性能优化(CPU优化技术)-ARM Neon详细介绍
本文主要介绍ARM Neon技术,包括SIMD技术、SIMT、ARM Neon的指令、寄存器、意图为读者提供对ARM Neon的一个整体理解。
🎬个人简介:一个全栈工程师的升级之路!
📋个人专栏:高性能(HPC)开发基础教程
🎀CSDN主页?发狂的小花
🌄人生秘诀:学习的本质就是极致重复!
目录
1 并行技术的几种方式
? ? ? ? 并行计算根据费林分类法,将指令流和数据流的几种不同的方式分成四种计算机类型:SISD、MISD、MIMD、SIMD。NVIDIA CUDA设计出SIMT技术区别于这四种。
1.2 SISD
????????SISD是单指令流单数据流(Single Instruction Single Data)的缩写,是一种计算机体系结构。在SISD中,所有的指令和数据都按照一定的顺序串行执行,即每条指令只处理一个操作数,且每个操作数只在一条指令中使用。
????????SISD的特点是简单、直观,但效率较低。因为所有指令和数据都必须按顺序执行,所以无法充分利用现代处理器的并行计算能力。不过,由于其实现相对简单,所以在一些简单的应用场景下仍然有一定的应用价值。
1.3 MIMD
????????MIMD是多指令流多数据流(Multiple Instruction Multiple Data)的缩写,是一种计算机体系结构。在MIMD中,可以同时有多条指令在不同的处理单元中并行执行,并且每个处理单元都可以同时处理多个数据。
????????与SISD和MISD相比,MIMD能够更好地利用现代处理器的并行计算能力,提高程序的执行效率。由于每个处理单元都可以独立地执行指令和处理数据,所以MIMD也被称为“真正并行”的计算机体系结构。
MIMD需要更复杂的控制逻辑来协调不同处理单元之间的操作,增加了实现难度。但是,随着多核处理器的普及和硬件技术的发展,MIMD已经成为现代高性能计算机的主要架构之一。
1.4 SIMD
1.4.1 概念和特点
????????SIMD是单指令流多数据流(Single Instruction Multiple Data)的缩写,是一种计算机体系结构。在SIMD中,所有的指令都按照一定的顺序串行执行,但是每个指令可以同时处理多个数据。
????????与SISD和MISD相比,SIMD能够更好地利用现代处理器的并行计算能力,提高程序的执行效率。由于每个指令可以同时处理多个数据,所以SIMD也被称为“向量化”的计算机体系结构。
????????SIMD需要更复杂的控制逻辑来协调不同数据之间的操作,增加了实现难度。但是,随着硬件技术的发展,SIMD已经成为现代高性能计算机、图形处理器和数字信号处理器等领域的主要架构之一。
1.4.2 产生的原因
????????许多程序需要处理大量的数据集,而且很多都是由少于32bits的位数来存储的。比如在视频、图形、图像处理中的8-bit像素数据;音频编码中的16-bit采样数据等。在诸如上述的情形中,很可能充斥着大量简单而重复的运算,且少有控制代码的出现。因此,SIMD就擅长为这类程序提供更高的性能。比如大量的数据集、2D、3D图像、视频、音频、色彩转换、流体力学、气象学、天体物理等。? ? ? ????????
