【面试深度解析】字节后端日常实习一面这么问吗?
🌈🌈🌈🌈🌈🌈🌈🌈
欢迎关注公众号(通过文章导读关注:【11来了】),及时收到 AI 前沿项目工具及新技术的推送!在我后台回复 「资料」 可领取
编程高频电子书!
在我后台回复「面试」可领取硬核面试笔记!文章导读地址:点击查看文章导读!
感谢你的关注!
🍁🍁🍁🍁🍁🍁🍁🍁 
前言:
🚀 春招季即将来临,你准备好迎接挑战了吗? 🌟
🎯 【30天面试冲刺计划】 —— 专为大厂面试量身定制!
🔥 加入我们,一起解锁面试新高度! 🔥
🌈 你将获得:
深入解析:每日精选大厂面试真题,从面试官视角出发,剖析问题背后的考察点。
实战演练:模拟面试场景,教你如何巧妙应对,展现最佳自我。
全面覆盖:涵盖技术、算法、数据结构、系统设计等多维度面试话题。
独家秘籍:分享面试技巧,助你轻松应对各种棘手问题。
🔗 关注我,开启你的春招逆袭之旅! 🌠

文章目录
字节后端日常实习一面这么问吗
题目分析
1、前端发送请求到后端的过程
这个问题还是比较开放的,我自己感觉主要有两个重点:TCP、Spring MVC
接下来,先说一下整体的流程:
从前端发送请求到后端的整个流程,前端点击按钮发送 HTTP 请求,那么会先和后端服务 建立 TCP 连接,建立连接之后,前端就可以向后端继续发送数据了,后端收到请求之后,通过 Spring MVC 来对请求进行处理
接下来说一下 Spring MVC 处理的流程,它会先去拿到 HTTP 请求的 url,根据 url 找到对应的处理器,通过对应的处理器处理之后,返回 JSON 数据给前端,前端就拿到了后端的数据,再将数据渲染到页面中
扩展
那么接下来,既然你说了 TCP 和 Spring MVC,那么这两个点是很有可能被面试官深入下去问的
其中 TCP 三次握手、四次挥手肯定是要了解吧,Spring MVC 具体执行的流程也要了解一下吧(这个我也不太清楚现在面试的频繁不频繁了,有知道的小伙伴可以讨论一下)
这里先说一下 TCP,三次握手、四次挥手的流程肯定要知道,为什么不能两次挥手这个问题怎么回答呢?
可以直接假设两次挥手,如果 client 发送的第一个 SYN 包并没有丢失,只是在网络中滞留,以致于延误到连接释放以后的某个时间才到达 server。本来这是一个早已失效的报文,但 server 收到此失效报文后,就误认为是 client 再次发出的一个新的连接,于是向 client 发出 SYN+ACK 包,如果不采用三次握手,只要 server 发出 SYN+ACK 包,就建立连接,会导致 client 没有发出建立连接的请求,因此不会理会 server 的 SYN+ACK 包,但是 server 却以为新的连接建立好了,并一直等待 client 发送数据,导致资源被浪费。
其实还有一种说法就是,经过了三次握手,客户端和服务端才可以确保自己的收发能力都是正常的。
