Nightingale 夜莺监控系统 - 部署篇(1)

Author:rab
官方文档:https://flashcat.cloud/docs
目录
一、概述
以下为夜莺官方解释。
夜莺监控是一款开源云原生观测分析工具,采用 All-in-One 的设计理念,集数据采集、可视化、监控告警、数据分析于一体,与云原生生态紧密集成,提供开箱即用的企业级监控分析和告警能力。夜莺于 2020 年 3 月 20 日,在 github 上发布 v1 版本,已累计迭代 100 多个版本。
夜莺最初由滴滴开发和开源,并于 2022 年 5 月 11 日,捐赠予中国计算机学会开源发展委员会(CCF ODC),为 CCF ODC 成立后接受捐赠的第一个开源项目。夜莺的核心研发团队,也是 Open-Falcon 项目原核心研发人员。
二、架构
2.1 中心机房架构
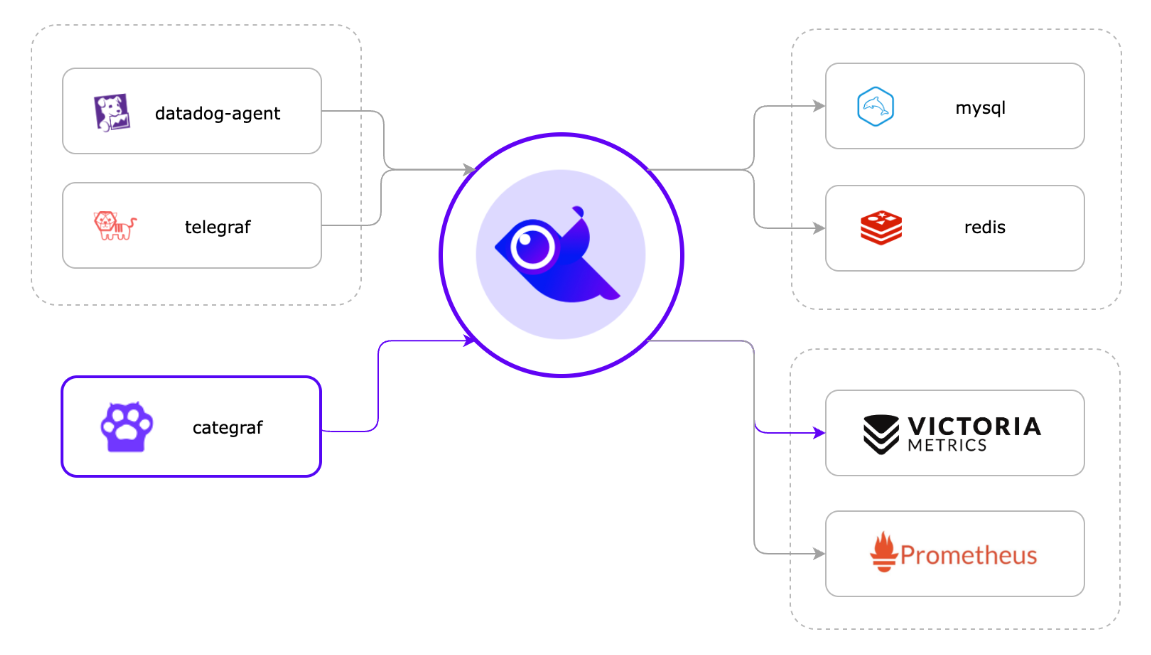
首先上图中间的飞鸟代表夜莺的核心进程 n9e (下文以 n9e 代替),它的集群方式非常简单只需部署多节点即可实现。
对于 n9e 来说,它本身依赖的存储有两个
- Mysql : 存放配置类别信息,如用户,监控大盘,告警规则等
- Redis : 存放访问令牌(JWT Token),心跳信息,如机器列表中 CPU、内存、时间偏移、核数、操作系统、CPU 架构等。
从 v6 版本开始,夜莺尝试转型为统一可观测性平台,n9e 不再仅支持接入时序数据源(Prometheus、Victoriametrics、M3DB、Thanos),也可以接入日志类数据源(Elasticsearch,Loki【预】),链路追踪数据源(Jaeger)。
这种中心架构还有一种就是:将 Prometheus、Thanos、VictoriaMetrics、M3DB、Mimir 等某个时序库作为夜莺的数据源,即只使用夜莺的告警管理功能。
但是本次我们并不使用时序数据库“作为数据源”的这种方式,而是采用夜莺接收数据并存储到时序数据库的方式!
当然了,作为后端时序数据存储的 prometheus 也是可以在该架构中用作数据源,这样的话,n9e 不仅能展示数据,也能读取 prometheus 数据进行告警。
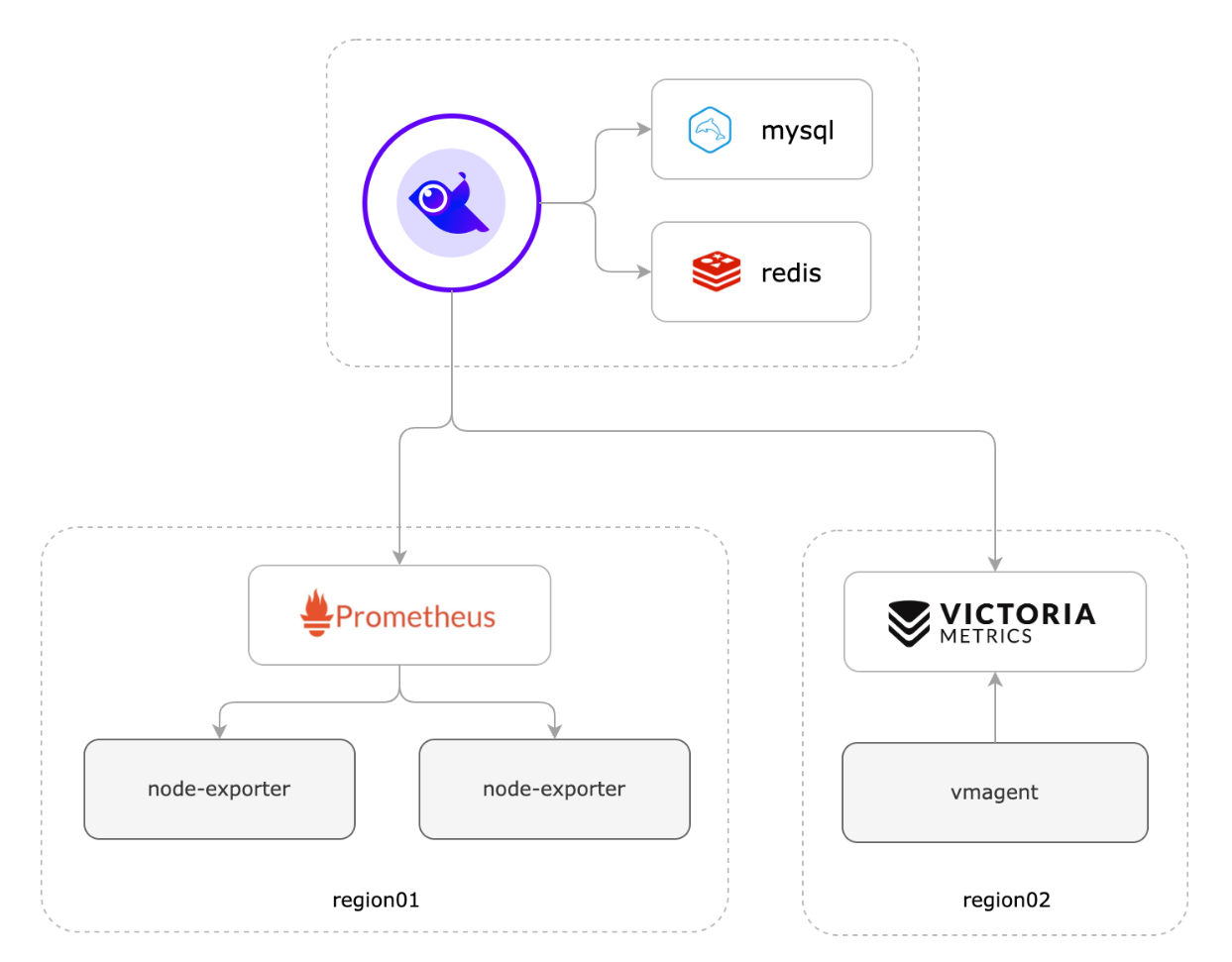
2.2 边缘下沉式混杂架构
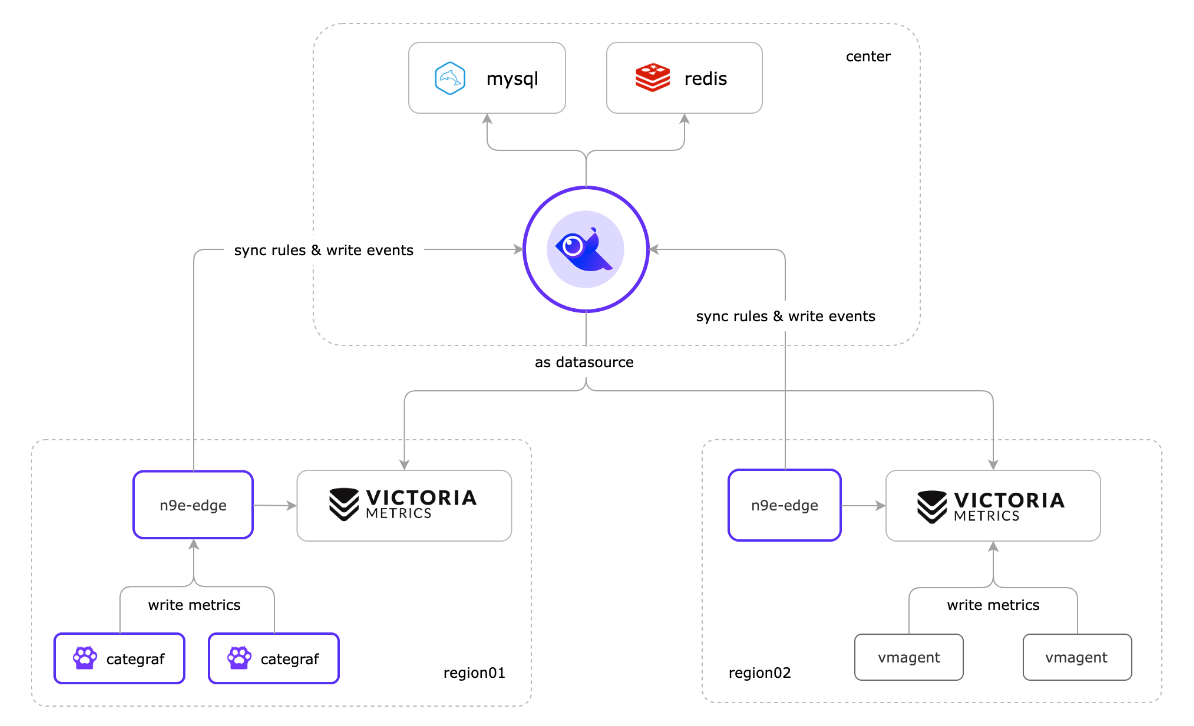
从 v6.0.0.ga.9 开始,合并了 n9e-alert、n9e-pushgw 模块为 n9e-edge,应对边缘机房的场景。n9e-edge 不依赖 mysql、redis,只依赖中心端的 n9e,所以 edge.toml 配置文件里,需要配置中心端 n9e 的地址。
三、环境
1、主机
| OS | Version | Comment |
|---|---|---|
| Rocky Linux | 8.5/4.18.0 | - |
2、服务
| Service | Version | Comment |
|---|---|---|
| n9e | 6.7.2 | 夜莺 - 服务端(数据展示) |
| Categraf | 0.3.45 | 夜莺 - 客户端(数据采集) |
| MySQL | 5.7.36 | DB 存储 |
| Redis | 6.2.6 | DB 缓存 |
| Prometheus | 2.37.0 | 时序数据库 |
时序数据存储选型:官方建议 VictoriaMetrics,但得根据你的实际业务场景来决定,如果你已经有 Prometheus 服务了,那也可以继续使用 Prometheus 直接作为数据源,如果没有,则可选择 VictoriaMetrics 作为时序库。
3、服务部署方式
DB 我采用 Docker 部署(当然你也可以采用其他方式部署),其他采用二进制部署!
