Protobuf小记(万字)
Protobuf小记

序列化概念
序列化和反序列化
序列化:把对象转换为字节序列的过程。反序列化:把字节序列恢复为对象的过程。
什么情况下需要序列化?
存储数据:当想把的内存中的对象状态保存到?个文件中或者存到数据库中时。网络传输:网络直接传输数据,但是无法直接传输对象,所以要在传输前序列化,传输完成后反序列化成对象。例如我们之前学习过 socket 编程中发送与接收数据。
如何实现序列化?
??xml(JavaScript Object Notation)、json(eXtensible Markup Language)、 protobuf(Protocol Buffers)
ProtoBuf 初识
??简单来讲, ProtoBuf(全称为 Protocol Buffer)是让结构数据序列化的方法,其具有以下特点:
语言无关、平台无关:即 ProtoBuf 支持 Java、C++、Python 等多种语?,支持多个平台。高效:即比 XML 更小、更快、更为简单。扩展性、兼容性好:你可以更新数据结构,而不影响和破坏原有的旧程序。
使用特点:
ProtoBuf是需要依赖通过编译生成的头文件和源文件来使用的。
快速上手
通讯录 1.0
- 将实现最为简易的通讯录:
- 对?个联系人的信息使用 ProtoBuf 进行序列化,并将结果打印出来。
- 对序列化后的内容使用 ProtoBuf 进行反序列,解析出联系人信息并打印出来。
- 联系人包含以下信息:姓名、年龄。
// 首行:语法指定行 - 如果没有指定,编译器会使?proto2语法
syntax = "proto3"; // 必须写在除去注释内容的第一行
/*
package 声明符
?件的命名空间 - 唯?性
*/
package contacts;
/*
message 定义消息
定义的结构化对象
*/
message peopleInfo
{
// = ? 标识编号
string name = 1 // 名字
int32 age = 2 // 年龄
// 字段编号是与其编译原理有关,必须要带上: 也就是之前所提到的之所以ProtoBuf序列化更小的原因
// 否者:报错,标识必须不相同
}
在 message 中我们可以定义其属性字段,字段定义格式为:
字段类型 字段名 = 字段唯一编号
字段名称命名规范:全小写字母,多个字母之间用 _ 连接。字段类型分为:标量数据类型 和 特殊类型(包括枚举、其他消息类型等)。字段唯?编号:用来标识字段,?旦开始使用就不能够再改变。
??该表格展示了定义于消息体中的标量数据类型,以及编译 .proto 文件之后自动生成的类中与之对应的字段类型。
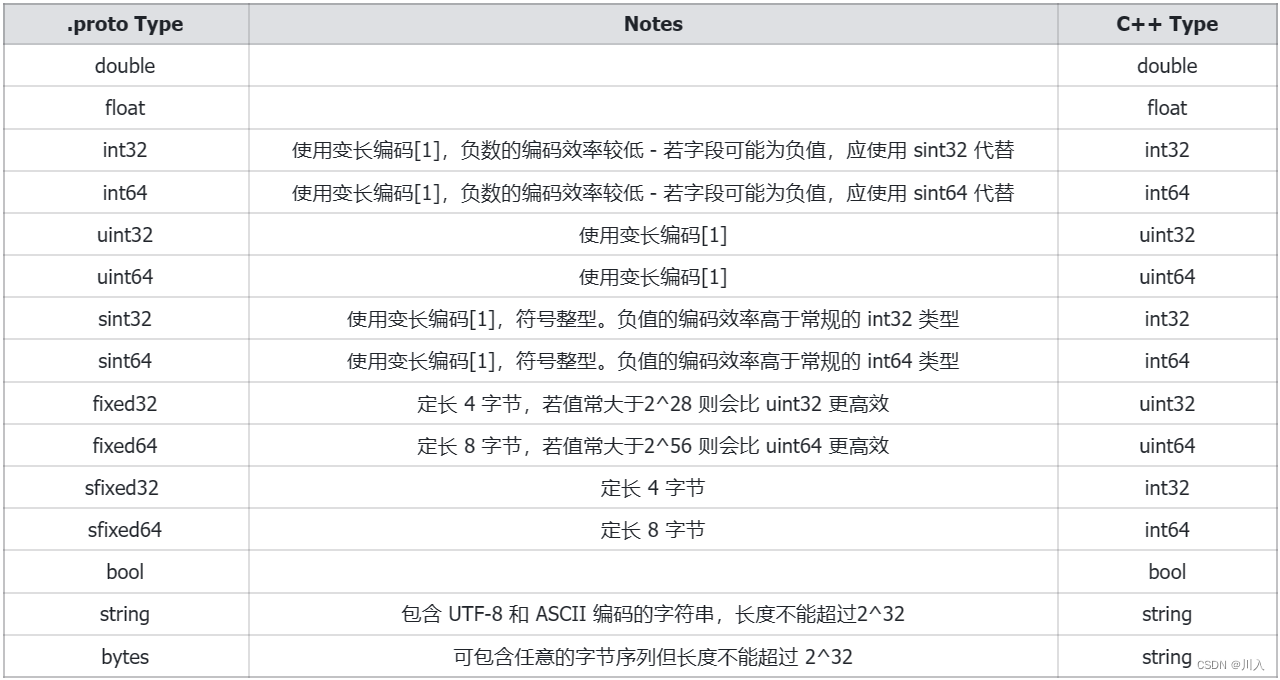
??[1] 变长编码是指:经过 protobuf 编码后,原本4字节或8字节的数可能会被变为其他字节数 - 也是 protobuf 较小的原因。
??protobuf 对于负数是会扩充成10字节的数 - 所以若字段可能为负值,需要代替,对其会有自己的编码逻辑。
字段唯一编号的范围:
??可用编号范围:1 ~ 536,870,911 (2^29 - 1) ,其中 19000 ~ 19999 不可用。
??19000 ~ 19999 不可用是因为:在 Protobuf 协议的实现中,对这些数进行了预留。如果非要在 .proto 文件中使用这些预留标识号,例如:将 name 字段的编号设置为19000,编译时就会报警:
// Field numbers 19,000 through 19,999 are reserved for the protobuf implementation
string name = 19000;
??范围为 1 ~ 15 的字段编号需要?个字节进行编码,16 ~ 2047 内的数字需要两个字节进行编码。编码后的字节不仅只包含了编号,还包含了字段类型。
??序列化和反序列化方法,序列化整个类的时候,其会将字段标号序列化进去的,所以其会向上述所说一样的占用字节。所以 1 ~ 15 要用来标记出现非常频繁的字段,要为将来有可能添加的或频繁出现的字段预留?些出来。
通讯录 1.0 - 函数 API 小结
1.(声明符::定义信息)对象.字段名() - 返回对应的数据
people_info.name();
// 函数声明
const std::string& name() const;
2.(声明符::定义信息)对象.set_字段名() - 给特定字段设置值
people_info.set_age(21);
// 函数声明
void set_age(int32_t value);
3.序列化:
bool SerializeToOstream(ostream* output) const; // 将序列化后数据写??件流
bool SerializeToArray(void *data, int size) const; // 将序列化后数据写?字节数组
bool SerializeToString(string* output) const; // 将序列化后数据写?string
4.反序列化:
bool ParseFromIstream(istream* input); // 从流中读取数据,再进?反序列化动作
bool ParseFromArray(const void* data, int size); // 从字节数组中读取数据,再进?反序列化动作
bool ParseFromString(const string& data); // 从string中读取数据,再进?反序列化动作
编译 contacts.proto 文件,生成 C++ 文件
protoc [--proto_path=IMPORT_PATH] --cpp_out=OUT_DIR path/to/file.proto
protoc 是 Protocol Buffer 提供的命令行编译工具。
--proto_path 指定被编译的 .proto 文件所在目录 (可多次指定、可简写成 -I IMPORT_PATH)默认当前目录进行搜索。
当某个.proto 文件 import 其他 .proto 文件或需要编译的 .proto 文件不在当前目录下,这时就要用
-I 来指定搜索目录。
--cpp_out= 指编译后的文件为 C++ 文件。
OUT_DIR 编译后生成文件的目标路径。
path/to/file.proto 要编译的.proto文件。
??查看protobuf的所有命令选项:
[qcr@VM-16-6-centos Learn_protoBuf]$ protoc -h
Usage: protoc [OPTION] PROTO_FILES
Parse PROTO_FILES and generate output based on the options given:
-IPATH, --proto_path=PATH Specify the directory in which to search for
imports. May be specified multiple times;
directories will be searched in order. If not
given, the current working directory is used.
If not found in any of the these directories,
the --descriptor_set_in descriptors will be
checked for required proto file.
--version Show version info and exit.
-h, --help Show this text and exit.
--encode=MESSAGE_TYPE Read a text-format message of the given type
from standard input and write it in binary
to standard output. The message type must
be defined in PROTO_FILES or their imports.
--deterministic_output When using --encode, ensure map fields are
deterministically ordered. Note that this order
is not canonical, and changes across builds or
releases of protoc.
--decode=MESSAGE_TYPE Read a binary message of the given type from
standard input and write it in text format
to standard output. The message type must
be defined in PROTO_FILES or their imports.
--decode_raw Read an arbitrary protocol message from
standard input and write the raw tag/value
pairs in text format to standard output. No
PROTO_FILES should be given when using this
flag.
--descriptor_set_in=FILES Specifies a delimited list of FILES
each containing a FileDescriptorSet (a
protocol buffer defined in descriptor.proto).
