C++基础语法和用法
文章目录
1.hello world
#include <iostream>
using namespace std;
int main()
{
cout << "hello world" << endl;
return 0;
}
这便是C++的hello world
2.引入namespace(命名空间/域问题)
在C/C++中,变量、函数和后面要学到的类都是大量存在的,这些变量、函数和类的名称将都存
在于全局作用域中,可能会导致很多冲突。使用命名空间的目的是对标识符的名称进行本地化,
以避免命名冲突或名字污染,namespace关键字的出现就是针对这种问题的。
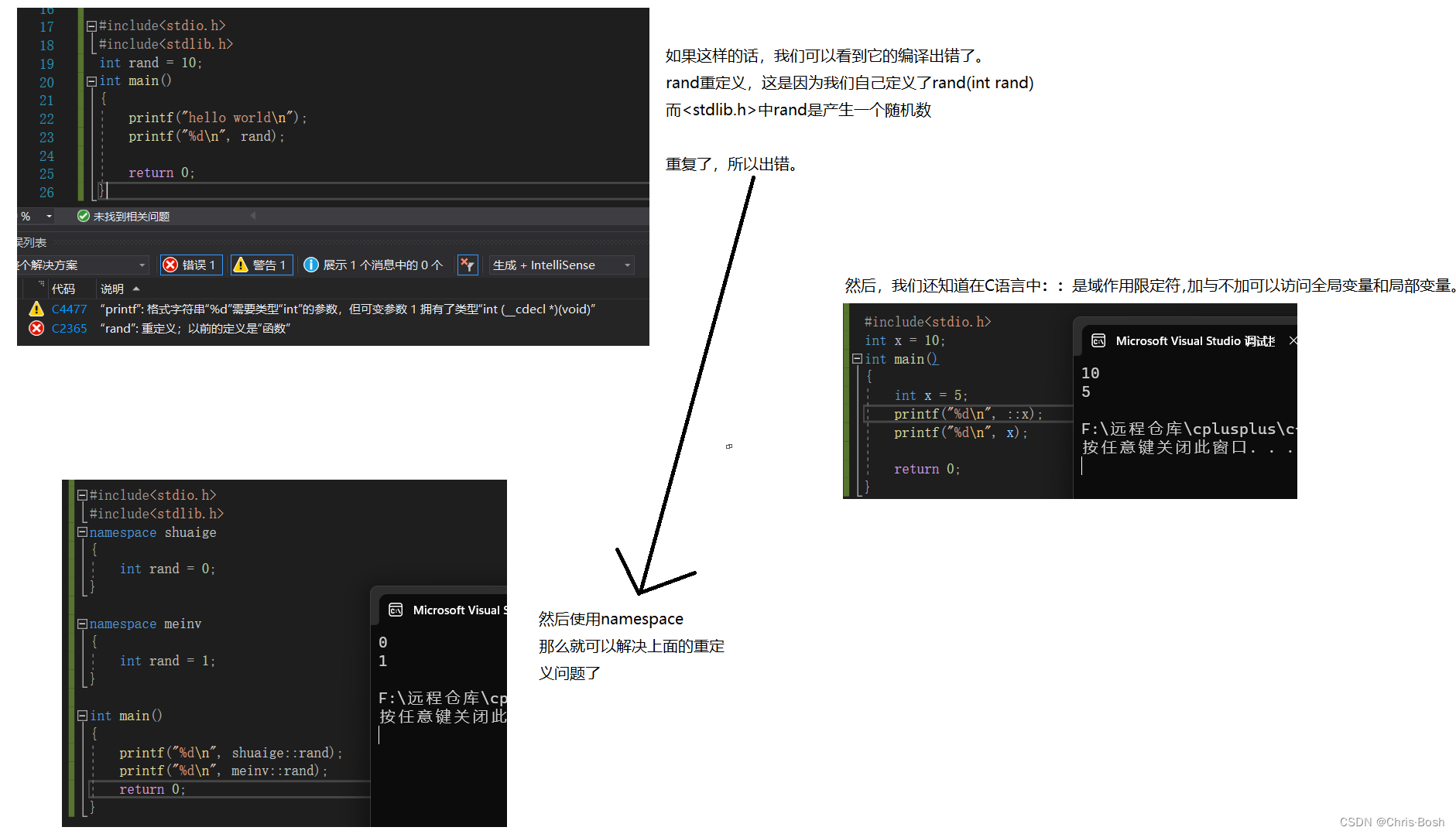
当namespace后的空间的名字一样时,C++会帮我们合并起来。
namespace shuaige
{
int rand = 0;
}
namespace shuaige
{
int x = 1;
}
这样就会合并!
