【教程】Linux环境下支持GPU加速的Pytorch、PyG、DGL环境配置步骤记录
无关紧要的前言
从接触深度学习以来配过很多次环境,但由于陆续使用了不同的设备,每个设备的系统、硬件配置都差别很大,不长记性的作者每次配环境都会踩一堆坑,在据说很好配的pytorch环境上次次耗费很长的时间。在这次吭哧吭哧配环境的过程中,终于克服了懒惰记录并梳理了一遍整体流程,希望如果还有下次,能参考这个记录,脑子清醒且顺畅地配好环境。原本是给自己看,但写完后想着写都写了,也许发上来能给其他踩了和我一样的坑的朋友一些参考~
这篇步骤记录针对的是在Linux系统下配置支持GPU加速的Pytorch(其它系统的也可以参考基本步骤,但是涉及到的具体的选项和指令会有所不同),以及做图神经网络会涉及到的PyG、DGL库的安装过程。如果不考虑GPU,网上有很多清晰的教程,步骤非常简单,自行搜索即可,本篇不涉及。
需要完成的前置工作: 安装python、创建conda环境并激活,所有步骤均在conda环境中完成。
文章目录
1. 查看系统及GPU的相关信息
(1)查看系统:
gcc --version
我的运行结果:gcc (Ubuntu 8.4.0-1ubuntu1~18.04) 8.4.0 (服务器为Linux系统,后续安装都选Linux)
(2)查看显卡:
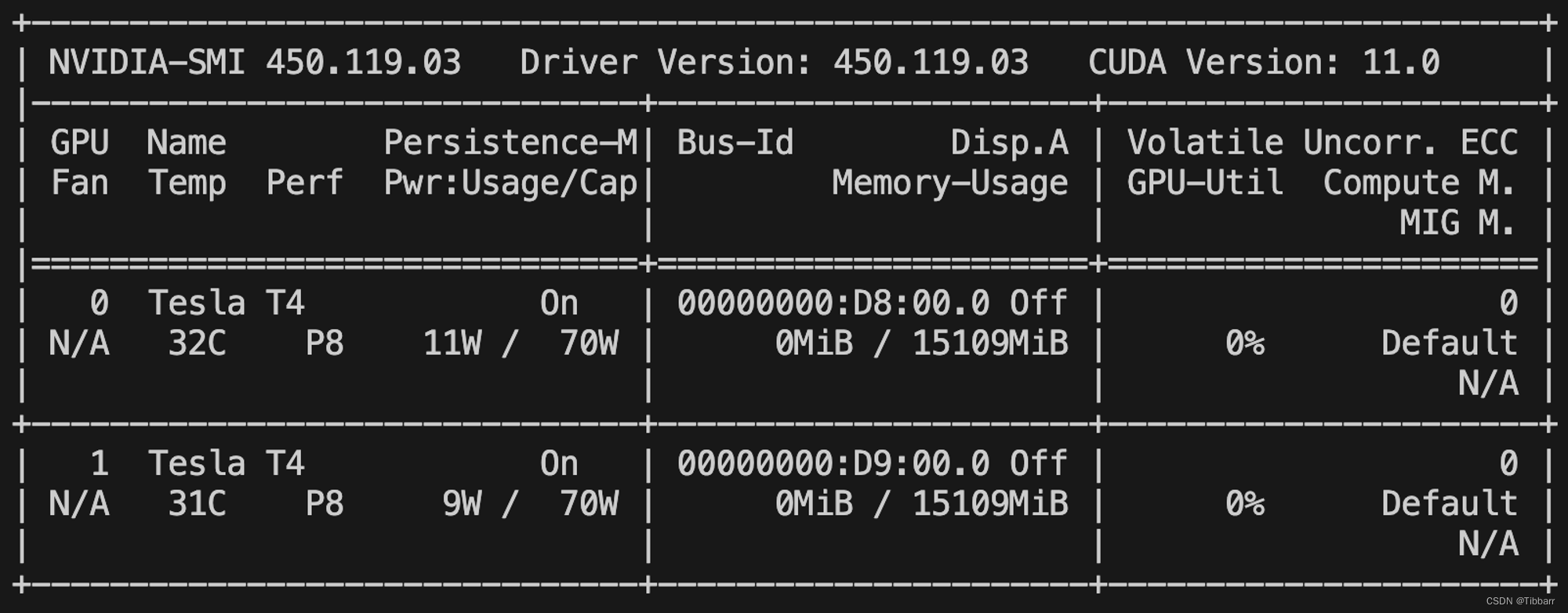
nvidia-smi
我的运行结果:有两块Tesla T4 GPU,NVIDIA驱动版本为450.119.03,支持CUDA 11.0
2. 安装与GPU对应的CUDA和cuDNN
(1) 安装CUDA的相关依赖库:
sudo apt-get install freeglut3-dev build-essential libx11-dev libxmu-dev libxi-dev libgl1-mesa-glx libglu1-mesa libglu1-mesa-dev
(2)对应显卡的查看结果,安装对应版本的CUDA Toolkit(此处为CUDA 11.0):
- 安装特定版本的GCC:
sudo apt install gcc-8 g++-8
