【Linux笔记】进程等待与程序替换
一、进程的终止
1、进程退出码
在讲解进程的终止之前,先要普及一下进程的退出码概念。
我们父进程之所以要创建子进程,就是为了让子进程运行不一样的任务,那么对于子进程执行的这个任务执行完毕后的结果是否正确或者是否出差错,我们父进程要对这个结果进行验收。
从而就引出了进程退出码和进程退出信号的概念,其中退出码就是main函数的返回值:

我们在命令行中可以使用“echo $?”这串指令来查看最近一个进程的退出码:
![]()
如果我们将main函数的返回值改成其他数,那echo $?查出来的值也会随之变化:
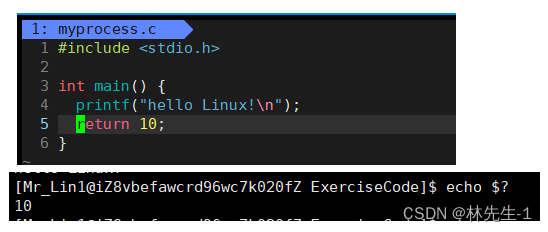
一般默认的退出码为0则表示程序运行正确,是其他数则表示程序出了问题,即运行失败。
所以0表示成功,非0就表示失败,具体非零的数字那个对应的是哪种错误,我们可以自己定义。
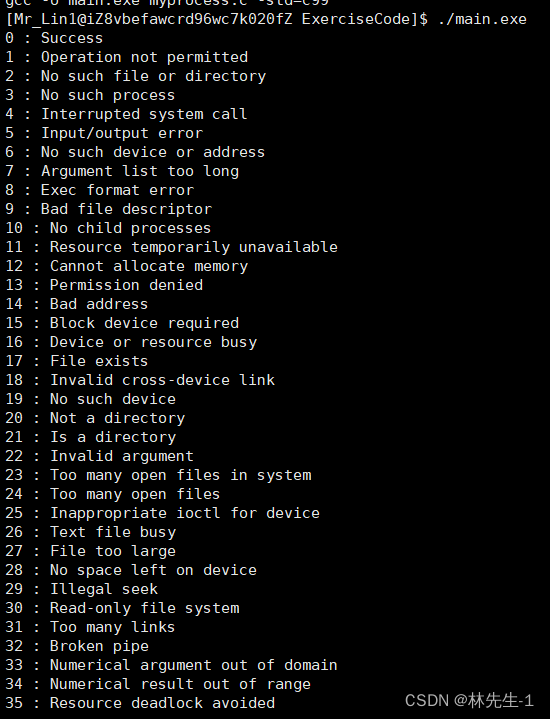
当然C语言内置的也有一套错误码对应的字符串解释,我们可以调用strerror这个函数来查看:

2、进程终止的方法
在main函数中直接return
在main函数中直接return的方法其实上面已经演示过了,这个其实很容易理解,main函数是程序的入口也是程序结束的地方,所以我们父进程需要回收的就是main函数的返回情况。
使用exit接口
还还有一种方式就是,使用exit接口,这是一个C语言提供的接口:
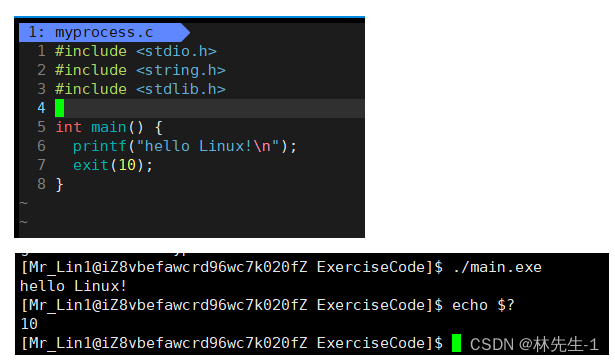
如果仅放在main函数中,其实它和return是同级的,但是它其实比return的级别还要高,因为它放在任何地方都可以让程序直接结束:
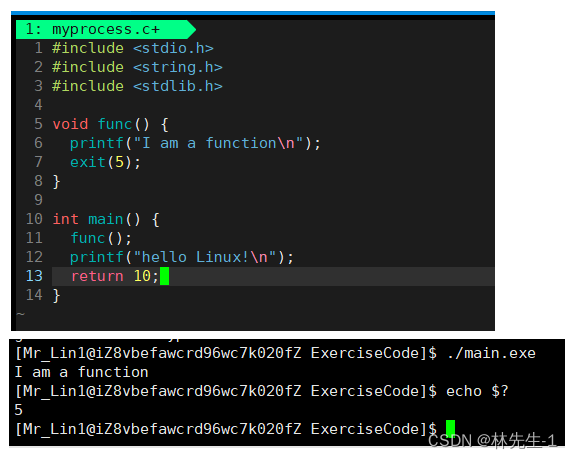
从其运行的结果我们可以看出exit的级别是要比return高的,因为程序的退出码为5,而且后面的打印语句也没有执行。
使用_exit系统调用
还有一个与exit类似的接口_exit也可以用来结束进程:
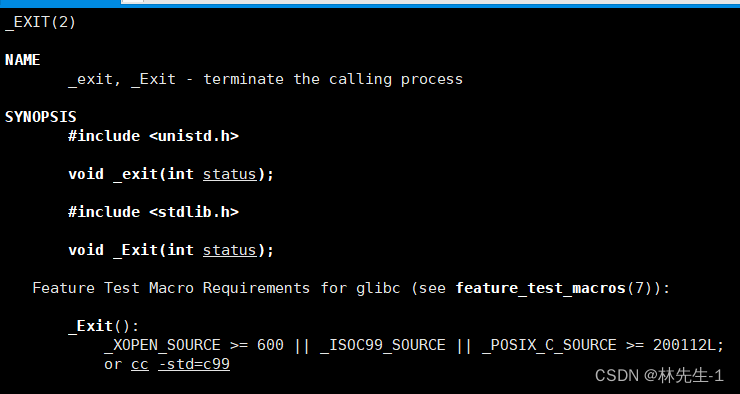
它是一个系统调用,它的正常使用其实是和exit接口执行的结果一样的,比如把上一段程序中的exit改成_exit后,我们会发现它们执行的结果一模一样:
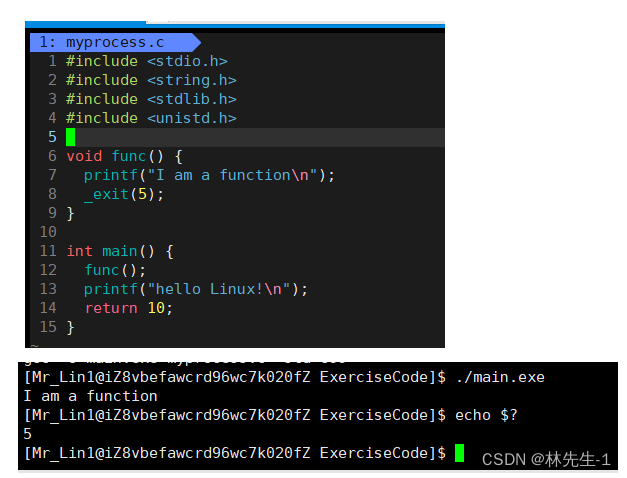
exit与_exit的区别
那它两到底有什么区别呢?
它两的区别其实就在于它们前者是C库函数,后者是系统调用。
