YOLOV5单目测距+车辆检测+车道线检测+行人检测(教程-代码)
YOLOv5是一种高效的目标检测算法,结合其在单目测距、车辆检测、车道线检测和行人检测等领域的应用,可以实现多个重要任务的精确识别和定位。
首先,YOLOv5可以用于单目测距。
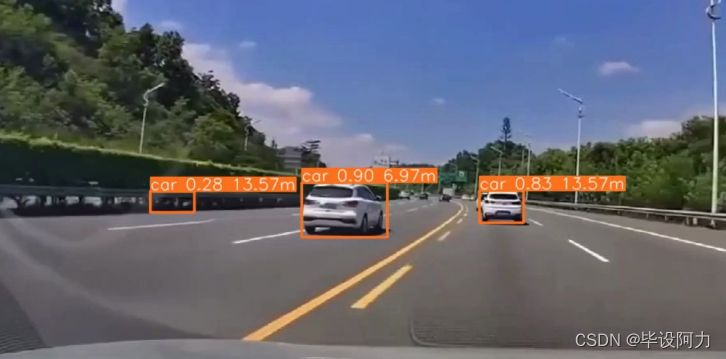
通过分析图像中的目标位置和尺寸信息,结合相机参数和几何关系,可以推断出目标与相机之间的距离。这对于智能驾驶、机器人导航等领域至关重要,可以帮助车辆或机器人感知周围环境的远近,并做出相应的决策。
其次,YOLOv5可以用于车辆检测。
它可以快速而准确地检测图像中的车辆,并给出其边界框和类别信息。这对于交通监控、智能交通管理等应用非常有用,可以帮助实时监测道路上的车辆情况,并进行车辆计数、违规检测等任务。
此外,YOLOv5还可以用于车道线检测。
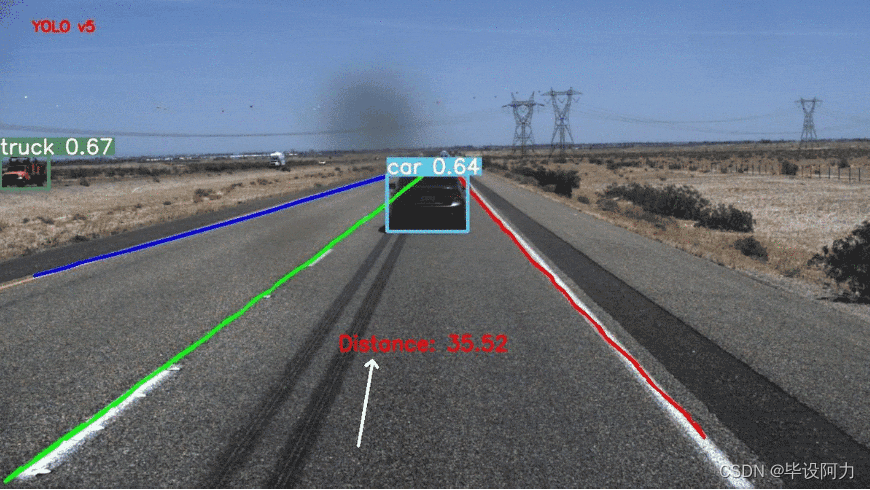
通过分析道路图像中的特征,如边缘、颜色等,结合YOLOv5的目标检测能力,可以有效地检测出车道线的位置和形状。这对于自动驾驶、车道保持等任务至关重要,可以帮助车辆实时判断自己在道路上的位置,并做出相应的控制动作。
最后,YOLOv5还可以用于行人检测。

它可以准确地检测图像中的行人,并给出其边界框和类别信息。这对于行人安全、城市规划等领域非常有用,可以帮助监测行人的数量和分布情况,并进行行人流量统计、行人路径规划等任务。
总之,YOLOv5作为一种高效的目标检测算法,在单目测距、车辆检测、车道线检测和行人检测等领域具有重要的应用价值。它的快速和精确性能使其成为实时场景中的首选算法,并在智能交通、自动驾驶等领域发挥着重要的作用。
1、论文流程的简介
项目的主题框架使用为yolo和opencv的形式实现,而模型的选择为基于深度学习的YOLO V5模型,权重为基于COCO2014训练的数据集,而车道线的检测是基于OpenCV的传统方法实现的。

2、论文主体部分
2.1、YOLO?V5模型
YoloV2的结构是比较简单的,这里要注意的地方有两个:
1.输出的是batchsize x (5+20)*5 x W x H的feature map;
2.这里为了提取细节,加了一个 Fine-Grained connection layer,将前面的细节信息汇聚到了后面的层当中。

YOLOv2结构示意图
2.1.1、DarkNet19模型
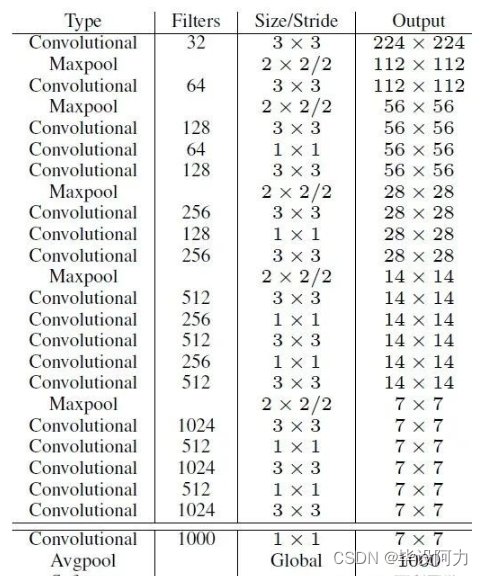
YOLOv2采用了一个新的基础模型(特征提取器),称为Darknet-19,包括19个卷积层和5个maxpooling层;Darknet-19与VGG16模型设计原则是一致的,主要采用33卷积,采用 22的maxpooling层之后,特征图维度降低2倍,而同时将特征图的channles增加两倍。
与NIN(Network in Network)类似,Darknet-19最终采用global avgpooling做预测,并且在33卷积之间使用11卷积来压缩特征图channles以降低模型计算量和参数。
