C++内联函数与引用(超详细)
前言
一、内联函数
1.为什么会存在内联函数
🧐🧐首先我们介绍内联函数之前,首先看一下我们之前学过的#define 定义的宏
写一个宏函数,实现两个函数的相加
#include <iostream>
using namespace std;
#define ADD(x,y) ((x)+(y))
int main()
{
int a = 10;
int b = 20;
cout << ADD(a,b) << endl;
return 0;
}
想想我们当初学习宏函数的的优点和缺点
??优点:这些函数我们也可以用函数来实现,但是函数调用需要开辟栈帧,浪费空间,
而宏就完美解决了这个问题,它会在调用它的地方展开。进行完全替换。
??缺点:不能调试,使用起来复杂,没有安全类型的检查,代码可读性差
那我们可不可以实现一个专门的库函数,既包含宏的有点又避免了函数调用的缺点呢??
这时内联函数就出现了!!!
2.什么是内联函数
? ?概念:用inline修饰的函数就是内联函数,编译时C++编译器会在调用的地方展开,没有函数调用建立栈帧的开销,提高程序运行效率。
int add(int x, int y)
{
return x + y;
}
int main()
{
int a = 10;
int b = 20;
int ret = add(a, b);
cout << ret<< endl;
return 0;
}
我们转到反汇编看一下这段代码
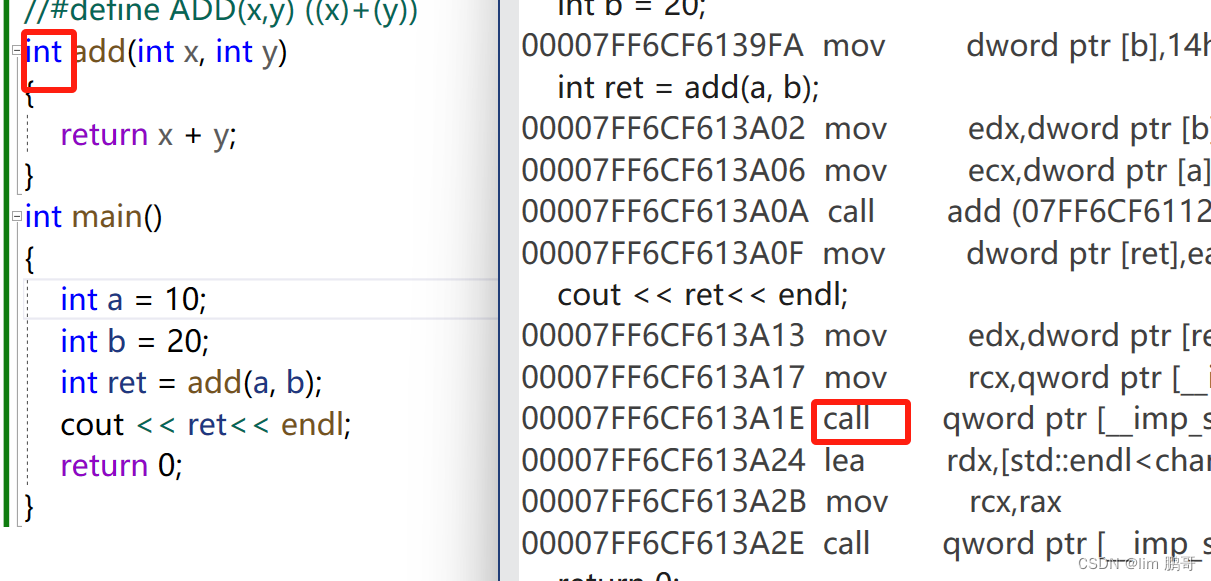
在正常情况下,没有加内联函数确实进行了函数调用建立栈帧。
我们加上内联函数再来看一下
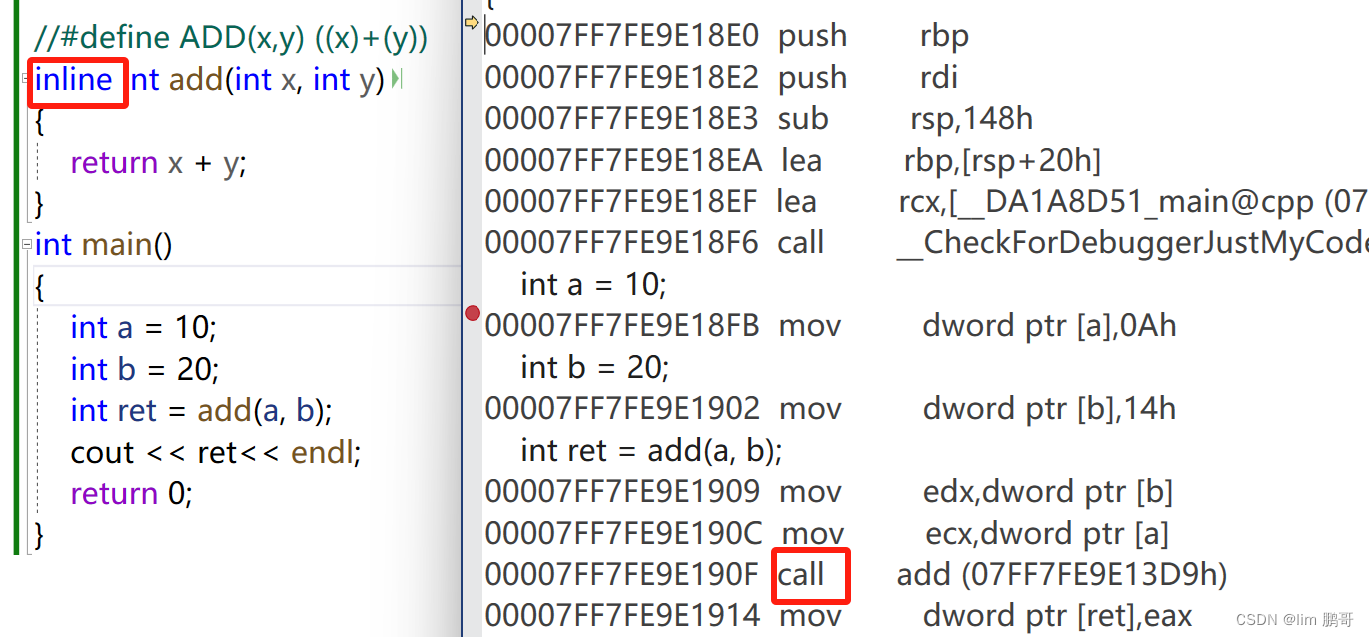
我们发现怎末跟上面代码一样,都调用了add函数,建立了栈帧。这厮怎末回事???
