19个Python语法糖和9个内置装饰器
19 个Sweet的 Python Syntax Sugar,用于改善您的编码体验
文章目录
- 19 个Sweet的 Python Syntax Sugar,用于改善您的编码体验
- 1. 联合运算符Union Operators:合并 Python 字典的最优雅方式
- 2. 类型提示Type Hints:使您的 Python 程序类型安全
- 3. F-Strings:一种 Pythonic 字符串格式化方法
- 4. 使用省略号Ellipsis作为未编写代码的占位符
- 5. Python 中的装饰器Decorators:一种模块化功能和分离关注点的方法
- 6.列表推导式List Comprehension:用一行代码创建一个列表
- 7.用于定义小型匿名函数的 Lambda 函数
- 8.三元条件操作符Ternary Conditional Operators:将 If 和 Else 放进一行代码中
- 9.使用 "枚举Enumerate" 方法优雅地迭代列表Iterate Lists
- 10.上下文管理器Context Manager自动关闭资源
- 11.Python 列表的花式切片技巧Fancy Slicing Tricks
- 12.海象运算符Walrus Operator:表达式内的赋值
- 13.连续比较Continuous Comparisons:一种更自然的方式来编写 If 条件
- 14.Zip 函数:轻松组合多个可迭代对象Multiple Iterables
- 15.直接交换两个变量Swapping Two Variables Directly
- 16.解构赋值技巧Destructuring Assignments Tricks
- 17.用星号拆包可迭代对象Unpacking Iterables
- 18.Any() 和 All() 函数
- 19.数字中的下划线
- 9 个可大幅优化代码的 Python 内置装饰器Built-In Decorators
- 1.@lru_cache:通过缓存加快程序运行速度
- 2.@total_ordering:补全缺失的排序方法的类装饰器
- 3.@contextmanager:创建自定义上下文管理器Customized Context Manager
- 4.@property:为 Python 类设置访问器Getters和修改器Setters
- 5.@cached_property:将方法Method的结果缓存为属性Attribute
- 6.@classmethod:在 Python 类中定义类方法
- 7.@staticmethod:在 Python 类中定义静态方法
- 8.@dataclass: 用更少的代码定义特殊类
- 9.@atexit.register:注册在正常程序终止时要执行的函数
使函数正常工作是一回事,使用精确而优雅的代码实现它是另一回事。
正如 Python 的禅宗所提到的,“美丽总比丑陋好”。
像 Python 这样好的编程语言总是会提供适当的语法糖,以帮助开发人员轻松编写优雅的代码。
本文重点介绍了 Python 中的 19 个关键语法糖。掌握的旅程涉及理解和熟练地利用它们。
1. 联合运算符Union Operators:合并 Python 字典的最优雅方式
在 Python 中合并多个字典的方法有很多种,但在 Python 3.9 发布之前,没有一种方法可以被描述为优雅。
例如,我们如何在 Python 3.9 之前合并以下三个字典?
其中一种方法是使用 for 循环:
cities_us = {'New York City': 'US', 'Los Angeles': 'US'}
cities_uk = {'London': 'UK', 'Birmingham': 'UK'}
cities_jp = {'Tokyo': 'JP'}
cities = {}
for city_dict in [cities_us, cities_uk, cities_jp]:
for city, country in city_dict.items():
cities[city] = country
print(cities)
# {'New York City': 'US', 'Los Angeles': 'US', 'London': 'UK', 'Birmingham': 'UK', 'Tokyo': 'JP'}
它很体面,但远非优雅和 Pythonic。
Python 3.9 引入了联合运算符,这是一种语法糖,使合并任务变得超级简单:
cities_us = {'New York City': 'US', 'Los Angeles': 'US'}
cities_uk = {'London': 'UK', 'Birmingham': 'UK'}
cities_jp = {'Tokyo': 'JP'}
cities = cities_us | cities_uk | cities_jp
print(cities)
# {'New York City': 'US', 'Los Angeles': 'US', 'London': 'UK', 'Birmingham': 'UK', 'Tokyo': 'JP'}
如上面的程序所示,我们可以使用一些管道符号pipe symbols,在这种情况下称为联合运算符union operators,来合并任意数量的 Python 字典。
是否可以通过联合运算符进行就地合并?
