【Flink-1.17-教程】-【二】Flink 集群搭建、Flink 部署、Flink 运行模式
【Flink-1.17-教程】-【二】Flink 集群搭建、Flink 部署、Flink 运行模式
1)集群角色
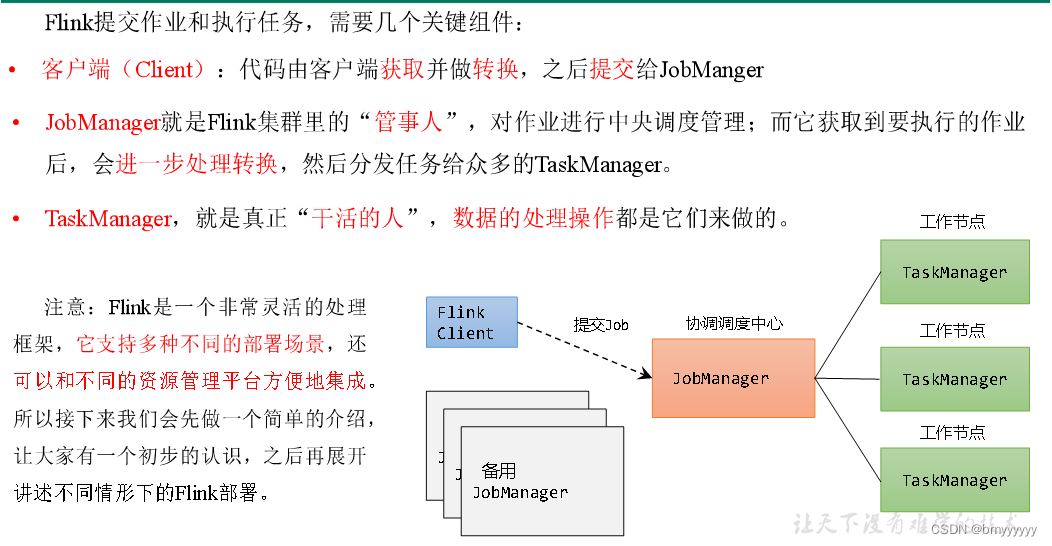
2)Flink 集群搭建
2.1.集群启动
集群规划:

具体安装部署步骤如下:
1、下载并解压安装包
(1)下载安装包 flink-1.17.0-bin-scala_2.12.tgz,将该 jar 包上传到 hadoop102 节点服务器的 /opt/software 路径上。
(2)在 /opt/software 路径上解压 flink-1.17.0-bin-scala_2.12.tgz 到 /opt/module 路径上。
[atguigu@hadoop102 software]$ tar -zxvf flink-1.17.0-bin-scala_2.12.tgz -C /opt/module/
2、修改集群配置
(1)进入 conf 路径,修改 flink-conf.yaml 文件,指定 hadoop102 节点服务器为 JobManager
[atguigu@hadoop102 conf]$ vim flink-conf.yaml
修改如下内容:
# JobManager节点地址.
jobmanager.rpc.address: hadoop102
jobmanager.bind-host: 0.0.0.0
rest.address: hadoop102
rest.bind-address: 0.0.0.0
# TaskManager节点地址.需要配置为当前机器名
taskmanager.bind-host: 0.0.0.0
taskmanager.host: hadoop102
(2)修改 workers 文件,指定 hadoop102、hadoop103 和 hadoop104 为 TaskManager
[atguigu@hadoop102 conf]$ vim workers
修改如下内容:
hadoop102
hadoop103
hadoop104
(3)修改 masters 文件
[atguigu@hadoop102 conf]$ vim masters
修改如下内容:
hadoop102:8081
(4)另外,在 flink-conf.yaml 文件中还可以对集群中的 JobManager 和 TaskManager 组件进行优化配置,主要配置项如下:
- jobmanager.memory.process.size:对 JobManager 进程可使用到的全部内存进行配置,包括 JVM 元空间和其他开销,默认为 1600M,可以根据集群规模进行适当调整。
- taskmanager.memory.process.size:对 TaskManager 进程可使用到的全部内存进行配置,包括 JVM 元空间和其他开销,默认为 1728M,可以根据集群规模进行适当调整。
- taskmanager.numberOfTaskSlots:对每个 TaskManager 能够分配的 Slot 数量进行配置,默认为1,可根据 TaskManager 所在的机器能够提供给 Flink 的 CPU 数量决定。所谓 Slot 就是 TaskManager 中具体运行一个任务所分配的计算资源。
- parallelism.default:Flink 任务执行的并行度,默认为 1。优先级低于代码中进行的并行度配置和任务提交时使用参数指定的并行度数量。