The FileDescriptor for each of the PROTO_FILES
………………………………………………………………………………………………
[qcr@VM-16-6-centos Learn_protoBuf]$ protoc --cpp_out=. contacts.proto
[qcr@VM-16-6-centos Learn_protoBuf]$ ll
total 28
-rw-rw-r-- 1 qcr qcr 11506 Nov 7 19:09 contacts.pb.cc
-rw-rw-r-- 1 qcr qcr 10278 Nov 7 19:09 contacts.pb.h
-rw-rw-r-- 1 qcr qcr 481 Nov 7 19:09 contacts.proto
对字段进行操作的方法:
编译 contacts.proto 文件后会生成什么?
??会根据选择语言的代码,编译后生成两个文件: contacts.pb.h contacts.pb.cc
- 对于编译生成的 C++ 代码,包含了以下内容 :
- 对于每个
message,都会生成?个对应的消息类。 - 在消息类中,编译器为每个字段提供了获取和设置方法,以及其他能够操作字段的方法。
- 编辑器会针对于每个
.proto文件生成.h和.cc文件,分别用来存放类的声明与类的实现。
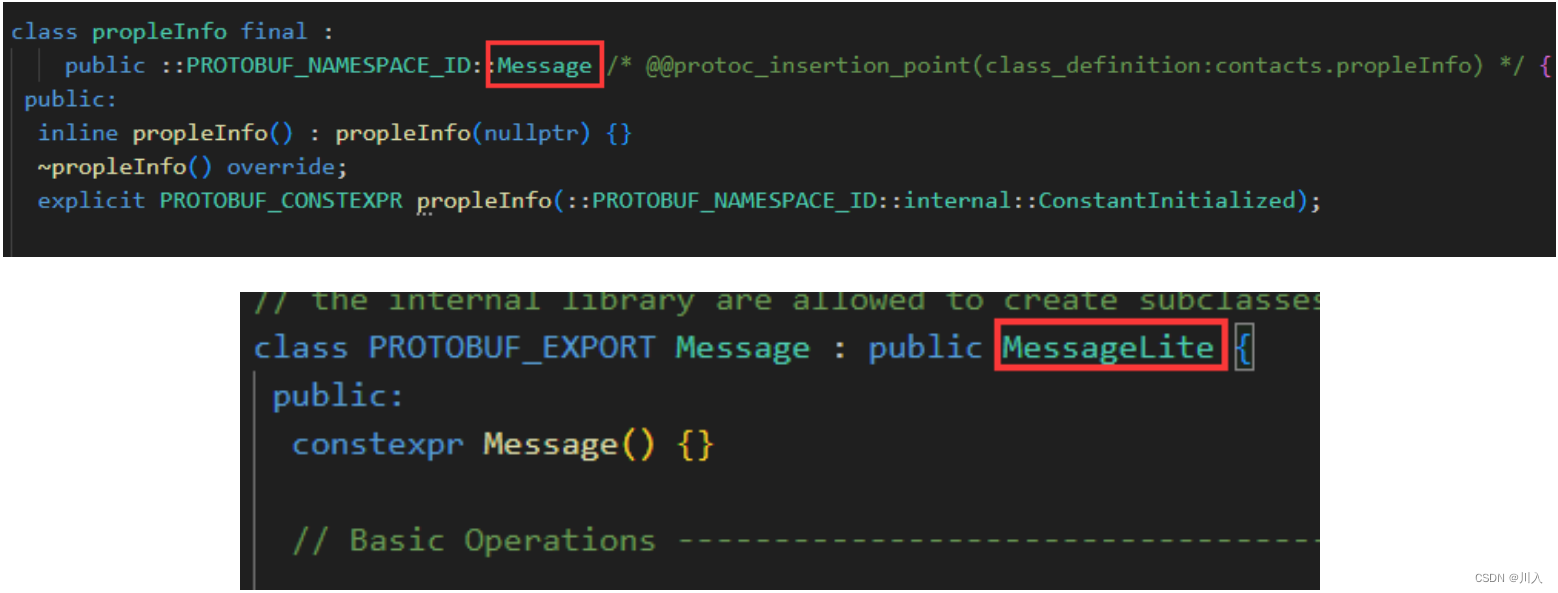
class PeopleInfo final : public ::PROTOBUF_NAMESPACE_ID::Message {
public:
using ::PROTOBUF_NAMESPACE_ID::Message::CopyFrom;
void CopyFrom(const PeopleInfo& from);
using ::PROTOBUF_NAMESPACE_ID::Message::MergeFrom;
void MergeFrom( const PeopleInfo& from) {
PeopleInfo::MergeImpl(*this, from);
}
static ::PROTOBUF_NAMESPACE_ID::StringPiece FullMessageName() {
return "PeopleInfo";
}
// string name = 1;
void clear_name();
const std::string& name() const;
template <typename ArgT0 = const std::string&, typename... ArgT>
void set_name(ArgT0&& arg0, ArgT... args);
std::string* mutable_name();
PROTOBUF_NODISCARD std::string* release_name();
void set_allocated_name(std::string* name);
// int32 age = 2;
void clear_age();
int32_t age() const;
void set_age(int32_t value);
};
上述的例子中:
- 每个字段都有设置和获取的方法,
getter的名称与小写字段完全相同,setter方法以set_开头。- 每个字段都有?个
clear_方法,可以将字段重新设置回empty状态。
在里面就可以看见一批的序列化和分序列化方法:
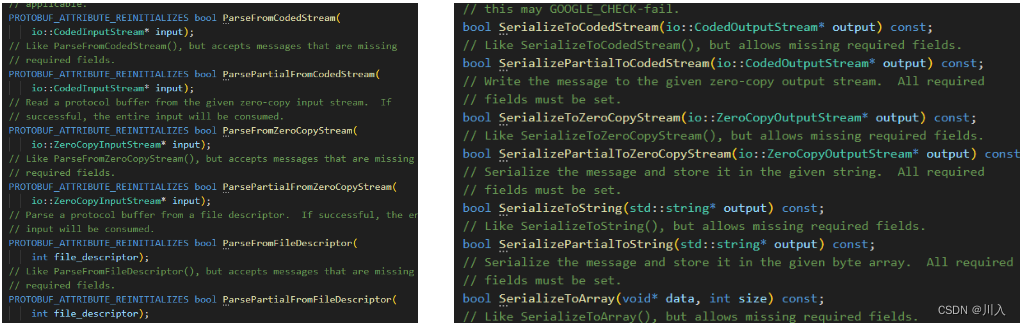
- 简化出来就是
class MessageLite {
public:
//序列化:
bool SerializeToOstream(ostream* output) const; // 将序列化后数据写??件流
bool SerializeToArray(void *data, int size) const;
bool SerializeToString(string* output) const;
//反序列化:
bool ParseFromIstream(istream* input); // 从流中读取数据,再进?反序列化动作
bool ParseFromArray(const void* data, int size);
bool ParseFromString(const string& data);
};
注意:
- 序列化的结果为二进制字节序列,而非文本格式。
- 以上各三种序列化的方法没有本质上的区别,只是序列化后输出的格式不同,可以供不同的应用场景使用。
序列化API 函数均为const成员函数,因为序列化不会改变类对象的内容,而是将序列化的结果保存到函数入参指定的地址中。- Message API
#include <iostream>
#include <string>
// 引?编译?成的头?件
#include "contacts.pb.h"
int main()
{
std::string people;
{
// .proto?件声明的package,通过protoc编译后,会为编译?成的C++代码声明同名的命名空间
contacts::PeopleInfo people_info;
people_info.set_name("cr");
people_info.set_age(21);
// 调?序列化?法,将序列化后的?进制序列存?string中
if(!people_info.SerializePartialToString(&people))
{
std::cerr << "序列化失败" << std::endl;
}
// 打印序列化结果
// 由于为二进制所以输出结果不可控,所以在终端打印的时候会有换?等?些乱码
std::cout << "序列化成功: " << people << std::endl;
}
{
contacts::PeopleInfo people_info;
// 调?反序列化?法,读取string中存放的?进制序列,并反序列化出对象
if(!people_info.ParseFromString(people))
{
std::cerr << "反序列化失败" << std::endl;
}
// 打印结果
std::cout << "反序列化成功: " << people_info.name() << "-" << people_info.age() << std::endl;
}
return 0;
}
--------------------------------------------------
?-lprotobuf:必加,不然会有链接错误
?-std=c++11:必加,protobuf内使用了C++11语法
--------------------------------------------------
[qcr@VM-16-6-centos Learn_protoBuf]$ g++ -o main.out contacts.pb.cc main.cc -std=c++11 -lprotobuf
[qcr@VM-16-6-centos Learn_protoBuf]$ ./main.out
序列化成功:
cr
反序列化成功: cr-21
??相对于xml和JSON来说,因为被编码成?进制,破解成本增大,ProtoBuf编码是相对安全的。
- 总的来说:
??ProtoBuf是需要依赖通过编译生成的头文件和源文件来使用的。有了这种代码生成机制,开发人员再也不用编写那些协议解析的代码了。
proto 3 语法详解
字段规则
singular:消息中可以包含该字段零次或?次(不超过?次)。proto3语法中,字段默认使用该规则 - 对某个字段不使用任何规则的时候就会默认使用该singular规则。
??给
singular规则字段设置值的时候,要么是不设置,要么就是只能设置一个,如果设置多个以最后设置的值为主。
repeated:消息中可以包含该字段任意多次(包括零次),其中重复值的顺序会被保留。可以理解为定义了?个数组。
syntax = "proto3";
package contacts;
message PeopleInfo {
string name = 1;
int32 age = 2;
repeated string phone_numbers = 3;
}
消息类型的定义与使用
定义
??在单个 .proto 文件中可以定义多个消息体,且支持定义嵌套类型的消息(任意多层)。每个消息体中的字段编号可以重复。
// -------------------------- 嵌套写法 -------------------------
syntax = "proto3";
package contacts;
message PeopleInfo
{
string name = 1;
int32 age = 2;
message Phone
{
// 字段编号可以重新开始
string number = 1;
}
}
// -------------------------- ?嵌套写法 -------------------------
syntax = "proto3";
package contacts;
message Phone
{
string number = 1;
}
message PeopleInfo
{
// 字段编号可以重新开始
string name = 1;
int32 age = 2;
repeated Phone phone = 3;
}
消息类型可作为字段类型使用
syntax = "proto3";
package contacts;
// 联系?