- 更新默认的GCC版本:
sudo update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-8 20
sudo update-alternatives --install /usr/bin/g++ g++ /usr/bin/g++-8 20
- 下载并安装CUDA Toolkit(此处为对应的CUDA Toolkit 11.0),指令从官网查找:https://developer.nvidia.com/cuda-toolkit-archive,选择一个cuda版本点进去(这里点击了cuda11.0.3)。根据前面gcc的查看结果,选择对应的系统(这里选择了Linux、x86_64、Ubuntu、18.04、deb(local)),在页面下方的Installation Instructions中得到对应的安装指令并运行。
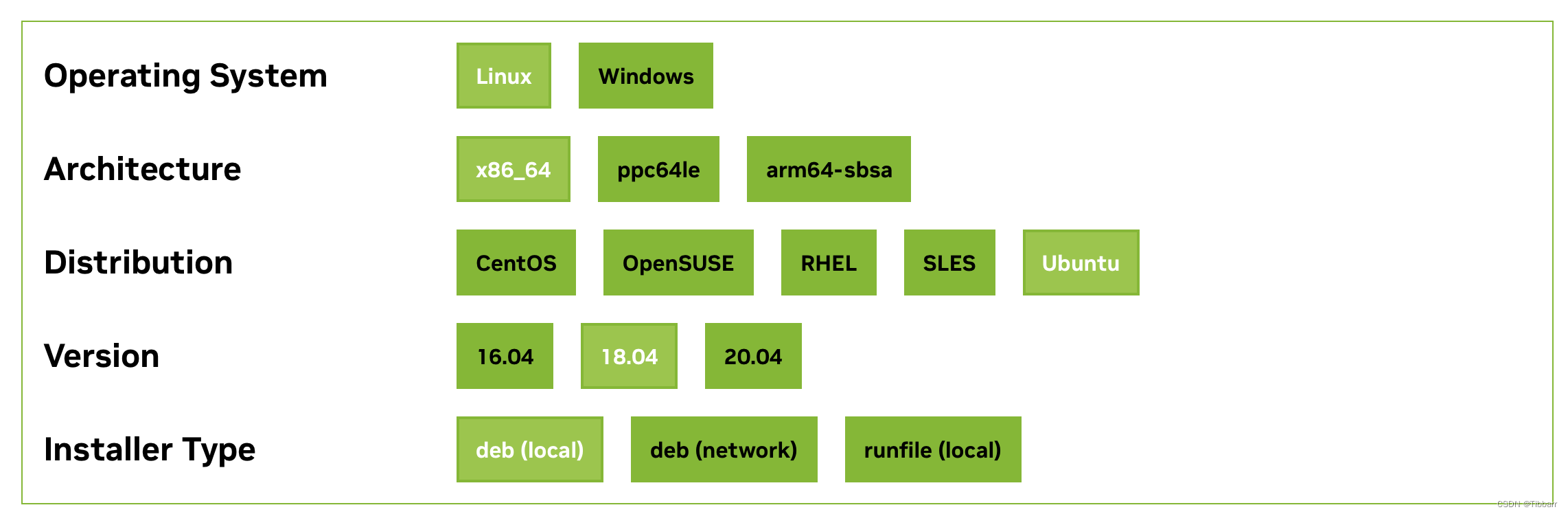
我得到的指令:
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64/cuda-ubuntu1804.pin
sudo mv cuda-ubuntu1804.pin /etc/apt/preferences.d/cuda-repository-pin-600
wget https://developer.download.nvidia.com/compute/cuda/11.0.3/local_installers/cuda-repo-ubuntu1804-11-0-local_11.0.3-450.51.06-1_amd64.deb
sudo dpkg -i cuda-repo-ubuntu1804-11-0-local_11.0.3-450.51.06-1_amd64.deb
sudo apt-key add /var/cuda-repo-ubuntu1804-11-0-local/7fa2af80.pub
sudo apt-get update
sudo apt-get -y install cuda