关于 Slot 和并行度的概念,我们会在下一章做详细讲解。
3、分发安装目录
(1)配置修改完毕后,将Flink安装目录发给另外两个节点服务器。
[atguigu@hadoop102 module]$ xsync flink-1.17.0/
(2)修改hadoop103的 taskmanager.host
[atguigu@hadoop103 conf]$ vim flink-conf.yaml
修改如下内容:
# TaskManager节点地址.需要配置为当前机器名
taskmanager.host: hadoop103
(3)修改hadoop104的 taskmanager.host
[atguigu@hadoop104 conf]$ vim flink-conf.yaml
修改如下内容:
# TaskManager节点地址.需要配置为当前机器名
taskmanager.host: hadoop104
4、启动集群
(1)在hadoop102 节点服务器上执行 start-cluster.sh 启动 Flink 集群:
[atguigu@hadoop102 flink-1.17.0]$ bin/start-cluster.sh
(2)查看进程情况:
[atguigu@hadoop102 flink-1.17.0]$ jpsall
=============== hadoop102 ===============
4453 StandaloneSessionClusterEntrypoint
4458 TaskManagerRunner
4533 Jps
=============== hadoop103 ===============
2872 TaskManagerRunner
2941 Jps
=============== hadoop104 ===============
2948 Jps
2876 TaskManagerRunner
jpsall 脚本:
#!/bin/bash
for host in hadoop102 hadoop103 hadoop104
do
echo ============ $host ===========
ssh $host jps $@ | grep -v Jps
done
5、访问 Web UI
启动成功后,同样可以访问 http://hadoop102:8081 对flink集群和任务进行监控管理。
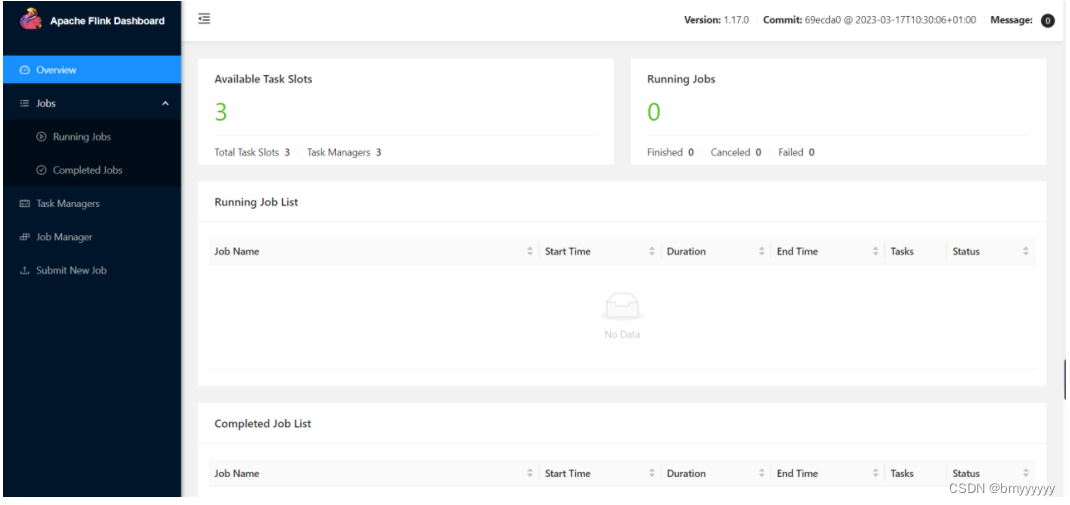
这里可以明显看到,当前集群的 TaskManager 数量为 3;由于默认每个 TaskManager 的 Slot 数量为 1,所以总 Slot 数和可用 Slot 数都为 3。
2.2.向集群提交作业
在上一章中,我们已经编写读取 socket 发送的单词并统计单词的个数程序案例。本节我们将以该程序为例,演示如何将任务提交到集群中进行执行。具体步骤如下。
1、环境准备
在 hadoop102 中执行以下命令启动 netcat。
[atguigu@hadoop102 flink-1.17.0]$ nc -lk 7777
2、程序打包
(1)在我们编写的 Flink 入门程序的 pom.xml 文件中添加打包插件的配置,具体如下:
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.2.4</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<artifactSet>
