秋招复习之数组与链表
目录
前言
复习数组和链表,包括数组链表和列表,以及他们的一些基本操作,这里主要写的Java和cpp语言。
1 数组

初始化数组:
两种方式
Java
/* 初始化数组 */
int[] arr = new int[5]; // { 0, 0, 0, 0, 0 }
int[] nums = { 1, 3, 2, 5, 4 };cpp:
/* 初始化数组 */
// 存储在栈上
int arr[5];
int nums[5] = { 1, 3, 2, 5, 4 };
// 存储在堆上(需要手动释放空间)
int* arr1 = new int[5];
int* nums1 = new int[5] { 1, 3, 2, 5, 4 };访问元素
索引本质上是内存地址的偏移量。
在数组中访问元素非常高效,我们可以在?O(1)?时间内随机访问数组中的任意一个元素。
/* 随机访问元素 */
int randomAccess(int[] nums) {
// 在区间 [0, nums.length) 中随机抽取一个数字
int randomIndex = ThreadLocalRandom.current().nextInt(0, nums.length);
// 获取并返回随机元素
int randomNum = nums[randomIndex];
return randomNum;
}/* 随机访问元素 */
int randomAccess(int *nums, int size) {
// 在区间 [0, size) 中随机抽取一个数字
int randomIndex = rand() % size;
// 获取并返回随机元素
int randomNum = nums[randomIndex];
return randomNum;
}这里Java和cpp中用于在一定范围内随机抽取一个数字用的方法是不一样。
插入元素
数组元素在内存中是“紧挨着的”,它们之间没有空间再存放任何数据。如图 所示,如果想在数组中间插入一个元素,则需要将该元素之后的所有元素都向后移动一位,之后再把元素赋值给该索引。

?
/* 在数组的索引 index 处插入元素 num */
void insert(int[] nums, int num, int index) {
// 把索引 index 以及之后的所有元素向后移动一位
for (int i = nums.length - 1; i > index; i--) {
nums[i] = nums[i - 1];
}
// 将 num 赋给 index 处的元素
nums[index] = num;
}/* 在数组的索引 index 处插入元素 num */
void insert(int *nums, int size, int num, int index) {
// 把索引 index 以及之后的所有元素向后移动一位
for (int i = size - 1; i > index; i--) {
nums[i] = nums[i - 1];
}
// 将 num 赋给 index 处的元素
nums[index] = num;
}删除元素?
?同理,如图 4-4 所示,若想删除索引?i处的元素,则需要把索引i?之后的元素都向前移动一位。

/* 删除索引 index 处的元素 */
void remove(int[] nums, int index) {
// 把索引 index 之后的所有元素向前移动一位
for (int i = index; i < nums.length - 1; i++) {
nums[i] = nums[i + 1];
}
}/* 删除索引 index 处的元素 */
void remove(int *nums, int size, int index) {
// 把索引 index 之后的所有元素向前移动一位
for (int i = index; i < size - 1; i++) {
nums[i] = nums[i + 1];
}
}总的来看,数组的插入与删除操作有以下缺点。
- 时间复杂度高:数组的插入和删除的平均时间复杂度均为O(n),其中n为数组长度。
- 丢失元素:由于数组的长度不可变,因此在插入元素后,超出数组长度范围的元素会丢失。
- 内存浪费:我们可以初始化一个比较长的数组,只用前面一部分,这样在插入数据时,丢失的末尾元素都是“无意义”的,但这样做会造成部分内存空间浪费。
遍历数组:
/* 遍历数组 */
void traverse(int[] nums) {
int count = 0;
// 通过索引遍历数组
for (int i = 0; i < nums.length; i++) {
count += nums[i];
}
// 直接遍历数组元素
for (int num : nums) {
count += num;
}
}/* 遍历数组 */
void traverse(int *nums, int size) {
int count = 0;
// 通过索引遍历数组
for (int i = 0; i < size; i++) {
count += nums[i];
}
}查找元素?