这里可能有wget得到了本地的cuda_11.0.3_450.51.06_linux.run,但出现图形化安装界面的情况
操作步骤为:
- 输入accept进行后续操作,出现安装选项界面:
- 取消勾选第一项,选择不安装驱动(已经有nvidia驱动了),选择Install
- 后续出现的一系列选项,都选择yes即可
- 配置环境变量(目的是让系统和其他应用程序能找到CUDA Toolkit,这一步不做后面大概率会报错),打开 ~/.bashrc文件:
nano ~/.bashrc
- 在文件末尾添加以下行,确保路径与实际安装路径一致(这里我不确定到底哪个有用,在查了一堆教程后这些都被我添加进去了,所以都写在这里):
export PATH=/usr/local/cuda-11.0/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda-11.0/lib64:$LD_LIBRARY_PATH
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda/lib64
export PATH=$PATH:/usr/local/cuda/bin
export CUDA_HOME=$CUDA_HOME:/usr/local/cuda
- 保存并关闭文件,指令为:
:wq!
- 重新加载.bashrc文件以应用更改:
source ~/.bashrc
- 验证CUDA Toolkit安装情况:
nvcc --version
到这里,如果最后一步的验证命令返回了CUDA的版本信息,则CUDA Toolkit安装成功。我的返回结果如下:

(3)安装对应版本的cuDNN:
- 下载cuDNN安装包:在nvidia官方查看CUDA对应的cuDNN版本:https://developer.nvidia.com/rdp/cudnn-archive 并点击展开,找到自己的系统对应的版本下载,我的选择为:cuDNN v8.7.0 (November 28th, 2022), for CUDA 11.x Local Installer for Linux x86_64 (Tar)
