Stable Diffusion基础界面介绍!!!!!
手把手教你入门绘图超强的AI绘画,用户只需要输入一段图片的文字描述,即可生成精美的绘画。给大家带来了全新保姆级教程资料包 (文末可获取)
Stable Diffusion Web UI 是一个基于 Stable Diffusion 的基础应用,利用 gradio 模块搭建出交互程序,可以在低代码 GUI 中立即访问 Stable Diffusion
- Stable Diffusion 是一个画像生成 AI,能够模拟和重建几乎任何可以以视觉形式想象的概念,而无需文本提示输入之外的任何指导
- Stable Diffusion Web UI 提供了多种功能,如 txt2img、img2img、inpaint
等,还包含了许多模型融合改进、图片质量修复等附加升级。 - 通过调节不同参数可以生成不同效果,用户可以根据自己的需要和喜好进行创作。
- 我们可以通过Stable Diffusion Web UI 训练我们自己的模型,它提供了多种训练方式,通过掌握训练方法可以自己制作模型。
界面
启动界面可以大致分为4个区域【模型】【功能】【参数】【出图】四个区域

1.模型区域:模型区域用于切换我们需要的模型,模型下载后放置相对路径为/modes/Stable-diffusion目录里面,网上下载的safetensors、ckpt、pt模型文件请放置到上面的路径,模型区域的刷新箭头刷新后可以进行选择。
- 功能区域:功能区域主要用于我们切换使用对应的功能和我们安装完对应的插件后重新加载UI界面后将添加对应插件的快捷入口在功能区域,功能区常见的功能描述如下
-
txt2img(文生图) — 标准的文字生成图像;
-
img2img (图生图)— 根据图像成文范本、结合文字生成图像;
-
PNG Info — 图像基本信息
-
Checkpoint Merger — 模型合并
-
Textual inversion — 训练模型对于某种图像风格
-
Settings — 默认参数修改
3.参数区域:根据您选择的功能模块不同,可能需要调整的参数设置也不一样。例如,在文生图模块您可以指定要使用的迭代次数,掩膜概率和图像尺寸等参数配置
4.出图区域:出图区域是我们看到AI绘图的最终结果,在这个区域我们可以看到绘图使用的相关参数等信息。
txt2img(文生图)
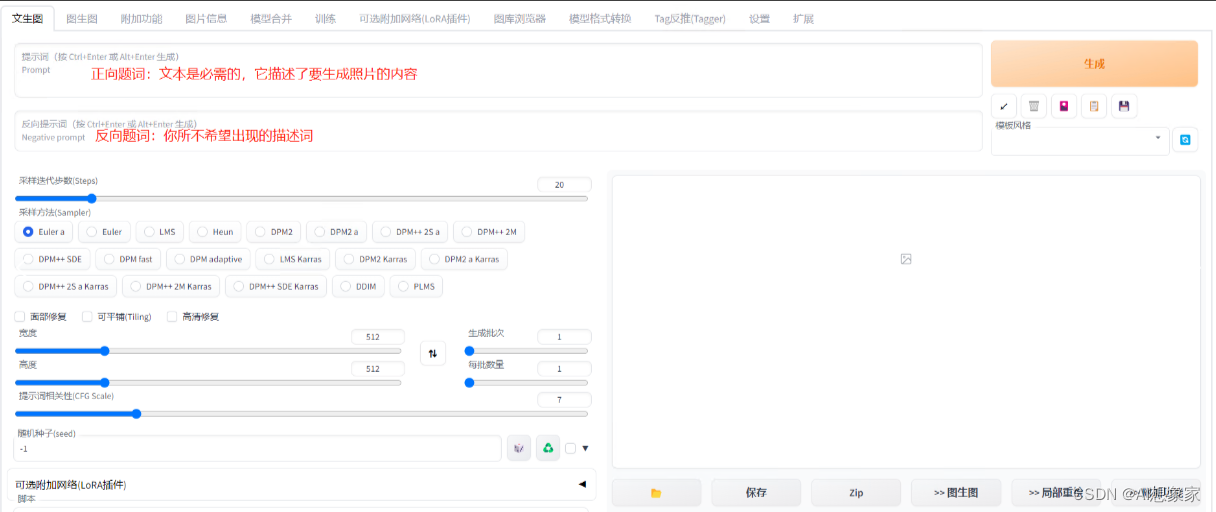
在设置页面中,您可以输入文本,选择模型并配置其他参数。文本是必需的,它将成为图像生成的依据。您可以选择预定义的模型或上传自己的模型。您还可以选择一些其他参数,例如批处理大小,生成的图像尺寸等。下面是一些参数的说明:
- 采样方法 (Sampler):这个参数允许您选择用于生成图像的采样方法。默认情况下,该参数设置为“Eulea”,但您也可以选择“DPM++”后面的新加入选项,这个会比默认的生成的图片细节内容更加丰富些。
Euler a:
i. Euler a是一种用于控制时间步长大小的可调参数,在Stable Diffusion中采用Euler时间步长采样方法。适当的Euler a值能够捕捉到细节和纹理,但如果值太大会导致过度拟合,生成图像出现噪点等不良效果。
ii. 一句话概括:采样生成速度最快,但是如果说在高细节图增加采样步数时,会产生不可控突变(如人物脸扭曲,细节扭曲等)。
适合:ICON,二次元图像,小场景。

