图像识别完整项目之Swin-Transformer,从获取关键词数据集到训练的完整过程
0. 前言
图像分类的大部分经典神经网络已经全部介绍完,并且已经作了测试
代码已经全部上传到资源,根据文章名或者关键词搜索即可
LeNet :pytorch 搭建 LeNet 网络对 CIFAR-10 图片分类
AlexNet :?pytorch 搭建AlexNet 对花进行分类
Vgg :?pytorch 搭建 VGG 网络
GoogLeNet :?pytorch 搭建GoogLeNet
ResNet :?ResNet 训练CIFAR10数据集,并做图片分类
关于轻量级网络
MobileNet 系列:
ShuffleNet 系列:
EfficientNet 系列:
- V1 :EfficientNet 分类花数据集
- V2 :EfficientNet V2?
Swin-Transformer :Swin-Transformer 在图像识别中的应用
本章将根据?Swin-Transformer 网络对图像分类ending,包括如何获取数据集,训练网络、预测图像等等。
本文从头实现对Marvel superhero 进行分类记录,项目下载在后面
代码尽量简单,小白均可运行,不需要定义复杂的变量
网络精度高,采用迁移学习
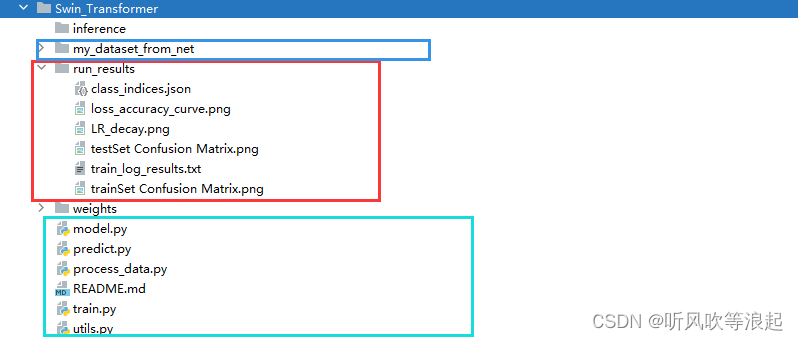
1. 项目目录
文件目录如下所示:
注:项目的文件夹和代码不可更改,要不然会报错,至于超参数的更改下面会介绍!!
inference 是预测的文件夹,将预测的图像放在该文件夹下,可以实现批预测
my_dataset_from_net 爬虫脚本,可以自动从网络上下载图片
run_results? 网络训练之后生成的信息,包括类别json文件、loss和accuracy精度曲线、学习率衰减曲线、训练过程日志、已经训练集和测试集的混淆矩阵
weights 下面存放的是Swin-Transformer 的预训练权重
py 文件:
- model Swin-Transformer 网络
- predict 预测脚本
- process_data 根据爬虫下载的图片,自动划分训练集和测试,并且提出损坏图像
- train 训练部分
- utils 工具函数
详细的可以参考README 文件
2. 获取数据集
当然最开始要配置好环境和requirements.txt 文件
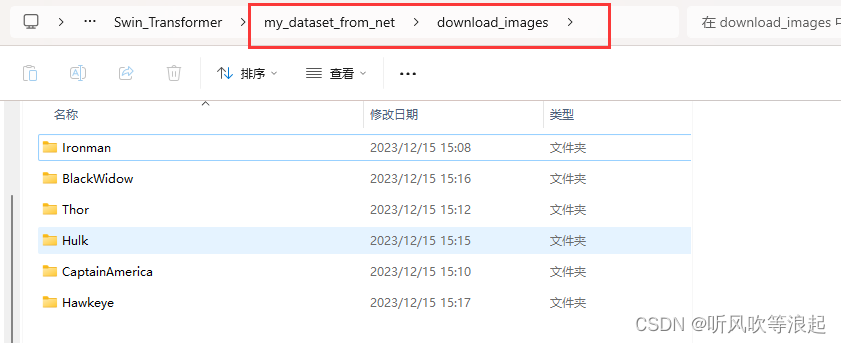