1.5 MISD
????????MISD是多指令流单数据流(Multiple Instruction Single Data)的缩写,是一种计算机体系结构。在MISD中,指令和数据都按照一定的顺序串行执行,但是可以同时有多条指令在不同的处理单元中并行执行。
????????与SISD相比,MISD能够更好地利用现代处理器的并行计算能力,提高程序的执行效率。但是,由于指令和数据仍然必须按顺序执行,所以仍然存在一些限制。此外,MISD需要更复杂的控制逻辑来协调不同处理单元之间的操作,增加了实现难度
1.6?SIMT
????????SIMT是单指令流多线程(Single Instruction, Multiple Threads)的缩写,是一种并行计算模型。在SIMT中,所有的线程都执行相同的指令,但是每个线程可以处理不同的数据。
????????与SIMD相比,SIMT能够更好地利用现代处理器的并行计算能力,提高程序的执行效率。由于每个线程可以独立地处理不同的数据,所以SIMT也被称为“线程化”的计算机体系结构。
????????SIMT需要更复杂的控制逻辑来协调不同线程之间的操作,增加了实现难度。但是,随着多核处理器和硬件技术的发展,SIMT已经成为现代高性能计算机、图形处理器和游戏机等领域的主要架构之一。
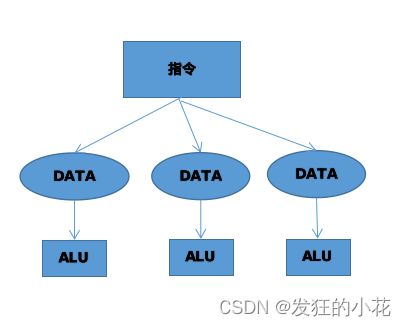
????????类似 CPU 上的多线程,所有的核心各有各的执行单元,数据不同,执行的命令是相同的。多个线程各有各的处理单元,和 SIMD 共用一个 ALU 不同。
 ?
?
????????
2?NEON介绍
? ? ? ? ?ARM NEON是ARM推出的一种CPU扩展技术SIMD,一般在Cortex-A应用处理器上和少量的Cortex-R处理器上支持Neon技术,使用SIMD方式可以在一定程度上提升CPU的运算效率。
? ? ? ? 由于现代处理器的寄存器、ALU都是为了32位或者64为设计的,但是这些大量的数据基本都是8位和16位的,因此如果每次执行一个数据就会很浪费寄存器的宽度,由此引入了Neon 的SIMD技术,通过一条指令控制同时处理多个数据来提高效率,这样就提高了寄存器和ALU的使用效率。
2.1?ARM Neon 特点
? ? ? ? (1)一般每个ARM核都有一个NEON单元,CPU与NEON共用一个ALU,相对于SIMT是每个核都有一个ALU。
? ? ? ? (2)NEON技术最早出现在ARMv7上,ARMv7有16个128位寄存器(Q),32个64位寄存器(D)。ARMv8有32个128位寄存器(Q),64个64位寄存器(D),Q寄存器物理上不存在,但是逻辑上存在,其核心是D寄存器组成的。因此优化时注意,Q寄存器和D寄存器的不能重复使用。
? ? ? ? (3)ARM NEON技术是一种SIMD,即单指令多数据技术,是区别于SISD和SIMT的不同的技术,对于提高CPU运行效率,有很大的作用。
? ? ? ?(4) NEON技术可以用于多线程,并且共享常规CPU的内存和cache,Cache一般有三级Cache L1、L2、L3。
2.2 ARM Neon 数据类型
2.2.1?Neon 数据类型的命名格式
? ? ? ??(1)?<type><size>x<number_of_lanes>_t
 ?
?
? ? ? ? (2)<type><size>x<number_of_lanes>x<length_of_array>_t
? ? ? ? ? ? ?例如 float32x4x2_t u1 表示定义两个128位向量寄存器数据 ,用两个128位寄存器存储,
? ? ? ? ? ? ? 每个寄存器存储4个float类型数据。
? ? ? ? ? ? ? ?内部的构造是:
? ? ? ? ? ? ? ? ? ? ? ? struct float32x4x2_t
? ? ? ? ? ? ? ? ? ? ? ? {
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? float32x4_t val[2];
? ? ? ? ? ? ? ? ? ? ? ? }float32x4x2_t;
? ? ? ? ? ? ? ?取每个寄存器数据的格式:
? ? ? ? ? ? ? ? ? ? ? ? u1.val[0]; u1.val[1];
2.2.2 支持的数据类型? ? ??