<excludes>
<exclude>com.google.code.findbugs:jsr305</exclude>
<exclude>org.slf4j:*</exclude>
<exclude>log4j:*</exclude>
</excludes>
</artifactSet>
<filters>
<filter>
<!-- Do not copy the signatures in
the META-INF folder.
Otherwise, this might cause
SecurityExceptions when using the JAR. -->
<artifact>*:*</artifact>
<excludes>
<exclude>METAINF/*.SF</exclude>
<exclude>METAINF/*.DSA</exclude>
<exclude>METAINF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers combine.children="append">
<transformer
implementation="org.apache.maven.plugins.shade.resource.ServicesRes
ourceTransformer">
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
(2)插件配置完毕后,可以使用 IDEA 的 Maven 工具执行 package 命令,出现如下提示即表示打包成功。
-------------------------------------------------------------------
[INFO] BUILD SUCCESS
-------------------------------------------------------------------
打包完成后,在 target 目录下即可找到所需 JAR 包,JAR 包会有两个,FlinkTutorial-1.0-SNAPSHOT.jar 和 FlinkTutorial-1.0-SNAPSHOT-jar-with-dependencies.jar,因为集群中已经具备任务运行所需的所有依赖,所以建议使用 FlinkTutorial-1.0-SNAPSHOT.jar。
3、在 Web UI 上提交作业
(1)任务打包完成后,我们打开 Flink 的 WEB UI 页面,在右侧导航栏点击“Submit New Job”,然后点击按钮“+ Add New”,选择要上传运行的 JAR 包,如下图所示。
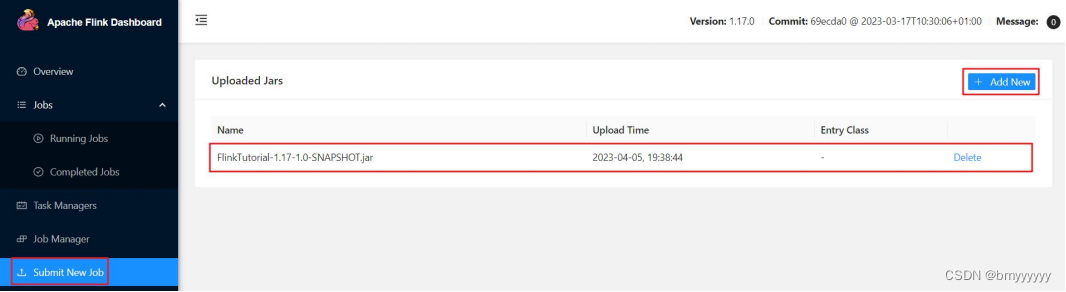
JAR 包上传完成,如下图所示:
(2)点击该 JAR 包,出现任务配置页面,进行相应配置。
主要配置程序入口主类的全类名,任务运行的并行度,任务运行所需的配置参数和保存点路径等,如下图所示,配置完成后,即可点击按钮“Submit”,将任务提交到集群运行。
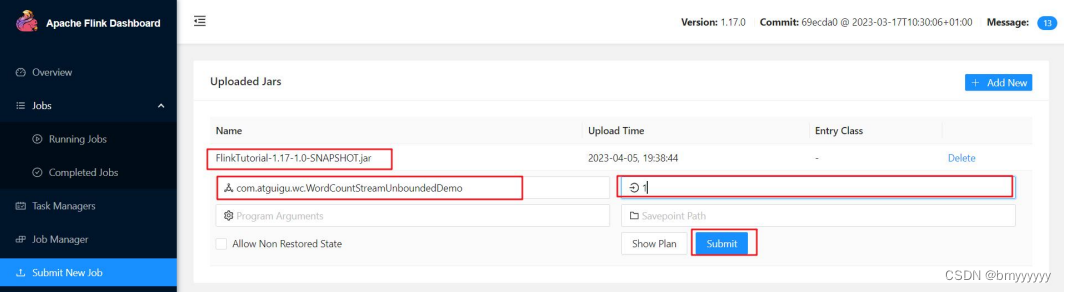
(3)任务提交成功之后,可点击左侧导航栏的“Running Jobs”查看程序运行列表情况。
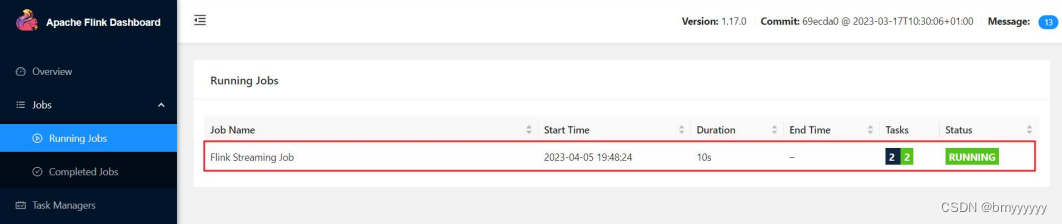