**为什么不四次握手?**因为三次握手就可以建立通信了,没必要四次握手,增加额外开销。
再说一下 Spring MVC 的执行流程,其实一句话就是通过 url 找到对应的处理器,执行对应的处理器即可(也就是 Controller),我也画了一张流程图,看着复杂,其实就是找到对应的 Handler 再执行,这里是通过 HandlerAdpter 来执行对应的 Handler
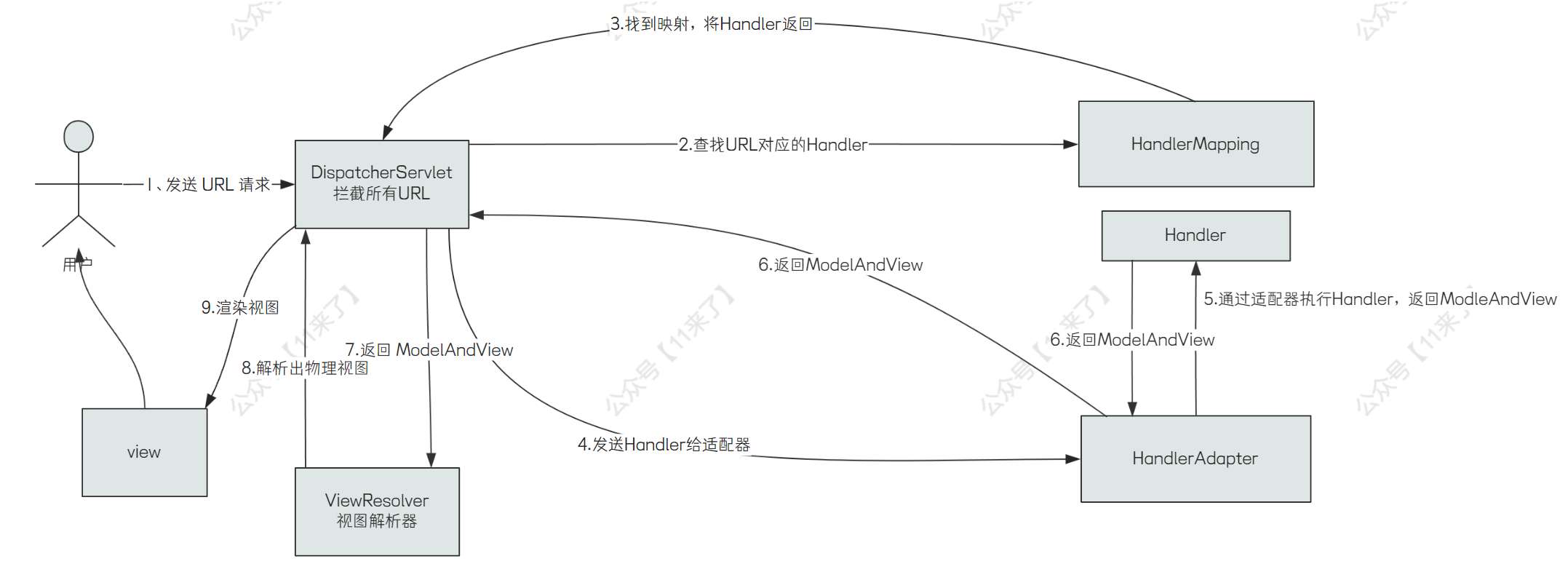
这里通过 Adapter 来执行 Handler 就使用了 适配器模式,那么适配器模式有什么好处呢?
让相互之间不兼容的类可以一起工作,客户端可以调用适配器的方法来适配不同的逻辑,这里举个例子:
如下,AdvancedMediaPlayer 是用来被适配的类,可以看到被适配的类中有两个不同的方法,要在不同的情况下调用不同的方法,那么就创建了 MediaPlayerAdapter 适配器类,定义一个 play() 方法,根据传入的类型不同,调用不同的方法,那么如果后来增加被适配的类,那么我们只需要在适配器中添加一个 if 条件即可完成扩展,这就是适配器模式的优势
public interface MediaPlayer {
void play(String audioType, String fileName);
}
// 被适配的类
public class AdvancedMediaPlayer {
public void playMp4(String fileName) {
System.out.println("Playing MP4 file: " + fileName);
}
public void playVlc(String fileName) {
System.out.println("Playing VLC file: " + fileName);
}
}
// 适配器
public class MediaPlayerAdapter implements MediaPlayer {
private AdvancedMediaPlayer advancedMediaPlayer;
public MediaPlayerAdapter(AdvancedMediaPlayer advancedMediaPlayer) {
this.advancedMediaPlayer = advancedMediaPlayer;
}
@Override
public void play(String audioType, String fileName) {
if ("mp4".equals(audioType)) {
advancedMediaPlayer.playMp4(fileName);
} else if ("vlc".equals(audioType)) {
advancedMediaPlayer.playVlc(fileName);
} else {
throw new IllegalArgumentException("Unsupported media type: " + audioType);
}
}
}
2、网关 Gateway 作用,怎么解决跨域问题?