在数组中查找指定元素需要遍历数组,每轮判断元素值是否匹配,若匹配则输出对应索引。
因为数组是线性数据结构,所以上述查找操作被称为“线性查找”。
/* 在数组中查找指定元素 */
int find(int[] nums, int target) {
for (int i = 0; i < nums.length; i++) {
if (nums[i] == target)
return i;
}
return -1;
}/* 在数组中查找指定元素 */
int find(int *nums, int size, int target) {
for (int i = 0; i < size; i++) {
if (nums[i] == target)
return i;
}
return -1;
}扩容数组:
在复杂的系统环境中,程序难以保证数组之后的内存空间是可用的,从而无法安全地扩展数组容量。因此在大多数编程语言中,数组的长度是不可变的。
如果我们希望扩容数组,则需重新建立一个更大的数组,然后把原数组元素依次复制到新数组。这是一个?O(n)的操作,在数组很大的情况下非常耗时。代码如下所示:
/* 扩展数组长度 */
int[] extend(int[] nums, int enlarge) {
// 初始化一个扩展长度后的数组
int[] res = new int[nums.length + enlarge];
// 将原数组中的所有元素复制到新数组
for (int i = 0; i < nums.length; i++) {
res[i] = nums[i];
}
// 返回扩展后的新数组
return res;
}/* 扩展数组长度 */
int *extend(int *nums, int size, int enlarge) {
// 初始化一个扩展长度后的数组
int *res = new int[size + enlarge];
// 将原数组中的所有元素复制到新数组
for (int i = 0; i < size; i++) {
res[i] = nums[i];
}
// 释放内存
delete[] nums;
// 返回扩展后的新数组
return res;
}数组的优点与局限性
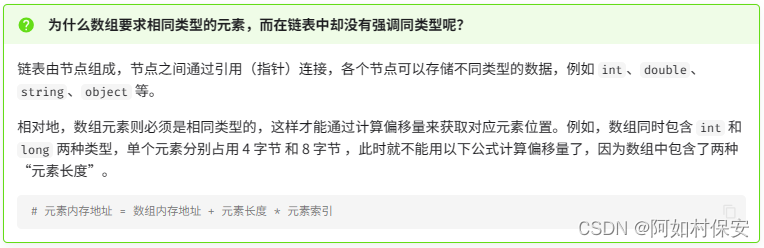
数组存储在连续的内存空间内,且元素类型相同。这种做法包含丰富的先验信息,系统可以利用这些信息来优化数据结构的操作效率。
- 空间效率高:数组为数据分配了连续的内存块,无须额外的结构开销。
- 支持随机访问:数组允许在?O(1)?时间内访问任何元素。
- 缓存局部性:当访问数组元素时,计算机不仅会加载它,还会缓存其周围的其他数据,从而借助高速缓存来提升后续操作的执行速度。
连续空间存储是一把双刃剑,其存在以下局限性。
- 插入与删除效率低:当数组中元素较多时,插入与删除操作需要移动大量的元素。
- 长度不可变:数组在初始化后长度就固定了,扩容数组需要将所有数据复制到新数组,开销很大。
- 空间浪费:如果数组分配的大小超过实际所需,那么多余的空间就被浪费了。
2 链表
「链表 linked list」是一种线性数据结构,其中的每个元素都是一个节点对象,各个节点通过“引用”相连接。引用记录了下一个节点的内存地址,通过它可以从当前节点访问到下一个节点。
链表的设计使得各个节点可以分散存储在内存各处,它们的内存地址无须连续。
 ?
?