- 安装cuDNN:进入到cudnn下载的安装路径下,命令行输入以下命令进行解压操作(-xzvf后面对应的是安装包的文件名):
tar -xzvf cudnn-11.0-linux-x64-v8.7.0.39.tgz
- 随后在当前路径的命令行终端输入以下三条命令进行cudnn的安装:
sudo cp cuda/include/cudnn.h /usr/local/cuda/include
sudo cp cuda/lib64/libcudnn* /usr/local/cuda/lib64
sudo chmod a+r /usr/local/cuda/include/cudnn.h /usr/local/cuda/lib64/libcudnn*
至此,CUDA和cuDNN安装完成,可以进入安装pytorch的步骤了。
3. 安装pytorch
在pytorch官网选择需要的版本,获得安装指令:https://pytorch.org/get-started/locally/(尽量选比较新的稳定版本,原因如下)
💡 很重要的TIPS:高版本的pytorch通常可以兼容低版本的CUDA。
- 我的CUDA是11.0,在查阅资料的时候,都说CUDA11.0对应的pytorch版本是1.7.0,于是最开始我安装了1.7.0。但是由于后续要用PyG,而安装对应pytorch1.7.0的PyG出现了很多问题,结论都指向了需要通过升级pytorch的版本进行解决。
- 后来经过测试,发现我一直对这里有误解,CUDA11.0对应的pytorch版本是1.7.0,意味着1.7.0之前的pytorch不支持CUDA11.0,但是新版本的pytorch可以支持旧CUDA。
- 最终,根据目前PyG首页提供的Quick Start,我选择了pytorch2.1.2+cuda11.8的版本。
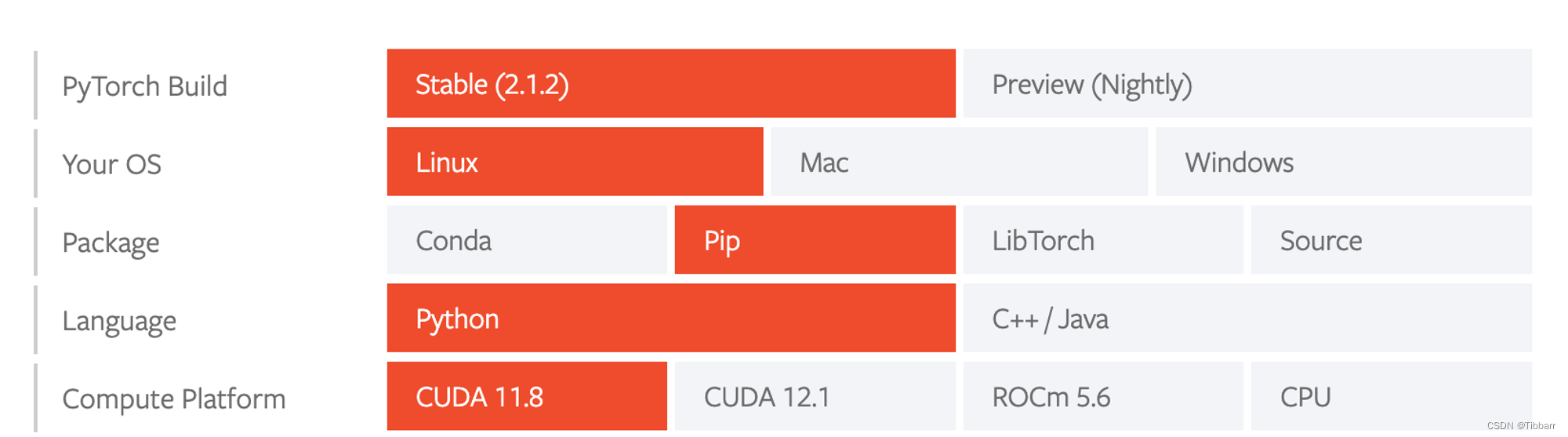
我得到的安装指令如下:
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
运行安装指令即可。