除此之外,namespace中还可以写函数,结构体等。
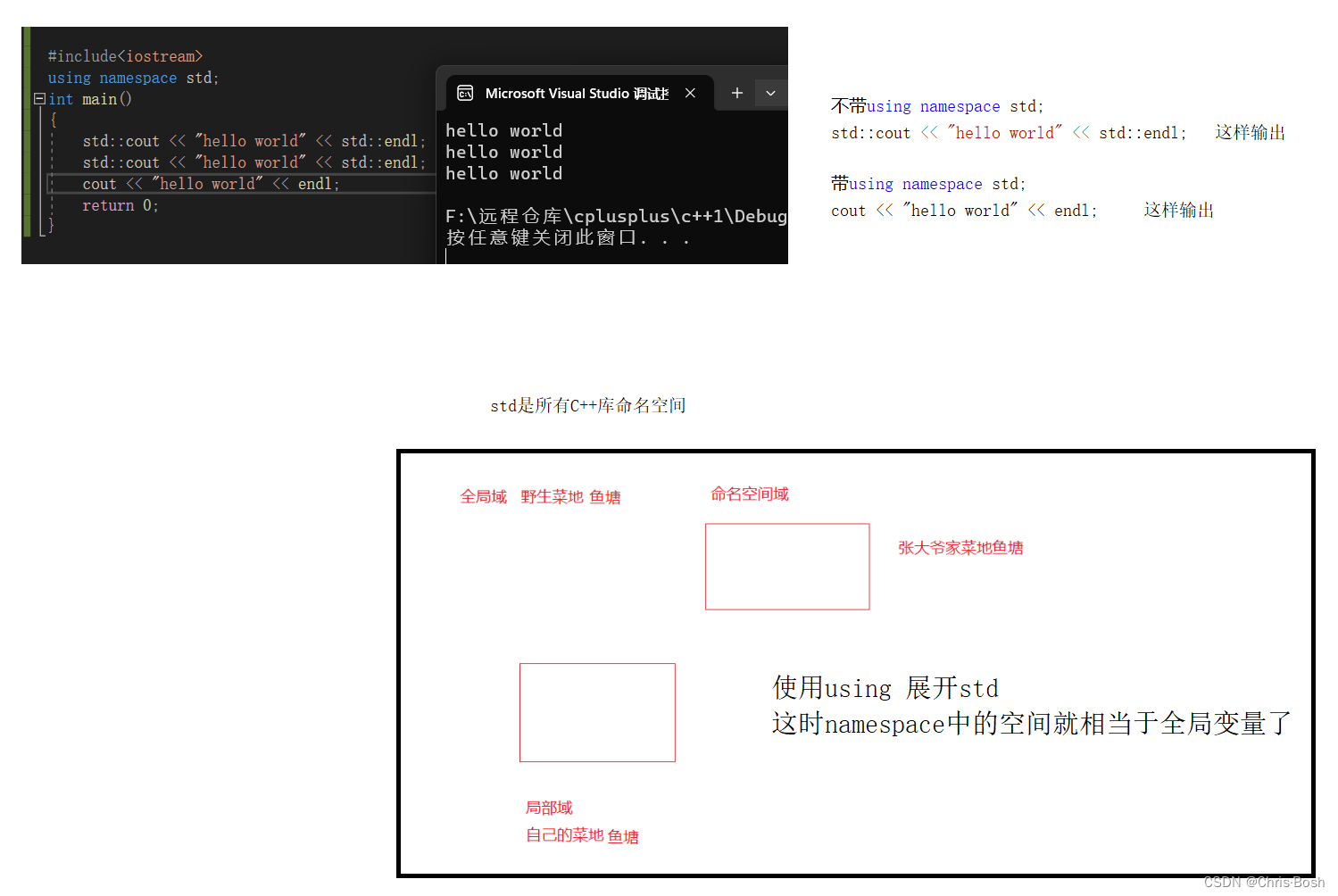
对于命名空间我们一般不建议全部展开,在大型项目时我们一般用什么展开什么,大致如下:
#include<iostream>
using std::cout;
using std::endl;
namespace shuaige
{
namespace zs
{
void push()
{
cout<<"zs"z<<endl;
}
}