Darknet-19每个卷积层后面同样使用了batch norm层以加快收敛速度,降低模型过拟合。在ImageNet分类数据集上,Darknet-19的top-1准确度为72.9%,top-5准确度为91.2%,但是模型参数相对小一些。使用Darknet-19之后,YOLOv2的mAP值没有显著提升,但是计算量却可以减少约33%。
?
?
"""Darknet19 Model Defined in Keras."""
import functools
from functools import partial
from keras.layers import Conv2D, MaxPooling2D
from keras.layers.advanced_activations import LeakyReLU
from keras.layers.normalization import BatchNormalization
from keras.models import Model
from keras.regularizers import l2
from ..utils import compose
# Partial wrapper for Convolution2D with static default argument.
_DarknetConv2D = partial(Conv2D, padding='same')
@functools.wraps(Conv2D)
def DarknetConv2D(*args, **kwargs):
"""Wrapper to set Darknet weight regularizer for Convolution2D."""
darknet_conv_kwargs = {'kernel_regularizer': l2(5e-4)}
darknet_conv_kwargs.update(kwargs)
return _DarknetConv2D(*args, **darknet_conv_kwargs)
def DarknetConv2D_BN_Leaky(*args, **kwargs):
"""Darknet Convolution2D followed by BatchNormalization and LeakyReLU."""
no_bias_kwargs = {'use_bias': False}
no_bias_kwargs.update(kwargs)
return compose(
DarknetConv2D(*args, **no_bias_kwargs),
BatchNormalization(),
LeakyReLU(alpha=0.1))
def bottleneck_block(outer_filters, bottleneck_filters):
"""Bottleneck block of 3x3, 1x1, 3x3 convolutions."""