后续的PyG和DGL是用来做图神经网络的,只需要安装pytorch的朋友可以跳过下面的4、5节,直接去最后找测试代码即可。
4. 安装支持GPU加速的PyG(非必需)
打开PyG官网:https://pytorch-geometric.readthedocs.io/en/latest/notes/installation.html,在Quick Start中选择和刚刚安装的pytorch对应的选项,获得安装指令。
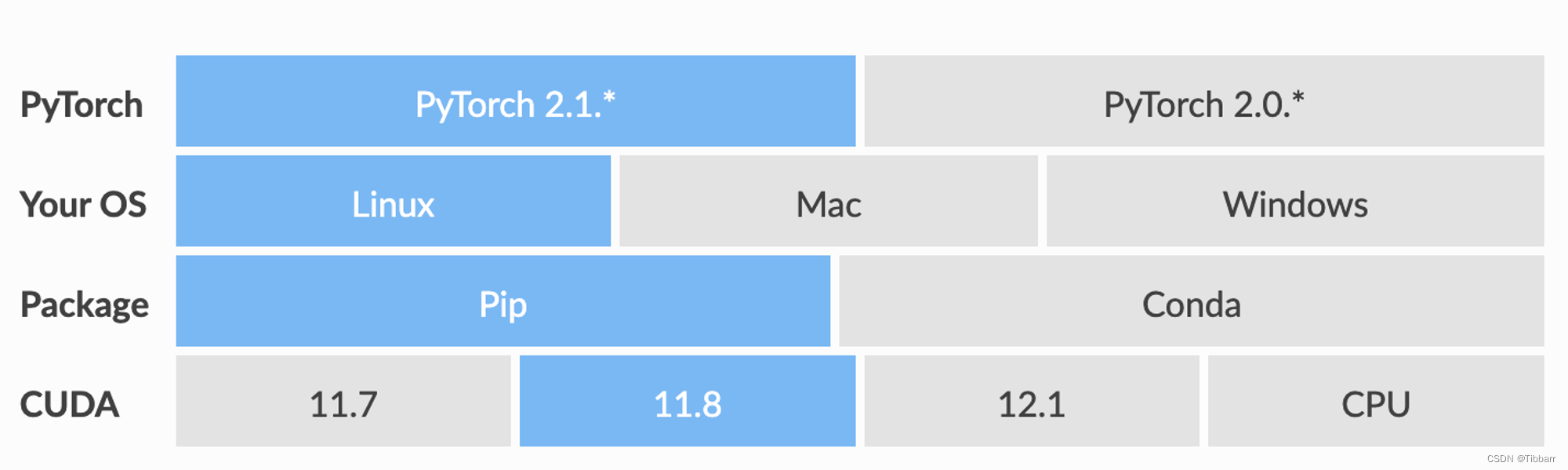
我选择了pytorch2.1.*+cuda11.8,得到的安装指令如下:
pip install torch_geometric
# Optional dependencies:
pip install pyg_lib torch_scatter torch_sparse torch_cluster torch_spline_conv -f https://data.pyg.org/whl/torch-2.1.0+cu118.html
5. 安装支持GPU加速的DGL(非必需)
打开DGL的下载官网:https://www.dgl.ai/pages/start.html,选择和pytorch、PyG同样的CUDA版本,获得安装指令。
我选择了CUDA11.8,得到的安装指令如下:
conda install -c dglteam/label/cu118 dgl
6. 测试所有环境的安装结果
这里我写了4段 python 代码,分别用来测试环境安装结果及版本、pytorch的安装情况及是否能够使用GPU、PyG的安装情况及是否能够使用GPU、DGL的安装情况及是否能够使用GPU。
(1)测试环境安装结果及版本
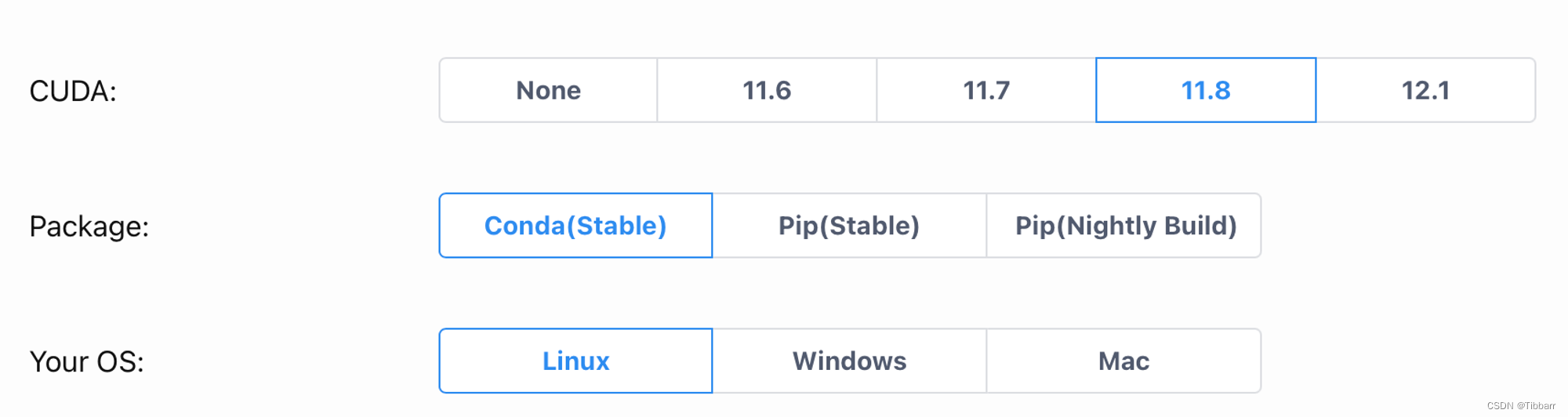
# 测试环境安装结果及版本
import torch
import torch_geometric
import dgl
import torch
if torch.cuda.is_available():
print("CUDA is available. GPU support is enabled.")