四、部署
4.1 中心机房架构部署
4.1.1 MySQL
MySQL 用于存储用户、监控大盘、告警规则等。
# 部署过程略,本次通过shell脚本化部署

4.1.2 Redis
存放访问令牌(JWT Token),心跳信息,如机器列表中CPU、内存、时间偏移、核数、操作系统、CPU架构等。
# 部署过程略,本次通过shell脚本化部署
4.1.3 Prometheus
作为时序库接收 remote write 协议的数据,即夜莺收到时序数据之后,会将时序数据写入 Prometheus 中。夜莺也可以同时将此时的时序库用作 n9e 的数据源。
1、二进制包下载

2、解药安装包
tar xf prometheus-2.45.2.linux-amd64.tar.gz -C /data/
3、配置 Systemd 管理
注意:启动 Prometheus 时需要在启动参数里添加
--enable-feature=remote-write-receiver,否则夜莺转发数据的时候会报 404,因为没有这个参数,Prometheus 就不会开启/api/v1/write接口的处理监听。
cat <<EOF >/etc/systemd/system/prometheus.service
[Unit]
Description="prometheus"
Documentation=https://prometheus.io/
After=network.target
[Service]
Type=simple
ExecStart=/data/prometheus-2.45.2.linux-amd64/prometheus --config.file=/data/prometheus-2.45.2.linux-amd64/prometheus.yml --storage.tsdb.path=/data/prometheus-2.45.2.linux-amd64/data --web.enable-lifecycle --enable-feature=remote-write-receiver --query.lookback-delta=2m
Restart=on-failure
SuccessExitStatus=0
LimitNOFILE=65536
StandardOutput=syslog
StandardError=syslog
SyslogIdentifier=prometheus
[Install]
WantedBy=multi-user.target
EOF
4、启动
systemctl daemon-reload
systemctl enable prometheus
systemctl restart prometheus
systemctl status prometheus
5、访问验证
http://yourIP:9090/
4.1.4 n9e
生产环境中建议使用二进制方式部署,便于后续的升级维护等管理。
1、二进制包下载
2、创建 work 目录
mkdir /data/n9e
3、上传安装包至服务器并解压
tar xzf n9e-v6.7.2-linux-amd64.tar.gz -C /data/n9e/
4、导入 sql 文件
mysql -h 10.206.0.17 -u root -p'Zhurs@123' < /data/n9e/n9e.sql

创建监控用户并授权:
CREATE USER 'nightingale'@'%' IDENTIFIED BY '67by5DV7vK3fiygm';
GRANT ALL PRIVILEGES ON n9e_v6.* TO 'nightingale'@'%';
5、修改配置文件
主要修改 DB 部分。
cp etc/config.toml etc/config.toml.bak
vim etc/config.toml

时序数据库配置:
如果你想把数据转发给后端多个时序库,就可以配置多个
[[Pushgw.Writers]],比如:[Pushgw] LabelRewrite = true [[Pushgw.Writers]] Url = "http://127.0.0.1:8428/api/v1/write" [[Pushgw.Writers]] Url = "http://127.0.0.1:9090/api/v1/write"

配置完成后,此时夜莺接收到 categraf、telegraf、grafana-agent 等各类 agent 上报上来的监控数据,都会转发给后端的 Prometheus。
6、配置 systemd 管理并启动
cat <<EOF >/etc/systemd/system/n9e.service
[Unit]
Description="n9e.service"
After=network.target
[Service]
Type=simple
ExecStart=/data/n9e/n9e
WorkingDirectory=/data/n9e
Restart=on-failure
SuccessExitStatus=0
LimitNOFILE=65536
StandardOutput=syslog
StandardError=syslog
SyslogIdentifier=n9e.service
[Install]
WantedBy=multi-user.target
EOF
systemctl daemon-reload
systemctl start n9e.service
systemctl enable n9e.service
systemctl status n9e.service
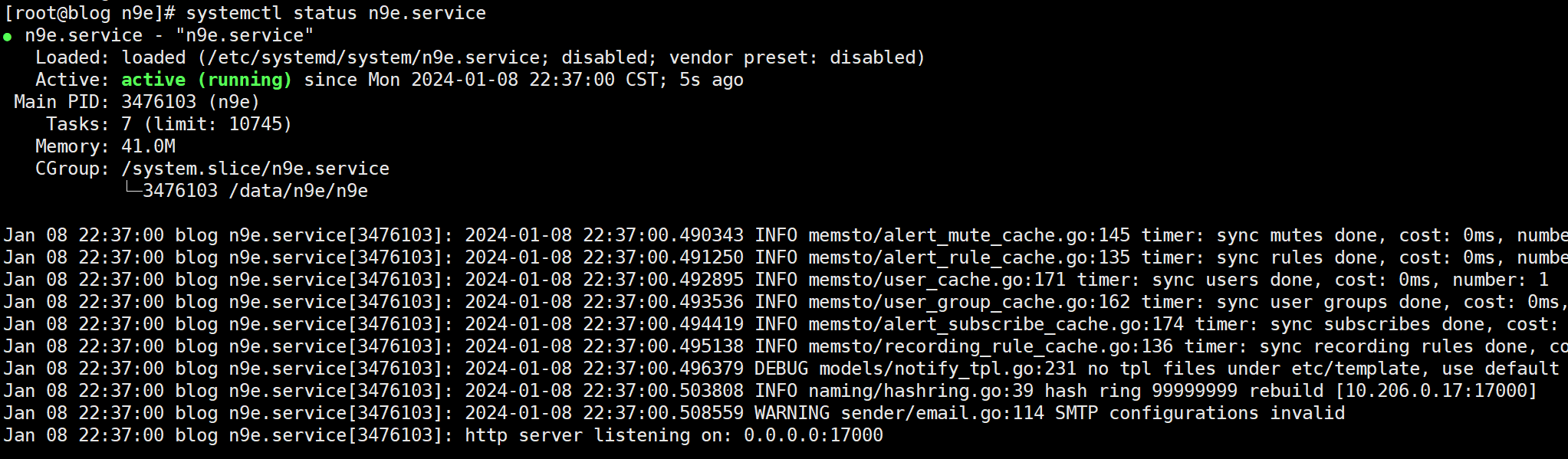
监听 17000 端口:

4.1.5 Categraf
1、概述
需要部署 categraf 上报监控数据,因为夜莺本身其实只是一个服务端组件,不负责数据采集。但如果我们 Prometheus、VictoriaMetrics、Thanos 等时序数据库已经存储有相关的监控指标数据,那也可以将他们作为夜莺的数据源使用,此时夜莺就相当于 Grafana 一样。
比如原本有一套 Prometheus + 各类 Exporter 的体系,复用即可,不需要非得用 categraf 替换采集逻辑,把这套 Prometheus 作为数据源接入夜莺,用夜莺告警就可以了。
我觉得官方文档说得已经非常明白了。
2、客户端下载
下载地址:https://github.com/flashcatcloud/categraf
3、上传服务器并解压
tar xzf categraf-v0.3.45-linux-amd64.tar.gz -C /data/
4、修改配置文件
官方参考文档:https://flashcat.cloud/docs/content/flashcat-monitor/nightingale-v6/agent/categraf/
vim /data/categraf-v0.3.45-linux-amd64/conf/config.toml
-
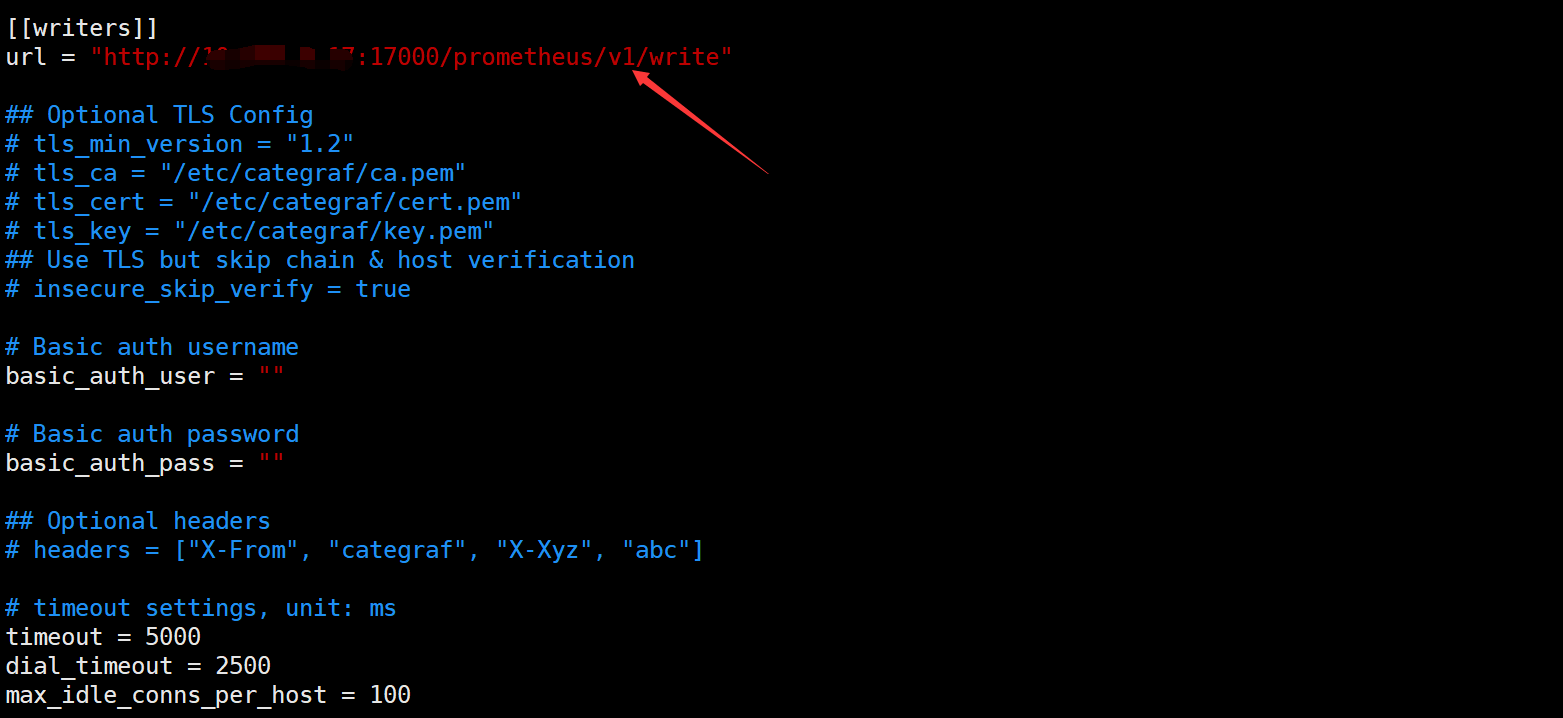
将数据推送到 n9e 服务端
数据到达 n9e 时,然后 n9e 服务端再将数据写入后端时序数据库(本次我们配置的是 Prometheus)
这里要清楚,官方文档说了,写入 prometheus 前,会将监控数据的一些元数据存储到 DB 中(MySQL/Redis)
-
Categraf 建立与 n9e 的心跳检测

5、配置 systemd 管理
cat <<EOF >/etc/systemd/system/categraf.service
[Unit]
Description="categraf.service"
After=network.target
[Service]
Type=simple
ExecStart=/data/categraf-v0.3.45-linux-amd64/categraf
WorkingDirectory=/data/categraf-v0.3.45-linux-amd64
Restart=on-failure
SuccessExitStatus=0
LimitNOFILE=65536
StandardOutput=syslog
StandardError=syslog
SyslogIdentifier=categraf.service
[Install]
WantedBy=multi-user.target
EOF
systemctl daemon-reload
systemctl start categraf.service
systemctl enable categraf.service
systemctl status categraf.service
因此这里我们要清楚的是,采集器(客户端)不止 Categraf,还有 telegraf、grafana-agent 等。
6、那该 agent 是如何采集数据的呢?