message PeopleInfo {
string name = 1;
int32 age = 2;
message Phone
{
string number = 1;
}
repeated Phone phone = 3;
}
多文件写法
??Phone 消息定义在 phone.proto 文件中:
syntax = "proto3";
package phone;
message Phone
{
string number = 1;
}
??contacts.proto 中的 PeopleInfo 使用 Phone 消息:
syntax = "proto3";
package contacts;
import "phone.proto"; // 使用 import 将 phone.proto ?件导?进来 !!!
message PeopleInfo
{
string name = 1;
int32 age = 2;
// 引?的?件声明了package,使?消息时,需要? “命名空间.消息类型” 格式
repeated phone.Phone phone = 3;
}
通讯录 2.0
- 通讯录升级如下内容:
- 不再打印联系人的序列化结果,而是将通讯录序列化后并写入文件中。
- 从文件中将通讯录解析出来,并进行打印。
- 新增联系人属性共包括:姓名、年龄、电话信息。
// 首行:语法指定行 - 如果没有指定,编译器会使?proto2语法
syntax = "proto3";
/*
package 声明符
?件的命名空间 - 唯?性
*/
package contacts;
/*
message 定义消息
定义的结构化对象
*/
message Phone
{
string number = 1;
}
message PeopleInfo
{
// = ? 标识编号
string name = 1; // 名字
int32 age = 2; // 年龄
// 字段编号是与其编译原理有关,必须要带上: 也就是之前所提到的之所以ProtoBuf序列化更小的原因
repeated Phone phone = 3; // 电话信息
}
message Contacts
{
repeated PeopleInfo contacts = 1;
}
通讯录 2.0 的写入实现
- write.cc (通讯录 2.0)
#include <iostream>
#include <string>
#include <fstream>
// 引?编译?成的头?件
#include "contacts.pb.h"
void AddPeopleInfo(contacts::PeopleInfo* people_info_ptr)
{
std::cout << "-------------新增联系?-------------" << std::endl;
// 记入姓名
std::string name;
std::cout << "请输入联系人姓名: ";
std::getline(std::cin, name);
people_info_ptr->set_name(name);
// // 清理"\n";
// std::cin.ignore(256, '\n');
// 记入年龄
int age;
std::cout << "请输入联系人年龄: ";
std::cin >> age;
people_info_ptr->set_age(age);
// 清理"\n";
std::cin.ignore(256, '\n');
// 记入电话
int i = 1;
while(i)
{
std::cout << "请输?联系?电话" << i << "(只输?回?完成电话新增): ";
std::string number;
getline(std::cin, number);
if(number.empty())
{
break;
}
contacts::Phone* phone = people_info_ptr->add_phone();
phone->set_number(number);
i++;
}
std::cout << "-----------添加联系?成功------------" << std::endl;
}
int main()
{
/*
GOOGLE_PROTOBUF_VERIFY_VERSION宏: 验证没有意外链接到与编译的头?件不兼容的库版本.
如果检测到版本不匹配, 程序将中?.
注意: 每个.pb.cc?件在启动时都会?动调?此宏. 在使?C++ Protocol Buffer 库之前执
?此宏是?种很好的做法, 但不是绝对必要的.
*/
GOOGLE_PROTOBUF_VERIFY_VERSION;
contacts::Contacts _contacts;
// 读取本地已存在的联系人文件
std::fstream input("contact.bin", std::ios::in | std::ios::binary);
if(!input)
{
std::cout << "File not found, Creating a new file" << std::endl;
}
else if(!_contacts.ParseFromIstream(&input))
{
std::cerr << "Failed to parse contacts" << std::endl;
input.close();
exit(-1);
}
// 向通讯录添加联系人
AddPeopleInfo(_contacts.add_contacts());
// 将通讯录写入本地文件中
std::fstream output("contact.bin", std::ios::out | std::ios::trunc | std::ios::binary);
if(!_contacts.SerializeToOstream(&output))
{
std::cerr << "Failed to write contacts." << std::endl;
input.close();
output.close();
exit(-2);
}
input.close();
output.close();
/*
在程序结束时调? ShutdownProtobufLibrary(), 为了删除 Protocol Buffer 库分配的所有
全局对象. 对于?多数程序来说这是不必要的, 因为该过程?论如何都要退出, 并且操作系统将负责回
收其所有内存. 但是, 如果我们使用了内存泄漏检查程序, 该程序需要释放每个最后对象, 或者你正在编
写可以由单个进程多次加载和卸载的库,那么你可能希望强制使? Protocol Buffers 来清理所有内容.
*/
google::protobuf::ShutdownProtobufLibrary();
return 0;
}
通讯录 2.0 的输出实现
- read.cc (通讯录 2.0)
#include <iostream>
#include <fstream>
#include "contacts.pb.h"
void PrintfContacts(const contacts::Contacts& _contacts)
{
for(int i = 0; i < _contacts.contacts_size(); i++)
{
const contacts::PeopleInfo& people = _contacts.contacts(i);
std::cout << "------------联系?" << i+1 << "------------" << std::endl;
std::cout << "姓名: " << people.name() << std::endl;
std::cout << "年龄: " << people.age() << std::endl;
int j = 1;
for(const auto& phone : people.phone())
{
std::cout << "电话" << j++ << ": " << phone.number() << std::endl;
}
}
}
int main()
{
GOOGLE_PROTOBUF_VERIFY_VERSION;
contacts::Contacts _contacts;
// 读取文件中已有数据
std::fstream input("contact.bin", std::ios::in | std::ios::binary);
if(!input)
{
std::cout << "File not found, Creating a new file" << std::endl;
}
else if(!_contacts.ParseFromIstream(&input))
{
std::cerr << "Failed to parse contacts" << std::endl;
input.close();
exit(-1);
}
// 打印 contacts
PrintfContacts(_contacts);
input.close();
google::protobuf::ShutdownProtobufLibrary();
return 0;
}
- makefile
all:write read
write:write.cc contacts.pb.cc
g++ -o $@ $^ -std=c++11 -lprotobuf
read:read.cc contacts.pb.cc
g++ -o $@ $^ -std=c++11 -lprotobuf
.PHONY:clean
clean:
rm -f write read
查看二进制文件:
hexdump
??用与二进制文件查看。注意:它能够查看任何文件,不限于与二进制文件。hexdump [选项] [文件]…选项
n length:格式化输出文件的前 length 个字节C:输出规范的十六进制和ASCII码b:单字节八进制显示c:单字节字符显示d:双字节十进制显示o:双字节八进制显示x:双字节十六进制显示s:从偏移量开始输出
[qcr@VM-16-6-centos Learn_protoBuf]$ make
g++ -o write write.cc contacts.pb.cc -std=c++11 -lprotobuf
g++ -o read read.cc contacts.pb.cc -std=c++11 -lprotobuf
[qcr@VM-16-6-centos Learn_protoBuf]$ ./write
File not found, Creating a new file
-------------新增联系?-------------
请输入联系人姓名: 川入
请输入联系人年龄: 21
请输?联系?电话1(只输?回?完成电话新增): 123456789
请输?联系?电话2(只输?回?完成电话新增): 987654321
请输?联系?电话3(只输?回?完成电话新增):
-----------添加联系?成功------------
[qcr@VM-16-6-centos Learn_protoBuf]$ ./write
-------------新增联系?-------------
请输入联系人姓名: 哈哈
请输入联系人年龄: 3
请输?联系?电话1(只输?回?完成电话新增): 1234512436
请输?联系?电话2(只输?回?完成电话新增):
-----------添加联系?成功------------
[qcr@VM-16-6-centos Learn_protoBuf]$ ./read
------------联系?1------------
姓名: 川入
年龄: 21
电话1: 123456789
电话2: 987654321
------------联系?2------------
姓名: 哈哈
年龄: 3
电话1: 1234512436
- 另一种验证方法 - - decode
??我们可以用protoc -h命令来查看ProtoBuf为我们提供的所有命令option。其中ProtoBuf提供?个命令选项--decode。
--decode=MESSAGE_TYPE Read a binary message of the given type from
standard input and write it in text format
to standard output. The message type must
be defined in PROTO_FILES or their imports.
