Python爬虫基础:千叶网4K高清壁纸批量下载,电脑桌面做到一天一换
发布时间:2024年01月04日
目录
前言
开发环境
操作系统:win 10
编辑器:pycharm专业版
语言及版本:python 3.8
使用的库:requests、os、parsel
代码流程
- 发送请求, 模拟浏览器对于 图片目录页面 发送请求
- 获取数据, 获取服务器返回响应数据
- 解析数据, 提取我们想要数据内容
- 发送请求, 模拟浏览器对于 图片详情页url 发送请求
- 获取数据, 获取服务器返回响应数据
- 解析数据, 提取我们想要数据内容
- 保存数据, 把图片保存文本文件夹
代码实现
1、导入相关库
import requests
import parsel
import os
2、发送请求
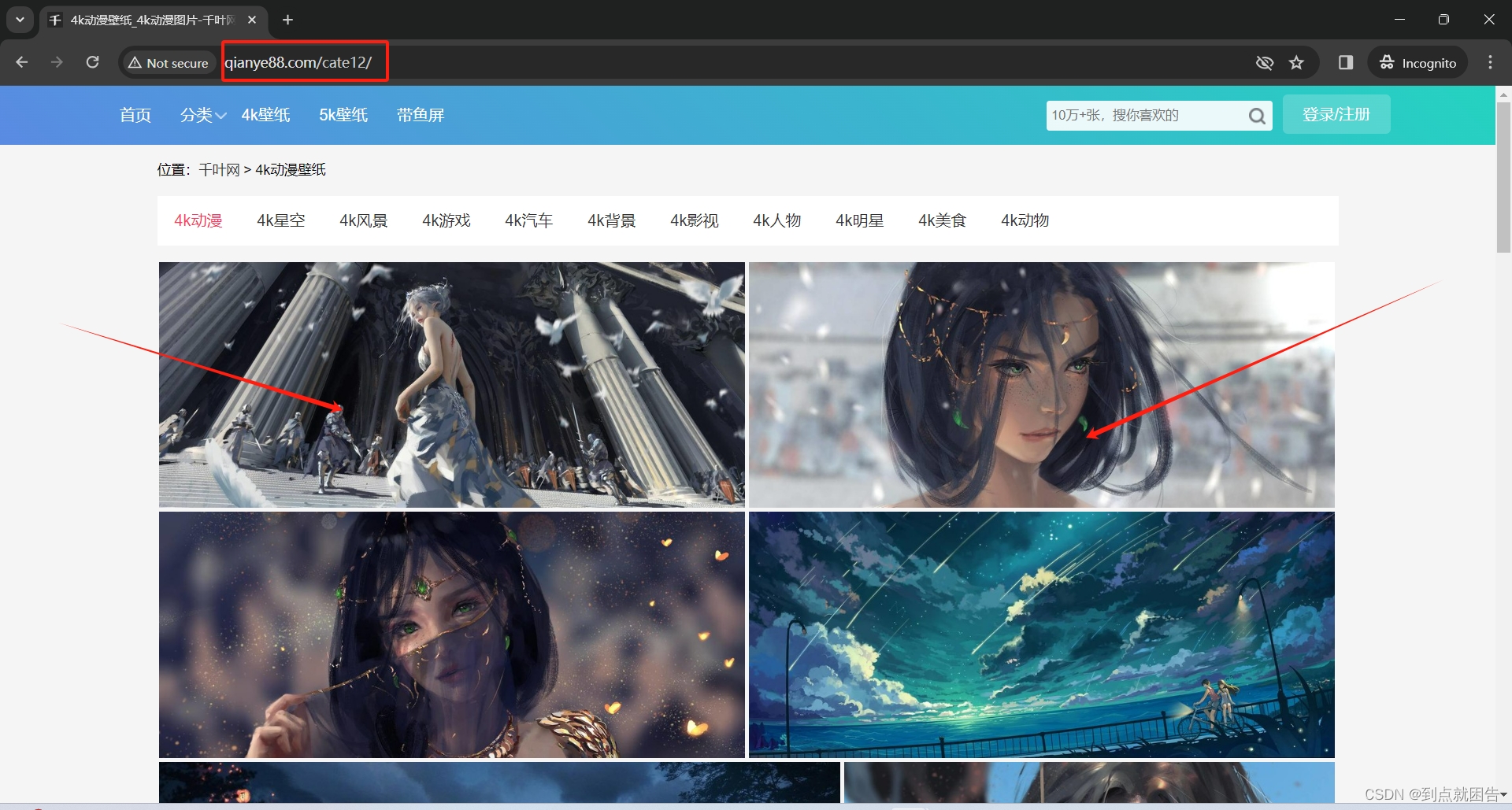
此次请求的目标网址是千叶网上的4K动漫壁纸,4k动漫壁纸_4k动漫图片-千叶网
url = 'http://qianye88.com/cate12/'
response = requests.get(url=url)
print(response)返回<Response [200]>代表对网址请求成功,到这就已经成功一半了。就问你惊不惊喜,有木有jio得嘎嘎简单!!!
