爬虫之牛刀小试(九):爬取小说
发布时间:2024年01月25日
今天爬取的是一本小说
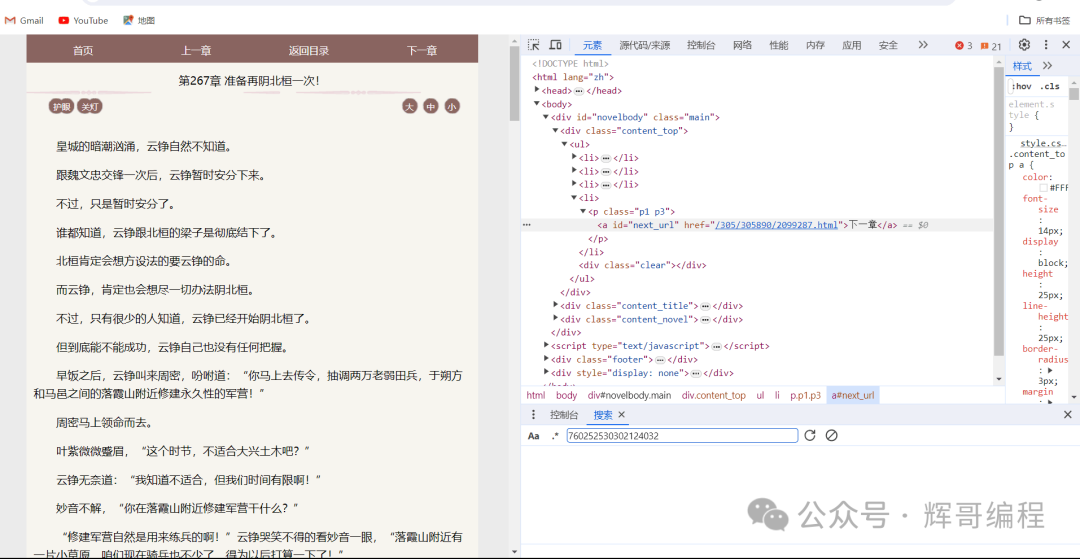
代码如下:
from selenium import webdriver
from selenium.webdriver.common.proxy import Proxy, ProxyType
import random
import time
from selenium.webdriver.common.by import By
def check():
option = webdriver.ChromeOptions()
option.add_argument('--ignore-certificate-errors')
driver = webdriver.Chrome(options=option)
url="https://www.fd80.com/305/305890/2099286.html"
for i in range(267,445):
print("正在爬取第"+str(i)+"章")
driver.get(url)
time.sleep(1)
url=get_text(driver)
print("爬取完成")
def get_text(driver):
element = driver.find_element(By.XPATH, '//*[@id="novelcontent"]/div')
title=driver.find_element(By.XPATH, '//*[@id="chaptertitle"]')
nexthtml=driver.find_element(By.XPATH, '//*[@id="next_url"]')
# 获取下一章的链接
next_url = nexthtml.get_attribute('href')
# 将结果写入文件
with open('无敌六皇子.txt', 'a', encoding='utf-8') as f:
f.write(title.text + '\n')
f.write(element.text + '\n\n')
return next_url
if __name__ == '__main__':
check()
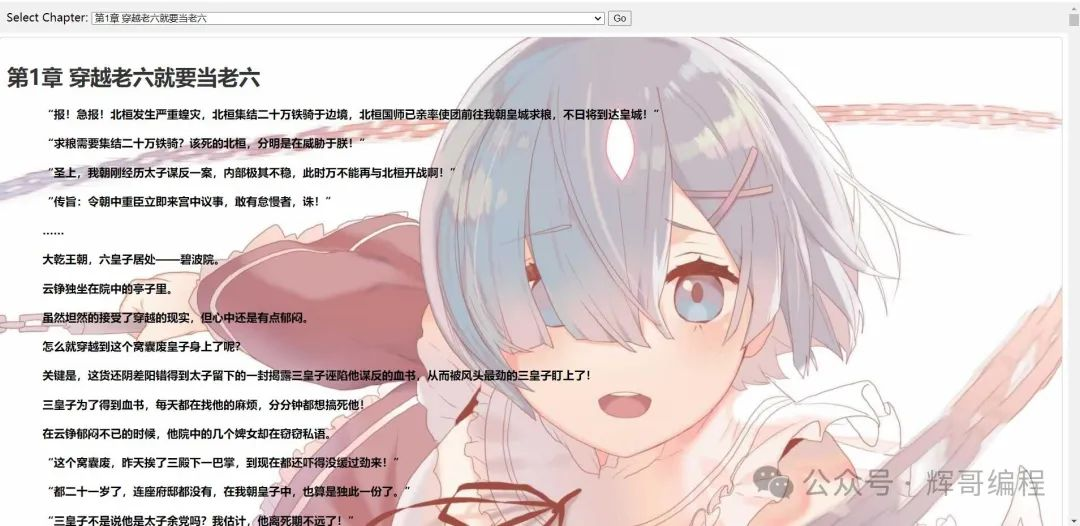
接着写一个网页来表示出文本内容(此段代码由陈同学提供,不方便展示),效果如下:
最近新开了公众号,请大家关注一下。

文章来源:https://blog.csdn.net/m0_68926749/article/details/135832658
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!