网关的作用一般包含以下几个:
- 对请求进行路由,路由到不同的机器中,还有动态路由功能,即新增了几台服务,那么网关可以感知到服务的变化,动态进行路由
- 负载均衡,将请求分散到提供相同服务的多个机器上去
- 限流熔断,为了保护后端服务,对请求进行限流和熔断
- 认证授权,对请求进行认证授权操作
跨域问题(Cross-Origin Resource Sharing,CORS)是指当一个Web应用尝试从与它所在的源(协议、域名和端口)不同的源(服务器)请求资源时遇到的问题,浏览器出于安全考虑会阻止跨域请求,但是如果服务器允许的话,就不阻止
那么我们作为后端,了解一下后端如何解决跨域问题,通过注解 @CrossOrigin 指定 CORS 策略,origins = "*" 表示允许所有源进行跨域请求,如下
@RestController
public class HelloController {
// 允许所有源的跨域请求
@CrossOrigin(origins = "*")
@GetMapping("/hello")
public String hello() {
return "...";
}
}
3、Redission 中分布式锁的实现
这里面试官应该是想要考察你知不知道 Redission 底层如何进行加锁
Redission 中获取锁逻辑:
在 Redission 中加锁,通过一系列调用会到达下边这个方法
他的可重入锁的原理也就是使用 hash 结构来存储锁,key 表示锁是否存在,如果已经存在,表示需要重复访问同一把锁,会将 value + 1,即每次重入一次 value 就加 1,退出一次 value 就减 1
比如执行以下加锁命令:
RLock lock = redisson.getLock("lock");
lock.lock();
加锁最终会走到下边这个方法,在执行 lua 脚本时有三个参数分别为:
KEYS[1]: 锁名称,也就是上边的 “lock”ARGV[1]: 锁失效时间,默认 30 sARGV[2]: 格式为id + “:” + threadId:锁的小key,值为 c023afb1-afaa-402a-b23e-a21a82abec9d:1
这里讲解下边这个 lua 脚本的执行流程:
-
先去判断
KEYS[1]这个哈希结构是否存在 -
如果不存在,通过
hset去创建一个哈希结构,并放入一个 k-v 对这个哈希表名为锁的名称,也就是 “lock”,key 为
ARGV[2],也就是c023afb1-afaa-402a-b23e-a21a82abec9d:1, value 为 1 -
通过
pexpire设置 key 的过期时间,pexpire 的过期时间单位是毫秒,expire 单位是秒 -
如果这个哈希结构存在,去判断这个 key 是否存在
-
如果这个 key 存在,表示之前已经被当前线程加过锁了,再去重入加锁即可,也就是通过
hincrby给这个 key 的值加 1 即可,并且设置过期时间
<T> RFuture<T> tryLockInnerAsync(long leaseTime, TimeUnit unit, long threadId, RedisStrictCommand<T> command) {
internalLockLeaseTime = unit.toMillis(leaseTime);
return commandExecutor.evalWriteAsync(getName(), LongCodec.INSTANCE, command,
"if (redis.call('exists', KEYS[1]) == 0) then " +
"redis.call('hset', KEYS[1], ARGV[2], 1); " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return nil; " +
"end; " +
"if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then " +
"redis.call('hincrby', KEYS[1], ARGV[2], 1); " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return nil; " +
"end; " +
"return redis.call('pttl', KEYS[1]);",
Collections.<Object>singletonList(getName()), internalLockLeaseTime, getLockName(threadId));
}
4、线程池中队列满的策略
这里考察的就是线程池中的 拒绝策略 有那些了,有 4 种拒绝策略,默认策略是直接抛出异常,我觉得面试官也并不是让你把 4 种拒绝策略都给一字不差的背出来,考察的是如果任务队列满了之后,对于接下来的任务要如何处理?
那么最简单的肯定就是有新任务进入的话,直接抛出异常就好了
- AbortPolicy :直接抛出异常,默认策略
其他三种策略是怎么做的呢?