??表示从标准输入中读取给定类型的?进制消息,并将其以文本格式写入标准输出。 消息类型必须在 .proto 文件或导入的文件中定义。
[qcr@VM-16-6-centos Learn_protoBuf]$ protoc --decode=contacts.Contacts contacts.proto < contact.bin
contacts {
name: "\345\267\235\345\205\245" // 在这?是将utf-8汉字转为?进制格式输出了
age: 21
phone {
number: "123456789"
}
phone {
number: "987654321"
}
}
contacts {
name: "\345\223\210\345\223\210" // 在这?是将utf-8汉字转为?进制格式输出了
age: 3
phone {
number: "1234512436"
}
}
通讯录 2.0 - 函数 API 小结
1.(声明符::定义信息)对象.字段名() - 返回对应的数据
people_info.name();
// 函数声明
const std::string& name() const;
2.(声明符::定义信息)对象.set_字段名() - 给特定字段设置值
people_info.set_age(21);
// 函数声明
void set_age(int32_t value);
3.序列化:
bool SerializeToOstream(ostream* output) const; // 将序列化后数据写??件流
bool SerializeToArray(void *data, int size) const; // 将序列化后数据写?字节数组
bool SerializeToString(string* output) const; // 将序列化后数据写?string
4.反序列化:
bool ParseFromIstream(istream* input); // 从流中读取数据,再进?反序列化动作
bool ParseFromArray(const void* data, int size); // 从字节数组中读取数据,再进?反序列化动作
bool ParseFromString(const string& data); // 从string中读取数据,再进?反序列化动作
//上述属于1.0(不再重复)----------------------------------------
1.repeated - "数组"的使用
1.(声明符::定义信息)对象.add_数组字段名() - 添加新的元素
_contacts.add_contacts();
// 函数声明 - 返回指针来设置新对象的属性
::contacts::PeopleInfo* add_contacts();
2.(声明符::定义信息)对象.数组字段名_size() - 数组元素个数
_contacts.contacts_size();
// 函数声明
int contacts_size() const;
enum 类型
定义规则
??语法支持我们定义枚举类型并使用。在.proto文件中枚举类型的书写规范为:
- 枚举类型名称:
- 使用驼峰命名法,首字母大写。
例如: MyEnum
- 使用驼峰命名法,首字母大写。
- 常量值名称:
- 全大写字母,多个字母之间用
_连接。例如: ENUM_CONST = 0;
- 全大写字母,多个字母之间用
??我们可以定义?个名为 PhoneType 的枚举类型,定义如下:
enum PhoneType {
MP = 0; // 移动电话
TEL = 1; // 固定电话
}
定义规则:
0值常量必须存在,且要作为第?个元素。这是为了与 proto2 的语义兼容:第?个元素作为默认值,且值为 0。- 枚举类型可以在消息外定义,也可以在消息体内定义(嵌套)。
- 枚举的常量值在 32 位整数的范围内,但因负值无效因而不建议使用(与编码规则有关)。
定义时注意:
enum PhoneType {
MP = 0; // 移动电话
TEL = 1; // 固定电话
}
enum PhoneTypeCopy {
MP = 0; // 移动电话 -- 此处会报错!!!
}
??将两个具有相同枚举值名称的枚举类型放在单个 .proto 文件下测试时,编译后会报错:某某某常量已经被定义!所以这里要注意:
同级(同层)的枚举类型,各个枚举类型中的常量不能重名。
enum PhoneType {
MP = 0; // 移动电话
TEL = 1; // 固定电话
}
enum PhoneTypeCopy {
MP_C = 0; // 移动电话 -- 如此才可以
}
- 单个
.proto文件下,最外层枚举类型和嵌套枚举类型,不算同级。 - 多个
.proto文件下,若?个文件引入了其他文件,且每个文件都未声明package,每个proto文件中的枚举类型都在最外层,算同级。 - 多个
.proto文件下,若?个文件引入了其他文件,且每个文件都声明了package,不算同级。
// ---------------------- 情况1:同级枚举类型包含相同枚举值名称---------------------
enum PhoneType {
MP = 0; // 移动电话
TEL = 1; // 固定电话
}
enum PhoneTypeCopy {
MP = 0; // 移动电话 // 编译后报错:MP 已经定义
}
// ---------------------- 情况2:不同级枚举类型包含相同枚举值名称-------------------
enum PhoneTypeCopy {
MP = 0; // 移动电话 // ?法正确
}
message Phone {
string number = 1; // 电话号码
enum PhoneType {
MP = 0; // 移动电话
TEL = 1; // 固定电话
}
}
// ---------------------- 情况3:多?件下都未声明package--------------------
// phone1.proto
import "phone1.proto"
enum PhoneType {
MP = 0; // 移动电话 // 编译后报错:MP 已经定义
TEL = 1; // 固定电话
}
// phone2.proto
enum PhoneTypeCopy {
MP = 0; // 移动电话
}
// ---------------------- 情况4:多?件下都声明了package--------------------
// phone1.proto
import "phone1.proto"
package phone1;
enum PhoneType {
MP = 0; // 移动电话 // ?法正确
TEL = 1; // 固定电话
}
// phone2.proto
package phone2;
enum PhoneTypeCopy {
MP = 0; // 移动电话
}
Any 类型
&e**msp;?字段还可以声明为 Any 类型,可以理解为:泛型类型。使用时可以在 Any 中存储任意 消息类型 。Any 类型的字段也用 repeated 来修饰。
??Any 类型是 google 已经帮我们定义好的类型,在安装 ProtoBuf 时,其中的 include 目录下查找所有 google 已经定义好的 .proto 文件。
[qcr@VM-16-6-centos Learn_protoBuf]$ cd /usr/local/protobuf/include/google/protobuf/
[qcr@VM-16-6-centos protobuf]$ ls
any.h descriptor.proto generated_enum_reflection.h map_field.h reflection.h timestamp.proto
any.pb.h duration.pb.h generated_enum_util.h map_field_inl.h reflection_internal.h type.pb.h
any.proto duration.proto generated_message_bases.h map_field_lite.h reflection_ops.h type.proto
api.pb.h dynamic_message.h generated_message_reflection.h map.h repeated_field.h unknown_field_set.h
api.proto empty.pb.h generated_message_tctable_decl.h map_type_handler.h repeated_ptr_field.h util
arena.h empty.proto generated_message_tctable_impl.h message.h service.h wire_format.h
arena_impl.h endian.h generated_message_util.h message_lite.h source_context.pb.h wire_format_lite.h
arenastring.h explicitly_constructed.h has_bits.h metadata.h source_context.proto wrappers.pb.h
arenaz_sampler.h extension_set.h implicit_weak_message.h metadata_lite.h struct.pb.h wrappers.proto
compiler extension_set_inl.h inlined_string_field.h parse_context.h struct.proto
descriptor_database.h field_access_listener.h io port_def.inc stubs
descriptor.h field_mask.pb.h map_entry.h port.h text_format.h
descriptor.pb.h field_mask.proto map_entry_lite.h port_undef.inc timestamp.pb.h

oneof 类型
??如果消息中有很多可选字段, 并且将来同时只有?个字段会被设置, 那么就可以使用 oneof 加强这个行为,也能有节约内存的效果。
- 注意:
- 可选字段中的字段编号,不能与非可选字段的编号冲突。
- 不能在
oneof中使用repeated字段。 - 将来在设置
oneof字段中值时,如果将oneof中的字段设置多个,那么只会保留最后?次设置的成员,之前设置的oneof成员会自动清除。 - 对于 oneof 字段:
- 会将
oneof中的多个字段定义为?个枚举类型。 - 设置和获取:对
oneof内的字段进行常规的设置和获取即可,但要注意只能设置?个。如果设置多个,那么只会保留最后?次设置的成员。 - 清空
oneof字段:clear_ 方法。 - 获取当前设置了哪个字段:_case 方法。
map 类型
??语法支持创建?个关联映射字段,也就是可以使用 map 类型去声明字段类型,格式为:map<key_type, value_type> map_field = N;
- 注意:
key_type是除了float和bytes类型以外的任意标量类型。value_type可以是任意类型。map字段不可以用repeated修饰。map中存入的元素是无序的。- 对于Map类型:
- 清空
map: clear_ 方法 - 设置和获取:获取方法的方法名称与小写字段名称完全相同。设置方法为 mutable_ 方法,返回
值为Map类型的指针,这类方法会为我们开辟好空间,可以直接对这块空间的内容进行修改。
通讯录3.0
- 通讯录升级如下内容:
- 不再打印联系人的序列化结果,而是将通讯录序列化后并写入文件中。
- 从文件中将通讯录解析出来,并进行打印。
- 新增联系人属性,共包括:姓名、年龄、电话信息(固定电话 or 移动电话) -
enum类型、地址(家庭住址 and 单位地址) -any类型、其他联系方式(QQ or 微信) -oneof类型、备注(标题: 正文) -map类型。
// 首行:语法指定行 - 如果没有指定,编译器会使?proto2语法
syntax = "proto3";
/*
package 声明符
?件的命名空间 - 唯?性
*/
package contacts;
// 引入 google 已经定义好的 .proto 文件
import "google/protobuf/any.proto";
/*
message 定义消息
定义的结构化对象
*/
message Phone{ // 电话信息
string number = 1; // 电话号
// enum 类型的使用
enum PhoneType{
MP = 0; // 固定电话
TEL = 1; // 移动电话
}
PhoneType type = 2;
}
message Address{
string home_address = 1; // 家庭住址
string unit_address = 2; // 单位地址
}
message PeopleInfo
{
// = ? 标识编号
string name = 1; // 名字
int32 age = 2; // 年龄
// 字段编号是与其编译原理有关,必须要带上: 也就是之前所提到的之所以ProtoBuf序列化更小的原因
// repeated Phone phone = 3; // 电话信息
repeated Phone phone = 3; // 电话信息
// Any 类型的使用
google.protobuf.Any data = 4;
// oneof 类型的使用
oneof other_contact{
// 不能使用 repeated
string qq = 5; // QQ号
string wechat = 6; // 微信号
}
// map 类型的使用
map<string, string> remark = 7; // 备注信息
}
// 通讯录 message
message Contacts{
repeated PeopleInfo contacts = 1;
}
通讯录 3.0 的写入实现
- write.cc (通讯录 3.0)
#include <iostream>
#include <string>
#include <fstream>
// 引?编译?成的头?件
#include "contacts.pb.h"
void AddPeopleInfo(contacts::PeopleInfo* people_info_ptr)
{
std::cout << "-------------新增联系?-------------" << std::endl;
// 记入姓名
std::string name;
std::cout << "请输入联系人姓名: ";
std::getline(std::cin, name);
people_info_ptr->set_name(name);
// 记入年龄
int age;
std::cout << "请输入联系人年龄: ";
std::cin >> age;
people_info_ptr->set_age(age);
// 清理"\n";
std::cin.ignore(256, '\n');
// 记入电话 - enum 的使用(并记录类型)
for(int i = 1; ; i++)
{
std::cout << "请输?联系?电话" << i << "(只输?回?完成电话新增): ";
std::string number;
getline(std::cin, number);
if(number.empty())
{
break;
}
contacts::Phone* phone = people_info_ptr->add_phone();
phone->set_number(number);
std::cout << "请输入该电话类型(1、移动电话 2、固定电话): ";
int type;
std::cin >> type;
// 清理"\n";
std::cin.ignore(256, '\n');
switch (type) {
case 1:
phone->set_type(contacts::Phone_PhoneType::Phone_PhoneType_MP);
break;
case 2:
phone->set_type(contacts::Phone_PhoneType::Phone_PhoneType_TEL);
break;
default:
std::cout << "选择有误!" << std::endl;
break;
}
}
// 输入地址 - Any 类型的使用
contacts::Address address;
std::cout << "请输入联系人家庭地址:";
std::string home_address;
getline(std::cin, home_address);
address.set_home_address(home_address);
std::cout << "请输入联系人单位地址:";
std::string unit_address;
getline(std::cin, unit_address);
address.set_unit_address(unit_address);
// Address->Any
people_info_ptr->mutable_data()->PackFrom(address);
// 记录通讯方式 - oneof 类型的使用
std::cout << "请选择要添加的其他联系方式(1、qq 2、微信号):" ;
int other_contact;
std::cin >> other_contact;
std::cin.ignore(256, '\n');
if(1 == other_contact){
std::cout << "请输入联系人qq号: ";
std::string qq;
getline(std::cin, qq);
people_info_ptr->set_qq(qq);
} else if (2 == other_contact) {
std::cout << "请输入联系人微信号: ";
std::string wechat;
getline(std::cin, wechat);
people_info_ptr->set_wechat(wechat);
} else {
std::cout << "选择有误,未成功设置其他联系方式!" << std::endl;
}
// 写入备注 - map 类型的使用
for(int i = 0; ; i++){
std::cout << "请输入备注" << i + 1 << "标题(只输入回车完成备注新增):";
std::string remark_key;
getline(std::cin, remark_key);
if(remark_key.empty()){
break;
}
std::cout << "请输入备注" << i + 1 << "内容: ";
std::string remark_value;
getline(std::cin, remark_value);
people_info_ptr->mutable_remark()->insert({remark_key, remark_value});
}
std::cout << "-----------添加联系?成功------------" << std::endl;
}
int main()
{
/*
GOOGLE_PROTOBUF_VERIFY_VERSION宏: 验证没有意外链接到与编译的头?件不兼容的库版本.