链表的组成单位是「节点 node」对象。每个节点都包含两项数据:节点的“值”和指向下一节点的“引用”。
- 链表的首个节点被称为“头节点”,最后一个节点被称为“尾节点”。
- 尾节点指向的是“空”,它在 Java、C++ 和 Python 中分别被记为?
null、nullptr?和?None?。 - 在 C、C++、Go 和 Rust 等支持指针的语言中,上述“引用”应被替换为“指针”。
如以下代码所示,链表节点?ListNode?除了包含值,还需额外保存一个引用(指针)。因此在相同数据量下,链表比数组占用更多的内存空间。
/* 链表节点类 */
class ListNode {
int val; // 节点值
ListNode next; // 指向下一节点的引用
ListNode(int x) { val = x; } // 构造函数
}/* 链表节点结构体 */
struct ListNode {
int val; // 节点值
ListNode *next; // 指向下一节点的指针
ListNode(int x) : val(x), next(nullptr) {} // 构造函数
};初始化链表
建立链表分为两步,第一步是初始化各个节点对象,第二步是构建节点之间的引用关系。初始化完成后,我们就可以从链表的头节点出发,通过引用指向?next?依次访问所有节点。
/* 初始化链表 1 -> 3 -> 2 -> 5 -> 4 */
// 初始化各个节点
ListNode n0 = new ListNode(1);
ListNode n1 = new ListNode(3);
ListNode n2 = new ListNode(2);
ListNode n3 = new ListNode(5);
ListNode n4 = new ListNode(4);
// 构建节点之间的引用
n0.next = n1;
n1.next = n2;
n2.next = n3;
n3.next = n4;/* 初始化链表 1 -> 3 -> 2 -> 5 -> 4 */
// 初始化各个节点
ListNode* n0 = new ListNode(1);
ListNode* n1 = new ListNode(3);
ListNode* n2 = new ListNode(2);
ListNode* n3 = new ListNode(5);
ListNode* n4 = new ListNode(4);
// 构建节点之间的引用
n0->next = n1;
n1->next = n2;
n2->next = n3;
n3->next = n4;数组整体是一个变量,比如数组?nums?包含元素?nums[0]?和?nums[1]?等,而链表是由多个独立的节点对象组成的。我们通常将头节点当作链表的代称,比如以上代码中的链表可记作链表?n0?。
插入节点
在链表中插入节点非常容易。如图 4-6 所示,假设我们想在相邻的两个节点?n0?和?n1?之间插入一个新节点?P?,则只需改变两个节点引用(指针)即可,时间复杂度为?O(1)?。
相比之下,在数组中插入元素的时间复杂度为?O(n)?,在大数据量下的效率较低。
 ?
?
/* 在链表的节点 n0 之后插入节点 P */
void insert(ListNode n0, ListNode P) {
ListNode n1 = n0.next;
P.next = n1;
n0.next = P;
}/* 在链表的节点 n0 之后插入节点 P */
void insert(ListNode *n0, ListNode *P) {
ListNode *n1 = n0->next;
P->next = n1;
n0->next = P;
}删除节点
在链表中删除节点也非常方便,只需改变一个节点的引用(指针)即可。
请注意,尽管在删除操作完成后节点?P?仍然指向?n1?,但实际上遍历此链表已经无法访问到?P?,这意味着?P?已经不再属于该链表了。
 ?
?
/* 删除链表的节点 n0 之后的首个节点 */
void remove(ListNode n0) {
if (n0.next == null)
return;
// n0 -> P -> n1
ListNode P = n0.next;
ListNode n1 = P.next;
n0.next = n1;
}/* 删除链表的节点 n0 之后的首个节点 */
void remove(ListNode *n0) {
if (n0->next == nullptr)
return;
// n0 -> P -> n1
ListNode *P = n0->next;
ListNode *n1 = P->next;
n0->next = n1;
// 释放内存
delete P;
}访问节点
在链表中访问节点的效率较低。如上一节所述,我们可以在?O(1)?时间下访问数组中的任意元素。链表则不然,程序需要从头节点出发,逐个向后遍历,直至找到目标节点。也就是说,访问链表的第 i?个节点需要循环?i?1?轮,时间复杂度为O(n)?。
/* 访问链表中索引为 index 的节点 */
ListNode access(ListNode head, int index) {
for (int i = 0; i < index; i++) {
if (head == null)
return null;
head = head.next;
}
return head;
}/* 访问链表中索引为 index 的节点 */
ListNode *access(ListNode *head, int index) {
for (int i = 0; i < index; i++) {
if (head == nullptr)
return nullptr;
head = head->next;
}
return head;
}查找节点
遍历链表,查找其中值为?target?的节点,输出该节点在链表中的索引。此过程也属于线性查找。代码如下所示:
/* 在链表中查找值为 target 的首个节点 */
int find(ListNode head, int target) {
int index = 0;
while (head != null) {
if (head.val == target)
return index;
head = head.next;
index++;
}
return -1;
}/* 在链表中查找值为 target 的首个节点 */
int find(ListNode *head, int target) {
int index = 0;
while (head != nullptr) {
if (head->val == target)
return index;
head = head->next;
index++;
}
return -1;
}数组 vs. 链表
 ?
