pandas之重复数据的查看、删除和提取(后附数据网盘链接)
发布时间:2024年01月15日
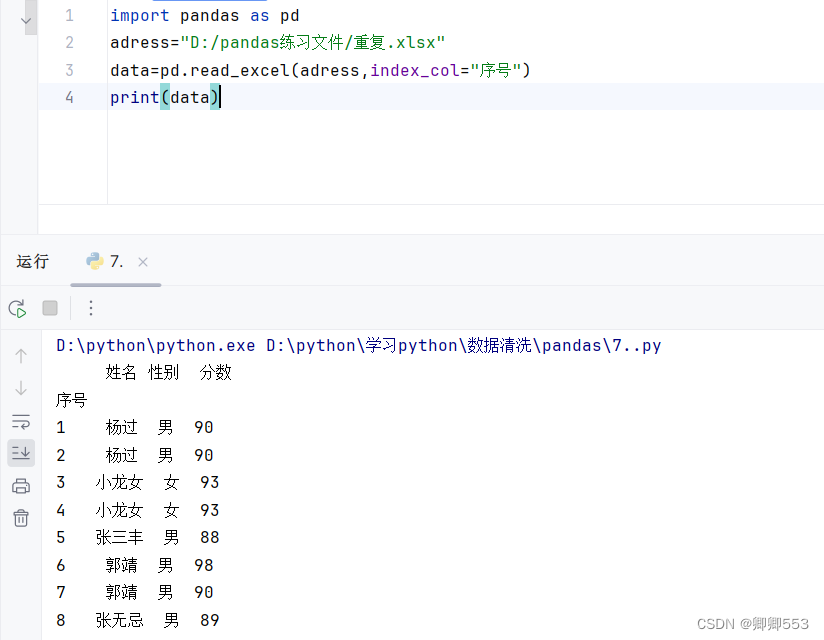
数据预览:
一、 查看value_counts()
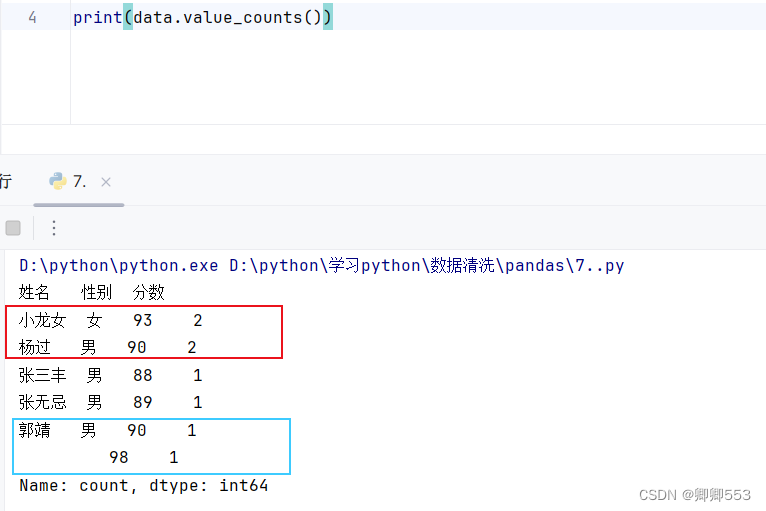
这一函数能够查看每一数据出现了几次,但是用data.value_counts()这一方法时,只有一行数据全都一样才算做重复行,如下图中的郭靖分数不一样的话它没有计入是重复行,要想以名字作为重复判断依据的话,可以用data['姓名'].value_counts()
data.value_counts()
二、删除重复?drop_duplicates()
DataFrame.drop_duplicates(subset=None, keep='first', inplace=False)
1.参数介绍
(1)subset
用来指定特定的列,默认是所有列
(2)keep
指定处理重复值的方法:
A.first:保留第一次出现的值
B.last:保留最后一次出现的值
C.False:删除所有重复值,留下没有出现过重复的
(3)inplace
是直接在原来数据上修改还是保留一个副本
2.使用方法
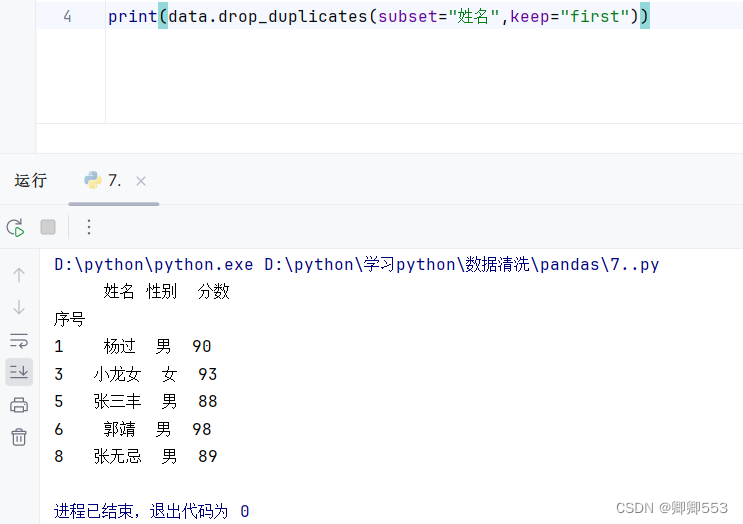
比如我想删除名字重复的整行数据,保留第一次出现的数据
data.drop_duplicates(subset="姓名",keep="first")
三、提取重复
1.参数介绍