? ? ? ?对64位D寄存器或者是128位Q寄存器拆分,比如int8x16_t指的是int8类型的16个数据存储在一个128位Q寄存器中,Q寄存器是虚拟的,真实并不存在;int8x8_t指的是int8类型的8个数据存储在一个64位D寄存器中。
? ? ? ? 主要支持的数据类型如下:
 ?
?
????????注:F16不适用于数据处理运算,只用于数据转换,仅用于实现半精度体系结构扩展的系统。
多项式算术在实现某些加密、数据完整性算法中非常有用。
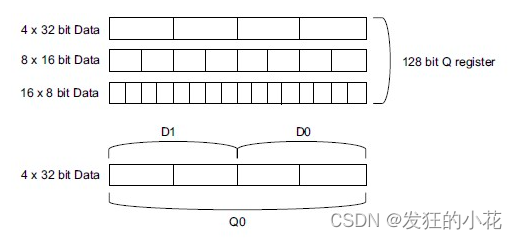
? ? ? 一个向量寄存器存储数据的格式如下图,通过一次处理多个数据,可以提高效率大概10倍左右,由于寄存器之间有专门的通道,处理的速度极快,因此使用SIMD的编程方式可以使得程序的性能变得优秀。
 ?
?
2.3 ARM Neon 指令
ARM Neon 指令集可以分为以下几类:
????????1. 加载和存储指令:用于从内存中加载数据或将数据存储到内存中。包括单精度浮点数的加载和存储指令,以及双精度浮点数的加载和存储指令。
????????2. 算术运算指令:用于执行各种算术运算,包括加法、减法、乘法、除法等。这些指令可以对单精度浮点数和整数进行操作,也可以对双精度浮点数进行操作。
????????3. 逻辑运算指令:用于执行各种逻辑运算,包括与、或、非等。这些指令可以对单精度浮点数和整数进行操作,也可以对双精度浮点数进行操作。
????????4. 比较指令:用于比较两个值的大小关系,包括相等、不等、大于、小于等。这些指令可以对单精度浮点数和整数进行操作,也可以对双精度浮点数进行操作。
????????5. 移位指令:用于将一个值向左或向右移动指定的位数。这些指令可以对单精度浮点数和整数进行操作,也可以对双精度浮点数进行操作。
????????6. 向量数据处理指令:用于对多个数据进行并行处理,包括向量加法、向量减法、向量乘法等。这些指令可以对单精度浮点数和整数进行操作,也可以对双精度浮点数进行操作。
 ?
?
2.4 Neon 寄存器
2.4.1 Neon一般的执行流程
 ?
?
? ? ? ? 第一步:从内存load数据到vector寄存器
? ? ? ? 第二步:使用Intrinsic指令或者汇编在ALU执行相应的运算
? ? ? ? 第三步:将执行后的结果save到内存
2.4.2 Neon 寄存器
?ARMv7上寄存器关系:
????????
 ?
?
????????
? ? ARMv7上寄存器的组合:(一个Q寄存器对应2个D寄存器)
- 16×128-bit寄存器(Q0-Q15);
- 或32×64-bit寄存器(D0-D31)
- 或上述寄存器的组合。
? ? 映射关系:
- D<2n> 映射到 Q?的最低有效半部;
- D<2n+1> 映射到 Q?的最高有效半部;
? ? Neon寄存器存储数据的几种形式:
 ?
?
2.5 Neon数据处理指令分类
? ? ? ? 一般分为普通指令、长指令、宽指令、窄指令、饱和指令等。
????????普通指令(Normal instructions?)
