【论文解读】Split to Be Slim: An Overlooked Redundancy in Vanilla Convolution(SPConv)
SPConv
摘要
为了减少推理加速模型的冗余,已经提出了许多有效的解决方案。然而,常见的方法大多侧重于消除不太重要的过滤器或构造高效的操作,而忽略了特征映射中的模式冗余。我们揭示了一个层中的许多特征映射共享相似但不相同的模式。然而,很难识别具有相似模式的特征是多余的还是包含必要的细节。因此,我们不是直接去除不确定的冗余特征,而是提出了一种基于分裂的卷积操作,即SPConv,以容忍具有相似模式但需要较少计算的特征。具体而言,我们将输入特征映射分为代表性部分和不确定冗余部分,通过相对繁重的计算从代表性部分提取固有信息,而不确定冗余部分中的微小隐藏细节则通过一些轻量级的操作进行处理。为了重新校准和融合这两组处理后的特征,我们提出了一个无参数特征融合模块。此外,我们的SPConv被制定为以即插即用的方式取代普通的卷积。没有任何花哨的东西,在基准测试上的实验结果表明,配备spconvn的网络在GPU上的准确性和推理时间方面始终优于最先进的基线,flop和参数急剧下降。
引言
FLOPS:注意全大写,是floating point operations per second的缩写,意指每秒浮点运算次数,理解为计算速度。是一个衡量硬件性能的指标。
FLOPs:注意s小写,是floating point operations的缩写(s表复数),意指浮点运算数,理解为计算量。可以用来衡量算法/模型的复杂度。
近年来,深度神经网络取得了显著的成功。然而,这种快速增长的精度是以日益复杂的模型为代价的,这些模型包含数百万个参数和数十亿个FLOPs

在ResNet-50中,输入图像的可视化(左上)和一些第二阶段的输入特征图。他们中的许多人表现出很大的模式相似性。因此,可以选择一些具有代表性的特征映射来补充内在信息,而剩余的冗余只需要补充微小的不同细节。
在本文中,我们提出了一种新颖的SPConv模块来减少普通卷积中的冗余。具体来说,我们将所有输入通道分成两部分:一部分用于代表性,另一部分用于冗余。固有信息可以通过正态k × k核从代表性部分提取出来。此外,隐藏的微小差异可以通过廉价的1×1内核从冗余部分收集。然后,我们将这两类提取的信息进行相应的融合,以确保在无参数的情况下不丢失任何细节。此外,我们以通用的方式设计SPConv,并使其成为普通卷积的即插即用替代品,而无需对网络架构或超参数设置进行任何其他调整。
主要贡献:
- 我们揭示了普通卷积中被忽视的冗余,并建议将所有输入通道分成两部分:一部分用于提供固有信息的代表,另一部分用于补充不同细节的冗余。
- 我们设计了一个即插即用的SPConv模块来取代没有任何调整的普通卷积,它实际上在精度和推理时间上都优于最先进的基线,参数和FLOPs急剧下降。
方法