如果检测到版本不匹配, 程序将中?.
注意: 每个.pb.cc?件在启动时都会?动调?此宏. 在使?C++ Protocol Buffer 库之前执
?此宏是?种很好的做法, 但不是绝对必要的.
*/
GOOGLE_PROTOBUF_VERIFY_VERSION;
contacts::Contacts _contacts;
// 读取本地已存在的联系人文件
std::fstream input("contact.bin", std::ios::in | std::ios::binary);
if(!input)
{
std::cout << "File not found, Creating a new file" << std::endl;
}
else if(!_contacts.ParseFromIstream(&input))
{
std::cerr << "Failed to parse contacts" << std::endl;
input.close();
exit(-1);
}
// 向通讯录添加联系人
AddPeopleInfo(_contacts.add_contacts());
// 将通讯录写入本地文件中
std::fstream output("contact.bin", std::ios::out | std::ios::trunc | std::ios::binary);
if(!_contacts.SerializeToOstream(&output))
{
std::cerr << "Failed to write contacts." << std::endl;
input.close();
output.close();
exit(-2);
}
input.close();
output.close();
/*
在程序结束时调? ShutdownProtobufLibrary(), 为了删除 Protocol Buffer 库分配的所有
全局对象. 对于?多数程序来说这是不必要的, 因为该过程?论如何都要退出, 并且操作系统将负责回
收其所有内存. 但是, 如果我们使用了内存泄漏检查程序, 该程序需要释放每个最后对象, 或者你正在编
写可以由单个进程多次加载和卸载的库,那么你可能希望强制使? Protocol Buffers 来清理所有内容.
*/
google::protobuf::ShutdownProtobufLibrary();
return 0;
}
通讯录 3.0 的输出实现
- read.cc (通讯录 3.0)
#include <iostream>
#include <fstream>
#include "contacts.pb.h"
void PrintfContacts(const contacts::Contacts& _contacts)
{
for(int i = 0; i < _contacts.contacts_size(); i++)
{
const contacts::PeopleInfo& people = _contacts.contacts(i);
std::cout << "------------联系?" << i+1 << "------------" << std::endl;
std::cout << "姓名: " << people.name() << std::endl;
std::cout << "年龄: " << people.age() << std::endl;
int j = 1;
for(const contacts::Phone& phone : people.phone())
{
std::cout << "联系人电话" << j+1 << ":" << phone.number();
// 电话类型
std::cout << "(" << phone.PhoneType_Name(phone.type()) << ")" << std::endl;
}
if(people.has_data() && people.data().Is<contacts::Address>())
{
contacts::Address address;
people.data().UnpackTo(&address);
if(!address.home_address().empty())
{
std::cout << "联系人家庭地址:" << address.home_address() << std::endl;
}
if(!address.unit_address().empty())
{
std::cout << "联系人家庭地址:" << address.unit_address() << std::endl;
}
}
switch(people.other_contact_case())
{
case contacts::PeopleInfo::OtherContactCase::kQq:
std::cout << "联系人qq: " << people.qq() << std::endl;
break;
case contacts::PeopleInfo::OtherContactCase::kWechat:
std::cout << "联系人微信: " << people.qq() << std::endl;
break;
default:
break;
}
if(people.remark_size())
{
std::cout << "备注信息:" << std::endl;
}
for (auto it = people.remark().cbegin(); it != people.remark().cend(); it++)
{
std::cout << " " << it->first << ": " << it->second << std::endl;
}
}
}
int main()
{
GOOGLE_PROTOBUF_VERIFY_VERSION;
contacts::Contacts _contacts;
// 读取文件中已有数据
std::fstream input("contact.bin", std::ios::in | std::ios::binary);
if(!input)
{
std::cout << "File not found, Creating a new file" << std::endl;
}
else if(!_contacts.ParseFromIstream(&input))
{
std::cerr << "Failed to parse contacts" << std::endl;
input.close();
exit(-1);
}
// 打印 contacts
PrintfContacts(_contacts);
input.close();
google::protobuf::ShutdownProtobufLibrary();
return 0;
}
[qcr@VM-16-6-centos Learn_protoBuf]$ ./write
File not found, Creating a new file
-------------新增联系?-------------
请输入联系人姓名: 你好
请输入联系人年龄: 21
请输?联系?电话1(只输?回?完成电话新增): 1234567
请输入该电话类型(1、移动电话 2、固定电话): 1
请输?联系?电话2(只输?回?完成电话新增): 7654321
请输入该电话类型(1、移动电话 2、固定电话): 2
请输?联系?电话3(只输?回?完成电话新增):
请输入联系人家庭地址:贵州
请输入联系人单位地址:天津
请选择要添加的其他联系方式(1、qq 2、微信号):2
请输入联系人微信号: 1234567
请输入备注1标题(只输入回车完成备注新增):备注1
请输入备注1内容: 电话号与微信号相同
请输入备注2标题(只输入回车完成备注新增):
-----------添加联系?成功------------
[qcr@VM-16-6-centos Learn_protoBuf]$ ./read
------------联系?1------------
姓名: 你好
年龄: 21
联系人电话2:1234567(MP)
联系人电话2:7654321(TEL)
联系人家庭地址:贵州
联系人家庭地址:天津
联系人微信:
备注信息:
备注1: 微信号相同
[qcr@VM-16-6-centos Learn_protoBuf]$
通讯录 3.0 - 函数 API 小结
1.(声明符::定义信息)对象.字段名() - 返回对应的数据
people_info.name();
// 函数声明
const std::string& name() const;
2.(声明符::定义信息)对象.set_字段名() - 给特定字段设置值
people_info.set_age(21);
// 函数声明
void set_age(int32_t value);
3.序列化:
bool SerializeToOstream(ostream* output) const; // 将序列化后数据写??件流
bool SerializeToArray(void *data, int size) const; // 将序列化后数据写?字节数组
bool SerializeToString(string* output) const; // 将序列化后数据写?string
4.反序列化:
bool ParseFromIstream(istream* input); // 从流中读取数据,再进?反序列化动作
bool ParseFromArray(const void* data, int size); // 从字节数组中读取数据,再进?反序列化动作
bool ParseFromString(const string& data); // 从string中读取数据,再进?反序列化动作
//上述属于1.0(不再重复)----------------------------------------
1.repeated - "数组"的使用
1.(声明符::定义信息)对象.add_数组字段名() - 添加新的元素
_contacts.add_contacts();
// 函数声明 - 返回指针来设置新对象的属性
::contacts::PeopleInfo* add_contacts();
2.(声明符::定义信息)对象.数组字段名_size() - 数组元素个数
_contacts.contacts_size();
// 函数声明
int contacts_size() const;
//上述属于2.0(不再重复)----------------------------------------
1.(声明符::定义信息)对象.has_字段名() - 检查字段的存在性
people.has_data();
// 函数声明 - 返回值为布尔值
