SAM-Track online / offline配置
segment anything model(SAM)是Meta于2023年4月5日发布的分割基础模型。SAM 允许分割任何对象而无需微调。
可以在这里尝试SAM模型的效果。

分割效果这么好,都忍不住想用SAM来做场景的语义分割,realtime与否先放在一边,能不能用SAM来做语义分割。
一张图片是可以的,但是多张连续图片序列或视频,就会出现颜色频繁变化的问题,因为它的颜色不代表语义,颜色是随机的。SAM只有分块功能,并没有判断类别的功能。
想让连续的图片序列中语义保持连续,就出现了SAM-Track.
github地址
可以实现某一个目标的分割+跟踪,也可以跟踪第一帧里分割出来的anything.

不想在本地配置的同学们可以直接线上运行,
SAMTrack.ipynb
好处是cuda版本这些的都不用在意,直接就能运行。
缺点是隔一段时间就要全部重新运行,而且上传速度慢。
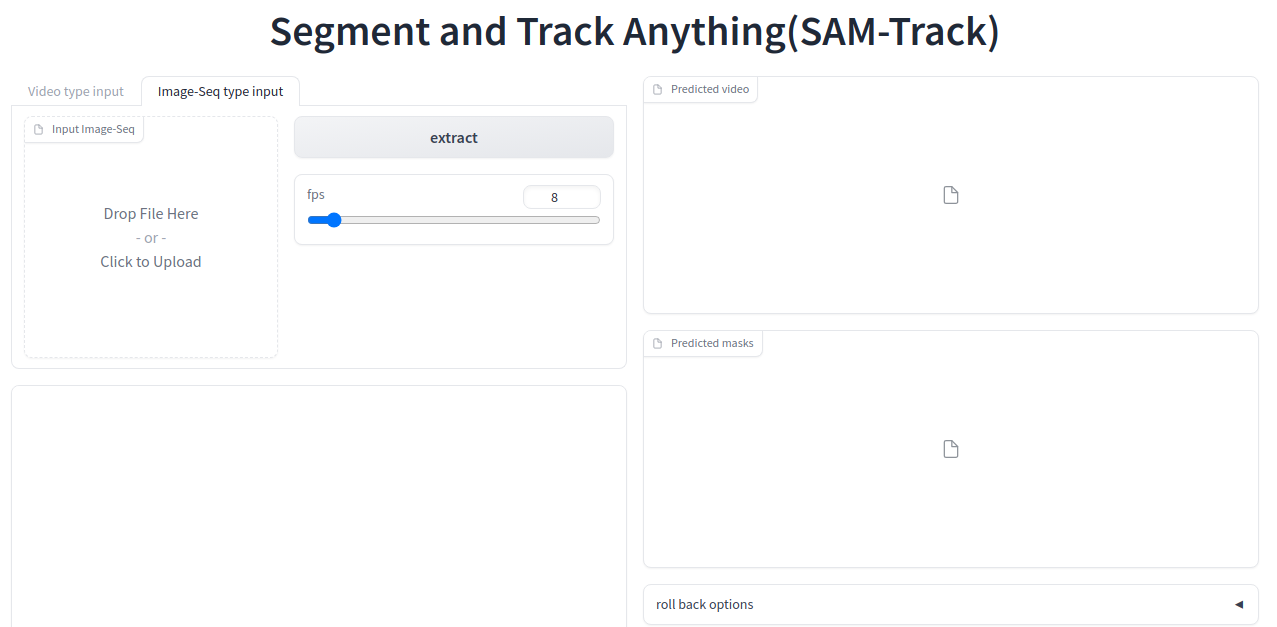
input可以选video, 也可以选image sequence.
上传之后,点segment everything for 1st frame(跟踪第一帧),
然后start tracking. 就可以坐等处理好的image sequence masks和mp4.
如果是本地配置,也可以按照SAMTrack.ipynb里的顺序执行,但是可能会出现问题。
python app.py
这时候会出现一个127.0.0.1的链接,进入连接就会出现上面的webUI,
但是当点segment everything for 1st frame时报错,
case 1:
NVIDIA driver too old
这是pytorch+cudatookit和本机的cuda不匹配的原因,本机只能用cuda11.X,
那么去pytorch官网找到匹配11.X的版本。
case 2:
ValueError: Unknown scheme for proxy URL URL(‘socks://127.0.0.1:10801/’)
你是否手动设置了network proxy?改为自动。
case 3:
OSError: We couldn’t connect to ‘https://huggingface.co’ to load this file
网络问题,把文件下载下来本地解决。
从报错内容得知路径为bert-base-uncased,
那么从这个站点下载需要的文件。
bert-base-uncased
下载这几个,
例如放在新建的bert_base文件夹,在Segment-and-Track-Anything/bert_base.
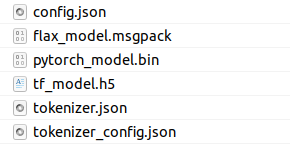
根据报错位置修改路径,比如
修改Segment-and-Track-Anything/src/groundingdino/groundingdino/util/ge
t_tokenlizer.py
#tokenizer = AutoTokenizer.from_pretrained(text_encoder_type)
tokenizer = AutoTokenizer.from_pretrained("Segment-and-Track-Anything/bert_base") #上面的文件放在新建的bert_base文件夹
#return BertModel.from_pretrained(text_encoder_type)
return BertModel.from_pretrained("Segment-and-Track-Anything/bert_base")
case 4:
Unable to load weights from pytorch checkpoint file
安装的pytorch版本和要求的不一致,
ipynb中的版本是torch 2.1.0+cu121, 试试看>=2.0。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- .h5文件简介
- GB 4806.5-2016 食品接触玻璃制品 餐具检测 第三方检测机构 实验室
- Move_Certificates-v1.9安装-Magisk movecert模块安装时出现‘unzip error‘的解决办法
- 2024年【陕西省安全员C证】考试总结及陕西省安全员C证复审考试
- 聊聊PowerJob的QueryConvertUtils
- Linux包的管理(RPM和YUM)
- 微软发布安卓版Copilot,可免费使用GPT-4、DALL-E 3
- 找不到x3daudio1_7.dll怎么解决,六种有效快速x3daudio1_7.dll修复教程分享
- crtc 原理
- 【方案】世微AP51656 电流采样降压恒流驱动 60V3A LED灯 SOT89-5