The Representative and the Redundant
我们的SPConv以α的比例将所有输入通道分成两个主要部分,一个用于代表应用k × k(这里我们采用广泛使用的3 × 3)卷积来提供内在信息;另一个用于冗余,应用便宜的1 × 1卷积来补充微小的隐藏细节

初始SPConv可以用方程表示
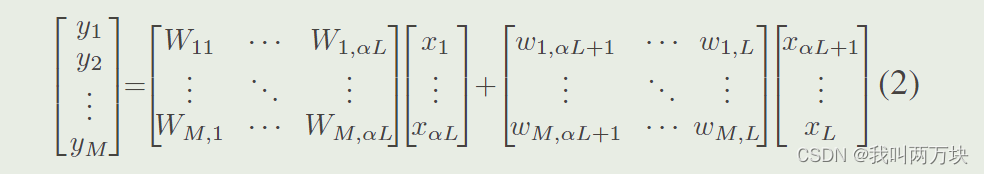
其中,Wi,j,j∈[1,αL]表示在αL代表通道上卷积的3 × 3核的参数。wi,j,j∈[αL + 1, L]表示对剩余(1?α)L个冗余特征进行点向卷积的廉价1 × 1核的参数。同时我们以相同的异构分布共享每个过滤器,而不是以移位的方式,其碎片化的内核使得在当前硬件上的计算更加困难,从而可以实现更快的推理速度
Further Reduction for the Representative
将所有输入通道分成两个主要部分后,代表性部分之间可能存在冗余。换句话说,代表性通道可以分为几个部分,每个部分代表一个主要的特征类别,例如颜色和纹理。因此,我们在代表性通道上采用群卷积进一步减少冗余,如图2中间部分所示。我们可以将群卷积视为具有稀疏块对角卷积核的普通卷积,其中每个块对应于通道的分区,并且分区之间没有连接。
这意味着,经过群卷积后,我们进一步减少了代表性部分之间的冗余,同时也切断了可能不可避免地有用的通道之间的连接。我们通过在所有代表性通道中添加逐点卷积来弥补这种信息损失。不同于常用的群体卷积和逐点卷积,我们在同一代表性渠道上同时进行GWC(Group-wise)和PWC(Point-wise)。然后我们通过直接求和来融合两个结果特征,因为它们的通道起源相同,从而获得额外的分数(这里我们将组大小设置为2)。
所以方程2的代表性部分可以写成方程
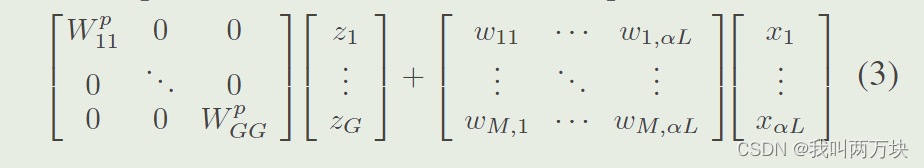
本文将αcL代表性通道分为G组,每组zl包含(αcL/G)通道。wp(ll)是第lth群的群卷积核的参数。
(左边是群卷积GWC,右边是逐点卷积PWC,逐点卷积是为了弥补群卷积的信息损失的)
【群卷积】群卷积(Group Convolution)是一种卷积神经网络(CNN)中的卷积操作的变体。在传统的卷积操作中,所有输入通道都与所有输出通道连接,形成一个全连接的卷积核。而在群卷积中,将输入通道和输出通道划分为若干个组,每个组内的通道之间进行卷积操作,但不同组之间没有连接。具体来说,群卷积将输入和输出通道分成若干个组,每个组有一组权重(卷积核),然后在每个组内进行卷积操作。这种方式可以减少参数量,降低计算复杂度,并且有助于模型的并行化,因为每个组内的卷积可以独立进行。
Parameter-Free Feature Fusion Module
我们为SPConv设计了一种新的特征融合模块,不需要引入额外的参数,有助于实现更好的性能。如图2右侧所示,我们使用全局平均池化来生成通道统计S1, S3∈RC,用于全局信息嵌入。通过压缩输出特征U的空间维度,S的第c个元素如式4所示
