限制新 leader 日志包含所有已提交日志项;
(3)Log Matching 日志匹配特性
这点主要是为了保证日志的唯一性,要求:
- 如果在不同日志中的两个条目有着相同索引和任期号,则所存储的命令是相同的;
- 如果在不同日志中的两个条目有着相同索引和任期号,则它们之间所有条目完全一样;
(4)Leader Completeness 选举完备性:leader 必须具备最新提交日志
Raft 规定:只有拥有最新提交日志的 follower 节点才有资格成为 leader 节点。具体做法:candidate 竞选投票时会携带最新提交日志,follower 会用自己的日志和 candidate 做比较。
- 如果 follower 的更新,那么拒绝这次投票;
- 否则根据前面的投票规则处理。这样就可以保证只有最新提交节点成为 leader;
日志更新判断方式是比较日志项的 term 和 index:
- 如果 TermId 不同,选择 TermId 最大的;
- 如果 TermId 相同,选择 Index 最大的;
(5)State Machine Safety 状态机安全性:确保当前任期日志提交
日志提交有两个条件需要满足:
- 当前任期;
- 复制结点超过半数;
动画演示:http://thesecretlivesofdata.com/raft/
官网动画:https://raft.github.io/
特别注意
一致性并不一定代表完全正确性,是否正确还需要由客户端保证。
三个可能的结果:成功、失败、unknown(未达到多数派导致 timeout,取决于系统下一步的状态:恢复 or 换届)。
Paxos VS Raft
这个世界上只有一种一致性算法,那就是 Paxos。
Basic Paxos 算法没有 leader proposer 角色,是一个纯粹的去中心化的分布式算法,但是它存在若干不足(只能单值共识 & 活锁 & 网络开销大)。所以才有了以 leader proposer 为核心的 Multi Paxos 算法(由一个去中心化的算法变为 leader-based 的算法)。Raft 算法相当于 Multi Paxos 的进一步优化,主要通过增加两个限制:
(1)日志添加次序性:
- Raft 要求日志必须要串行连续添加的;
- Multi Paxos 可以并发添加日志,没有顺序性要求,所以日志可能存在空洞现象;
(2)选主限制:
- Raft 要求只有拥有最新日志的节点才有资格当选 leader,因为日志是串行连续添加的,所以 Raft 能够根据日志确认最新节点;
- 在 Multi Paxos 算法中由于日志是并发添加的,所以无法确认最新日志的节点,所以 Multi Paxos 可以选择任意节点作为了 leader proposer 节点,成为 leader 节点后需要把其他日志补全;
个人理解:
(1)作为分布式算法,Raft 的规则限制很多,但是每个规则都简单易懂,最重要的是 leader-based 的,整个程序是一个串行的流程,这使得更加容易理解和实现;
(2)作为对比,Multi Paxos 的限制就很少了,每个节点都可以成为 leader,并发添加日志,这使得理解和落地就没那么简单;
不同业务场景下有着不同的述求,所以一致性算法选择 Multi Paxos 还是 Raft 看各自需求。毕竟程序员更容易理解串行程序。
Zab
简介