cities_us = {'New York City': 'US', 'Los Angeles': 'US'}
cities_uk = {'London': 'UK', 'Birmingham': 'UK'}
cities_jp = {'Tokyo': 'JP'}
cities_us |= cities_uk | cities_jp
print(cities_us)
# {'New York City': 'US', 'Los Angeles': 'US', 'London': 'UK', 'Birmingham': 'UK', 'Tokyo': 'JP'}
当然,只需将联合运算符移动到等号的左侧,如上面的代码所示。
2. 类型提示Type Hints:使您的 Python 程序类型安全
动态类型化Dynamic typing,即在运行时确定变量的类型,是使 Python 灵活方便的关键特性。但是,如果变量类型不正确,也可能导致隐藏的错误和错误。
为了解决这个问题,Python 在 3.5 版本中引入了键入提示功能typing hint feature。它提供了一种在代码中注释变量类型annotate variable types的方法,现代 IDE 可以在开发过程中为开发人员及早发现类型错误。
例如,如果我们将一个变量定义为整数,但将其更改为字符串,如下所示,IDE(在本例中为 PyCharm)将为我们突出显示意外的代码:
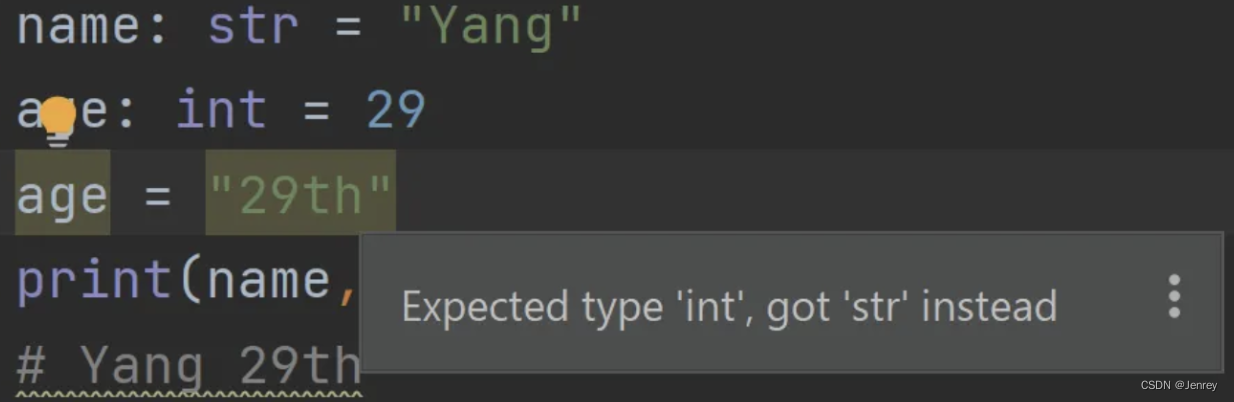
除了原始类型之外,还有一些高级类型提示技巧。
例如,在 Python 中使用所有大写字母定义常量是一种常见的约定。
DATABASE = 'MySQL'
但是,这只是一种约定,没有人可以阻止您为这个“常量constant”分配新值。
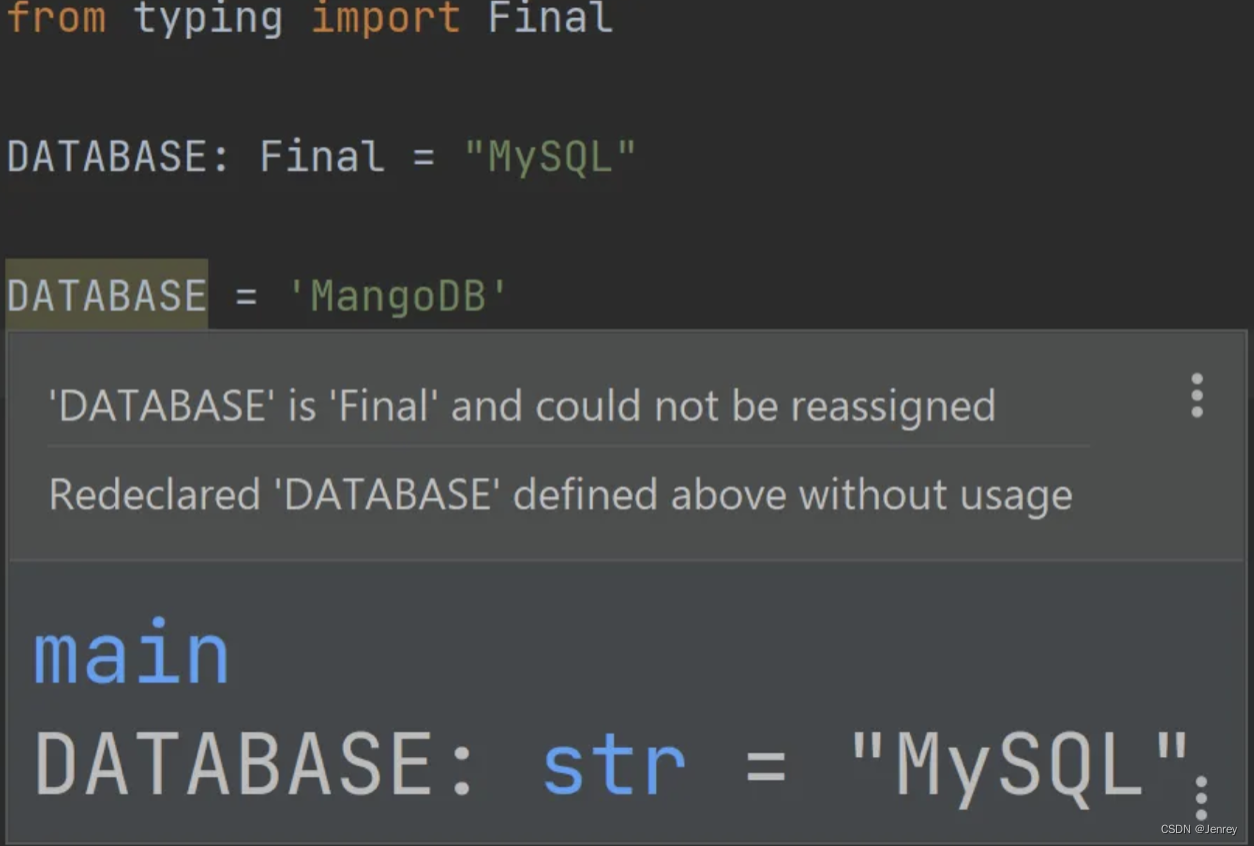
为了改进它,我们可以使用 Final 类型提示,它指示变量旨在成为常量值,不应重新赋值:
from typing import Final
DATABASE: Final = "MySQL"