return compose(
DarknetConv2D_BN_Leaky(outer_filters, (3, 3)),
DarknetConv2D_BN_Leaky(bottleneck_filters, (1, 1)),
DarknetConv2D_BN_Leaky(outer_filters, (3, 3)))
def bottleneck_x2_block(outer_filters, bottleneck_filters):
"""Bottleneck block of 3x3, 1x1, 3x3, 1x1, 3x3 convolutions."""
return compose(
bottleneck_block(outer_filters, bottleneck_filters),
DarknetConv2D_BN_Leaky(bottleneck_filters, (1, 1)),
DarknetConv2D_BN_Leaky(outer_filters, (3, 3)))
def darknet_body():
"""Generate first 18 conv layers of Darknet-19."""
return compose(
DarknetConv2D_BN_Leaky(32, (3, 3)),
MaxPooling2D(),
DarknetConv2D_BN_Leaky(64, (3, 3)),
MaxPooling2D(),
bottleneck_block(128, 64),
MaxPooling2D(),
bottleneck_block(256, 128),
MaxPooling2D(),
bottleneck_x2_block(512, 256),
MaxPooling2D(),
bottleneck_x2_block(1024, 512))
def darknet19(inputs):
"""Generate Darknet-19 model for Imagenet classification."""
body = darknet_body()(inputs)
logits = DarknetConv2D(1000, (1, 1), activation='softmax')(body)
return Model(inputs, logits)
2.1.2、Fine-Grained Features
YOLOv2的输入图片大小为416416,经过5次maxpooling之后得到1313大小的特征图,并以此特征图采用卷积做预测。13*13大小的特征图对检测大物体是足够了,但是对于小物体还需要更精细的特征图(Fine-Grained Features)。因此SSD使用了多尺度的特征图来分别检测不同大小的物体,前面更精细的特征图可以用来预测小物体
YOLOv2提出了一种passthrough层来利用更精细的特征图。YOLOv2所利用的Fine-Grained Features是2626大小的特征图(最后一个maxpooling层的输入),对于Darknet-19模型来说就是大小为 2626512的特征图。passthrough层与ResNet网络的shortcut类似,以前面更高分辨率的特征图为输入,然后将其连接到后面的低分辨率特征图上。前面的特征图维度是后面的特征图的2倍,passthrough层抽取前面层的每个22的局部区域,然后将其转化为channel维度,对于2626512的特征图,经passthrough层处理之后就变成了13132048的新特征图(特征图大小降低4倍,而channles增加4倍,图6为一个实例),这样就可以与后面的13131024特征图连接在一起形成13133072大小的特征图,然后在此特征图基础上卷积做预测。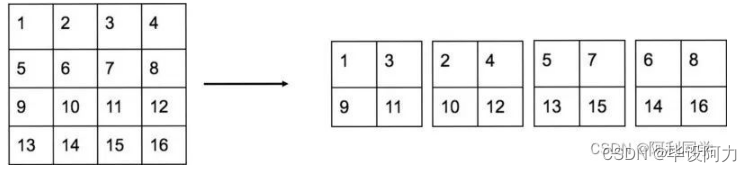
2.1.3、YOLOv5的训练
YOLOv2的训练主要包括三个阶段。第一阶段就是先在coco分类数据集上预训练Darknet-19,此时模型输入为224*224,共训练160个epochs。然后第二阶段将网络的输入调整为448*448,继续在ImageNet数据集上finetune分类模型,训练10个epochs,此时分类模型的top-1准确度为76.5%,而top-5准确度为93.3%。第三个阶段就是修改Darknet-19分类模型为检测模型,并在检测数据集上继续finetune网络
?
def yolo_loss(args,
anchors,
num_classes,
rescore_confidence=False,
print_loss=False):
"""YOLO localization loss function.
Parameters
----------
yolo_output : tensor
Final convolutional layer features.
true_boxes : tensor
Ground truth boxes tensor with shape [batch, num_true_boxes, 5]
containing box x_center, y_center, width, height, and class.
detectors_mask : array
0/1 mask for detector positions where there is a matching ground truth.
matching_true_boxes : array
Corresponding ground truth boxes for positive detector positions.