我们下载后的安装包中就包含了基本的采集项:即以 input. 开头的目录就是各种采集插件的配置目录,运行 Categraf 客户端时,它就会通过这些目录的配置去采集数据。如果某个采集器 xx 不想启用,把 input.xx 改个其他前缀(或者删除这个目录),比如 bak.input.xx,categraf 就会忽略这个采集器。
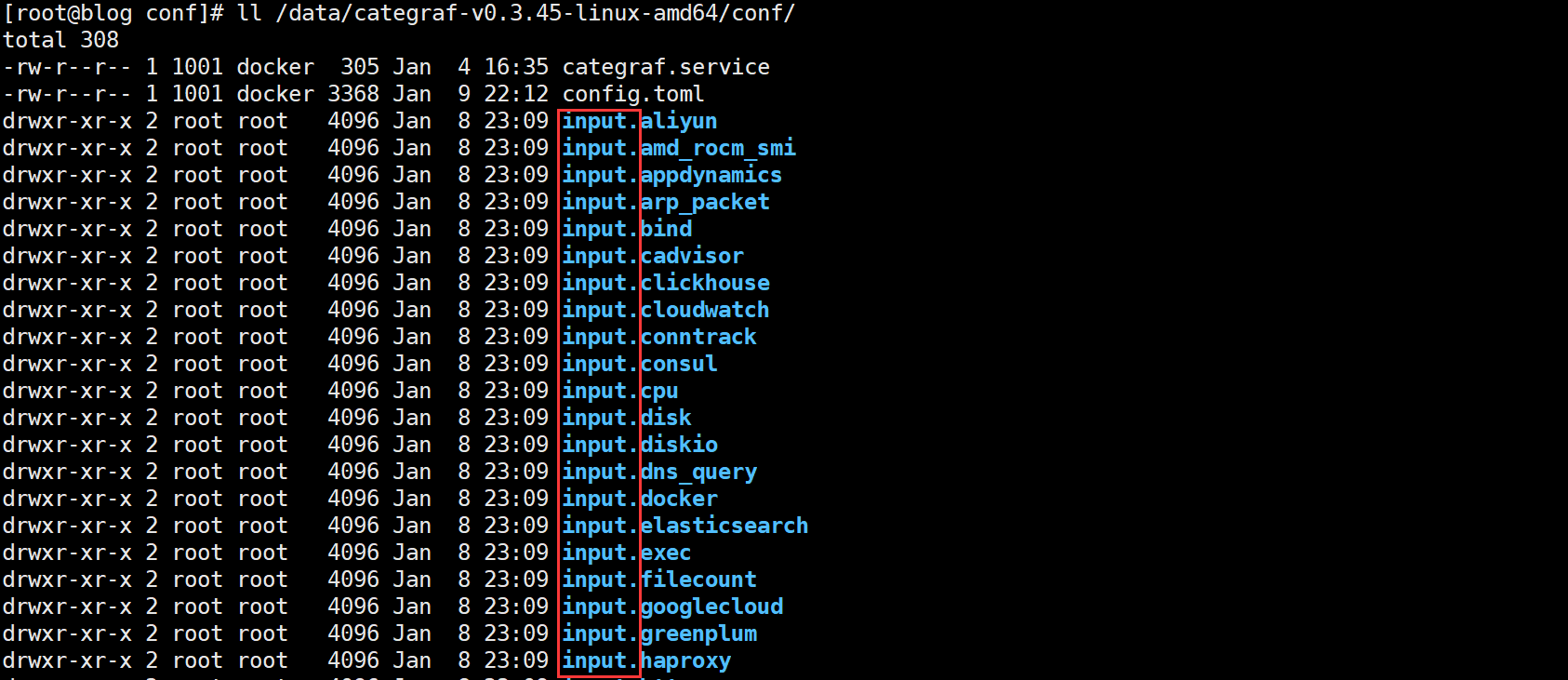
categraf启动时 可以通过-configs参数指定配置目录,如果不指定,会默认读取工作目录下的conf。 conf 目录结构如下:
config.toml# 主配置logs.toml# logs-agent 配置prometheus.toml# prometheus agent 配置traces.yaml# trace-agent 配置conf/input.*/*.toml插件配置文件
主配置文件看官方文档解释就行,说得很清楚了。
一般地,Categraf 采集 agent 中的采集插件已经实现了基本的数据采集(CPU、内存、磁盘、磁盘 IO、网络),因此我们直接运行采集客户端 Categraf 时就会帮我们采集这些基础数据。
4.1.6 验证
默认账户/密码:root/root.2020
默认的密码可登陆后自行更改即可。
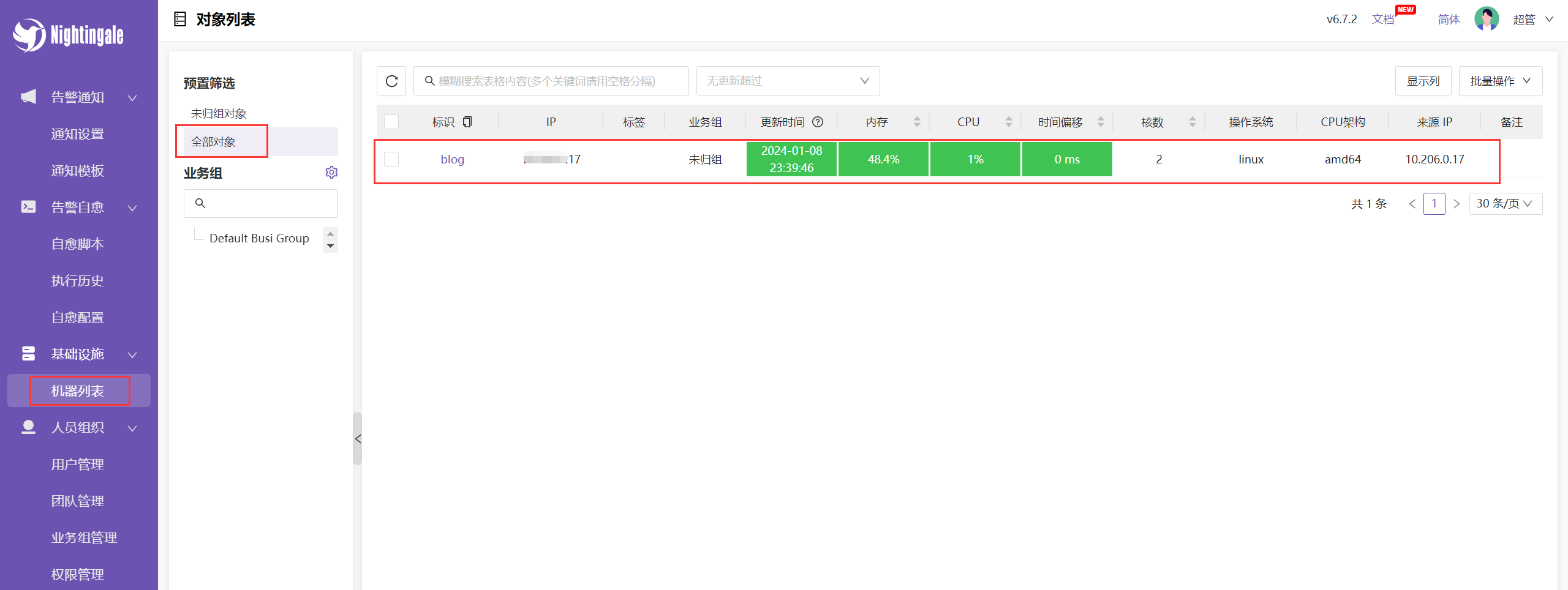
查看是否监控到主机:
但此时的主机是没有归组的,我们可创建用户及团队,然后将对应主机放入该团队中,那团队中的用户就可以看见监控主机了。
创建用户:
创建团队:
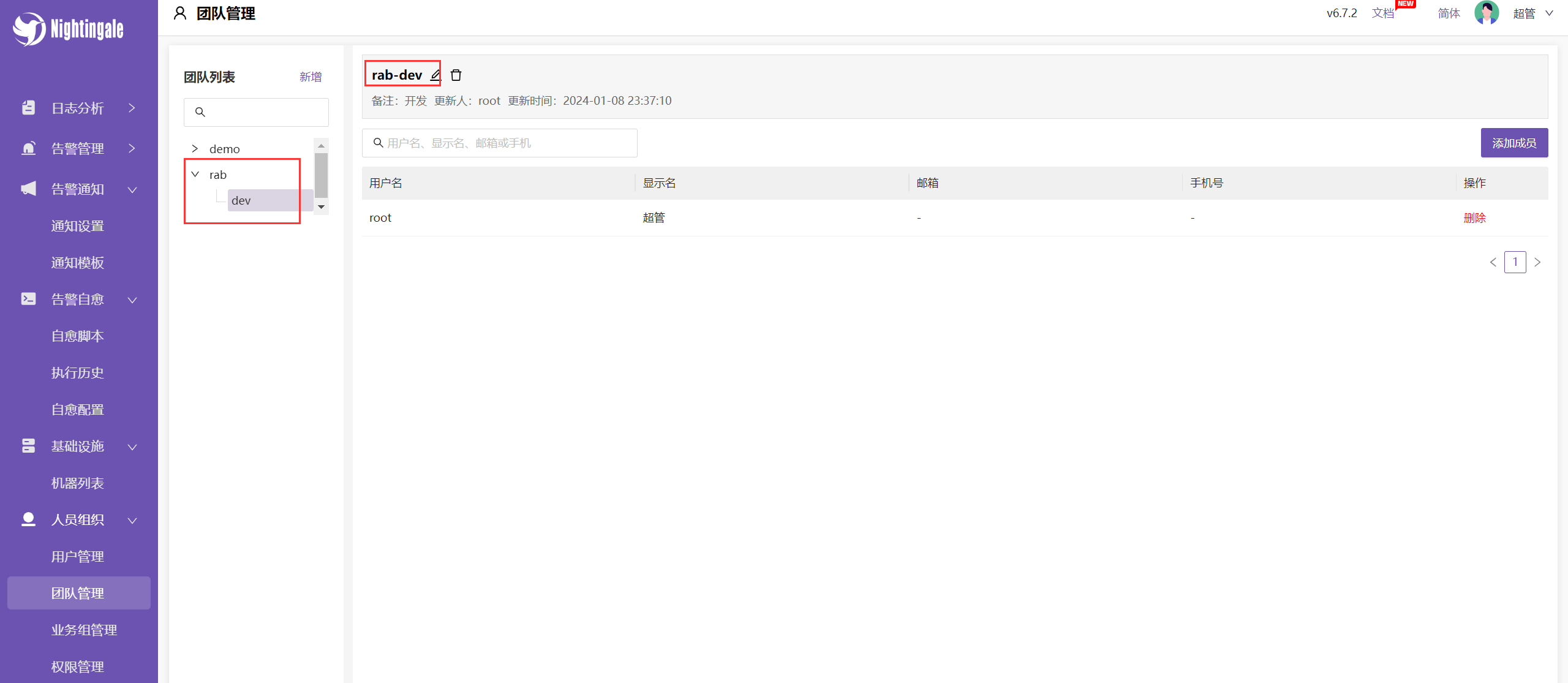
注意书写:rab-dev => 这表示一个层级关系,如下图
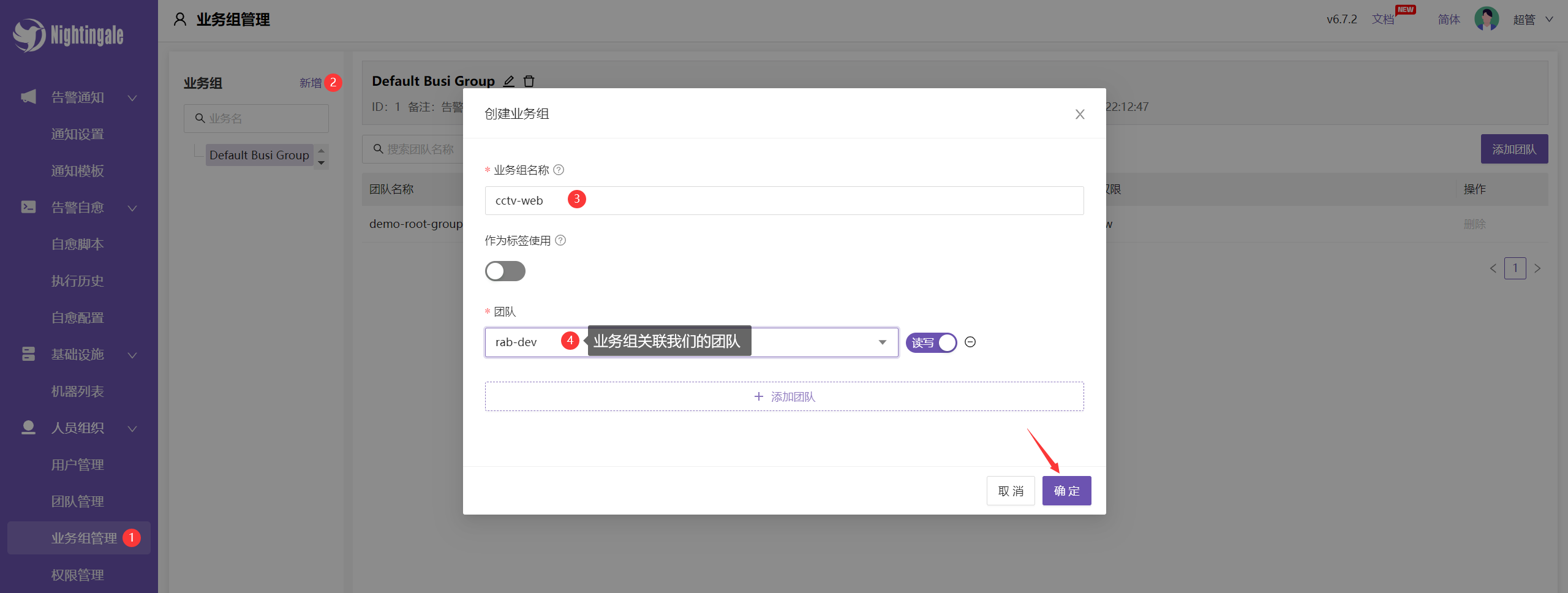
创建业务组:
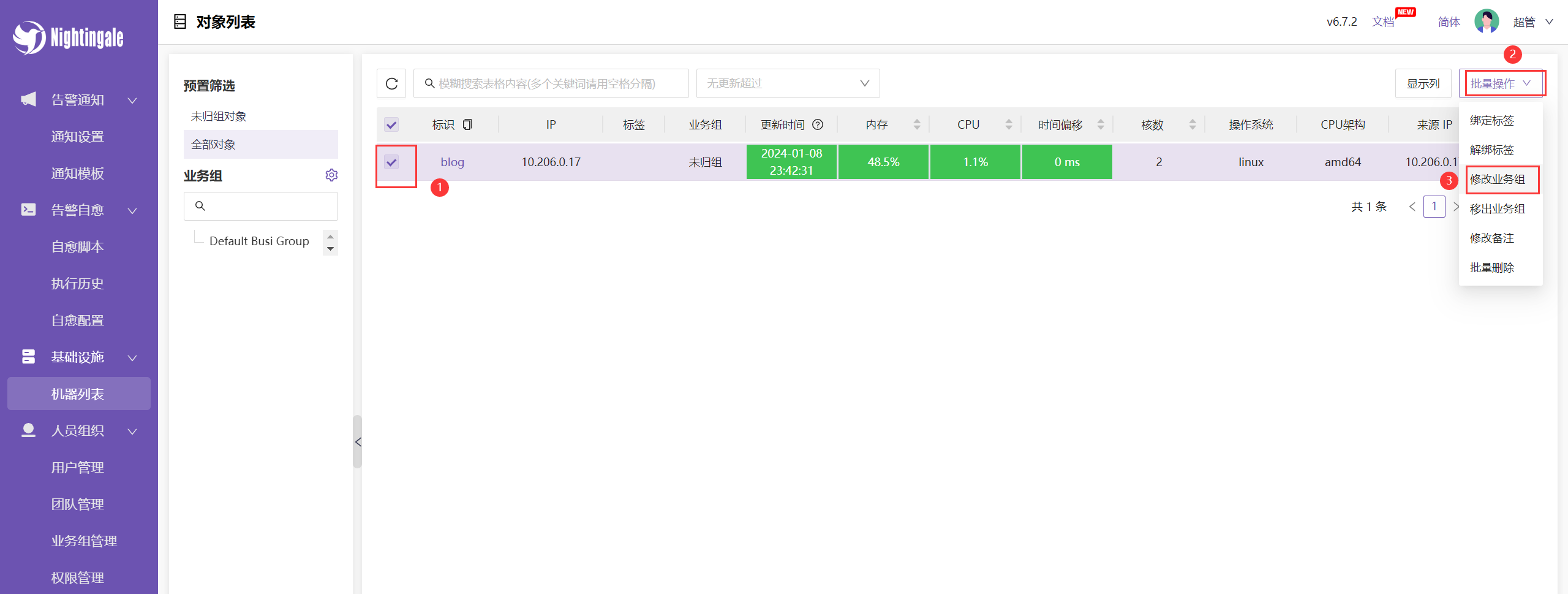
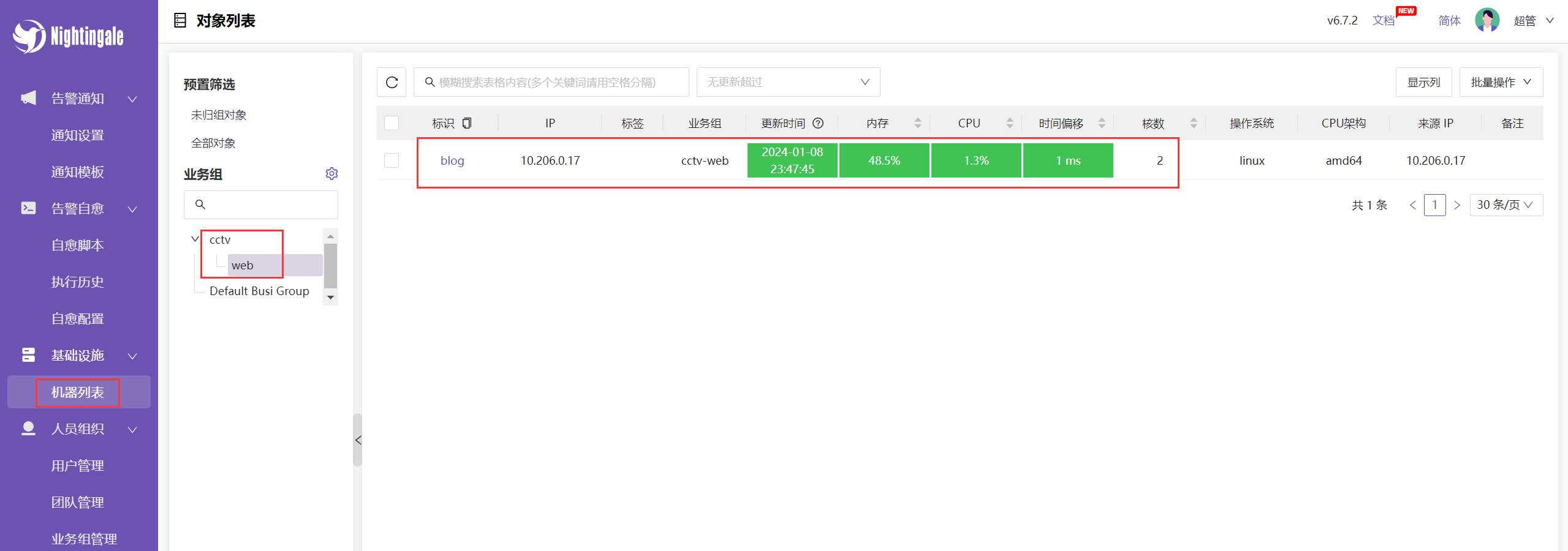