我们先来看一个现象:
我们会发现,程序执行后确实是成功了,因为退出码正确了,但是程序并没有输出任何结果。
不急我们再来对程序进行微微的改动,在printf里面加上\n:
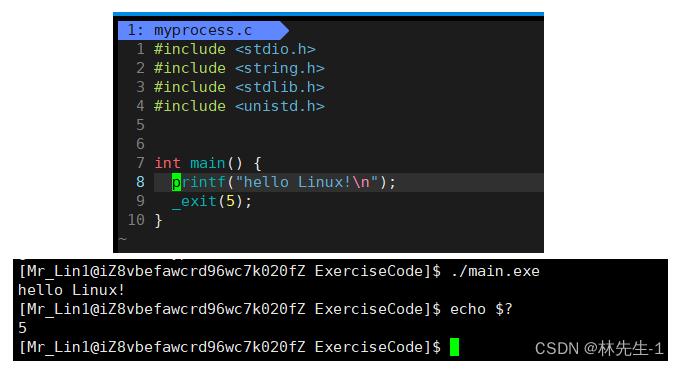
加上\n之后就打印出来了。
然后我们可以再对比一下exit:
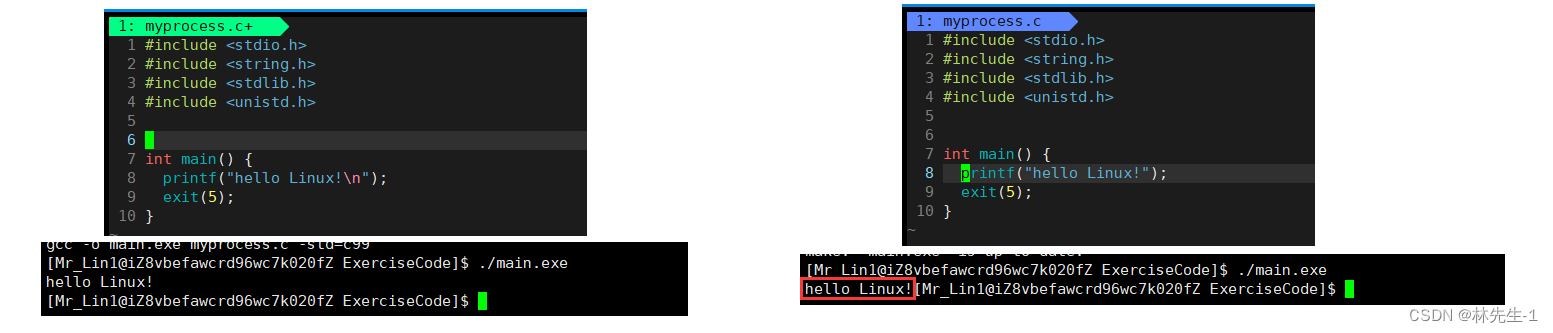
经过观察会发现,exit不论是否加上\n它都有结果打印出来,那这是怎么一回事呢?
其实上面的结果的本质就是exit在退出前会刷新缓冲区,而_exit在退出前不会刷新缓冲区。因为缓冲区的刷新条件之一就是遇到了\n,所以只要加上了\n,exit和_exit都会有结果输出,而从_exit退出之前没有刷新缓冲区的结果来看,我们可以推测出缓冲器肯定不在操作系统内部。
道理就是_exit是系统调用肯定是比库函数exit更接近操作系统内部的,但是偏偏exit刷新了,而_exit没有刷新,如果缓冲区是在操作系统内部,那exit都刷新了,为什么更接近操作系统的_exit没有刷新呢?
二、进程等待、
我们知道,如果子进程先于父进程退出,那么子进程就会变成僵尸进程,如果僵尸进程一直不被回收,就会造成内存泄漏问题。
所以,进程等待就是为了回收子进程从而解决子进程僵尸问题造成的内存泄漏而生的。
1、如何进程进程等待
wait的使用
解决进程等待,我们使用的是wait系统调用:

#include<sys/types.h>#include<sys/wait.h>pid_t wait(int*status);返回值:成功返回被等待进程 pid ,失败返回 -1 。参数:输出型参数,获取子进程退出状态 , 不关心则可以设置成为 NULL


解释wait的阻塞等待
而且wait的等待方式为阻塞等待,所谓阻塞等待即父进程在等待子进程的过程中会一直停滞着,不会执行任何任务,下面以一个例子来演试一下:
代码:

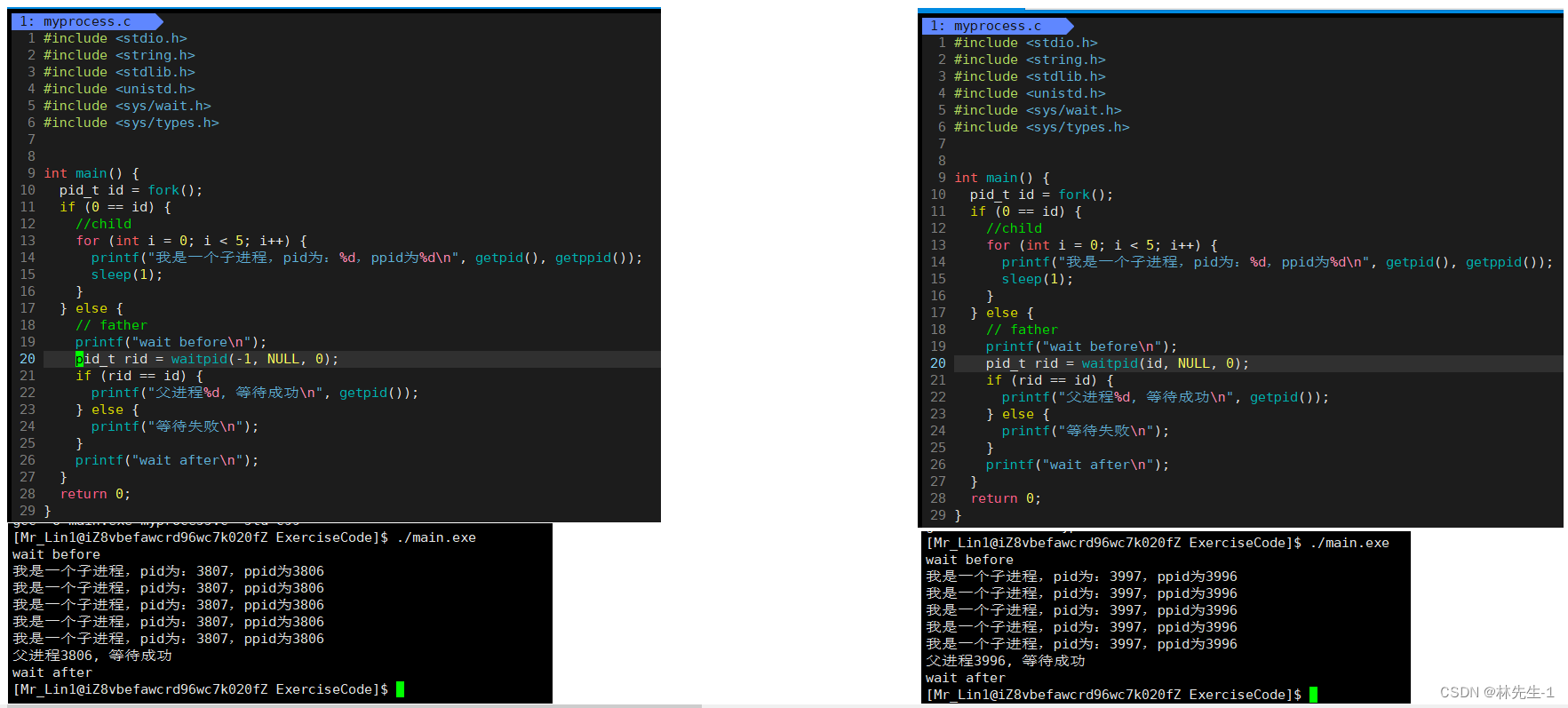
运行结果:

从结果我们可以看出,在子进程执行期间,父进程其实也已经在执行了,但是一直到子进程执行完毕之后父进程才执行结束。所以在子进程执行期间,父进程一直在做阻塞等待。
waitpid的使用
waitpid相比于wait来说选择性更多,wait只能等待任意一个进程,而waitpid既能等待任意一个进程也能等待指定进程,wait只能阻塞等待,而waitpid既能阻塞等待也能非阻塞等待。