print("Number of GPUs available:", torch.cuda.device_count())
for i in range(torch.cuda.device_count()):
print(f"GPU {i}: {torch.cuda.get_device_name(i)}")
# 显示PyTorch使用的CUDA版本
print("CUDA Version:", torch.version.cuda)
# 检查cuDNN是否启用
print("cuDNN enabled:", torch.backends.cudnn.enabled)
# 打印cuDNN版本
print("cuDNN version:", torch.backends.cudnn.version())
else:
print("CUDA is not available. GPU support is not enabled.")
print("PyTorch Version:", torch.__version__)
print("DGL Version:", dgl.__version__)
print("PyG Version:", torch_geometric.__version__)
我的测试结果:
(2)pytorch的安装情况及是否能够使用GPU
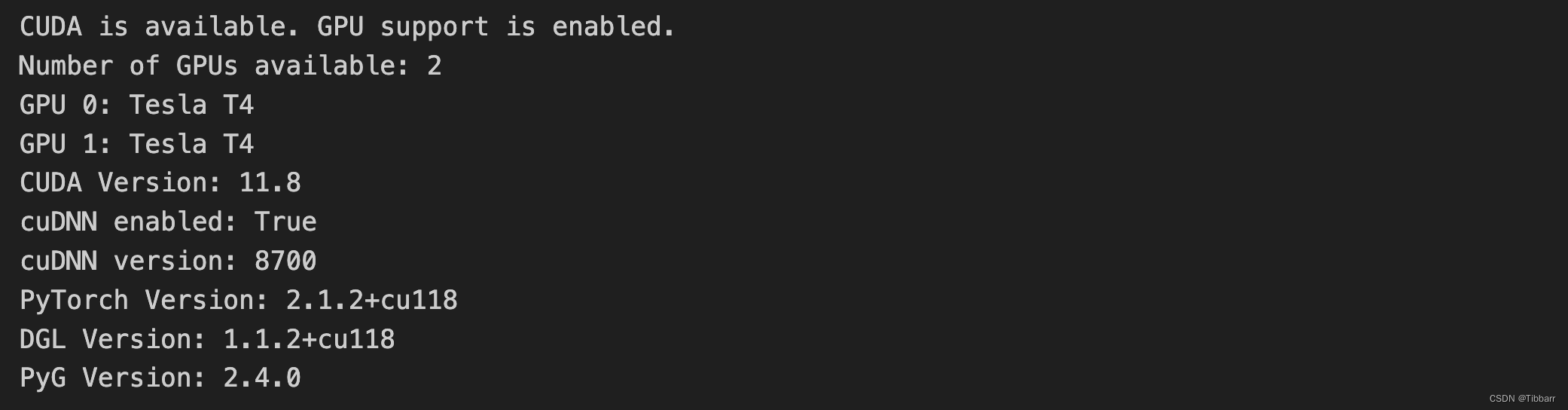
# 测试pytorch,用PyTorch来创建一个简单的张量,并检查是否能够使用GPU
import torch
# 创建一个简单的张量
x = torch.rand(5, 3)
print("Tensor x:", x)
# 检查是否支持CUDA(GPU)
if torch.cuda.is_available():
print("CUDA is available. GPU support is enabled.")
# 打印出GPU数量和型号
print("Number of GPUs available:", torch.cuda.device_count())
for i in range(torch.cuda.device_count()):
print(f"GPU {i}: {torch.cuda.get_device_name(i)}")
# 将张量移至GPU
x = x.to('cuda')
print("Moved tensor x to GPU:", x)
else:
print("CUDA is not available. GPU support is not enabled.")