?
常见链表类型
如图所示,常见的链表类型包括三种。
- 单向链表:即前面介绍的普通链表。单向链表的节点包含值和指向下一节点的引用两项数据。我们将首个节点称为头节点,将最后一个节点称为尾节点,尾节点指向空?
None?。 - 环形链表:如果我们令单向链表的尾节点指向头节点(首尾相接),则得到一个环形链表。在环形链表中,任意节点都可以视作头节点。
- 双向链表:与单向链表相比,双向链表记录了两个方向的引用。双向链表的节点定义同时包含指向后继节点(下一个节点)和前驱节点(上一个节点)的引用(指针)。相较于单向链表,双向链表更具灵活性,可以朝两个方向遍历链表,但相应地也需要占用更多的内存空间。
/* 双向链表节点类 */
class ListNode {
int val; // 节点值
ListNode next; // 指向后继节点的引用
ListNode prev; // 指向前驱节点的引用
ListNode(int x) { val = x; } // 构造函数
}/* 双向链表节点结构体 */
struct ListNode {
int val; // 节点值
ListNode *next; // 指向后继节点的指针
ListNode *prev; // 指向前驱节点的指针
ListNode(int x) : val(x), next(nullptr), prev(nullptr) {} // 构造函数
}; ?
?
3?列表
「列表 list」是一个抽象的数据结构概念,它表示元素的有序集合,支持元素访问、修改、添加、删除和遍历等操作,无须使用者考虑容量限制的问题。列表可以基于链表或数组实现。
- 链表天然可以看作一个列表,其支持元素增删查改操作,并且可以灵活动态扩容。
- 数组也支持元素增删查改,但由于其长度不可变,因此只能看作一个具有长度限制的列表。
当使用数组实现列表时,长度不可变的性质会导致列表的实用性降低。这是因为我们通常无法事先确定需要存储多少数据,从而难以选择合适的列表长度。若长度过小,则很可能无法满足使用需求;若长度过大,则会造成内存空间浪费。
为解决此问题,我们可以使用「动态数组 dynamic array」来实现列表。它继承了数组的各项优点,并且可以在程序运行过程中进行动态扩容。
实际上,许多编程语言中的标准库提供的列表是基于动态数组实现的,例如 Python 中的?list?、Java 中的?ArrayList?、C++ 中的?vector?和 C# 中的?List?等。在接下来的讨论中,我们将把“列表”和“动态数组”视为等同的概念。
初始化列表
/* 初始化列表 */
// 无初始值
List<Integer> nums1 = new ArrayList<>();
// 有初始值(注意数组的元素类型需为 int[] 的包装类 Integer[])
Integer[] numbers = new Integer[] { 1, 3, 2, 5, 4 };
List<Integer> nums = new ArrayList<>(Arrays.asList(numbers));/* 初始化列表 */
// 需注意,C++ 中 vector 即是本文描述的 nums
// 无初始值
vector<int> nums1;
// 有初始值
vector<int> nums = { 1, 3, 2, 5, 4 };访问元素
列表本质上是数组,因此可以在?O(1)?时间内访问和更新元素,效率很高。
/* 访问元素 */
int num = nums.get(1); // 访问索引 1 处的元素
/* 更新元素 */