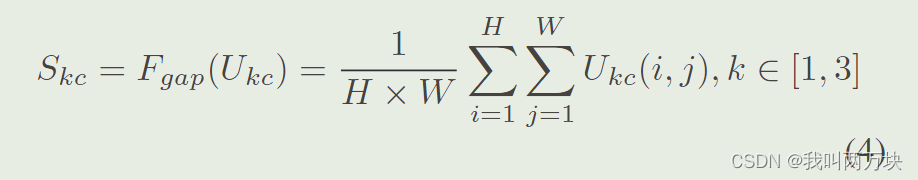
然后我们将这两个结果S3, S1向量叠加在一起,然后进行跨通道的软注意运算,生成特征重要性向量β∈Rc, γ∈Rc,其第c个元素如下所示

【soft-attention】可以理解为Soft Attention每个权重取值范围为[0,1](是我们常用的Attention)。对于Hard Attention来说,每个key的注意力只会取0或者1,也就是说我们只会令某几个特定的key有注意力,且权重均为1。
我们的最终输出Y可以通过融合特征U3和u1来获得,它们分别来自代表性部分和冗余部分,由特征重要性向量β, γ以通道方式引导
【总结】
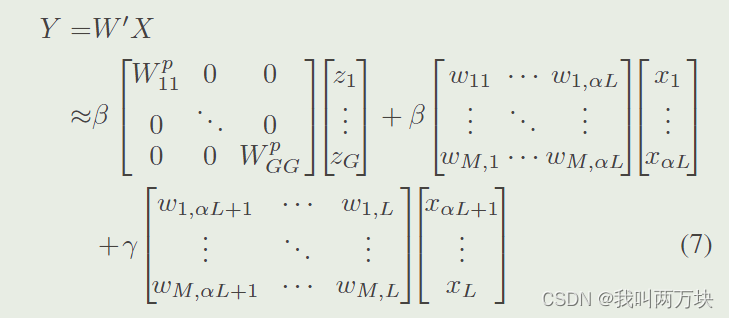
其中大写W代表3×3内核,小写w代表1×1内核。
当我们选择一半的输入通道作为代表,将代表部分分成2组,并采用广泛使用的3x3核时,参数的数量可以减少2.8倍,而模型在准确率和推理速度上都比普通卷积略好一些。
实验
我们只使用我们的SPConv模块替换广泛使用的3 × 3内核进行实验。升级后的网络只有一个全局超参数α,表示代表特征在所有输入特征中的比例。虽然不同的层/阶段可能需要不同数量的代表性特征,但我们在实验中对所有层使用相同的α。仔细地为不同的层设计不同的α会得到一个更紧凑的模型。同时,我们将代表部分的分组大小设为2。
Small Scale Classfication Task
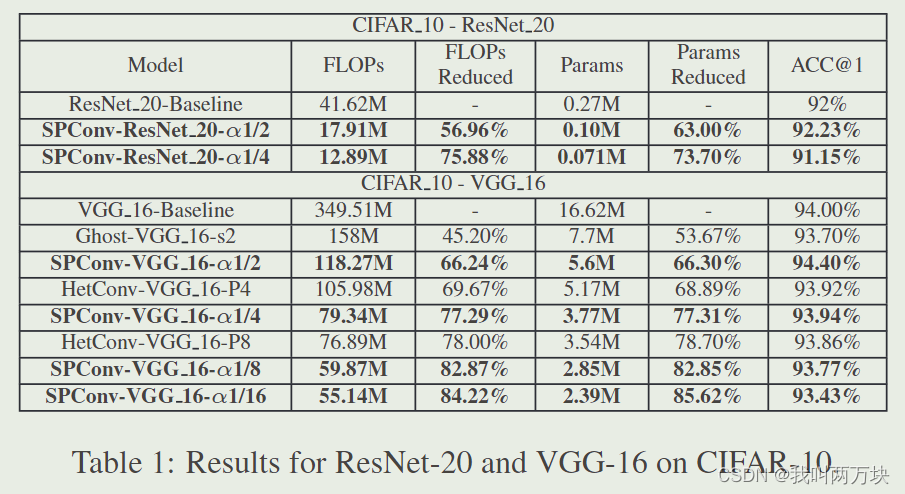
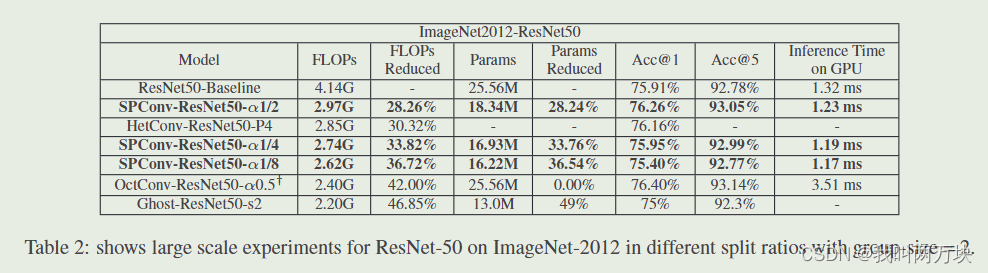
Large Scale Experiments on ImageNet
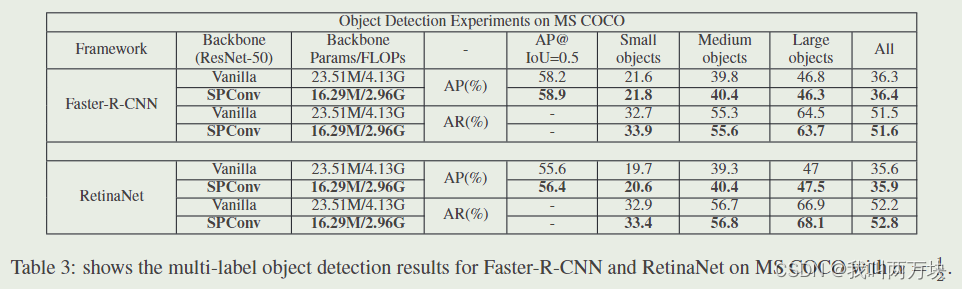
Obeject Detection on MS COCO
(multi-label)
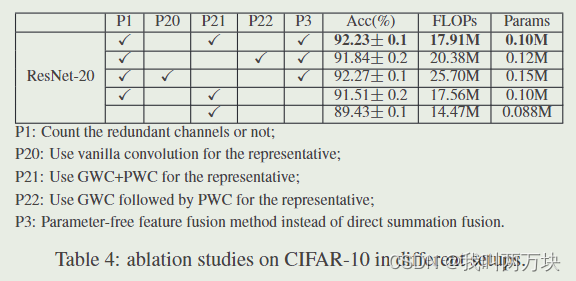
Ablation Studies
结论
在这项工作中,我们揭示了普通卷积中被忽视的模式冗余。为了解决这一问题,我们提出了一种新的SPConv模块,将所有输入特征映射拆分为代表性部分和不确定冗余部分。在各种数据集和网络架构上的大量实验证明了我们的SPConv的有效性。更重要的是,它实现了比基线更快的推理速度,优于现有的工作。在MS COCO上进行的多标签目标检测实验证明了其通用性。由于我们的SPConv与当前的模型压缩方法是正交的,并且是互补的,因此它们的仔细组合将在未来获得更轻量级的模型。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!