int main()
{
int i = 0;
std::cin >> i;
cout << "xxxxxx" << endl;
cout << "xxxxxx" << endl;
bit::zs::Push();
return 0;
}
3.输入输出

4.缺省参数/默认参数
①第一种
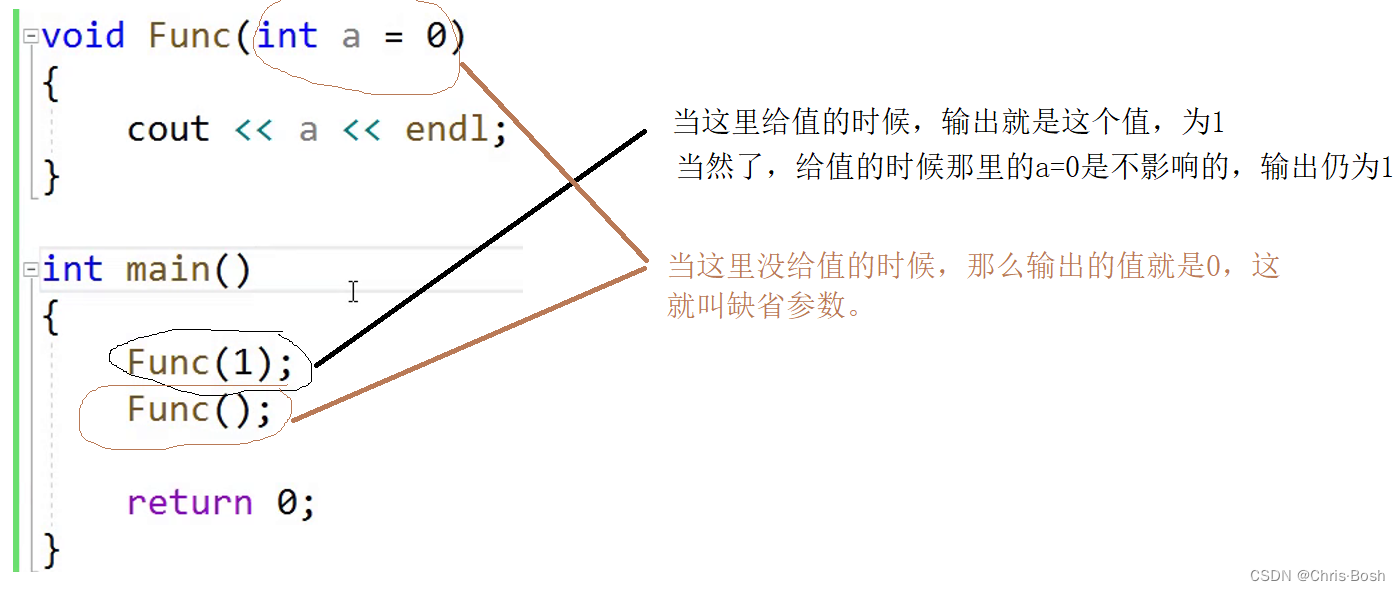
②第二种:全缺省
可以这样花着玩,但是不能跳跃着传参。
比如,第一个不传二三传。一三传,第二个不传!