将监控的机器归到指定的业务组中:
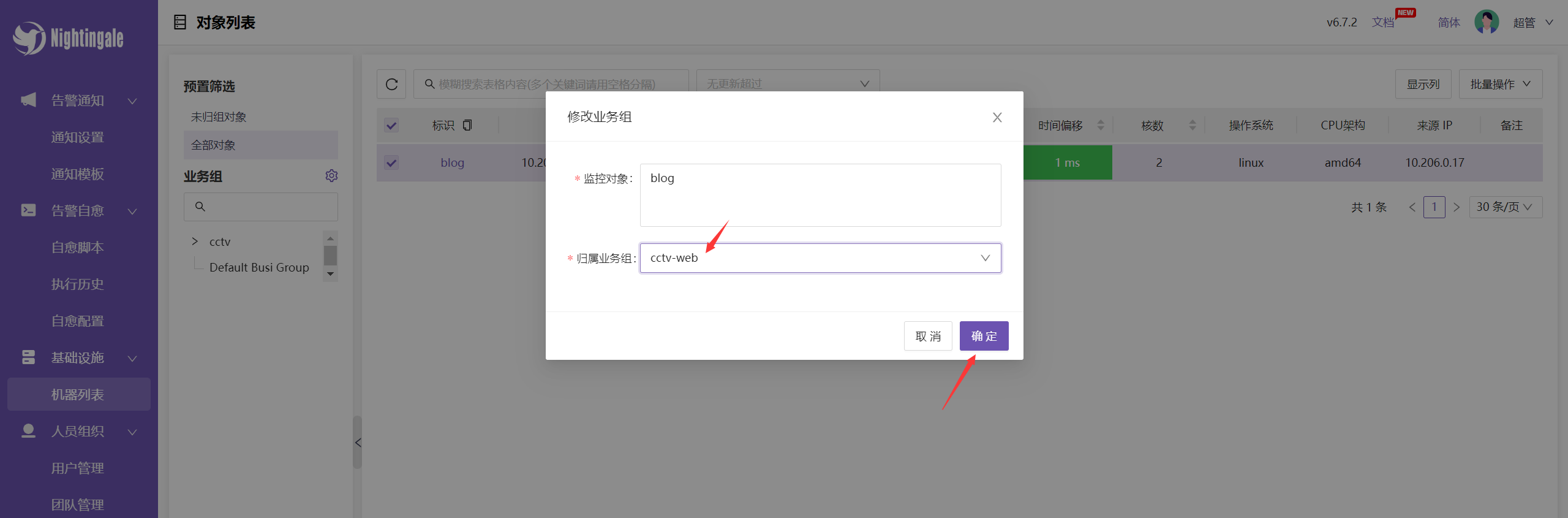
此时该服务器就属于 cctv/web 这个业务组了,同时这个业务组中的团队就可以查看这些服务器:
4.1.7 配置数据源
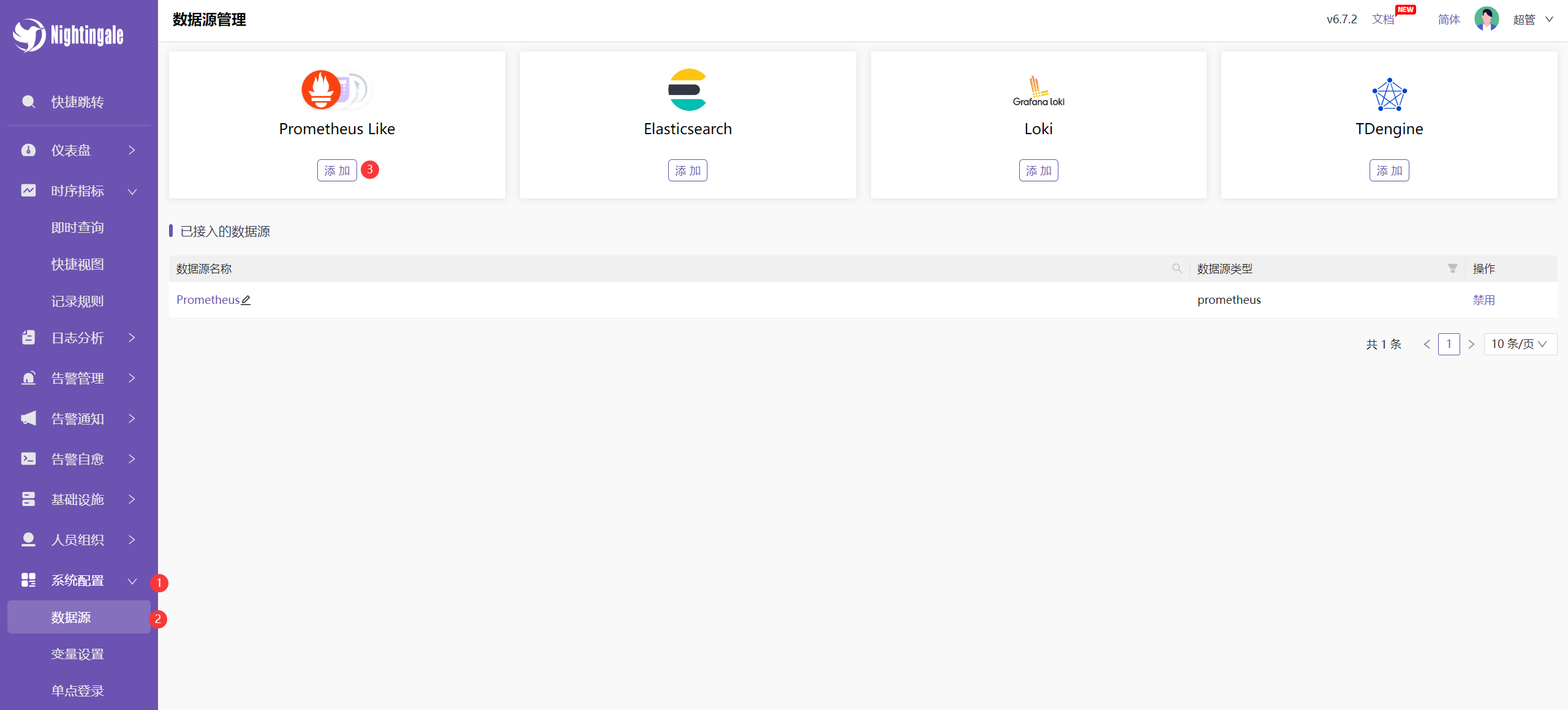
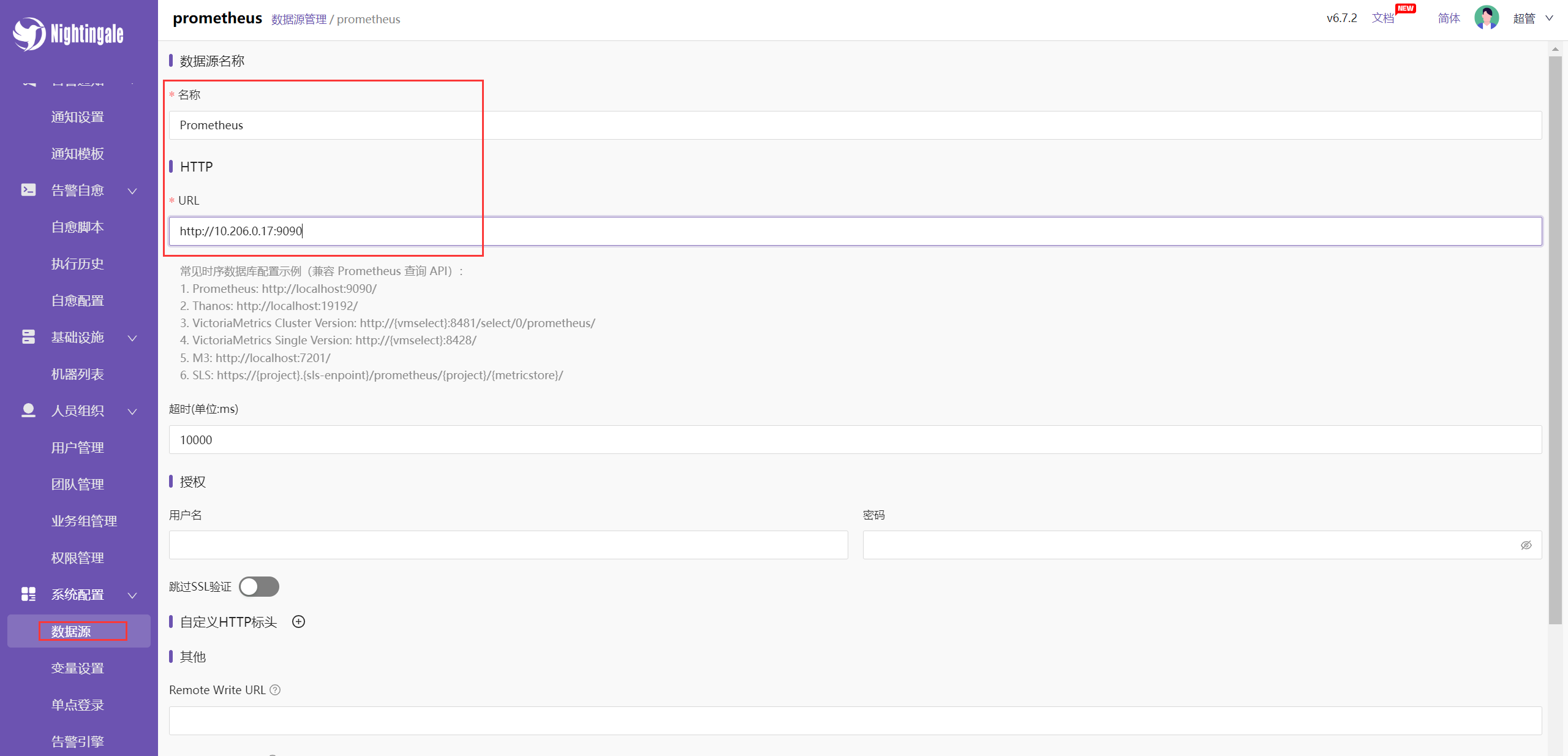
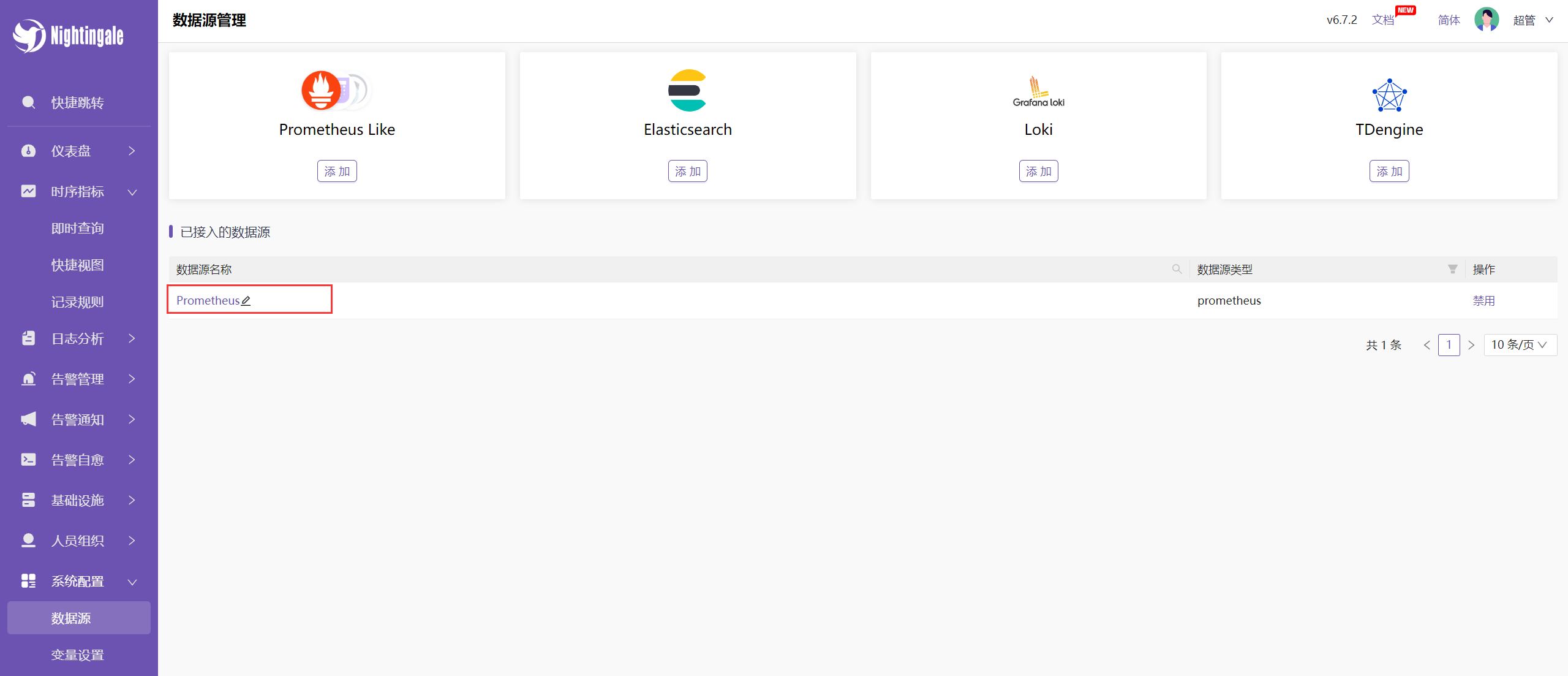
如何将我们的时序库作为 n9e 的数据源(如下操作即可):
4.2 边缘下沉式混杂部署
4.2.1 架构分析
官方文档说的很清楚【看文档】,无需再造轮子。
边缘监控无需依赖 MySQL、Redis 存储。
所谓的下沉,其思想就是将中心 N9e 的时序数据库下沉部署到边缘机房,避免大量时序数据传输到中心机房带来的网络带宽压力,同时也避免了因网络问题,边缘机房无法上报数据的问题。但是其本质还是需要和中心机房建立网络通信,尽管有时也会因为网络原因,边缘监控与中心监控也会存在延迟,但是边缘机房的监控数据是不会丢的。
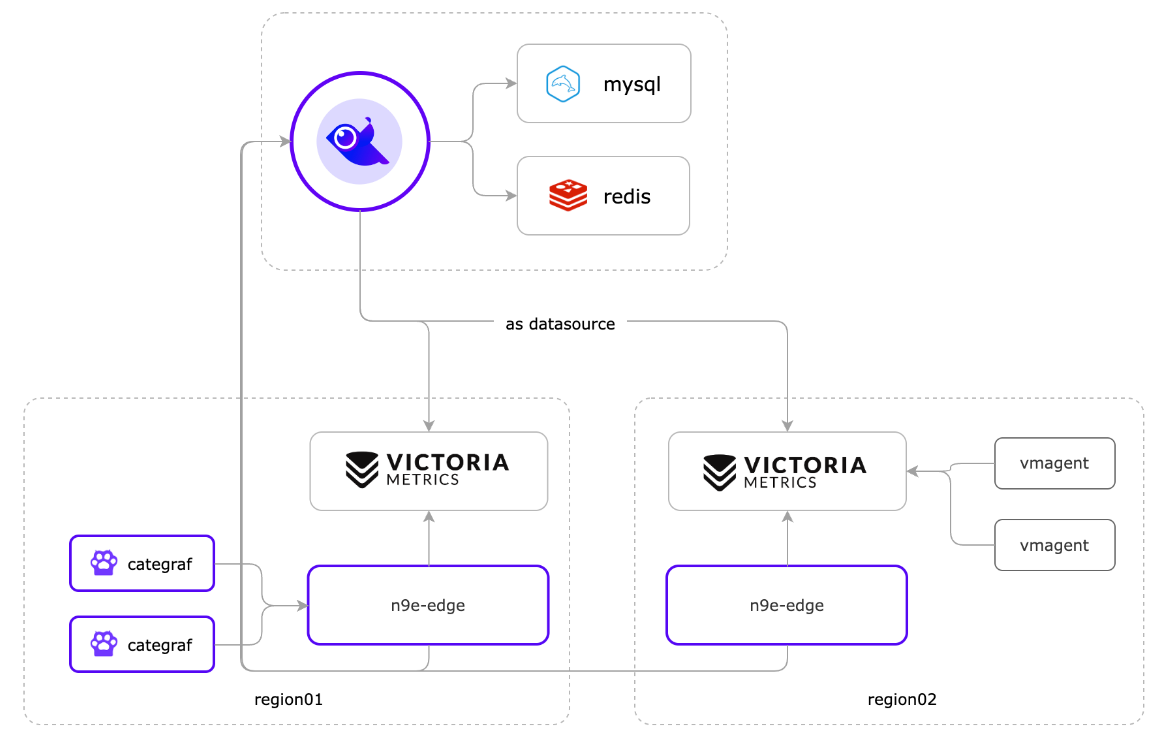
图中 region02 的机房中采集器使用的是 vmagent,并把采集的数据直接写入时序数据库,通过 n9e-edge 对监控数据做告警判断。这种架构比较简洁,但是会有一点点小问题,由于采集数据没有流经 n9e-edge,就没法从数据流中解析出机器信息,也就没法把机器信息写入数据库 target 表,也就导致页面上机器列表页面看不到相关的机器。这不影响告警,看图这些核心功能,只是用不了机器分组,自定义标签,告警自愈之类的功能。
更推荐使用 Categraf + n9e-edge 的方式来采集数据,其架构如图 region01 所示。当 Categraf 采集的数据上报给 n9e-edge 后,n9e-edge 就可以从监控数据中解析出机器信息,然后通过中心端的 n9e 写入数据库 target 表,这样就可以在页面上看到机器列表了。就可以使用机器分组,自定义标签,告警自愈之类的功能。