????????可以对任意类型的向量进行操作,并生成与操作数向量相同大小和通常相同类型的结果向量。
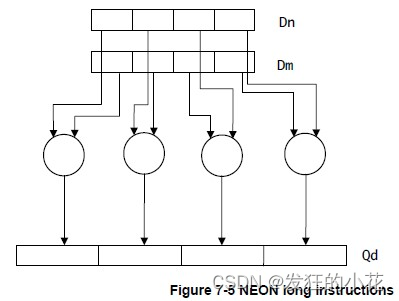
????????长指令(Long instructions)
????????对双字向量操作数进行操作,并生成四倍长字向量结果。结果元素的宽度通常是操作数的两倍,并且类型相同。长指令使用在指令中添加字母L来指定。
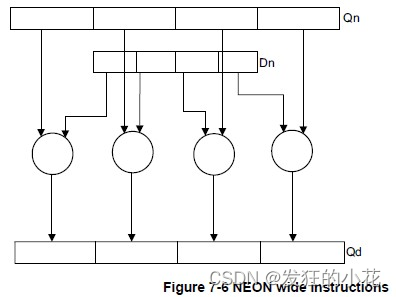
????????宽指令(Wide instructions)
????????对一个双字向量操作数和一个四倍长字向量操作数进行操作,生成四倍长字向量结果。结果元素和第一个操作数都是第二个操作数的元素宽度的两倍。宽指令在指令中添加字母W来指定。
????????窄指令(Narrow instructions)
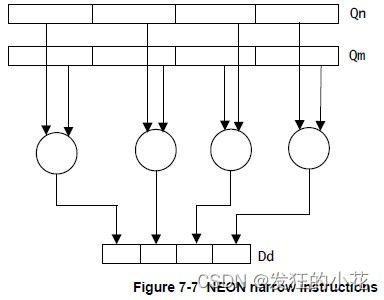
????????对四倍长字向量操作数进行操作,并生成双字向量结果。结果元素的宽度通常是操作数元素宽度的一半。窄指令使用在指令中添加字母N来指定。
????????饱和变体(Saturating variants)
????????在ARM中,饱和算法如下:
????????????????对于有符号饱和运算,如果结果小于 -2^n,则返回的结果将为 -2^n;
????????????????对于无符号饱和运算,如果整个结果将是负值,那么返回的结果是 0;如果结果大于 2^n - 1,则返回的结果将为 2^n - 1;
????????????????在NEON中,饱和算法通过在V和指令助记符之间使用Q前缀来指定饱和指令,原理与上述内容相同。
? ? ? ? 来自官方文档的一些参考说明图:
 ?
?
 ?
?
 ?
?
3 一般使用ARM Neon优化的几种方式
? ? ? ? a.通过使用编译选项增加-O3 和针对Neon的优化编译选项,对于一些简单的运算,让编译器
? ? ? ? ? ?自动优化,效果会出奇的好
? ? ? ? c.通过使用一些已经优化好的ARM Neon库来加速程序
? ? ? ? d.使用Intrinsic Instruction 来编写SIMD相关的代码优化,编写该类程序时需要注意不同的指
? ? ? ? ? ?令速度有所不同,选择合适的指令也是优化的一个难点,同时要对数据进行一个预取,利用
? ? ? ? ? ?cache的高性能来提高效率,也要注意不要做超过寄存器长度的处理。
? ? ? ? e.使用ARM Neon汇编来提高运行效率
🌈我的分享也就到此结束啦🌈
如果我的分享也能对你有帮助,那就太好了!
若有不足,还请大家多多指正,我们一起学习交流!
📢未来的富豪们:点赞👍→收藏?→关注🔍,如果能评论下就太惊喜了!
感谢大家的观看和支持!最后,?祝愿大家每天有钱赚!!!下一节将介绍如何在一个Android手机进行ARM Neon的优化测试,并且包括Intrinsic指令的使用。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 在EasyBoss ERP上查Shopee产品表现,数据更全、处理更高效!
- 基于python的生物多样性分析软件
- 圣诞树代码
- 第二十一章 网络编程
- Linux下的HTTP代理服务器Squid的配置和使用
- 大流量下唯一订单号的设计
- 百万级监控指标的秒级采集与处理
- 能源互联网:照亮我们绿色、智能的未来
- Ubuntu20.04安装Opencv3,ROS及gnss_comm
- (每日持续更新)jdk api之FileReader基础、应用、实战