自监督学习综述
1.简介
其实自监督学习的核心思想很简单,利用大量的无标签数据训练模型,然后将其作为预训练模型在下游任务上进行微调(有标签)。在用无标签图像训练模型时主要通过设计辅助任务,用图像自身的信息作为标签训练。常见的就是对比学习,将原图本身和经过图像增强的图像作为正样本,其他作为负样本。
对比学习,cv通过对输入图像进行数据增强,将数据增强的图像作为原图的正样本,其他输入图像作为负样本。但是这种模式在nlp中却不好使用,将一句话中的单词替换为同义词,预测的结果很可能会产生偏差,所以nlp选择用dropout的方法。同一张图像通过两个分支进行dropout,其中dropout的层是不一样的,随机选择的,所以产生的结果向量也是不同的,那么这两个向量就互相为正样本了。
token。Tokenization is a way of separating a piece of text into smaller units called tokens.And tokens are the building blocks of Natural Language,which can be either words, characters, or subwords.
token包含:class token、patch token,在NLP叫每一个单词为token,然后有一个标注句子语义的标注是CLS,在CV中就是把图像切割成不重叠的patch序列(其实就是token)。
在大型语言模型中,"token"是指文本中的一个最小单位。通常,一个token可以是一个单词、一个标点符号、一个数字、一个符号等。在自然语言处理中,tokenization是将一个句子或文本分成tokens的过程。
在大型语言模型的训练和应用中,模型接收一串tokens作为输入,并尝试预测下一个最可能的token。对于很多模型来说,tokens还可以通过embedding操作转换为向量表示,以便在神经网络中进行处理。由于大型语言模型处理的文本非常大,因此对于处理速度和内存占用等方面的考虑,通常会使用特定的tokenization方法,例如基于字节对编码(byte-pair encoding,BPE)或者WordPiece等算法。?