获取数据集在 my_dataset_from_net 文件下,运行文件下的main.py 可以得到:
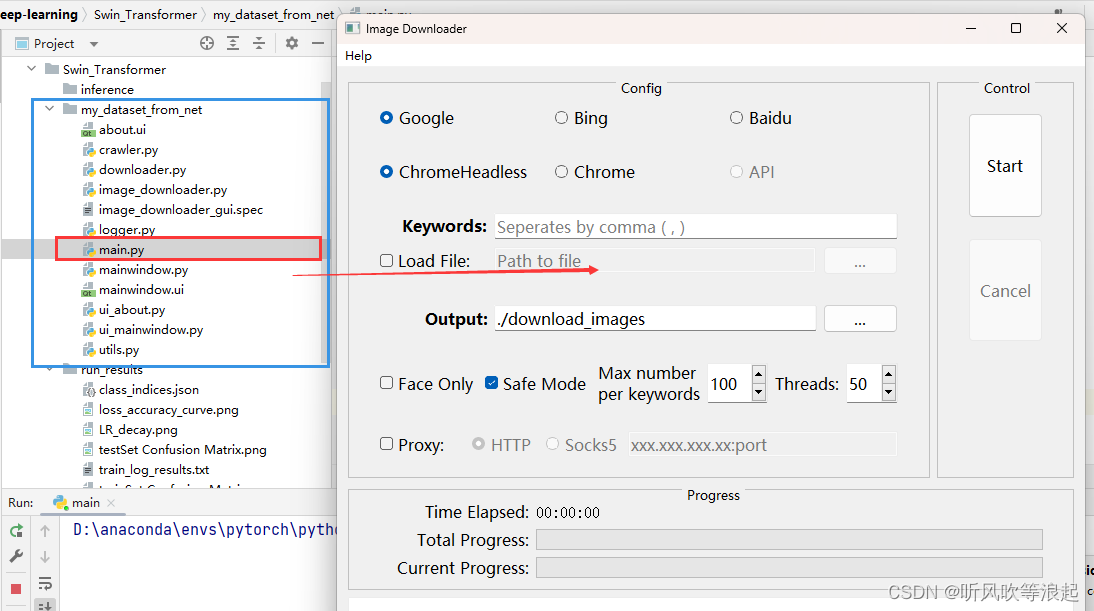
脚本会自动在该文件下生成download_images文件目录,然后会根据关键词生成子文件夹
批下载的话,可以新建txt文件,按照这样操作就行:
按照下面操作: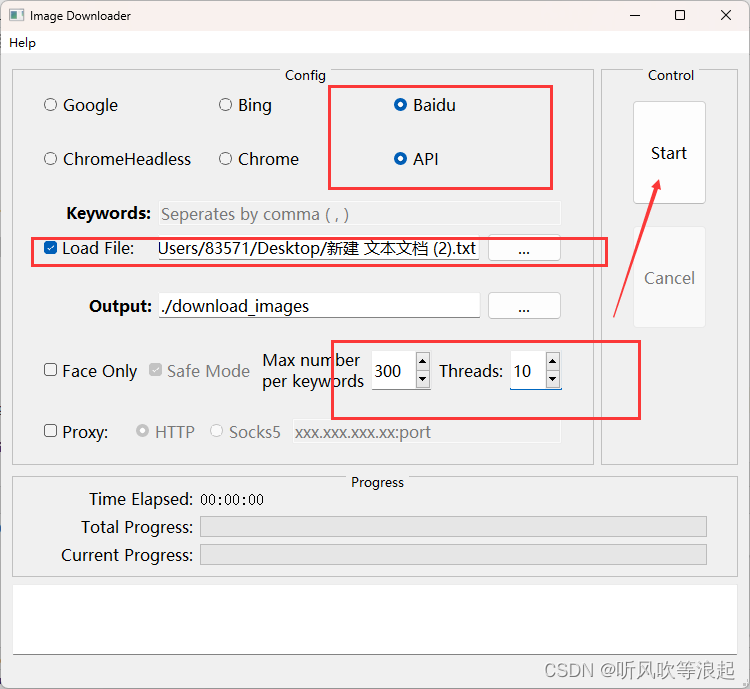
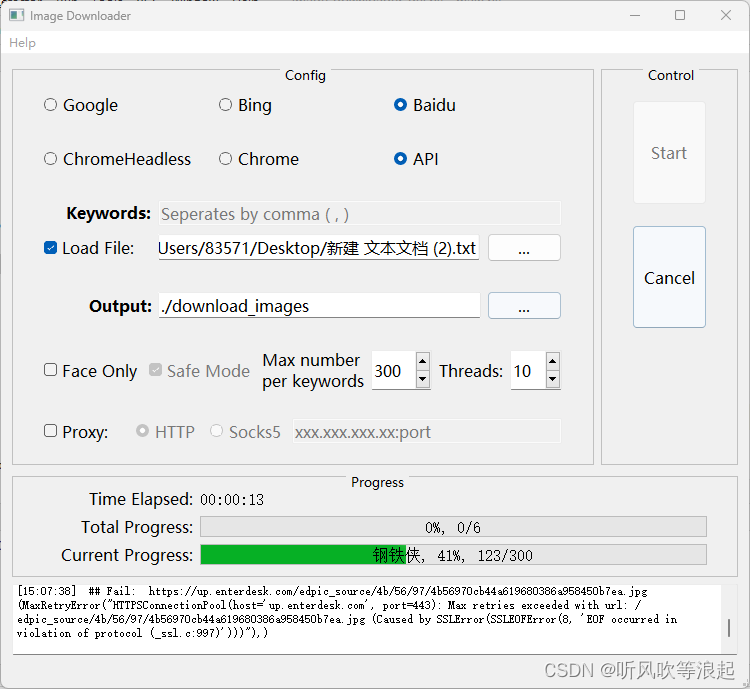
选中baidu API ,load file就是刚刚新建的txt文件
Max number per keywords 就是每个关键词下载的图像个数,Threads 最好设定小一点,否则可能会漏下载
下载过程如下:
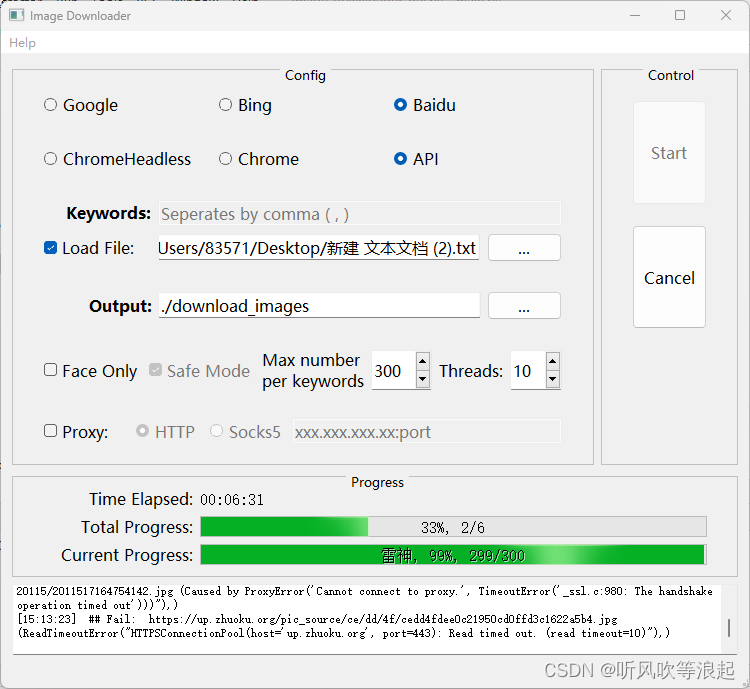
下载完成如下:

3. 对下载的图像处理、划分训练集和测试集
代码是 process_data.py 文件,因为代码用中文可能报错,这里要将文件夹改成英文
该脚本会自动删除那些 PIL 打不开的文件
代码会自动将每个子文件夹下按照 0.2比例划分测试集?

