Python实现离散选择负二项式模型(NegativeBinomial算法)项目实战
说明:这是一个机器学习实战项目(附带数据+代码+文档+视频讲解),如需数据+代码+文档+视频讲解可以直接到文章最后获取。


1.项目背景
离散选择负二项式模型是一种统计和经济计量模型,它结合了离散选择理论与负二项分布的特点来分析计数型的离散决策变量。在实际应用中,这种模型主要用于处理那些具有“过度分散”(overdispersion)特性的计数数据,即观测到的数据方差显著大于基于某种简单概率模型(如泊松回归模型)所预测的方差。
在离散选择框架下,个体通常会从一系列选项中做出决策,每个选项对应一个特定的计数值(比如消费者购买产品的数量、企业在一定时期内的项目投资次数等)。负二项式分布可以灵活地捕捉到不同决策背后的成功或失败试验次数以及成功之间的异质性,同时允许因变量的方差独立于其期望值而变化。
因此,离散选择负二项式模型常用于估计个体在不同情境下选择某一数量级别的概率,尤其是在社会科学、经济学、市场营销等领域,当研究对象是计数数据且存在过度离散现象时。模型参数通常用来解释影响决策的各种因素及其效应大小。
本项目通过NegativeBinomial算法来构建负二项式模型。 ?
2.数据获取
本次建模数据来源于网络(本项目撰写人整理而成),数据项统计如下:
| 编号 | 变量名称 | 描述 |
| 1 | x1 | |
| 2 | x2 | |
| 3 | x3 | |
| 4 | x4 | |
| 5 | x5 | |
| 6 | x6 | |
| 7 | x7 | |
| 8 | x8 | |
| 9 | x9 | |
| 10 | x10 | |
| 11 | y |
数据详情如下(部分展示):
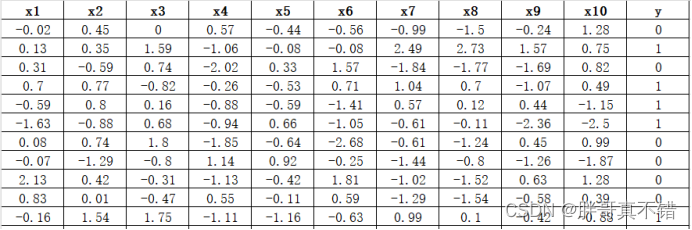
3.数据预处理
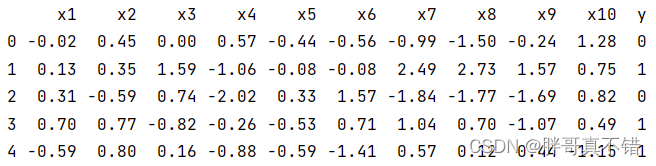
3.1?用Pandas工具查看数据
使用Pandas工具的head()方法查看前五行数据:?
关键代码:

3.2 数据缺失查看
使用Pandas工具的info()方法查看数据信息:
 ???????
???????
从上图可以看到,总共有11个变量,数据中无缺失值,共2000条数据。
关键代码:

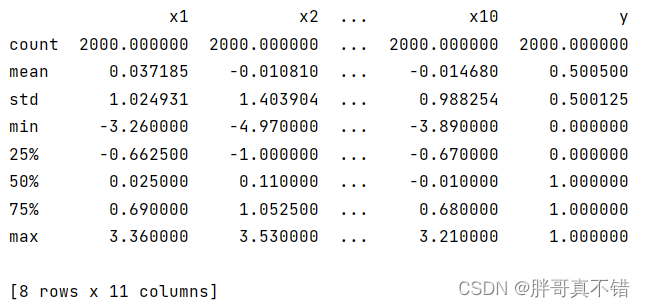
3.3?数据描述性统计
通过Pandas工具的describe()方法来查看数据的平均值、标准差、最小值、分位数、最大值。
关键代码如下: ???