bool contacts::PeopleInfo::has_data() const;
2.(声明符::定义信息)对象.字段名().IS<定义消息>() - 类型检查
people.data().Is<contacts::Address>();
// 函数声明 - 返回值为布尔值
template<typename T> bool Is() const;
3.enum 类型 - 枚举的使用
1.(声明符::定义信息)enum对象.set_字段名(enum类型元素之一) - 对应设置枚举数据
phone->set_type(contacts::Phone_PhoneType::Phone_PhoneType_MP);
// 函数声明
void contacts::Phone::set_type(contacts::Phone_PhoneType value);
4.any 类型 - 存储任意消息类型(泛型)
1.(声明符::定义信息)对象地址->mutable_字段名() - 为我们开辟好空间
people_info_ptr->mutable_data()->PackFrom(address);
// 函数声明 - 返回值为Any类型的指针
google::protobuf::Any *contacts::PeopleInfo::mutable_data();
2.(声明符::定义信息)any对象地址->PackFrom字段名(消息类型) - 将括号内任意消息类型转为 Any 类型
people_info_ptr->mutable_data()->PackFrom(address);
// 函数声明 - 返回值为布尔值
bool google::protobuf::Any::PackFrom(const google::protobuf::Message &message);
3.对象.any字段名().UnpackTo(消息类型数据地址) - 提取出转为 Any 类型的原类型数据
people.data().UnpackTo(&address);
// 函数声明 - 返回值为布尔值
bool google::protobuf::Any::UnpackTo(google::protobuf::Message *message) const
5.oneof 类型 - 只有?个字段会被设置
1.(声明符::定义信息)对象地址->set_字段名() - 给特定oneof字段设置值
people_info_ptr->set_wechat(wechat);
// 函数声明
void contacts::PeopleInfo::set_wechat<std::string &>(std::string &arg0);
2.对象.oneof字段名_case() - 获取当前设置的 oneof 类型字段
people.other_contact_case()
// 函数声明
contacts::PeopleInfo::OtherContactCase contacts::PeopleInfo::other_contact_case() const;
6.map类型 - 创建关联映射字段
1.(声明符::定义信息)对象地址->mutable_字段名() - 为我们开辟好空间
people_info_ptr->mutable_remark()->insert({remark_key, remark_value});
// 函数声明 - 返回值为map类型的指针
google::protobuf::Map<std::string, std::string> *contacts::PeopleInfo::mutable_remark()
2.(声明符::定义信息)map对象地址->insert() - 向开辟的map插入数据
people_info_ptr->mutable_remark()->insert({remark_key, remark_value});
// 函数声明
std::pair<google::protobuf::Map<std::string, std::string>::iterator, bool> google::protobuf::Map<std::string, std::string>::insert(google::protobuf::MapPair<std::string, std::string> &&value)
// oneof 数据提取的方式
switch(people.other_contact_case())
{
case contacts::PeopleInfo::OtherContactCase::kQq:
std::cout << "联系人qq: " << people.qq() << std::endl;
break;
case contacts::PeopleInfo::OtherContactCase::kWechat:
std::cout << "联系人微信: " << people.qq() << std::endl;
break;
default:
break;
}
// map 数据提取的方式 - const_iterator 迭代器
for (auto it = people.remark().cbegin(); it != people.remark().cend(); it++)
{
std::cout << " " << it->first << ": " << it->second << std::endl;
}
默认值
??反序列化消息时,如果被反序列化的?进制序列中不包含某个字段,反序列化对象中相应字段时,就会设置为该字段的默认值。不同的类型对应的默认值不同:
字符串:默认值为空字符串。字节:默认值为空字节。布尔值:默认值为 false。数值类型:默认值为 0。枚举:默认值是第?个定义的枚举值, 必须为 0。消息字段:未设置该字段,它的取值是依赖于语?。- 设置了
repeated的字段的默认值是空的( 通常是相应语言的?个空列表 )。 消息字段、oneof字段、any字段:C++ 和 Java 语言中都有 has_ 方法来检测当前字段是否被设置。
更新消息
- 新增
注意不要和老字段冲突即可 ! ! ! - 修改
??如果现有的消息类型已经不再满足我们的需求,例如:需要扩展?个字段,在不破坏任何现有代码的情况下更新消息类型。遵循如下规则即可: - 禁止修改任何已有字段的字段编号。
- 若是移除老字段,要保证不再使?移除字段的字段编号。正确的做法是保留字段编号(reserved),以确保该编号将不能被重复使用。不建议直接删除或注释掉字段。
int32,uint32,int64,uint64和 bool 是完全兼容的。可以从这些类型中的?个改为另?个,而不破坏前后兼容性。若解析出来的数值与相应的类型不匹配,会采用与 C++ ?致的处理方案(例如,若将 64 位整数当做 32 位进行读取,它将被截断为 32 位)。sint32和sint64相互兼容但不与其他的整型兼容。string和bytes在合法 UTF-8 字节前提下也是兼容的。bytes包含消息编码版本的情况下,嵌套消息与bytes也是兼容的。fixed32与sfixed32兼容,fixed64与sfixed64兼容。enum与int32,uint32,int64和uint64兼容(注意若值不匹配会被截断)。但要注意当反序列化消息时会根据语言采用不同的处理方案:例如,未识别的 proto3 枚举类型会被保存在消息中,但是当消息反序列化时如何表示是依赖于编程语?的。整型字段总是会保持其的值。oneof:- 将?个单独的值更改为新
oneof类型成员之?是安全和?进制兼容的。 - 若确定没有代码?次性设置多个值那么将多个字段移入?个新
oneof类型也是可行的。 - 将任何字段移入已存在的
oneof类型是不安全的。
- 将?个单独的值更改为新
- 删除
如果要删除老字段,要保证不使用已经被删除的或者已经被注释掉的字段编号。
保留字段 reserved
??如果通过 删除 或 注释掉 字段来更新消息类型,未来的用户在添加新字段时,有可能会使用以前已经存在,但已经被删除或注释掉的字段编号。将来使用该 .proto 的旧版本时的程序会引发很多问题:数据损坏、隐私错误等等。
??确保不会发生这种情况的?种方法是:使用 reserved 将指定字段的编号或名称设置为保留项 。当我们再使用这些编号或名称时,protocol buffer 的编译器将会警告这些编号或名称不可用。
message Message {
// 设置保留项
reserved 100, 101, 200 to 299;
reserved "field3", "field4";
// 注意:不要在?? reserved 声明中同时声明字段编号和名称。
// reserved 102, "field5";
// 设置保留项之后,下?代码会告警
int32 field1 = 100; //告警:Field 'field1' uses reserved number 100
int32 field2 = 101; //告警:Field 'field2' uses reserved number 101
int32 field3 = 102; //告警:Field name 'field3' is reserved
int32 field4 = 103; //告警:Field name 'field4' is reserved
}
??因为 Protocol Buffers 使用字段编号来标识消息中的字段,而不是字段的名称。在读取数据时,解析器会根据字段编号来识别并映射到相应的字段。 - 因为使用了 reserved 关键字,ProtoBuf在编译阶段就拒绝了我们使?已经保留的字段编号。
未知字段
??未知字段: 解析结构良好的 protocol buffer 已序列化数据中的未识别字段的表示方式。例如,当旧程序解析带有新字段的数据时,这些新字段就会成为旧程序的未知字段。
??本来,proto3 在解析消息时总是会丢弃未知字段,但在 3.5 版本 中重新引入了对未知字段的保留机制。所以在 3.5 或更高版本中,未知字段在反序列化时会被保留,同时也会包含在序列化的结果中。
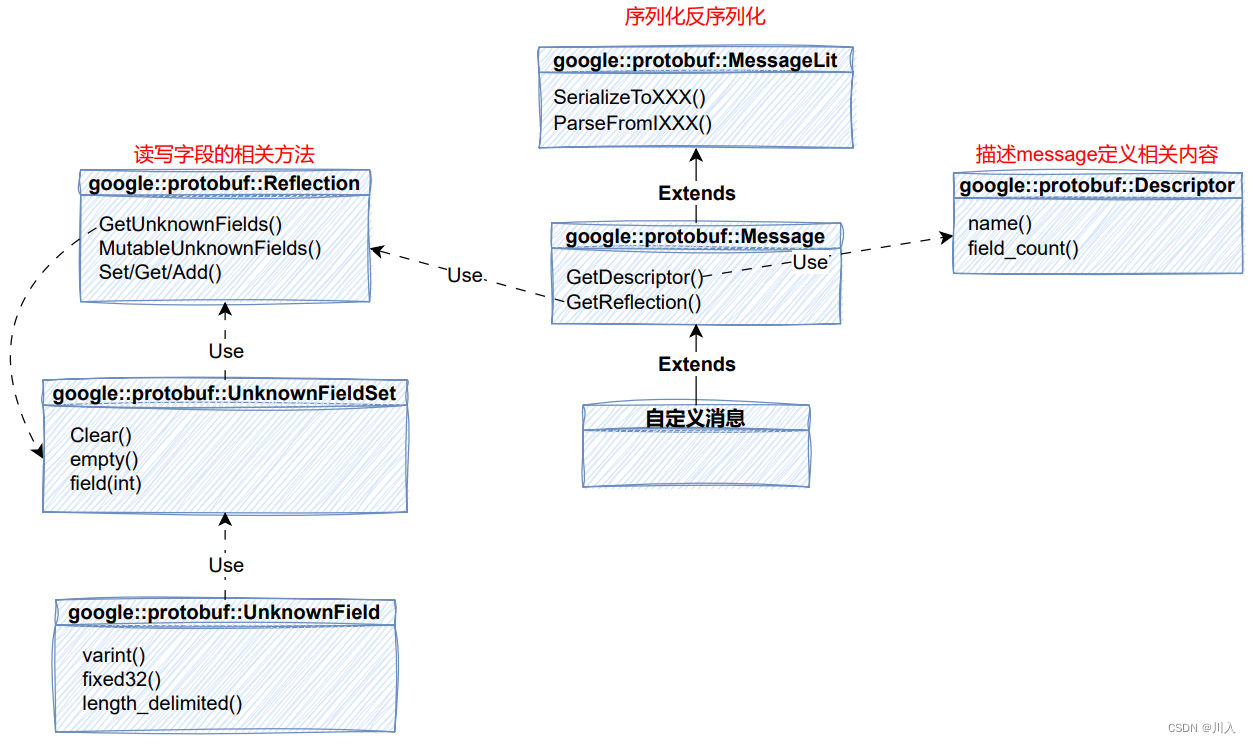
- MessageLite 类介绍
- MessageLite 从名字看是轻量级的 message,仅仅提供序列化、反序列化功能。
- 类定义在 google 提供的 message_lite.h 中。
- Message 类介绍
- 我们自定义的message类,都是继承自Message。
- Message 最重要的两个接口
GetDescriptor/GetReflection,可以获取该类型对应的Descriptor对象指针 和 Reflection 对象指针。 - 类定义在 google 提供的 message.h 中。
//google::protobuf::Message 部分代码展?
