爬虫—响应页面乱码问题解决方法
发布时间:2024年01月13日
爬虫—响应页面乱码问题解决方法
案例:腾牛网图片抓取
源代码如下:
import requests
url = 'https://www.qqtn.com/wm/meinvtp_1.html'
headers = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36'
}
res = requests.get(url, headers=headers
data = res.content.decode()
print(data)
执行之后,报错如下:

解决办法:
- 方法一,设置解码格式为’GBK’
data = res.content.decode('GBK')
print(data)
运行结果如下:
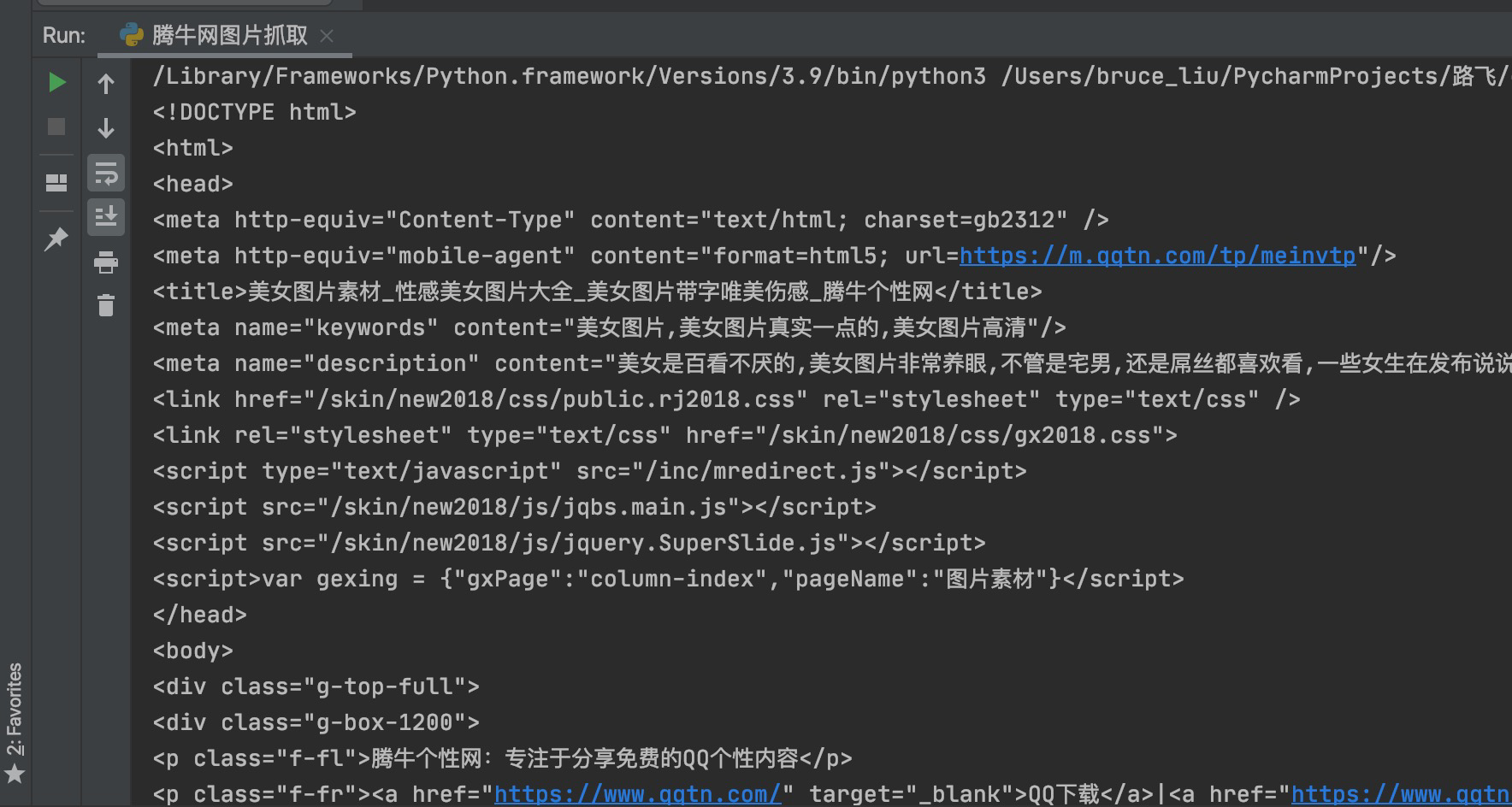
- 方法二,自动获取解码格式
# 自动获取解码格式
res.encoding = res.apparent_encoding
data = res.text
print(data)
文章来源:https://blog.csdn.net/weixin_41905135/article/details/135567150
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- JD商品详情实时数据的采集item_get-获得JD商品详情
- VSC(Visual Studio Code)好用插件推荐
- 论文分享—— Prediction of Landslide Risk Based on Modified GRNN Algorithm
- 供应链+低代码,实现数字化【共赢链】转型新策略
- 做到这两条,破解35岁中年危机
- 理解DOM树的加载过程
- web前端案例之星星点灯
- 专业130+总分380+哈尔滨工程大学810信号与系统考研经验水声电子信息与通信
- vim插件使用
- #vue3 实现前端下载excel文件模板功能