全称 Zookeeper 原子广播协议(Zookeeper Atomic Broadcast)。基本与 Raft 相同,只是一些名词的叫法上有些区别:如 Zab 将某个 leader 的任期成为 epoch,而 raft 则称为 term。
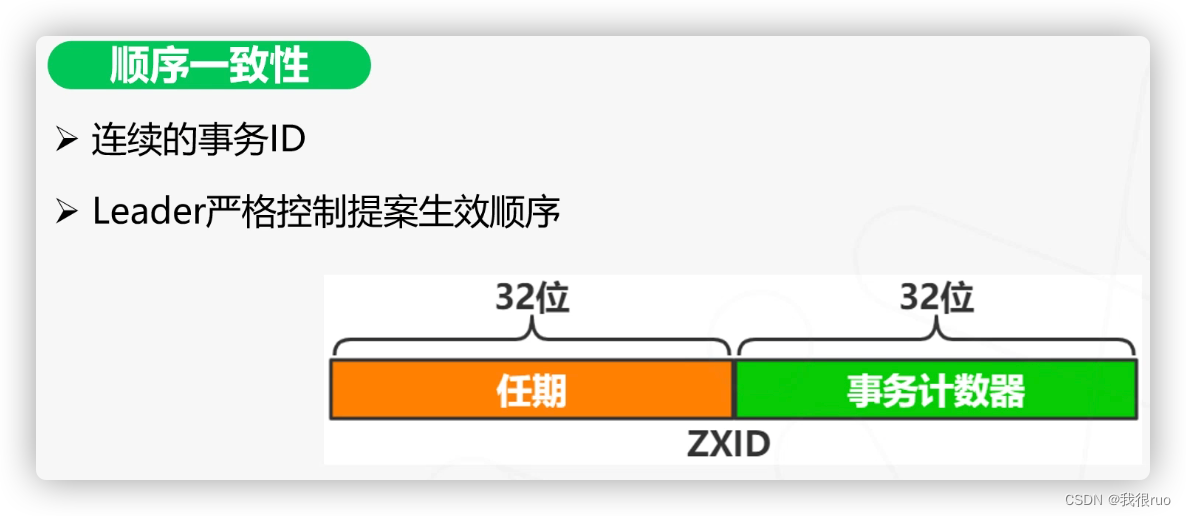
zab 协议类似于 2PC
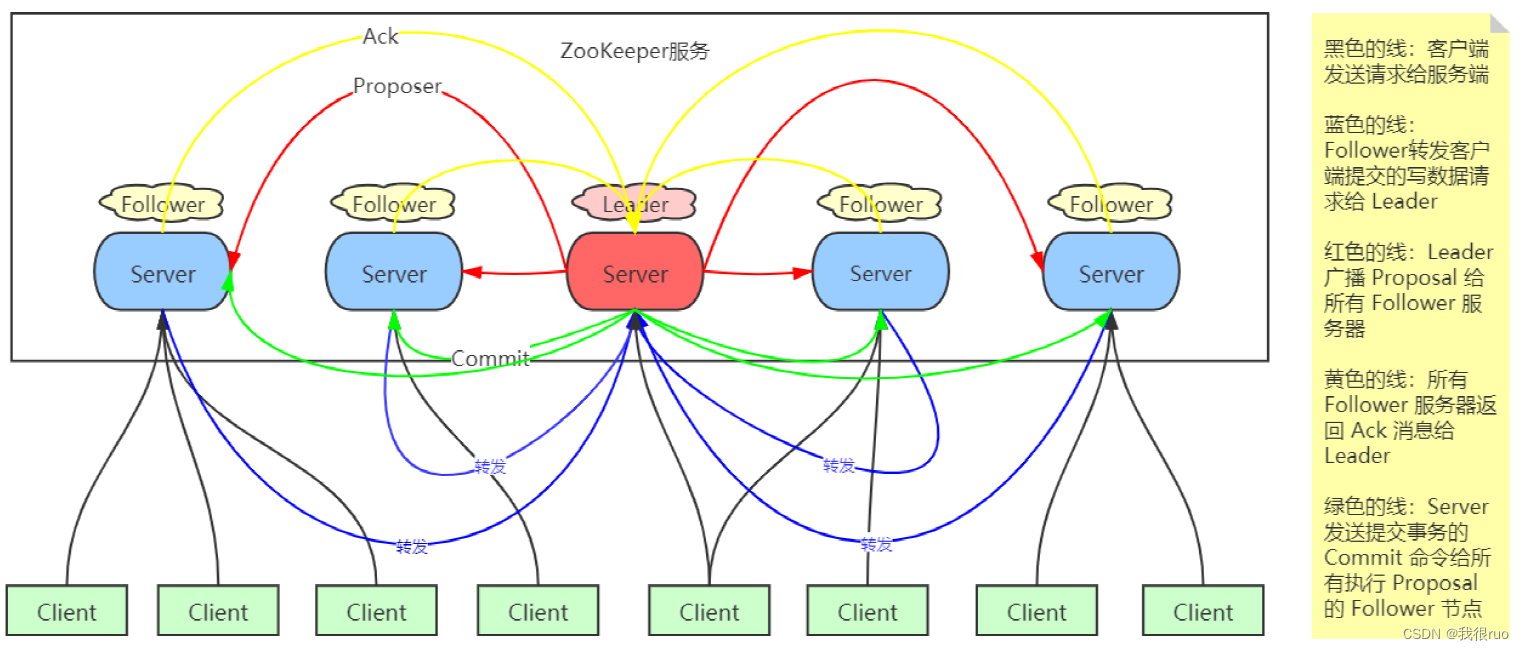
- follower server 可以直接处理读请求,但不能直接处理写请求。写请求只能转发给 leader server 进行处理。
- 最终所有的写请求在 leader server 端串行执行。(分布式环境下永远无法精确地确认不同服务器不同事件发生的先后顺序)
- ZooKeeper 集群中的所有节点的数据状态通过 ZAB 协议保持一致。ZAB 有两种工作模式:
(1)崩溃恢复:集群没有 Leader 角色,内部在执行选举。
(2)原子广播:集群有 Leader 角色,Leader 主导分布式事务的执行,向所有的 Follower 节点,按照严格顺序广播事务。
(3)补充一点:实际上,ZAB 有四种工作模式,分别是:ELECTION,DISCOVERY,SYNCHRONIZATION,BROADCAST。
再谈 CAP
- 严格意义上讲,ZooKeeper 实现了 P 分区容错性、C 中的写入强一致性,丧失的是 C 中的读取一致性。ZooKeeper 并不保证读取的是最新数据。
- 如果客户端刚好链接到一个刚好没执行事务成功的节点,也就是说没和 Leader 保持一致的 Follower 节点的话,是有可能读取到非最新数据的。
- 如果要保证读取到最新数据,请使用 sync 回调处理。这个机制的原理:是先让 Follower 保持和 Leader 一致,然后再返回结果给客户端。
- 关于 zookeeper 到底是 CP 还是 AP 的讨论,zk 的 ap 和 cp 是从不同的角度分析的:
(1)从一个读写请求分析,保证了可用性(不用阻塞等待全部follwer同步完成),保证不了数据的一致性,所以是ap。
(2)但是从 zk 架构分析,zk 在 leader 选举期间,会暂停对外提供服务(为啥会暂停,因为 zk 依赖 leader 来保证数据一致性),所以丢失了可用性,保证了一致性,即 cp。 再细点话,这个c不是强一致性,而是最终一致性。即上面的写案例,数据最终会同步到一致,只是时间问题。
(3)综上,zk 广义上来说是 cp,狭义上是 ap。
Gossip
动画演示:https://rrmoelker.github.io/gossip-visualization/
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 手柄上(switch、ps4、PSVita)竟然也能看B站客户端,简直太香了
- 开箱即用的企业级数据和业务管理中后台前端框架Ant Design Pro 5的开箱使用和偏好配置
- [NOIP2006 提高组] 作业调度方案(待修改)
- windows系统下docker软件中使用ubuntu发行版本的linux系统
- 数据采集卡技术参数一览!
- 计算机毕业设计SSM基于Java的题库管理系统的设计与实现9516x9【附源码】
- maxwell同步全量历史数据
- 简单的MOV转MP4方法
- Linux服务器nginx部署Vue前端(详细版)
- Cisco Nexus Alias别名使用方法