4.2.2 实验环境
在 4.1 你会看到服务器的主机名是 blog,为了实验方便查看,我这里先将主机命令为 n9e,另一个测试主机为 pro-blog。
hostnamectl set-hostname n9e
| OS | Host | Comment |
|---|---|---|
| RockyLinux 8.5 | n9e(10.206.0.17) | VPC/南京 |
| RockyLinux 8.5 | pro-blog(172.xx.xx.15) | VPC/香港 |
这里相当于模拟了两个机房,n9e 作为监控中心机房,pro-blog 作为边缘监控机房。
4.2.3 Prometheus
上面说了,边缘主机的监控数据会采集到边缘主机的时序库(Prometheus、VIVTORIA 等时序库),因此这里需要部署时序数据库。
部署方式同 4.1.3 小结,这里不再演示。
4.2.4 n9e-edge
这个应用程序已经包含在 n9e 压缩包中,直接使用即可。
1、二进制包下载
2、创建 work 目录
mkdir -p /data/n9e-edge
3、解压二进制包
tar xzf n9e-v6.7.2-linux-amd64.tar.gz -C /data/n9e-edge/
4、配置 n9e-edge 连接中心 n9e
从 v6.0.0.ga.9 开始,合并了 n9e-alert、n9e-pushgw 模块为 n9e-edge,应对边缘机房的场景。n9e-edge 不依赖 mysql、redis,只依赖中心端的 n9e,所以 edge.toml 配置文件里,需要配置中心端 n9e 的地址。
vim /data/n9e-edge/etc/edge/edge.toml
...
[CenterApi]
Addrs = ["http://119.45.140.59:17000"]
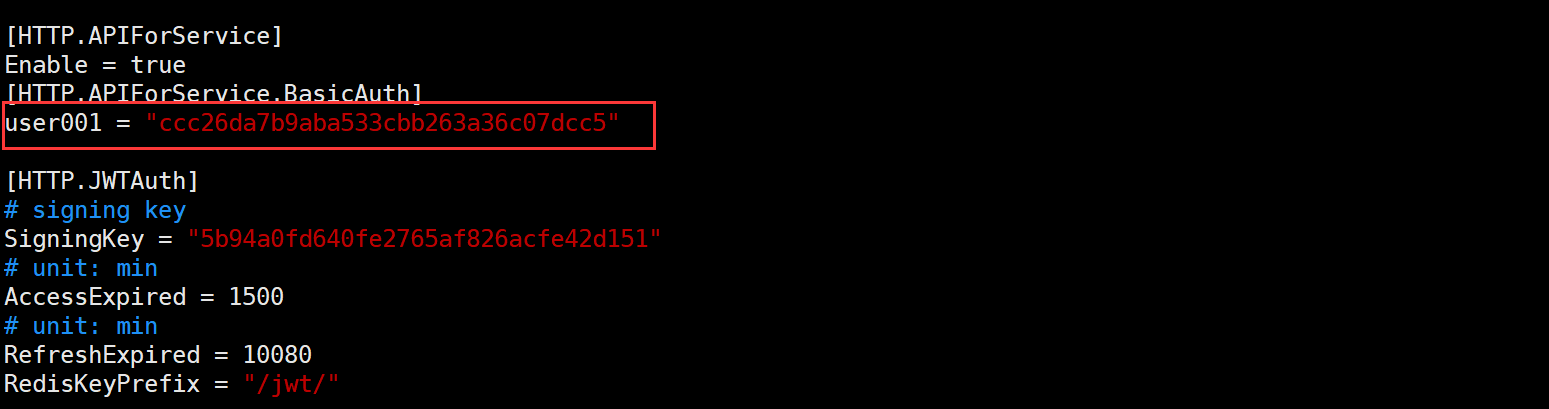