Already adjusted for conv height and width.
anchors : tensor
Anchor boxes for model.
num_classes : int
Number of object classes.
rescore_confidence : bool, default=False
If true then set confidence target to IOU of best predicted box with
the closest matching ground truth box.
print_loss : bool, default=False
If True then use a tf.Print() to print the loss components.
Returns
-------
mean_loss : float
mean localization loss across minibatch
"""
(yolo_output, true_boxes, detectors_mask, matching_true_boxes) = args
num_anchors = len(anchors)
object_scale = 5
no_object_scale = 1
class_scale = 1
coordinates_scale = 1
pred_xy, pred_wh, pred_confidence, pred_class_prob = yolo_head(
yolo_output, anchors, num_classes)
# Unadjusted box predictions for loss.
# TODO: Remove extra computation shared with yolo_head.
yolo_output_shape = K.shape(yolo_output)
feats = K.reshape(yolo_output, [
-1, yolo_output_shape[1], yolo_output_shape[2], num_anchors,
num_classes + 5
])
pred_boxes = K.concatenate(
(K.sigmoid(feats[..., 0:2]), feats[..., 2:4]), axis=-1)
# TODO: Adjust predictions by image width/height for non-square images?
# IOUs may be off due to different aspect ratio.
# Expand pred x,y,w,h to allow comparison with ground truth.
# batch, conv_height, conv_width, num_anchors, num_true_boxes, box_params
pred_xy = K.expand_dims(pred_xy, 4)
pred_wh = K.expand_dims(pred_wh, 4)
pred_wh_half = pred_wh / 2.
pred_mins = pred_xy - pred_wh_half
pred_maxes = pred_xy + pred_wh_half
true_boxes_shape = K.shape(true_boxes)
# batch, conv_height, conv_width, num_anchors, num_true_boxes, box_params
true_boxes = K.reshape(true_boxes, [
true_boxes_shape[0], 1, 1, 1, true_boxes_shape[1], true_boxes_shape[2]
])
true_xy = true_boxes[..., 0:2]
true_wh = true_boxes[..., 2:4]
# Find IOU of each predicted box with each ground truth box.
true_wh_half = true_wh / 2.
true_mins = true_xy - true_wh_half
true_maxes = true_xy + true_wh_half
intersect_mins = K.maximum(pred_mins, true_mins)
intersect_maxes = K.minimum(pred_maxes, true_maxes)
intersect_wh = K.maximum(intersect_maxes - intersect_mins, 0.)
intersect_areas = intersect_wh[..., 0] * intersect_wh[..., 1]
pred_areas = pred_wh[..., 0] * pred_wh[..., 1]
true_areas = true_wh[..., 0] * true_wh[..., 1]
union_areas = pred_areas + true_areas - intersect_areas
iou_scores = intersect_areas / union_areas
# Best IOUs for each location.
best_ious = K.max(iou_scores, axis=4) # Best IOU scores.
best_ious = K.expand_dims(best_ious)
# A detector has found an object if IOU > thresh for some true box.
object_detections = K.cast(best_ious > 0.6, K.dtype(best_ious))
# TODO: Darknet region training includes extra coordinate loss for early
# training steps to encourage predictions to match anchor priors.
# Determine confidence weights from object and no_object weights.
# NOTE: YOLO does not use binary cross-entropy here.
no_object_weights = (no_object_scale * (1 - object_detections) *
(1 - detectors_mask))
no_objects_loss = no_object_weights * K.square(-pred_confidence)
if rescore_confidence:
objects_loss = (object_scale * detectors_mask *
K.square(best_ious - pred_confidence))
else:
objects_loss = (object_scale * detectors_mask *
K.square(1 - pred_confidence))