这是因为在Debug模式下,方便调试,编译器默认不进行优化,也就是不进行展开,依然使用一般的函数调用。
我们对vs设置一下环境
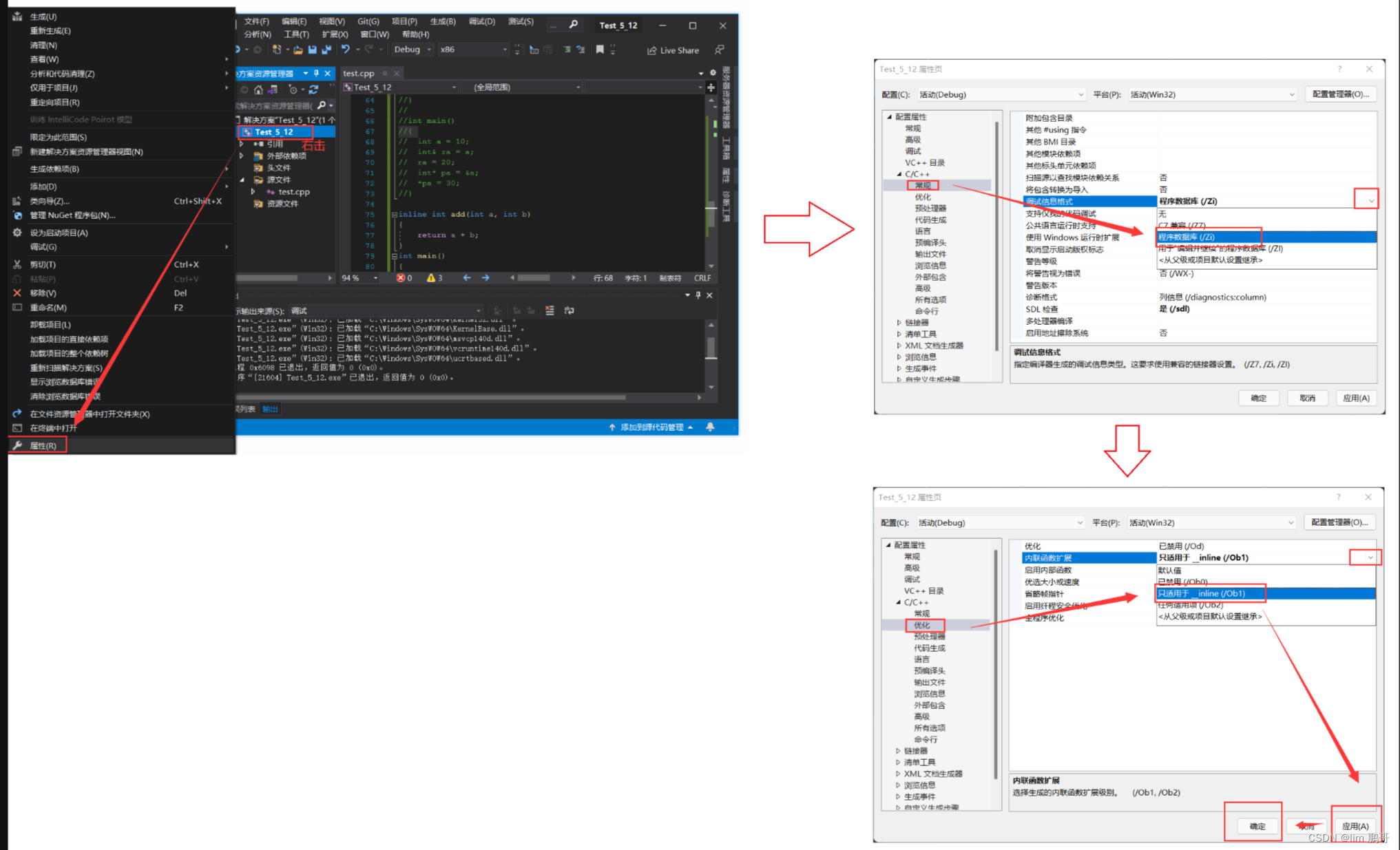
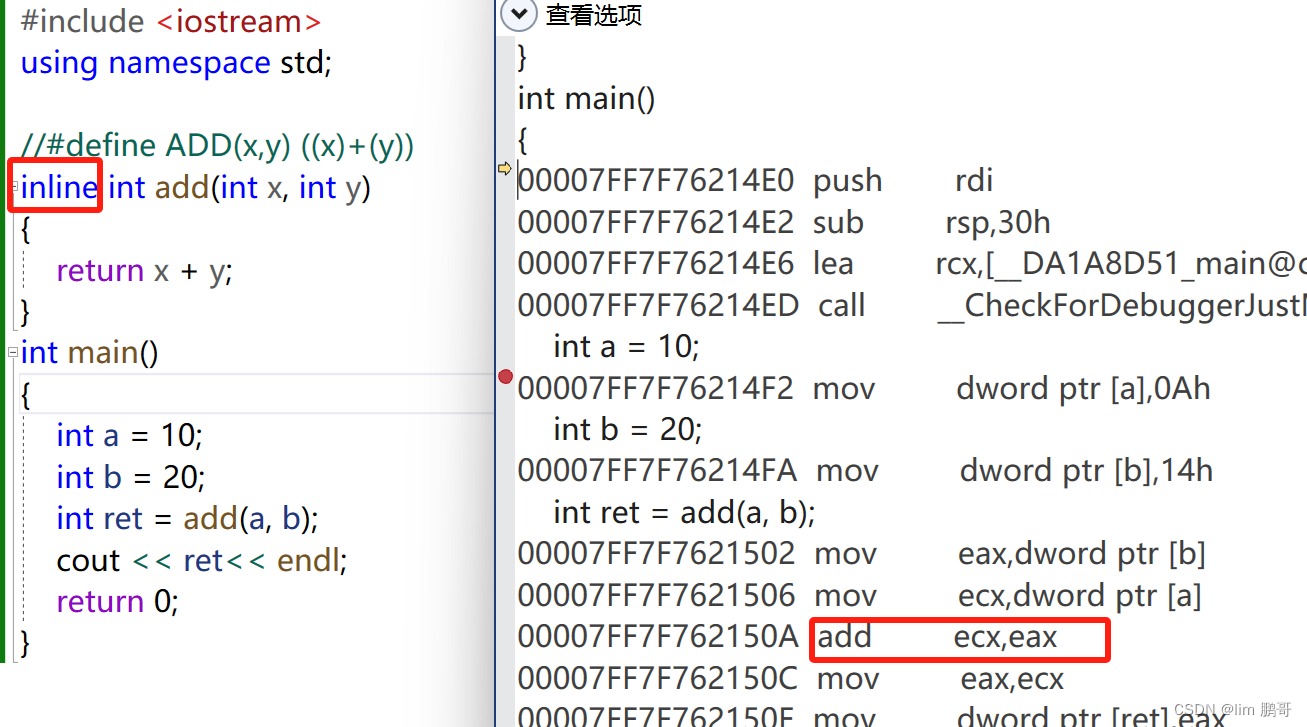
可以看到,优化之后inline修饰过的函数会直接展开。
也就是说,在Debug模式下你写代码、调试代码时,inline 相当于普通函数,可以进行调试;在release模式下,又可直接进行原地展开,提高效率(这里指的是避免了调用函数、创建栈帧等方面的资源消耗)
3.内联函数注意事项
🎇🎇内联函数是一种以空间换时间的方法,如果编译器将函数当成内联函数处理,在编译阶段,会当成函数体替换来调用。
缺陷:函数体目标变大
优势:少了调用开销,提高程序运行效率
🎇🎇内联函数对于编译器来说,只是一个建议,不同编译器关于inline实现机制可能不同,一般建议函数规模较小的,不是递归实现,调用频繁的采用内联函数修饰,否则编译器会忽略inline的特性
🎇🎇inline不建议声明和定义分离,分离会导致链接错误。因为inline被展开,就没有函数地址了,链接就会找不到。