BasicAuthUser = "user001"
BasicAuthPass = "ccc26da7b9aba533cbb263a36c07dcc5"
# unit: ms
Timeout = 9000
...
认证信息(BasicAuthUser、BasicAuthPass)对应中心端 n9e 的 HTTP.APIForService.BasicAuth 配置段,如下:
/data/n9e/etc/config.toml当然,这个值是可自定义的。
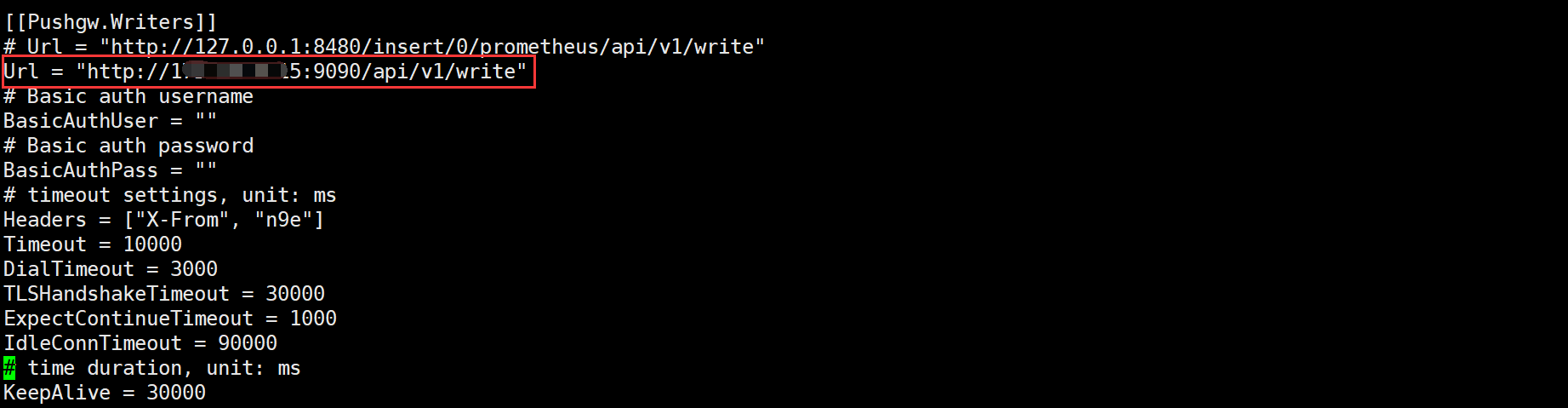
5、配置 n9e-edge 时序数据库
vim /data/n9e-edge/etc/edge/edge.toml
# 填写时序库IP+Port即可
6、启动 n9e-edge
cat <<EOF >/etc/systemd/system/n9e-edge.service
[Unit]
Description="n9e-edge.service"
After=network.target
[Service]
Type=simple
ExecStart=/data/n9e-edge/n9e-edge --configs /data/n9e-edge/etc/edge
WorkingDirectory=/data/n9e-edge
Restart=on-failure
SuccessExitStatus=0
LimitNOFILE=65536
StandardOutput=syslog
StandardError=syslog
SyslogIdentifier=n9e-edge.service
[Install]
WantedBy=multi-user.target
EOF
systemctl start n9e-edge.service
systemctl enable n9e-edge.service
systemctl status n9e-edge.service
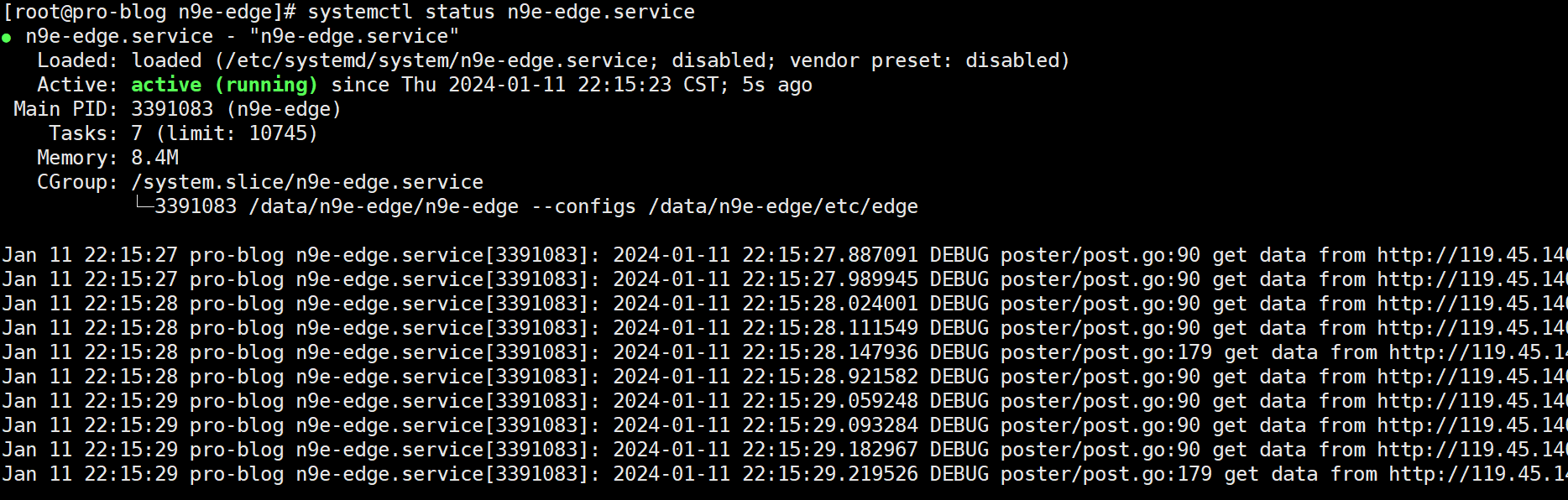