(4)测试
① 在 socket 端口中输入 hello
[atguigu@hadoop102 flink-1.17.0]$ nc -lk 7777
hello
② 先点击 Task Manager,然后点击右侧的 192.168.10.104 服务器节点
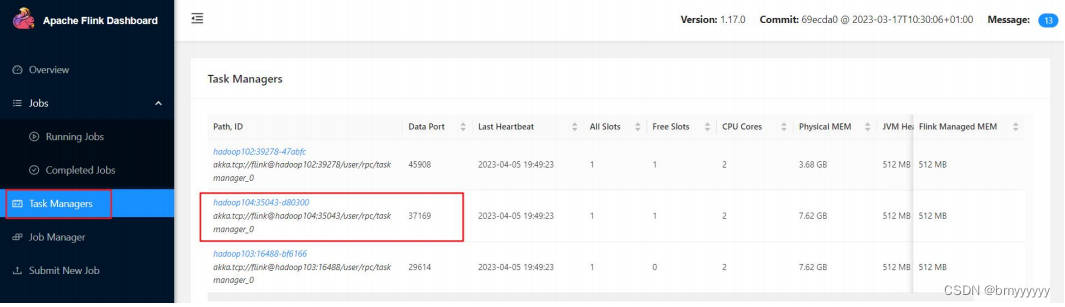
③ 点击 Stdout,就可以看到 hello 单词的统计
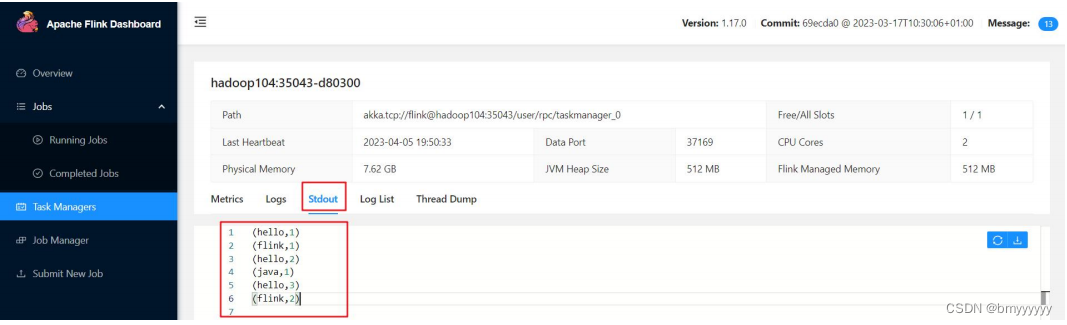
注意:如果 hadoop104 节点没有统计单词数据,可以去其他 TaskManager 节点查看。
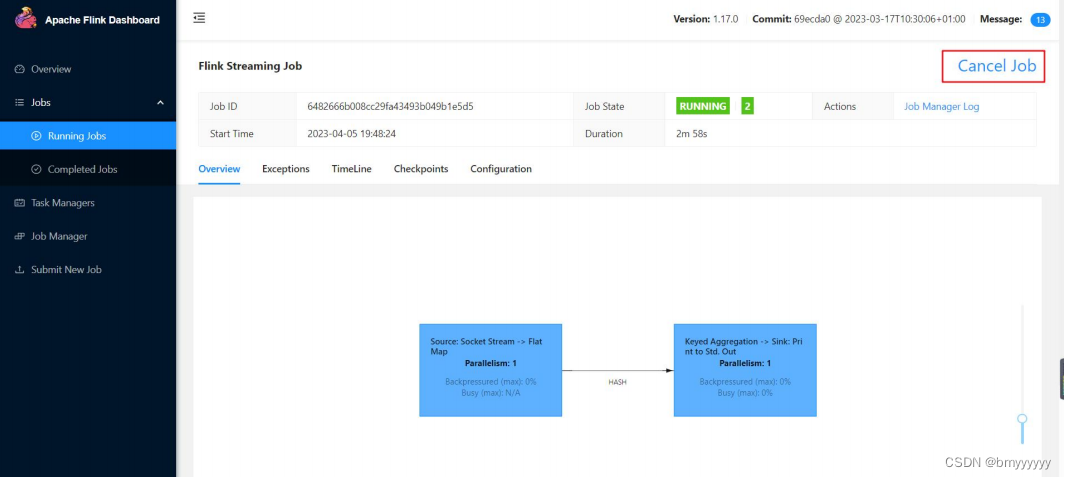
(5)点击该任务,可以查看任务运行的具体情况,也可以通过点击“Cancel Job”结束任务运行。
4、命令行提交作业
除了通过 WEB UI 界面提交任务之外,也可以直接通过命令行来提交任务。这里为方便起见,我们可以先把 jar 包直接上传到目录 flink-1.17.0 下
(1)首先需要启动集群。
[atguigu@hadoop102 flink-1.17.0]$ bin/start-cluster.sh
(2)在 hadoop102 中执行以下命令启动 netcat。
[atguigu@hadoop102 flink-1.17.0]$ nc -lk 7777
(3)将 flink 程序运行 jar 包上传到/opt/module/flink-1.17.0 路径。
(4)进入到 flink 的安装路径下,在命令行使用 flink run 命令提交作业。
[atguigu@hadoop102 flink-1.17.0]$ bin/flink run -m hadoop102:8081 -c com.atguigu.wc.SocketStreamWordCount ./FlinkTutorial-1.0-SNAPSHOT.jar
这里的参数 -m 指定了提交到的 JobManager,-c 指定了入口类。
(5)在浏览器中打开 Web UI,http://hadoop102:8081 查看应用执行情况。用 netcat 输入数据,可以在 TaskManager 的标准输出(Stdout)看到对应的统计结果。
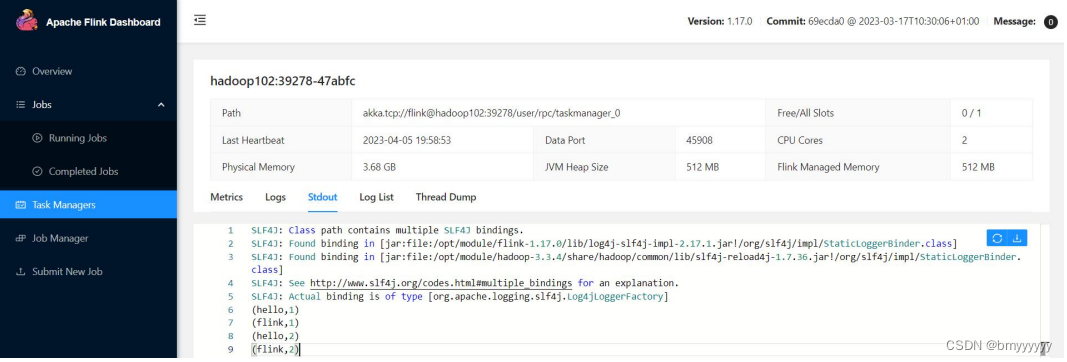
(6)在 /opt/module/flink-1.17.0/log 路径中,可以查看 TaskManager 节点。
[atguigu@hadoop102 log]$ cat flink-atguigu-standalonesession-0-hadoop102.out
(hello,1)
(hello,2)
(flink,1)
(hello,3)
(scala,1)
3)部署模式
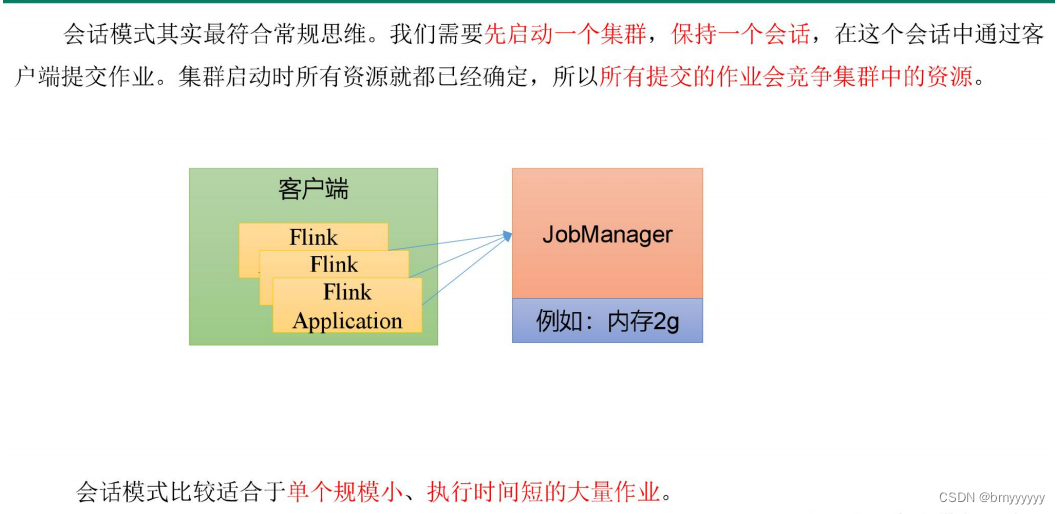
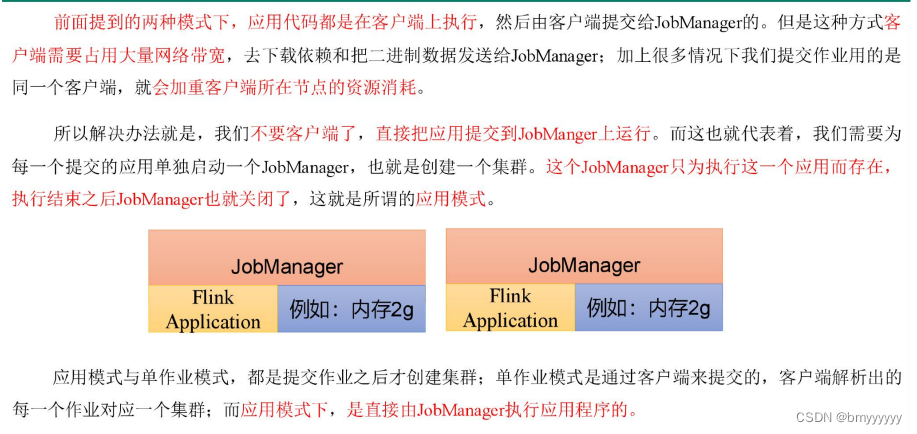
在一些应用场景中,对于集群资源分配和占用的方式,可能会有特定的需求。Flink 为各种场景提供了不同的部署模式,主要有以下三种:会话模式(Session Mode)、单作业模式(Per-Job Mode)、应用模式(Application Mode)。
它们的区别主要在于:集群的生命周期以及资源的分配方式;以及应用的 main 方法到底在哪里执行——客户端(Client)还是 JobManager。