DPM++2S a Karras :
i. 采用 DPM++2S a Karras 采样方法生成高质量图像,该方法在每个时间步长中执行多次操作,同等分辨率下细节会更多,比如可以在小图下塞进全身,代价是采样速度更慢。
ii. 适合:写实人像,复杂场景刻画。

DDIM:
i. DDIM 采样方法可以快速生成高质量的图像,相比其他采样方法具有更高的效率,想尝试超高步数时可以使用,随着步数增加可以叠加细节。
- 迭代步数(Sampling
steps):输出画面需要的步数,每一次采样步数都是在上一次的迭代步骤基础上绘制生成一个新的图片,一般来说采样迭代步数保持在18-30左右即可,低的采样步数会导致画面计算不完整,高的采样步数仅在细节处进行优化,对比输出速度得不偿失。 - 宽度&高度:这个参数允许您指定图片生成的高度和宽度。较大的高度宽度需要更多的显存计算资源,这里默认512*512即可,需要图片放大我们可以去更多(send
to extras)模块用放大算法进行图片放大。 - 生成批次(Batch
count):此参数允许您用指定模型将为每个生成的图像运行的最大迭代次数。增加这个值多次生成图片但生成的时间也会更长(有多图需要建议减少图片生成的批次改为增加单次生成图片的数量参数即可)。 - 每批数量(Batch
size):此参数允许您指定一次可以生成的最大图像数量。如果您的系统资源有限,并且需要以较小的批量生成映像,那么这可能很有用。 - 提示词相关性(CFG
Scale):此参数可以变更图像与提示符的一致程度(增加这个值将导致图像更接近你的提示,但过高会让图像色彩过于饱和,数值越小AI绘图发挥的自我空间越大越有可能产生有创意的结果(默认为7)。 - Stable
Diffusion中的提示词相关性指的是输入提示词对生成图像的影响程度。当我们提高提示词相关性时,生成的图像将更符合提示信息的样子;相反,如果提示词相关性较低,对应的权重也较小,则生成的图像会更加随机。因此,通过调整提示词相关性,可以引导模型生成更符合预期的样本,从而提高生成的样本质量。
i. 在具体应用中,对于人物类的提示词,一般将提示词相关性控制在7-15之间。
ii. 而对于建筑等大场景类的提示词,一般控制在3-7左右。这样可以在一定程度上突出随机性,同时又不会影响生成图像的可视化效果。因此,提示词相关性可以帮助我们通过引导模型生成更符合预期的样本,从而提高生成的样本质量。
- 种子数(Seed):
此参数允许您指定一个随机种子,将用于初始化图像生成过程。相同的种子值每次都会产生相同的图像集,这对于再现性和一致性很有用。如果将种子值保留为-1,则每次运行文本-图像特性时将生成一个随机种子。
i. 随机种子是一个可以锁定生成图像的初始状态的值。当使用相同的随机种子和其他参数,我们可以生成完全相同的图像。设置随机种子可以增加模型的可比性和可重复性,同时也可以用于调试和优化模型,以观察不同参数对图像的影响。
ii. 在Stable Diffusion中,常用的随机种子有-1和其他数值。当输入-1或点击旁边的骰子按钮时,生成的图像是完全随机的,没有任何规律可言。而当输入其他随机数值时,就相当于锁定了随机种子对画面的影响,这样每次生成的图像只会有微小的变化。因此,使用随机种子可以控制生成图像的变化程度,从而更好地探索模型的性能和参数的影响。
