海量并发场景下,如何实现分布式事务
什么是分布式事务
首先得知道,正常一个事务要满足ACID原则,但是实际上,海量并发环境下是分库分表的,需要协调多个系统才能完成一个事务。那么怎么设计策略来保证事务的ACID中的C一致性呢?接下来介绍主要的两种思想。
强一致性(集中式)
两阶段提交协议
这是最朴素的解决方式,将事务分为两个阶段,分别是投票和提交。有一个全局管理者——协调者,还有若干参与者(即发起事务请求的)
投票
协调者会向事务的参与者发起执行操作的CanCommit请求,并等待参与者的响应。参与者收到请求后会执行自己的事务操作,然后记录日志,但不提交事务。执行成功向协调者发Yes,反之No
提交
协调者看是不是所有参与者都是Yes,是的话向参与者发送DoCommit,参与者收到后会提交事务并释放资源(锁)。
假设协调者发现不是所有参与者都Yes了,那就向所有参与者发送DoAbort,此时发Yes的参与者就回滚。
最后所有参与者接收到不论是DoCommit还是DoAbort都会回复协调者HaveCommitted
不足
协调者寄了,系统就崩了。
网络出问题了,假设协调者发DoCommit不是所有参与者都受到了,那系统数据就不一致了。
所有参与者都是事务阻塞型的,无法高并发。
三阶段提交协议
为了解决二阶段提交的同步阻塞和数据不一致问题,三阶段提交引入了超时机制和准备阶段。
CanCommit
与二阶段一样,只不过参与者接收到协调者发来的CanCommit后只判断能不能正常执行,而不真的执行。判断能就返回Yes,不能就No
PreCommit
如果所有参与者都给协调者发的Yes,那么协调者就会发送PreCommit给所有参与者。参与者执行事务,并记录日志,并返回ACK给协调者。
假设有参与者给协调者发No,或者超时了,那协调者就会给所有参与者发Abort指令。参与者收到Abort或者超时就中断事务执行。
DoCommit
若协调者接收到所有参与者发送的Ack响应,则向所有参与者发送DoCommit消息。参与者接收到DoCommit消息之后,正式提交事务。完成事务提交之后,释放所有锁住的资源,并向协调者发送Ack响应。协调者接收到所有参与者的Ack响应之后,完成事务。
假设有参与者没返回Ack或者协调者等待超时,协调者向所有参与者发送Abort请求。参与者接收到Abort消息之后,利用其在PreCommit阶段记录的Undo信息执行事务的回滚操作,释放所有锁住的资源,并向协调者发送Ack消息。协调者接收到参与者反馈的Ack消息之后,执行事务的中断,并结束事务。
最终一致性(分布式)
eBay
基于分布式消息的最终一致性方案,其引入了一个消息中间件(Message Queue,MQ,消息队列)。以网购下单为例,假设用户A在某电商平台下了一个订单,需要支付50元,发现自己的账户余额共150元,就使用余额支付,支付成功之后,订单状态修改为支付成功,然后通知仓库发货。过程如下所示:
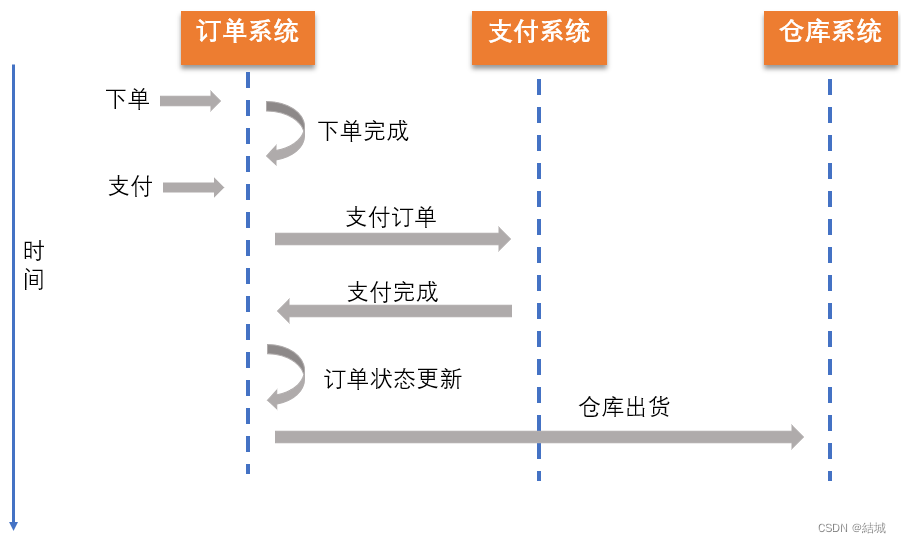
那对于eBay而言,处理流程是:

每次执行成功一个指令,都在消息队列(消息中间件)里持久化一条消息。假设失败就删除消息。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- flutter项目用vscode打包apk包,完美运行到手机上
- 阿里云主导《Serverless 计算安全指南》国际标准正式立项!
- 命令行导出excel格式mysql中文数据乱码解决
- 【C++】C++入门(一)
- 《后疫情时代薪酬管理和数字化趋势报告》
- 05-微服务Sentinel流量哨兵
- 聊一下JVM调优
- 面向对象三大特征之三:多态--java学习笔记
- 【FPGA & Modsim】数字频率计
- JAVA面试题13