3.1.会话模式(Session Mode)
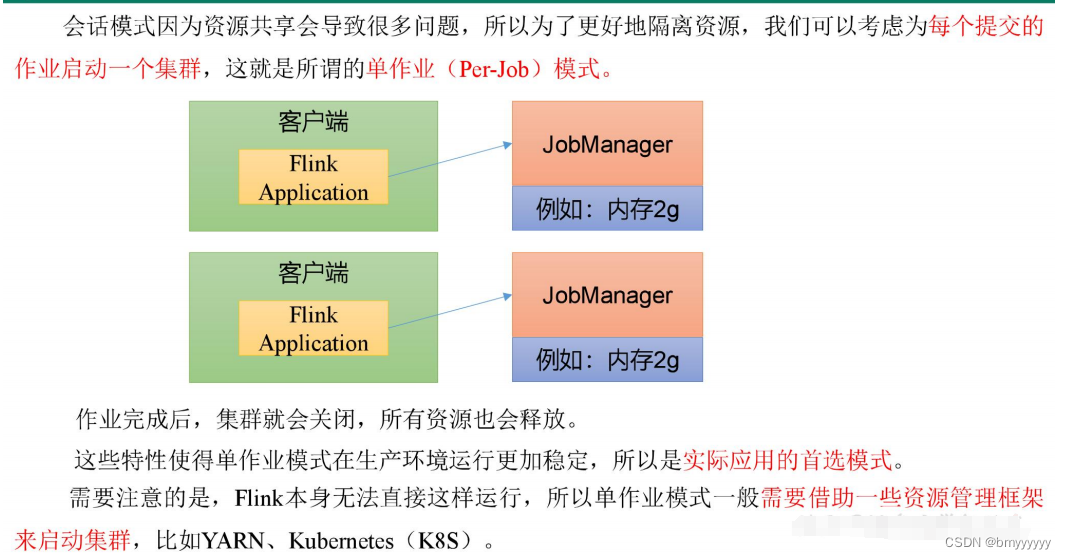
3.2.单作业模式(Per-Job Mode)
3.3.应用模式(Application Mode)
这里我们所讲到的部署模式,相对是比较抽象的概念。实际应用时,一般需要和资源管理平台结合起来,选择特定的模式来分配资源、部署应用。接下来,我们就针对不同的资源提供者的场景,具体介绍 Flink 的部署方式。
3.4.Standalone 运行模式(了解)
独立模式是独立运行的,不依赖任何外部的资源管理平台;当然独立也是有代价的:如果资源不足,或者出现故障,没有自动扩展或重分配资源的保证,必须手动处理。所以独立模式一般只用在开发测试或作业非常少的场景下。
3.4.1.会话模式部署
我们在第 2)节用的就是 Standalone 集群的会话模式部署。
提前启动集群,并通过 Web 页面客户端提交任务(可以多个任务,但是集群资源固定)。

3.4.2.单作业模式部署
Flink 的 Standalone 集群并不支持单作业模式部署。因为单作业模式需要借助一些资源管理平台。
3.4.3.应用模式部署
应用模式下不会提前创建集群,所以不能调用 start-cluster.sh 脚本。我们可以使用同样在 bin 目录下的 standalone-job.sh 来创建一个 JobManager。

具体步骤如下:
(0)环境准备。在 hadoop102 中执行以下命令启动 netcat。
[atguigu@hadoop102 flink-1.17.0]$ nc -lk 7777
(1)进入到 Flink 的安装路径下,将应用程序的 jar 包放到 lib/目录下。
[atguigu@hadoop102 flink-1.17.0]$ mv FlinkTutorial-1.0-SNAPSHOT.jar lib/
(2)执行以下命令,启动 JobManager。
[atguigu@hadoop102 flink-1.17.0]$ bin/standalone-job.sh start --job-classname com.atguigu.wc.SocketStreamWordCount
这里我们直接指定作业入口类,脚本会到 lib 目录扫描所有的 jar 包。
(3)同样是使用 bin 目录下的脚本,启动 TaskManager。
[atguigu@hadoop102 flink-1.17.0]$ bin/taskmanager.sh start
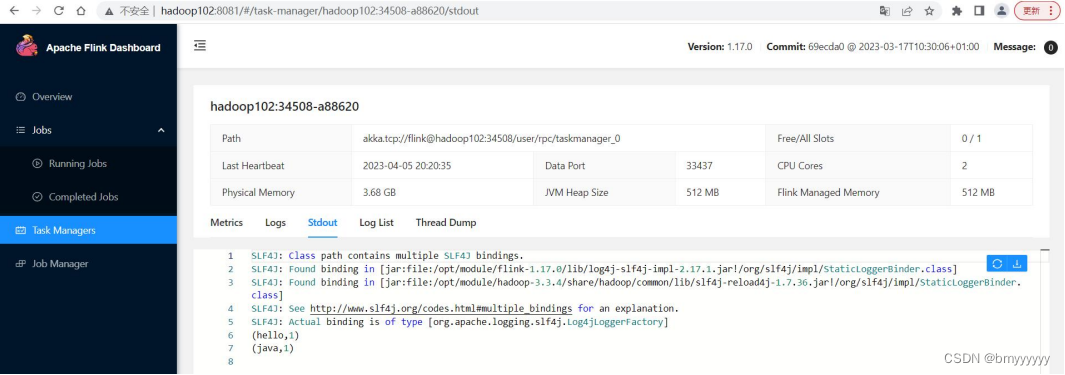
(4)在 hadoop102 上模拟发送单词数据。
[atguigu@hadoop102 ~]$ nc -lk 7777
hello
(5)在 hadoop102:8081 地址中观察输出数据
(6)如果希望停掉集群,同样可以使用脚本,命令如下。
[atguigu@hadoop102 flink-1.17.0]$ bin/taskmanager.sh stop
[atguigu@hadoop102 flink-1.17.0]$ bin/standalone-job.sh stop
3.5.YARN 运行模式(重点)