nums.set(1, 0); // 将索引 1 处的元素更新为 0/* 访问元素 */
int num = nums[1]; // 访问索引 1 处的元素
/* 更新元素 */
nums[1] = 0; // 将索引 1 处的元素更新为 0插入与删除元素
相较于数组,列表可以自由地添加与删除元素。在列表尾部添加元素的时间复杂度为?O(1)?,但插入和删除元素的效率仍与数组相同,时间复杂度为?O(n)?。
/* 清空列表 */
nums.clear();
/* 在尾部添加元素 */
nums.add(1);
nums.add(3);
nums.add(2);
nums.add(5);
nums.add(4);
/* 在中间插入元素 */
nums.add(3, 6); // 在索引 3 处插入数字 6
/* 删除元素 */
nums.remove(3); // 删除索引 3 处的元素/* 清空列表 */
nums.clear();
/* 在尾部添加元素 */
nums.push_back(1);
nums.push_back(3);
nums.push_back(2);
nums.push_back(5);
nums.push_back(4);
/* 在中间插入元素 */
nums.insert(nums.begin() + 3, 6); // 在索引 3 处插入数字 6
/* 删除元素 */
nums.erase(nums.begin() + 3); // 删除索引 3 处的元素遍历列表
与数组一样,列表可以根据索引遍历,也可以直接遍历各元素。
/* 通过索引遍历列表 */
int count = 0;
for (int i = 0; i < nums.size(); i++) {
count += nums.get(i);
}
/* 直接遍历列表元素 */
for (int num : nums) {
count += num;
}/* 通过索引遍历列表 */
int count = 0;
for (int i = 0; i < nums.size(); i++) {
count += nums[i];
}
/* 直接遍历列表元素 */
count = 0;
for (int num : nums) {
count += num;
}拼接列表
给定一个新列表?nums1?,我们可以将其拼接到原列表的尾部。
/* 拼接两个列表 */
List<Integer> nums1 = new ArrayList<>(Arrays.asList(new Integer[] { 6, 8, 7, 10, 9 }));
nums.addAll(nums1); // 将列表 nums1 拼接到 nums 之后/* 拼接两个列表 */
vector<int> nums1 = { 6, 8, 7, 10, 9 };
// 将列表 nums1 拼接到 nums 之后
nums.insert(nums.end(), nums1.begin(), nums1.end());排序列表
完成列表排序后,我们便可以使用在数组类算法题中经常考查的“二分查找”和“双指针”算法。
/* 排序列表 */
Collections.sort(nums); // 排序后,列表元素从小到大排列/* 排序列表 */
sort(nums.begin(), nums.end()); // 排序后,列表元素从小到大排列列表实现
简易版列表,包括以下三个重点设计。
- 初始容量:选取一个合理的数组初始容量。在本示例中,我们选择 10 作为初始容量。
- 数量记录:声明一个变量?