3、解析网页,获取图片详情页地址?
按下键盘F12打开开发者工具,点击图片会跳转。可以看到这边包括有图片详情页地址以及壁纸标题。可以使用parsel库解析我们需要的数据内容
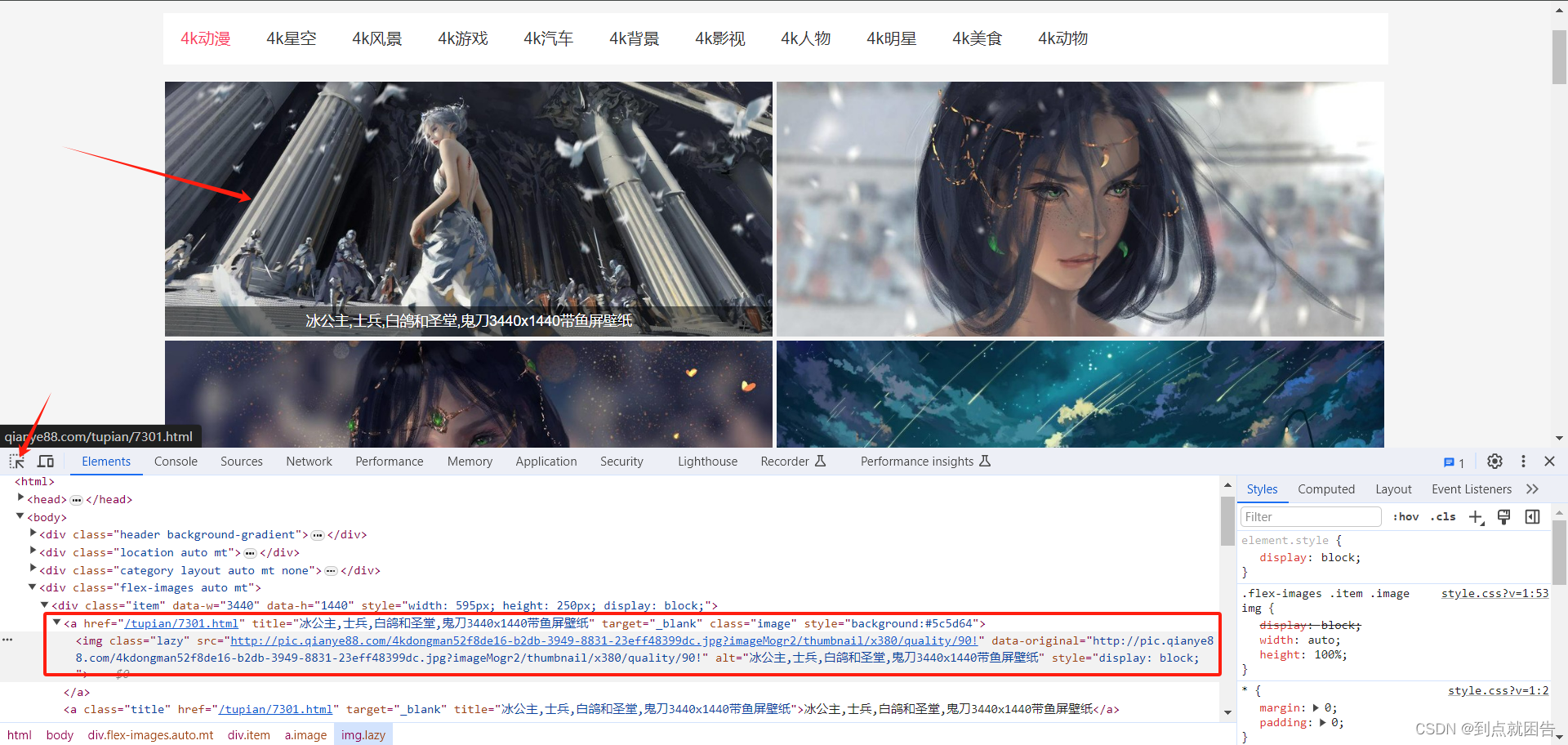
sel = parsel.Selector(response)
divs = sel.xpath('//div[@class="flex-images auto mt"]/div')
for div in divs:
href = 'http://qianye88.com/' + div.xpath('.//a[1]/@href').get()
title = div.xpath('.//a[1]/@title').get()
print(title, href)这样就可以得到我们需要的壁纸的详情页啦~
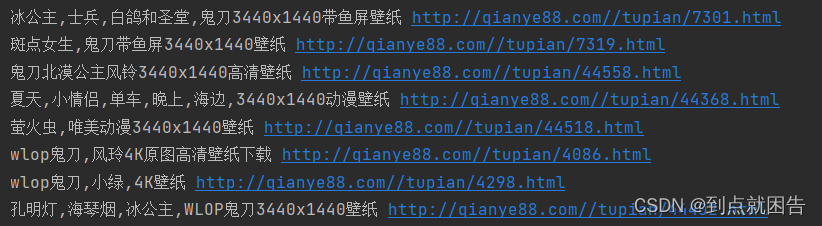
4、获取高清4K原图地址

以第一张鬼刀壁纸为例。同上操作,我们可以看到这边的src地址就是我们需要的图片资源。到这里寻找原链接的过程基本就实现啦~

resp = requests.get(url=href).text
se = parsel.Selector(resp)
src = se.xpath('//div[@class="content-left layout fl"]/img/@src').get()5、向图片链接发送请求,保存壁纸
模拟浏览器:?