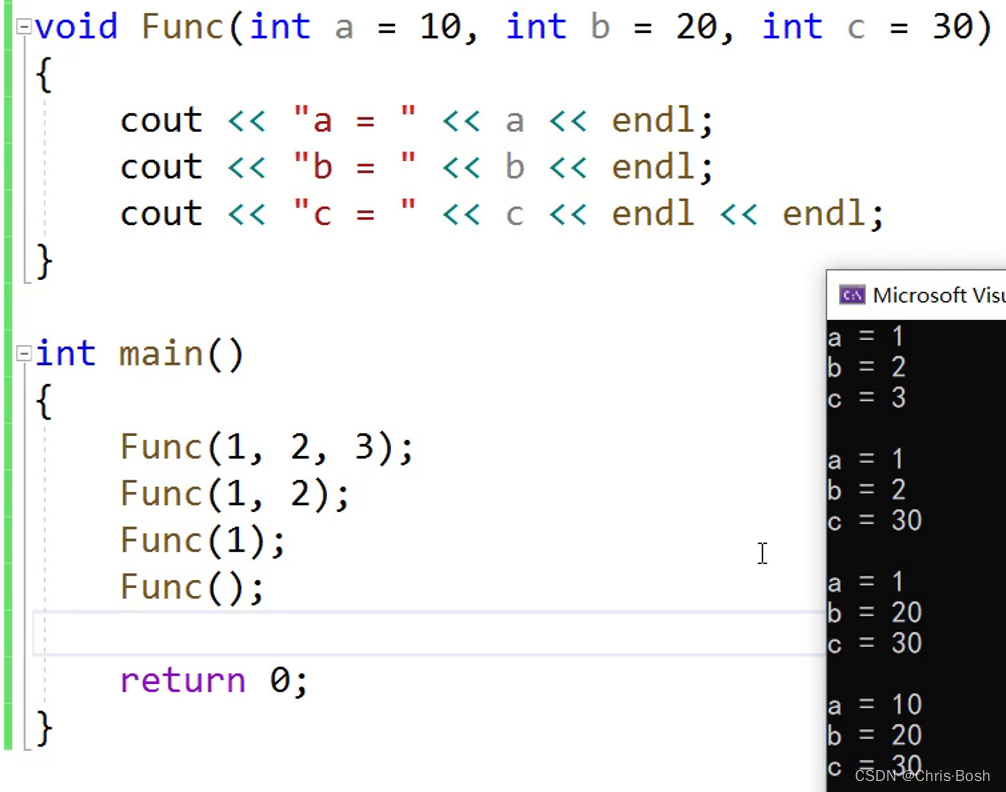
③第三种:半缺省(部分缺省)
其必须从右往左连续给,也是不能跳跃

④应用场景举例:

这样就可以编译成功!
5.函数重载
在学Cpp之前学了一下JAVA的基础语法,JAVA里面也是有函数重载,感觉是一样的
CPP语言允许同名函数,要求:函数名相同,参数不同,构成函数重载