const Descriptor* GetDescriptor() const;
const Reflection* GetReflection() const;
- Descriptor 类介绍
- Descriptor:是对message类型定义的描述,包括message的名字、所有字段的描述、原始的
proto文件内容等。 - 类定义在 google 提供的 descriptor.h 中。
// 部分代码展?
class PROTOBUF_EXPORT Descriptor : private internal::SymbolBase {
string& name () const
int field_count() const;
const FieldDescriptor* field(int index) const;
const FieldDescriptor* FindFieldByNumber(int number) const;
const FieldDescriptor* FindFieldByName(const std::string& name) const;
const FieldDescriptor* FindFieldByLowercaseName(
const std::string& lowercase_name) const;
const FieldDescriptor* FindFieldByCamelcaseName(
const std::string& camelcase_name) const;
int enum_type_count() const;
const EnumDescriptor* enum_type(int index) const;
const EnumDescriptor* FindEnumTypeByName(const std::string& name) const;
const EnumValueDescriptor* FindEnumValueByName(const std::string& name) const;
}
- Reflection 类介绍
- Reflection接口类,主要提供了动态读写消息字段的接口,对消息对象的自动读写主要通过该类完成。
- 提供方法来动态访问 / 修改message中的字段,对每种类型,Reflection都提供了一个单独的接口用于读写字段对应的值。
- 针对所有不同的field类型 FieldDescriptor::TYPE_* ,需要使用不同的 Get*() / Set*() / Add*() 接口;
- repeated类型需要使用 GetRepeated*() / SetRepeated*() 接口,不可以和非repeated类型接口混用;
- message对象只可以被由它自身的 reflection(message.GetReflection()) 来操作;
- 类中还包含了访问 / 修改未知字段的方法。
- 类定义在 google 提供的 message.h 中。
- UnknownFieldSet 类介绍
- UnknownFieldSet 包含在分析消息时遇到但未由其类型定义的所有字段。
- 若要将 UnknownFieldSet 附加到任何消息,请调用 Reflection::GetUnknownFields()。
- 类定义在 unknown_field_set.h 中。
class PROTOBUF_EXPORT UnknownFieldSet {
inline void Clear();
void ClearAndFreeMemory();
inline bool empty() const;
inline int field_count() const;
inline const UnknownField& field(int index) const;
inline UnknownField* mutable_field(int index);
// Adding fields ---------------------------------------------------
void AddVarint(int number, uint64_t value);
void AddFixed32(int number, uint32_t value);
void AddFixed64(int number, uint64_t value);
void AddLengthDelimited(int number, const std::string& value);
std::string* AddLengthDelimited(int number);
UnknownFieldSet* AddGroup(int number);
// Parsing helpers -------------------------------------------------
// These work exactly like the similarly-named methods of Message.
bool MergeFromCodedStream(io::CodedInputStream* input);
bool ParseFromCodedStream(io::CodedInputStream* input);
bool ParseFromZeroCopyStream(io::ZeroCopyInputStream* input);
bool ParseFromArray(const void* data, int size);
inline bool ParseFromString(const std::string& data)
{
return ParseFromArray(data.data(), static_cast<int>(data.size()));
}
// Serialization.
bool SerializeToString(std::string* output) const;
bool SerializeToCodedStream(io::CodedOutputStream* output) const;
static const UnknownFieldSet& default_instance();
};
- UnknownField 类介绍
- 表示未知字段集中的一个字段。
- 类定义在 unknown_field_set.h 中。
class PROTOBUF_EXPORT UnknownField {
public:
enum Type {
TYPE_VARINT, // 打印变长整数的值
TYPE_FIXED32, // 打印32位固定整数的值
TYPE_FIXED64, // 打印64位固定整数的值
TYPE_LENGTH_DELIMITED, // 打印长度限定类型的值
TYPE_GROUP // 表示未知字段的分组类型(旧版中存在分组概念,较新版不推荐)
};
inline int number() const;
inline Type type() const;
// Accessors -------------------------------------------------------
// Each method works only for UnknownFields of the corresponding type.
inline uint64_t varint() const;
inline uint32_t fixed32() const;
inline uint64_t fixed64() const;
inline const std::string& length_delimited() const;
inline const UnknownFieldSet& group() const;
inline void set_varint(uint64_t value);
inline void set_fixed32(uint32_t value);
inline void set_fixed64(uint64_t value);
inline void set_length_delimited(const std::string& value);
inline std::string* mutable_length_delimited();
inline UnknownFieldSet* mutable_group();
};
验证未知字段
- 保留字段 reserved代码实现:
client代码实现
// c_contacts.proto
syntax = "proto3";
package c_contacts;
// 联系?
message PeopleInfo {
string name = 1; // 姓名
int32 age = 2; // 年龄
message Phone {
string number = 1; // 电话号码
}
repeated Phone phone = 3; // 电话
}
// 通讯录
message Contacts {
repeated PeopleInfo contacts = 1;
}
// client.cc
#include <iostream>
#include <fstream>
#include "c_contacts.pb.h"
using std::endl;
using std::cin;
using std::cout;
using std::cerr;
using namespace c_contacts;
using namespace google::protobuf;
/**
* 打印联系?列表
*/
void PrintfContacts(const Contacts& contacts) {
for (int i = 0; i < contacts.contacts_size(); ++i) {
const PeopleInfo& people = contacts.contacts(i);
cout << "------------联系?" << i+1 << "------------" << endl;
cout << "联系?姓名:" << people.name() << endl;
cout << "联系?年龄:" << people.age() << endl;
int j = 1;
for (const PeopleInfo_Phone& phone : people.phone()) {
cout << "联系?电话" << j++ << ": " << phone.number() << endl;
}
}
}
int main() {
Contacts contacts;
// 先读取已存在的 contacts
std::fstream input("../contacts.bin", std::ios::in | std::ios::binary);
if (!contacts.ParseFromIstream(&input)) {
cerr << "Failed to parse contacts." << endl;
input.close();
return -1;
}
// 打印 contacts
PrintfContacts(contacts);
input.close();
return 0;
}
server代码实现
// s_contacts.proto
syntax = "proto3";
package s_contacts;
// 联系?
message PeopleInfo {
reserved 2;
string name = 1; // 姓名
// 修改掉 age , 添加 birthday
// int32 age = 2; // 年龄
// int32 birthday = 2; -- 用了客户端的2号(age)是不可以的
/*
因为 Protocol Buffers 使用字段编号来标识消息中的字段,而不是字
段的名称。在读取数据时,解析器会根据字段编号来识别并映射到相应的字段。
*/
int32 birthday = 4; // 年龄
message Phone
{
string number = 1; // 电话号码
}
repeated Phone phone = 3; // 电话
}
// 通讯录
message Contacts
{
repeated PeopleInfo contacts = 1;
}
// server.cc
#include <iostream>
#include <fstream>
#include <string>
#include "s_contacts.pb.h"
using std::endl;
using std::cin;
using std::cout;
using std::cerr;
using namespace s_contacts;
/**
* 新增联系?
*/
void AddPeopleInfo(PeopleInfo *people_info_ptr) {
cout << "-------------新增联系?-------------" << endl;
cout << "请输?联系?姓名: ";
std::string name;
getline(cin, name);
people_info_ptr->set_name(name);
cout << "请输?联系?生日: ";
int birthday;
cin >> birthday;
people_info_ptr->set_birthday(birthday);
cin.ignore(256, '\n');
for(int i = 1; ; i++) {
cout << "请输?联系?电话" << i << "(只输?回?完成电话新增): ";
std::string number;
getline(cin, number);
if (number.empty()) {
break;
}
PeopleInfo_Phone* phone = people_info_ptr->add_phone();
phone->set_number(number);
}
cout << "-----------添加联系?成功-----------" << endl;
}
int main() {
Contacts contacts;
// 先读取已存在的 contacts
std::fstream input("../contacts.bin", std::ios::in | std::ios::binary);
if (!input) {
cout << "contacts.bin not found. Creating a new file." << endl;
} else if (!contacts.ParseFromIstream(&input)) {
cerr << "Failed to parse contacts." << endl;
input.close();
return -1;
}
// 新增?个联系?