YARN 上部署的过程是:客户端把 Flink 应用提交给 Yarn 的 ResourceManager,Yarn 的 ResourceManager 会 向 Yarn 的 NodeManager 申 请 容 器 。 在 这 些 容 器 上 , Flink 会 部 署 JobManager 和 TaskManager 的实例,从而启动集群。Flink 会根据运行在 JobManger 上的作业所需要的 Slot 数量动态分配 TaskManager 资源。
3.5.1.相关准备和配置
在将 Flink 任务部署至 YARN 集群之前,需要确认集群是否安装有 Hadoop,保证 Hadoop 版本至少在 2.2 以上,并且集群中安装有 HDFS 服务。
具体配置步骤如下:
(1)配置环境变量,增加环境变量配置如下:
$ sudo vim /etc/profile.d/my_env.sh
HADOOP_HOME=/opt/module/hadoop-3.3.4
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export HADOOP_CLASSPATH=`hadoop classpath`
(2)启动 Hadoop 集群,包括 HDFS 和 YARN。
[atguigu@hadoop102 hadoop-3.3.4]$ start-dfs.sh
[atguigu@hadoop103 hadoop-3.3.4]$ start-yarn.sh
(3)在 hadoop102 中执行以下命令启动 netcat。
[atguigu@hadoop102 flink-1.17.0]$ nc -lk 7777
3.5.2.会话模式部署
YARN 的会话模式与独立集群略有不同,需要首先申请一个 YARN 会话(YARN Session)来启动 Flink 集群。具体步骤如下:
1、启动集群
(1)启动 Hadoop 集群(HDFS、YARN)。
(2)执行脚本命令向 YARN 集群申请资源,开启一个 YARN 会话,启动 Flink 集群。
[atguigu@hadoop102 flink-1.17.0]$ bin/yarn-session.sh -nm test
可用参数解读:
- -d:分离模式,如果你不想让 Flink YARN 客户端一直前台运行,可以使用这个参数,
即使关掉当前对话窗口,YARN session 也可以后台运行。 - -jm(–jobManagerMemory):配置 JobManager 所需内存,默认单位 MB。
- -nm(–name):配置在 YARN UI 界面上显示的任务名。
- -qu(–queue):指定 YARN 队列名。
- -tm(–taskManager):配置每个 TaskManager 所使用内存。
注意:Flink1.11.0 版本不再使用-n 参数和-s 参数分别指定 TaskManager 数量和 slot 数量,YARN 会按照需求动态分配 TaskManager 和 slot。所以从这个意义上讲,YARN 的会话模式也不会把集群资源固定,同样是动态分配的。
YARN Session 启动之后会给出一个 Web UI 地址以及一个 YARN application ID,如下所示,用户可以通过 Web UI 或者命令行两种方式提交作业。
2022-11-17 15:20:52,711 INFO org.apache.flink.yarn.YarnClusterDescriptor [] -Found Web Interface hadoop104:40825 of application
'application_1668668287070_0005'.