- CallerRunsPolicy:用调用者所在的线程来执行任务
- DiscardOldestPolicy:丢弃阻塞队列里最老的任务,也就是队列里靠前的任务
- DiscardPolicy :当前任务直接丢弃
可以看到,要么将老任务丢弃,要么将当前任务丢弃,要么线程池不执行,通过当前调用者的线程执行
扩展
其实我们 自己也可以定义拒绝策略,这个作为扩展点
比如有这样一个业务场景,任务队列满了,但是我们不能把任务丢弃掉,是必须要执行的
那么就可以定义一个拒绝策略,将任务异步持久化到磁盘中去,再通过定时任务将任务取出来进行执行
这里异步持久化到磁盘也就是存储到 MySQL 中,给任务标记一个状态(未提交、已提交、已完成),执行完成的话,就给任务状态更改标记
5、ConcurrentHashMap 了解吗?
考察并发安全的 HashMap 框架
那么这里要了解 ConcurrentHashMap 是如何去加锁来保证线程安全的
ConcurrentHashMap 在 JDK1.7 之前使用的是分段锁,这种锁开销比较大,并且锁的粒度也比较大,因此在 1.8 进行了优化
ConcurrentHashMap在 JDK1.8 中是通过 CAS + synchronized 来实现线程安全的,锁的粒度为单个节点,它的结构和 HashMap 一样:数组 + 链表 + 红黑树
在将节点往数组中存放的时候(没有哈希冲突),通过 CAS 操作进行存放
如果节点在数组中存放的位置有元素了,发生哈希冲突,则通过 synchronized 锁住这个位置上的第一个元素
那么面试官可能会问 ConcurrentHashMap 向数组中存放元素的流程,这里我给写一下(主要看一下插入元素时,在什么时候加锁了):
- 根据 key 计算出在数组中存放的索引
- 判断数组是否初始化过了
- 如果没有初始化,先对数组进行初始化操作,通过 CAS 操作设置数组的长度,如果设置成功,说明当前线程抢到了锁,当前线程对数组进行初始化
- 如果已经初始化过了,判断当前 key 在数组中的位置上是否已经存在元素了(是否哈希冲突)
- 如果当前位置上没有元素,则通过 CAS 将要插入的节点放到当前位置上