4.探索性数据分析
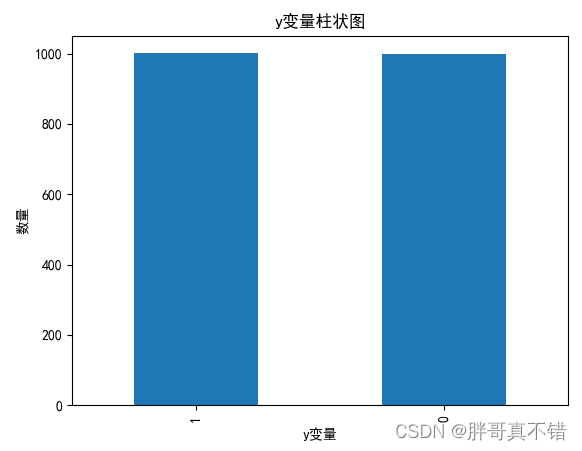
4.1?y变量柱状图
用Matplotlib工具的plot()方法绘制柱状图:
4.2 y=1样本x1变量分布直方图
用Matplotlib工具的hist()方法绘制直方图:

4.3 相关性分析

从上图中可以看到,数值越大相关性越强,正值是正相关、负值是负相关。??
5.特征工程
5.1 建立特征数据和标签数据
关键代码如下:

5.2 数据集拆分
通过train_test_split()方法按照80%训练集、20%测试集进行划分,关键代码如下:
![]()
6.构建负二项式模型
主要使用NegativeBinomial算法,用于目标分类。
6.1?构建模型
| 编号 | 模型名称 | 参数 |
| 1 | 负二项式模型? | 默认参数 |
6.2?模型的摘要信息

7.模型评估
7.1 评估指标及结果
评估指标主要包括准确率、查准率、查全率、F1分值等等。
| 模型名称 | 指标名称 | 指标值 |
| 测试集 | ||
| 负二项式模型 | 准确率 | 0.8075 |
| 查准率 | 0.7602 | |
| 查全率 | ?0.875 | |
| F1分值 | 0.8136 | |
从上表可以看出,F1分值为0.8136,说明模型效果较好。?
关键代码如下:???

7.2 分类报告
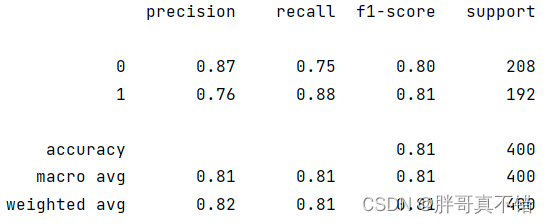 ??????
??????
从上图可以看出,分类为0的F1分值为0.80;分类为1的F1分值为0.81。
7.3 混淆矩阵
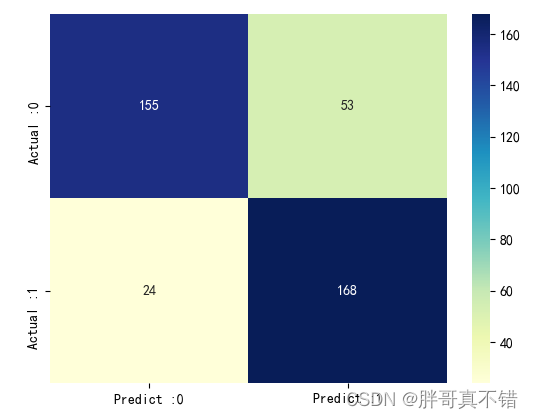
从上图可以看出,实际为0预测不为0的 有53个样本;实际为1预测不为1的 有24个样本,整体预测准确率良好。 ??
8.结论与展望
综上所述,本文采用了NegativeBinomial算法来构建负二项式模型,最终证明了我们提出的模型效果良好。此模型可用于日常产品的预测。??
# 本次机器学习项目实战所需的资料,项目资源如下:
# 项目说明:
# 获取方式一:
# 项目实战合集导航:
https://docs.qq.com/sheet/DTVd0Y2NNQUlWcmd6?tab=BB08J2
# 获取方式二:
链接:https://pan.baidu.com/s/1MHmxzubKZcmwR4frXgScXg
提取码:37on本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!