JobManager Web Interface: http://hadoop104:40825
2、提交作业
(1)通过 Web UI 提交作业
这种方式比较简单,与上文所述 Standalone 部署模式基本相同。
(2)通过命令行提交作业
① 将 FlinkTutorial-1.0-SNAPSHOT.jar 任务上传至集群。
② 执行以下命令将该任务提交到已经开启的 Yarn-Session 中运行。
[atguigu@hadoop102 flink-1.17.0]$ bin/flink run-c com.atguigu.wc.SocketStreamWordCount FlinkTutorial-1.0-SNAPSHOT.jar
客户端可以自行确定 JobManager 的地址,也可以通过-m 或者-jobmanager 参数指定 JobManager 的地址,JobManager 的地址在 YARN Session 的启动页面中可以找到。
③ 任务提交成功后,可在 YARN 的 Web UI 界面查看运行情况。hadoop103:8088。
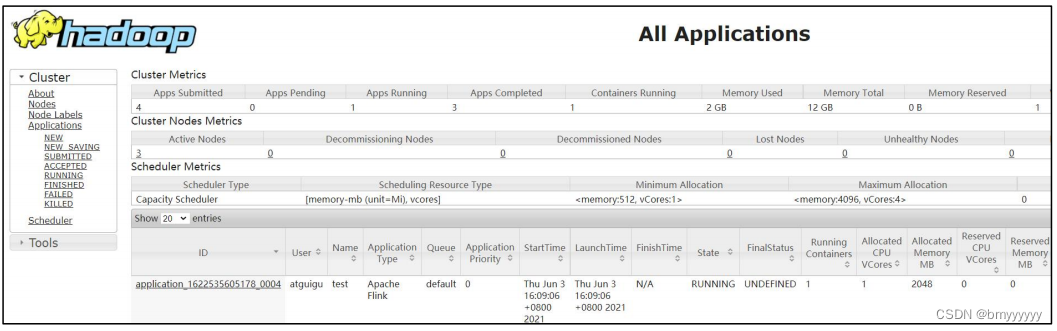
从上图中可以看到我们创建的 Yarn-Session 实际上是一个 Yarn 的 Application,并且有唯一的 Application ID。
④ 也可以通过 Flink 的 Web UI 页面查看提交任务的运行情况,如下图所示。
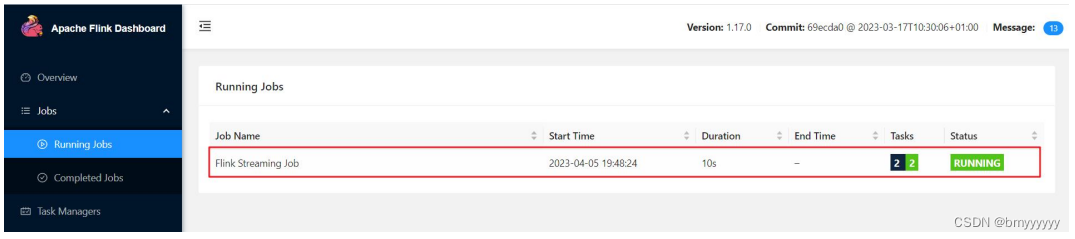
3.5.3.单作业模式部署
在 YARN 环境中,由于有了外部平台做资源调度,所以我们也可以直接向 YARN 提交一个单独的作业,从而启动一个 Flink 集群。
(1)执行命令提交作业。
[atguigu@hadoop102 flink-1.17.0]$ bin/flink run -d -t yarn-per-job-c com.atguigu.wc.SocketStreamWordCount FlinkTutorial-1.0-SNAPSHOT.jar
注意:如果启动过程中报如下异常。
Exception in thread “Thread-5” java.lang.IllegalStateException:Trying to access closed classloader. Please check if you store
classloaders directly or indirectly in static fields. If thestacktrace suggests that the leak occurs in a third party library
and cannot be fixed immediately, you can disable this check withthe configuration ‘classloader.check-leaked-classloader’.