DataFrame.duplicated(subset=None, keep='first')
本函数的参数同drop_duplicates()是一样的,这里不再赘述
2.使用方法
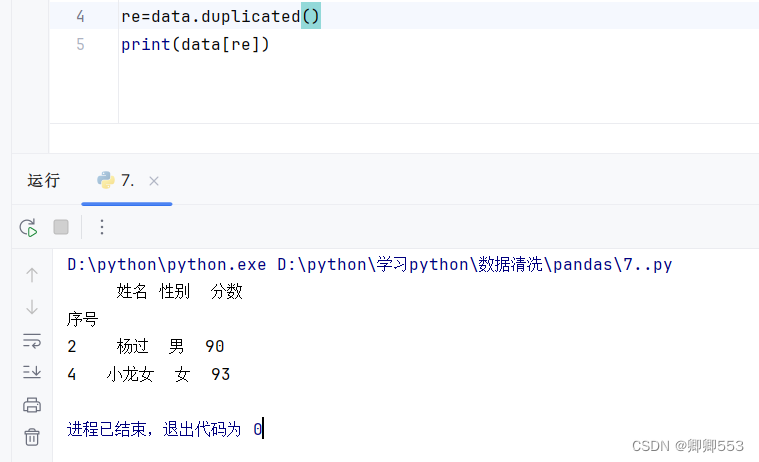
比如我想提取各列数据都一样的重复数据,由一中我们可知这样的数据有杨过和小龙女两人
re=data.duplicated() print(data[re])
四、源数据网盘链接
链接:https://pan.baidu.com/s/1FhJqeJM51ufSfcoPQJzwtg?
提取码:1234?
?
文章来源:https://blog.csdn.net/2302_80061155/article/details/135587133
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- B3842 起动电流小,工作频率 可达500kHz的Dc-Dc开关电源芯片
- 域名如何跳转到另一个域名?
- MIT线性代数笔记-第35讲-期末复习
- Anders Hejlsberg在Build 2018大会上介绍TypeScript的演讲
- k8s之对外服务ingress
- spring boot项目启动的时候 ,运行main方法报错如下:NoClassDefFoundError
- 秋招阿里巴巴java笔试试题-精
- 20240117金融读报1分钟小得
- 【jvm调优】使用JConsole工具
- App在线封装的革命性创新