size?,用于记录列表当前元素数量,并随着元素插入和删除实时更新。根据此变量,我们可以定位列表尾部,以及判断是否需要扩容。 - 扩容机制:若插入元素时列表容量已满,则需要进行扩容。先根据扩容倍数创建一个更大的数组,再将当前数组的所有元素依次移动至新数组。在本示例中,我们规定每次将数组扩容至之前的 2 倍。
/* 列表类 */
class MyList {
private int[] arr; // 数组(存储列表元素)
private int capacity = 10; // 列表容量
private int size = 0; // 列表长度(当前元素数量)
private int extendRatio = 2; // 每次列表扩容的倍数
/* 构造方法 */
public MyList() {
arr = new int[capacity];
}
/* 获取列表长度(当前元素数量) */
public int size() {
return size;
}
/* 获取列表容量 */
public int capacity() {
return capacity;
}
/* 访问元素 */
public int get(int index) {
// 索引如果越界,则抛出异常,下同
if (index < 0 || index >= size)
throw new IndexOutOfBoundsException("索引越界");
return arr[index];
}
/* 更新元素 */
public void set(int index, int num) {
if (index < 0 || index >= size)
throw new IndexOutOfBoundsException("索引越界");
arr[index] = num;
}
/* 在尾部添加元素 */
public void add(int num) {
// 元素数量超出容量时,触发扩容机制
if (size == capacity())
extendCapacity();
arr[size] = num;
// 更新元素数量
size++;
}
/* 在中间插入元素 */
public void insert(int index, int num) {
if (index < 0 || index >= size)
throw new IndexOutOfBoundsException("索引越界");
// 元素数量超出容量时,触发扩容机制
if (size == capacity())
extendCapacity();
// 将索引 index 以及之后的元素都向后移动一位
for (int j = size - 1; j >= index; j--) {
arr[j + 1] = arr[j];
}
arr[index] = num;
// 更新元素数量
size++;
}
/* 删除元素 */
public int remove(int index) {
if (index < 0 || index >= size)
throw new IndexOutOfBoundsException("索引越界");
int num = arr[index];
// 将索引 index 之后的元素都向前移动一位
for (int j = index; j < size - 1; j++) {
arr[j] = arr[j + 1];
}
// 更新元素数量
size--;
// 返回被删除的元素
return num;
}
/* 列表扩容 */
public void extendCapacity() {
// 新建一个长度为原数组 extendRatio 倍的新数组,并将原数组复制到新数组
arr = Arrays.copyOf(arr, capacity() * extendRatio);
// 更新列表容量
capacity = arr.length;
}
/* 将列表转换为数组 */
public int[] toArray() {
int size = size();
// 仅转换有效长度范围内的列表元素
int[] arr = new int[size];
for (int i = 0; i < size; i++) {
arr[i] = get(i);
}
return arr;
}
}/* 列表类 */
class MyList {
private:
int *arr; // 数组(存储列表元素)
int arrCapacity = 10; // 列表容量
int arrSize = 0; // 列表长度(当前元素数量)
int extendRatio = 2; // 每次列表扩容的倍数
public:
/* 构造方法 */
MyList() {
arr = new int[arrCapacity];
}
/* 析构方法 */
~MyList() {
delete[] arr;
}
/* 获取列表长度(当前元素数量)*/
int size() {
return arrSize;
}
/* 获取列表容量 */
int capacity() {
return arrCapacity;
}
/* 访问元素 */
int get(int index) {
// 索引如果越界,则抛出异常,下同
if (index < 0 || index >= size())
throw out_of_range("索引越界");
return arr[index];
}
/* 更新元素 */
void set(int index, int num) {