- 如果当前位置上有元素,则对已经存在的这个元素通过 synchronized 加锁,再去遍历链表,通过将元素插到链表尾
扩展
什么时候链表转为红黑树呢?
当链表长度大于 8 并且数组长达大于 64 时,才会将链表转为红黑树
6、轻量级、重量级锁
这里说的就是 JDK 在 1.6 中引入的对 synchronized 锁的优化,之前 synchronized 一直都是重量级锁,性能开销比较高
JDK 1.6 引入了偏向锁和轻量级锁
那么 synchronized 锁共有 4 种状态:无锁、偏向锁、轻量级锁、重量级锁
下边说一下锁的状态是如何进行升级的:
-
当线程第一次竞争到锁,
拿到的就是偏向锁,此时不存在其他线程的竞争偏向锁的性能是很高的,他会偏向第一个访问锁的线程,持有偏向锁的线程不需要触发同步,连 CAS 操作都不需要
JDK15 中标记了偏向锁为废弃状态,因为维护的开销比较大
-
如果有线程竞争的话,并且竞争不太激烈的情况下,
偏向锁升级为轻量级锁,也就是通过 CAS 自旋来竞争 -
当 CAS 自旋达到一定次数,
就会升级为重量级锁
这几种锁的状态存储在了对象头的 Mark Word 中,并且还指向了持有当前对象锁的线程
synchronized 加锁流程如下:
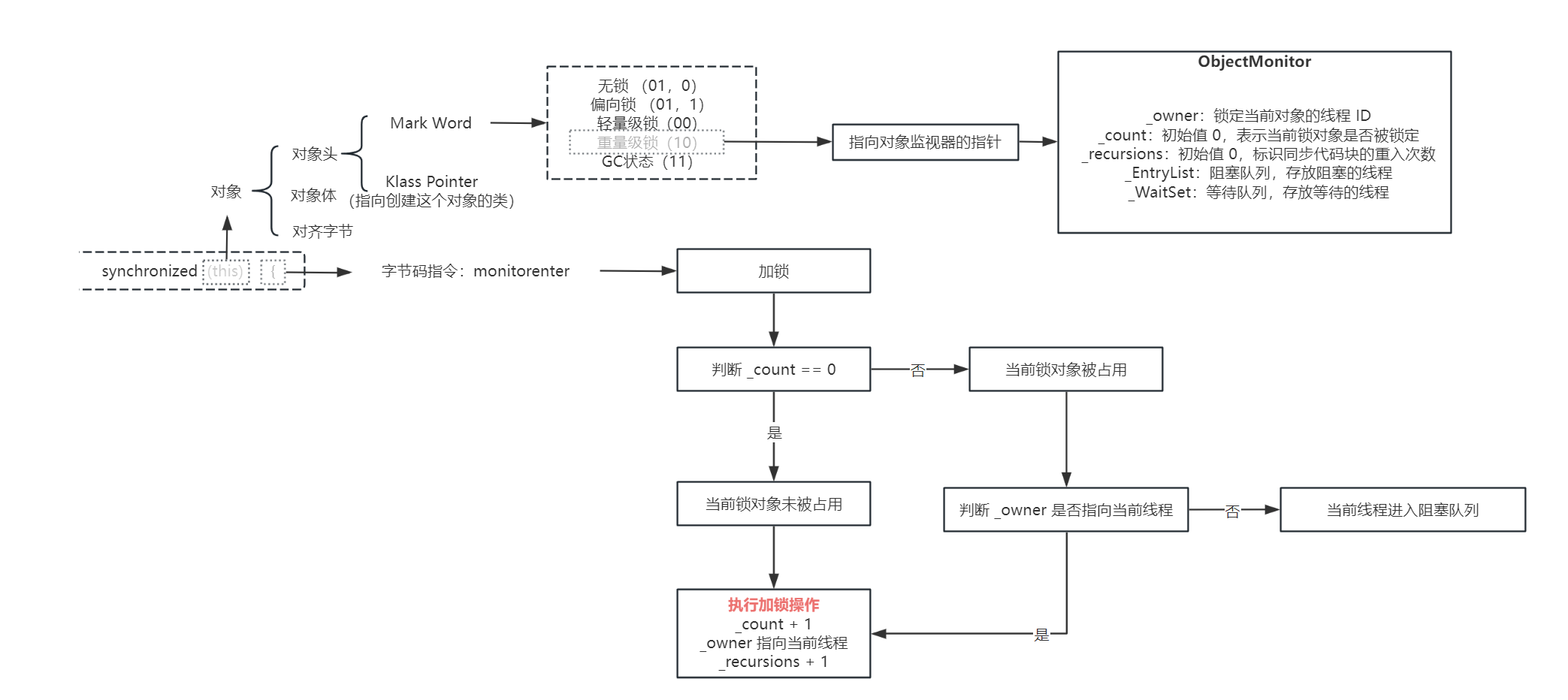
扩展
偏向锁在 JDK 15 之后就被废弃掉了,因为偏向锁增加了维护开销太高,并且偏向锁在一个线程一直访问的时候性能很高,但是大多数情况下会有多个线程来竞争,那么此时偏向锁的性能就会下降,因此逐渐废弃掉
Java 团队更推荐使用轻量级锁或者重量级锁:
- 如果竞争不激烈的话,并且每个线程对锁持有时间较短的情况下,可以使用轻量级锁,也就是 CAS 自旋等待获取锁
- 如果竞争激烈的情况下,或者每个线程持有锁的时间很长,如果还是用 CAS 自旋会导致大量线程在空转,大量占用 CPU 资源,因此要使用重量级锁
7、怎么实现锁?
我个人理解,可能面试官是要问锁的实现原理,因为毕竟上边已经说到 synchronized 锁的优化了,肯定会继续深入 synchronized 继续说,这里就说一下 CAS 和 synchronized 的底层原理怎么实现的
CAS 如何加锁?