1、参数类型的不同
2、参数个数不同
3、参数顺序不同(本质还是类型不同)
应该很好理解,就举下面一个例子


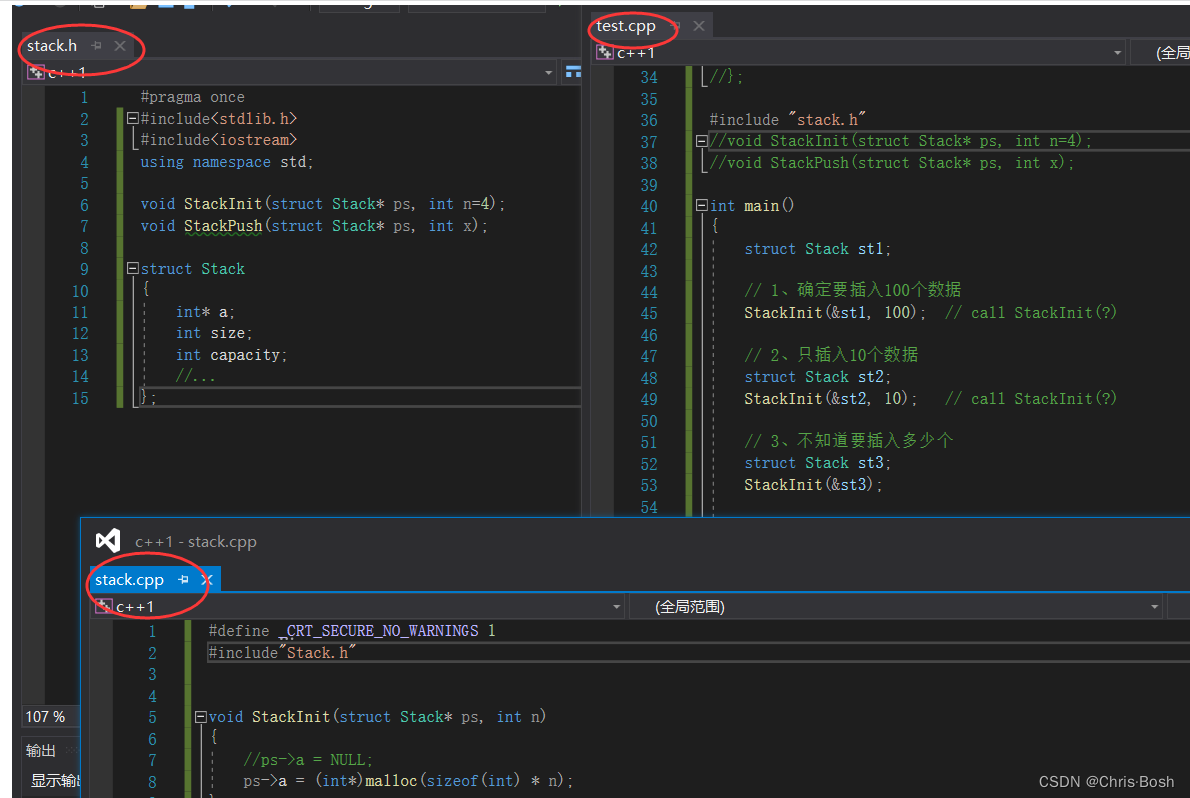
6.引用
引用的最基本用法如下:
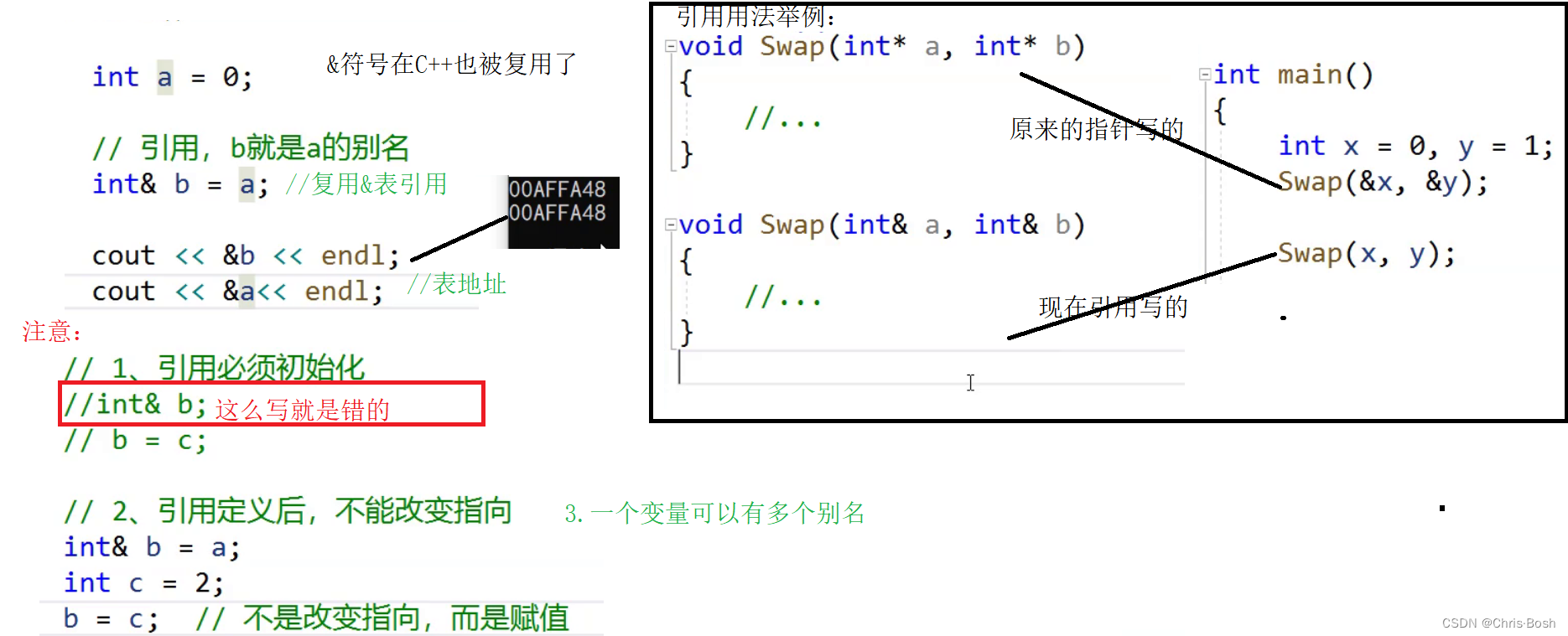