如果我们真的更改了“常量constant”,IDE肯定会提醒我们:
3. F-Strings:一种 Pythonic 字符串格式化方法
Python 支持几种不同的字符串格式化技术,例如使用 % 符号的 C 样式格式化、内置 format() 函数和 f-strings。
除非您仍在使用比 Python 3.6 更旧的版本,否则 f-strings 绝对是执行字符串格式的最 Python 方式。因为它们可以用最少的代码完成所有格式化任务,甚至可以在字符串中运行表达式。
from datetime import datetime
today = datetime.today()
print(f"Today is {today}")
# Today is 2023-12-28 13:43:13.944146
print(f"Today is {today:%B %d, %Y}")
# Today is December 28, 2023
print(f"Today is {today:%m-%d-%Y}")
# Today is 12-28-2023
如上面的代码所示,使用 f-strings 只需做两件事:
- 在字符串前添加字母“f”以指示它是 f-string。
- 使用带有变量名称的大括号和字符串 (
{variable_name:format}) 内的可选格式说明符,以特定格式插值变量的值。
“简单总比复杂好。 f-strings 很好地反映了 Python 禅宗中的这句话。
更重要的是,我们可以直接在 f-string 中执行一个表达式:
from datetime import datetime
print(f"Today is {datetime.today()}")
# Today is 2023-12-28 13:46:18.905805
4. 使用省略号Ellipsis作为未编写代码的占位符
在 Python 中,我们通常将 pass 关键字作为未编写代码的占位符。但是我们也可以使用省略号来实现此目的。
def write_an_article():
...
class Author:
...