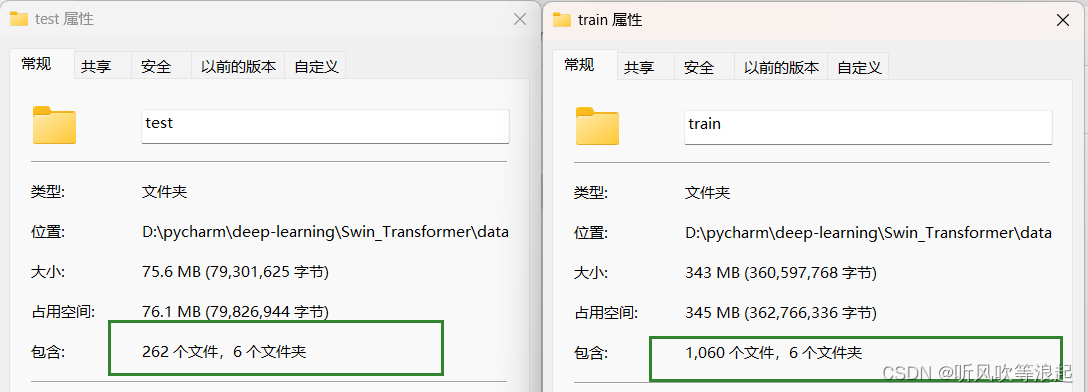
运行?process_data.py 结果如下:
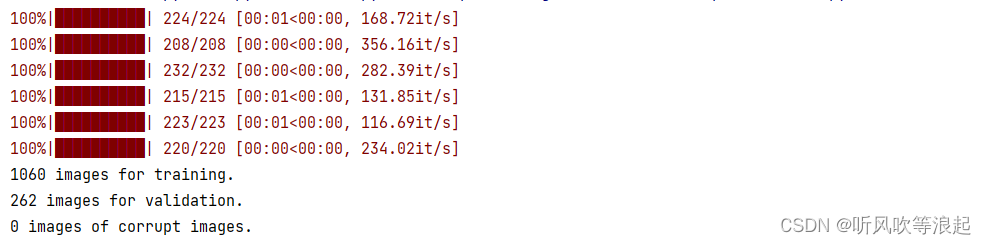
代码会在主目录下生成数据
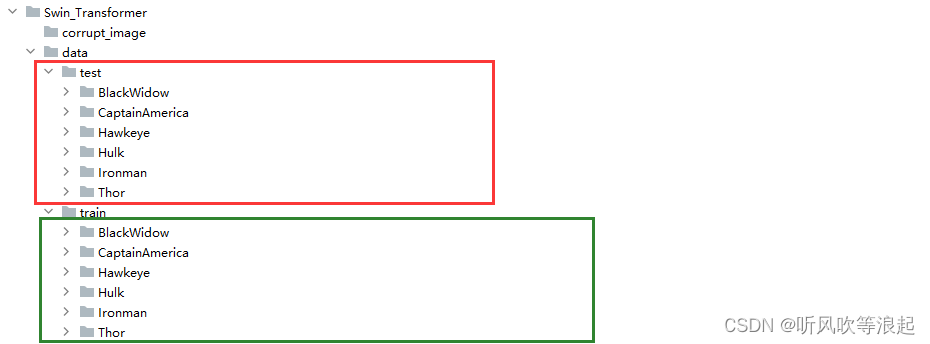
4. 开始训练
训练代码是 train.py 文件
4.1 超参数设定
超参数如下:
关于--freeze-layers,设定为True,只会训练MLP权重。False会训练全部网络
parser = argparse.ArgumentParser()
parser.add_argument('--epochs', type=int, default=100)
parser.add_argument('--batch-size', type=int, default=32)
parser.add_argument('--lr', type=float, default=0.0001)
parser.add_argument('--lrf', type=float, default=0.1)
parser.add_argument('--freeze-layers', type=bool, default=False) # 是否冻结权重至于分类的个数啊、对应标签json文件等等,这里使用 datasets.ImageFolder,代码会自动生成,不需要设定!!
只需要更改上面超参数就行!!