引用不能代替指针的应用场景:
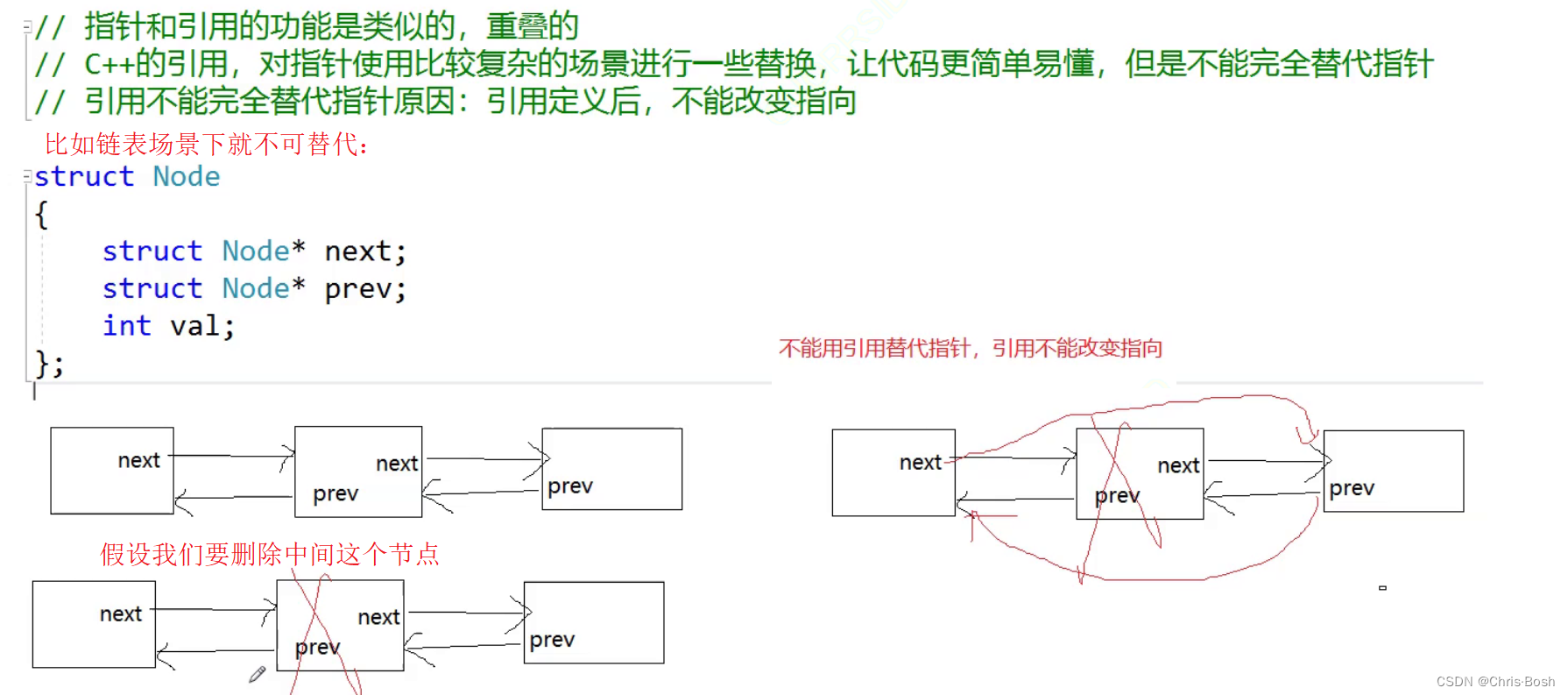
野引用和引用返回:
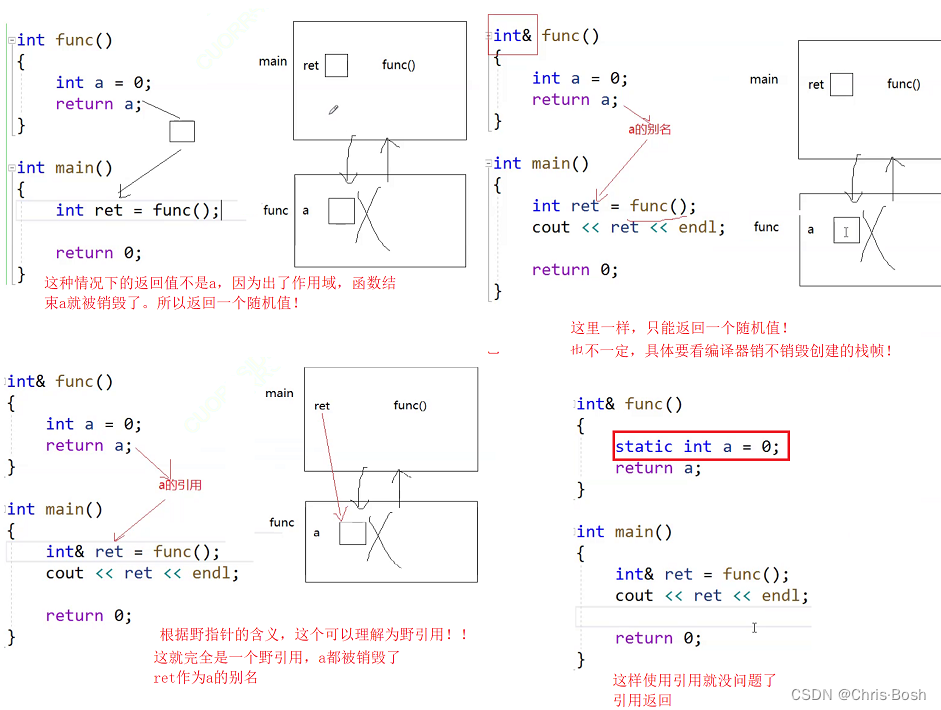
引用和指针的对比:
在语法上:
1.引用就是一个别名,不需要开辟新空间;指针是一个地址,需要开辟新空间存贮地址!