在工作产出中,如果细微调整,我们将会固定某个种子参数然后进行批量生成。
- 优化面部(Restore faces):优绘制面部图像可勾选,头像是近角时勾选貌似容易过度拟合出现虚化,适合在远角时勾选该选项。
- 可平铺(Tiling):用于生成一个可以平铺的图像。
- Highres.
fix:使用两个步骤的过程进行生成,以较小的分辨率创建图像,然后在不改变构图的情况下改进其中的细节,选择该部分会有两个新的参数Scale
latent在潜空间中对图像进行缩放。另一种方法是从潜在的表象中产生完整的图像,将其升级,然后将其移回潜在的空间。Denoising
strength 决定算法对图像内容的保留程度。在0处,什么都不会改变,而在1处,你会得到一个不相关的图像;
image2image(图生图)
img2img功能可以让你用stable diffusion web ui生成元画像和似的构图色彩的画像,或者指定一部分内容进行变换。
与text2img相比,img2img新增了缩放模式和重绘幅度(Denoising strength)参数设置
- 缩放模式:主要是我们调整了图片尺寸后以何种模式保证图片的输出效果;
- 重绘幅度(Denoising strength):图像模仿自由度,越高越自由发挥,越低和参考图像越接近,通常小于0.3基本就是加滤镜;
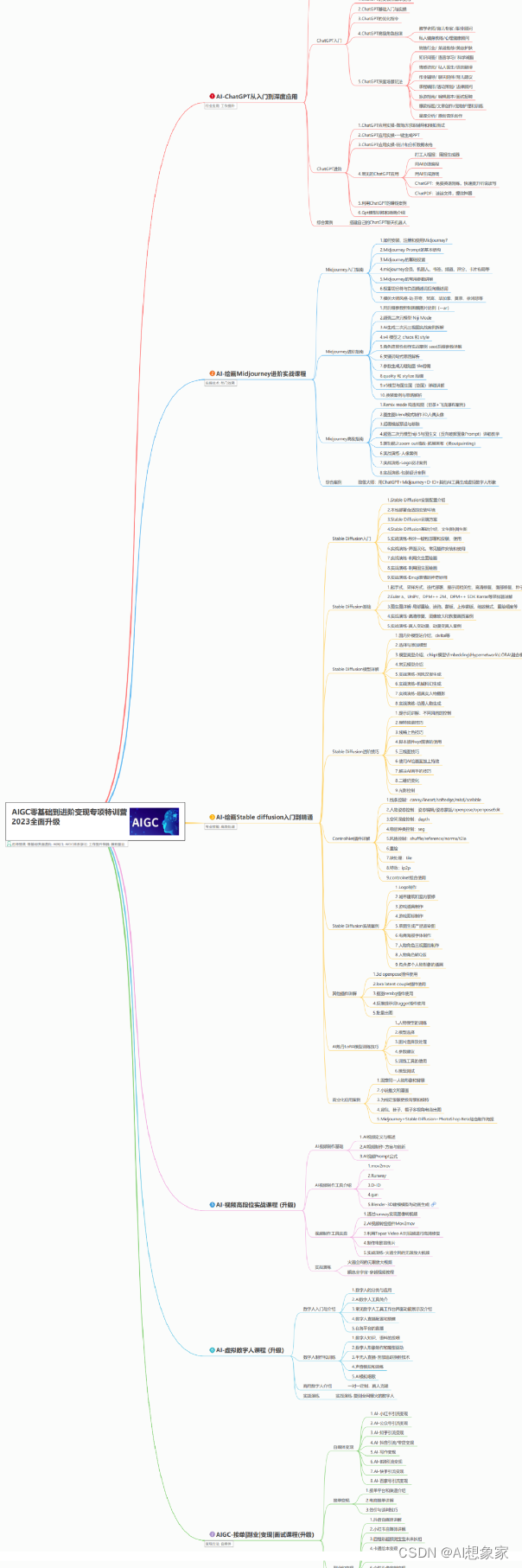
AI绘画所有方向的学习路线思维导图
这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。如果下面这个学习路线能帮助大家将AI利用到自身工作上去,那么我的使命也就完成了:
👉stable diffusion新手0基础入门PDF👈

👉AI绘画必备工具👈
温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉AI绘画基础+速成+进阶使用教程👈
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
👉12000+AI关键词大合集👈

这份完整版的AI绘画资料我已经打包好,戳下方蓝色字体,即可免费领取!
CSDN大礼包:《全套AI绘画基础学习资源包》免费分享
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 小米SU7正式亮相,媒介盒子多家媒体报道
- [linux] git clone一个repo,包括它的子模块submodule
- JDK17:Java HashMap源码解读
- 金蝶云星空创建普通动态表单
- Liunx:线程控制
- 【Python百宝箱】图像魔法师:Python数据可视化的艺术之旅
- <软考高项备考>《论文专题 - 18 资源管理(四) 》
- linux异常情况,排除中
- 2024年【起重机司机(限桥式起重机)】考试报名及起重机司机(限桥式起重机)考试技巧
- ArgoCD