main.cpp
#include "add.h"
int main()
{
int ret = add(10, 20);
cout << ret<< endl;
return 0;
}
add.cpp
#include "add.h"
inline int add(int x, int y)
{
return x + y;
}
add.h
#include <iostream>
using namespace std;
inline int add(int x, int y);
严重性 代码 说明 项目 文件 行 禁止显示状态
错误 LNK2019 无法解析的外部符号 “int __cdecl add(int,int)” (?add@@YAHHH@Z),函数 main 中引用了该符号 12_29 D:\study C\c嘎嘎\12_29\12_29\main.obj 1
我们一般建议把内联函数放在一个文件夹中进行处理
#include <iostream>
using namespace std;
inline int add(int x, int y)
{
return x + y;
}
int main()
{
int ret = add(10, 20);
cout << ret<< endl;
return 0;
}
二、引用
1.什么是引用
其实引用就是给变量取别名,这个别名和这个变量共用同一块空间。
使用:类型名 &别名=变量名; 对别名的改变同样也改变变量名的值
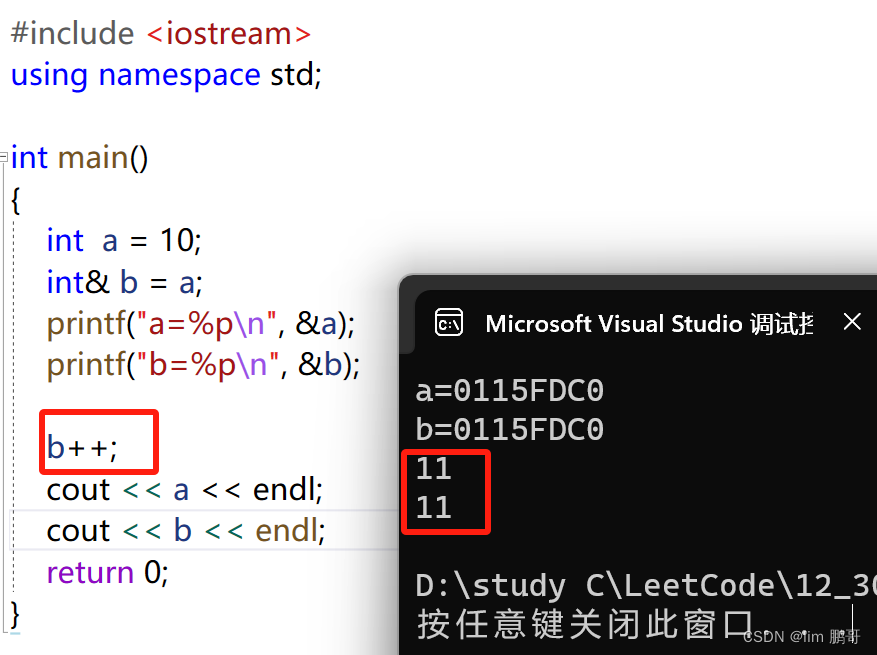
引用只能用于同类型变量才可以
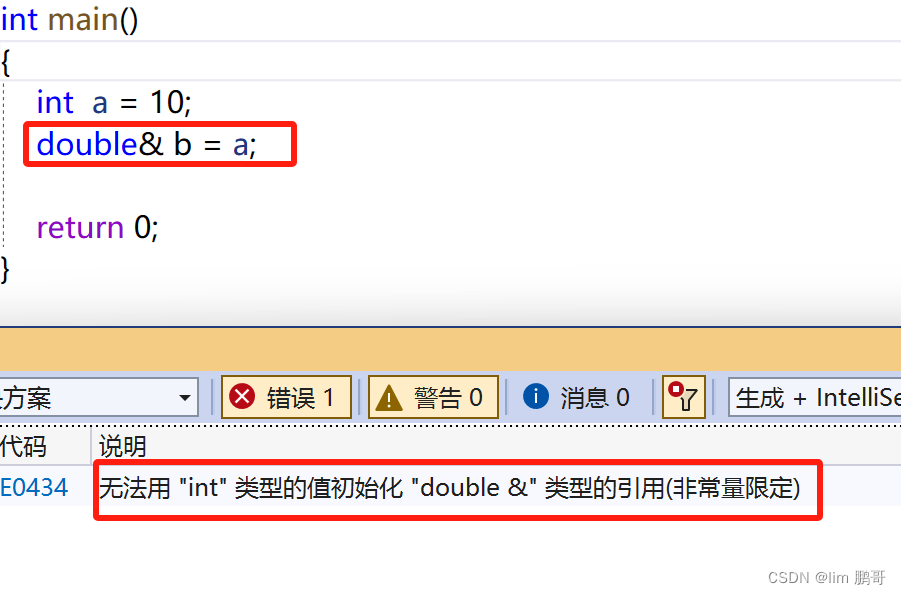
2.引用的特性
引用时必须初始化
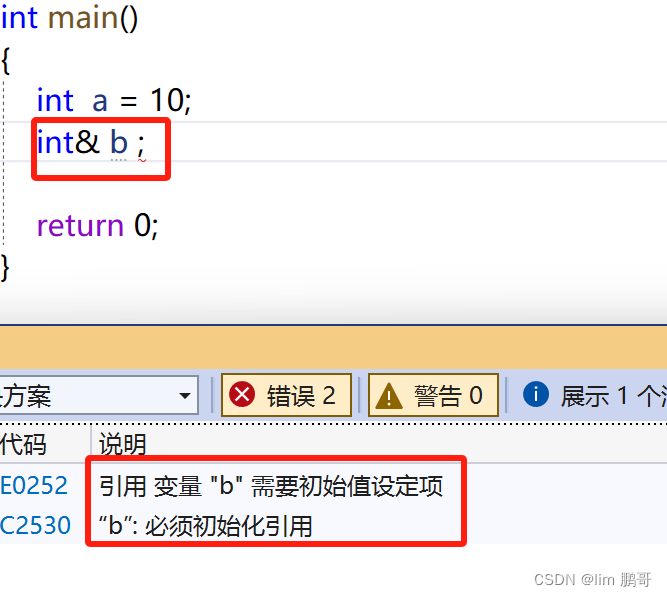
可以给一个变量取多个别名,也可以给别名起别名
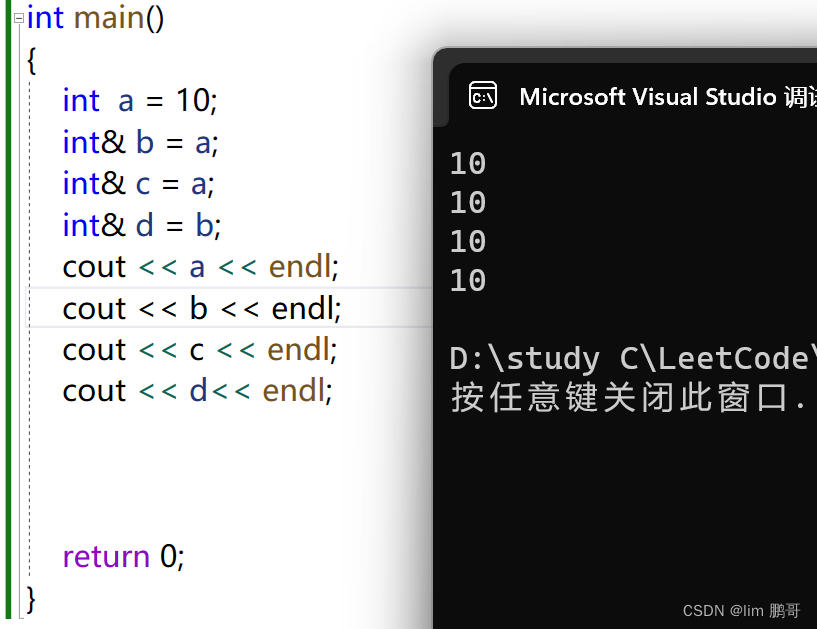
引用一旦引用了一个实体,就不可以在引用其他实体
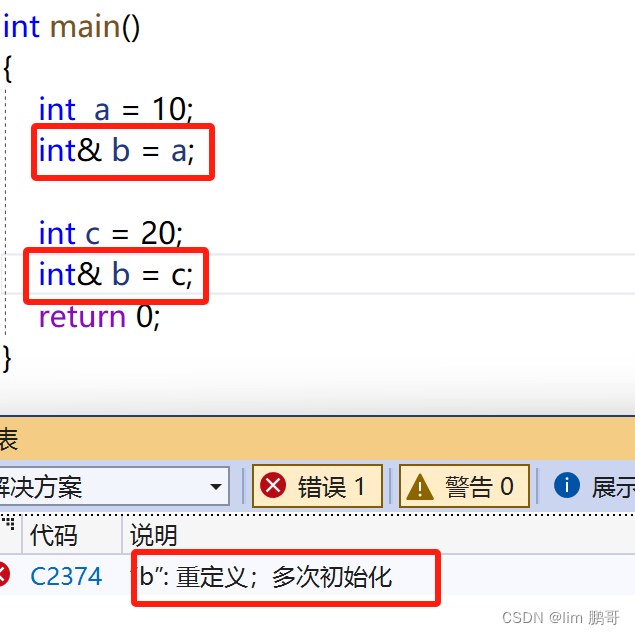
3.常引用
我们对引用加上const修饰后会发生什么呢???