Python 之父 Guido van Rossum 在 Python 中加入了这种语法糖,因为他觉得这种语法糖很可爱。
5. Python 中的装饰器Decorators:一种模块化功能和分离关注点的方法
Python 装饰器的理念是允许开发者在不修改现有对象原始逻辑的情况下为其添加新功能。
我们可以自己定义装饰器。此外,还有许多出色的内置装饰器可供使用。
例如,Python 类中的静态方法static methods并不与实例instance或类class绑定。它们被包含在类中只是因为它们在逻辑上属于这个类。
要定义静态方法,我们只需使用 @staticmethod 装饰器,如下所示:
class Student:
def __init__(self, first_name, last_name):
self.first_name = first_name
self.last_name = last_name
self.nickname = None
def set_nickname(self, name):
self.nickname = name
@staticmethod
def suitable_age(age):
return 6 <= age <= 70
print(Student.suitable_age(99)) # False
print(Student.suitable_age(27)) # True
print(Student('zhang', 'san').suitable_age(27)) # True
6.列表推导式List Comprehension:用一行代码创建一个列表
Python 以其简洁性而闻名,这主要归功于其精心设计的语法糖,如列表推导式List Comprehension。
通过列表推导式,我们可以在一行代码中加入 for loops 和 if conditions,从而生成一个 Python 列表:
Genius = ["Yang", "Tom", "Jerry", "Jack", "tom", "yang"]
L1 = [name for name in Genius if name.startswith('Y')]
L2 = [name for name in Genius if name.startswith('Y') or len(name) < 4]
L3 = [name for name in Genius if len(name) < 4 and name.islower()]
print(L1, L2, L3)
# ['Yang'] ['Yang', 'Tom', 'tom'] ['tom']
此外,Python 中还有set, dictionary, and generator comprehensions。它们的语法与 列表推导式 类似。
例如,下面的程序在 dict推导式 的帮助下基于某些条件生成一个dict:
Entrepreneurs = ["Yang", "Mark", "steve", "jack", "tom"]
D1 = {id: name for id, name in enumerate(Entrepreneurs) if name[0].isupper()}
print(D1)
# {0: 'Yang', 1: 'Mark'}
7.用于定义小型匿名函数的 Lambda 函数
lambda 函数(或称为匿名函数anonymous function)是一种语法糖,可以在 Python 中轻松定义一个小函数,使代码更简洁、更短小。
lambda 函数的一个常见应用是用来定义内置 sort() 函数的比较方法:
leaders = ["Warren Buffett", "Zhang San", "Tim Cook", "Elon Musk"]
leaders.sort(key=lambda x: len(x))
print(leaders)
# ['Tim Cook', 'Zhang San', 'Elon Musk', 'Warren Buffett']
在上面的示例中,定义了一个接收变量并返回其长度的 lambda 函数,作为列表排序的比较方法。当然,我们也可以用正常的方法在这里写一个完整的函数。但鉴于这个函数非常简单,将其写成 lambda 函数无疑更简洁明了。
8.三元条件操作符Ternary Conditional Operators:将 If 和 Else 放进一行代码中
许多编程语言都有三元条件运算符Ternary Conditional Operators。Python 的语法就是将 if 和 else 放在同一行:
short_one = a if len(a) < len(b) else b
如果我们在不使用三元条件语法的情况下实现与上述相同的逻辑,则需要几行代码:
short_one = ''
if len(a) < len(b):
short_one=a
else:
short_one=b
9.使用 “枚举Enumerate” 方法优雅地迭代列表Iterate Lists
在某些情况下,我们在迭代列表时需要同时使用列表中元素的索引和值。
经典的 C-style 方法如下:
for (int i = 0; i < len_of_list; i++) {
printf("%d %s\n", i, my_list[i]);
}
我们可以在 Python 中编写类似的逻辑,但 my_list[i] 似乎有点难看,尤其是当我们需要多次调用元素的值时。
真正的 Pythonic 方法是使用 enumerate() 函数直接获取索引和值:
leaders = ["Warren", "Yang", "Tim", "Elon"]
for i,v in enumerate(leaders):
print(i, v)
# 0 Warren
# 1 Yang
# 2 Tim
# 3 Elon
10.上下文管理器Context Manager自动关闭资源
我们知道,一旦文件被打开并处理,及时关闭文件以释放内存资源是非常重要的。如果忽略了这一点,就会导致内存泄漏memory leak,甚至使系统崩溃system crash。
f = open("test.txt", 'w')
f.write("Hi,Yang!")
# some logic here
f.close()
在 Python 中处理文件相当容易。正如上面的代码所示,我们只需记住调用 f.close() 方法来释放内存。
然而,当程序program变得越来越复杂complex和庞大large时,没有人能够始终记住一些东西。这就是 Python 提供上下文管理器语法糖的原因。
with open("test.txt", 'w') as f:
f.write("Hi, Yang!")