confidence_loss = objects_loss + no_objects_loss
# Classification loss for matching detections.
# NOTE: YOLO does not use categorical cross-entropy loss here.
matching_classes = K.cast(matching_true_boxes[..., 4], 'int32')
matching_classes = K.one_hot(matching_classes, num_classes)
classification_loss = (class_scale * detectors_mask *
K.square(matching_classes - pred_class_prob))
# Coordinate loss for matching detection boxes.
matching_boxes = matching_true_boxes[..., 0:4]
coordinates_loss = (coordinates_scale * detectors_mask *
K.square(matching_boxes - pred_boxes))
confidence_loss_sum = K.sum(confidence_loss)
classification_loss_sum = K.sum(classification_loss)
coordinates_loss_sum = K.sum(coordinates_loss)
total_loss = 0.5 * (
confidence_loss_sum + classification_loss_sum + coordinates_loss_sum)
if print_loss:
total_loss = tf.Print(
total_loss, [
total_loss, confidence_loss_sum, classification_loss_sum,
coordinates_loss_sum
],
message='yolo_loss, conf_loss, class_loss, box_coord_loss:')
return total_loss
2.2、车距的计算
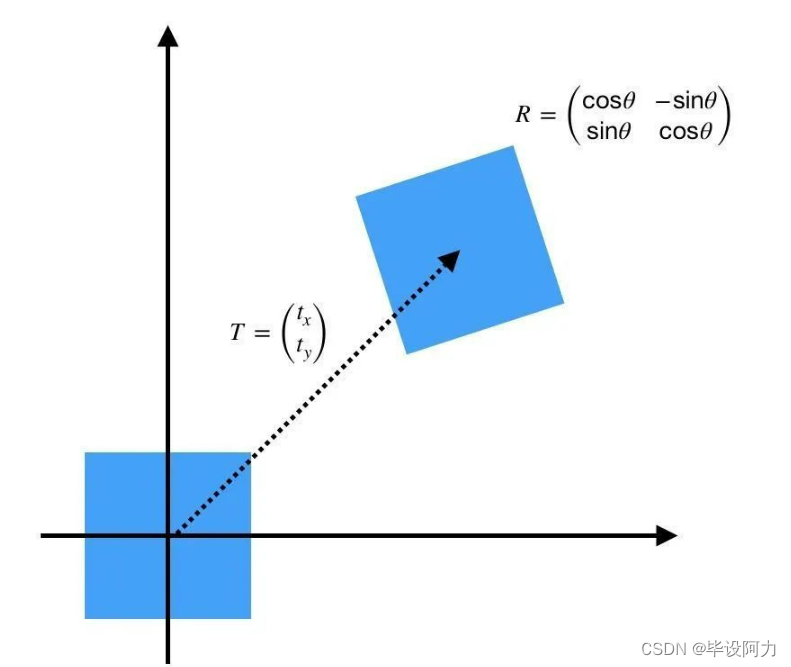
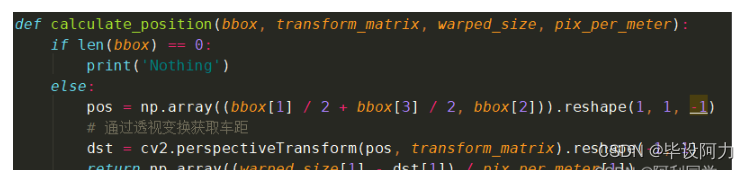
过YOLO进行检测车量,然后返回的车辆检测框的坐标与当前坐标进行透视变换获取大约的距离作为车辆之间的距离。
所使用的函数API接口为:
?