AddPeopleInfo(contacts.add_contacts());
// 向磁盘?件写?新的 contacts
std::fstream output("../contacts.bin", std::ios::out | std::ios::trunc | std::ios::binary);
if (!contacts.SerializeToOstream(&output)) {
cerr << "Failed to write contacts." << endl;
input.close();
output.close();
return -1;
}
input.close();
output.close();
return 0;
}
- 验证未知字段(打印):
cat /usr/local/protobuf/include/google/protobuf/unknown_field_set.h
#include <iostream>
#include <fstream>
#include "c_contacts.pb.h"
#include <google/protobuf/unknown_field_set.h>
using std::endl;
using std::cin;
using std::cout;
using std::cerr;
using namespace c_contacts;
using namespace google::protobuf;
/**
* 打印联系?列表
*/
void PrintfContacts(const Contacts& contacts) {
for (int i = 0; i < contacts.contacts_size(); ++i) {
const PeopleInfo& people = contacts.contacts(i);
cout << "------------联系?" << i+1 << "------------" << endl;
cout << "联系?姓名:" << people.name() << endl;
cout << "联系?年龄:" << people.age() << endl;
int j = 1;
for (const PeopleInfo_Phone& phone : people.phone())
{
cout << "联系?电话" << j++ << ": " << phone.number() << endl;
}
// 打印未知字段
const Reflection* reflection = PeopleInfo::GetReflection();
const UnknownFieldSet& unknowSet = reflection->GetUnknownFields(people);
for(int j = 0; j < unknowSet.field_count(); j++)
{
const UnknownField& unknown_field = unknowSet.field(j);
cout << "未知字段" << j + 1 << ": " << " 编号:" << unknown_field.number();
switch(unknown_field.type())
{
case UnknownField::Type::TYPE_VARINT:
cout << " 值:" << unknown_field.varint() << endl;
break;
case UnknownField::Type::TYPE_FIXED32:
cout << " 值:" << unknown_field.fixed32() << endl;
break;
case UnknownField::Type::TYPE_FIXED64:
cout << " 值:" << unknown_field.fixed64() << endl;
break;
case UnknownField::Type::TYPE_LENGTH_DELIMITED:
cout << " 值:" << unknown_field.length_delimited() << endl;
break;
}
}
}
}
int main() {
Contacts contacts;
// 先读取已存在的 contacts
std::fstream input("../contacts.bin", std::ios::in | std::ios::binary);
if (!contacts.ParseFromIstream(&input)) {
cerr << "Failed to parse contacts." << endl;
input.close();
return -1;
}
// 打印 contacts
PrintfContacts(contacts);
input.close();
return 0;
}
[qcr@VM-16-6-centos client]$ ./client
------------联系?1------------
联系?姓名:你好
联系?年龄:0
联系?电话1: 123456789
未知字段1: 编号:4 值:1030
未知字段 - 函数 API 小结
1.获取消息类型 PeopleInfo 的反射信息, 反射信息将用于后续获取未知字段的信息
const Reflection* reflection = PeopleInfo::GetReflection();
// 函数声明 - 返回指向该反射信息的指针
static const google::protobuf::Reflection* GetReflection();
2.通过反射信息获取消息对象 people 中的未知字段集合
const UnknownFieldSet& unknowSet = reflection->GetUnknownFields(people);
// 函数声明 - 返回一个 UnknownFieldSet 对象,其中包含了所有未知字段的信息
UnknownFieldSet& GetUnknownFields(const Message& message) const;
3.获取 UnknownFieldSet 对象中未知字段的数量
for(int j = 0; j < unknowSet.field_count(); j++);
// 函数声明 - 返回整数, 未知字段个数
int field_count() const;
4.获取当前迭代的未知字段
const UnknownField& unknown_field = unknowSet.field(j);
// 函数声明 - 返回对应的 UnknownField 对象的引用
const UnknownField& field(int index) const;
5.获取当前迭代的未知字段的编号
cout << "未知字段" << j + 1 << ": " << " 编号:" << unknown_field.number();
// 函数声明 - 返回整数, 未知字段编号
int number() const;
6.用于获取当前迭代的未知字段的类型 - 因为是enum枚举
switch(unknown_field.type());
// 函数声明 - 返回枚举值, 未知字段类型。
Type type() const;
- TYPE_VARINT : 变长整数
- TYPE_FIXED32 : 32位固定整数
- TYPE_FIXED64 : 64位固定整数
- TYPE_LENGTH_DELIMITED : 长度限定类型
7.未知字段中获取特定类型的值
inline uint64_t varint() const;
inline uint32_t fixed32() const;
inline uint64_t fixed64() const;
inline const std::string& length_delimited() const;
前后兼容性
??根据上述的例子可以得出,pb是具有向前兼容的。增加了 “生日” 属性的 service 称为“新模块”;未做变动的 client 称为 “老模块”。
- 向前兼容: 老模块能够正确识别新模块生成或发出的协议。这时新增加的 “生日” 属性会被当作未知字段
(pb 3.5版本及之后)。 - 向后兼容: 新模块也能够正确识别?模块?成或发出的协议。
- 前后兼容的作用: 当我们维护?个很庞大的分布式系统时,由于我们无法同时升级所有模块,为了保证在升级过程中,整个系统能够尽可能不受影响,就需要尽量保证通讯协议的
向后兼容或向前兼容。
选项 option
??.proto 文件中可以声明许多选项,使用 option 标注。选项能影响 proto 编译器的某些处理方式。
选项分类
??选项的完整列表在google/protobuf/descriptor.proto中定义。
syntax = "proto3"; // descriptor.proto 使? proto3 语法版本
message FileOptions { ... } // ?件选项 定义在 FileOptions 消息中
message MessageOptions { ... } // 消息类型选项 定义在 MessageOptions 消息中
message FieldOptions { ... } // 消息字段选项 定义在 FieldOptions 消息中
message OneofOptions { ... } // oneof字段选项 定义在 OneofOptions 消息中
message EnumOptions { ... } // 枚举类型选项 定义在 EnumOptions 消息中
message EnumValueOptions { .. } // 枚举值选项 定义在 EnumValueOptions 消息中
message ServiceOptions { ... } // 服务选项 定义在 ServiceOptions 消息中
message MethodOptions { ... } // 服务?法选项 定义在 MethodOptions 消息中
......
??由此可见,选项分为 文件级、消息级、字段级 等等,但并没有?种选项能作用于所有的类型。
常用选项列举
optimize_for: 该选项为文件选项,可以设置 protoc 编译器的优化级别,分别为SPEED、
CODE_SIZE、LITE_RUNTIME。受该选项影响,设置不同的优化级别,编译 .proto 文件后生
成的代码内容不同。SPEED: protoc 编译器将生成的代码是高度优化的,代码运行效率高,但是由此生成的代码编译后会占用更多的空间。SPEED是默认选项。CODE_SIZE: proto 编译器将生成最少的类,会占用更少的空间,是依赖基于反射的代码来实现序列化、反序列化和各种其他操作。但和SPEED恰恰相反,它的代码运行效率较低。这种方式适合用在包含大量的.proto?件,但并不盲目追求速度的应用中。LITE_RUNTIME: 生成的代码执行效率高,同时生成代码编译后的所占用的空间也是非常少。这是以牺牲Protocol Buffer提供的反射功能为代价的,仅仅提供 encoding+序列化 功能,所以我们在链接 BP 库时仅需链接 libprotobuf-lite ,而非 libprotobuf 。这种模式通常用于资源有限的平台,例如移动?机平台中。
option optimize_for = LITE_RUNTIME;
??注:
LITE_RUNTIME选项主要用于提供 Protocol Buffers 数据的 序列化(编码) 和 反列化(解码) 操作,而不包括一些在标准运行时环境中提供的其他功能。
??allow_alias :允许将相同的常量值分配给不同的枚举常量,用来定义别名。
enum PhoneType {
option allow_alias = true;
MP = 0;
TEL = 1;
LANDLINE = 1; // 若不加 option allow_alias = true; 这??会编译报错
}
ProtoBuf 与 JSON 的性能对比
编解码性能:ProtoBuf 的编码解码性能,比JSON高出2 - 4倍。内存占用:ProtoBuf的内存占用只有JSON的1/2左右。
并不全面,是大致的测试。
| 序列化协议 | 通用性 | 格式 | 可读性 | 序列化大小 | 序列化性能 | 适用场景 |
|---|---|---|---|---|---|---|
| JSON | 通? (json、xml已成为多种行业标准的编写工具) | 文本格式 | 好 | 轻量(使用键值对方式,压缩了?定的数据空间) | 中 | web项目、因为浏览器对于json数据支持非常好,有很多内建的函数支持 |
| XML | 通用 | 文本格式 | 好 | 重量(数据冗余,因为需要成对的闭合标签) | 低 | XML 作为?种扩展标记语?,衍生出了HTML、RDF/RDFS,它强调数据结构化的能力和可读性 |
| ProtoBuf | 独立(Protobuf只是Google公司内部的工具) | ?进制格式 | 差(只能反序列化后得到真正可读的数据) | 轻量(比JSON更轻量,传输起来带宽和速度会有优化) | 高 | 适合高性能,对响应速度有要求的数据传输场景Protobuf比XML、JSON 更小、更快 |
小结:
- XML、JSON、ProtoBuf 都具有数据结构化和数据序列化的能力。
- XML、JSON 更注重数据结构化,关注可读性和语义表达能力。ProtoBuf 更注重数据序列化,关注效率、空间、速度,可读性差,语义表达能力不足,为保证极致的效率,会舍弃?部分元信息。
- ProtoBuf 的应用场景更为明确,XML、JSON 的应用场景更为丰富。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 黑客帝国(代码雨)
- 很抱歉,Midjourney,但Leonardo AI的图像指导暂时还无人能及…至少目前是这样
- FPGA分频电路设计(2)
- Speckle+IFC.js 结合 ,碰出火花的产品
- 北京互联网医院|互联网医院定制体现数字化优势
- 新火种极绘AI重磅亮相2023广州国际人工智能展览会
- 软考高项论文范文 | 进度管理
- 东方甄选“去董化”舆情危机处置分析
- xilinx入门操作
- 作为一个新人怎么快速建立自己的网站呢