如上所述,with 语句是 Python 上下文管理器Context Manager的关键。只要我们通过它打开文件并在其下处理文件,文件就会在处理后自动关闭。
11.Python 列表的花式切片技巧Fancy Slicing Tricks
从列表中获取部分 items 是一种常见的需求。在 Python 中,切片操作符由三个部分组成:
a_list[start:end:step]
- “起始start”:起始索引(默认值为 0)。
- “结束end”:结束索引(默认值为列表长度)。
- “步长step”:定义迭代列表时的步长(默认值为 1)。
在此基础上,有一些技巧可以让我们的代码变得更加整洁。
用切片技巧逆转Reverse列表
由于切片运算符可以是负数(-1 是最后一项,以此类推),我们可以利用这一特性来反转列表:
a = [1, 2, 3, 4]
print(a[::-1])
# [4, 3, 2, 1]
获取列表的浅拷贝shallow copy
a = [1, 2, 3, 4, 5, 6]
b = a[:]
b[0] = 100
print(b) # [100, 2, 3, 4, 5, 6]
print(a) # [1, 2, 3, 4, 5, 6]
b=a[:] 与 b=a 不同,因为它分配的是 a 的浅层副本,而不是 a 本身。因此,如上所述, b 的更改根本不会影响 a 。
12.海象运算符Walrus Operator:表达式内的赋值
海象运算符Walrus Operator 也称为 赋值表达式操作符assignment expression operator,在 Python 3.8 中引入,用 := 符号表示。
它用于为表达式expression中的变量赋值,而不是单独赋值。
例如,请看下面的代码:
while (line := input()) != "stop":
print(line)
在这段代码中,我们使用 海象运算符walrus operator 将用户输入的值赋值给变量 line ,同时检查输入是否为 “stop”。只要用户输入不是 “stop”,while 循环就会继续运行。
顺便提一下,海象操作员 := 的可爱名字来源于海象的眼睛和獠牙:

13.连续比较Continuous Comparisons:一种更自然的方式来编写 If 条件
在 Java 或 C 等语言中,有时需要这样编写 if 条件:
if (a > 1 && a < 10){
//do somthing
}
但是,如果你不使用Python,就无法写出像下面这样优雅的代码:
if 1 < a < 10:
...
是的,Python 允许我们编写连续的比较continuous comparisons。它让我们的代码看起来就像数学中的代码一样自然。
14.Zip 函数:轻松组合多个可迭代对象Multiple Iterables
Python 有一个内置的built-in zip() 函数,它接受两个或多个可迭代对象iterables作为参数,并返回一个聚合了来自每个可迭代对象中的元素的迭代器iterator,即返回一个元组的迭代器iterator of tuples。
例如,在 zip() 函数的帮助下,下面的代码可以将 3 个列表聚合aggregation为一个列表,而无需任何循环:
id = [1, 2, 3, 4]
leaders = ['Elon Mask', 'Tim Cook', 'Bill Gates', 'Zhang San']
sex = ['male', 'male', 'male', 'male']
record = zip(id, leaders, sex)
print(list(record)) # record: <zip object at 0x1068d29c0>
# [(1, 'Elon Mask', 'male'), (2, 'Tim Cook', 'male'), (3, 'Bill Gates', 'male'), (4, 'Zhang San', 'male')]
15.直接交换两个变量Swapping Two Variables Directly
交换两个变量通常是初学者beginner在打印 "Hello world!"之后编写的第一个程序first program。
在许多编程语言programming languages中,实现这一功能的经典方法需要一个临时变量temporary variable来存储其中一个变量的值。
例如,您可以在 Java 中交换两个整数,如下所示:
int a = 5;
int b = 10;
int temp = a;
a = b;
b = temp;
System.out.println("a = " + a); // Output: a = 10
System.out.println("b = " + b); // Output: b = 5
在 Python 中,语法是如此直观intuitive和优雅elegant:
a = 10
b = 5
a, b = b, a
print(a, b)
# 5 10
16.解构赋值技巧Destructuring Assignments Tricks
Destructuring解构 (也称为拆包unpacking)
Assignment赋值
Python 中的 “解构赋值Destructuring assignments” 是一种将 迭代器iterator 或 字典dictionary 中的 元素elements 赋值给各个变量的方法。它避免了使用 索引indexes 或 键keys 访问单个元素的需要,从而使代码更短、更易读。
person = {'name': 'Yang', 'age': 30, 'location': 'Mars'}
name, age, loc = person.values()
print(name, age, loc)
# Yang 30 Mars
如上例所示,我们可以在一行代码中直接将字典的值赋值给 3 个单独的变量。
但是,如果左侧只有两个变量variables,如何接收赋值呢?