注意,n9e-edge 启动命令中 --configs 选项指定的是一个目录,而不能是文件,否则报错:

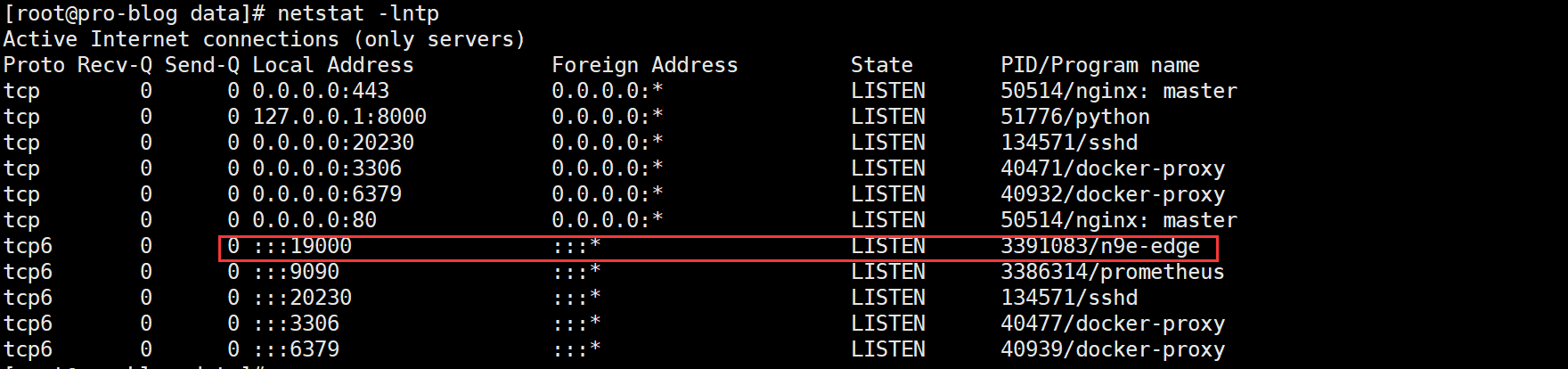
监听 19000 端口:
问题?
边缘机房的 n9e-edge 如果只有一个实例,挂了就麻烦了,如何做高可用?简单,只需要在边缘机房部署多台 n9e-edge 就可以了,注意,同一个 edge 集群,edge.toml 里配置的 EngineName 要一样。n9e-edge 前面再搞个负载均衡,给 agent 上报数据、心跳使用,这样就可以实现 n9e-edge 的高可用了。
4.2.5 Categraf
安装同 4.1.5 小节,这里不再演示。
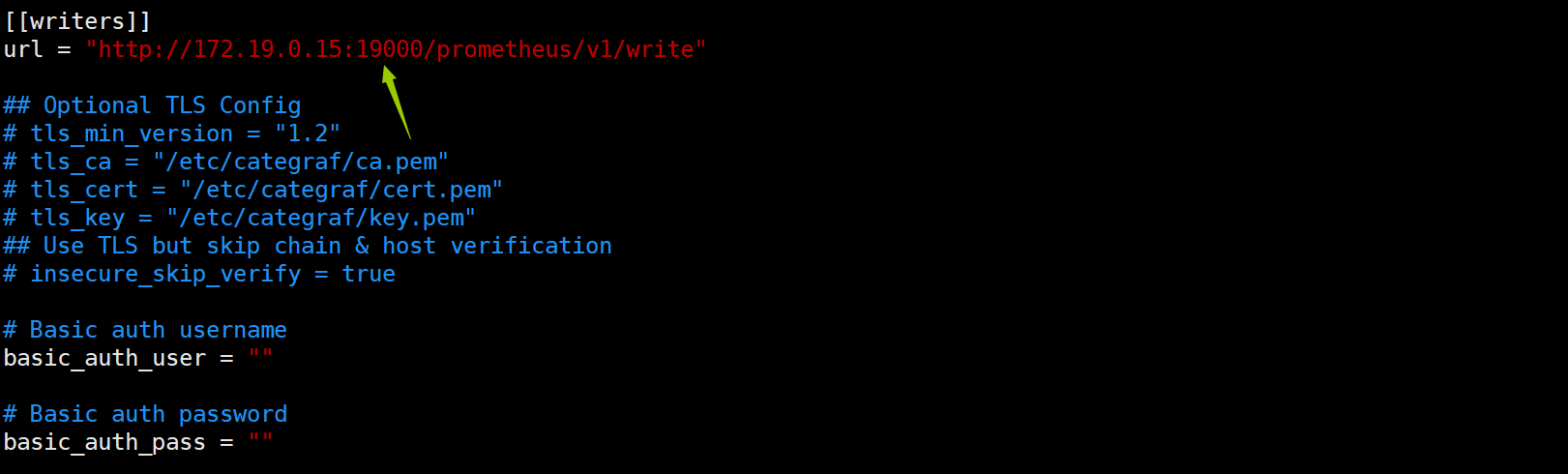
不同之处1:上报数据
注意端口号
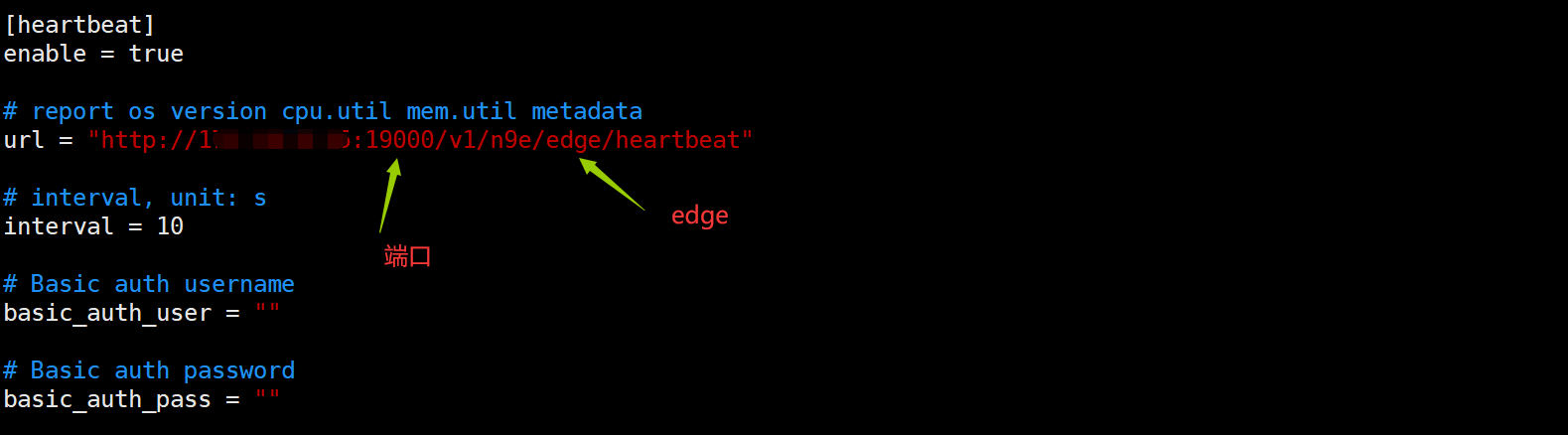
不同之处2:心跳检测
categraf 向 n9e-edge 心跳的话,urlpath 就不能写
/v1/n9e/heartbeat了,而要写成/v1/n9e/edge/heartbeat。
4.2.6 验证
配置好后,就去中心夜莺监控,看边缘机房的数据是否正常采集成功。
1、到 n9e 去查看告警引擎
如下图,n9e-edge 已经和 n9e 建立心跳连接了。
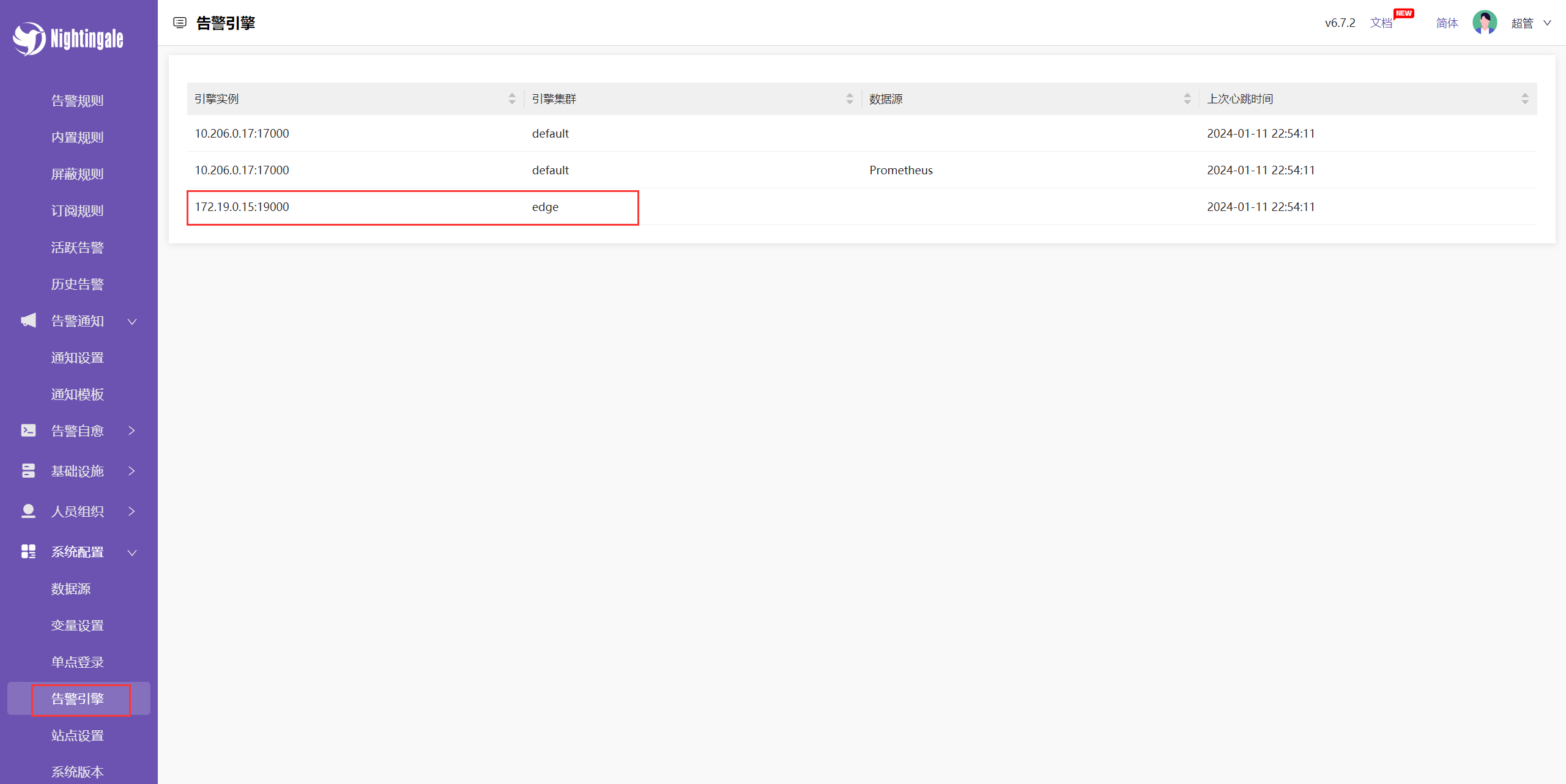
边缘机房的 n9e-edge 默认的引擎名字是 edge,与中心端 n9e 的引擎名字(default)相区分。注意:边缘机房的时序库在夜莺里添加数据源的时候,要选择边缘机房的告警引擎(edge)。如果你有两个边缘机房,注意两个边缘机房的 n9e-edge 的引擎名字要不一样。下图是配置数据源的时候,选择告警引擎的地方:
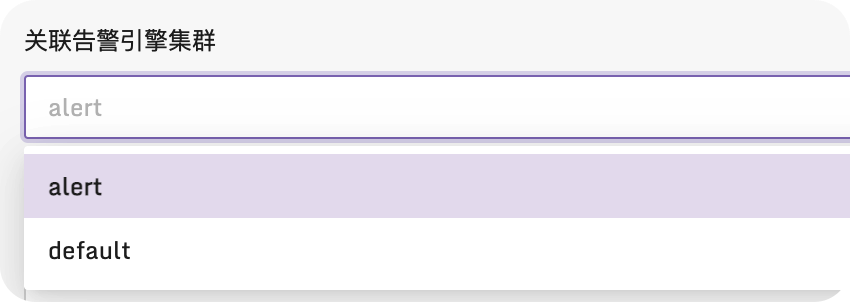
如何设置每个边缘机房的 n9e-egde 的引擎名?