2.引用必须初始化;指针初步初始化无所谓。
3.引用不能改变指向;指针可以改变指向!
4.引用相对指针更安全,没有空引用,但是指针有NULL。野指针很容易出现,但是野引用不那么常见!
5.在sizeof中含义不同:引用结果为引用类型的大小,但指针始终是地址空间所占字节个数(32
位平台下占4个字节)。
6.引用自加即引用的实体增加1,指针自加即指针向后偏移一个类型的大小。
7.有多级指针,但是没有多级引用。
8.访问实体方式不同,指针需要显式解引用,引用编译器自己处理。
在底层上:
1.引用底层时用指针实现的,会在底层开空间。和语法上是背离的。
2.在最底层汇编的层面上,是没有引用的,都是指针!!!
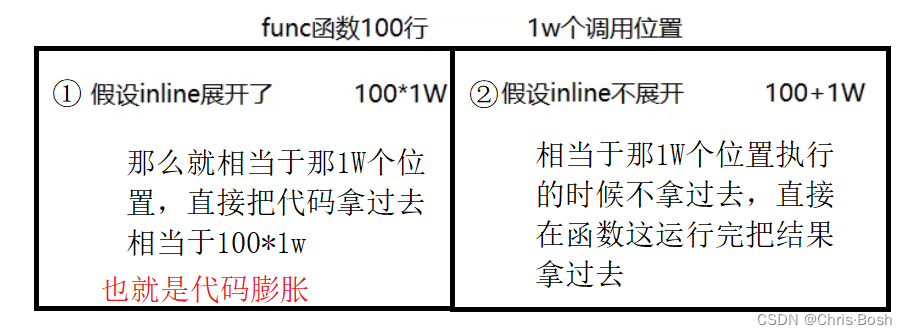
7.内联函数

但是内联函数也是有缺陷的!我们不能把所有函数都加上inline
如果全部使用内联函数,那么最后我们生成的可执行程序会非常大,这是不好的!!
inline是一种以空间(编译好的可执行程序)换时间的做法,如果编译器将函数当成内联函数处理,在编译阶段,会用函数体替换函数调用,缺陷:可能会使目标文件变大,优势:少了调用开销,提高程序运行效率。
8.auto关键字,基于范围的for循环,空指针NULL
8.1 auto
auto可以自动推导类型
int i=0;
auto k=i;//自动识别k是一个整数
auto p1=&i;//识别其是一个指针
auto *p2=&i;//这样本身定义了指针,对右边是有要求的
auto *p3=i;//这样写就错了,和上面做一个对比
auto& r=i;//复用 ,r是i的别名
使用场景:

注意: auto不能作为参数!auto也不能定义数组!不过现在auto可以作为返回值了。
但是不建议这样一直使用auto,因为如果有多层嵌套,我们很难推断出他到底是什么类型的值!
8.2 基于范围的for循环
auto还有基于范围的for循环:

int array[] = { 1, 2, 3, 4, 5 };
for (int i = 0; i < sizeof(array) / sizeof(array[0]); ++i)
array[i] *= 2;
for (int* p = array; p < array + sizeof(array)/ sizeof(array[0]); ++p)
cout << *p << endl;
其就和这个代码意思一样,用起来十分方便。遍历数组可以多用这个方法!!!