Python 为此提供了另一种语法糖syntax sugar:
person = {'name': 'Yang', 'age': 30, 'location': 'Mars'}
name, *others = person.values()
print(name, others)
# Yang [30, 'Mars']
如上图所示,我们只需在变量前添加一个星号asterisk,就可以让它接收 person.values() 中的所有剩余变量。
简单而优雅,不是吗?
17.用星号拆包可迭代对象Unpacking Iterables
除了解构赋值destructuring assignments,Python中的星号也是可迭代对象拆包iterable unpacking的关键。
A = [1, 2, 3]
B = (4, 5, 6)
C = {7, 8, 9}
L = [*A, *B, *C]
print(L)
# [1, 2, 3, 4, 5, 6, 8, 9, 7]
如上所述,将一个列表、一个集合和一个元组合并为一个列表的最简单方法是在新列表中通过星号将它们拆包。
18.Any() 和 All() 函数
在某些情况下,我们需要检查可迭代对象(如列表list、元组tuple或集合set)中的任何元素或所有元素是否为真。
当然,我们可以使用 for 循环来逐一检查它们。但 Python 提供了两个内置函数 any() 和 all() 来简化这两个操作的代码。
例如,下面的程序使用 all() 来判断列表中的所有元素是否都是奇数odd numbers:
my_list = [3, 5, 7, 8, 11]
# [num % 2 == 1 for num in my_list] # [True, True, True, False, True]
all_odd = all(num % 2 == 1 for num in my_list)
print(all_odd)
# False
下面的代码使用 any() 函数来检查是否存在名称以 "Y "开头的领导者:
leaders = ['Yang', 'Elon', 'Sam', 'Tim']
starts_with_Y = any(name.startswith('Y') for name in leaders)
print(starts_with_Y)
# True
19.数字中的下划线
要数清一个大数字中有多少个零是一件令人头疼的事。
幸运的是,Python 允许在数字中包含下划线underscores,以提高可读性readability。
例如,在 Python 中,我们可以不写 10000000000 而是写 10_000_000_000 ,这样更容易阅读。
9 个可大幅优化代码的 Python 内置装饰器Built-In Decorators
leverage the power of decorators
少花钱多办事:利用装饰器的力量
“Simple is better than complex.” - “简单胜于复杂”。
装饰器decorator是应用 “Python 禅宗 zen of Python” 哲学的最佳 Python 特性feature。
装饰器decorator可以帮助你编写更少、更简单的代码来实现复杂的逻辑,并在任何地方重复使用reuse。
更重要的是,Python 内置了许多超棒awesome 的装饰器,它们让我们的生活变得更加轻松,因为我们只需使用一行代码就能为现有函数或类添加复杂的功能。
废话少说Talk is cheap,让我们看看我精心挑选的 9 个装饰器,它们将向你展示 Python 是多么优雅。
1.@lru_cache:通过缓存加快程序运行速度
使用缓存技巧加速 Python 函数的最简单方法是使用 @lru_cache 装饰器。
这个装饰器decorator可以用来缓存函数的结果,这样后续使用相同的参数对此函数进行调用时就不会再次执行此函数。
对于计算成本较高或经常调用相同参数的函数,它尤其有用。
让我们来看一个直观的例子intuitive example:
import time
def fibonacci(n):
print(n)
if n < 2:
return n
return fibonacci(n - 1) + fibonacci(n - 2)
start_time = time.perf_counter()
print(fibonacci(30)) # 832040
end_time = time.perf_counter()
print(f"The execution time: {end_time - start_time:.8f} seconds")
# The execution time: 6.88886595 seconds
上述程序使用 Python 函数计算第 N 个斐波纳契数。这很耗时,因为在计算 fibonacci(30) 时,在递归recursion过程中会多次计算之前的许多斐波那契数。
现在,让我们使用 @lru_cache 装饰器来加快速度:
from functools import lru_cache
import time
@lru_cache(maxsize=None)
def fibonacci(n):
print(n)
if n < 2:
return n
return fibonacci(n - 1) + fibonacci(n - 2)
start_time = time.perf_counter()
print(fibonacci(30))
end_time = time.perf_counter()
print(f"The execution time: {end_time - start_time:.8f} seconds")
