深度学习记录--Train/dev/test sets
发布时间:2024年01月15日
为什么需要训练集、验证集(简单交叉验证集)和测试集?
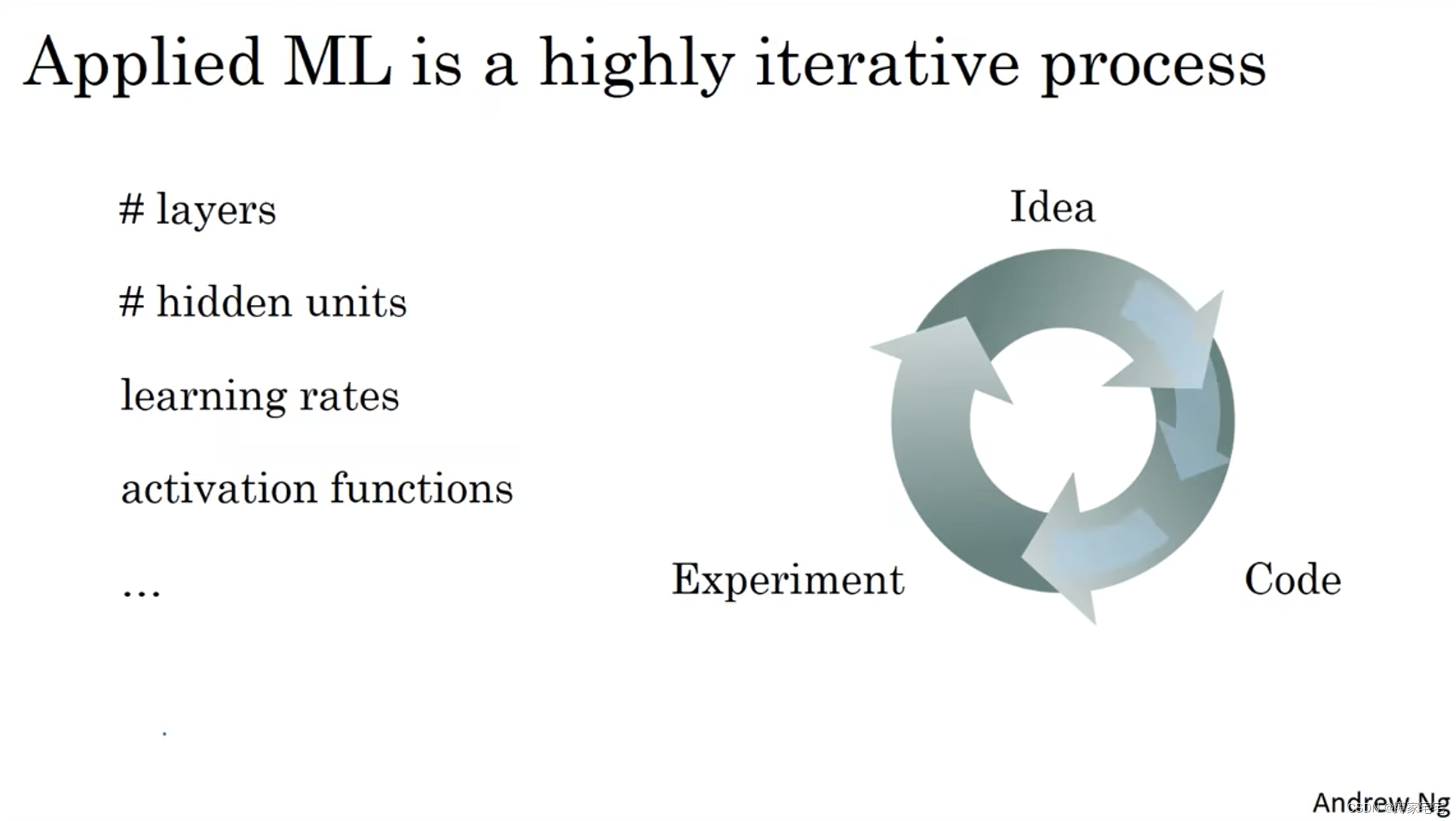 为了创建高效的神经网络,需要不断进行训练(迭代)
为了创建高效的神经网络,需要不断进行训练(迭代)
一个神经网络的产生
从最开始的想法idea开始,然后付诸于代码code,根据结果验证反过来对一开始的想法idea进行修正,而这就完成了一次训练(迭代)
循环速率(迭代速率)
train/dev/test sets会加速神经网络的集成
数据的配置

一般将数据分为三个部分(train/dev/test sets)
在训练集和验证集之后得到匹配的神经网络,然后利用测试集来对当前神经网络进行评估
分配的演变
小数据时代:
70% train sets 30% test sets
60% train sets 20% dev sets 20% test sets
大数据时代:
绝大部分为train sets,极小部分为dev sets和test sets
对于百万量级的数据,可以分为98% train sets 1% dev sets 1% test sets
对于超百万量级的数据,可以分为99.5% train sets 0.25% dev sets 0.25% test sets
原因:
由于大数据量的存在,dev sets只需要对不同的算法进行验证与取舍即可,故得出几种合适的算法来优化性能即可,而test sets只需要对神经网络进行无偏评估即可,所以数据量不需要很大
补充:
一条法则:
dev和test sets最好来自同一分布(same distribution),这样可以加快速率与优化性能
test sets不是必须的
如果不需要进行无偏评估,那么只用保证train/dev sets(训练验证集)即可
文章来源:https://blog.csdn.net/Xudong_12345/article/details/135612177
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!