response.text 获取响应文本数据
response.json() 获取响应json字典数据
response.content 获取响应二进制数据
我们使用requests.get()方法向指定的url发送get请求,并获取到响应的内容
content = requests.get(url=src).content
with open('千叶网\\' + title + '.jpg', mode='wb') as f:
f.write(content)
print('保存成功:', title)
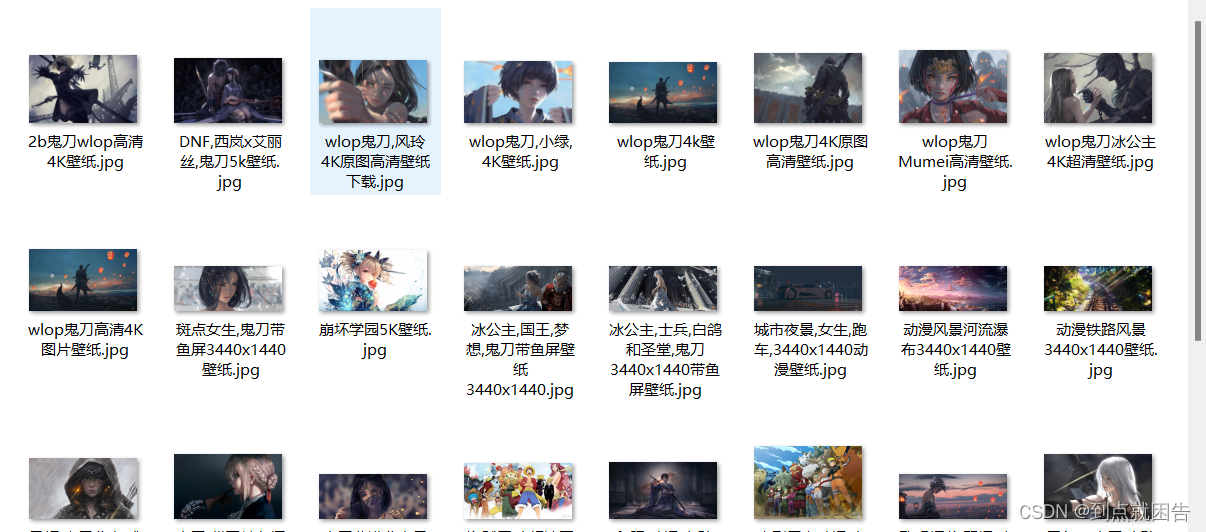
这样就基本实现壁纸自由啦~
其实还可以做到多页爬取的,等后续熟悉再去自行探索吧哈哈哈
例外
可能会出现显示文件夹不存在的报错,那是因为我新建了一个叫千叶网的文件夹并把所有图片都保存在该目录下面,只要在前面加上下面这段代码就可以解决这个问题了。
if not os.path.exists('千叶网\\'):
os.mkdir('千叶网\\')
文章来源:https://blog.csdn.net/weixin_44765053/article/details/135370855
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 怎么查已经安装了什么版本了的软件?
- Python中的h5py包使用
- Xcode15 升级问题记录
- Java进阶第十章——反射机制
- 如何提高建筑模板在施工中的效率?
- UCAS-AOD遥感旋转目标检测数据集——基于YOLOv8obb,map50已达96.7%
- 网页测试遇到自动弹窗,Alert类无法处理?或许你该来学学这招了!
- MicroPython性能调优
- 道可云元宇宙每日资讯|2024冬青奥会将首次推出冬青奥“元宇宙”
- Sectigo dv通配符ssl证书