权限不可以扩大,本来是const int 类型,现在变成了int类型
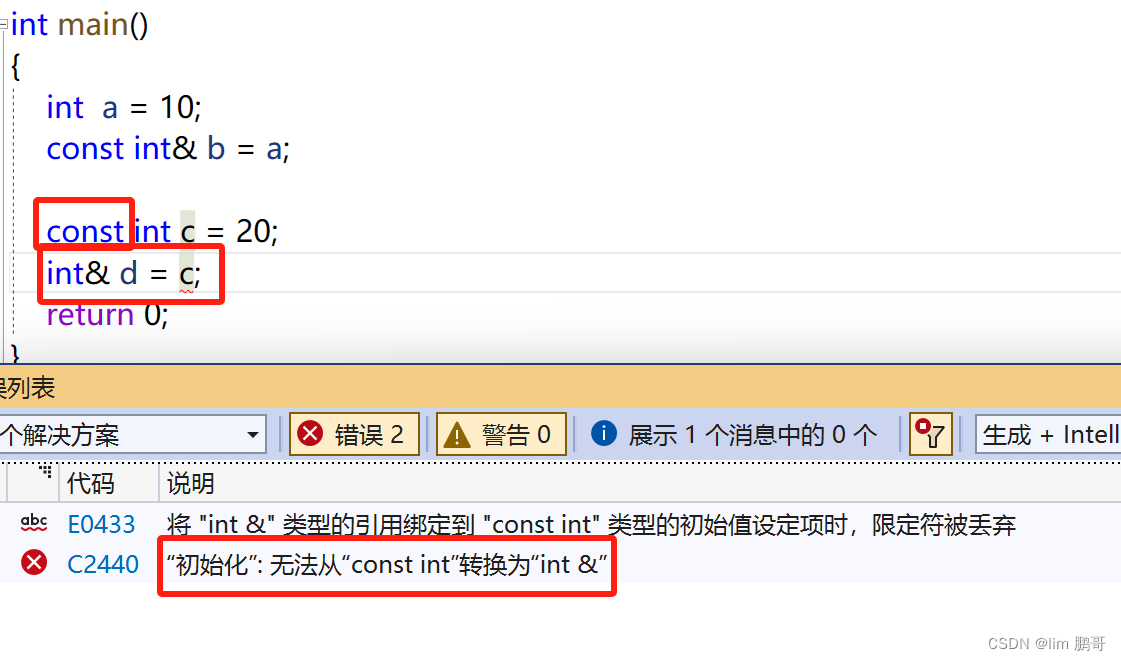
那我们如何进行修改呢??
只要在引用前边加上const就可以
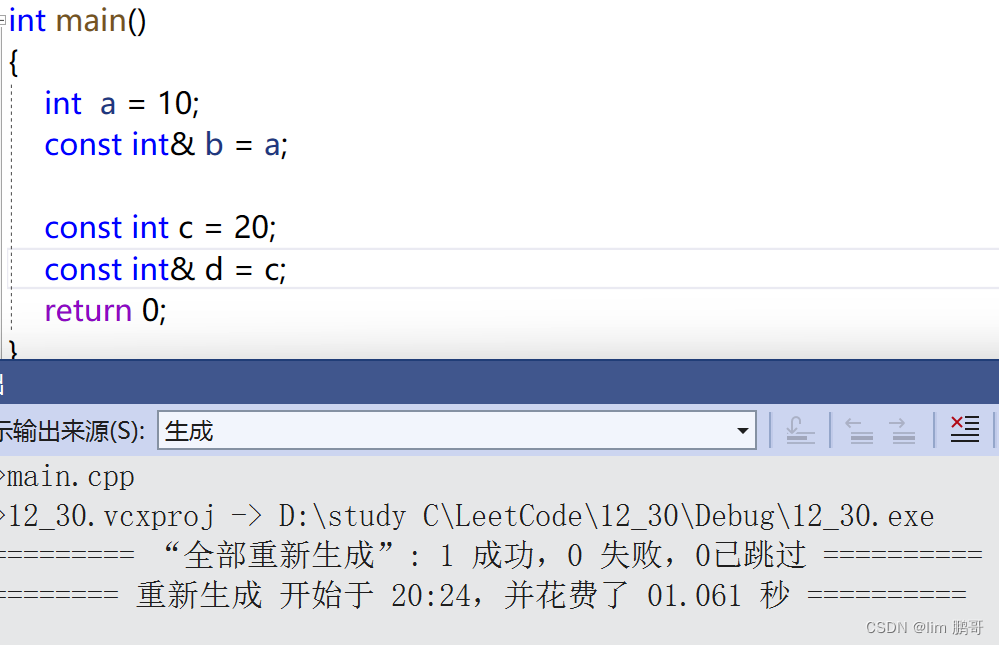
这其实就是权限的平移,本来是一个const int 类型,现在变成了const int 。两个权限一致
深度理解临时变量
我们看一下这段代码
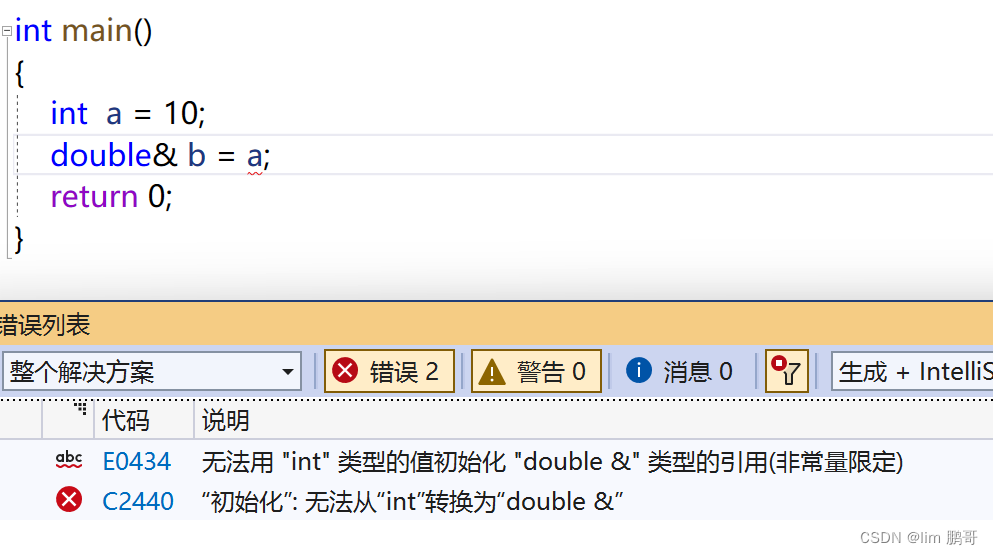
我们发现他出错了,但是为什么会出错呢??