我的测试结果:
(3)PyG的安装情况及是否能够使用GPU
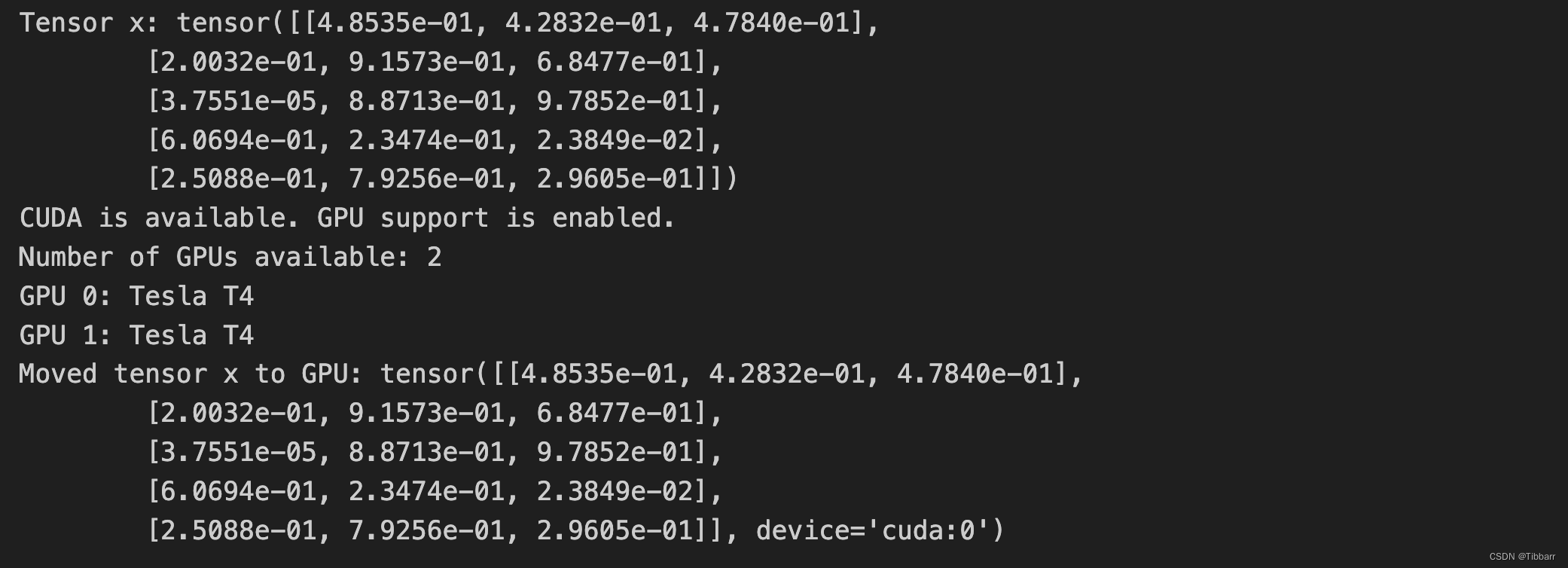
# 测试PyTorch Geometric (PyG)(未调用GPU)
print("测试PyTorch Geometric (PyG)(未调用GPU)")
import torch
from torch_geometric.data import Data
# 创建一个简单的PyG图
edge_index = torch.tensor([[0, 1, 2], [1, 2, 3]], dtype=torch.long) # 定义边
x = torch.tensor([[-1], [0], [1], [2]], dtype=torch.float) # 定义每个节点的特征
data = Data(x=x, edge_index=edge_index.t().contiguous())
print("PyG Graph:", data)
print("Nodes:", data.x)
print("Edges:", data.edge_index)
# 测试PyG能否正常调用GPU
print("测试PyG能否正常调用GPU")
import torch
from torch_geometric.data import Data
def test_pyg_gpu():
# 检查 CUDA 是否可用
if torch.cuda.is_available():
# 遍历所有可用的 GPU
for i in range(torch.cuda.device_count()):
# 创建一个简单的 PyG 图数据
edge_index = torch.tensor([[0, 1], [1, 0]], dtype=torch.long)
x = torch.tensor([[-1], [0]], dtype=torch.float)
data = Data(x=x, edge_index=edge_index.t().contiguous())
# 将数据移动到指定 GPU
data = data.to(f'cuda:{i}')
print(f'PyG successfully using GPU {i}: {torch.cuda.get_device_name(i)}')
else:
print("CUDA is not available.")