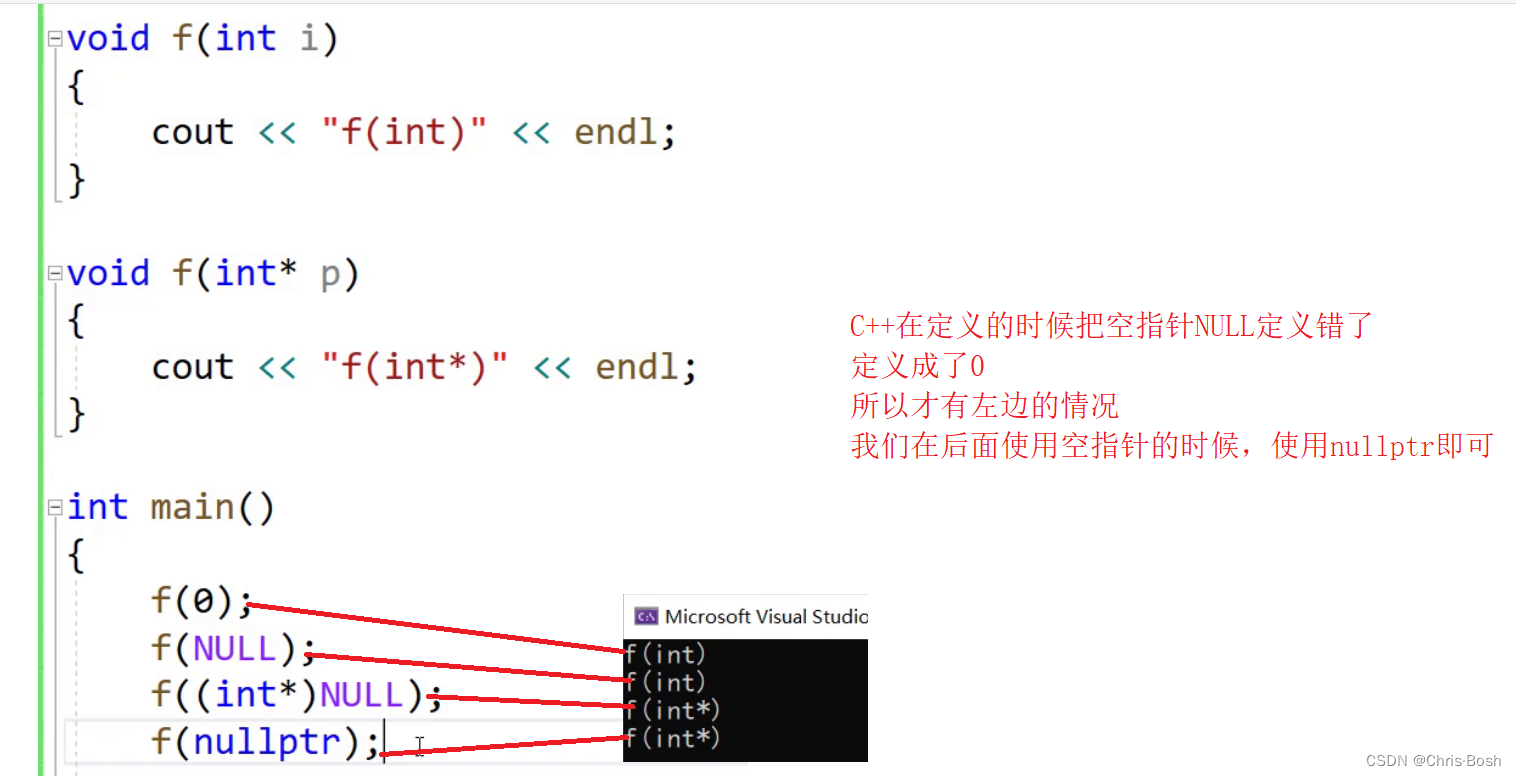
8.3 nullptr
C++空指针问题:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- pip 常用的国内镜像源
- 移动神器RAX3000M路由器变身家庭云之二:外网访问家庭云
- Groovy基本语法使用
- 计算机毕业设计 基于SpringBoot的高校物品捐赠管理系统的设计与实现 Java实战项目 附源码+文档+视频讲解
- Java中的序列化和反序列化:深入理解和实战
- Java Web基础
- UI走查+样式小技巧
- 【C语言】一.数据的存储(整数&&浮点数在内存中的存储||大小端||原码反码补码)
- 小程序必须要有后台吗?
- LWIP热插拔功能实现