微服务实战系列之ZooKeeper(中)
前言
昨日博主的第一篇ZooKeeper,对它自身具备的能力做了初步介绍。书接上文,马不停蹄,我们继续挖掘它内在的美,充分把握它的核心与脉络。

揭秘ZooKeeper
Q:集群一致性协同是如何进行的
我们讲到分布式,一般是在集群环境下实现的。以ZooKeeper为例,它是如何保障集群环境下的成功运转呢?
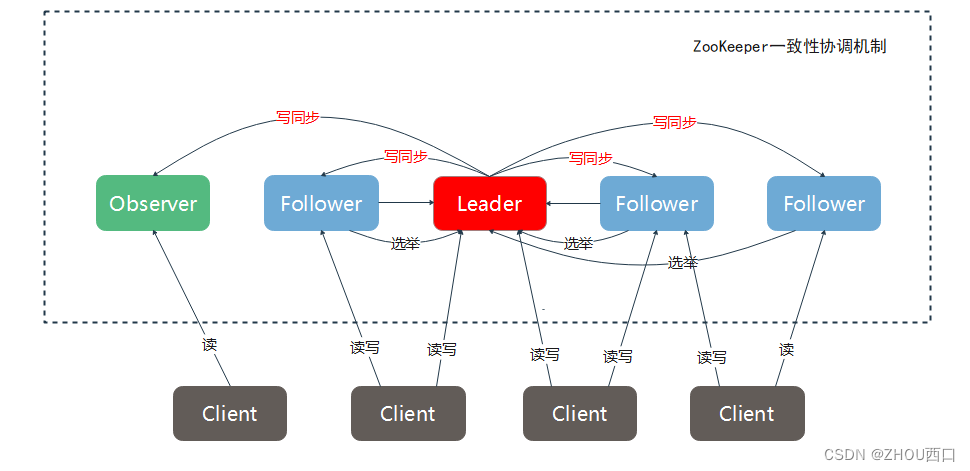
1. 节点角色
通过上图,我们认识一下ZooKeeper的3类节点:
- Leader节点
Leader作为ZooKeeper的领袖,有着举足轻重的作用。它是ZooKeeper集群环境如何稳定运行的关键,主要负责读写和调度等核心工作。如果它宕机了,一致性调度从此冷却,整个集群将面临群龙无首的局面,直至系统瘫痪。 - Follower节点
作为随从节点,主要负责客户端的读操作,如果遇到写申请, 需要转发Leader节点完成,自身不做任何处理。如Leader宕机,会立即参与Leader的选举,具有投票权。 - Observer节点
作为候选角色,Observer为提升整个集群的执行效率提供一定帮助,但仅限于读操作。不参与写,不参与Leader的选举。
了解3类节点后,我们大概知道每个Server(Node)是如何执行客户端申请以及Server集群内部是如何完成最终一致性协同的过程。
比如Client对任一类节点发起读操作,则每个节点均可立即返回本地数据,如此便提高了响应性能;
比如Client对Follower节点发起写操作,则它会写命令转交Leader完成,最后由Leader完成写操作和数据同步;
比如Leader发生宕机,则Follower们立即启动选举,任命新的Leader。而Observer完全可以“袖手旁观,置之不理”,此刻真是“开心开心极了...”

2. 基础协议
为了实现上述一致性数据同步,ZooKeeper基于ZAB(Zookeeper Atomic Broadcast 原子广播协议)完成的。
ZAB准确来讲提供了一套完整的数据同步消息机制。(无论哪类节点)从接收客户端请求到客户端收到实时数据,并实现集群内部数据写操作的一致性,均是通过ZAB机制完成的。