4.2 训练过程
将train这部分代码放开,可以查看网络训练图像信息

如下:
训练过程:
代码会自动计算分类的类别个数


训练结果:
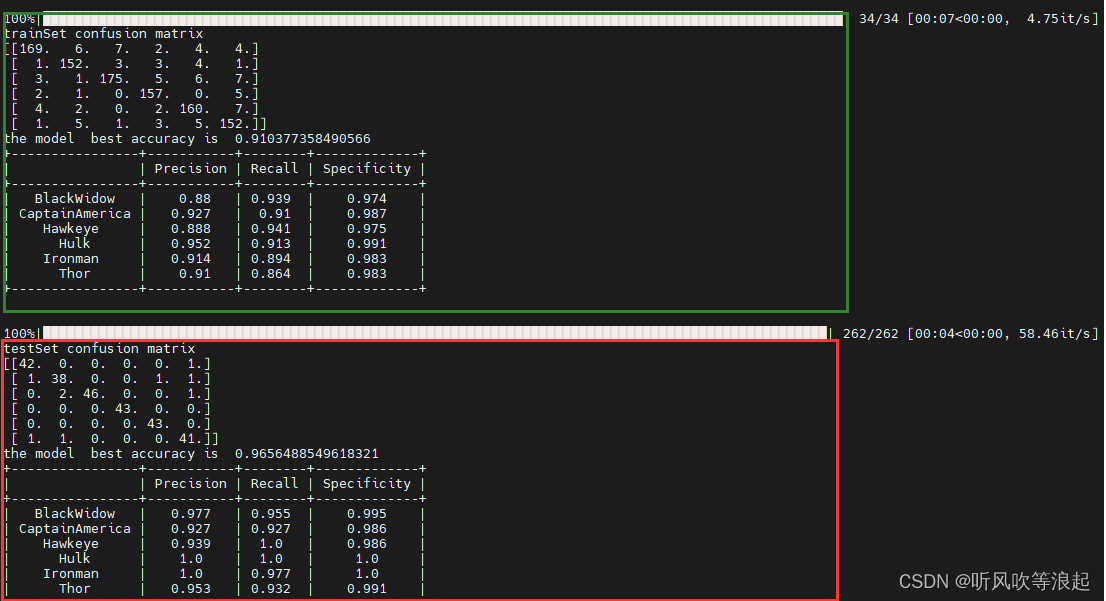
4.3 生成的训练日志
生成的结果全部保存在run_results目录下:
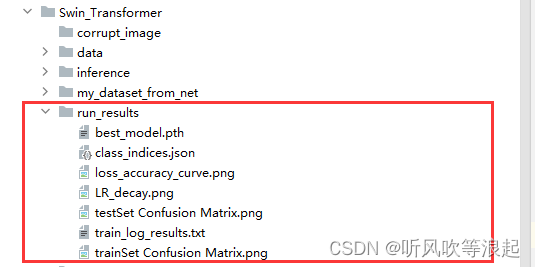
json 文件:
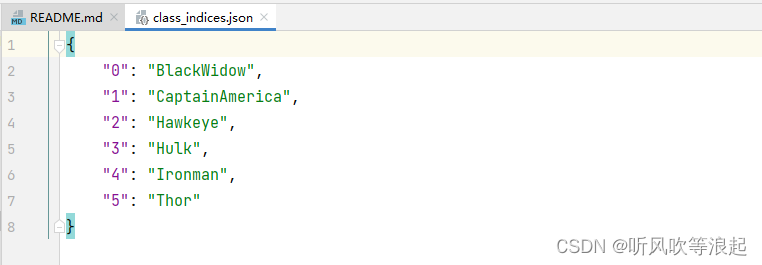
loss-accuracy-curve:
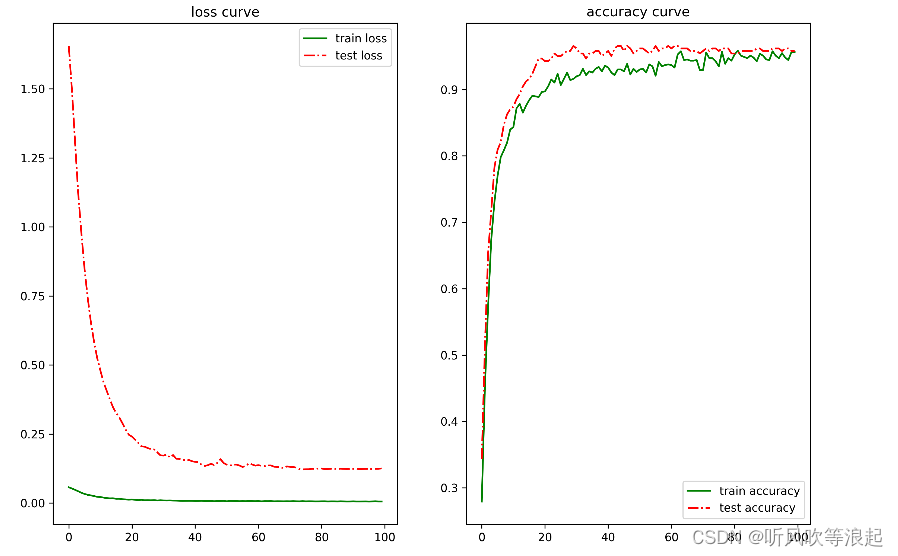
学习率衰减曲线:
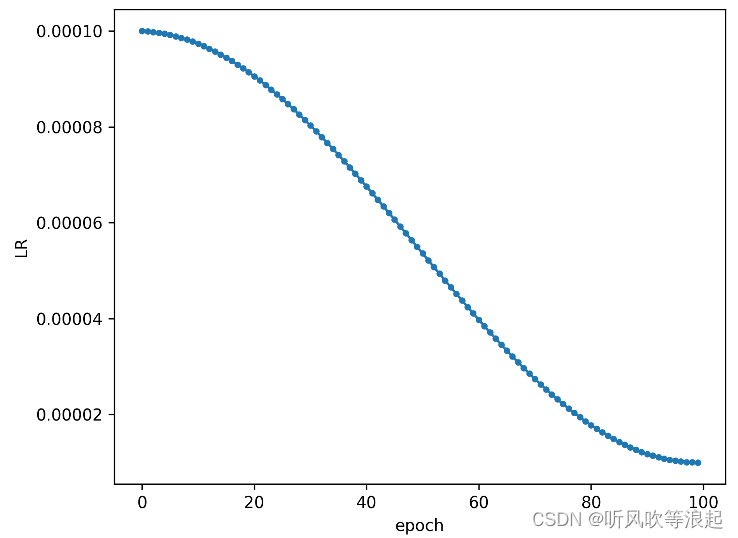
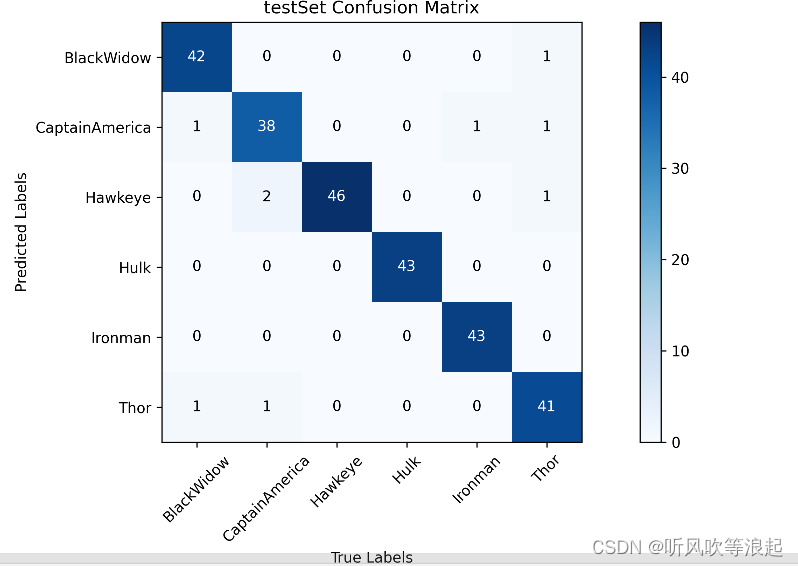
训练集和测试集的混淆矩阵:
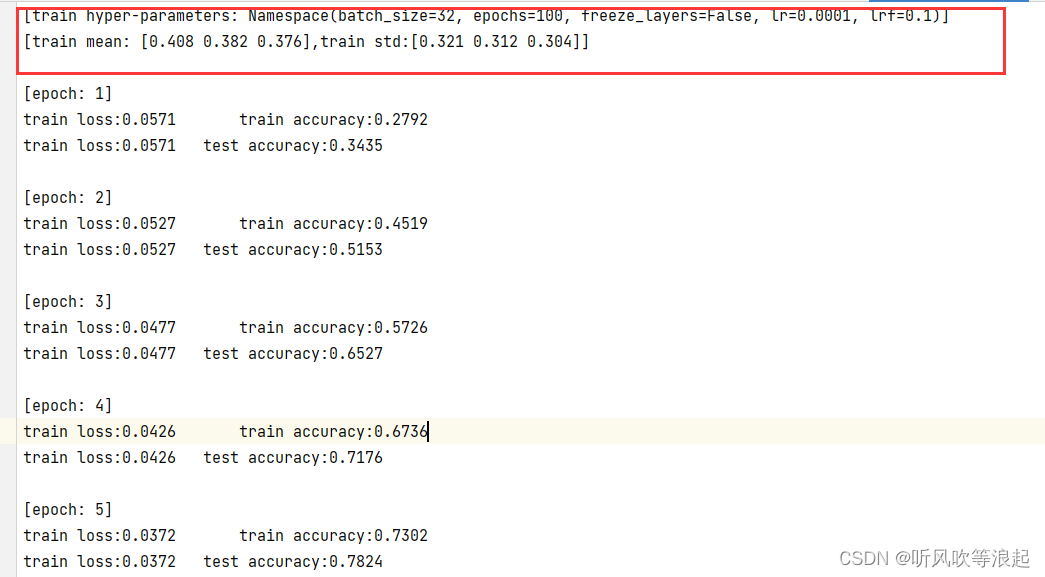
训练日志:
5. 预测脚本
预测脚本在 inference 中,predict.py 会预测该目录下所有图片
不需要任何更改!!
运行 predict.py结果如下:
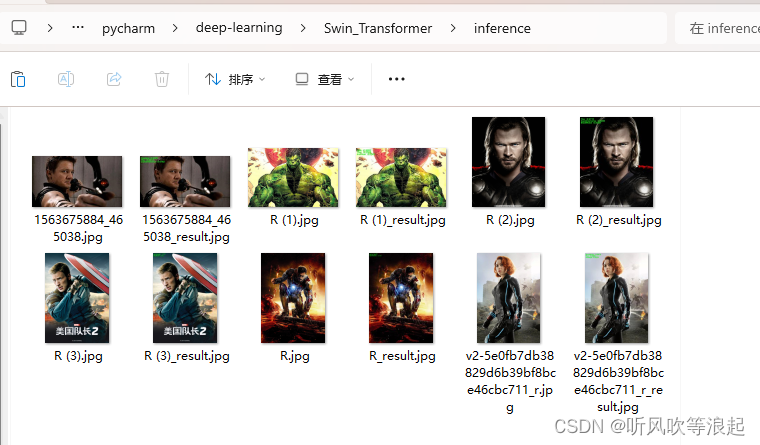
结果展示:


6. 项目的一些问题和下载
完整项目下载:图像识别完整项目之Swin-Transformer,从获取关键词数据集到训练的完整过程
爬虫下载图片的时候,下载的数目往往和设定的不一致,这个只需要将数目调大就行。事实上,本项目每个类别仅有200多张图片仍能有不错的表现
爬虫下载的图片有时候会出现不能打开的错误,但是在process_data脚本处理的时候,是没有报错的。
训练过程也没有出现错误,可能是process_data脚本的问题
如果不放心,可以手动删除,

预测的时候,因为预处理train mean和train std的原因,会计算的很慢,如果将项目部署的话,可以手动设定

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Java之LinkedList核心源码解读
- 代码随想录算法训练营第28天(回溯算法04 |● 93.复原IP地址 ● 78.子集 ● 90.子集II
- Linux的Shell程序(全面超详细的介绍)
- 未势能源受邀参加中国氢能100人论坛并发表演讲
- yolov8实时获取视频预测结果
- 探索 Golang 中的错误处理机制与最佳实践
- (1)(1.13) SiK无线电高级配置(五)
- docker应用:搭建uptime-kuma监控站点
- GreptimeAI + Xinference 联合方案:高效部署并监控你的 LLM 应用
- 从浅入深讲解Java多态