cv2.perspectiveTransform(src, m[, dst]) → dst
参数解释
?src:输入的2通道或者3通道的图片
?m:变换矩阵
返回距离
2.3、车道线的分割
实现步骤
1.图片校正(对于相机畸变较大的需要先计算相机的畸变矩阵和失真系数,对图片进行校正);
2.截取感兴趣区域,仅对包含车道线信息的图像区域进行处理;
3.使用透视变换,将感兴趣区域图片转换成鸟瞰图;
4.针对不同颜色的车道线,不同光照条件下的车道线,不同清晰度的车道线,根据不同的颜色空间使用不同的梯度阈值,颜色阈值进行不同的处理。并将每一种处理方式进行融合,得到车道线的二进制图;
5.提取二进制图中属于车道线的像素;
6.对二进制图片的像素进行直方图统计,统计左右两侧的峰值点作为左右车道线的起始点坐标进行曲线拟合;
7.使用二次多项式分别拟合左右车道线的像素点(对于噪声较大的像素点,可以进行滤波处理,或者使用随机采样一致性算法进行曲线拟合);
8.计算车道曲率及车辆相对车道中央的偏离位置;
9.效果显示(可行域显示,曲率和位置显示)。
class that finds the whole lane
class LaneFinder:
def init(self, img_size, warped_size, cam_matrix, dist_coeffs, transform_matrix, pixels_per_meter,
warning_icon):
self.found = False
self.cam_matrix = cam_matrix
self.dist_coeffs = dist_coeffs
self.img_size = img_size
self.warped_size = warped_size
self.mask = np.zeros((warped_size[1], warped_size[0], 3), dtype=np.uint8)
self.roi_mask = np.ones((warped_size[1], warped_size[0], 3), dtype=np.uint8)
self.total_mask = np.zeros_like(self.roi_mask)
self.warped_mask = np.zeros((self.warped_size[1], self.warped_size[0]), dtype=np.uint8)
self.M = transform_matrix
self.count = 0
self.left_line = LaneLineFinder(warped_size, pixels_per_meter, -1.8288) # 6 feet in meters
self.right_line = LaneLineFinder(warped_size, pixels_per_meter, 1.8288)
if (warning_icon is not None):
self.warning_icon = np.array(mpimg.imread(warning_icon) * 255, dtype=np.uint8)
else:
self.warning_icon = None
?
def undistort(self, img):
return cv2.undistort(img, self.cam_matrix, self.dist_coeffs)
def warp(self, img):
return cv2.warpPerspective(img, self.M, self.warped_size, flags=cv2.WARP_FILL_OUTLIERS + cv2.INTER_CUBIC)
def unwarp(self, img):
return cv2.warpPerspective(img, self.M, self.img_size, flags=cv2.WARP_FILL_OUTLIERS +
cv2.INTER_CUBIC + cv2.WARP_INVERSE_MAP)
def equalize_lines(self, alpha=0.9):
mean = 0.5 * (self.left_line.coeff_history[:, 0] + self.right_line.coeff_history[:, 0])
self.left_line.coeff_history[:, 0] = alpha * self.left_line.coeff_history[:, 0] + \
(1 - alpha) * (mean - np.array([0, 0, 1.8288], dtype=np.uint8))
self.right_line.coeff_history[:, 0] = alpha * self.right_line.coeff_history[:, 0] + \
(1 - alpha) * (mean + np.array([0, 0, 1.8288], dtype=np.uint8))
def find_lane(self, img, distorted=True, reset=False):
# undistort, warp, change space, filter
if distorted:
img = self.undistort(img)
if reset:
self.left_line.reset_lane_line()
self.right_line.reset_lane_line()
img = self.warp(img)
img_hls = cv2.cvtColor(img, cv2.COLOR_RGB2HLS)
img_hls = cv2.medianBlur(img_hls, 5)