test_pyg_gpu()
我的测试结果:
(4)DGL的安装情况及是否能够使用GPU
# 测试Deep Graph Library (DGL)(未调用GPU)
print("测试Deep Graph Library (DGL)(未调用GPU)")
import dgl
# 创建一个简单的DGL图
g = dgl.graph(([0, 1, 2], [1, 2, 3]))
print("DGL Graph:", g)
print("Nodes:", g.nodes())
print("Edges:", g.edges())
# 测试DGL能否正常调用GPU
print("测试DGL能否正常调用GPU")
import dgl
import torch
def test_dgl_gpu():
# 检查 CUDA 是否可用
if torch.cuda.is_available():
# 遍历所有可用的 GPU
for i in range(torch.cuda.device_count()):
# 创建一个 DGL 图
g = dgl.DGLGraph()
g.add_nodes(10)
g.add_edges([0, 1, 2, 3, 4, 5, 6, 7, 8, 9], [1, 2, 3, 4, 5, 6, 7, 8, 9, 0])
# 将图移动到指定 GPU
g.to(f'cuda:{i}')
print(f'DGL successfully using GPU {i}: {torch.cuda.get_device_name(i)}')
else:
print("CUDA is not available.")
test_dgl_gpu()
我的测试结果:
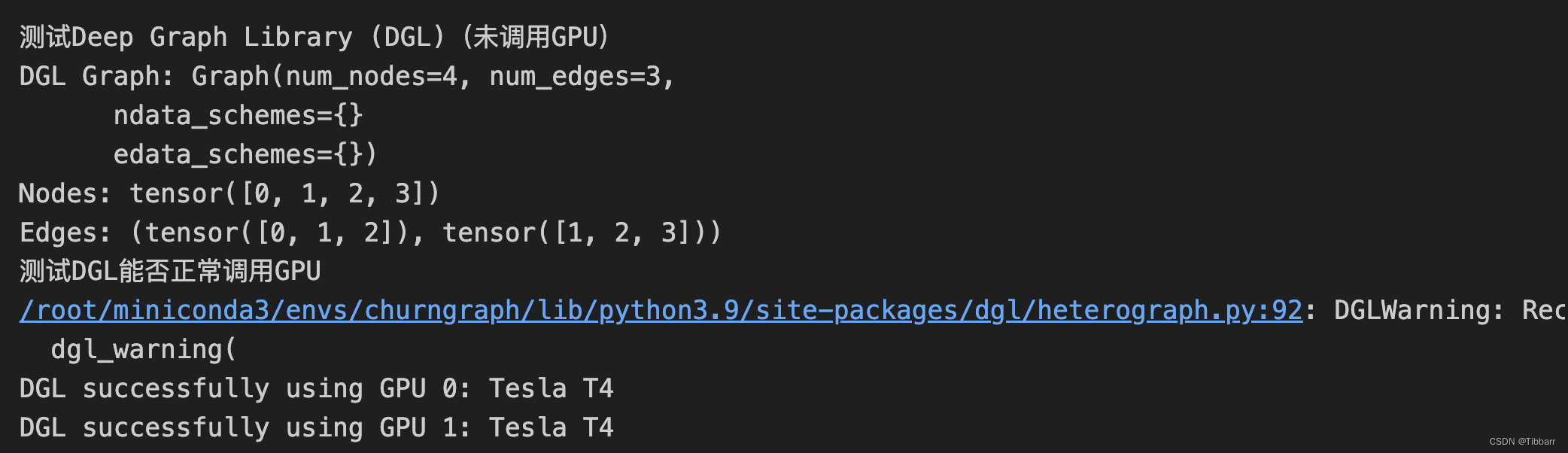
如果四段代码均能成功运行(如果仅配置pytorch,成功运行(1)和(2)即可),那么所有环境的配置都成功了!祝大家还有我自己实验顺利~
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 12.22~12.23拓扑排序(字典序顺序),dij再理解,链式前向星,pta题目
- VisualSVN Server下载安装和使用方法、服务器搭建、使用TortoiseSvn将项目上传到云端服务器、各种错误解决方法
- HTML小白入门学习-列表标签
- mss32.dll文件丢失的解决方法,和mss32.dll文件作用丢失原因详解
- 计算机网络技术-2022期末考试解析
- 外包干了5个月,技术退步明显...
- 未来消费趋势:消费降级
- SQL SERVER无法连接到服务器解决办法
- Altium Designer简介以及下载安装
- 储能技术:未来能源系统的关键