# The execution time: 0.00020197 seconds
如上面的代码所示,在使用 @lru_cache 装饰器后,我们可以在 0.00020197 秒内获得相同的结果,这比之前的 6.88886595 秒要快得多。
@lru_cache 装饰器有一个 maxsize 参数,用于指定缓存中要存储的结果的最大数量。当缓存已满,需要存储新结果时,最近使用最少的结果将从缓存中删除,为新结果腾出空间。这就是所谓的最近最少使用(LRU)策略least recently used (LRU) strategy。
默认情况下, maxsize 设置为 128 。如果设置为 None ,就像我们的例子一样,LRU 功能将被禁用,缓存可以无限制地增长。
2.@total_ordering:补全缺失的排序方法的类装饰器
functools 模块中的 @total_ordering 装饰器用于根据已定义的比较方法为 Python 类生成缺失的比较方法。
这里有一个例子:
from functools import total_ordering
@total_ordering
class Student:
def __init__(self, name, grade):
self.name = name
self.grade = grade
def __eq__(self, other):
return self.grade == other.grade
def __lt__(self, other):
return self.grade < other.grade
student1 = Student("Alice", 85)
student2 = Student("Bob", 75)
student3 = Student("Charlie", 85)
print(student1 < student2) # False
print(student1 > student2) # True
print(student1 == student3) # True
print(student1 <= student3) # True
print(student3 >= student2) # True
如上面的代码所示,在 Student 类中没有定义 __ge__ 、 __gt__ 和 __le__ 方法。但是,由于使用了 @total_ordering 装饰器,我们对不同实例的比较结果都是正确的。
这种装饰的好处显而易见:
- 它可以让你的代码更简洁,节省时间。因为你不需要编写所有的比较方法。
- 一些旧类可能没有定义足够的比较方法。比较安全的做法是为其添加
@total_ordering装饰器,以便进一步使用。
3.@contextmanager:创建自定义上下文管理器Customized Context Manager
Python 有一个上下文管理器Context Manager机制来帮助您正确管理资源。
大多数情况下,我们只需使用 with 语句:
with open("test.txt",'w') as f:
f.write("Yang is writing!")
如上面的代码所示,我们可以使用 with 语句打开文件,这样文件在写入后就会自动关闭。我们不需要明确调用 f.close() 函数来关闭文件。
有时,我们需要为一些特殊的需求定义一个自定义的上下文管理器。在这种情况下,@contextmanager 装饰器就是我们的朋友。
例如,下面的代码实现了一个简单的自定义上下文管理器simple customized context manager,可以在文件打开或关闭时打印相应的信息。
from contextlib import contextmanager
@contextmanager
def file_manager(filename, mode):
print("The file is opening...")
file = open(filename, mode)
yield file
print("The file is closing...")
file.close()
with file_manager("test.txt", "w") as f:
f.write("Yang is writing!")
# The file is opening...
# The file is closing...
4.@property:为 Python 类设置访问器Getters和修改器Setters
访问器Getters和修改器Setters是面向对象编程(OOP,object-oriented programming)中的重要概念。
对于类中的每个实例instance变量,getter 方法返回其值,而 setter 方法则设置或更新其值。因此,getter 和 setter 也分别被称为访问器和修改器。
它们用于保护您的数据不被直接或意外访问或修改。They are used to protect your data from being accessed or modified directly and unexpectedly.
不同的 OOP 语言有不同的机制来定义 getter 和 setter。在 Python 中,我们可以简单地使用 @property 装饰器。
class Student:
def __init__(self):
self._score = 0
@property
def score(self):
return self._score
@score.setter
def score(self, s):
if 0 <= s <= 100:
self._score = s
else:
raise ValueError('The score must be between 0 ~ 100!')