CAS 操作主要涉及 3 个操作数:
- V:要写的内存地址
- E:预期值
- N:新写入的值
CAS 底层加锁的逻辑就是当内存地址的值等于预期值时,将该内存地址的值写为新的值,那么当多个线程来通过 CAS 操作时,肯定只有第一个线程可以操作成功
synchronized 如何加锁?
synchronized 是基于两个 JVM 指令来实现的:monitorenter 和 monitorexit
那么在这两个 JVM 指令中的代码就是被上了锁的,这一段代码就只有当前加锁的线程可以执行,从而保证线程之间的同步操作
另外一种可能
那么还有可能是问 Java 并发包下的 ReentrantLock 是如何实现加锁的,这里也来说一下
使用 ReentrantLock 来加锁时,要先构造一个 ReentrantLock 实例对象,再调用 lock 方法加锁,如果该锁没有被其他线程持有,则加锁成功
如果该锁被其他线程持有,当前线程会阻塞,那么就会把当前线程封装成为一个 Node 节点,加入到 AQS 队列中进行等待,当获取锁的线程释放锁之后,会从 AQS 队列中唤醒一个线程,AQS 队列如下:

ReentrantLock 还可以支持重入,如果锁重入的话,它里边会有一个属性 state 值进行加 1 操作记录,退出的话,会给 state 值减 1
如果 ReentrantLock 是公平锁的话,队列中的节点会按照顺序去抢占锁,如果是非公平锁,则可以直接抢占锁,不需要按顺序
如果 ReentrantLock 加锁成功的话,主要会修改两个地方:
- 修改 ReentrantLock 同步状态 state,修改为 1,表示被上了锁
- 修改 ReentrantLock 锁的持有线程为当前线程,表示当前线程持有了这把锁
如果是释放锁的话,也是修改同步状态 state = 0 和持有当前锁的线程为 null 接口
这里贴出来一个简单用法:
public class Counter {
private int count = 0;
private final ReentrantLock lock = new ReentrantLock(true); // 创建一个公平锁
public void increment() {
// 尝试获取锁
lock.lock();
try {
// 在锁的保护下执行操作
count++;
System.out.println("Incrementing counter to " + count);
} finally {
// 无论操作是否成功,都要释放锁
lock.unlock();
}
}
public static void main(String[] args) {
Counter counter = new Counter();
// 创建多个线程来操作计数器
Thread t1 = new Thread(() -> counter.increment());
Thread t2 = new Thread(() -> counter.increment());
// 启动线程
t1.start();
t2.start();
}
}
8、where 多条件查询,是否走索引?
这个就是 MySQL 中的基础了,要你判断是不是走索引,根据最左前缀原则判断即可
这里讲一下最左前缀原则
最左前缀原则:规定了联合索引在何种查询中才能生效。
规则如下:
- 如果想使用联合索引,联合索引的最左边的列必须作为过滤条件,否则联合索引不生效
如下图:
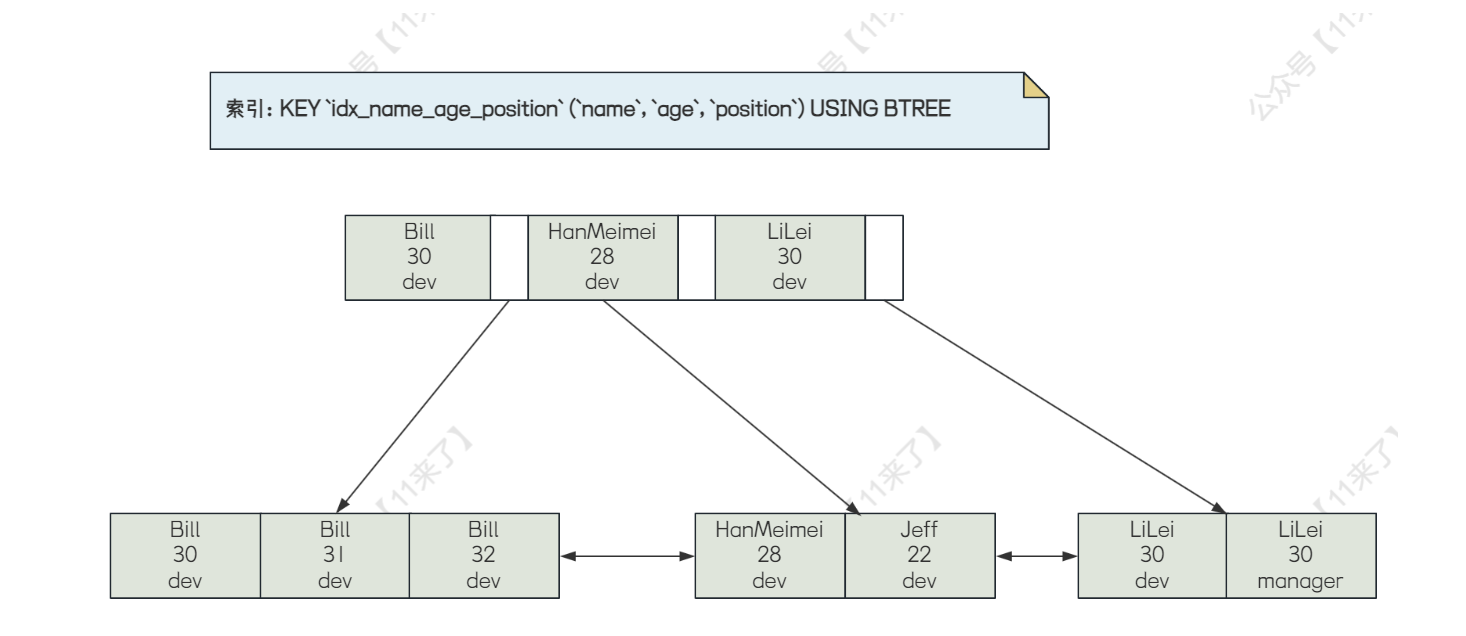
假如索引为:(name, age, position)
select * from employee where name = 'Bill' and age = 31;
select * from employee where age = 30 and position = 'dev';
select * from employee where position = 'manager';
索引的顺序是:name、age、position,因此对于上边三条 sql 语句,只有第一条 sql 语句走了联合索引
第二条语句将索引中的第一个 name 给跳过了,因此不走索引
第三条语句将索引中的前两个 name、age 给跳过了,因此不走索引
为什么联合索引需要遵循最左前缀原则呢?
因为索引的排序是根据第一个索引、第二个索引依次排序的,假如我们单独使用第二个索引 age 而不使用第一个索引 name 的话,我们去查询age为30的数据,会发现age为30的数据散落在链表中,并不是有序的,所以使用联合索引需要遵循最左前缀原则。
9、如何将同姓名记录拼到同一行?
应该是考察 sql 的使用把,group by 和 group_concat
group_concat 将多个值拼接在一起
这里写一个例子,对下边这个 user 表:
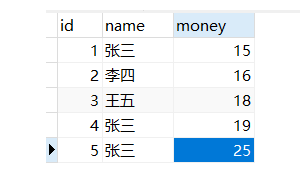
sql 语句:
select name, group_concat(money separator ',') as records
from user
group by money;
10、字符串拼接
这个就是 Java 基础的东西了
字符串拼接可以通过 + 和 StringBuilder 两种方式来进行拼接
而使用 + 进行字符串拼接,其实底层还是使用 StringBuilder 来拼接的,但是如果在循环中,使用 + 进行字符串拼接,会导致创建很多 StringBuilder 对象,因此如果需要字符串拼接,推荐还是直接使用 StringBuilder
再说一下 StringBuilder 和 StringBuffer 的区别(StringBuffer 可以保证线程安全):
- 单线程操作字符串缓冲区下操作大量数据使用
StringBuilder - 多线程操作字符串缓冲区下操作大量数据使用
StringBuffer
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 论文阅读--EFFICIENT OFFLINE POLICY OPTIMIZATION WITH A LEARNED MODEL
- 作业--day35
- 【leetcode题解C++】232.用栈实现队列 and 225.用队列实现栈 and 20.有效的括号 and 1047.删除字符串中的所有相邻重复项
- 【SpringCloud】-GateWay源码解析
- 淘宝商家实现批量上货API接口调用接入说明(淘宝开放平台免申请接入)
- 电商API接入|四步轻松搞定电商商品详情页数据埋点
- GraphPad Prism 10.1.1 For Mac 安装及新功能梳理
- 博客社区资讯APP源码/开源知识付费社区小程序源码/资源社区源码/独有付费阅读+兼容安卓苹果
- ABC210(A-C)
- Spark与Elasticsearch的集成与全文搜索