vim /data/n9e-edge/etc/edge/edge.toml
# 修改其配置文件即可
...
[Alert]
[Alert.Heartbeat]
# auto detect if blank
IP = ""
# unit ms
Interval = 1000
EngineName = "edge" # 修改此处(保证各个边缘机房的引擎名唯一)
# [Alert.Alerting]
# NotifyConcurrency = 10
...
2、中心 n9e 配置数据源
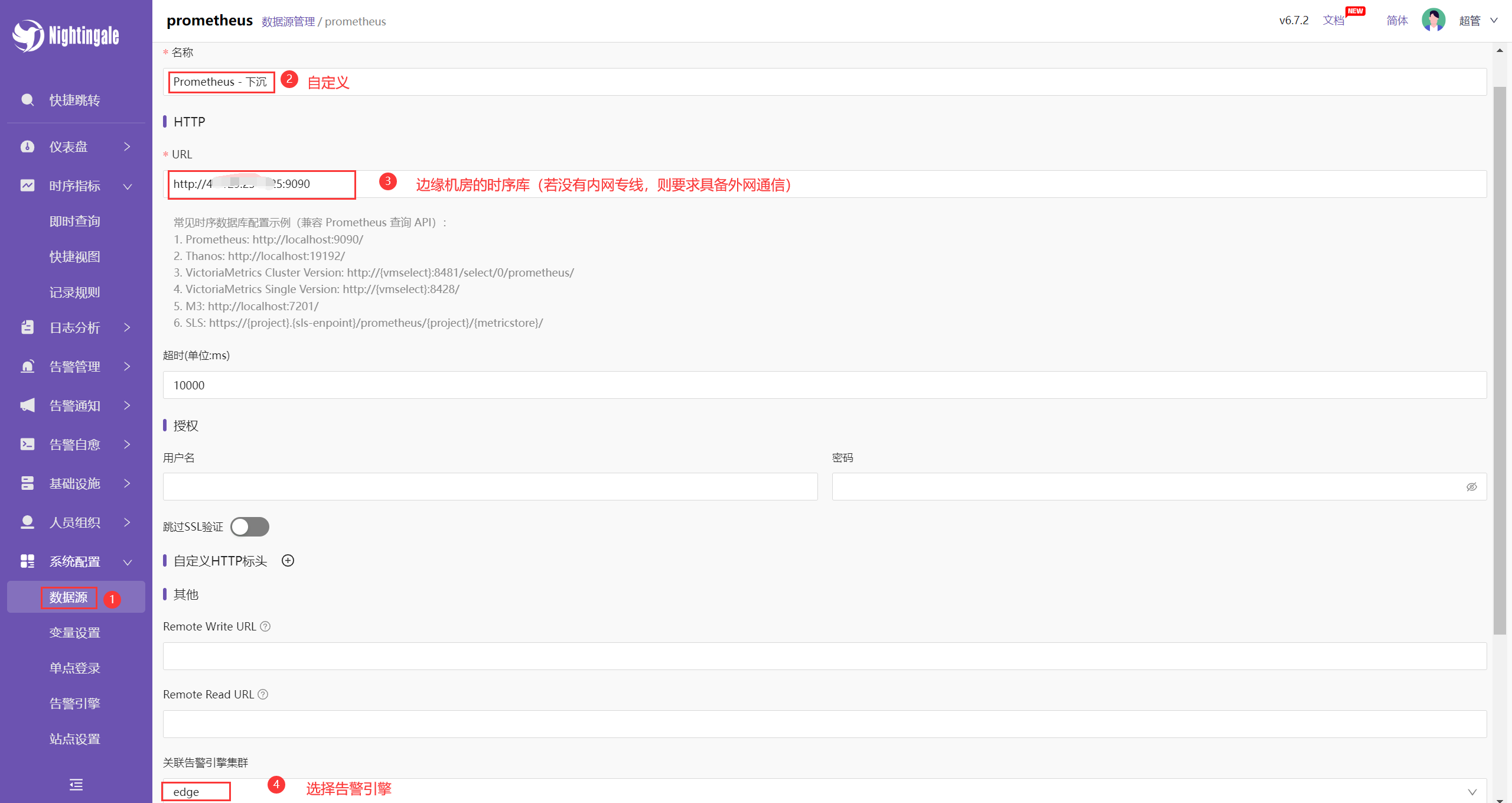
3、查看数据
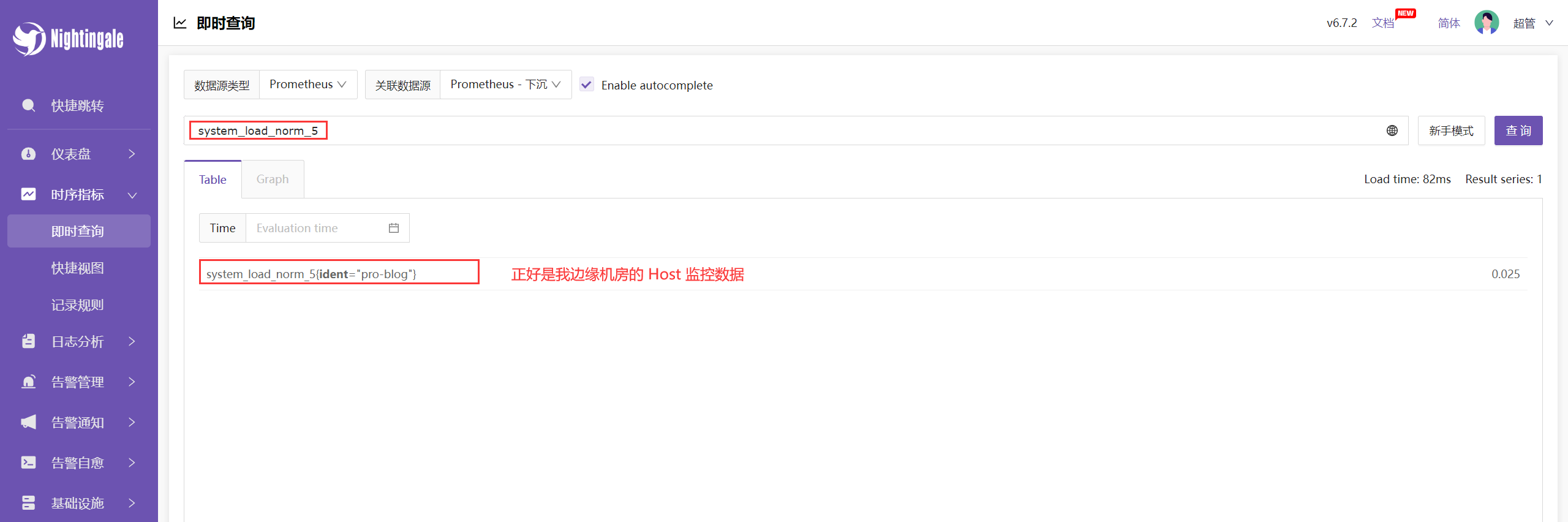
注意:边缘式下沉部署不是通过 n9e-edge 推送数据,而是将 n9e-edge 边缘机房的时序数据库作为 n9e 中心机房的数据源。
总结
1. 中心机房
- 工作流:n9e 作为中心机房的 Server 端,Categraf 作为 Agent 目标数据采集端,上报数据给 n9e,然后 n9e 将相关数据对于存储于 MySQL、Redis、时序库中;
- 存储:n9e 依赖 MySQL、Redis,用于存储用户、规则等相关元信息;
- 时序数据库:Prometheus、influxDB 等时序库;
- 单点问题:部署多实例 n9e 并采用 Nginx 负载均衡/反代/VIP。
2. 边缘机房
- 工作流:n9e-edge 作为下沉机房的 Server 端,Categraf 作为 Agent 目标数据采集端,上报数据给 n9e-edge,然后 n9e-edge 将相关数据对于存储于时序库中;
- 存储:n9e-edge 不依赖于 MySQL、Redis;
- 时序数据库:Prometheus、influxDB 等时序库;
- 单点问题:部署多实例 n9e-edge 并采用 Nginx 负载均衡/反代/VIP。
官方:如果机房之间网络链路很好,就让所有的 categraf 和中心端的 n9e 通信即可,如果某个机房和中心端网络链路不好,就让 categraf 和 n9e-edge 通信,n9e-edge 和中心端的 n9e 通信。
—END
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 代码随想录算法训练营第24天 | 回溯算法理论基础 77.组合
- 不擅长设计也能做好邮件营销:实用技巧与指南分享
- QT用户管理效果预览
- uniapp todo list
- (每日持续更新)信息系统项目管理(第四版)(高级项目管理)考试重点整理第8章 项目整合管理(四)
- 六、新建窗体时,几种窗体的区别
- MongoDB基本常用命令(一)
- Cortex-M3/M4内核中断及HAL库函数详解(1):中断相关寄存器
- 如何查看SSL证书到期时间
- 剑指offer——重建二叉树