有点人感觉这是类型不匹配导致的!!但其实并不是这样,他还有更深层次的理解
隐式类型转化,强转,截断都会发生产生临时变量,这个临时变量具有常性(不可被修改)
举个例子::
int a=10;double b=a;
这段代码肯定不会报错,会正常运行,但是他为什么可以实现呢???
本质是编译器把a那个变量进行了拷贝,产生了临时变量,通过这个临时变量取进行类型转化????
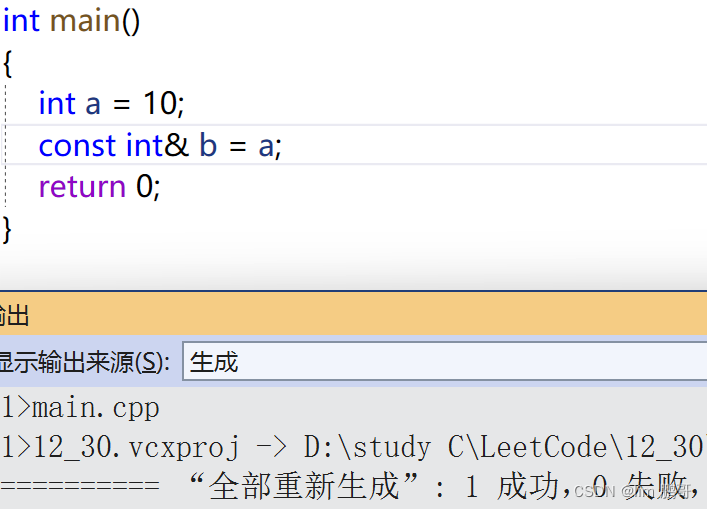
权限既然不能放大,那我们可不可以缩小呢??
这个其实是可以的,我们来具体看一下
4.引用使用场景
作为函数参数,进行传参,避免指针的使用错误
我们来回忆一下之前c语言通过一个函数对两个变量进行交换,我们的形参必须用指针才可以实现,是不是很麻烦,那这时我们就可以用引用来实现了!!!
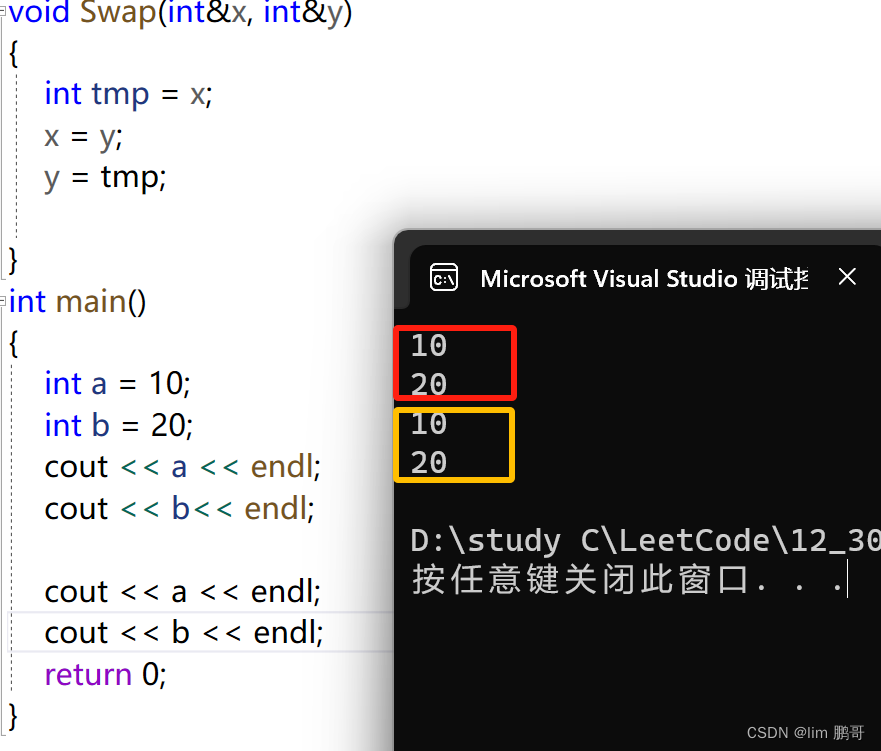
在这种场景下我们用引用就会非常方便
作为函数参数,进行传参,避免拷贝,提高程序运行效率
想想我们当时为什么会用指针来进行传参,比如我们传结构体传参,会生成一份原大小的拷贝,对资源浪费非常大。指针传参仅仅会拷贝4/8个字节,减少了空间的浪费。那我们也可以用引用来进行传参,南无连这个4/8个字节的拷贝也不需要了。