通过上图,我们了解到,Leader负责处理写请求,如其他节点接收到写请求,需转发Leader完成。那么Leader收到请求后,如何继续工作呢?
- 发布全局唯一事务申请zxid(
zxid是64位的Long类型); - 所有的
Follower均对此申请进行反馈; Leader如收到反馈过半,则执行写提交,最后完成集群同步;
Q:集群选举如何进行的
我们都知道Leader至关重要,是维持ZooKeeper的集群健康运转的大脑。但天有不测风云,即使7*24高可用高可靠,也难免百密一疏。如果Leader真的宕机了? 如何维持集群秩序呢?
接下来,博主带着各位盆友,继续揭秘ZooKeeper中 Leader的选举过程。
既然有选举,就有投票,有投票,就有候选人,有投票人。那么候选人和投票人是怎么产生的,最终谁才能胜任?
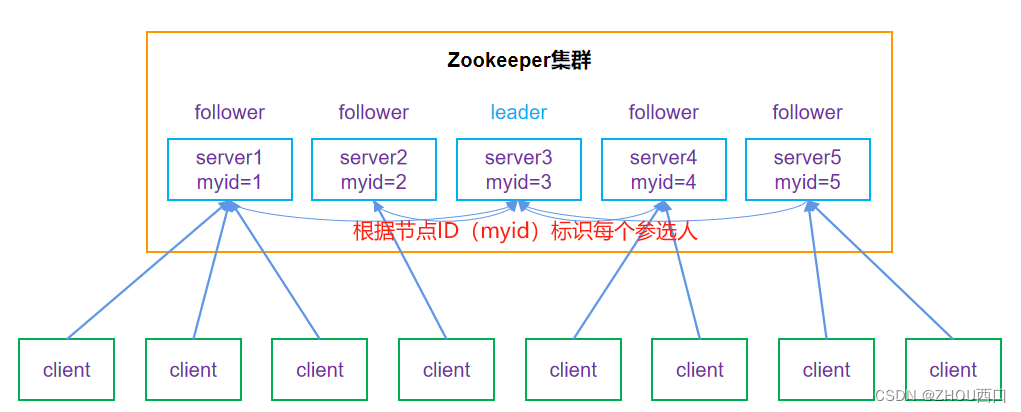
在正式讲解选项过程前,我们先了解一些基础知识。
1. 节点状态
在ZooKeeper集群中,涉及4中状态:
| 节点状态 | 简介 |
|---|---|
| LOOKING | 寻 找 Leader 状态,即开始选举的初始状态 |
| FOLLOWING | 跟随者状态,表明当前节点为Follower |
| LEADING | 领袖状态,表明当前节点为Leader |
| OBSERVING | 观察者状态,表明当前节点为Observer |
2. 节点ID
我们在搭建ZooKeeper集群时,一般需要为每个Server(Node)标识一个唯一的编号(从小到大,比如1.2.3,以此类推)。
这个ID一般记录在每个ZooKeeper Server中的数据文件中,安装时指定。
3. 奇数
ZooKeeper集群信仰奇数,为什么? 因为有“过半才OK”的理念。
所以我们在搭建集群时,务必按要求配置,否则ZooKeeper可能无法正常工作哦。
4. 投票选举Leader
| 选举场景 | 简介 |
|---|---|
| 启动时 | 选择此刻集群中的节点ID最大者投票。当然开始时,均可为自己投票,实时更新状态 |
| 故障恢复时 | 根据ZXID顺序,优先执行,并选择此刻集群中的节点ID最大者投票 |
投票结束后,收到票数过半者则当选新一任Leader,其他节点自动更新为Follower,而Observer自必不说,全程不参与。
到此为止,我们具备了以上基础知识后,继续回看上图,是不是可以理解了?
结语
博主通过揭秘ZooKeeper内在的核心逻辑,剖析它是如何完成我们想象中的职责和工作的。通过以上内容,我们可以发现,无论是什么协议或算法,均服务于某个业务和技术场景。所以感谢前辈们的辛勤耕耘,才有ZooKeeper的用武之地。
历史回顾
- 微服务实战系列之ZooKeeper(上)
- 微服务实战系列之MQ
- 微服务实战系列之通信
- 微服务实战系列之J2Cache
- 微服务实战系列之Cache(技巧篇)
- 微服务实战系列之MemCache
- 微服务实战系列之EhCache
- 微服务实战系列之Redis
- 微服务实战系列之Cache
- 微服务实战系列之Nginx(技巧篇)
- 微服务实战系列之Nginx
- 微服务实战系列之Feign
- 微服务实战系列之Sentinel
- 微服务实战系列之Token
- 微服务实战系列之Nacos
- 微服务实战系列之Gateway
- 微服务实战系列之加密RSA
- 微服务实战系列之签名Sign

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- vectorCast基于分类树设计测试用例
- Java基础 |数组排序
- 1 电科院FTU检测标准学习笔记-外观检查
- pdmaner从pg数据库导入表结构,无法筛选schema的问题处理
- HOOPS助力AVEVA数字化转型:支持多种3D模型格式转换!
- ArchVizPRO Interior Vol.8 URP
- 详解FreeRTOS:如何查询任务状态(拓展篇—6)
- 别再使用 RestTemplate了,试试官方推荐的 WebClient !
- 51单片机之按键和数码管
- 003 Windows用户与组管理