pid_ t waitpid(pid_t pid, int *status, int options);返回值:? ? 当正常返回的时候 waitpid 返回收集到的子进程的进程 ID ;? ? 如果设置了选项 WNOHANG, 而调用中 waitpid 发现没有已退出的子进程可收集 , 则返回 0 ;? ? 如果调用中出错 , 则返回 -1, 这时 errno 会被设置成相应的值以指示错误所在;参数:? ?pid :? ? ? Pid=-1, 等待任一个子进程。与 wait 等效。? ? ? Pid>0. 等待其进程 ID 与 pid 相等的子进程。? ?status:? ? ? WIFEXITED(status): 若为正常终止子进程返回的状态,则为真。(查看进程是否是正常? ? ? ? 退出)? ? ? WEXITSTATUS(status): 若 WIFEXITED 非零,提取子进程退出码。(查看进程的退出? ? ? ? ? ?码)? options:? ? ? WNOHANG: 若 pid 指定的子进程没有结束,则 waitpid() 函数返回 0 ,不予以等待。若正常? ? ? ? 结束,则返回该子进? ? ? 程的 ID 。
解释waitpid的第二个参数
上面说过进程等待其实是为了解决子进程僵尸状态所造成的内存泄漏问题,但是进程等待还有第二个目的,就是检查子进程的运行结果,即获取子进程的退出码和终止信号。而这个工作就是有waitpid的第二个参数来做的。
wait和waitpid都有这个status参数,它其实是一个输出型参数,即通过外部传参的方式,在内部对参数进程修改,然后外部得到对应的状态。
这个status虽然是一个32位的整型,但我们并不整体使用它,而是只是用它的低16位:

但是我们想直接通过打印出status的只来判断退出信息的话,是有点奇怪的,例如:

正如上面所说的,status并不是整体使用的,而是在进程正常退出时,退出码“直接被放到次低八位”的:

如果想要提取出10来,有两种方法,一种是直接进行位运算,一种是使用上面提供的接口:WEXITSTATUS。
位运算有点儿不好记,而且久了也容易忘,所以我这里就只演示使用函数的情况:

再来演示一下进程异常退出的情况,进程异常退出时,退出码其实是没有意义的,所以我们主要看的是,终止信号。
比如我们可以设置一个常见的空指针异常:
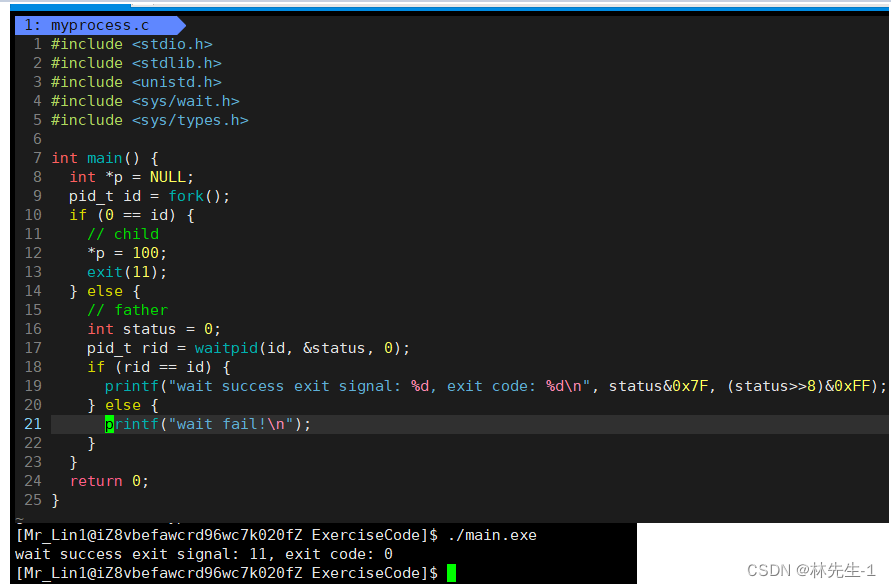
这里就只能使用位运算了,这里的位运算没什么,记住就行。
如果不想记的话,也可以用上面提到的WIFEXITED函数来直接判断子进程是否正常退出,只是不能看出进程异常对应的信号值:

waitpid等待多个进程
那么如何使用waitpid来等待多个子进程呢?
其实很简单,我们创建多个子进程使用的是循环的方式,那我们在等待的时候也使用循环等待即可,先演示阻塞等待的。

演示waitpid的轮训等待(非阻塞等待)
waitpid的第三个参数options默认支持两种等待方式,阻塞等待和非阻塞等待。设置为0表示阻塞等待,而设置成另一个数(宏)WNOHONG则表示,非阻塞等待。
而如果我们直接像使用wait一样使用waitpid的非阻塞等待的话,就会发现父进程直接就结束了,并没有继续等:

显然父进程是并没有成功回收子进程的。因为它先于子进程退出了。
如果我们想让如进程成功回收子进程,就必须使用循环的方式:

三、程序替换
1、程序替换与创建子进程的区别
我们之前是通过创建子进程的方式来让进程“分流”的执行不同的任务,但是子进程执行的任务本质上还是父进程代码的一部分。如果我们想要让子进程执行新的代码和访问新的数据,不再和父进程有瓜葛,就得使用进程替换的方式。
2、进程程序替换的接口
先介绍execl接口
execl这个接口可以为我们执行进程替换的工作,所谓的进程替换其实并不是创建新进程,而是将进程的代码和数据替换:
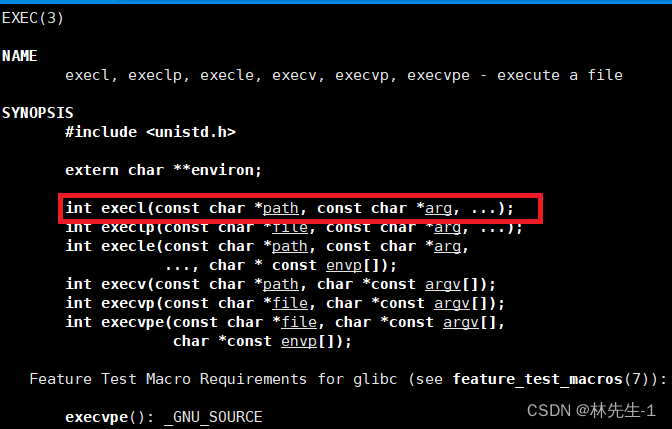
它的第一个参数表示你要替换的进程的路径+文件名,而后面的可变参数列表则表示你想要怎样执行这个进程,因为各种进程执行所对应的执行选项不同,所以这里需要用可变参数列表,需要注意的是在可变参数列表的最后,一定要传一个NULL,表示参数传递完毕。
先拿我们最常用的“ls”这个指令来演示:


这样我们就可以在我们自己写的C语言代码中调用我们系统的指令了。
然后我们再来看一个现象:

上面的结果中只打印了replace before而没有打印replace after,这其实就说明了进程替换其实是将代码替换掉的。代码都不同了,当然就没有打印啦。
然后我们再来看看它有没有创建新进程:

从结果可以看出,前面创建的子进程后后面付进程等待到的子进程id是一样的,所以进程替换并没有创建新进程。
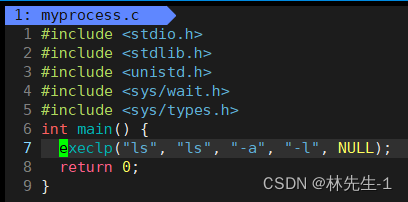
execlp:
execlp与execl的区别在于,execl需要传文件路径+文件名,而execlp只需要传文件名就行了,多出来的这个p可以理解为自带路径path的含义:

execv:
这个接口,与之前两个不同之处在于,它后面的命令函参数是一个一个数字的形式传递的。他后面的这个v其实就是vector的意思:
剩下的几个接口其实在介绍完上面的三个接口之后,就可以类推出来他们的含义和用法了,如上所述,如果带‘l’则表示后面的命令函参数一列表的形式传递,如果带‘p’则表示它是自带路径的,传第一个参数的时候就只需要传文件名即可,如果是带'v'的,则表示他后面的命令行参数是以数组的形式传递。
以此类推即可。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- CSS基础笔记-03选择器
- 上门服务小程序|预约上门服务系统开发有哪些功能?
- 关于linux中断
- 【温故而知新】HTML5的Video/Audio
- Linux网络配置概述
- 【CCF BDCI 2023】多模态多方对话场景下的发言人识别 Baseline 0.71 Slover 部分
- 图片如何压缩变小?3款软件助你轻松掌控
- 嵌入式C设计模式:职责链设计模式
- 云数据仓库实践:AWS Redshift在大数据储存分析上的落地经验分享
- 剑指offer题解合集——Week1day3