Yang = Student()
Yang.score=99
print(Yang.score)
# 99
Yang.score = 999
# ValueError: The score must be between 0 ~ 100!
如上例所示, score 变量不能设置为 999,这是一个毫无意义的数字。因为我们在 setter 函数中使用 @property 装饰器限制了它的可接受范围。
毫无疑问Without doubt,添加这个修改器setter可以成功地避免意想不到的错误或结果。
5.@cached_property:将方法Method的结果缓存为属性Attribute
Python 3.8 为 functool 模块引入了一个新的强大装饰器 - @cached_property 。它可以将一个类的方法method of a class转换为一个属性property,其值只需计算一次,然后在实例的生命周期中作为一个普通属性缓存。
这里有一个例子:
from functools import cached_property
class Circle:
def __init__(self, radius):
self.radius = radius
@cached_property
def area(self):
return 3.14 * self.radius ** 2
circle = Circle(10)
print(circle.area)
# prints 314.0
print(circle.area)
# returns the cached result (314.0) directly
在上述代码中,我们通过 @cached_property 装饰了 area 方法。因此,同一不变实例的 circle.area 不会出现重复计算。
6.@classmethod:在 Python 类中定义类方法
在 Python 的类中,可能有 3 种方法:
- 实例方法Instance methods: 与实例绑定的方法 bound to an instance。它们可以访问和修改实例instance数据。实例方法在类的实例上调用,可以通过
self参数访问实例数据。 - 类方法Class methods: 与类绑定的方法 bound to the class。它们不能修改实例数据。类方法的调用对象是类本身class itself,它接收的第一个参数是类,通常命名为
cls。 - 静态方法Static methods: 不与实例或类绑定的方法。
实例方法可以被定义为普通的Python函数,只要它的第一个参数是 self。但是,要定义类方法,我们需要使用 @classmethod 装饰器decorator。
为了演示,下面的示例定义了一个类方法Class Method,可用于通过直径diameter获取 Circle 实例:
class Circle:
def __init__(self, radius):
self.radius = radius
@classmethod
def from_diameter(cls, diameter):
return cls(diameter / 2)
@property
def diameter(self):
return self.radius * 2
@diameter.setter
def diameter(self, diameter):
self.radius = diameter / 2
c = Circle.from_diameter(8)
print(c.radius) # 4.0
print(c.diameter) # 8.0
7.@staticmethod:在 Python 类中定义静态方法
如前所述,静态方法Static methods不与实例instance或类class绑定。之所以静态方法被放在一个类中,只是因为它们在逻辑上属于这个类。
静态方法通常用于执行一组相关任务(如数学计算)的实用程序类utility classes中。通过将相关功能组织到类中的静态方法中,我们的代码会变得更有条理,也更容易理解。
要定义静态方法,我们只需使用 @staticmethod 装饰器。让我们来看一个例子:
class Student:
def __init__(self, first_name, last_name):
self.first_name = first_name
self.last_name = last_name
self.nickname = None
def set_nickname(self, name):
self.nickname = name
@staticmethod
def suitable_age(age):
return 6 <= age <= 70
print(Student.suitable_age(99)) # False
print(Student.suitable_age(27)) # True
print(Student('zhang', 'san').suitable_age(27)) # True
8.@dataclass: 用更少的代码定义特殊类
@dataclass 装饰器(在 Python 3.7 中引入)可以为类自动生成几个特殊方法,如 __init__ , __repr__ , __eq__ , __lt__ 等。
因此,它可以节省我们编写这些基本方法的大量时间。如果一个类主要用于存储数据,那么 @dataclass 装饰器就是我们最好的朋友。
为了演示,下面的示例只定义了名为 Point 的类的两个数据字段。多亏了 @dataclass 装饰器, Point 类才可以被使用:
from dataclasses import dataclass
@dataclass
class Point:
x: float
y: float
point = Point(1.0, 2.0)
print(point)
# Point(x=1.0, y=2.0)
9.@atexit.register:注册在正常程序终止时要执行的函数
来自 atexit 模块的 @register 装饰器可以让我们在 Python 解释器interpreter退出时执行一个函数。
这个装饰器对于执行最终任务非常有用,例如释放资源或只是说再见!
下面就是一个例子:
import atexit
@atexit.register
def goodbye():
print("Bye bye!")
print("Hello Yang!")
输出为
Hello Yang!
Bye bye!
如示例所示,由于使用了 @register 装饰器,即使我们没有明确调用 goodbye 函数,终端terminal也会打印出 “Bye bye!”。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!