if (index < 0 || index >= size())
throw out_of_range("索引越界");
arr[index] = num;
}
/* 在尾部添加元素 */
void add(int num) {
// 元素数量超出容量时,触发扩容机制
if (size() == capacity())
extendCapacity();
arr[size()] = num;
// 更新元素数量
arrSize++;
}
/* 在中间插入元素 */
void insert(int index, int num) {
if (index < 0 || index >= size())
throw out_of_range("索引越界");
// 元素数量超出容量时,触发扩容机制
if (size() == capacity())
extendCapacity();
// 将索引 index 以及之后的元素都向后移动一位
for (int j = size() - 1; j >= index; j--) {
arr[j + 1] = arr[j];
}
arr[index] = num;
// 更新元素数量
arrSize++;
}
/* 删除元素 */
int remove(int index) {
if (index < 0 || index >= size())
throw out_of_range("索引越界");
int num = arr[index];
// 索引 i 之后的元素都向前移动一位
for (int j = index; j < size() - 1; j++) {
arr[j] = arr[j + 1];
}
// 更新元素数量
arrSize--;
// 返回被删除的元素
return num;
}
/* 列表扩容 */
void extendCapacity() {
// 新建一个长度为原数组 extendRatio 倍的新数组
int newCapacity = capacity() * extendRatio;
int *tmp = arr;
arr = new int[newCapacity];
// 将原数组中的所有元素复制到新数组
for (int i = 0; i < size(); i++) {
arr[i] = tmp[i];
}
// 释放内存
delete[] tmp;
arrCapacity = newCapacity;
}
/* 将列表转换为 Vector 用于打印 */
vector<int> toVector() {
// 仅转换有效长度范围内的列表元素
vector<int> vec(size());
for (int i = 0; i < size(); i++) {
vec[i] = arr[i];
}
return vec;
}
};4?内存与缓存
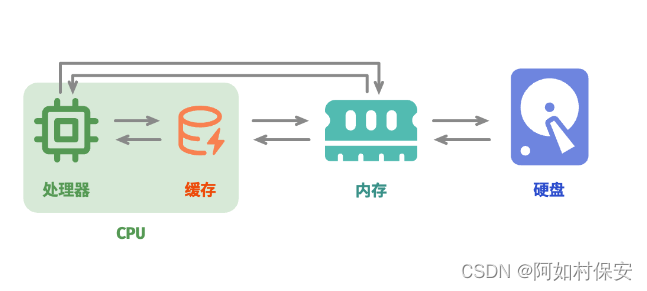
物理结构在很大程度上决定了程序对内存和缓存的使用效率,进而影响算法程序的整体性能。
计算机中包括三种类型的存储设备:「硬盘 hard disk」、「内存 random-access memory, RAM」、「缓存 cache memory」。表展示了它们在计算机系统中的不同角色和性能特点。
 ?
?
越靠近金字塔顶端的存储设备的速度越快、容量越小、成本越高。这种多层级的设计并非偶然,而是计算机科学家和工程师们经过深思熟虑的结果。
- 硬盘难以被内存取代。首先,内存中的数据在断电后会丢失,因此它不适合长期存储数据;其次,内存的成本是硬盘的几十倍,这使得它难以在消费者市场普及。
- 缓存的大容量和高速度难以兼得。随着 L1、L2、L3 缓存的容量逐步增大,其物理尺寸会变大,与 CPU 核心之间的物理距离会变远,从而导致数据传输时间增加,元素访问延迟变高。在当前技术下,多层级的缓存结构是容量、速度和成本之间的最佳平衡点。
 ?
?
计算机的存储层次结构体现了速度、容量和成本三者之间的精妙平衡。实际上,这种权衡普遍存在于所有工业领域,它要求我们在不同的优势和限制之间找到最佳平衡点。
总的来说,硬盘用于长期存储大量数据,内存用于临时存储程序运行中正在处理的数据,而缓存则用于存储经常访问的数据和指令,以提高程序运行效率。三者共同协作,确保计算机系统高效运行。
如图所示,在程序运行时,数据会从硬盘中被读取到内存中,供 CPU 计算使用。缓存可以看作 CPU 的一部分,它通过智能地从内存加载数据,给 CPU 提供高速的数据读取,从而显著提升程序的执行效率,减少对较慢的内存的依赖。
 ?
?
总结
 ?
?
 ?
?
 ?
?
 ?
?
 ?
?
 ?
?
 ?
?
语言真的烦的很,不同的项目就要用不同的语言,所以都复习一下,但是很容易搞混。
这里的复习参考是:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 通过建立良好的客户服务体系,提高用户对淘宝商品详情API的满意度和忠诚度
- Day03-ES6
- 腾讯云轻量应用服务器详细配置教程(最新版)
- Python 爬虫入门指南:网络数据采集的艺术
- 第6章-第2节-Java中的String类
- LeetCode 30. 串联所有单词的子串
- tritonserver学习之五:backend实现机制
- 扫一扫计数的工具有哪些?分享3款实用的!
- 高校教务系统登录页面JS分析——河北农业大学教务系统
- 知识笔记(五十四)———mysql比较varchar值大小_Mysql varchar大小长度问题