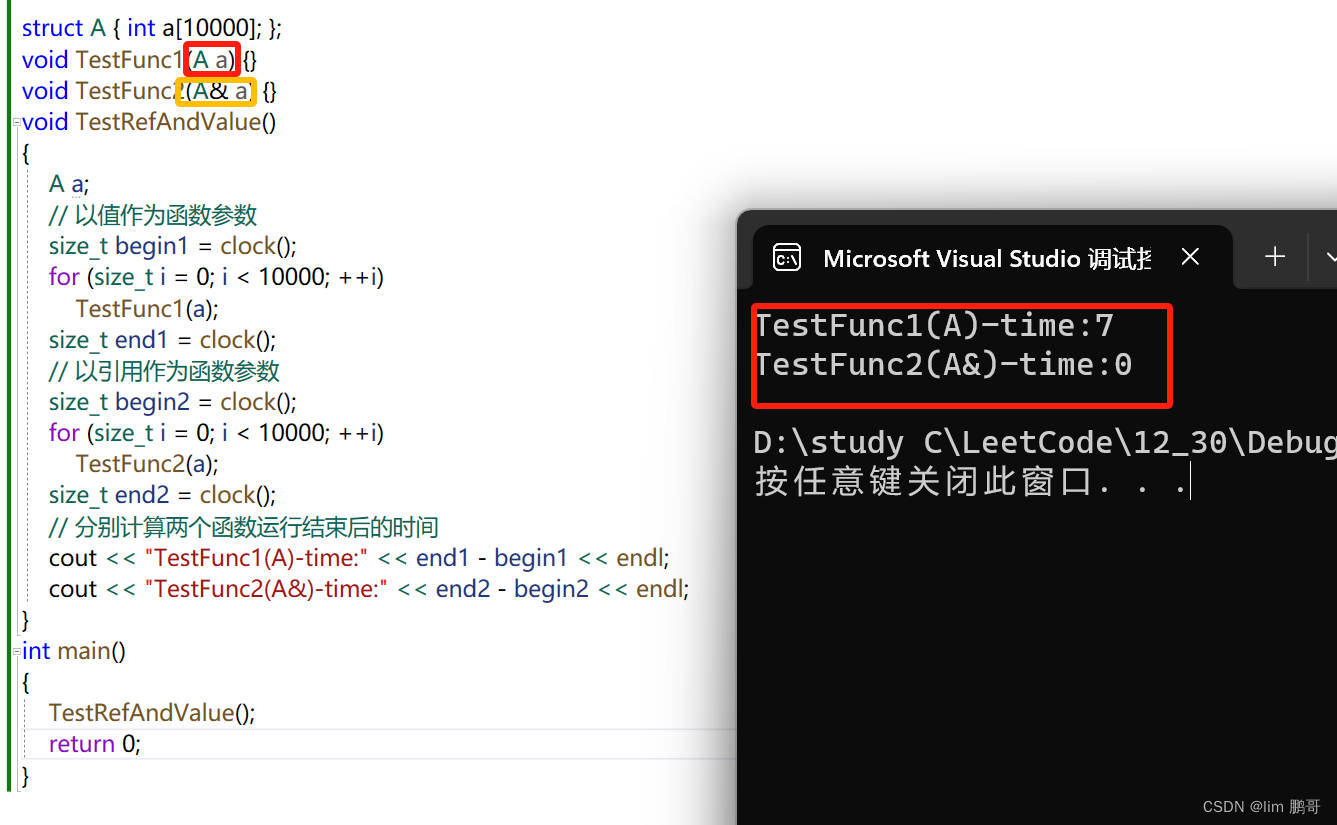
作为返回值,进行传参,避免拷贝,提高程序运行效率
我们知道调用函数,我们并不是返回的那个对象,而是那个对象那个的拷贝,我们也可以通过进行引用返回避免拷贝
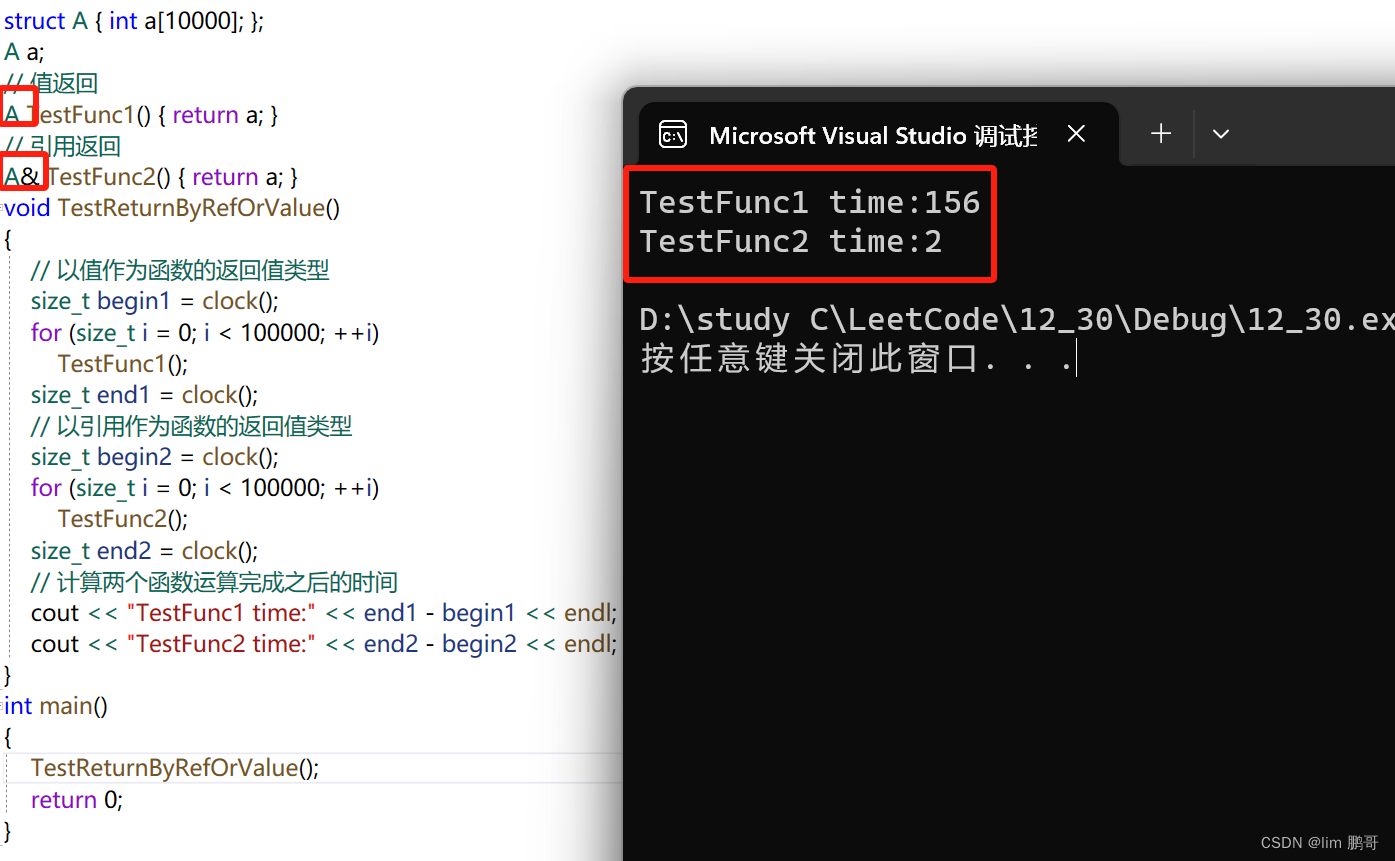
作为返回值,我们还可以对返回值进行修改,做返回值如果出了作用于还在,可以用传引用返回,如果出了作用域就不在了(销毁了),那就不能用传引用返回,只能用传值返回
5.引用与指针
在语法概念上,我们知道,引用就是一个别名,没有独立空间,和其引用实体共用同一块空间。

但是在底层上,我们会发现,引用也是用指针实现的
我们转到反汇编观察一下
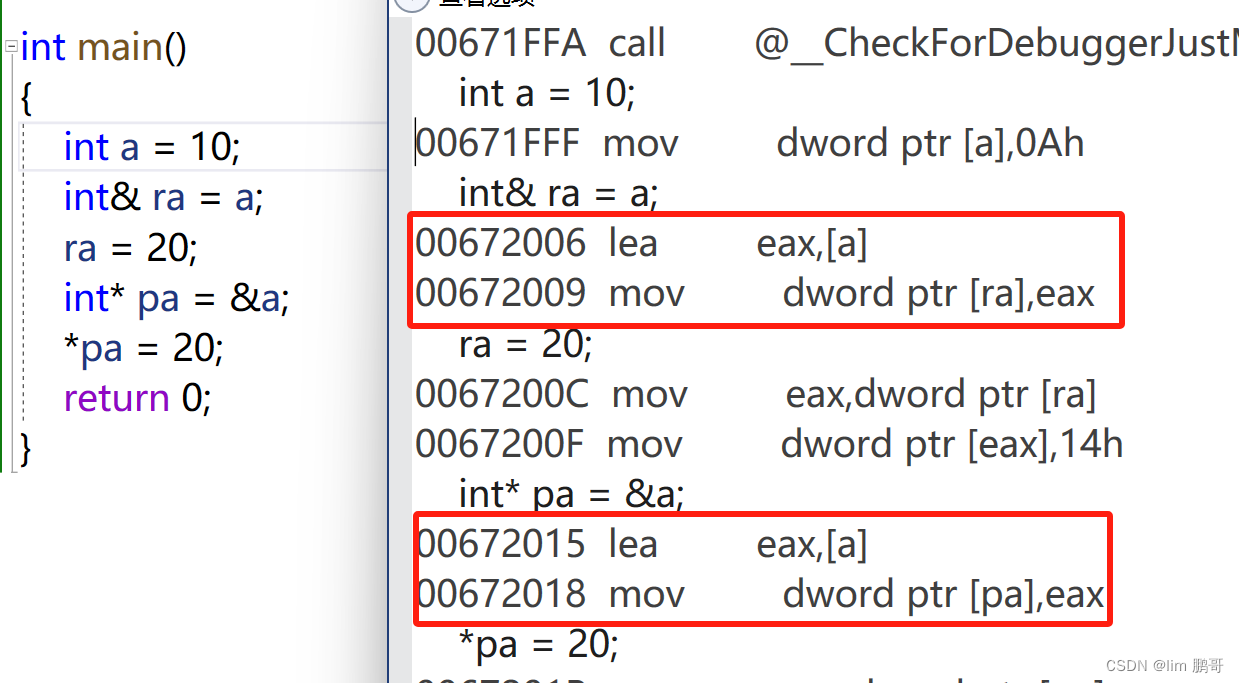
🌟指针存储一个变量地址,而引用是一个变量的别名
🌟引用必须初始化,指针没有要求
🌟引用一旦引用了一个实体,就不可以再引用其他实体。地址可以在任何时候指向一个
同类型的实体
🌟只有空指针,没有空引用
🌟只有多级指针,没有多级引用
🌟引用+1是指向的变量大小进行加一,指针+1是跳过一个指向类型的大小的地址
🌟引用大小为引用实体的大小,而指针的大小是4/8字节
🌟访问方式不同,指针需要解引用访问,引用编译器自己处理
🌟引用使用起来比指针相对安全
总结
以上就是今天要讲的内容,本文仅仅详细介绍了C++内联函数与引用,希望对大家的学习有所帮助,仅供参考 如有错误请大佬指点我会尽快去改正 欢迎大家来评论~~ 😘 😘 😘 😘
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 动态启停kafka消费者
- 【技术前沿】数字孪生技术助推城市智慧供热:探讨换热站3D可视化的创新之路
- 全功能知识付费小程序源码系统,开发组合:PHP+MySQL,效率提升到商业变现的互联网解决方案 附带完整的搭建教程
- 【FPGA】分享一些FPGA入门学习的书籍
- uniCloud 云数据库(1)
- 美多商城用户注册-展示用户注册页面-补充短信验证码后端逻辑-避免频发发送-pipeline操作redis-7...
- 影视动画行业发展现状与方向:AI技术推动动画工业化体系新变革
- pixel_avg2_w20_neon x264像素宽度为20的均值计算
- leetcode 每日一题 2024年01月07日 赎金信
- 抖音外卖怎么加盟代理,附免费申请攻略!