atorg.apache.flink.runtime.execution.librarycache.FlinkUserCodeClassLoaders
解决办法:在 flink 的/opt/module/flink-1.17.0/conf/flink-conf.yaml 配置文件中设置
[atguigu@hadoop102 conf]$ vim flink-conf.yaml
classloader.check-leaked-classloader: false
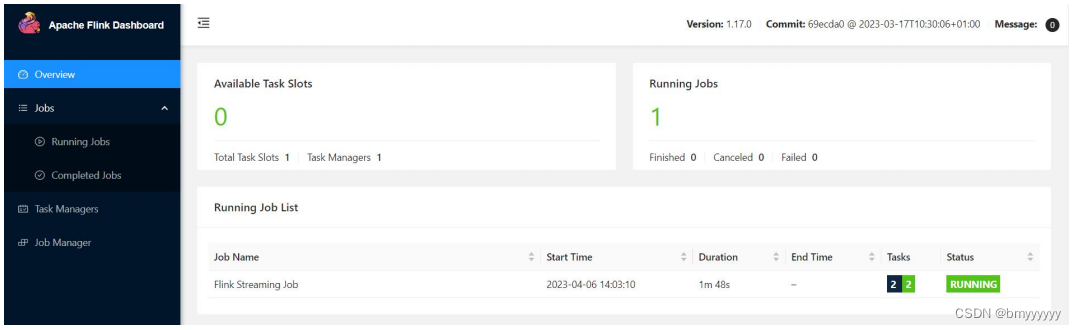
(2)在 YARN 的 ResourceManager 界面查看执行情况。

点击可以打开 Flink Web UI 页面进行监控,如下图所示:
(3)可以使用命令行查看或取消作业,命令如下。
[atguigu@hadoop102 flink-1.17.0]$ bin/flink list -t yarn-per-job -Dyarn.application.id=application_XXXX_YY
[atguigu@hadoop102 flink-1.17.0]$ bin/flink cancel -t yarn-per-job -Dyarn.application.id=application_XXXX_YY <jobId>
这里的 application_XXXX_YY 是当前应用的 ID,是作业的 ID。注意如果取消作业,整个 Flink 集群也会停掉。
3.5.4.应用模式部署
应用模式同样非常简单,与单作业模式类似,直接执行 flink run-application 命令即可。
1、命令行提交
(1)执行命令提交作业。
[atguigu@hadoop102 flink-1.17.0]$ bin/flink run-application -t yarn-application -c com.atguigu.wc.SocketStreamWordCount FlinkTutorial-1.0-SNAPSHOT.jar
(2)在命令行中查看或取消作业。
[atguigu@hadoop102 flink-1.17.0]$ bin/flink list -t yarnapplication -Dyarn.application.id=application_XXXX_YY
[atguigu@hadoop102 flink-1.17.0]$ bin/flink cancel -t yarnapplication -Dyarn.application.id=application_XXXX_YY <jobId>
2、上传 HDFS 提交
可以通过 yarn.provided.lib.dirs 配置选项指定位置,将 flink 的依赖上传到远程。
(1)上传 flink 的 lib 和 plugins 到 HDFS 上
[atguigu@hadoop102 flink-1.17.0]$ hadoop fs -mkdir /flink-dist
[atguigu@hadoop102 flink-1.17.0]$ hadoop fs -put lib/ /flink-dist
[atguigu@hadoop102 flink-1.17.0]$ hadoop fs -put plugins/ /flink-dist
(2)上传自己的 jar 包到 HDFS
[atguigu@hadoop102 flink-1.17.0]$ hadoop fs -mkdir /flink-jars
[atguigu@hadoop102 flink-1.17.0]$ hadoop fs -put FlinkTutorial-1.0-SNAPSHOT.jar /flink-jars
(3)提交作业
[atguigu@hadoop102 flink-1.17.0]$ bin/flink run-application -t yarn-application -Dyarn.provided.lib.dirs="hdfs://hadoop102:8020/flink-dist" -c com.atguigu.wc.SocketStreamWordCount hdfs://hadoop102:8020/flink-jars/FlinkTutorial-1.0-SNAPSHOT.jar
这种方式下,flink 本身的依赖和用户 jar 可以预先上传到 HDFS,而不需要单独发送到集
群,这就使得作业提交更加轻量了。
3.6.K8S 运行模式(了解)
容器化部署是如今业界流行的一项技术,基于 Docker 镜像运行能够让用户更加方便地对应用进行管理和运维。容器管理工具中最为流行的就是 Kubernetes(k8s),而 Flink 也在最近的版本中支持了 k8s 部署模式。基本原理与 YARN 是类似的,具体配置可以参见官网说明,这里我们就不做过多讲解了。
3.7.历史服务器
运行 Flink job 的集群一旦停止,只能去 yarn 或本地磁盘上查看日志,不再可以查看作业挂掉之前的运行的 Web UI,很难清楚知道作业在挂的那一刻到底发生了什么。如果我们还没有 Metrics 监控的话,那么完全就只能通过日志去分析和定位问题了,所以如果能还原之前的 Web UI,我们可以通过 UI 发现和定位一些问题。
Flink 提供了历史服务器,用来在相应的 Flink 集群关闭后查询已完成作业的统计信息。我们都知道只有当作业处于运行中的状态,才能够查看到相关的 WebUI 统计信息。通过History Server 我们才能查询这些已完成作业的统计信息,无论是正常退出还是异常退出。
此外,它对外提供了 REST API,它接受 HTTP 请求并使用 JSON 数据进行响应。Flink任务停止后,JobManager 会将已经完成任务的统计信息进行存档,History Server 进程则在任务停止后可以对任务统计信息进行查询。比如:最后一次的 Checkpoint、任务运行时的相关配置。
1、创建存储目录
hadoop fs -mkdir -p /logs/flink-job
2、在 flink-config.yaml 中添加如下配置
jobmanager.archive.fs.dir: hdfs://hadoop102:8020/logs/flink-job
historyserver.web.address: hadoop102
historyserver.web.port: 8082
historyserver.archive.fs.dir: hdfs://hadoop102:8020/logs/flink-job
historyserver.archive.fs.refresh-interval: 5000
3、启动历史服务器
bin/historyserver.sh start
4、停止历史服务器
bin/historyserver.sh stop
5、在浏览器地址栏输入:http://hadoop102:8082 查看已经停止的 job 的统计信息
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 会声会影2024最新视频制作教程及最新下载免费中文版
- STM32+HAL库驱动ADXL345传感器(SPI协议)
- OxLint 发布了,Eslint 何去何从?
- 宏集嵌入式工业树莓派,为企业提供更高效、精确和灵活的包装解决方案
- Java语言第三篇集合
- Python实现滚动回归模型(RollingOLS算法)项目实战
- 数学模型与数学建模(急救版80+)常考知识点(二)
- 浅谈MySQL之索引
- 《统计学习方法:李航》笔记 从原理到实现(基于python)-- 第3章 k邻近邻法
- ubuntu 安装apisix -亲测可用