在NLP比如BERT,输入一段句子,分词器会将句子中的单词、符号转换成一个个token。对于视觉Transformer,把每个像素看作是一个token的话并不现实,因为一张224x224的图片铺平后就有4万多个token,计算量太大了,BERT都限制了token最长只能512。所以ViT把一张图切分成一个个16x16的patch(具体数值可以自己修改)每个patch看作是一个token,这样一共就只有(224/16)*(224/16)=196个token了。当然了,单单的切分还不够,还要做一个线性映射+位置编码等等。不同的Transformer在处理细节上也会有不同,比如最近看的Swin-T加入了多尺度,从最开始的4*4的patch缩放到后边的32*32。
BEIT最终得到的就是一个ViT预训练模型,用这个预训练模型在下游任务上进行训练,效果会有明显提升。
2.自监督网络
2.1 SimCLR
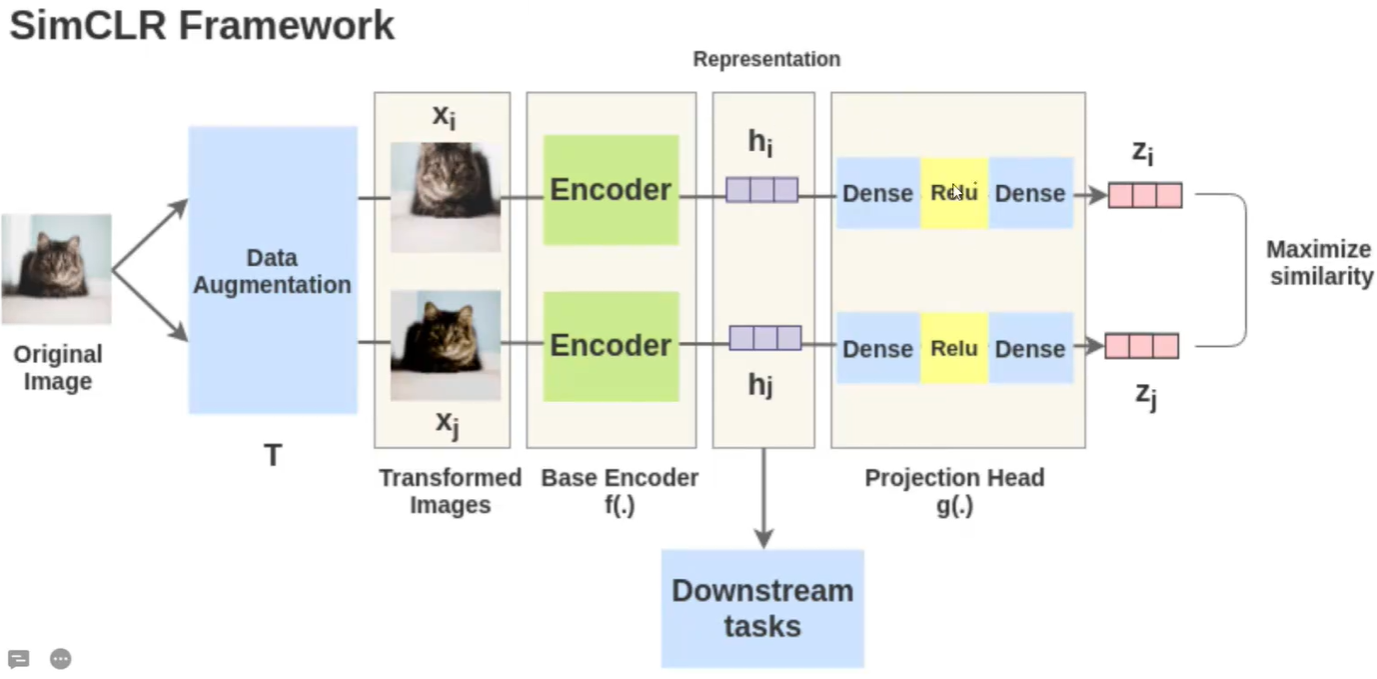
SimCLR的原理非常简单,输入一个图像,对该图像先进行数据增强得到不同的两个图象,然后经过encoder进行特征提取,分别得到hi和hj,在经过一个MLP得到最终的向量Zi和Zj。训练好后得到一个特征提取器Encoder,这样在用到下游任务上时训练速度精度都会更好。
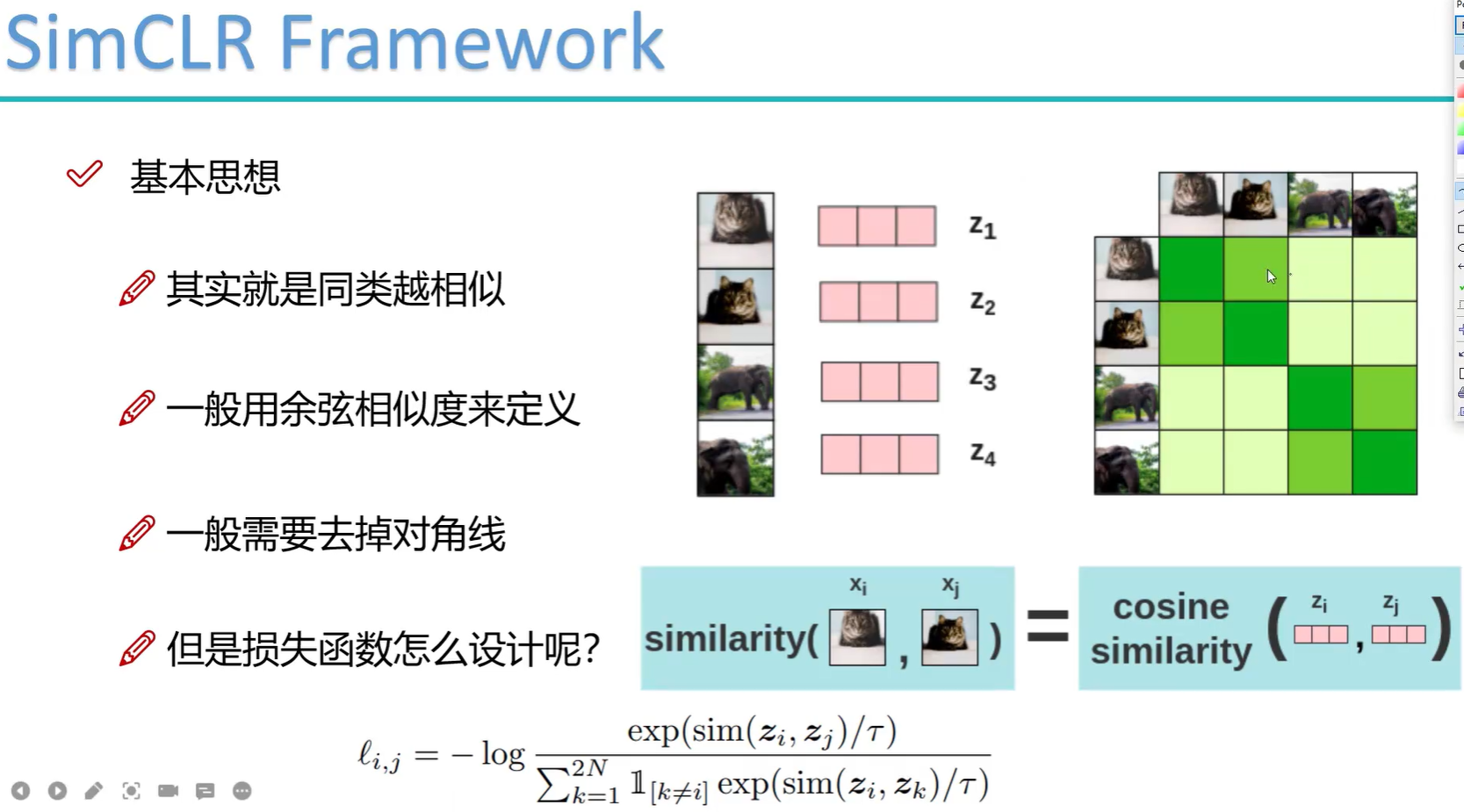
训练过程的batchsize为8192,所以需要的硬件条件比较苛刻。训练时输入经过数据增强的数据,将其他8191个样本作为负样本,原图的数据增强图作为正样本。对输出的向量算余弦相似度,对角线上的值接近一。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【Flutter】dart class、 mixin和extends、implements、with那些事
- c++知识总结
- 20240111在ubuntu20.04.6下解压缩RAR格式的压缩包
- ???恒峰|配网行波型故障预警定位装置:电力系统的守护神
- Dockerfile详解
- 如何科学地防范冬季流感
- 【排序】快速排序(C语言实现)
- 【基础算法】前缀和
- MongoDB的原子操作findAndModify和findOneAndUpdate
- OpenHarmony开发环境快速搭建(无需命令行)