img_lab = cv2.cvtColor(img, cv2.COLOR_RGB2LAB)
img_lab = cv2.medianBlur(img_lab, 5)
big_kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (31, 31))
small_kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (7, 7))
greenery = (img_lab[:, :, 2].astype(np.uint8) > 130) & cv2.inRange(img_hls, (0, 0, 50), (138, 43, 226))
road_mask = np.logical_not(greenery).astype(np.uint8) & (img_hls[:, :, 1] < 250)
road_mask = cv2.morphologyEx(road_mask, cv2.MORPH_OPEN, small_kernel)
road_mask = cv2.dilate(road_mask, big_kernel)
img2, contours, hierarchy = cv2.findContours(road_mask, cv2.RETR_LIST, cv2.CHAIN_APPROX_NONE)
biggest_area = 0
for contour in contours:
area = cv2.contourArea(contour)
if area > biggest_area:
biggest_area = area
biggest_contour = contour
road_mask = np.zeros_like(road_mask)
cv2.fillPoly(road_mask, [biggest_contour], 1)
self.roi_mask[:, :, 0] = (self.left_line.line_mask | self.right_line.line_mask) & road_mask
self.roi_mask[:, :, 1] = self.roi_mask[:, :, 0]
self.roi_mask[:, :, 2] = self.roi_mask[:, :, 0]
kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (7, 3))
black = cv2.morphologyEx(img_lab[:, :, 0], cv2.MORPH_TOPHAT, kernel)
lanes = cv2.morphologyEx(img_hls[:, :, 1], cv2.MORPH_TOPHAT, kernel)
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (13, 13))
lanes_yellow = cv2.morphologyEx(img_lab[:, :, 2], cv2.MORPH_TOPHAT, kernel)
self.mask[:, :, 0] = cv2.adaptiveThreshold(black, 1, cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY, 13, -6)
self.mask[:, :, 1] = cv2.adaptiveThreshold(lanes, 1, cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY, 13, -4)
?2.4、测试过程和结果
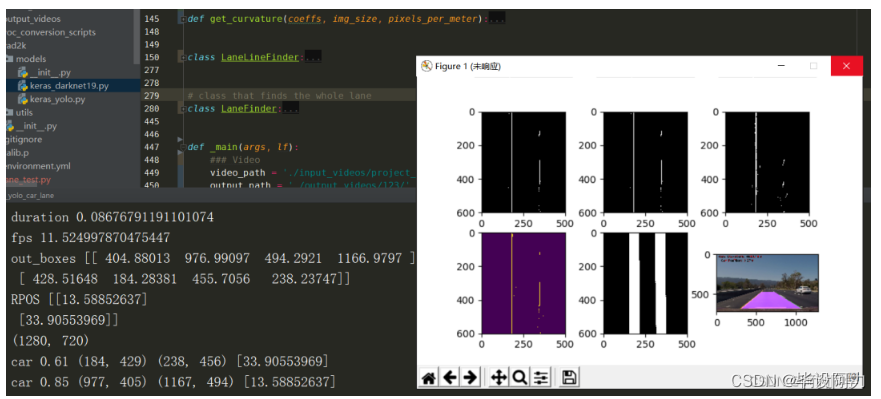
总结与效果展示
单目测距(Monocular Depth Estimation):
单目测距是指通过使用单个摄像头来估计场景中物体的距离。YOLOv5可以通过训练一个深度估计模型,从图像中预测每个像素的深度信息,并据此计算物体距离。在YOLOv5中,可以使用深度学习框架如PyTorch进行模型的训练和推断。
车辆检测(Vehicle Detection):
车辆检测是指从图像或视频中检测和识别出车辆的位置和边界框。YOLOv5可以通过训练一个车辆检测模型,对图像中的车辆进行准确的定位和分类。车辆检测可以应用于交通监控、自动驾驶等领域。
车道线检测(Lane Detection):
车道线检测是指从图像或视频中检测和提取出道路上的车道线信息。YOLOv5可以通过训练一个车道线检测模型,从图像中识别出车道线的位置和形状。车道线检测在自动驾驶、驾驶辅助系统等方面具有重要应用。
行人检测(Pedestrian Detection):
行人检测是指从图像或视频中检测和识别出行人的位置和边界框。YOLOv5可以通过训练一个行人检测模型,对场景中的行人进行准确的定位和分类。行人检测可应用于安防监控、智能交通等领域。

?交流学习QQ767172261

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- yum install net-tools 命令报错,无法安装成功
- 聊聊equals()方法
- 如何从格式化的 Windows 和 Mac 电脑硬盘恢复文件
- 重磅发布|博睿数据2023年度精选案例集—— IT运维之光
- 在 PyTorch 中,将数据从 CPU 移动到 GPU 有几种方法
- Python实现模块热加载
- 终极解决Flutter项目运行ios项目报错Without CocoaPods, plugins will not work on iOS or macOS.
- python初试七
- 现代商业空间的展示设计
- C++轮子 · STL 序列容器